
Scrapeless के स्क्रैपिंग ब्राउज़र का उपयोग करके वेब पेज कैसे स्क्रैप करें
Advanced Data Extraction Specialist
वेब स्क्रैपिंग व्यवसायों के लिए वास्तविक समय डेटा एकत्र करने का एक महत्वपूर्ण उपकरण बन गया है, जिसमें प्रतियोगी मूल्य निर्धारण से लेकर बाजार के रुझान शामिल हैं। हाल ही में हुए एक Statista सर्वेक्षण में पाया गया है कि 70% से अधिक व्यवसाय मूल्यवान डेटा निकालने के लिए वेब स्क्रैपिंग पर निर्भर करते हैं, जो इसे डेटा-संचालित निर्णय लेने का एक महत्वपूर्ण हिस्सा बनाता है।
जैसे-जैसे वेब स्क्रैपिंग बाजार बढ़ रहा है, 2025 तक 5.4 बिलियन अमरीकी डालर तक पहुँचने का अनुमान है (MarketsandMarkets), व्यवसाय अपनी दक्षता और स्केलेबिलिटी के लिए स्क्रैपिंग टूल को तेजी से अपना रहे हैं। हालाँकि, IP ब्लॉकिंग, CAPTCHAs और गतिशील सामग्री जैसी चुनौतियाँ स्क्रैपिंग प्रक्रिया को बाधित कर सकती हैं।
Scrapeless अपने AI-संचालित समाधानों के साथ इन मुद्दों को हल करता है, जो सामान्य एंटी-स्क्रैपिंग बाधाओं के सामने भी सहज डेटा निष्कर्षण सुनिश्चित करता है।
Scrapeless के स्क्रैपिंग ब्राउज़र के साथ आज ही स्मार्ट स्क्रैपिंग शुरू करें! हमारे उपयोगकर्ता के अनुकूल टूल के साथ वेब पेजों से डेटा आसानी से निकालें, जिसे सबसे जटिल वेबसाइटों को भी संभालने के लिए डिज़ाइन किया गया है। इसे अभी आज़माएँ और पहले जैसा सहज डेटा निष्कर्षण अनुभव करें!
Scrapeless एक उन्नत AI-संचालित वेब स्क्रैपिंग समाधान प्रदान करता है जिसे व्यवसायों को इन सामान्य बाधाओं को दूर करने में मदद करने के लिए डिज़ाइन किया गया है। Scrapeless टूलकिट उन लोगों के लिए तैयार किया गया है जो वेब से उच्च-गुणवत्ता, विश्वसनीय और तेज़ डेटा निष्कर्षण की तलाश में हैं। चाहे आप ई-कॉमर्स साइट, सोशल मीडिया प्लेटफ़ॉर्म या समाचार एग्रीगेटर को स्क्रैप करना चाहते हों, Scrapeless काम पूरा करने के लिए सही उपकरण प्रदान करता है।
Scrapeless के प्रमुख लाभ शामिल हैं:
- सहज प्रॉक्सी प्रबंधन: IP रोटेशन और वैश्विक कवरेज के साथ अपने स्क्रैपिंग सत्रों की सुरक्षा करें।
- AI-संचालित CAPTCHA समाधान: अपने डेटा संग्रह को निर्बाध रखने के लिए CAPTCHA चुनौतियों को स्वचालित रूप से हल करें।
- उन्नत ब्राउज़र तकनीक: त्रुटियों के बिना जटिल, गतिशील वेब पेजों को नेविगेट करें।
- स्केलेबल समाधान: छोटे डेटा निष्कर्षण कार्यों से लेकर बड़े पैमाने पर स्क्रैपिंग संचालन तक, Scrapeless आपकी आवश्यकताओं को पूरा करने के लिए स्केल कर सकता है।
Scrapeless केवल एक और स्क्रैपिंग टूल से कहीं अधिक है। यह एक व्यापक प्लेटफ़ॉर्म है जो वेब स्क्रैपिंग से जुड़ी प्रमुख चुनौतियों का समाधान करता है, यह सुनिश्चित करता है कि आपका डेटा संग्रह तेज़, कुशल और विश्वसनीय रहे। चाहे आप एक स्टार्टअप हों या एक बड़ा उद्यम, Scrapeless का लचीलापन आपको अपने स्क्रैपिंग कार्यों को अपनी विशिष्ट आवश्यकताओं के अनुसार अनुकूलित करने की अनुमति देता है। प्रॉक्सी प्रबंधन से लेकर गतिशील सामग्री वाली जटिल वेबसाइटों को संभालने तक, Scrapeless आपके वेब स्क्रैपिंग संचालन को सरल बनाने और बहुमूल्य समय बचाने के लिए सभी आवश्यक उपकरण प्रदान करता है।
Scrapeless स्क्रैपिंग ब्राउज़र:
Scrapeless वेब स्क्रैपिंग समाधान के केंद्र में स्क्रैपिंग ब्राउज़र है। Scrapeless का स्क्रैपिंग ब्राउज़र सबसे चुनौतीपूर्ण स्क्रैपिंग परिदृश्यों को संभालने के लिए अनुकूलित है और एक असाधारण स्क्रैपिंग अनुभव प्रदान करने के लिए Scrapeless टूलकिट के साथ सहज रूप से एकीकृत होता है।
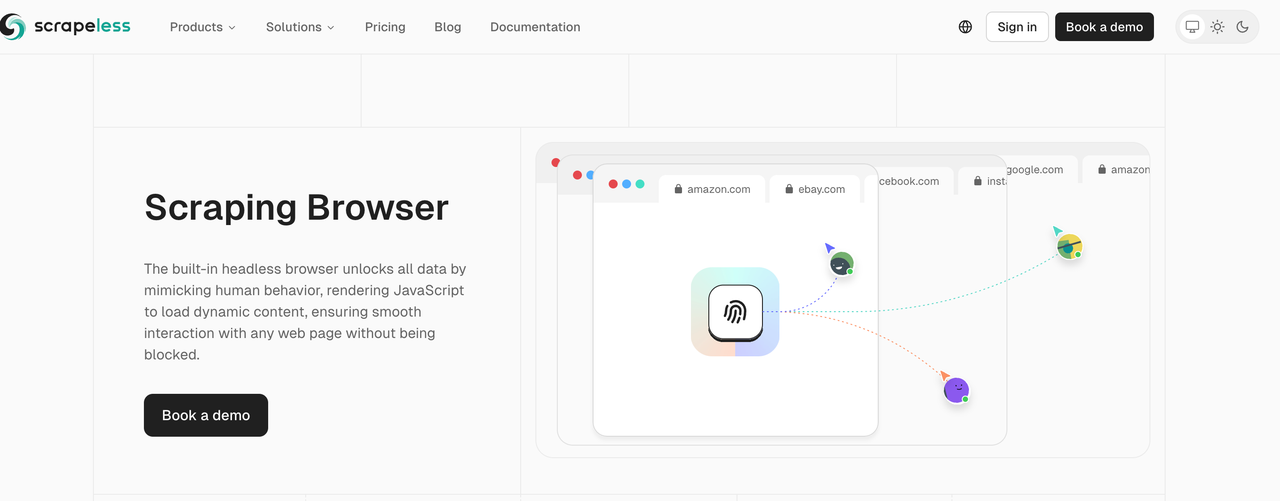
Scrapeless स्क्रैपिंग ब्राउज़र की प्रमुख विशेषताएँ:
- 🌐 गतिशील सामग्री हैंडलिंग: भारी जावास्क्रिप्ट और गतिशील सामग्री वाली वेबसाइटों को आसानी से स्क्रैप करें, जिनसे अन्य उपकरण अक्सर जूझते हैं।
- 🖥️ हेडलेस मोड: पूर्ण ब्राउज़र विंडो लॉन्च किए बिना स्क्रैपिंग कार्य चलाएँ, प्रदर्शन में सुधार करें और संसाधन उपयोग को कम करें।
- 🛡️ एंटी-डिटेक्शन तकनीक: ब्राउज़र फ़िंगरप्रिंट और स्टील्थ मोड जैसी उन्नत तकनीकों के साथ पता लगाने से बचें।
- ⚡ बेहतर दक्षता: पारंपरिक ब्राउज़र मोड से 10 गुना तेज, सर्वर साइड पर चल रहा है, जिससे तेज़ प्रतिक्रिया समय और बड़े पैमाने पर समवर्ती पहुँच का समर्थन होता है।
- ⏱️ 99.99% अपटाइम: विश्वसनीय, 24/7 उपलब्धता सुनिश्चित करती है कि आपके स्क्रैपिंग कार्य हमेशा समय पर चलते रहें।
Scrapeless के स्क्रैपिंग ब्राउज़र के साथ, आपकी डेटा निष्कर्षण प्रक्रिया तेज, अधिक विश्वसनीय और आसान हो जाती है, यह सुनिश्चित करती है कि आप स्क्रैपिंग की तकनीकी चुनौतियों से निपटने के बजाय मूल्यवान अंतर्दृष्टि निकालने पर ध्यान केंद्रित कर सकें।
Scrapeless के स्क्रैपिंग ब्राउज़र के साथ आरंभ करना
API कुंजी (एप्लिकेशन प्रोग्रामिंग इंटरफ़ेस कुंजी) एक उपकरण है जिसका उपयोग पहचान सत्यापित करने और API तक पहुँच को अधिकृत करने के लिए किया जाता है। यह आमतौर पर अक्षरों, संख्याओं और प्रतीकों का एक अनूठा क्रम होता है। API कुंजी API तक पहुँचते समय प्रमाणीकरण "पास" के रूप में कार्य करती है, यह सुनिश्चित करती है कि अनुरोध एक वैध उपयोगकर्ता या एप्लिकेशन द्वारा किया गया है।
✅ आप नीचे दिए गए चरणों का पालन करके API कुंजी प्राप्त कर सकते हैं:
- Scrapeless में लॉग इन करने के लिए क्लिक करने के बाद, आप स्वचालित रूप से संबंधित API कुंजी प्राप्त कर सकते हैं।
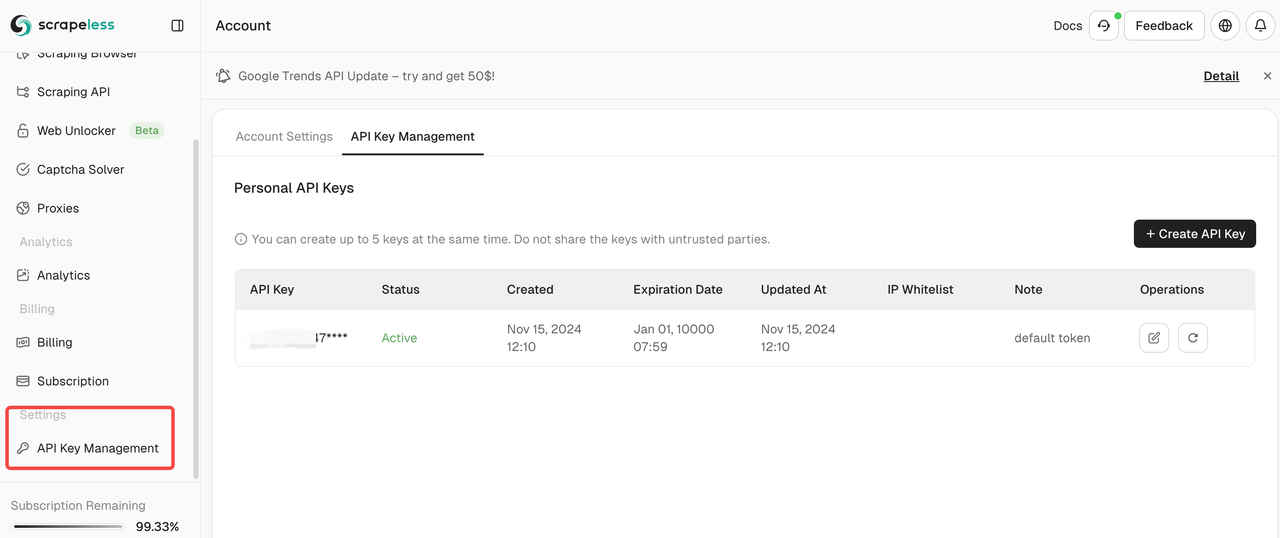
- आप API कुंजी प्रबंधन में अपनी API कुंजी देख सकते हैं:
Scrapeless के साथ वेब पेजों को स्क्रैप करने के लिए चरण-दर-चरण मार्गदर्शिका
इस खंड में, हम Amazon में उत्पाद सामग्री क्रॉल करने के तरीके को प्रदर्शित करने के लिए scrapeless + puppeteer का उपयोग करेंगे।
Puppeteer Google द्वारा विकसित एक Node.js लाइब्रेरी है जो क्रोमियम या क्रोम ब्राउज़र के माध्यम से स्वचालित संचालन करने के लिए एक उच्च-स्तरीय API प्रदान करती है। इसका उपयोग ब्राउज़र को संचालित करने, क्लिक करने, इनपुट करने, नेविगेट करने आदि के लिए किया जा सकता है, जैसे कि एक मानव उपयोगकर्ता, और यह पृष्ठ सामग्री को क्रॉल भी कर सकता है, स्क्रीनशॉट और पीडीएफ उत्पन्न कर सकता है, वेब पेजों का परीक्षण कर सकता है, आदि।
सबसे पहले, हमें API कुंजी scrapeless प्राप्त करने की आवश्यकता है। आप अपनी API कुंजी प्राप्त करने और देखने का तरीका जानने के लिए पिछले अनुभाग को देख सकते हैं।
Scrapeless के साथ वेब पेजों को स्क्रैप करने के लिए चरण-दर-चरण मार्गदर्शिका:
- npm कमांड के माध्यम से puppeteer स्थापित करें
npm i puppeteer-core- scrapeless के लिए कनेक्शन पैरामीटर तैयार करें। आप सत्र समय और प्रॉक्सी देश कॉन्फ़िगरेशन सेट कर सकते हैं।
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';- Amazon पर उत्पाद डेटा क्रॉल करने की तैयारी शुरू करें।
- इनपुट बॉक्स और खोज तत्वों को प्राप्त करने के लिए ब्राउज़र के डेवलपर टूल (F12) का उपयोग करें, और तत्व का चयनकर्ता प्राप्त करें।
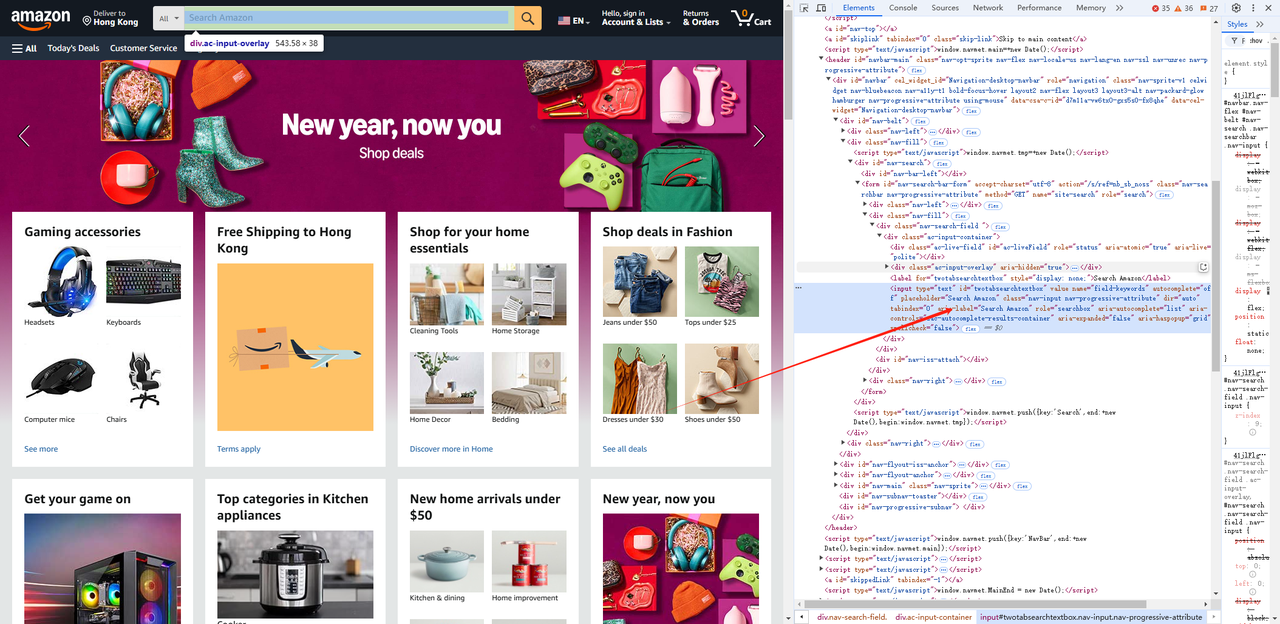
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')आप अपनी इच्छित सामग्री को क्रॉल करने के लिए iphone 15 को बदल सकते हैं।
- फिर हम उत्पाद सूची पृष्ठ पर आते हैं, और हम उन सभी div तत्वों को प्राप्त करते हैं जिनकी भूमिका विशेषता listitem है।
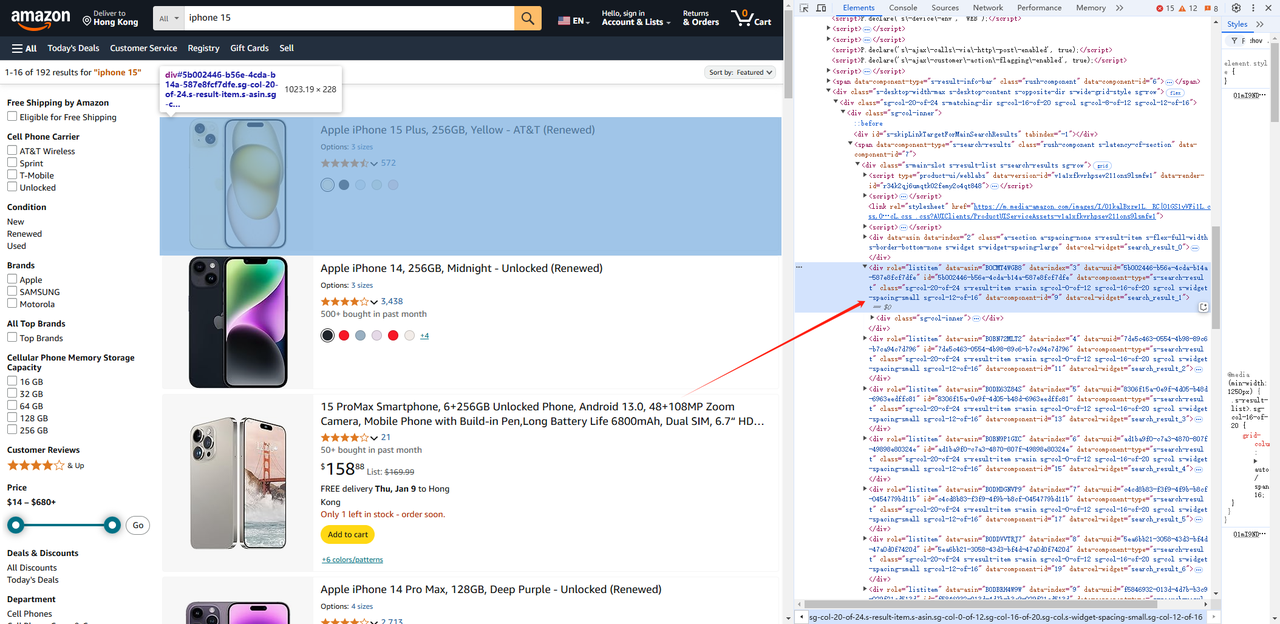
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]') // इसे लाने से पहले आपको तत्व के रेंडर होने की प्रतीक्षा करने की आवश्यकता है
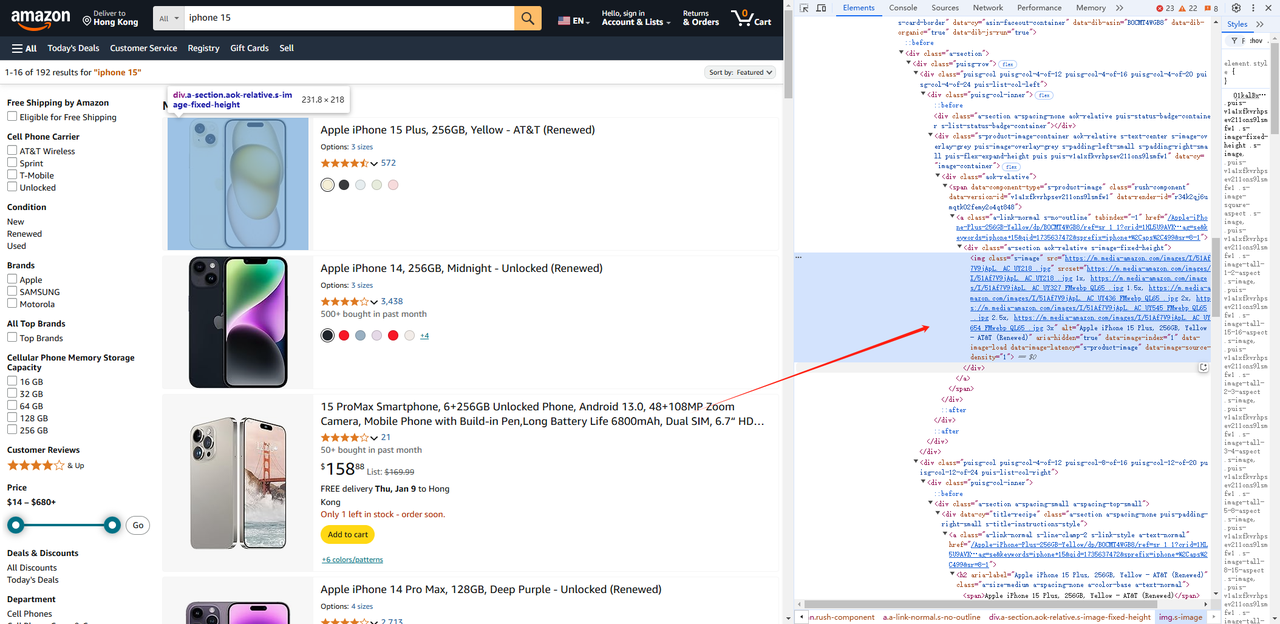
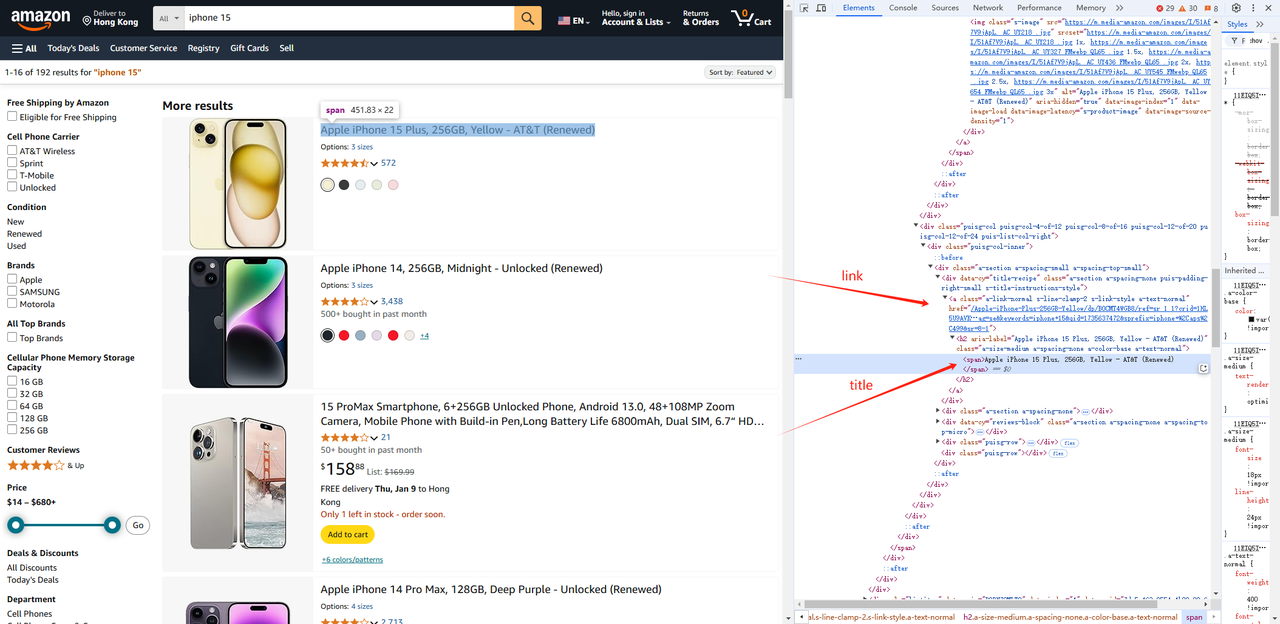
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')- इसी तरह, हम प्रत्येक तत्व के लिए चित्र, शीर्षक, लिंक आदि जैसी उत्पाद जानकारी प्राप्त कर सकते हैं।
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}क्रॉल की गई सामग्री प्राप्त करने के लिए निम्नलिखित पूर्ण कोड चलाएँ:
import puppeteer from 'puppeteer-core';
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';
(async () => {
try {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
await page.goto('https://www.amazon.com/');
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}
console.log(JSON.stringify(renderList))
} catch (e) {
console.error(e)
}
})();[
{
"img": "https://m.media-amazon.com/images/I/61WUSYIQdKL._AC_UY218_.jpg",
"title": "Apple iPhone 14, 256GB, Midnight - Unlocked (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-14-256GB-Midnight/dp/B0BN72MLT2/ref=sr_1_1?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-1"
},
{
"img": "https://m.media-amazon.com/images/I/51Af7V9jApL._AC_UY218_.jpg",
"title": "Apple iPhone 15 Plus, 256GB, Yellow - AT&T (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-Plus-256GB-Yellow/dp/B0CMT4WGB8/ref=sr_1_2?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-2"
},
{
"img": "https://m.media-amazon.com/images/I/71wtsuGLA4L._AC_UY218_.jpg",
"title": "15 ProMax Smartphone, 6+256GB Unlocked Phone, Android 13.0, 48+108MP Zoom Camera, Mobile Phone with Build-in Pen,Long Batt...",
"link": "https://www.amazon.com/15-ProMax-Smartphone-Unlocked-Titanium/dp/B0DK63Z84S/ref=sr_1_3?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-3"
},
{
"img": "https://m.media-amazon.com/images/I/71Xu6GSGm1L._AC_UY218_.jpg",
"title": "Apple iPhone 15 Pro, 128GB, Natural Titanium - Boost Mobile (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-128GB-Natural-Titanium/dp/B0DK7BCPH5/ref=sr_1_4?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-4"
},
{
"img": "https://m.media-amazon.com/images/I/61j3-75mrLL._AC_UY218_.jpg",
"title": "SZV 15 ProMAX 12+512GB Unlocked Cell Phone,Smartphone 6.85\" HD Screen Unlocked Phones,Battery 7000mAh Android 13,5G/Face I...",
"link": "https://www.amazon.com/SZV-Unlocked-Smartphone-Battery-Fingerprint/dp/B0DHDGNVP9/ref=sr_1_5?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-5"
}
]पावर उपयोगकर्ताओं के लिए उन्नत सुविधाएँ
बड़े पैमाने पर या जटिल वेब स्क्रैपिंग संचालन करते समय, दक्षता बनाए रखने, बाधाओं को दूर करने और अपने स्क्रैपिंग कार्यों को बढ़ाने के लिए उन्नत सुविधाएँ आवश्यक हैं। Scrapeless स्क्रैपिंग ब्राउज़र पेशेवर उपयोगकर्ताओं की ज़रूरतों को पूरा करने के लिए शक्तिशाली सुविधाओं की एक श्रृंखला प्रदान करता है, जिन्हें बुनियादी स्क्रैपिंग क्षमताओं से अधिक की आवश्यकता होती है, और कुछ उन्नत सुविधाएँ भी प्रदान करता है:
- विशिष्ट उपयोग के मामलों के लिए स्क्रैपिंग पैरामीटर को अनुकूलित करें
वेब स्क्रैपिंग की मुख्य चुनौतियों में से एक यह है कि अपने टूल को ठीक वही निकालने के लिए तैयार किया जाए जिसकी आपको आवश्यकता है, बिना अनावश्यक डेटा उत्पन्न किए या अवसरों को याद किए। Scrapeless उन्नत अनुकूलन विकल्प प्रदान करता है जो उपयोगकर्ताओं को अपने सटीक उपयोग के मामले में फिट होने के लिए विशिष्ट स्क्रैपिंग पैरामीटर सेट करने की अनुमति देता है।
- CAPTCHA और एंटी-स्क्रैपिंग सुरक्षा को संभालें
वेबसाइटें अक्सर स्वचालित रोबोट को ब्लॉक करने के लिए CAPTCHA चुनौतियों और जटिल एंटी-स्क्रैपिंग तंत्र को तैनात करती हैं। Scrapeless स्क्रैपिंग ब्राउज़र CAPTCHA अनब्लॉकिंग क्षमताओं वाला एक क्लाउड-आधारित फ़िंगरप्रिंटिंग ब्राउज़र है। ये उन्नत समाधान न केवल डेटा संग्रह की गति को बढ़ाते हैं, बल्कि मजबूत एंटी-बॉट उपायों वाली वेबसाइटों द्वारा पता लगाए जाने या ब्लॉक किए जाने की संभावना को भी कम करते हैं।
- स्केलेबिलिटी के लिए प्रॉक्सी और रोटेशन का उपयोग करें और IP प्रतिबंधों से बचें
स्क्रैपिंग संचालन को बढ़ाना अक्सर वेबसाइटों को IP को प्रतिबंधित करने और दरों को सीमित करने की ओर ले जाता है, जो डेटा संग्रह को बाधित करता है। इस समस्या को कम करने के लिए, Scrapeless एक शक्तिशाली प्रॉक्सी नेटवर्क प्रदान करता है जिसमें IP रोटेशन और प्रॉक्सी पूल शामिल हैं ताकि आपको बिना किसी रुकावट के निरंतर, बड़े पैमाने पर क्रॉलिंग बनाए रखने में मदद मिल सके। Scrapeless 200 से अधिक देशों के 80 मिलियन से अधिक IP के विशाल प्रॉक्सी नेटवर्क तक पहुँच प्रदान करता है, यह सुनिश्चित करता है कि उपयोगकर्ता अनुरोधों को वितरित कर सकें और IP प्रतिबंधों से बच सकें।
प्रभावी वेब स्क्रैपिंग के लिए सर्वोत्तम अभ्यास
वेब से मूल्यवान डेटा एकत्र करने के इच्छुक व्यवसायों के लिए वेब स्क्रैपिंग एक शक्तिशाली उपकरण है। हालाँकि, डेटा को कुशलतापूर्वक निकालने और सामान्य नुकसान से बचने के लिए, सर्वोत्तम अभ्यासों का पालन करना महत्वपूर्ण है। Scrapeless जैसे AI-संचालित समाधानों का लाभ उठाकर, व्यवसाय अपनी स्क्रैपिंग रणनीतियों को सटीकता, अनुपालन और स्केलेबिलिटी सुनिश्चित करने के लिए बढ़ा सकते हैं। यहाँ वेब स्क्रैपिंग के सर्वोत्तम अभ्यासों का विवरण दिया गया है, जिसमें यह भी बताया गया है कि Scrapeless इन प्रक्रियाओं को आपके लिए कैसे अनुकूलित कर सकता है।
डेटा सटीकता और पूर्णता सुनिश्चित करें
वेब स्क्रैपिंग की मुख्य चुनौतियों में से एक यह सुनिश्चित करना है कि एकत्रित डेटा सटीक है। विभिन्न स्रोतों से बड़े डेटासेट निकालते समय, डेटा में गुम या असंगति जैसी समस्याओं में भागना आसान है। इसका मुकाबला करने के लिए, Scrapeless में AI एल्गोरिदम स्वचालित रूप से वेब पेज संरचना का विश्लेषण कर सकते हैं और सामग्री में फिट होने के लिए स्क्रैपिंग दृष्टिकोण को समायोजित कर सकते हैं।
कानूनी और नैतिक मानकों का पालन करें
वेब स्क्रैपिंग पर बढ़ती जाँच के साथ, कानूनी और नैतिक सीमाओं के भीतर काम करना महत्वपूर्ण है। स्क्रैपर्स को गोपनीयता कानूनों, वेबसाइट की सेवा की शर्तों और GDPR जैसे नियमों से अवगत होना चाहिए। Scrapeless यह सुनिश्चित करने के लिए बुद्धिमान robots.txt पहचान को एकीकृत करके अनुपालन बनाए रखने में मदद करता है कि स्क्रैपिंग वेबसाइट के मालिकों द्वारा निर्धारित नियमों का पालन करता है।
इसके अतिरिक्त, AI का उपयोग वेब पेज सामग्री का विश्लेषण करने और संवेदनशील या संरक्षित डेटा को फ़िल्टर करने के लिए किया जा सकता है, यह सुनिश्चित करते हुए कि व्यवसाय अनैतिक प्रथाओं से बचते हैं। Scrapeless के AI एल्गोरिदम उपयोगकर्ताओं को कानूनी आवश्यकताओं का पालन करने में मदद करने के लिए डिज़ाइन किए गए हैं, जिससे उन्हें बौद्धिक संपदा उल्लंघन या गोपनीयता उल्लंघन जैसे जोखिमों से बचने में मदद मिलती है।
वेबसाइटों द्वारा ब्लॉक होने से बचें
वेबसाइटें अक्सर स्वचालित स्क्रैपर्स का पता लगाने और ब्लॉक करने के लिए एंटी-स्क्रैपिंग उपायों को तैनात करती हैं। Scrapeless में AI तकनीक मानव ब्राउज़िंग व्यवहार का अनुकरण करके पता लगाने से बचने में मदद करती है, जिससे स्क्रैपिंग अनुरोध अधिक स्वाभाविक दिखते हैं। AI एल्गोरिथम वास्तविक उपयोगकर्ता गतिविधि की नकल करने के लिए अनुरोध आवृत्ति, समय और हेडर को समायोजित करता है, जिससे ब्लॉक होने की संभावना बहुत कम हो जाती है।
इसके अलावा, Scrapeless प्रॉक्सी रोटेशन का उपयोग करता है, एक AI-संचालित प्रणाली जो अनुरोधों को वितरित करने के लिए स्वचालित रूप से कई IP पतों के बीच स्विच करती है। यह दर सीमा को बायपास करने में मदद करता है और एक ही IP पते को बहुत अधिक अनुरोध भेजने के लिए वेबसाइटों को ब्लॉक करने से रोकता है। AI-आधारित प्रॉक्सी रोटेशन का बुद्धिमानी से उपयोग करके, Scrapeless निर्बाध डेटा निष्कर्षण सुनिश्चित करता है।
बड़े पैमाने पर डेटा संग्रह के लिए Scrapeless तकनीक का अनुकूलन
बड़े पैमाने पर डेटा संग्रह में लगे व्यवसायों के लिए, स्क्रैपिंग दक्षता और स्केलेबिलिटी महत्वपूर्ण हैं। Scrapeless की AI क्षमताएँ इष्टतम प्रदर्शन सुनिश्चित करने के लिए स्क्रैपिंग रणनीतियों को स्वचालित रूप से समायोजित करती हैं, भले ही जटिल या बड़ी वेबसाइटों से डेटा निकाला जा रहा हो। उदाहरण के लिए, Scrapeless का AI-संचालित क्रॉलर जावास्क्रिप्ट-गहन वेबसाइटों जैसी गतिशील सामग्री को संभाल सकता है, जिससे व्यवसायों को व्यापक रेंज की सामग्री क्रॉल करने में सक्षम हो सकता है जिसे पारंपरिक उपकरण संभालने के लिए संघर्ष कर सकते हैं।
इसके अतिरिक्त, AI एल्गोरिदम बड़ी मात्रा में जानकारी संसाधित करते समय संसाधनों के कुशल आवंटन को सुनिश्चित करते हुए, सबसे महत्वपूर्ण डेटा को प्राथमिकता देने में मदद करते हैं। यह सहज उच्च-वॉल्यूम क्रॉलिंग को सक्षम बनाता है जो गति और प्रदर्शन को बनाए रखते हुए व्यावसायिक आवश्यकताओं को पूरा करता है।
वेब स्क्रैपिंग के सर्वोत्तम अभ्यासों का पालन करना एकत्रित डेटा के मूल्य को अधिकतम करने की कुंजी है। Scrapeless की AI-संचालित क्रॉलिंग तकनीक का लाभ उठाकर, व्यवसाय डेटा सटीकता में सुधार कर सकते हैं, कानूनी अनुपालन सुनिश्चित कर सकते हैं, वेबसाइटों द्वारा ब्लॉक होने से बच सकते हैं और बड़े पैमाने पर डेटा संग्रह के लिए क्रॉलिंग संचालन को अनुकूलित कर सकते हैं। Scrapeless के साथ, कंपनियां जल्दी, कुशलतापूर्वक और नैतिक रूप से अपनी आवश्यक डेटा तक पहुँच प्राप्त कर सकती हैं, जिससे उन्हें एक प्रतिस्पर्धी, डेटा-संचालित स्थान में आगे रहने में मदद मिलती है।
सामान्य वेब स्क्रैपिंग समस्याओं का निवारण
- वेबसाइट संरचना परिवर्तन
- समस्या: वेबसाइटें अक्सर अपने लेआउट या HTML संरचना को अपडेट करती हैं, जिससे विशिष्ट टैग पर निर्भर करने वाले स्क्रैपर्स टूट जाते हैं।
- समाधान: गतिशील तकनीकों का उपयोग करके लचीले स्क्रैपर्स बनाएँ या त्रुटि हैंडलिंग लागू करें जो मामूली परिवर्तनों के अनुकूल हो सकें। Scrapeless एक स्मार्ट, AI-संचालित स्क्रैपर प्रदान करता है जो परिवर्तनों का पता लगाता है और तदनुसार समायोजित करता है।
- IP ब्लॉकिंग
- समस्या: वेबसाइटें एक ही IP पते से अनुरोधों की संख्या को सीमित करती हैं, बहुत अधिक प्रयासों के बाद स्क्रैपर्स को ब्लॉक करती हैं।
- समाधान: अनुरोधों को कई IP में वितरित करने के लिए IP रोटेशन के साथ Scrapeless प्रॉक्सी का उपयोग करें, जिससे वेबसाइटों के लिए स्क्रैपिंग पैटर्न का पता लगाना और पहुँच को ब्लॉक करना कठिन हो जाता है।
- CAPTCHAs और एंटी-स्क्रैपिंग तंत्र
- समस्या: CAPTCHAs और अन्य एंटी-बॉट उपाय (जैसे जावास्क्रिप्ट चुनौतियाँ) आपके स्क्रैपर को रोक सकते हैं।
- समाधान: CAPTCHA को हल करने के लिए स्वचालित करने के लिए Scrapeless कैप्चा सॉल्वर का लाभ उठाएँ। जावास्क्रिप्ट-भ
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


