
Playwright का उपयोग करके CAPTCHA को कैसे बायपास करें
Advanced Bot Mitigation Engineer
क्या किसी भी CAPTCHA ने आपको वेब स्क्रैपिंग से रोक दिया है? डेटा के एकत्रीकरण को स्वचालित करते समय इन कठिनाइयों से सिरदर्द हो सकता है। सौभाग्य से, Playwright का उपयोग करके CAPTCHA को बायपास करने के 2 तरीके हैं, जिनके बारे में हम इस पोस्ट में बताएंगे।
क्या Playwright CAPTCHA को हल करने में सक्षम है?
CAPTCHA को बॉट्स के लिए मुश्किल लेकिन लोगों के लिए आसान बनाया गया है, लेकिन हम यह भी देखेंगे कि आप CAPTCHA को खत्म करने के लिए Playwright का उपयोग अन्य उपयोगी उपकरणों के साथ कैसे कर सकते हैं।
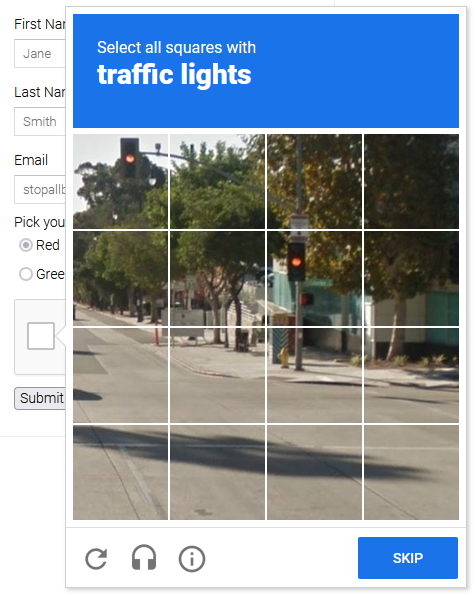
एक महत्वपूर्ण सबक यह है कि आप या तो: A) परीक्षा पूरी होने पर जल्द से जल्द इसे पूरा कर सकते हैं; या B) इसे पूरी तरह से टालें और यदि यह दिखाई देता है तो फिर से प्रयास करें।
पहले परिदृश्य में, Playwright CAPTCHA सॉल्वर का उपयोग करना आवश्यक होगा, और बड़ी मात्रा में यह महंगा हो सकता है। दूसरे मामले में पता लगाने से बचने के लिए, आपके स्क्रैपर को मानव व्यवहार की बेहतर नकल करनी होगी। दोनों रणनीतियों को दिखाया जाएगा, लेकिन शुरुआती बिंदु के रूप में, दूसरा सबसे बड़ा है।
आइए अब देखें कि आप इनका अभ्यास कैसे कर सकते हैं!
विधि 1: CAPTCHA को बायपास करने के लिए बेस Playwright और Captcha सॉल्वर का उपयोग करें।
पहली विधि जिसकी हम चर्चा करेंगे, वह Playwright का उपयोग Scrapeless के साथ है, जो एक ऐसी सेवा है जो आपकी ओर से मनुष्यों को नियोजित करके CAPTCHA को हल करती है।
क्या आप CAPTCHA और निरंतर वेब स्क्रैपिंग ब्लॉक से थके हुए हैं?
Scrapeless: उपलब्ध सर्वोत्तम ऑल-इन-वन ऑनलाइन स्क्रैपिंग समाधान!
अपने डेटा निष्कर्षण की पूरी क्षमता को उजागर करने के लिए हमारे शक्तिशाली टूलकिट का उपयोग करें:
सर्वश्रेष्ठ CAPTCHA सॉल्वर
जटिल CAPTCHA का स्वचालित समाधान चल रहे और सुचारू स्क्रैपिंग सुनिश्चित करने के लिए।
इसे मुफ्त में आज़माएं!
विधि 2: Playwright में स्टील्थ प्लगइन का उपयोग करें
यदि आपको किसी वेबसाइट से डेटा स्क्रैप करने की आवश्यकता है जो अधिक कठिन CAPTCHA बाधाओं का उपयोग करती है, तो पिछला Playwright सेटअप काम नहीं करेगा, लेकिन Stealth प्लगइन एक उपयोगी समाधान है। यह ओपन-सोर्स प्रोजेक्ट Playwright में ऐसे तत्व जोड़ता है जो इसे वास्तविक वेब ट्रैफ़िक की तरह बनाते हैं:
- आपका User-Agent छिपा हुआ है।
- IP पते की पहचान से बचने के लिए, WebRTC अक्षम है। यह ट्रैकिंग स्क्रिप्ट को विशेष रूप से प्रतिबंधित नहीं करने पर भी ब्राउज़िंग इतिहास को छिपाकर गोपनीयता बनाए रखता है।
- आपके अनुरोधों को अधिक प्राकृतिक बनाने के लिए, यह आपके हेडलेस ब्राउज़र को अतिरिक्त घटकों के साथ बढ़ाता है।
- हमारे उदाहरण में अतिरिक्त शक्ति जोड़ने के लिए, आइए Astra को आज़माएं, एक ऐसी वेबसाइट जिसमें न्यूनतम Cloudflare सुरक्षा है।
शुरू करने से पहले अपने प्रोजेक्ट फ़ोल्डर के भीतर निम्न कमांड निष्पादित करके आवश्यक निर्भरताएँ स्थापित करें:
language
npm install playwright playwright-extraयह ध्यान दिया जाना चाहिए कि playwright-extra फ़्रेमवर्क में Stealth प्लगइन है।
Playwright को बढ़ाने के लिए, playwright-extra का उपयोग करके एक हेडलेस क्रोम ब्राउज़र लॉन्च करें और chromium.use(pluginStealth) का उपयोग करके puppeteer-extra-plugin-stealth को सक्षम करें। प्रौद्योगिकियों का यह समूह वेबसाइटों को आपके वेब स्क्रैपर की पहचान करने में कठिनाई बनाने के लिए और सुरक्षा प्रदान करता है।
language
const { chromium } = require('playwright-extra')
// Load the stealth plugin and use defaults (all tricks to hide playwright usage)
const pluginStealth = require("puppeteer-extra-plugin-stealth");
// Use stealth
chromium.use(pluginStealth)
// That's it, the rest is playwright usage as normal 😊
chromium.launch({ headless: true }).then(async browser => {
// Create a new page
const page = await browser.newPage()
// Go to the website
await page.goto('https://www.scrapeless.com/')
// Wait for page to download
await page.waitForTimeout(1000);
// Take screenshot
await page.screenshot({ path: 'screen.png'})
// Close the browser
console.log('All done, check the screenshot. ✨')
await browser.close()
})हमारी वेबसाइट स्क्रैपिंग के लिए तैयार है जब एक नया पेज browser.newPage() का उपयोग करके लोड किया गया है और page.goto() मेथड को कॉल किया गया है।
निष्कर्ष
प्लेराइट का उपयोग करके CAPTCHA को दरकिनार करना मुश्किल हो सकता है क्योंकि यह प्रसिद्ध बाधा वेबसाइटों तक स्वचालित पहुंच को रोकने के लिए है। फिर भी, यदि आपके पास उचित उपकरण और लाइब्रेरी हैं, तो आप वांछित डेटा को स्क्रैप करने में सक्षम होंगे।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


