
वेब स्क्रैपिंग के लिए सर्वोत्तम प्रथाएँ क्या हैं?
Senior Web Scraping Engineer
परिचय: एआई युग में ब्राउज़र स्वचालन और डेटा संग्रह का एक नया पैरेडाइम
जनरेटिव एआई, एआई एजेंटों, और डेटा-गहन अनुप्रयोगों के तेजी से उभरने के साथ, ब्राउज़र पारंपरिक "उपयोगकर्ता इंटरैक्शन उपकरणों" से "डेटा निष्पादन इंजनों" के रूप में विकसित हो रहे हैं। इस नए पैरेडाइम में, कई कार्य अब एकल एपीआई एंडपॉइंट्स पर निर्भर नहीं करते हैं, बल्कि जटिल पृष्ठ इंटरैक्शनों, सामग्री स्क्रैपिंग, कार्य प्रबंधन, और संदर्भ पुनर्प्राप्ति को संभालने के लिए स्वचालित ब्राउज़र नियंत्रण का लाभ उठाते हैं।
ई-कॉमर्स साइटों पर मूल्य तुलना और मानचित्र स्क्रीनशॉट से लेकर खोज इंजन परिणाम का विश्लेषण और सोशल मीडिया सामग्री निष्कर्षण तक, ब्राउज़र वास्तविक-संसार के डेटा तक एआई की पहुंच के लिए एक महत्वपूर्ण इंटरफ़ेस बनता जा रहा है। हालांकि, आधुनिक वेब संरचनाओं की जटिलता, मजबूत एंटी-बॉट उपाय, और उच्च समवर्ती मांगें पारंपरिक समाधानों जैसे स्थानीय Puppeteer/Playwright उदाहरण या प्रॉक्सी रोटेशन रणनीतियों के लिए महत्वपूर्ण तकनीकी और परिचालन चुनौतियाँ पेश करती हैं।
स्क्रेपलेस स्क्रैपिंग ब्राउज़र में प्रवेश करें—एक उन्नत, क्लाउड-आधारित ब्राउज़र प्लेटफॉर्म जो बड़े पैमाने पर स्वचालन के लिए विशेष रूप से निर्मित है। यह एंटी-स्क्रैपिंग तंत्र, फिंगरप्रिंट पहचान, और प्रॉक्सी रखरखाव जैसी प्रमुख तकनीकी बाधाओं को पार करता है। इसके अलावा, यह क्लाउड-नेटीव समवर्ती शेड्यूलिंग, मानव-समान व्यवहार अनुकरण, और संरचित डेटा निष्कर्षण की पेशकश करता है, जिससे यह स्वचालन प्रणालियों और डेटा पाइपलाइनों की अगली पीढ़ी में एक महत्वपूर्ण अवसंरचना घटक के रूप में स्थापित होता है।
यह लेख स्क्रेपलेस की प्रमुख क्षमताओं और ब्राउज़र स्वचालन और वेब स्क्रैपिंग में इसके व्यावहारिक अनुप्रयोगों की खोज करता है। वर्तमान उद्योग प्रवृत्तियों और भविष्य की दिशाओं का विश्लेषण करके, हम डेवलपर्स, उत्पाद निर्माताओं, और डेटा टीमों को एक व्यापक और प्रणालीबद्ध मार्गदर्शिका प्रदान करने का लक्ष्य रखते हैं।
I. पृष्ठभूमि: हमें स्क्रेपलेस स्क्रैपिंग ब्राउज़र की आवश्यकता क्यों है?
1.1 ब्राउज़र स्वचालन का विकास
एआई-चलित स्वचालन युग में, ब्राउज़र केवल मानव इंटरैक्शन के उपकरण नहीं रह गए हैं—वे संरचित और असंरचित डेटा को अधिग्रहित करने के लिए अनिवार्य निष्पादनEndpoints बन गए हैं। कई वास्तविक-जीवन परिदृश्यों में, एपीआई या तो अनुपलब्ध हैं या सीमित हैं, जिससे डेटा संग्रह, कार्य निष्पादन, और जानकारी निष्कर्षण के लिए ब्राउज़रों के माध्यम से मानव व्यवहार का अनुकरण करना आवश्यक हो जाता है।
सामान्य उपयोग के मामले में शामिल हैं:
- ई-कॉमर्स साइटों पर मूल्य तुलना: मूल्य और स्टॉक डेटा अक्सर ब्राउज़र में असंगठित रूप से लोड होते हैं।
- खोज इंजन परिणाम पृष्ठों का आकृति-विश्लेषण: सामग्री को पूर्ण रूप से लोड करने के लिए स्क्रॉलिंग और पृष्ठ तत्वों पर क्लिक करना आवश्यक है।
- बहुभाषी वेबसाइटें, पुरानी प्रणालियाँ, और इंट्रानेट प्लेटफार्म: एपीआई के माध्यम से डेटा की पहुंच असंभव है।
पारंपरिक स्क्रैपिंग समाधान (जैसे, स्थानीय रूप से चलने वाले Puppeteer/Playwright या प्रॉक्सी रोटेशन सेटअप) अक्सर उच्च समवर्ती के तहत खराब स्थिरता, बार-बार एंटी-बॉट ब्लॉकिंग, और उच्च रखरखाव लागतों से ग्रस्त होते हैं। स्क्रेपलेस स्क्रैपिंग ब्राउज़र, अपने क्लाउड-नेटीव डिप्लॉयमेंट और वास्तविक ब्राउज़र व्यवहार अनुकरण के साथ, डेवलपर्स को उच्च-उपलब्धता, विश्वसनीय ब्राउज़र स्वचालन प्लेटफॉर्म प्रदान करता है—जो एआई स्वचालन प्रणालियों और डेटा कार्यप्रवाहों के लिए महत्वपूर्ण अवसंरचना के रूप में कार्य करता है।
1.2 एंटी-बॉट तंत्र की चुनौती
एक ही समय में, जैसे-जैसे एंटी-बॉट तकनीक विकसित होती है, पारंपरिक क्रॉलर उपकरणों को लक्षित वेबसाइटों द्वारा बॉट ट्रैफिक के रूप में increasingly फ्लैग किया जाता है, जिसके परिणामस्वरूप आईपी प्रतिबंध और पहुँच सीमाएँ होती हैं। सामान्य एंटी-स्क्रैपिंग तंत्र में शामिल हैं:
- ब्राउज़र फिंगरप्रिंटिंग: यूजर-एजेंट, कैनवास रेंडरिंग, टीएलएस हैंडशेक, आदि के माध्यम से असामान्य पहुँच पैटर्न का पता लगाना।
- कैप्चा सत्यापन: उपयोगकर्ताओं से यह साबित करने की आवश्यकता है कि वे मानव हैं।
- आईपी ब्लैकलिस्टिंग: उस आईपी को ब्लॉक करता है जो बहुत बार एक्सेस करता है।
- व्यवहारात्मक विश्लेषण एल्गोरिदम: असामान्य माउस मूवमेंट, स्क्रॉल गति, और इंटरैक्शन लॉजिक का पता लगाते हैं।
स्क्रेपलेस स्क्रैपिंग ब्राउज़र इन चुनौतियों का प्रभावी ढंग से सामना करता है, सटीक ब्राउज़र फिंगरप्रिंट अनुकूलन, निर्मित कैप्चा समाधान, और लचीले प्रॉक्सी समर्थन के माध्यम से—जो अगली पीढ़ी के स्वचालन उपकरणों के लिए केंद्रीय अवसंरचना बन जाता है।
II. स्क्रेपलेस की मुख्य क्षमताएँ
स्क्रेपलेस स्क्रैपिंग ब्राउज़र शक्तिशाली मुख्य क्षमताएँ प्रदान करता है, उपयोगकर्ताओं को स्थिर, कुशल, और स्केलेबल डेटा इंटरैक्शन सुविधाएँ प्रदान करता है। नीचे इसके मुख्य कार्यात्मक मॉड्यूल और तकनीकी विवरण दिए गए हैं:
2.1 वास्तविक ब्राउज़र वातावरण
स्क्रेपलेस क्रोमियम इंजन पर आधारित है, जो वास्तविक उपयोगकर्ता व्यवहार का अनुकरण करने में सक्षम एक पूर्ण ब्राउज़र वातावरण प्रदान करता है। इसकी प्रमुख विशेषताएँ शामिल हैं:
- टीएलएस फिंगरप्रिंट धोखा: पारंपरिक एंटी-बॉट तंत्र को दरकिनार करने के लिए टीएलएस हैंडशेक पैरामीटर को दिखावटी बनाना।
- डायनामिक फिंगरप्रिंट अस्पष्टता: प्रत्येक सत्र को अत्यधिक मानव-समान बनाने के लिए यूजर-एजेंट, स्क्रीन रिज़ॉल्यूशन, टाइमज़ोन आदि को समायोजित करता है।
- स्थानीयकरण समर्थन: लक्षित वेबसाइटों के साथ इंटरैक्शन को अधिक स्वाभाविक बनाने के लिए भाषा, क्षेत्र, और टाइमज़ोन सेटिंग्स को अनुकूलित करें।
ब्राउज़र फिंगरप्रिंट की गहरी अनुकूलनशीलता
स्क्रेपलेस उपयोगकर्ताओं को और "प्रामाणिक" ब्राउज़िंग वातावरण बनाने की अनुमति देने के लिए ब्राउज़र फिंगरप्रिंट का व्यापक अनुकूलन प्रदान करता है:
- यूज़र-एजेंट नियंत्रण: ब्राउज़र HTTP अनुरोधों में यूज़र-एजेंट स्ट्रिंग को परिभाषित करें, जिसमें ब्राउज़र इंजन, संस्करण और OS शामिल हैं।
- स्क्रीन रिज़ॉल्यूशन मैपिंग: सामान्य डिस्प्ले आकारों का अनुकरण करने के लिए
screen.widthऔरscreen.heightके लौटने वाले मान सेट करें। - प्लेटफ़ॉर्म प्रॉपर्टी लॉकिंग: JavaScript में
navigator.platformका लौटने वाला मान निर्दिष्ट करें ताकि ऑपरेटिंग सिस्टम के प्रकार का अनुकरण किया जा सके। - स्थानीयकरण वातावरण अनुकरण: पूरी तरह से कस्टम स्थानीयकरण सेटिंग्स को समर्थन करता है, जो वेबसाइटों पर सामग्री रेंडरिंग, समय प्रारूप, और भाषा प्राथमिकता पहचान को प्रभावित करता है।
2.2 क्लाउड-आधारित तैनाती और स्केलेबिलिटी
Scrapeless पूरी तरह से क्लाउड में तैनात है और निम्नलिखित लाभ प्रदान करता है:
- कोई स्थानीय संसाधन की आवश्यकता नहीं: हार्डवेयर लागत को कम करता है और तैनाती की लचीलापन को सुधारता है।
- वैश्विक वितरित नोड्स: बड़े पैमाने पर समवर्ती कार्यों का समर्थन करता है और भौगोलिक सीमाओं को पार करता है।
- उच्च समवर्ती समर्थन: 50 से असीमित समवर्ती सत्र— छोटे कार्यों से लेकर जटिल स्वचालन कार्यप्रवाह तक के लिए आदर्श।
प्रदर्शन तुलना
पारंपरिक उपकरणों जैसे कि Selenium और Playwright की तुलना में, Scrapeless उच्च-समवर्ती परिदृश्यों में उत्कृष्ट प्रदर्शन करता है। नीचे एक सरल तुलना तालिका दी गई है:
| विशेषता | Scrapeless | Selenium | Playwright |
|---|---|---|---|
| समवर्ती समर्थन | असीमित (उद्यम-ग्रेड अनुकूलन) | सीमित | मध्यम |
| फिंगरप्रिंट अनुकूलन | उन्नत | बुनियादी | मध्यम |
| CAPTCHA हल करना | अंतर्निहित (98% सफलता दर) reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome आदि का समर्थन करता है |
बाहरी निर्भरता | बाहरी निर्भरता |
एक ही समय में, Scrapeless उच्च-समवर्ती परिदृश्यों में अन्य प्रतिस्पर्धी उत्पादों की तुलना में बेहतर प्रदर्शन करता है। इसके क्षमताओं का विभिन्न आयामों से संक्षेप नीचे दिया गया है:
| विशेषता / प्लेटफार्म | Scrapeless | Browserless | Browserbase | HyperBrowser | Bright Data | ZenRows | Steel.dev |
|---|---|---|---|---|---|---|---|
| तैनाती विधि | क्लाउड-आधारित | क्लाउड-आधारित Puppeteer कंटेनर | मल्टी-ब्राउज़र क्लाउड क्लस्टर | क्लाउड-आधारित हेडलेस ब्राउज़र प्लेटफार्म | क्लाउड तैनाती | ब्राउज़र API इंटरफेस | ब्राउज़र क्लाउड क्लस्टर + ब्राउज़र API |
| समवर्ती समर्थन | 50 से असीमित | 3–50 | 3–50 | 1–250 | निर्भर करता है योजना पर असीमित | 100 तक (बिजनेस योजना) | कोई आधिकारिक डेटा |
| एंटी-डिटेक्शन क्षमता | फ्री CAPTCHA मान्यता और बायपास, reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome आदि का समर्थन करता है | CAPTCHA बायपास | CAPTCHA बायपास + इंकॉग्निटो मोड | CAPTCHA बायपास + इंकॉग्निटो + सत्र प्रबंधन | CAPTCHA बायपास + फिंगरप्रिंट धोखाधड़ी + प्रॉक्सी | कस्टम ब्राउज़र फिंगरप्रिंट | प्रॉक्सी + फिंगरप्रिंट मान्यता |
| ब्राउज़र रनटाइम लागत | $0.063 – $0.090/घंटा (फ्री CAPTCHA बायपास शामिल है) | $0.084 – $0.15/घंटा (यूनिट-आधारित) | $0.10 – $0.198/घंटा (2–5GB फ्री प्रॉक्सी शामिल है) | $30–$100/महीना | ~$0.10/घंटा | ~$0.09/घंटा | $0.05 – $0.08/घंटा |
| प्रॉक्सी लागत | $1.26 – $1.80/GB | $4.3/GB | $10/GB (फ्री कोटा के परे) | कोई आधिकारिक डेटा | $9.5/GB (मानक); $12.5/GB (प्रीमियम डोमेन) | $2.8 – $5.42/GB | $3 – $8.25/GB |
2.3 CAPTCHA स्वचालित समाधान और घटना निगरानी तंत्र
Scrapeless उन्नत CAPTCHA समाधान प्रदान करता है और Chrome DevTools प्रोटोकॉल (CDP) के माध्यम से विश्वसनीयता बढ़ाने के लिए एक श्रृंखला की कस्टम फ़ंक्शन को विस्तारित करता है।
CAPTCHA हल करने की क्षमता
Scrapeless स्वचालित रूप से मुख्यधारा CAPTCHA प्रकारों को संभाल सकता है, जिसमें शामिल हैं: reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome, आदि।
घटना निगरानी तंत्र
Scrapeless CAPTCHA समाधान प्रक्रिया की निगरानी के लिए तीन मुख्य घटनाएँ प्रदान करता है:
| घटना नाम | विवरण |
|---|---|
| Captcha.detected | CAPTCHA का पता चला |
| Captcha.solveFinished | CAPTCHA हल हुआ |
| Captcha.solveFailed | CAPTCHA हल करने में असफल |
घटना प्रतिक्रिया डेटा संरचना
| क्षेत्र | प्रकार | विवरण |
|---|---|---|
| type | string | CAPTCHA प्रकार (जैसे, reCAPTCHA, Turnstile) |
| success | boolean | हल करने का परिणाम |
| message | string | स्थिति संदेश (जैसे, "NOT_DETECTED", "SOLVE_FINISHED") |
| token? | string | सफलता पर लौटाया गया टोकन (वैकल्पिक) |
2.4 शक्तिशाली प्रॉक्सी समर्थन
Scrapeless बहुउपयोगी और नियंत्रणीय प्रॉक्सी एकीकरण प्रणाली प्रदान करता है जो कई प्रॉक्सी मोड का समर्थन करता है:
- अंतर्निर्मित आवासीय प्रॉक्सी: दुनिया भर के 195 देशों/क्षेत्रों में भौगोलिक प्रॉक्सी का समर्थन, तुरंत उपलब्ध।
- कस्टम प्रॉक्सी (प्रीमियम सदस्यता): उपयोगकर्ताओं को अपनी स्वयं की प्रॉक्सी सेवा से कनेक्ट करने की अनुमति देता है, जो Scrapeless के प्रॉक्सी बिलिंग में शामिल नहीं है।
2.5 सत्र पुनरावृत्ति
सत्र पुनरावृत्ति Scrapeless स्क्रैपिंग ब्राउज़र की सबसे शक्तिशाली सुविधाओं में से एक है। यह आपको पृष्ठ-दर-पृष्ठ सत्र को पुनः चलाने की अनुमति देता है ताकि किए गए संचालन और नेटवर्क अनुरोधों की जांच की जा सके।
3. कोड उदाहरण: Scrapeless एकीकरण और उपयोग
3.1 Scrapeless स्क्रैपिंग ब्राउज़र का उपयोग
Puppeteer उदाहरण
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=your-scrapeless-api-key&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright उदाहरण
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=your-scrapeless-api-key&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();3.2 Scrapeless स्क्रैपिंग ब्राउज़र फिंगरप्रिंट पैरामीटर उदाहरण कोड
नीचे एक सरल उदाहरण कोड है जो दिखाता है कि Puppeteer और Playwright के माध्यम से Scrapeless के ब्राउज़र फिंगरप्रिंट कस्टमाइजेशन फ़ंक्शन को कैसे एकीकृत किया जाता है:
Puppeteer उदाहरण
const puppeteer = require('puppeteer-core');
// कस्टम ब्राउज़र फिंगरप्रिंट
const fingerprint = {
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',
platform: 'Windows',
screen: {
width: 1280, height: 1024
},
localization: {
languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',
}
}
const query = new URLSearchParams({
token: 'APIKey', // आवश्यक
session_ttl: 180,
proxy_country: 'ANY',
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
const info = await page.evaluate(() => {
return {
screen: {
width: screen.width,
height: screen.height,
},
userAgent: navigator.userAgent,
timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,
languages: navigator.languages
};
});
console.log(info);
await browser.close();
})();
Playwright उदाहरण
const { chromium } = require('playwright-core');
// कस्टम ब्राउज़र फिंगरप्रिंट
const fingerprint = {
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',
platform: 'Windows',
screen: {
width: 1280, height: 1024
},
localization: {
languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',
}
}
const query = new URLSearchParams({
token: 'APIKey', // आवश्यक
session_ttl: 180,
proxy_country: 'ANY',
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
const info = await page.evaluate(() => {
return {
screen: {
width: screen.width,
height: screen.height,
},
userAgent: navigator.userAgent,
timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,
languages: navigator.languages
};
});
console.log(info);
await browser.close();
})();3.3 CAPTCHA घटना निगरानी उदाहरण
निम्नलिखित एक पूरा कोड उदाहरण है Scrapeless का उपयोग करके CAPTCHA घटनाओं की निगरानी करने के लिए, यह दिखाते हुए कि वास्तविक समय में CAPTCHA के समाधान की स्थिति की निगरानी कैसे की जाए:
// CAPTCHA हल करने की घटनाओं के लिए सुनें
const client = await page.createCDPSession();
client.on('Captcha.detected', (result) => {
console.log('Captcha का पता चला:', result);
});
await new Promise((resolve, reject) => {
client.on('Captcha.solveFinished', (result) => {
if (result.success) resolve();
});
client.on('Captcha.solveFailed', () =>
reject(new Error('Captcha हल करने में विफल'))
);
setTimeout(() =>
reject(new Error('Captcha हल करने की समय सीमा समाप्त')),
5 * 60 * 1000
);
});Scrapeless स्क्रैपिंग ब्राउज़र की मूल सुविधाओं और लाभों को समझने के बाद, हम न केवल आधुनिक वेब स्क्रैपिंग में इसके मूल्य को बेहतर ढंग से समझ सकते हैं बल्कि प्रदर्शन लाभों का अधिक प्रभावी ढंग से लाभ उठा सकते हैं। डेवलपर्स को वेबसाइटों को अधिक कुशलता और सुरक्षित रूप से स्वचालित और स्क्रैप करने में मदद करने के लिए, हम अब सामान्य परिदृश्यों के आधार पर Scrapeless स्क्रैपिंग ब्राउज़र को विशेष उपयोग के मामलों में लागू करने का तरीका खोजेंगे।
4. स्वचालन और वेब स्क्रैपिंग के लिए सबसे अच्छी प्रथाएँ Scrapeless स्क्रैपिंग ब्राउज़र का उपयोग करना
कानूनी अस्वीकरण और सावधानियाँ
यह ट्यूटोरियल शैक्षणिक उद्देश्यों के लिए लोकप्रिय वेब स्क्रैपिंग तकनीकों को कवर करता है। सार्वजनिक सर्वरों के साथ संपर्क करने में सतर्कता और सम्मान की आवश्यकता होती है और यहाँ क्या नहीं करना है इसका एक अच्छा सारांश है:
- ऐसी दरों पर स्क्रैप न करें, जो वेबसाइट को नुकसान पहुँचा सकें।
- उन डेटा को स्क्रैप न करें जो सार्वजनिक रूप से उपलब्ध नहीं हैं।
- GDPR के तहत संरक्षित EU नागरिकों की व्यक्तिगत जानकारी (PII) को स्टोर न करें।
- सार्वजनिक डेटा सेट को पुनर्परिभाषित न करें, जो कुछ देशों में अवैध हो सकता है।
क्लाउडफ्लेयर सुरक्षा को समझना
- क्लाउडफ्लेयर क्या है?
क्लाउडफ्लेयर एक क्लाउड प्लेटफ़ॉर्म है जो सामग्री वितरण नेटवर्क (CDN), DNS या तेज करना, और सुरक्षा संरक्षण को एकीकृत करता है। वेबसाइटें Distributed Denial of Service (DDoS) हमलों को कम करने के लिए क्लाउडफ्लेयर का उपयोग करती हैं (यानि, कई एक्सेस अनुरोधों के कारण वेबसाइटों का ऑफ़लाइन होना) और सुनिश्चित करती हैं कि इसका उपयोग करने वाली वेबसाइटें हमेशा चालू रहें।
क्लाउडफ्लेयर के काम करने के तरीके को समझने के लिए यहाँ एक सरल उदाहरण है:
जब आप किसी ऐसी वेबसाइट पर जाते हैं जिसमें क्लाउडफ्लेयर सक्षम है (जैसे example.com), आपका अनुरोध पहले क्लाउडफ्लेयर के एज सर्वर तक पहुँचता है, न कि मूल सर्वर तक। क्लाउडफ्लेयर तब तय करेगा कि आपके अनुरोध को जारी रखने की अनुमति दी जाए या नहीं, कई नियमों के आधार पर, जैसे कि:
- क्या कैश किया गया पृष्ठ सीधे लौटाया जा सकता है;
- क्या आपको एक CAPTCHA परीक्षण पास करना होगा;
- क्या आपका अनुरोध अवरुद्ध किया जाएगा;
- क्या अनुरोध को वास्तविक वेबसाइट सर्वर (मूल) को अग्रेषित किया जाएगा।
यदि आपको एक वैध उपयोगकर्ता के रूप में पहचाना जाता है, तो क्लाउडफ्लेयर अनुरोध को मूल सर्वर पर अग्रेषित करेगा और सामग्री को आपके लिए लौटा देगा। यह तंत्र वेबसाइट की सुरक्षा को बहुत बढ़ाता है लेकिन स्वचालित पहुंच के लिए महत्वपूर्ण चुनौतियाँ भी पेश करता है।
क्लाउडफ्लेयर को बायपास करना कई डेटा संग्रह कार्यों में से एक कठिन तकनीकी चुनौती है। नीचे, हम गहराई से जानेंगे कि क्लाउडफ्लेयर को बायपास करना कठिन क्यों है।
- क्लाउडफ्लेयर सुरक्षा को बायपास करने में चुनौतियाँ
क्लाउडफ्लेयर को बायपास करना आसान नहीं है, विशेषकर जब उन्नत एंटी-बॉट सुविधाएँ (जैसे बॉट प्रबंधन, प्रबंधित चुनौती, टर्नस्टाइल सत्यापन, JS चुनौतियाँ, आदि) चालू होती हैं। कई पारंपरिक स्क्रैपिंग उपकरण (जैसे Selenium और Puppeteer) अक्सर स्पष्ट फिंगरप्रिंट सुविधाओं या अस्वाभाविक व्यवहार अनुकरण के कारण सही अनुरोध किए जाने से पहले ही पहचान लिए जाते हैं और अवरुद्ध कर दिए जाते हैं।
हालांकि, कुछ ओपन-सोर्स उपकरण हैं जो विशेष रूप से क्लाउडफ्लेयर को बायपास करने के लिए डिज़ाइन किए गए हैं (जैसे FlareSolverr, undetected-chromedriver), ये उपकरण आमतौर पर छोटी जीवनकाल के होते हैं। जैसे ही उनका व्यापक उपयोग होता है, क्लाउडफ्लेयर अपनी पहचान नियमों को तेजी से अपडेट करता है ताकि उन्हें अवरुद्ध किया जा सके। इसका मतलब है कि क्लाउडफ्लेयर की सुरक्षा तंत्रों को स्थिर और दीर्घकालिक तरीके से बायपास करने के लिए, टीमों को अक्सर इन-हाउस विकास क्षमताओं और रखरखाव और अपडेट के लिए निरंतर संसाधन निवेश की आवश्यकता होती है।
क्लाउडफ्लेयर सुरक्षा को बायपास करने में मुख्य चुनौतियाँ निम्नलिखित हैं:
- सख्त ब्राउज़र फिंगरप्रिंट पहचान: क्लाउडफ्लेयर अनुरोधों में उपयोगकर्ता-एजेंट, भाषा सेटिंग, स्क्रीन रिज़ॉल्यूशन, समय क्षेत्र, और कैनवस/वेबजीएल रेंडरिंग जैसी फिंगरप्रिंट सुविधाओं का पता लगाता है। यदि यह असामान्य ब्राउज़रों या स्वचालन व्यवहारों का पता लगाता है, तो यह अनुरोध को अवरुद्ध करता है।
- जटिल JS चुनौती तंत्र: Cloudflare गतिशील रूप से जावास्क्रिप्ट चुनौतियों (जैसे CAPTCHA, विलंबित रीडायरेक्ट, तार्किक गणनाएँ, आदि) को उत्पन्न करता है, और स्वचालित स्क्रिप्ट अक्सर इन जटिल तर्कों को सही ढंग से पार्स या निष्पादित करने में संघर्ष करती हैं।
- व्यवहारात्मक विश्लेषण प्रणाली: स्थिर फ़िंगरप्रिंट्स के अलावा, Cloudflare उपयोगकर्ता व्यवहार की प्रगति का विश्लेषण भी करता है, जैसे माउस मूवमेंट, किसी पृष्ठ पर बिताया गया समय, स्क्रॉलिंग क्रियाएँ, आदि। इसके लिए मानव व्यवहार को अनुकरण करने में उच्च सटीकता की आवश्यकता होती है।
- दर और समवर्ती नियंत्रण: उच्च-आवृत्ति पहुंच आसानी से Cloudflare की दर सीमित करने और IP ब्लॉकिंग रणनीतियों को सक्रिय कर सकती है। प्रॉक्सी पूल और वितरित शेड्यूलिंग को अत्यधिक अनुकूलित करना आवश्यक है।
- अदृश्य सर्वर-साइड सत्यापन: चूंकि Cloudflare एक किनारे का इंटरसेप्टर है, इसलिए कई वास्तविक अनुरोधों को मूल सर्वर तक पहुंचने से पहले ब्लॉक कर दिया जाता है, जिससे पारंपरिक पैकेट कैप्चर विश्लेषण विधियाँ अप्रभावी हो जाती हैं।
इसलिए, Cloudflare को सफलतापूर्वक बायपास करने के लिए वास्तविक ब्राउज़र व्यवहार का अनुकरण करना, जावास्क्रिप्ट को गतिशील रूप से निष्पादित करना, फ़िंगरप्रिंट को लचीले ढंग से कॉन्फ़िगर करना, और उच्च गुणवत्ता वाले प्रॉक्सियों और गतिशील शेड्यूलिंग तंत्र का उपयोग करना आवश्यक है।
Scrapeless Scraping Browser के साथ Idealista Cloudflare को बायपास करना और रियल एस्टेट डेटा एकत्र करना
इस अध्याय में, हम Scrapeless Scraping Browser का उपयोग करके Idealista से रियल एस्टेट डेटा को स्क्रैप करने के लिए एक कुशल, स्थिर, और एंटी-एंटी-स्क्रैपिंग स्वचालन प्रणाली बनाने का प्रदर्शन करेंगे, जो एक प्रमुख यूरोपीय रियल एस्टेट प्लेटफ़ॉर्म है। Idealista कई सुरक्षा तंत्रों का उपयोग करता है, जिनमें Cloudflare, गतिशील लोडिंग, IP दर सीमित करना, और उपयोगकर्ता व्यवहार पहचान शामिल हैं, जिससे यह एक बहुत चुनौतीपूर्ण लक्ष्य प्लेटफ़ॉर्म बन जाता है।
हम निम्नलिखित तकनीकी पहलुओं पर ध्यान केंद्रित करेंगे:
- Cloudflare सत्यापन पृष्ठों को बायपास करना
- कस्टम फ़िंगरप्रिंटिंग और वास्तविक उपयोगकर्ता व्यवहार का अनुकरण करना
- सत्र पुनरावृत्ति का उपयोग करना
- कई प्रॉक्सी पूल के साथ उच्च-संवर्द्धन स्क्रैपिंग
- लागत अनुकूलन
चुनौती को समझना: Idealista का Cloudflare सुरक्षा
Idealista दक्षिणी यूरोप में एक प्रमुख ऑनलाइन रियल एस्टेट प्लेटफार्म है, जो विभिन्न प्रकार की संपत्तियों के लिए लाखों लिस्टिंग प्रदान करता है, जिनमें आवासीय घर, अपार्टमेंट और साझा कमरे शामिल हैं। इसकी संपत्ति डेटा के उच्च व्यावसायिक मूल्य को देखते हुए, प्लेटफ़ॉर्म ने कड़े एंटी-स्क्रैपिंग उपाय लागू किए हैं।
स्वचालित स्क्रैपिंग से लड़ने के लिए, Idealista ने Cloudflare को तैनात किया है - जो एक व्यापक रूप से उपयोग किया जाने वाला एंटी-बॉट और सुरक्षा सुरक्षा प्रणाली है, जो दुर्भावनापूर्ण बॉट, DDoS हमलों, और डेटा दुरुपयोग से रक्षा करने के लिए डिज़ाइन की गई है। Cloudflare की एंटी-स्क्रैपिंग तंत्र मुख्य रूप से निम्नलिखित तत्वों से मिलकर बनी हैं:
- पहुंच सत्यापन तंत्र: JS चुनौती, ब्राउज़र पारदर्शिता जांच, और CAPTCHA सत्यापन सहित, यह तय करने के लिए कि क्या आगंतुक एक वास्तविक उपयोगकर्ता है।
- व्यवहारात्मक विश्लेषण: माउस मूवमेंट, क्लिक पैटर्न, और स्क्रॉल गति जैसी क्रियाओं के माध्यम से वास्तविक उपयोगकर्ताओं का पता लगाना।
- HTTP हेडर विश्लेषण: ब्राउज़र प्रकार, भाषा सेटिंग्स, और संदर्भ डेटा की जांच करने के लिए असमानताओं की जांच करना। संदिग्ध हेडर स्वचालित बॉट के रूप में छिपाने के प्रयासों को उजागर कर सकते हैं।
- फ़िंगरप्रिंट पहचान और अवरोधन: ब्राउज़र फ़िंगरप्रिंट, TLS फ़िंगरप्रिंट, और हेडर जानकारी के माध्यम से स्वचालन उपकरणों (जैसे Selenium और Puppeteer) द्वारा उत्पन्न ट्रैफ़िक की पहचान करना।
- किनारे नोड फ़िल्टरिंग: अनुरोध पहले Cloudflare के वैश्विक किनारे नेटवर्क में प्रवेश करते हैं, जो उनके जोखिम का मूल्यांकन करता है। केवल उन अनुरोधों को जो कम-जोखिम वाले समझा जाता है, Idealista के मूल सर्वरों पर अग्रेषित किया जाता है।
अगला, हम विस्तार से समझाएंगे कि Scrapeless Scraping Browser का उपयोग करके Idealista के Cloudflare सुरक्षा को कैसे बायपास किया जाए और सफलतापूर्वक रियल एस्टेट डेटा एकत्र किया जाए।
Scrapeless Scraping Browser के साथ Idealista Cloudflare को बायपास करना
आवश्यकताएँ
इससे पहले कि हम शुरू करें, आइए सुनिश्चित करें कि हमारे पास आवश्यक उपकरण हैं:
-
पायथन: यदि आपने अभी तक पायथन स्थापित नहीं किया है, तो कृपया नवीनतम संस्करण डाउनलोड करें और इसे अपने सिस्टम पर स्थापित करें।
-
आवश्यक पुस्तकालय: आपको कई पायथन पुस्तकालय स्थापित करने की आवश्यकता है। एक टैर्मिनल या कमांड प्रांप्ट खोलें और निम्नलिखित कमांड चलाएँ:
pip install requests beautifulsoup4 lxml selenium selenium-wire undetected-chromedriver -
ChromeDriver: ChromeDriver डाउनलोड करें। सुनिश्चित करें कि आप उस संस्करण को चुनें जो आपके स्थापित Chrome संस्करण से मेल खाता है।
-
Scrapeless खाता: Idealista के बॉट सुरक्षा को बायपास करने के लिए, आपको एक Scrapeless Scraping Browser खाता चाहिए। आप यहाँ साइन अप कर सकते हैं और एक $2 मुफ्त परीक्षण प्राप्त कर सकते हैं।
डेटा प्राप्त करना
हमारा लक्ष्य Idealista पर प्रत्येक संपत्ति सूची के बारे में विस्तृत जानकारी निकालना है। हम साइट की संरचना को समझने और लक्षित करने के लिए आवश्यक HTML तत्वों की पहचान करने के लिए ब्राउज़र के डेवलपर उपकरणों का उपयोग कर सकते हैं।
पृष्ठ पर किसी भी स्थान पर दाएँ-क्लिक करें और स्रोत देखने के लिए Inspect का चयन करें।
इस लेख में, हम मैड्रिड के आल्काला दे हेनार्स से संपत्ति सूची को स्क्रैप करने पर ध्यान केंद्रित करेंगे, निम्नलिखित URL का उपयोग करते हुए:
https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/
हम प्रत्येक सूची से निम्नलिखित डेटा पॉइंट्स निकालना चाहते हैं:
- शीर्षक
- कीमत
- क्षेत्र की जानकारी
- संपत्ति वर्णन
- चित्र URLs
नीचे आप एनोटेटेड संपत्ति सूची पृष्ठ देख सकते हैं जो दिखाता है कि प्रत्येक संपत्ति के लिए सभी जानकारी कहाँ स्थित है।
HTML स्रोत कोड की जाँच करने से, हम प्रत्येक डेटा पॉइंट के लिए CSS चयनकर्ता की पहचान कर सकते हैं। CSS चयनकर्ता उन पैटर्न हैं जो HTML दस्तावेज़ में तत्वों का चयन करने के लिए उपयोग किए जाते हैं।
HTML स्रोत कोड की जाँच करने पर, हमने पाया कि प्रत्येक संपत्ति सूची एक <article> टैग में है जिसका वर्ग item है। प्रत्येक आइटम के भीतर:
- शीर्षक एक
<a>टैग में है जिसका वर्गitem-linkहै। - कीमत एक
<span>टैग में है जिसका वर्गitem-priceहै। - और इसी तरह अन्य डेटा पॉइंट्स के लिए।
चरण 1: ChromeDriver के साथ Selenium सेटअप करें
पहले, हमें Selenium को ChromeDriver का उपयोग करने के लिए कॉन्फ़िगर करना होगा। chrome_options सेट करके और ChromeDriver को प्रारंभ करके शुरू करें।
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
s = Service("अपने ChromeDriver के पथ के साथ बदलें")
driver = webdriver.Chrome(service=s, chrome_options=chrome_options)यह कोड आवश्यक मॉड्यूल को आयात करता है, जिसमें seleniumwire उन्नत ब्राउज़र इंटरएक्शन के लिए और HTML पार्सिंग के लिए BeautifulSoup शामिल है।
हम एक फ़ंक्शन listings(url) परिभाषित करते हैं और Chrome को हेडलेस मोड में चलाने के लिए chrome_options में --headless तर्क जोड़ते हैं। फिर, हम निर्दिष्ट सेवा पथ का उपयोग करके ChromeDriver को प्रारंभ करते हैं।
चरण 2: लक्षित URL लोड करें
अगले चरण में, हम लक्षित URL को लोड करते हैं और पृष्ठ के पूरी तरह से लोड होने की प्रतीक्षा करते हैं।
driver.get(url)
time.sleep(8) # वेबसाइट के लोड समय के आधार पर समायोजित करेंयहां, driver.get(url) आदेश ब्राउज़र को निर्दिष्ट URL पर जाने का निर्देश देता है।
हम स्क्रिप्ट को 8 सेकंड के लिए रोकने के लिए time.sleep(8) का उपयोग करते हैं, जिससे वेब पृष्ठ को पूरी तरह से लोड होने के लिए पर्याप्त समय मिलता है। यह प्रतीक्षा समय वेबसाइट की लोडिंग गति के आधार पर समायोजित किया जा सकता है।
चरण 3: पृष्ठ सामग्री का विश्लेषण करें
पृष्ठ लोड होने के बाद, हम BeautifulSoup का उपयोग करके इसकी सामग्री का विश्लेषण करते हैं:
soup = BeautifulSoup(driver.page_source, "lxml")
driver.quit()यहां, हम driver.page_source का उपयोग लोड किए गए पृष्ठ की HTML सामग्री प्राप्त करने के लिए करते हैं, और इसे lxml पार्सर के साथ BeautifulSoup का उपयोग करके पार्स करते हैं। अंत में, हम ब्राउज़र इंस्टेंस को बंद करने और संसाधनों को साफ करने के लिए driver.quit() का उपयोग करते हैं।
चरण 4: पार्स किए गए HTML से डेटा निकालें
अगले चरण में, हम पार्स किए गए HTML से संबंधित डेटा निकालते हैं।
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
"शीषक": listing.find("a", class_="item-link").get("title", "nil"),
"कीमत": listing.find("span", class_="item-price").get_text(strip=True),
"बेडरूम": bedrooms,
"क्षेत्र": area,
"विवरण": description_text,
"छवि URL": first_image_url,
}
extracted_data.append(listing_info)यहां, हम article टैग वाले सभी तत्वों को खोजते हैं जिनका वर्ग नाम item है, जो व्यक्तिगत संपत्ति सूचियों का प्रतिनिधित्व करते हैं। प्रत्येक सूची के लिए, हम इसके शीर्षक, विवरण (जैसे बेडरूम की संख्या और क्षेत्र), और चित्र URL निकालते हैं। हम इन विवरणों को एक डिक्शनरी में संग्रहीत करते हैं और प्रत्येक डिक्शनरी को extracted_data नामक एक सूची में जोड़ते हैं।
चरण 5: निकाले गए डेटा को सहेजें
अंत में, हम निकाले गए डेटा को एक JSON फ़ाइल में सहेजते हैं।
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"new_revised_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
```hi
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"एक्सट्रैक्ट किए गए डेटा को {json_filename} में सहेजा गया")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)बॉट डिटेक्शन को बायपास करना
यदि आपने इस ट्यूटोरियल के दौरान स्क्रिप्ट कम से कम दो बार चलाई है, तो आपने देखा होगा कि एक CAPTCHA पृष्ठ प्रकट होता है।
क्लाउडफ्लेयर चैलेंज पृष्ठ प्रारंभ में cf-chl-bypass स्क्रिप्ट लोड करता है और जावास्क्रिप्ट गणनाएं करता है, जो आमतौर पर लगभग 5 सेकंड लेता है।
स्क्रेपलेस एक सरल और विश्वसनीय तरीके की पेशकश करता है जिससे आप आइडियालिस्टा जैसी साइटों से डेटा पहुंच सकते हैं, बिना अपने स्वयं के स्क्रैपिंग बुनियादी ढांचे का निर्माण और रखरखाव किए। स्क्रेपलेस स्क्रैपिंग ब्राउज़र एक उच्च-अवधि स्वचालन समाधान है जिसे एआई के लिए बनाया गया है। यह एक उच्च प्रदर्शन, लागत-प्रभावी, एंटी-ब्लॉकिंग ब्राउज़र प्लेटफॉर्म है जिसे बड़े पैमाने पर डेटा स्क्रैपिंग के लिए डिज़ाइन किया गया है और अत्यधिक मानव जैसी व्यवहार को अनुकरण करता है। यह रीकैप्चा, क्लाउडफ्लेयर टर्नस्टाइल/चैलेंज, AWS WAF, डेटा डोम, और वास्तविक समय में अधिक को संभाल सकता है, जिससे यह एक कुशल वेब स्क्रैपिंग समाधान बनता है।
नीचे क्लाउडफ्लेयर सुरक्षा को स्क्रेपलेस का उपयोग करके बायपास करने के चरण दिए गए हैं:
चरण 1: तैयारी
1.1 प्रोजेक्ट फ़ोल्डर बनाना
- अपने प्रोजेक्ट के लिए एक नया फ़ोल्डर बनाएं, उदाहरण के लिए,
scrapeless-bypass। - अपने टर्मिनल में फ़ोल्डर में जाएं:
cd path/to/scrapeless-bypass1.2 Node.js प्रोजेक्ट को प्रारंभ करना
पैकेज.json फ़ाइल बनाने के लिए निम्नलिखित आदेश चलाएँ:
npm init -y1.3 आवश्यक निर्भरताएँ स्थापित करें
पुपेटियर-कोर स्थापित करें, जो ब्राउज़र इंस्टेंस के लिए रिमोट कनेक्शन की अनुमति देता है:
npm install puppeteer-coreयदि पुपेटियर पहले से आपके सिस्टम पर स्थापित नहीं है, तो पूर्ण संस्करण स्थापित करें:
npm install puppeteer puppeteer-coreचरण 2: अपना स्क्रेपलेस एपीआई कुंजी प्राप्त करें
2.1 स्क्रेपलेस पर साइन अप करें
- स्क्रेपलेस पर जाएं और एक खाता बनाएं।
- API की प्रबंधन अनुभाग पर जाएं।
- एक नया एपीआई की उत्पन्न करें और इसे कॉपी करें।
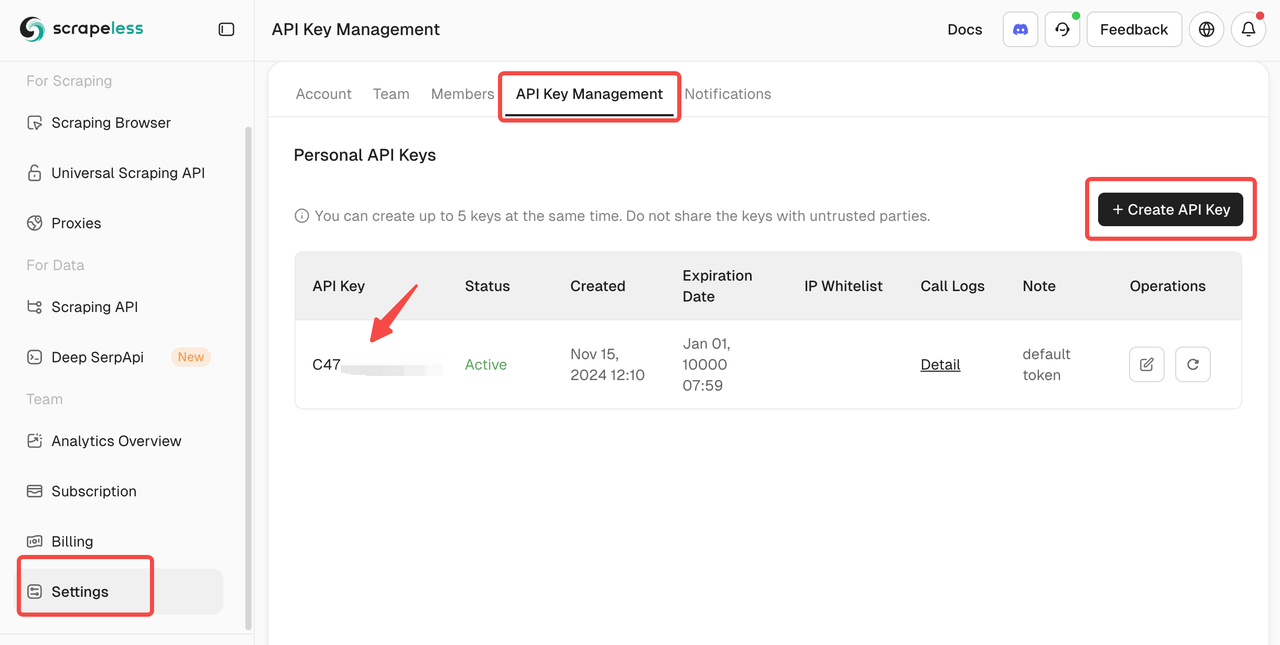
चरण 3: स्क्रेपलेस ब्राउज़रलेस से कनेक्ट करें
3.1 वेबस्कॉट कनेक्शन यूआरएल प्राप्त करें
स्क्रेपलेस क्लाउड-आधारित ब्राउज़र के साथ बातचीत के लिए पुपेटियर को एक वेबस्कॉट कनेक्शन यूआरएल प्रदान करता है।
फॉर्मेट इस प्रकार है:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYAPIKey को अपनी वास्तविक स्क्रेपलेस एपीआई कुंजी से परिवर्तन करें।
3.2 कनेक्शन पैरामीटर कॉन्फ़िगर करें
token: आपकी स्क्रेपलेस एपीआई कुंजीsession_ttl: ब्राउज़र सत्र की अवधि (सेकंड में), उदाहरण के लिए,180proxy_country: प्रॉक्सी सर्वर का देश कोड (उदाहरण के लिए, यूनाइटेड किंगडम के लिएGB, संयुक्त राज्य के लिएUS)
---
#### चरण 4: पुपटीयर स्क्रिप्ट लिखें
##### 4.1 स्क्रिप्ट फ़ाइल बनाएँ
अपने प्रोजेक्ट फ़ोल्डर के अंदर, `bypass-cloudflare.js` नाम की एक नई जावास्क्रिप्ट फ़ाइल बनाएँ।
##### 4.2 स्क्रैपलेस से कनेक्ट करें और पुपटीयर लॉन्च करें
`bypass-cloudflare.js` में निम्नलिखित कोड जोड़ें:import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // अपने असली एपीआई की से बदलें
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({token: API_KEY,session_ttl: '180', // ब्राउज़र सत्र की अवधि, सेकंड मेंproxy_country: 'GB', // प्रॉक्सी देश कोडproxy_session_id: 'test_session', // प्रॉक्सी सत्र आईडी (समान आईपी बनाए रखता है)proxy_session_duration: '5' // प्रॉक्सी सत्र की अवधि, मिनट में
}).toString();
const connectionURL = ${host}/browser?${query};
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL,defaultViewport: null,
});
console.log('Scrapeless से कनेक्ट हो गया');
##### 4.3 एक वेबपेज खोलें और क्लाउडफ्लेयर को बायपास करें
स्क्रिप्ट को एक नया पृष्ठ खोलने और क्लाउडफ्लेयर से सुरक्षित वेबसाइट पर जाने के लिए विस्तारित करें:const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
##### 4.4 पृष्ठ तत्वों के लोड होने की प्रतीक्षा करें
आगे बढ़ने से पहले सुनिश्चित करें कि क्लाउडफ्लेयर सुरक्षा को बायपास किया गया है:await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // आवश्यकतानुसार चयनकर्ता समायोजित करें
##### 4.5 एक स्क्रीनशॉट लें
यह सत्यापित करने के लिए कि क्लाउडफ्लेयर सुरक्षा को सफलतापूर्वक बायपास किया गया है, पृष्ठ का एक स्क्रीनशॉट लें:await page.screenshot({ path: 'challenge-bypass.png' });
console.log('स्क्रीनशॉट को challenge-bypass.png के रूप में सहेजा गया');
##### 4.6 पूर्ण स्क्रिप्ट
नीचे दी गई पूर्ण स्क्रिप्ट है:import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // अपने असली एपीआई की से बदलें
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = ${host}/browser?${query};
(async () => {
try {
// Scrapeless से कनेक्ट करें
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Scrapeless से कनेक्ट हो गया');
// एक नया पृष्ठ खोलें और लक्ष्य वेबसाइट पर जाएँ
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// पृष्ठ के पूरी तरह लोड होने की प्रतीक्षा करें
await page.waitForTimeout(5000); // यदि आवश्यक हो तो देरी समायोजित करें
await page.waitForSelector('main.page-content', { timeout: 30000 });
// एक स्क्रीनशॉट कैप्चर करें
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('स्क्रीनशॉट को challenge-bypass.png के रूप में सहेजा गया');
// ब्राउज़र बंद करें
await browser.close();
console.log('ब्राउज़र बंद किया गया');} catch (error) {
console.error('त्रुटि:', error);
}
})();
#### चरण 5: स्क्रिप्ट चलाएँ
##### 5.1 स्क्रिप्ट सहेजें
सुनिश्चित करें कि स्क्रिप्ट को bypass-cloudflare.js के रूप में सहेजा गया है।
##### 5.2 स्क्रिप्ट को निष्पादित करें
स्क्रिप्ट को Node.js का उपयोग करके चलाएँ:node bypass-cloudflare.js
##### 5.3 अपेक्षित आउटपुट
यदि सब कुछ ठीक से सेट किया गया है, तो टर्मिनल में यह प्रदर्शित होगा:Scrapeless से कनेक्ट हो गया
स्क्रीनशॉट को challenge-bypass.png के रूप में सहेजा गया
ब्राउज़र बंद किया गया
challenge-bypass.png फ़ाइल आपके प्रोजेक्ट फ़ोल्डर में दिखाई देगी, यह पुष्टि करते हुए कि क्लाउडफ्लेयर सुरक्षा को सफलतापूर्वक बायपास किया गया है।
आप अपने स्क्रैपिंग कोड में सीधे Scrapeless स्क्रैपिंग ब्राउज़र को भी एकीकृत कर सकते हैं:const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=C4778985476352D77C08ECB031AF0857&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();
### फ़िंगरप्रिंट अनुकूलन
जब वेबसाइटों से डेटा स्क्रैप करते समय—विशेष रूप से बड़े रियल एस्टेट प्लेटफ़ॉर्म जैसे **Idealista**—यहां तक कि यदि आप **Scrapeless** का उपयोग करके **Cloudflare** चुनौतियों को सफलतापूर्वक बायपास करते हैं, तो भी आपको दोहराने या उच्च मात्रा में एक्सेस के कारण बॉट के रूप में चिह्नित किया जा सकता है।
वेबसाइटें अक्सर स्वचालित व्यवहार का पता लगाने और एक्सेस को प्रतिबंधित करने के लिए **ब्राउज़र फ़िंगरप्रिंटिंग** का उपयोग करती हैं।
---
#### ⚠️ सामान्य समस्याएँ जिनका आप सामना कर सकते हैं
- **कई स्क्रैप करने के बाद धीमी प्रतिक्रिया समय**
साइट अपनी आईपी या व्यवहार पैटर्न के आधार पर अनुरोधों को धीमा कर सकती है।
- **पृष्ठ लेआउट रेंडर करने में विफल हो रहा है**
गतिशील सामग्री वास्तविक ब्राउज़र वातावरण पर निर्भर हो सकती है, जिससे स्क्रैपिंग के दौरान डेटा गायब या टूट सकता है।
- **कुछ क्षेत्रों में लिस्टिंग गायब हैं**
वेबसाइटें संदेहास्पद ट्रैफ़िक पैटर्न के आधार पर सामग्री को ब्लॉक या छिपा सकती हैं।
---
ये समस्याएँ आमतौर पर प्रत्येक अनुरोध के लिए समान ब्राउज़र कॉन्फ़िगरेशन के कारण होती हैं। यदि आपकी ब्राउज़र फिंगरप्रिंट अपरिवर्तित रहता है, तो स्वचालन का पता लगाना एंटी-बॉट सिस्टम के लिए आसान हो जाता है।
---
#### समाधान: स्क्रैपलेस के साथ कस्टम फिंगरप्रिंटिंग
**स्क्रैपलेस स्क्रैपिंग ब्राउज़र** वास्तविक उपयोगकर्ता व्यवहार की नकल करने और पता लगाने से बचने के लिए फिंगरप्रिंट अनुकूलन के लिए अंतर्निहित समर्थन प्रदान करता है।
आप निम्नलिखित फिंगरप्रिंट तत्वों को **यादृच्छिक या अनुकूलित** कर सकते हैं:
| फिंगरप्रिंट तत्व | विवरण |
|---------------------|--------------------------------------------------------------------------|
| **यूजर-एजेंट** | विभिन्न OS/ब्राउज़र संयोजनों की नकल करें (जैसे, विंडोज/मैक पर क्रोम)। |
| **प्लेटफ़ॉर्म** | विभिन्न ऑपरेटिंग सिस्टम (विंडोज, मैकओएस, आदि) का अनुकरण करें। |
| **स्क्रीन आकार** | मोबाइल/डेस्कटॉप असमानताओं से बचने के लिए विभिन्न उपकरण रिज़ॉल्यूशनों की नकल करें। |
| **स्थानीयकरण** | संगति के लिए भाषा और समय क्षेत्र को भौगोलिक स्थान के साथ संरेखित करें। |
---
इन मूल्यों को घुमाने या अनुकूलित करके, प्रत्येक अनुरोध अधिक स्वाभाविक प्रतीत होता है—जो पहचान के जोखिम को कम करता है और डेटा निकासी की विश्वसनीयता में सुधार करता है।
**कोड का उदाहरण:**const puppeteer = require('puppeteer-core');
const query = new URLSearchParams({
token: 'your-scrapeless-api-key', // आवश्यक
session_ttl: 180,
proxy_country: 'ANY',
// फिंगरप्रिंट पैरामीटर सेट करें
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.6998.45 Safari/537.36',
platform: 'Windows',
screen: JSON.stringify({ width: 1280, height: 1024 }),
localization: JSON.stringify({
locale: 'zh-HK',
languages: ['zh-HK', 'en-US', 'en'],
timezone: 'Asia/Hong_Kong',
})
});
const connectionURL = wss://browser.Scrapeless.com/browser?${query.toString()};
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.Scrapeless.com');
console.log(await page.title());
await browser.close();
})();
### सत्र पुनर्प्राप्ति
ब्राउज़र फिंगरप्रिंट को अनुकूलित करने के बाद, पृष्ठ स्थिरता काफी बेहतर हो जाती है, और सामग्री निकासी अधिक विश्वसनीय हो जाती है।
हालांकि, बड़े पैमाने पर स्क्रैपिंग संचालन के दौरान, अप्रत्याशित समस्याएं अभी भी निकासी विफलताओं का कारण बन सकती हैं। इसे संबोधित करने के लिए, **स्क्रैपलेस** एक शक्तिशाली **सत्र पुनर्प्राप्ति** सुविधा प्रदान करता है।
---
#### सत्र पुनर्प्राप्ति क्या है?
सत्र पुनर्प्राप्ति पूरी ब्राउज़र सत्र को विस्तार से रिकॉर्ड करती है, जिसमें सभी इंटरैक्शन कैप्चर होते हैं, जैसे:
- पृष्ठ लोड प्रक्रिया
- नेटवर्क अनुरोध और प्रतिक्रिया डेटा
- जावास्क्रिप्ट निष्पादन व्यवहार
- गतिशील रूप से लोड किया गया लेकिन असंदर्भित सामग्री
---
#### सत्र पुनर्प्राप्ति का उपयोग क्यों करें?
जटिल वेबसाइटों जैसे **Idealista** को स्क्रैप करते समय, सत्र पुनर्प्राप्ति गंभीरता से डिबगिंग दक्षता में सुधार कर सकती है।
| लाभ | विवरण |
|--------------------------|-------------------------------------------------------------------------|
| **सटीक समस्या ट्रैकिंग** | बिना अनुमान के विफल अनुरोधों की तेजी से पहचान करें |
| **कोड फिर से चलाने की आवश्यकता नहीं** | स्क्रैपिंग को फिर से चलाने के बजाय सीधे पुनर्प्राप्ति से मुद्दों का विश्लेषण करें |
| **बेहतर सहयोग** | आसान समस्या निवारण के लिए टीम के सदस्यों के साथ पुनर्प्राप्ति लॉग साझा करें |
| **गतिशील सामग्री विश्लेषण** | समझें कि स्क्रैपिंग के दौरान गतिशील रूप से लोड किया गया डेटा कैसे व्यवहार करता है |
---
#### उपयोग टिप
एक बार जब **सत्र पुनर्प्राप्ति** सक्षम हो जाए, तो जब भी स्क्रैप विफल हो या डेटा अधूरा दिखे, सबसे पहले पुनर्प्राप्ति लॉग की जांच करें। इससे आपको समस्या को तेजी से पहचानने में मदद मिलेगी और डिबगिंग का समय कम होगा।
### प्रॉक्सी कॉन्फ़िगरेशन
जब Idealista को स्क्रैप करते हैं, तो यह ध्यान देने योग्य है कि प्लेटफ़ॉर्म गैर-स्थानीय IP पते के प्रति अत्यधिक संवेदनशील है—विशेष रूप से विशिष्ट शहरों से सूचियों तक पहुँचते समय। यदि आपका IP देश से बाहर से आता है, तो Idealista:
- अनुरोध को पूरी तरह से ब्लॉक कर सकता है
- पृष्ठ का सरलीकृत या स्ट्रिप-डाउन संस्करण लौटाता है
- यहां तक कि CAPTCHA को ट्रिगर किए बिना भी, खाली या अधूरी डेटा प्रदान कर सकता है
---
#### स्क्रैपलेस अंतर्निहित प्रॉक्सी समर्थन
स्क्रैपलेस **निर्मित प्रॉक्सी कॉन्फ़िगरेशन** प्रदान करता है, जो आपको अपने भौगोलिक स्रोत को सीधे निर्दिष्ट करने की अनुमति देता है।
आप इसे निम्नलिखित का उपयोग करके कॉन्फ़िगर कर सकते हैं:
- `proxy_country`: एक दो-अक्षर वाला देश कोड (जैसे, `'ES'` स्पेन के लिए)
- `proxy_url`: आपके अपने प्रॉक्सी सर्वर URL
उदाहरण उपयोग:proxy_country: 'ES',
### उच्च समवर्तीता
हमने Idealista से जो पृष्ठ स्क्रैप किया—[अल्कालá डे हेनेरेस रियल एस्टेट लिस्टिंग](https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/)—उसमें 6 पृष्ठ की लिस्टिंग हो सकती है।
जब आप उद्योग प्रवृत्तियों का अनुसंधान कर रहे हों या प्रतिस्पर्धात्मक विपणन रणनीतियों को इकट्ठा कर रहे हों, तो आपको **20+ शहरों से दैनिक** रियल एस्टेट डेटा स्क्रैप करने की आवश्यकता हो सकती है, जो **हजारों पृष्ठों** को कवर करता है। कुछ मामलों में, आपको हर घंटे इस डेटा को भी ताज़ा करने की आवश्यकता हो सकती है।
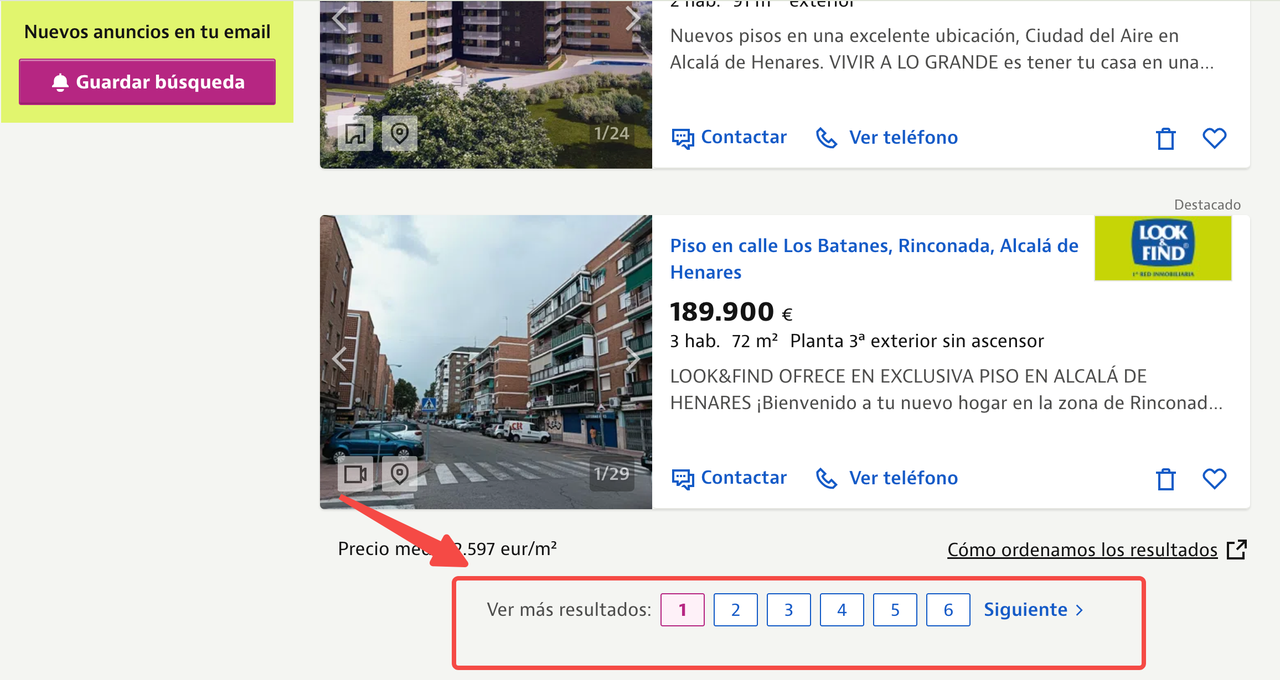
#### उच्च संचार आवश्यकताएँ
इस मात्रा को प्रभावी ढंग से संभालने के लिए, निम्नलिखित आवश्यकताओं पर विचार करें:
- **एकाधिक समवर्ती कनेक्शन**: बिना लंबे इंतजार के सैकड़ों पृष्ठों से डेटा स्क्रैप करने के लिए।
- **स्वचालन उपकरण**: Scrapeless Scraping Browser या समान उपकरणों का उपयोग करें जो बड़े पैमाने पर समवर्ती अनुरोधों को संभाल सकते हैं।
- **सत्र प्रबंधन**: अत्यधिक CAPTCHA या IP ब्लॉकों से बचने के लिए लगातार सत्र बनाए रखें।
---
#### Scrapeless स्केलेबिलिटी
Scrapeless विशेष रूप से उच्च संचार स्क्रैपिंग के लिए डिज़ाइन किया गया है। यह प्रदान करता है:
- **समांतर ब्राउज़र सत्र**: एक ही समय में कई अनुरोधों को संभालें, जिससे आप कई शहरों में बड़ी मात्रा में डेटा स्क्रैप कर सकें।
- **कम लागत, उच्च दक्षता स्क्रैपिंग**: समांतर स्क्रैपिंग प्रति पृष्ठ की स्क्रैपिंग लागत को कम करते हुए थ्रूपुट को अनुकूलित करती है।
- **ऊंची मात्रा वाले एंटी-बॉट डिफेंस को बायपास करें**: स्वचालित रूप से CAPTCHA और अन्य सत्यापन प्रणालियों को संभालता है, यहां तक कि उच्च लोड स्क्रैपिंग के दौरान।
---
> **टिप**: सुनिश्चित करें कि आपके अनुरोधों के बीच इतना अंतराल हो कि यह मानव-जैसी ब्राउज़िंग व्यवहार का अनुकरण करे और Idealista से दर-सीमित या प्रतिबंधित होने से रोके।
#### स्केलेबिलिटी और लागत दक्षता
नियमित Puppeteer सत्रों को प्रभावी ढंग से स्केल करने और कतार प्रणाली के साथ एकीकृत करने में संघर्ष करता है। हालाँकि, Scrapeless Scraping Browser डজনों से लेकर अनगिनत समवर्ती सत्रों तक बिना किसी कतार के समय और बिना समयबद्धताओं के सहज स्केलिंग का समर्थन करता है, यह सुनिश्चित करते हुए कि **जीरो कतार का समय और जीरो टाइमआउट्स** यहां तक कि पीक टास्क लोड के दौरान।
यहां उच्च संचार स्क्रैपिंग के लिए विभिन्न उपकरणों की तुलना है। Scrapeless के उच्च संचार ब्राउज़र के साथ भी, आपको लागतों की चिंता करने की आवश्यकता नहीं है—दरअसल, यह आपको शुल्क में लगभग **50%** बचाने में मदद कर सकता है।
---
#### उपकरण की तुलना
| **उपकरण का नाम** | **घंटे का दाम (USD/घंटा)** | **प्रॉक्सी शुल्क (USD/GB)** | **समवर्ती समर्थन** |
| ------------- | ------------------------- | ----------------------- | ---------------------- |
| **Scrapeless** | $0.063 – $0.090/घंटा (समवर्तीता और उपयोग पर निर्भर करता है) | $1.26 – $1.80/GB | 50 / 100 / 200 / 400 / 600 / 1000 / अनलिमिटेड |
| **Browserbase** | $0.10 – $0.198/घंटा (2-5GB फ्री प्रॉक्सीज़ शामिल) | $10/GB (मुफ्त आवंटन के बाद) | 3 (बुनियादी) / 50 (उन्नत) |
| **Brightdata** | $0.10/घंटा | $9.5/GB (मानक); $12.5/GB (उन्नत डोमेन) | अनलिमिटेड |
| **Zenrows** | $0.09/घंटा | $2.8 – $5.42/GB | अधिकतम 100 |
| **Browserless** | $0.084 – $0.15/घंटा (यूनिट-आधारित बिलिंग) | $4.3/GB | 3 / 10 / 50 |
> **टिप**: यदि आपको **विशाल पैमाने पर स्क्रैपिंग** और **उच्च संचार समर्थन** की आवश्यकता है, तो **Scrapeless** सबसे अच्छे लागत-से-प्रदर्शन अनुपात की पेशकश करता है।
### वेब स्क्रैपिंग के लिए लागत नियंत्रण रणनीतियाँ
सावधान उपयोगकर्ताओं ने यह देखा होगा कि Idealista के पृष्ठों में अक्सर उच्च-परिभाषा संपत्ति छवियों, इंटरएक्टिव मानचित्रों, वीडियो प्रस्तुतियों और विज्ञापन स्क्रिप्टों की बड़ी मात्रा होती है। जबकि ये तत्व अंतिम उपयोगकर्ताओं के लिए उपयोगकर्ता-केंद्रित होते हैं, वे डेटा निकालने के लिए अनावश्यक होते हैं और बैंडविड्थ खपत और लागत को काफी बढ़ा देते हैं।
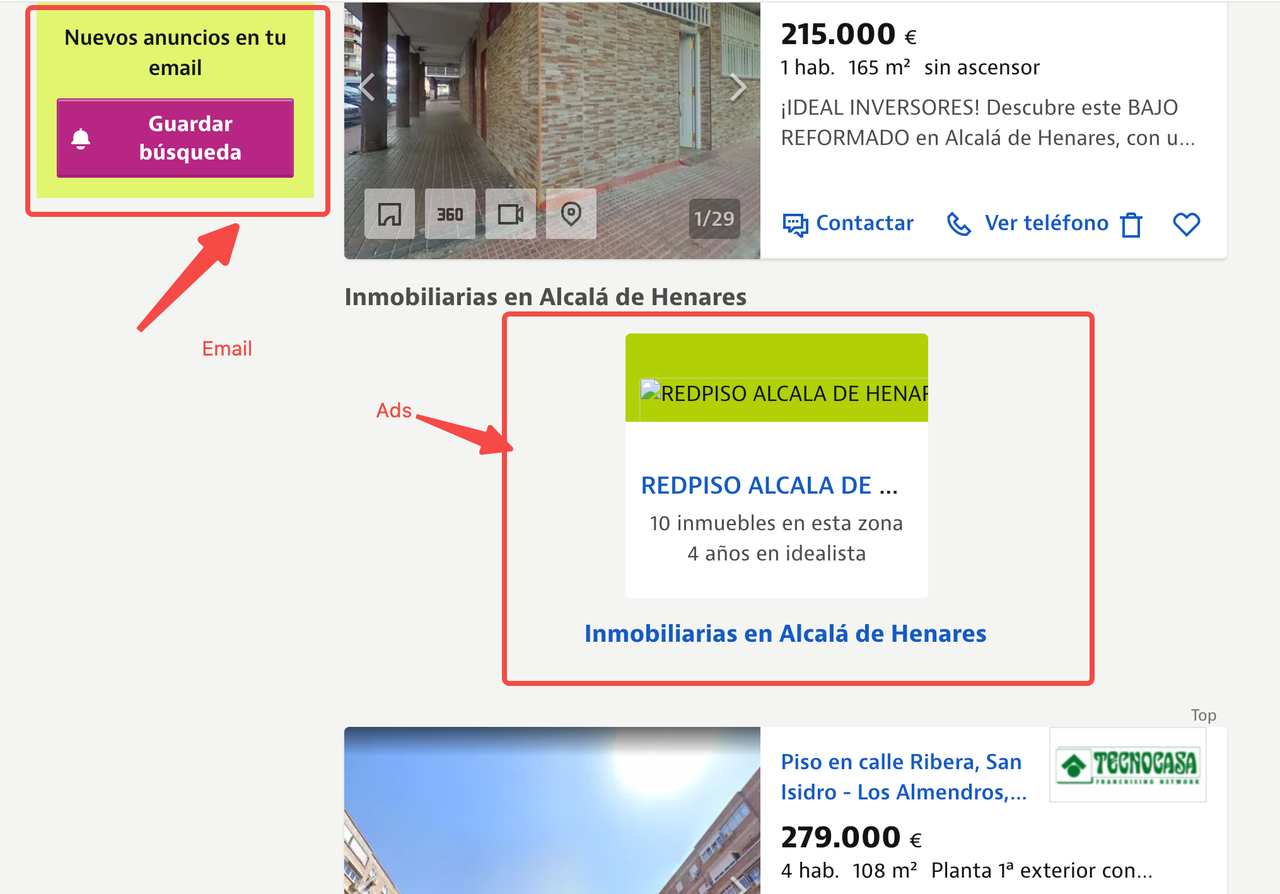
ट्रैफ़िक उपयोग को अनुकूलित करने के लिए, हम उपयोगकर्ताओं को निम्नलिखित रणनीतियाँ लागू करने की सिफारिश करते हैं:
1. **संसाधन अवरोधन**: ट्रैफ़िक खपत को कम करने के लिए अनावश्यक संसाधन अनुरोधों को रोकें।
2. **अनुरोध URL अवरोधन**: ट्रैफ़िक को और कम करने के लिए URL विशेषताओं के आधार पर विशिष्ट अनुरोधों को अवरुद्ध करें।
3. **मोबाइल उपकरणों का अनुकरण करें**: हल्के पृष्ठ संस्करण प्राप्त करने के लिए मोबाइल डिवाइस कॉन्फ़िगरेशन का उपयोग करें।
---
#### विस्तृत रणनीतियाँ
##### 1. **संसाधन अवरोधन**
संसाधन अवरोधन को सक्षम करना स्क्रैपिंग दक्षता में काफी सुधार कर सकता है। Puppeteer के `setRequestInterception` फ़ंक्शन को कॉन्फ़िगर करके, हम छवियों, मीडिया, फ़ॉन्ट और स्टाइलशीट जैसे संसाधनों को अवरुद्ध कर सकते हैं, जिससे बड़े सामग्री डाउनलोड से बचा जा सके।
##### 2. **अनुरोध URL फ़िल्टरिंग**
अनुरोध URL की जांच करके, हम विज्ञापन सेवाओं और तीसरे पक्ष के विश्लेषण स्क्रिप्ट जैसे अव्यवस्थित अनुरोधों को फ़िल्टर कर सकते हैं जो डेटा निष्कर्षण से संबंधित नहीं हैं। इससे अनावश्यक नेटवर्क ट्रैफ़िक कम होता है।
##### 3. **मोबाइल उपकरणों का अनुकरण करना**
एक मोबाइल उपकरण का अनुकरण करना (जैसे, यूज़र एजेंट को iPhone पर सेट करना) आपको पृष्ठ का हल्का, मोबाइल-अनुकूलित संस्करण प्राप्त करने की अनुमति देता है। इससे लोड होने वाले संसाधनों की संख्या कम हो जाती है और स्क्रैपिंग प्रक्रिया तेज हो जाती है।
> अधिक जानकारी के लिए, कृपया [Scrapeless आधिकारिक दस्तावेज़](https://docs.scrapeless.com/en/scraping-browser/guides/optimizing-cost/) देखें।
---
#### उदाहरण कोड
यहां संसाधन स्क्रैपिंग को अनुकूलित करने के लिए Scrapeless Cloud Browser + Puppeteer का उपयोग करते हुए इन तीन रणनीतियों को जोड़ने का एक उदाहरण है:import puppeteer from 'puppeteer-core';
const scrapelessUrl = 'wss://browser.scrapeless.com/browser?token=your_api_key&session_ttl=180&proxy_country=ANY';
async function scrapeWithResourceBlocking(url) {
const browser = await puppeteer.connect({
browserWSEndpoint: scrapelessUrl,
defaultViewport: null
});
const page = await browser.newPage();
// अनुरोध अवरोधन सक्षम करें```hi
await page.setRequestInterception(true);
// संसाधन प्रकारों को अवरुद्ध करने के लिए परिभाषित करें
const BLOCKED_TYPES = new Set([
'छवि',
'फॉन्ट',
'मीडिया',
'स्टाइलशीट',
]);
// अनुरोधों को बाधित करें
page.on('request', (request) => {
if (BLOCKED_TYPES.has(request.resourceType())) {
request.abort();
console.log(`अवरोधित: ${request.resourceType()} - ${request.url().substring(0, 50)}...`);
} else {
request.continue();
}
});
await page.goto(url, {waitUntil: 'domcontentloaded'});
// डेटा निकालें
const data = await page.evaluate(() => {
return {
title: document.title,
content: document.body.innerText.substring(0, 1000)
};
});
await browser.close();
return data;
}
// उपयोग
scrapeWithResourceBlocking('https://www.scrapeless.com')
.then(data => console.log('स्क्रैपिंग परिणाम:', data))
.catch(error => console.error('स्क्रैपिंग विफल:', error));इस तरह, आप न केवल उच्च ट्रैफ़िक लागतों को बचा सकते हैं, बल्कि डेटा गुणवत्ता सुनिश्चित करते हुए क्रॉलिंग गति को भी गति दे सकते हैं, जिससे प्रणाली की कुल स्थिरता और दक्षता में सुधार होता है।
5. सुरक्षा और अनुपालन अनुशंसा
Scrapeless का उपयोग करते समय, डेवलपर्स को निम्नलिखित बातों का ध्यान रखना चाहिए:
- लक्ष्य वेबसाइट की
robots.txtफ़ाइल और संबंधित कानूनों और विनियमों का पालन करें: सुनिश्चित करें कि आपकी स्क्रैपिंग गतिविधियाँ कानूनी हैं और साइट की दिशानिर्देशों का सम्मान करती हैं। - अत्यधिक अनुरोधों से बचें जो वेबसाइट के डाउनटाइम का कारण बन सकते हैं: सर्वर ओवरलोड से बचने के लिए स्क्रैपिंग की आवृत्ति के प्रति जागरूक रहें।
- संवेदनशील जानकारी को स्क्रैप न करें: उपयोगकर्ता गोपनीयता डेटा, भुगतान जानकारी या किसी अन्य संवेदनशील सामग्री को इकट्ठा न करें।
6. निष्कर्ष
बिग डेटा के युग में, डेटा संग्रहण विभिन्न उद्योगों में डिजिटल परिवर्तन के लिए एक महत्वपूर्ण आधार बन गया है। विशेष रूप से बाजार बुद्धिमत्ता, ई-कॉमर्स मूल्य तुलना, प्रतिस्पर्धी विश्लेषण, वित्तीय जोखिम प्रबंधन और रियल एस्टेट विश्लेषण जैसे क्षेत्रों में, डेटा-आधारित निर्णय लेने की मांग तेजी से बढ़ रही है। हालाँकि, वेब प्रौद्योगिकियों के निरंतर विकास के साथ, विशेष रूप से गतिशील रूप से लोड किए गए सामग्री के बड़े पैमाने पर उपयोग के साथ, पारंपरिक वेब स्क्रैपर्स धीरे-धीरे अपनी सीमाओं को उजागर कर रहे हैं। ये सीमाएँ न केवल स्क्रैपिंग को अधिक कठिन बनाती हैं बल्कि एंटी-स्क्रैपिंग तंत्र के बढ़ने का कारण भी बनती हैं, जिससे वेब स्क्रैपिंग के लिए बाधाएँ बढ़ जाती हैं।
वेब प्रौद्योगिकियों की प्रगति के साथ, पारंपरिक स्क्रैपर्स अब जटिल स्क्रैपिंग आवश्यकताओं को पूरा नहीं कर सकते। कुछ प्रमुख चुनौतियाँ और उनके साथ संबंधित समाधान नीचे दिए गए हैं:
- गतिशील सामग्री लोडिंग: ब्राउज़र-आधारित स्क्रैपर्स, JavaScript सामग्री के वास्तविक ब्राउज़र रेंडरिंग का अनुकरण करके, सुनिश्चित करते हैं कि वे गतिशील रूप से लोड किए गए वेब डेटा को स्क्रैप कर सकें।
- एंटी-स्क्रैपिंग तंत्र: प्रॉक्सी पूल, फिंगरप्रिंट पहचान, व्यवहार अनुकरण और अन्य तकनीकों का उपयोग करके, हम पारंपरिक स्क्रैपर्स द्वारा सामान्यतः ट्रिगर किए जाने वाले एंटी-स्क्रैपिंग तंत्र को बायपास कर सकते हैं।
- उच्च-समांतर स्क्रैपिंग: हेडलेस ब्राउज़र उच्च-समांतर कार्य तैनाती का समर्थन करते हैं, प्रॉक्सी शेड्यूलिंग के साथ मिलकर, बड़े पैमाने पर डेटा स्क्रैपिंग की आवश्यकताओं को पूरा करने के लिए।
- अनुपालन मुद्दे: कानूनी एपीआई और प्रॉक्सी सेवाओं का उपयोग करके, स्क्रैपिंग गतिविधियों को सुनिश्चित किया जा सकता है कि वे लक्षित वेबसाइटों के नियमों का पालन करें।
इसके परिणामस्वरूप, ब्राउज़र-आधारित स्क्रैपर्स उद्योग में एक नया प्रवृत्ति बन गए हैं। यह तकनीक न केवल वास्तविक ब्राउज़रों के माध्यम से उपयोगकर्ता व्यवहार का अनुकरण करती है, बल्कि आधुनिक वेबसाइटों की जटिल संरचनाओं और एंटी-स्क्रैपिंग तंत्रों को भी लचीला रूप से संभालती है, जिससे डेवलपर्स के लिए अधिक स्थिर और प्रभावी स्क्रैपिंग समाधान प्रदान करती है।
Scrapeless Scraping Browser इस तकनीकी प्रवृत्ति को अपनाता है, ब्राउज़र रेंडरिंग, प्रॉक्सी प्रबंधन, एंटी-डिटेक्शन तकनीकों और उच्च-समांतर कार्य शेड्यूलिंग को संयोजित करके, डेवलपर्स को जटिल ऑनलाइन वातावरण में डेटा स्क्रैपिंग कार्यों को प्रभावी ढंग से और स्थिरता से पूरा करने में मदद करता है। यह कई मुख्य लाभों के माध्यम से स्क्रैपिंग दक्षता और स्थिरता में सुधार करता है:
- उच्च-समांतर ब्राउज़र समाधान: Scrapeless का समर्थन बड़े पैमाने पर, उच्च-समांतर कार्यों के लिए है, जिससे हजारों स्क्रैपिंग कार्यों को तेजी से तैनात करना संभव हो जाता है ताकि दीर्घकालिक स्क्रैपिंग आवश्यकताओं को पूरा किया जा सके।
- एंटी-डिटेक्शन सेवा के रूप में: अंतर्निर्मित CAPTCHA समाधान और अनुकूलन योग्य फिंगरप्रिंट डेवलपर्स की मदद करते हैं, जो फिंगरप्रिंट और व्यवहार पहचान तंत्रों को बायपास करते हैं, जिससे अवरोधित होने के जोखिम को काफी कम किया जा सकता है।
- दृश्यमान डिबगिंग उपकरण - सत्र पुनरावृत्ति: स्क्रैपिंग प्रक्रिया के दौरान प्रत्येक ब्राउज़र इंटरैक्शन को पुनरावृत्ति करके, डेवलपर्स आसानी से स्क्रैपिंग प्रक्रिया में समस्याओं को डिबग और निदान कर सकते हैं, विशेष रूप से जटिल पृष्ठों और गतिशील रूप से लोड किए गए सामग्री को संभालने के लिए।
- अनुपालन और पारदर्शिता सुनिश्चित करना: Scrapeless अनुपालित डेटा स्क्रैपिंग पर जोर देता है, लक्षित वेबसाइटों के
robots.txtनियमों के पालन का समर्थन करता है और उपयोगकर्ताओं के डेटा स्क्रैपिंग गतिविधियों को लक्षित वेबसाइटों की नीतियों के साथ सुनिश्चित करने के लिए विस्तृत स्क्रैपिंग लॉग प्रदान करता है।
- **लचीलापन स्केलेबिलिटी**: Scrapeless Puppeteer के साथ सहजता से एकीकृत होता है, जिससे उपयोगकर्ता अपनी स्क्रैपिंग रणनीतियों को अनुकूलित कर सकते हैं और डेटा स्क्रैपिंग और विश्लेषण कार्य प्रवाह के लिए अन्य उपकरणों या प्लेटफार्मों के साथ कनेक्ट कर सकते हैं।
चाहे आप ई-कॉमर्स प्लेटफार्मों से मूल्य तुलना के लिए स्क्रैपिंग कर रहे हों, रियल एस्टेट वेबसाइट डेटा निकाल रहे हों, या वित्तीय जोखिम निगरानी और मार्केट इंटेलिजेंस विश्लेषण में इसका उपयोग कर रहे हों, Scrapeless विभिन्न उद्योगों के लिए उच्च दक्षता, बुद्धिमान, और विश्वसनीय समाधान प्रदान करता है।
इस लेख में तकनीकी विवरण और सर्वोत्तम प्रथाओं को कवर करने के साथ, आप अब समझते हैं कि Scrapeless का उपयोग बड़े पैमाने पर डेटा स्क्रैपिंग के लिए कैसे करें। चाहे आप गतिशील पृष्ठों को संभाल रहे हों, जटिल इंटरएक्टिव डेटा निकाल रहे हों, ट्रैफ़िक उपयोग को अनुकूलित कर रहे हों, या एंटी-स्क्रैपिंग तंत्र को पार कर रहे हों, Scrapeless आपको अपने स्क्रैपिंग लक्ष्यों को तेजी और प्रभावी तरीके से हासिल करने में मदद करता है।स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


