
स्क्रैपलेस एसडीके का आधिकारिक लॉन्च: वेब स्क्रैपिंग और ब्राउज़िंग के लिए आपका ऑल-इन-वन समाधान
Expert Network Defense Engineer
हम यह घोषणा करते हुए रोमाँचित हैं कि आधिकारिक Scrapeless SDK अब उपलब्ध है! 🎉
यह आपके और शक्तिशाली Scrapeless प्लेटफ़ॉर्म के बीच का सर्वश्रेष्ठ पुल है - जो वेब डेटा निष्कर्षण और ब्राउज़र स्वचालन को पहले से कहीं अधिक सरल बनाता है।
कुछ ही लाइनों के कोड के साथ, आप बड़े पैमाने पर वेब स्क्रैपिंग और SERP डेटा निष्कर्षण कर सकते हैं, जो Agentic AI सिस्टम के लिए स्थिर समर्थन प्रदान करता है।
Scrapeless SDK डेवलपर्स को सभी मूल सेवाओं के लिए एक आधिकारिक लपेटन प्रदान करता है, जिसमें शामिल हैं:
- स्क्रैपिंग ब्राउज़र: Puppeteer और Playwright-आधारित स्वचालन परत, वास्तविक क्लिक, फ़ॉर्म भरने और अन्य उन्नत सुविधाओं का समर्थन करता है।
- ब्राउज़र API: ब्राउज़र सत्र बनाएं और प्रबंधित करें, उन्नत स्वचालन आवश्यकताओं के लिए आदर्श।
- स्क्रैपिंग API: वेबपृष्ठ लाएं और कई प्रारूपों में सामग्री निकालें।
- डीप SERP API: Google और अन्य से खोज इंजन परिणाम आसानी से स्क्रैप करें।
- यूनिवर्सल स्क्रैपिंग API: JS रेंडरिंग, स्क्रीनशॉट और मेटाडेटा निष्कर्षण के साथ सामान्य प्रयोजन वेब स्क्रैपिंग।
- प्रॉक्सी API: IP पते और भू-स्थान सहित प्रॉक्सियों को तुरंत कॉन्फ़िगर करें।
चाहे आप एक डेटा इंजीनियर हों, क्रॉलर डेवलपर हों, या डेटा-संचालित उत्पादों का निर्माण करने वाले स्टार्टअप का हिस्सा हों, Scrapeless SDK आपकी आवश्यक डेटा को तेजी से और अधिक विश्वसनीयता से प्राप्त करने में मदद करता है।
ब्राउज़र स्वचालन से लेकर खोज इंजन परिणामों के पार्सिंग, वेब डेटा निष्कर्षण से लेकर स्वचालित प्रॉक्सी प्रबंधन तक, Scrapeless SDK आपके पूरे डेटा अधिग्रहण वर्कफ़्लो को सहज बनाता है।
Scrapeless SDK उपयोग संदर्भ
पूर्वापेक्षा
लॉग इन करें Scrapeless डैशबोर्ड में और API कुंजी प्राप्त करें
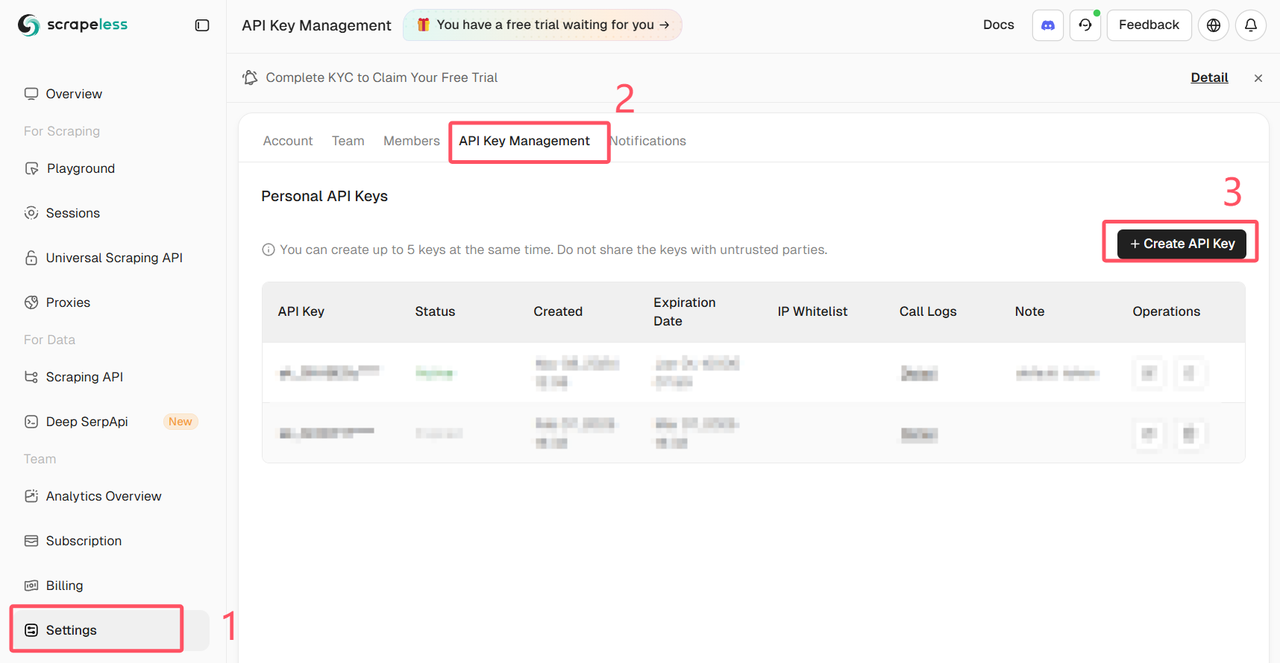
इंस्टॉलेशन
- npm:
Bash
npm install @scrapeless-ai/sdk- यार्न:
Bash
yarn add @scrapeless-ai/sdk- pnpm:
Bash
pnpm add @scrapeless-ai/sdkबुनियादी सेटअप
JavaScript
import { Scrapeless } from '@scrapeless-ai/sdk';
// क्लाइंट प्रारंभ करें
const client = new Scrapeless({
apiKey: 'your-api-key' // अपनी API कुंजी प्राप्त करें https://scrapeless.com से
});पर्यावरण चर
आप पर्यावरण चर का उपयोग करके SDK को भी कॉन्फ़िगर कर सकते हैं:
Bash
# आवश्यक
SCRAPELESS_API_KEY=your-api-key
# वैकल्पिक - कस्टम API एंडपॉइंट
SCRAPELESS_BASE_API_URL=https://api.scrapeless.com
SCRAPELESS_ACTOR_API_URL=https://actor.scrapeless.com
SCRAPELESS_STORAGE_API_URL=https://storage.scrapeless.com
SCRAPELESS_BROWSER_API_URL=https://browser.scrapeless.com
SCRAPELESS_CRAWL_API_URL=https://crawl.scrapeless.comस्क्रैपिंग ब्राउज़र (ब्राउज़र स्वचालन लपेटन)
स्क्रैपिंग ब्राउज़र मॉड्यूल ब्राउज़र स्वचालन के लिए एक उच्च-स्तरीय, संविलियन API प्रदान करता है, जो Scrapeless ब्राउज़र API के शीर्ष पर बना है। यह Puppeteer और Playwright दोनों का समर्थन करता है, और मानक पृष्ठ ऑब्जेक्ट को उन्नत विधियों जैसे realClick, realFill, और liveURL के साथ विस्तृत करता है ताकि अधिक मानव-समान स्वचालन हो सके।
Puppeteer उदाहरण:
Python
import { PuppeteerBrowser } from '@scrapeless-ai/sdk';
const browser = await PuppeteerBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('वर्तमान पृष्ठ URL:', urlInfo.liveURL);
await browser.close();Playwright उदाहरण:
Python
import { PlaywrightBrowser } from '@scrapeless-ai/sdk';
const browser = await PlaywrightBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('वर्तमान पृष्ठ URL:', urlInfo.liveURL);
await browser.close();👉 हमारे दस्तावेज़ पर जाएँ और अधिक उपयोग के मामलों के लिए
👉 GitHub के माध्यम से एक-क्लिक एकीकरण
व्यावहारिक उदाहरण: Nike.com पर “Air Max” खोज परिणाम स्क्रैपिंग
मान लीजिए कि आप एक जूते तुलना प्लेटफ़ॉर्म के लिए एक बैकएंड सिस्टम बना रहे हैं और Nike की आधिकारिक साइट से “Air Max” के लिए खोज परिणाम वास्तविक समय में लाना चाहते हैं। पारंपरिक रूप से, आपको Puppeteer को तैनात करने, प्रॉक्सियों का प्रबंधन करने, ब्लॉकों से बचने, पृष्ठ संरचनाओं को पार्स करने... समय-खपत और गलती-प्रवण प्रक्रियाओं का सामना करना पड़ता है।
अब, Scrapeless SDK के साथ, पूरी प्रक्रिया कुछ ही लाइनों के कोड में पूरी हो जाती है:
चरण 1. SDK स्थापित करें
अपने पसंदीदा पैकेज प्रबंधक का उपयोग करें:
Python
npm install @scrapeless-ai/sdkचरण 2. क्लाइंट प्रारंभ करें
TypeScript
import { Scrapeless } from '@scrapeless-ai/sdk';
const client = new Scrapeless({
apiKey: 'your-api-key' // https://scrapeless.com पर प्राप्त करें
});चरण 3. एक-क्लिक SERP स्क्रैपिंग
TypeScript
const results = await client.deepserp.scrape({
actor: 'scraper.google.search',
input: {
q: 'Air Max site:www.nike.com'
}
});
console.log(results);आपको प्रॉक्सी, एंटी-बॉट तंत्र, ब्राउज़र अनुकरण या आईपी रोटेशन के बारे में चिंता करने की आवश्यकता नहीं है — Scrapeless इन सब चीजों को अपने अंदर ही संभालता है।
उदाहरण आउटपुट
JSON
{
inline_images: [
{
position: 1,
thumbnail: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtHPNOwXmvXfYfaT_4UqM1IvNBqZDZe7rScA&s',
related_content_id: 'N2x0F2OpsGqRuM,xzJA7z__Ip2bvM',
related_content_link: 'https://www.google.com/search/about-this-image?img=H4sIAAAAAAAA_wEXAOj_ChUIx-WA-v7nv5GdARC32NG7sayq2GoyjCpjFwAAAA%3D%3D&q=https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2&ctx=iv&hl=en-US',
source: 'Nike',
source_logo: '',
title: "Nike Air Max 1 पुरुषों के जूते",
link: 'https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2',
original: 'https://static.nike.com/a/images/t_PDP_936_v1/f_auto,q_auto:eco/c5ff2a6b-579f-4271-85ea-0cd5131691fa/NIKE+AIR+MAX+1.png',
original_width: 936,
original_height: 1170,
in_stock: false,
is_product: false
},
....
}अब आप इन परिणामों को अपने डेटाबेस में स्टोर कर सकते हैं या इन्हें सीधे प्रदर्शित करने और रैंकिंग विश्लेषण के लिए उपयोग कर सकते हैं।
अभी Scrapeless SDK स्थापित करें
Scrapeless Node.js SDK वेब स्क्रैपिंग और ब्राउज़र स्वचालन को पहले से कहीं अधिक आसान बनाता है। चाहे आप एक मूल्य निगरानी उपकरण, एक SERP विश्लेषण प्रणाली बना रहे हों, या वास्तविक उपयोगकर्ता व्यवहार का अनुकरण कर रहे हों — एक ही कोड की पंक्ति आपको Scrapeless की शक्तिशाली अवसंरचना से जोड़ देती है।
Scrapeless SDK MIT लाइसेंस के तहत ओपन-सोर्स है। डेवलपर्स कोड योगदान करने, समस्याएं सबमिट करने या अधिक विचारों के लिए हमारे डिस्कॉर्ड समुदाय में शामिल होने के लिए स्वागत हैं!
✅ मुफ्त परीक्षण उपलब्ध है
🔗 डॉक्यूमेंट्स पढ़ें
💬 सवाल हैं? हमारे Discord Community में शामिल हों
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


