स्क्रेपलेस क्लाउड ब्राउज़र क्रियाशीलता में: ऑटोमेशन, फिंगरप्रिंट और CAPTCHA हैंडलिंग के लिए पुपीटीयर का अनुकूलन
Expert Network Defense Engineer
वेब स्वचालन और डेटा स्क्रैपिंग परिदृश्यों में, विकासकर्ता अक्सर तीन मूल तकनीकी चुनौतियों का सामना करते हैं:
- पर्यावरण पृथक्करण:
जब एक साथ दर्जनों या यहां तक कि सैकड़ों स्वतंत्र ब्राउज़र सत्रों को चलाया जाता है, तो पारंपरिक स्थानीय तैनाती समाधान ऊंचे संसाधन उपभोग, जटिल प्रबंधन, और ओवरहैड कॉन्फ़िगरेशन से ग्रस्त होते हैं।
- फिंगरप्रिंट पहचान जोखिम:
एक ही ब्राउज़र फिंगरप्रिंट का उपयोग कर बार-बार आने से लक्षित वेबसाइटों पर एंटी-बॉट और फिंगरप्रिंट पहचान तंत्र को आसानी से सक्रिय कर सकता है।
- कैप्चा व्य interruptions:
एक बार सक्रिय होने पर, reCAPTCHA या Cloudflare Turnstile जैसे सत्यापन स्वचालन स्क्रिप्ट को बाधित करते हैं। तृतीय-पक्ष कैप्चा समाधान सेवाओं को एकीकृत करना न केवल विकास की लागत और जटिलता को बढ़ाता है, बल्कि क्रियान्वयन की दक्षता को कम करता है।
ये समस्याएं अक्सर विकासकर्ताओं को स्थानीय वातावरण स्थापित करने या बाहरी सेवाओं को एकीकृत करने के लिए महत्वपूर्ण समय बिताने के लिए मजबूर करती हैं, जिससे समय और संचालन लागत दोनों बढ़ जाती हैं।
मूलतः, आवश्यकता है एक ऐसे उपकरण की जो निम्नलिखित कार्य कर सके:
- विशाल पृथक वातावरण:
API के माध्यम से स्वतंत्र ब्राउज़र प्रोफाइल उत्पन्न करें, प्रत्येक प्रोफाइल एक पूरी तरह से पृथक ब्राउज़र उदाहरण का प्रतिनिधित्व करता है।
- स्वयंकारित फिंगरप्रिंट रैंडमाइजेशन:
मुख्य पैरामीटर जैसे यूजर-एजेंट, टाइमज़ोन, भाषा, और स्क्रीन रिज़ॉल्यूशन को रैंडम बनाएं—सभी कुछ वास्तविक ब्राउज़र वातावरण के साथ पूर्ण स्थिरता बनाए रखते हुए।
- बिल्ट-इन कैप्चा हैंडलिंग:
स्वतः सामान्य कैप्चा चुनौतियों को पहचानें और हल करें बिना मानव हस्तक्षेप या तृतीय-पक्ष एकीकरण के।
तो, फिंगरप्रिंट ब्राउज़रों के बारे में क्या?
घरेलू उद्यम स्वचालन में, स्थानीय रूप से तैनात फिंगरप्रिंट ब्राउज़र का व्यापक रूप से उपयोग होता है। हालाँकि, ये अक्सर सिस्टम संसाधनों की बड़ी मात्रा का उपभोग करते हैं, उदाहरणों के बीच लगातार बनाए रखना कठिन होते हैं, और सत्यापन हैंडलिंग के लिए अभी भी तृतीय-पक्ष कैप्चा सेवाओं की आवश्यकता होती है।
इसके विपरीत, आधुनिक क्लाउड-आधारित हेडलेस ब्राउज़र जैसे Scrapeless.com एक अधिक स्केल करने योग्य और कुशल विकल्प प्रदान करते हैं। वे विकासकर्ताओं को अनुमति देते हैं:
- API के माध्यम से पृथक ब्राउज़र प्रोफाइल बनाना,
- स्वदेशी रूप से फिंगरप्रिंट रैंडमाइज़ करना, और
- स्वतः कैप्चा चुनौतियों को संभालना,
सभी क्लाउड में—जो विकास और रखरखाव की लागत को काफी कम करता है और ऊंची समवर्ती कार्यभारों का समर्थन करता है।
आगामी अनुभागों में, हम कई बेंचमार्क परिदृश्यों का अन्वेषण करेंगे ताकि यह मूल्यांकन किया जा सके कि क्लाउड-आधारित हेडलेस ब्राउज़र फिंगरप्रिंट पृथक्करण, समवर्तीता, और कैप्चा हैंडलिंग के संदर्भ में कैसे प्रदर्शन करते हैं।
⚠️ अस्वीकृति:
किसी भी ब्राउज़र स्वचालन समाधान का उपयोग करते समय, सदैव लक्षित वेबसाइट की सेवा की शर्तों, robots.txt नियमों, और संबंधित कानूनों और विनियमों का पालन करें।
बिना अनुमति या अवैध उद्देश्यों के लिए डेटा स्क्रैपिंग करना, या दूसरों के अधिकारों का उल्लंघन करना सख्त वर्जित है।
हम दुरुपयोग के परिणामस्वरूप उत्पन्न होने वाले किसी भी कानूनी परिणामों या हानियों के लिए कोई जिम्मेदारी नहीं लेते।
पर्यावरण सेटअप
सबसे पहले, Scrapeless Node SDK स्थापित करें। यदि आपके पास Node स्थापित नहीं है, तो कृपया पहले Node स्थापित करें।
bash
npm install @scrapeless-ai/sdk puppeteer-coreबुनियादी कनेक्शन परीक्षण
js
// अपनी API कुंजी सेट करें
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer } from "@scrapeless-ai/sdk";
const browser = await Puppeteer.connect({
sessionName: "sdk_test",
sessionTTL: 180,
proxyCountry: "ANY",
sessionRecording: true,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://www.scrapeless.com");
console.log(await page.title());
await browser.close();यदि पृष्ठ का शीर्षक प्रिंट किया जाता है, तो पर्यावरण सफलतापूर्वक कॉन्फ़िगर किया गया है।
अपने वेब स्वचालन को सुपरचार्ज करने के लिए तैयार हैं? आज ही Scrapeless क्लाउड ब्राउज़र का प्रयास करें और स्वतंत्र फिंगरप्रिंट, स्वचालित कैप्चा हैंडलिंग, और निर्बाध प्रोफाइल प्रबंधन का अनुभव करें—सभी क्लाउड में!
केस 1: यादृच्छिक ब्राउज़र फिंगरप्रिंट सत्यापन
उद्देश्य: यह सत्यापित करना कि प्रत्येक प्रोफाइल द्वारा उत्पन्न ब्राउज़र फिंगरप्रिंट वास्तव में स्वतंत्र है।
यह उदाहरण:
- कई स्वतंत्र प्रोफाइल बनाता है
- फिंगरप्रिंट परीक्षण स्थल पर जाता है: https://xfreetool.com/zh/fingerprint-checker
- प्रत्येक प्रोफाइल के फिंगरप्रिंट आईडी को निकालता और तुलना करता है
- फिंगरप्रिंट की स्वतंत्रता और यादृच्छिकता को सत्यापित करता है
यह साइट https://xfreetool.com/zh/fingerprint-checker एक वेबसाइट है जो ब्राउज़र फिंगरप्रिंट की जांच करती है और आगंतुक ब्राउज़र से फिंगरप्रिंट जानकारी को स्वचालित रूप से कैप्चर करती है।
उदाहरण कोड:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from "@scrapeless-ai/sdk";
// कॉन्फ़िगरेशन स्थिरांक
const MAX_PROFILES = 3; // आवश्यक प्रोफाइल की अधिकतम संख्या
// क्लाइंट आरंभ करें
const client = new ScrapelessClient();Sure! Here is the translation of the provided text into Hindi:
hi
* CreepJS पृष्ठ से ब्राउज़र फिंगरप्रिंट आईडी प्राप्त करें
* @param {Object} page - Puppeteer पृष्ठ वस्तु
* @returns {Promise<string>} ब्राउज़र फिंगरप्रिंट आईडी
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* एकल कार्य चलाएँ
* @param {string} profileId - प्रोफ़ाइल आईडी
* @param {number} taskId - कार्य आईडी
* @returns {Promise<string>} ब्राउज़र फिंगरप्रिंट आईडी
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'मेरा ब्राउज़र',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
const page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://xfreetool.com/zh/fingerprint-checker', {
waitUntil: 'networkidle0'
});
// कुकी जानकारी प्राप्त करें और प्रिंट करें
const cookies = await page.cookies();
console.log(`[${taskId}] कुकीज़:`);
cookies.forEach(cookie => {
// console.log(` नाम: ${cookie.name}, मान: ${cookie.value}, डोमेन: ${cookie.domain}`);
});
const fpId = await getFPId(page);
console.log(`[${taskId}] ✓ ब्राउज़र फिंगरप्रिंट आईडी = ${fpId}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* एक नई प्रोफ़ाइल बनाएं
* @returns {Promise<string>} हाल ही में बनाई गई प्रोफ़ाइल आईडी
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('मेरा प्रोफ़ाइल' + randomString());
console.log('प्रोफ़ाइल बनाई गई:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('प्रोफ़ाइल बनाने में विफल:', error);
throw error;
}
};
/**
* आवश्यक प्रोफाइल की सूची प्राप्त करें या बनाएं
* @param {number} count - आवश्यक प्रोफाइल की संख्या
* @returns {Promise<string[]>} प्रोफ़ाइल आईडी की सूची
*/
const getProfiles = async (count) => {
try {
// मौजूदा प्रोफाइल प्राप्त करें
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
// यदि मौजूदा प्रोफाइल पर्याप्त नहीं हैं तो नई प्रोफाइल बनाएं
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
// यदि पर्याप्त हैं तो पहले `गिनती` प्रोफाइल लौटाएं
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('प्रोफ़ाइल प्राप्त करने में विफल:', error);
throw error;
}
};
/**
* कार्यों को समांतर रूप से चलाएँ
*/
const runTasks = async () => {
try {
// आवश्यक प्रोफाइल प्राप्त करें या बनाएं
const profileIds = await getProfiles(MAX_PROFILES);
// प्रत्येक प्रोफ़ाइल के लिए कार्य बनाएं
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('सभी कार्य सफलतापूर्वक पूर्ण हुए');
} catch (error) {
console.error('कार्य चलाने में त्रुटि:', error);
}
};
// कार्यों को निष्पादित करें
await runTasks();परीक्षण परिणाम:
- 3 प्रोफाइल एक साथ चल रहे हैं, प्रत्येक वातावरण पूरी तरह से स्वतंत्र है।
- प्रत्येक प्रोफाइल के लिए ब्राउज़र फिंगरप्रिंट आईडी पूरी तरह से भिन्न है।
परिणामों की व्याख्या:
-
फिंगरप्रिंट की विशिष्टता
3 प्रोफाइल अलग-अलग फिंगरप्रिंट आईडी लौटाते हैं। हर बार जब एक प्रोफाइल बनाई जाती है, ब्राउज़र फिंगरप्रिंट यादृच्छिक रूप से उत्पन्न होता है, जिससे डुप्लिकेट फिंगरप्रिंट के कारण पहचान से बचा जाता है।
-
पर्यावरण अलगाव सत्यापन
प्रत्येक प्रोफाइल के लिए कुकीज़ पूरी तरह से स्वतंत्र हैं:- प्रोफाइल 1 से कुकीज़ प्रोफाइल 2 या 3 में नहीं दिखाई देती हैं।
- कई प्रोफाइल विभिन्न खातों में एक साथ लॉग इन कर सकते हैं बिना एक-दूसरे को प्रभावित किए।
केस 2: उच्च समांतरता और पर्यावरण अलगाव परीक्षण
लक्ष्य: उच्च समांतरता परिदृश्यों के तहत प्रोफाइल का पर्यावरण अलगाव सत्यापित करना, और प्रोफाइल को थोक में बनाने और प्रबंधित करने की क्षमता का परीक्षण करना।
कई मामलों में, डेटा स्क्रैपिंग की गति बढ़ाने या कई खातों में लॉग इन करने के लिए, उपकरणों को उच्च समवर्तीता और वातावरण का अलगाव समर्थन करने की आवश्यकता होती है—जो समानांतर में दर्जनों या सैकड़ों स्वतंत्र ब्राउज़र उदाहरणों के होने के बराबर है। Scrapeless मैन्युअल रूप से प्रोफाइल जोड़ने या API के माध्यम से प्रोफाइल संचालित करने का समर्थन करता है।
इस उदाहरण में:
- API के माध्यम से 10 स्वतंत्र प्रोफाइल बनाए जाते हैं
- प्रत्येक प्रोफाइल पहले https://abrahamjuliot.github.io/creepjs/ पर जाकर ब्राउज़र फिंगरप्रिंट ID प्राप्त करता है
- फिर https://minecraftpocket-servers.com/login/ पर जाकर एक स्क्रीनशॉट लेता है
- फिंगरप्रिंट स्वतंत्रता और वातावरण के अलगाव को सत्यापित करता है
उदाहरण कोड:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
// कॉन्फ़िगरेशन स्थिरांक
const MAX_PROFILES = 5; // आवश्यक प्रोफाइलों की अधिकतम संख्या
// क्लाइंट प्रारंभ करें
const client = new ScrapelessClient({});
/**
* CreepJS पृष्ठ से ब्राउज़र फिंगरप्रिंट ID प्राप्त करें
* @param {Object} page - Puppeteer पृष्ठ वस्तु
* @returns {Promise<string>} ब्राउज़र फिंगरप्रिंट ID
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* एकल कार्य चलाएं
* @param {string} profileId - प्रोफाइल ID
* @param {number} taskId - कार्य ID
* @returns {Promise<string>} ब्राउज़र फिंगरप्रिंट ID
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 30000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
// चरण 1: ब्राउज़र फिंगरप्रिंट प्राप्त करें
let page = await browser.newPage();
page.setDefaultTimeout(30000);
await page.goto('https://abrahamjuliot.github.io/creepjs/', {
waitUntil: 'networkidle0'
});
const fpId = await getFPId(page);
await page.close(); // पहले पृष्ठ को बंद करें
// चरण 2: स्क्रीनशॉट के लिए एक नया पृष्ठ उपयोग करें
page = await browser.newPage();
const screenshotPath = `fp_${taskId}_${fpId}.png`;
await page.goto('https://minecraftpocket-servers.com/login/', {
waitUntil: 'networkidle0'
});
await page.screenshot({
fullPage: true,
path: screenshotPath
});
console.log(`[${taskId}] ✓ फिंगरप्रिंट ID: ${fpId}, स्क्रीनशॉट बचाया गया: ${screenshotPath}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* एक नया प्रोफाइल बनाएं
* @returns {Promise<string>} नया बनाया गया प्रोफाइल ID
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('प्रोफाइल बनाई गई:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('प्रोफाइल बनाने में विफल:', error);
throw error;
}
};
/**
* आवश्यक प्रोफाइलों की सूची प्राप्त करें या बनाएं
* @param {number} count - आवश्यक प्रोफाइलों की संख्या
* @returns {Promise<string[]>} प्रोफाइल IDs की सूची
*/
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('प्रोफाइल प्राप्त करने में विफल:', error);
throw error;
}
};
/**
* कार्यों को समवर्ती रूप से चलाएं
*/
const runTasks = async () => {
try {
console.log(`कार्य प्रारंभ कर रहे हैं, ${MAX_PROFILES} प्रोफाइलों की आवश्यकता है`);
const profileIds = await getProfiles(MAX_PROFILES);
console.log(`प्राप्त किए गए ${profileIds.length} प्रोफाइल`);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
const results = await Promise.all(tasks);
console.log('सभी कार्य सफलतापूर्वक पूर्ण हो गए!');
console.log('फिंगरप्रिंट ID सूची:', results);
} catch (error) {
```javascript
console.error('कार्य चलाने में त्रुटि:', त्रुटि);
}
};
// कार्य निष्पादित करें
await runTasks();परीक्षण परिणाम:
- फिंगरप्रिंट स्वतंत्रता: फिंगरप्रिंट और पर्यावरण पैरामीटर यादृच्छिक रूप से उत्पन्न होते हैं और एक दूसरे से भिन्न होते हैं।
- पर्यावरण अलगाव: प्रत्येक कार्य एक स्वतंत्र प्रोफ़ाइल में चलता है; ब्राउज़र डेटा (कुकी, लोकलस्टोरेज, सत्र, आदि) साझा नहीं किया जाता है।
- समानांतर स्थिरता: 10 प्रोफाइल सफलतापूर्वक बनाए और एक साथ निष्पादित किए गए।
उदाहरण परिणाम व्याख्या:
- प्रोफ़ाइल निर्माण और कनेक्शन प्रक्रिया
आउटपुट प्रोफ़ाइल निर्माण और ब्राउज़र कनेक्शन प्रक्रिया को पूरी तरह से दिखाता है:
प्रोफ़ाइल बनाई गई: a27cd6f9-7937-4af0-a0fc-51b2d5c70308
प्रोफ़ाइल बनाई गई: d92b0cb1-5608-4753-92b0-b7125fb18775
...
जानकारी पुपेटियर: सफलतापूर्वक Scrapeless ब्राउज़र से जुड़ा {}
...
सभी कार्य सफलतापूर्वक पूर्णसभी 10 प्रोफाइलों को लगभग एक साथ Scrapeless Cloud Browser से जोड़ा गया, जो उच्च समानांतरता के तहत स्थिरता को प्रदर्शित करता है।
-
फिंगरप्रिंट स्वतंत्रता सत्यापन
प्रत्येक प्रोफ़ाइल पूरी तरह से भिन्न फिंगरप्रिंट आईडी लौटाती है।10 अद्वितीय फिंगरप्रिंट यह साबित करते हैं कि प्रत्येक प्रोफाइल का ब्राउज़र फिंगरप्रिंट स्वतंत्र और यादृच्छिक रूप से उत्पन्न होता है, जिसमें कोई डुप्लिकेट नहीं होता।
-
उच्च समानांतर निष्पादन स्थिरता
सभी 10 कार्य एक साथ चलाए जाते हैं, सफलतापूर्वक बिना किसी त्रुटि या संघर्ष के पूरा होते हैं। -
प्रोफाइल बनाने के लिए कई तरीके
Scrapeless कई तरीकों से प्रोफाइल बनाने और प्रबंधित करने की सुविधा प्रदान करता है:
- डैशबोर्ड मैनुअल निर्माण: जल्दी शुरू करने और व्यक्तिगत संचालन के लिए सीधे डैशबोर्ड से प्रोफाइल बनाएं।
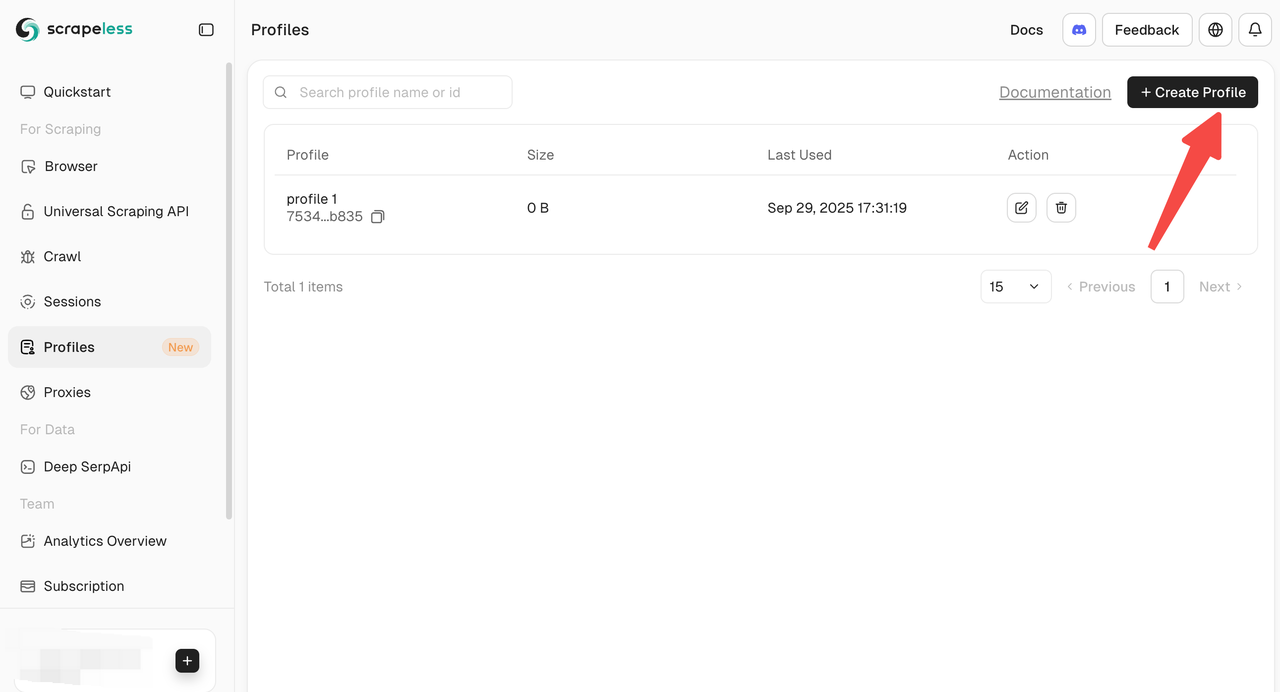
- API निर्माण: बैच संचालन के लिए प्रोफ़ाइल बनाएँ API के माध्यम से प्रोग्रामेटिक रूप से प्रोफाइल बनाएं।
- SDK निर्माण: उच्च समानांतरता या कस्टम स्वचालित कार्यप्रवाह के लिए उपयुक्त, आधिकारिक SDK का उपयोग करके प्रोफाइल बनाएं।
मामला 3: क्लाउडफ्लेयर चुनौती + गूगल reCAPTCHA – बिना मैनुअल हस्तक्षेप के पूरी तरह स्वचालित CAPTCHA बाईपास
लक्ष्य: परीक्षण करना कि क्या Scrapeless Cloud Browser स्वचालित रूप से साइटों पर जाने पर reCAPTCHA या क्लाउडफ्लेयर चुनौतियों का पता लगा सकता है और पास कर सकता है, और पुनरुत्पादन योग्य सत्यापन प्रक्रियाओं और परिणामों को रिकॉर्ड करना।
इस उदाहरण में:
- Amazon खोज पृष्ठ पर जाना https://www.amazon.com/s?k=toy (reCAPTCHA ट्रिगर होने की उच्च संभावना)
- स्वचालित रूप से CAPTCHA को संभालना और उत्पाद डेटा निकालना
- स्वचालित CAPTCHA हैंडलिंग क्षमता को सत्यापित करना
उदाहरण कोड:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
const client = new ScrapelessClient();
const MAX_PROFILES = 1; // आवश्यक प्रोफाइलों की अधिकतम संख्या
// CreepJS पृष्ठ से ब्राउज़र फिंगरप्रिंट आईडी प्राप्त करें
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector('#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div');
return fpContainer.textContent;
});
};
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'मेरा ब्राउज़र',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
let page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://www.amazon.com/s?k=toy&crid=37T7KZIWF16VC&sprefix=to%2Caps%2C351&ref=nb_sb_noss_2');
await page.waitForSelector('[role="listitem"]', { timeout: 15000 });
console.log('पृष्ठ सफलतापूर्वक लोड हुआ...');
const products = await page.evaluate(() => {
const items = [];
const productElements = document.querySelectorAll('[role="listitem"]');
productElements.forEach((product) => {
const titleElement = product.querySelector('[data-cy="title-recipe"] a h2 span');
const title = titleElement ? titleElement.textContent.trim() : 'N/A';
console.log(title);
const priceWhole = product.querySelector('.a-price-whole');
const priceFraction = product.querySelector('.a-price-fraction');
const price = priceWhole && priceFraction
? `$${priceWhole.textContent}${priceFraction.textContent}`
: 'N/A';
const ratingElement = product.querySelector('.a-icon-alt');
const rating = ratingElement ? ratingElement.textContent.split(' ')[0] : 'N/A';
const imageElement = product.querySelector('.s-image');
hi
const imageUrl = imageElement ? imageElement.src : 'N/A';
const asin = product.getAttribute('data-asin') || 'N/A';
items.push({
title,
price,
rating,
imageUrl,
asin
});
});
return items;
});
console.log(JSON.stringify(products, null, 2));
return products;
} finally {
await browser.close();
}
};
// एक नया प्रोफ़ाइल बनाएं
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('मेरा प्रोफ़ाइल' + randomString());
console.log('प्रोफ़ाइल बनाई गई:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('प्रोफ़ाइल बनाने में विफल:', error);
throw error;
}
};
// आवश्यक प्रोफाइल प्राप्त करें या बनाएं
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({ page: 1, pageSize: count });
const profiles = response?.docs;
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate).fill(0).map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [...profiles.map(p => p.profileId), ...newProfiles];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('प्रोफ़ाइल प्राप्त करने में विफल:', error);
throw error;
}
};
// कार्यों को समानांतर में चलाएं
const runTasks = async () => {
try {
const profileIds = await getProfiles(MAX_PROFILES);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('सभी कार्य सफलतापूर्वक पूरे हुए');
} catch (error) {
console.error('कार्य चलाने में त्रुटि:', error);
}
};
// कार्यों को निष्पादित करें
await runTasks();परीक्षण परिणाम:
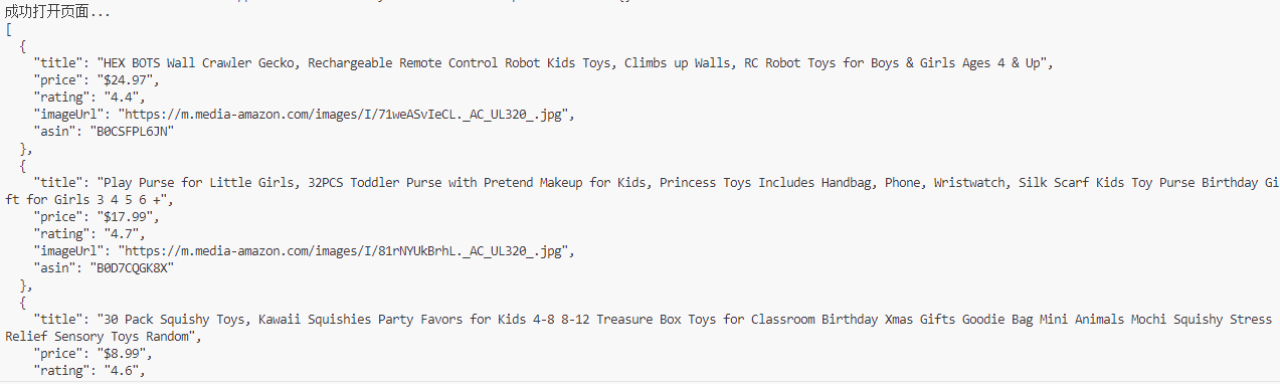
- अमेज़न खोज पृष्ठ ने स्वचालित रूप से ट्रिगर की गई reCAPTCHA को संभाला
- सफलतापूर्वक उत्पाद का शीर्षक, मूल्य, रेटिंग, छवि, ASIN और अन्य डेटा निकाला
- पूरे प्रक्रिया में कोई मानव हस्तक्षेप आवश्यक नहीं था; CAPTCHA को स्वचालित रूप से पहचाना और पारित किया गया
उदाहरण परिणाम व्याख्या:
- सफल reCAPTCHA बायपास और डेटा निकासी:
पृष्ठ सफलतापूर्वक लोड होता है, और उत्पाद डेटा निकाला जाता है:
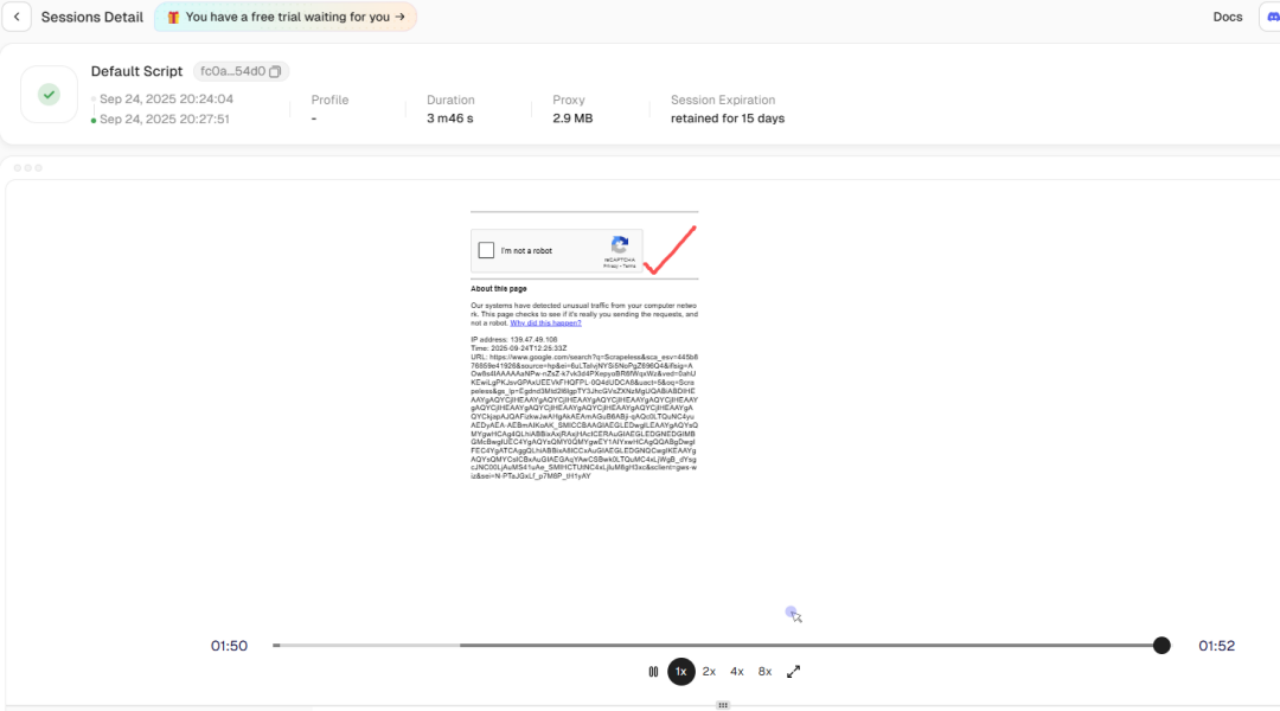
- स्वचालित CAPTCHA हैंडलिंग:
सत्र इतिहास प्लेबैक विशेषता का उपयोग करते हुए, आप देख सकते हैं कि डेटा स्क्रैपिंग के दौरान जोखिम सत्यापन को ट्रिगर किया गया, लेकिन Scrapeless ने आंतरिक रूप से reCAPTCHA को स्वचालित रूप से बायपास कर दिया। यह पृष्ठभूमि में अवरोधित डेटा स्क्रैपिंग की बाधा का समाधान करता है।
साधारणतः, अमेज़न खोज पृष्ठों पर जाना reCAPTCHA को ट्रिगर कर सकता है जो मैनुअल इंटरैक्शन की आवश्यकता होती है। Scrapeless क्लाउड ब्राउज़र के साथ:
- reCAPTCHA स्वचालित रूप से पहचाना जाता है
- अंतर्निहित एपीआई सत्यापन प्रवाह को स्वचालित रूप से पूरा करता है
- स्क्रिप्ट निष्पादन जारी रखती है और उत्पाद डेटा निकालती है
- क्लाउड अवलोकनशीलता:
Scrapeless पैनल प्रदान करता है:
- जीवित सत्र: स्क्रिप्ट निष्पादन को देखने के लिए ब्राउज़र उदाहरणों की वास्तविक समय में निगरानी
- सत्र इतिहास: डिबगिंग और CAPTCHA हैंडलिंग की समीक्षा के लिए पिछले सत्रों को पुनः चलाना
हालांकि ब्राउज़र क्लाउड में चल रहा है, यह स्थानीय डिबगिंग के समान अनुभव प्रदान करता है, जिससे क्लाउड ब्राउज़र डिबगिंग की कठिनाई को काफी कम किया जा रहा है।
सारांश
तीन व्यावहारिक परिदृश्यों से, हम Scrapeless क्लाउड ब्राउज़र के प्रदर्शन का मुख्य आयाम में सारांश प्राप्त कर सकते हैं:
- समानांतरता और वातावरण अलगाव
- प्रोफाइल बनाने और प्रबंधित करने का बैच समर्थन करता है
- प्रत्येक प्रोफ़ाइल का अंगूठा निशान, कुकीज़, कैश, और ब्राउज़र डेटा पूरी तरह से अलग होता है
- उदाहरणों में बिना संघर्ष या संसाधन प्रतिस्पर्धा के 10+ समवर्ती कार्यों का समर्थन करता है; हजारों समवर्ती कार्यों तक बढ़ने में सक्षम
- सैकड़ों या हजारों स्वतंत्र ब्राउज़र उदाहरणों की समानता है
- यादृच्छिक ब्राउज़र अंगूठे के निशान
- प्रत्येक प्रोफ़ाइल निर्माण यादृच्छिक रूप से मूल मापदंडों जैसे उपयोगकर्ता-एजेंट, समय क्षेत्र, भाषा, और स्क्रीन रिज़ॉल्यूशन को उत्पन्न करता है
- अंगूठे का निशान वास्तविक ब्राउज़र वातावरण की निकटता से अनुकरण करता है
- स्वचालित रूप से पहुंच के रूप में पहचाने जाने की संभावना को कम करता है
- बिल्ट-इन CAPTCHA ऑटोमेशन
- reCAPTCHA, Cloudflare टर्नस्टाइल/चुनौती, और अन्य CAPTCHA प्रकारों की स्वचालित पहचान का समर्थन करता है
- मानव हस्तक्षेप के बिना स्वचालित रूप से सत्यापन पूरा करता है
- क्लाउड ब्राउज़र अवलोकनशीलता
* **लाइव सत्र:** वास्तविक समय में ब्राउज़र निष्पादन की निगरानी करें
* **सत्रों का इतिहास:** डिबगिंग और सत्यापन के लिए पिछले सत्रों को दोहराएं
कई वातावरणों के पृथक्करण, उच्च समवर्तीता, और CAPTCHA बाइपास की आवश्यकता वाले स्वचालन परिदृश्यों के लिए, Scrapeless Cloud Browser एक मजबूत विकल्प है।
> क्या आप अपनी वेब स्वचालन को सुपरचार्ज करने के लिए तैयार हैं? [Scrapeless](https://app.scrapeless.com/passport/login?utm_source=wechat&utm_medium=official_account&utm_campaign=bee) Cloud Browser का आज़माएं और निर्बाध प्रोफ़ाइल प्रबंधन, स्वतंत्र फिंगरप्रिंट, और स्वचालित CAPTCHA हैंडलिंग का अनुभव करें—सभी क्लाउड में!
---
**अस्वीकृति:** किसी भी स्वचालन उपकरण का उपयोग लक्षित साइट की सेवा की शर्तों और संबंधित कानूनों के अनुरूप होना चाहिए। यह लेख तकनीकी अनुसंधान और सत्यापन उद्देश्यों के लिए केवल है।स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


