
TikTok से वीडियो जानकारी कैसे प्राप्त करें?
Expert Network Defense Engineer
TikTok एक प्रमुख सोशल मीडिया प्लेटफॉर्म है जिसका ट्रैफ़िक बहुत ज़्यादा है। ज़रा सोचिए कि TikTok कितना मूल्यवान डेटा प्रदान कर सकता है!
इस लेख में, हम समझाएंगे कि TikTok वीडियो की जानकारी कैसे स्क्रैप करनी है। इसके अतिरिक्त, हम TikTok के छिपे हुए API या एम्बेडेड JSON डेटासेट के माध्यम से इस डेटा को स्क्रैप करना दिखाएंगे। आइए शुरू करते हैं!
TikTok स्क्रैप क्यों करें?
TikTok में जबरदस्त सामाजिक जुड़ाव है, जिससे विभिन्न उपयोग के मामलों के लिए विभिन्न अंतर्दृष्टि प्राप्त करना संभव हो जाता है:
ट्रेंड विश्लेषण
TikTok पर ट्रेंड तेज़ी से बदलते हैं, जिससे उपयोगकर्ताओं की नवीनतम प्राथमिकताओं के साथ बने रहना चुनौतीपूर्ण हो जाता है। TikTok को स्क्रैप करने से इन ट्रेंड बदलावों और उनके प्रभाव को प्रभावी ढंग से कैप्चर किया जाता है, जिससे उपयोगकर्ता के हितों के अनुरूप बेहतर मार्केटिंग रणनीतियों की अनुमति मिलती है।
लीड जनरेशन
TikTok डेटा को स्क्रैप करने से व्यवसायों को मार्केटिंग के अवसरों और नए ग्राहकों की पहचान करने में मदद मिलती है। यह उन प्रभावशाली लोगों को इंगित करके प्राप्त किया जा सकता है जिनके अनुयायियों का जनसांख्यिकी प्रासंगिक व्यावसायिक क्षेत्रों से मेल खाता है।
सेंटीमेंट विश्लेषण
TikTok वेब स्क्रैपिंग टिप्पणियों से पाठ डेटा एकत्र करने के लिए एक उत्कृष्ट स्रोत के रूप में कार्य करता है, जिसका विश्लेषण सेंटीमेंट मॉडल के माध्यम से विशिष्ट विषयों पर राय एकत्र करने के लिए किया जा सकता है।
TikTok स्क्रैपिंग की चुनौतियाँ
TikTok स्क्रैपिंग, TikTok से सार्वजनिक रूप से उपलब्ध डेटा निकालने की प्रक्रिया को संदर्भित करता है। जबकि इसमें मैनुअल और स्वचालित दोनों गतिविधियाँ शामिल हो सकती हैं, यह आमतौर पर एक स्वचालित प्रक्रिया है जिसे वेब क्रॉलर या कस्टम स्क्रिप्ट द्वारा निष्पादित किया जाता है जो TikTok के API (एप्लिकेशन प्रोग्रामिंग इंटरफ़ेस) के साथ इंटरैक्ट करते हैं।
डेटा में विभिन्न प्रकार की जानकारी शामिल हो सकती है जैसे:
- उपयोगकर्ता प्रोफ़ाइल: TikTok उपयोगकर्ताओं के बारे में जानकारी, जिसमें प्रोफ़ाइल नाम, बायो और अनुयायी गणना शामिल हैं।
- जनसांख्यिकी: आयु, लिंग, स्थान और रुचियों जैसी उपयोगकर्ता विशेषताओं से संबंधित डेटा।
- वीडियो: उपयोगकर्ताओं द्वारा पोस्ट किए गए लघु वीडियो, जिसमें कैप्शन, लाइक्स, कमेंट, शेयर और व्यूज शामिल हैं।
- हैशटैग: TikTok सामग्री को वर्गीकृत करने के लिए उपयोग किए जाने वाले कीवर्ड या वाक्यांश।
- टिप्पणियाँ: उपयोगकर्ताओं द्वारा प्रस्तुत पाठ प्रतिक्रियाएँ, जिसमें पाठ सामग्री, टाइमस्टैम्प और लाइक की गणना शामिल है।
- जुड़ाव मीट्रिक: उपयोगकर्ता सामग्री (लाइक्स, कमेंट, शेयर, व्यूज) के साथ कैसे इंटरैक्ट करते हैं, इस पर जानकारी।
- ट्रेंड: TikTok पर लोकप्रिय विषयों, थीम या शैलियों के बारे में डेटा।
अपना TikTok स्क्रैपर कैसे बनाएँ?
आइए चीजों को सरल करें! अब हम औपचारिक रूप से TikTok वीडियो डेटा को स्क्रैप करने की चरण-दर-चरण प्रक्रिया शुरू करते हैं। TikTok द्वारा प्रदान किए जाने वाले जबरदस्त मूल्य का अनुभव करने का समय आ गया है!
वास्तविक स्क्रैपिंग प्रक्रिया शुरू करने से पहले, आइए पहले मिलकर TikTok की वीडियो सामग्री संरचना की जांच करें। यह हमें आवश्यक जानकारी का अधिक कुशलतापूर्वक पता लगाने और डेटा निष्कर्षण को अधिक सरल तरीके से पूरा करने में सक्षम करेगा।
वीडियो से हम कौन सा डेटा स्क्रैप कर सकते हैं?
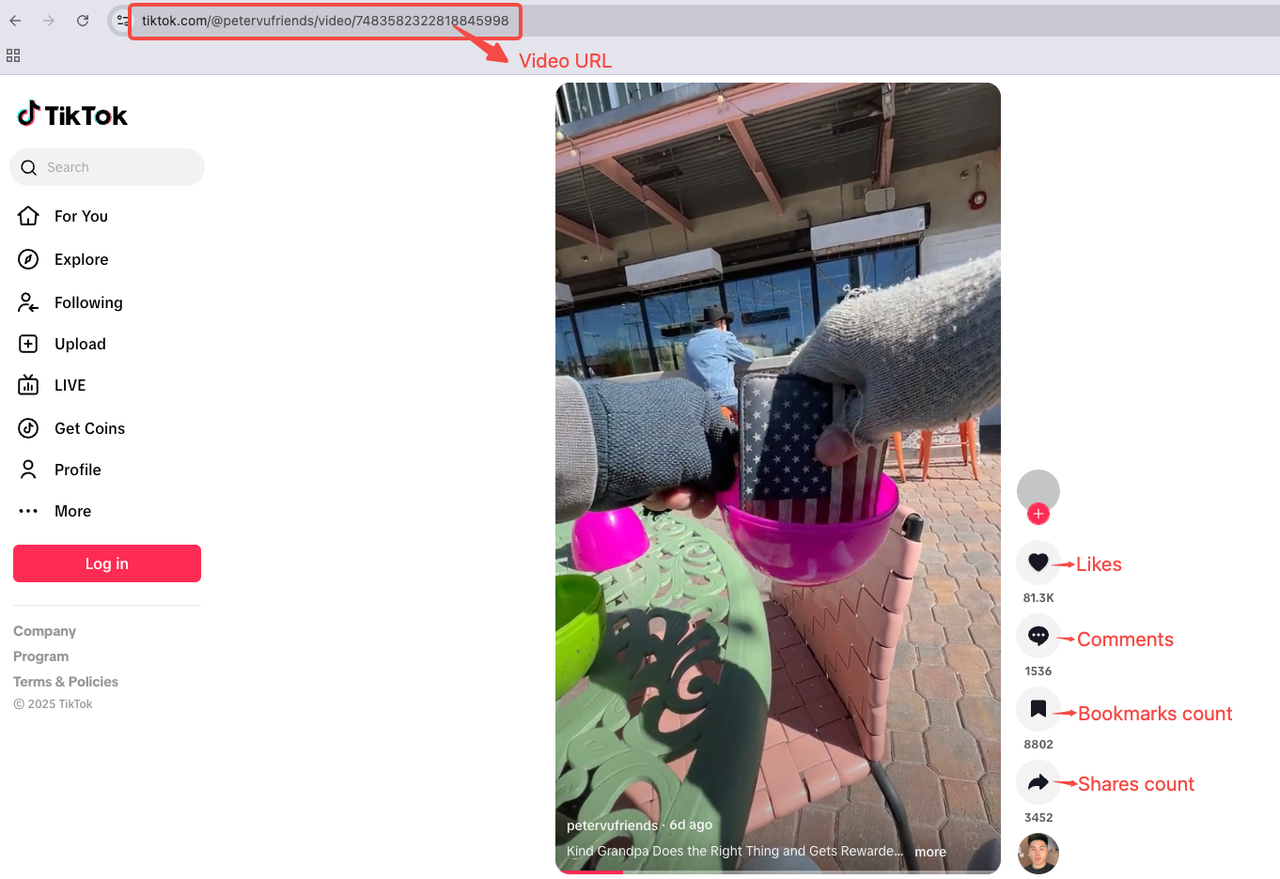
- वीडियो URL
- वीडियो विवरण
- संगीत का नाम
- रिलीज़ की तारीख
- टैग
- दृश्य
- लाइक्स की गणना
- टिप्पणियों की गणना
- शेयरों की गणना
- बुकमार्क की गणना
वीडियो पृष्ठ विश्लेषण
डेटा स्क्रैपिंग को अधिक सहज बनाने के लिए, हम संदर्भ के रूप में निम्नलिखित वीडियो का विश्लेषण करेंगे: https://www.tiktok.com/@petervufriends/video/7476546872253893934।
हम वेबसाइट की गोपनीयता की दृढ़ता से रक्षा करते हैं। इस ब्लॉग में सभी डेटा सार्वजनिक हैं और केवल क्रॉलिंग प्रक्रिया के प्रदर्शन के रूप में उपयोग किए जाते हैं। हम कोई भी जानकारी और डेटा सहेजते नहीं हैं।
हमें जिस डेटा की आवश्यकता है उसे कैसे ढूंढें?
आइए HTML संरचना में गहराई से उतरें! यहाँ हमें इस वीडियो से निकालने की आवश्यकता है:
व्यू काउंट
व्यू काउंट आमतौर पर वीडियो पेज पर प्रमुख रूप से प्रदर्शित होता है। बस डेवलपर टूल खोलें और प्रासंगिक टैग का पता लगाएँ:
Python
<strong data-e2e="video-views" class="video-count css-dirst9-StrongVideoCount e148ts222">281.4K</strong>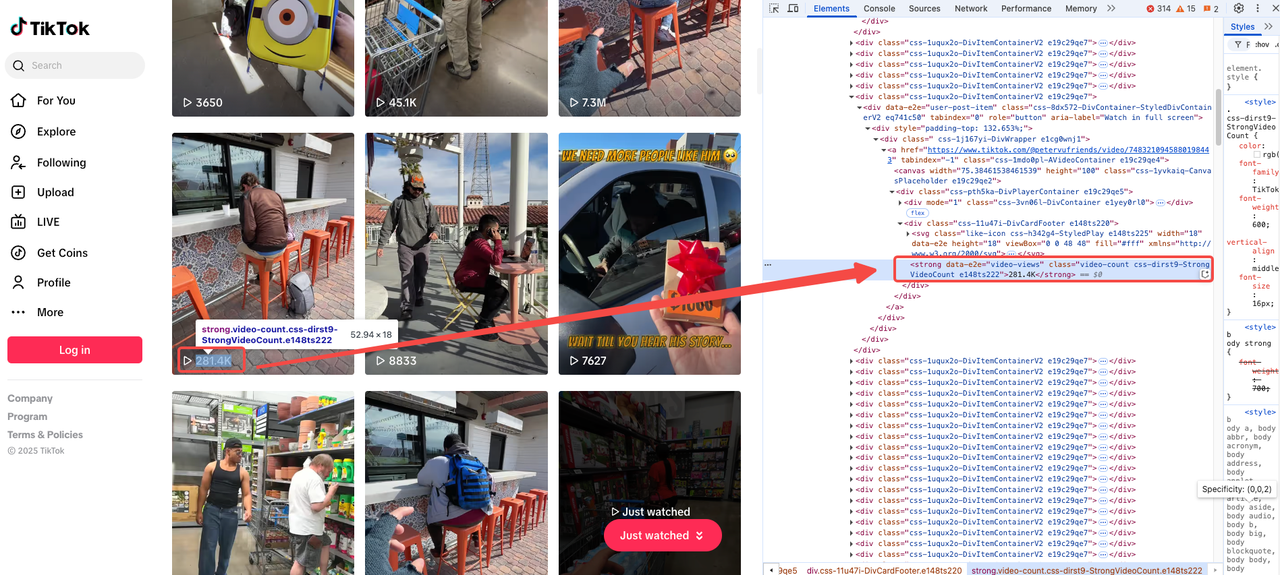
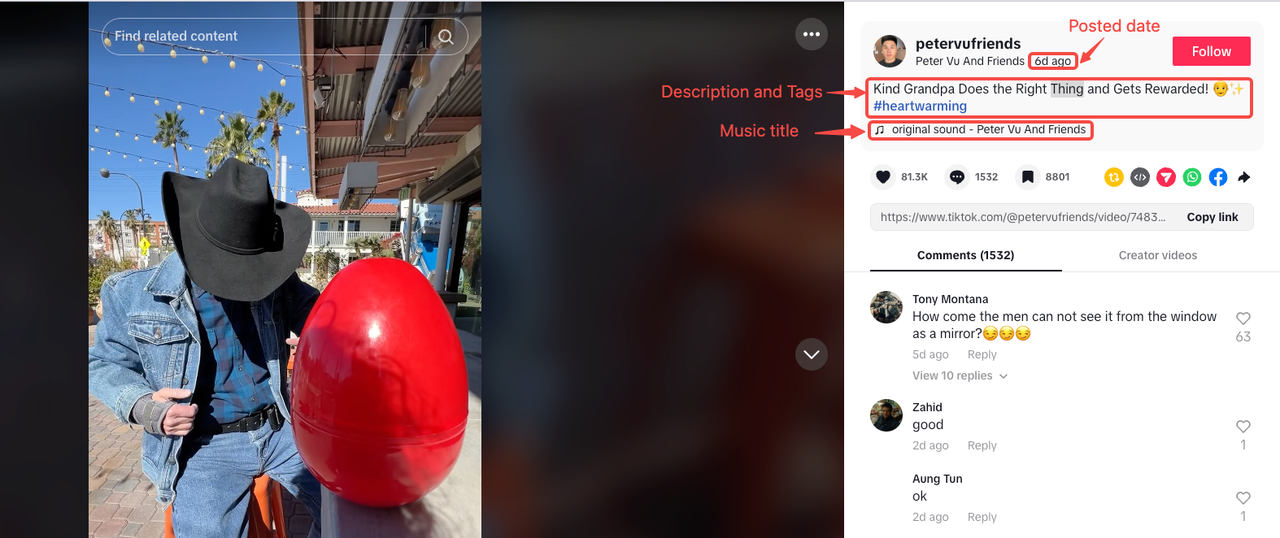
वीडियो विवरण और टैग
जैसा कि हमने शुरू में देखा, वीडियो विवरण और टैग आमतौर पर एक ही खंड में दिखाई देते हैं। हालाँकि, कुछ वीडियो में विवरण या टैग नहीं हो सकते हैं।
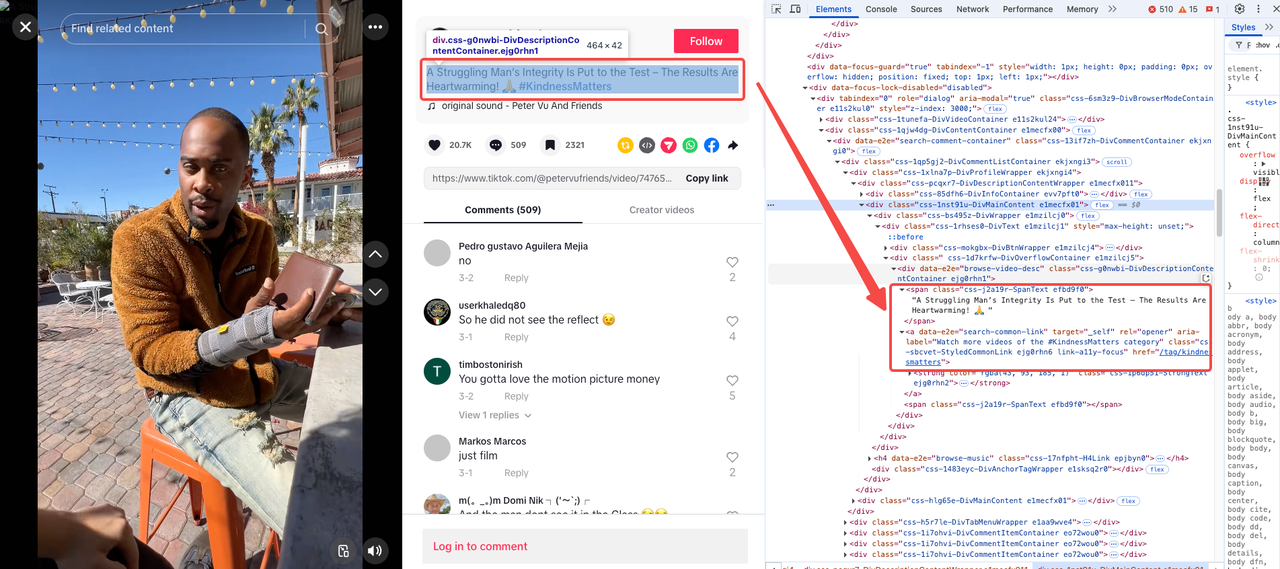
- वीडियो विवरण एक
<span>के अंदर है जिसमें एक अनूठी कक्षा है:css-j2a19r-SpanText। - वीडियो टैग अलग हैं लेकिन एक ही विशेषता साझा करते हैं:
data-e2e="search-common-link"।
संगीत शीर्षक
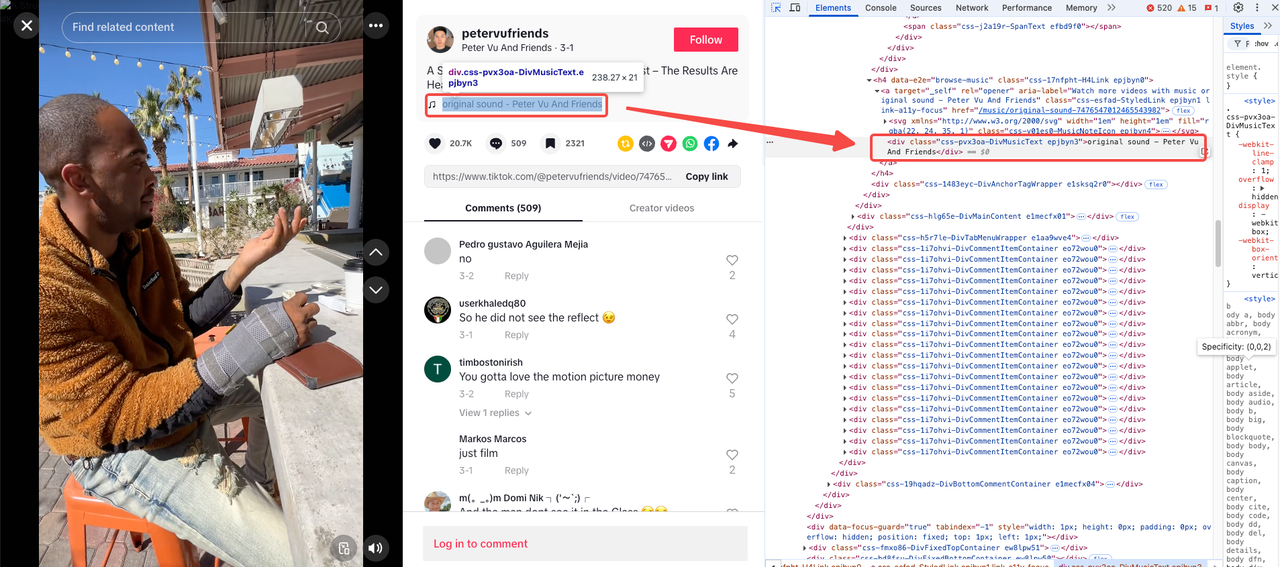
अपलोड तिथि
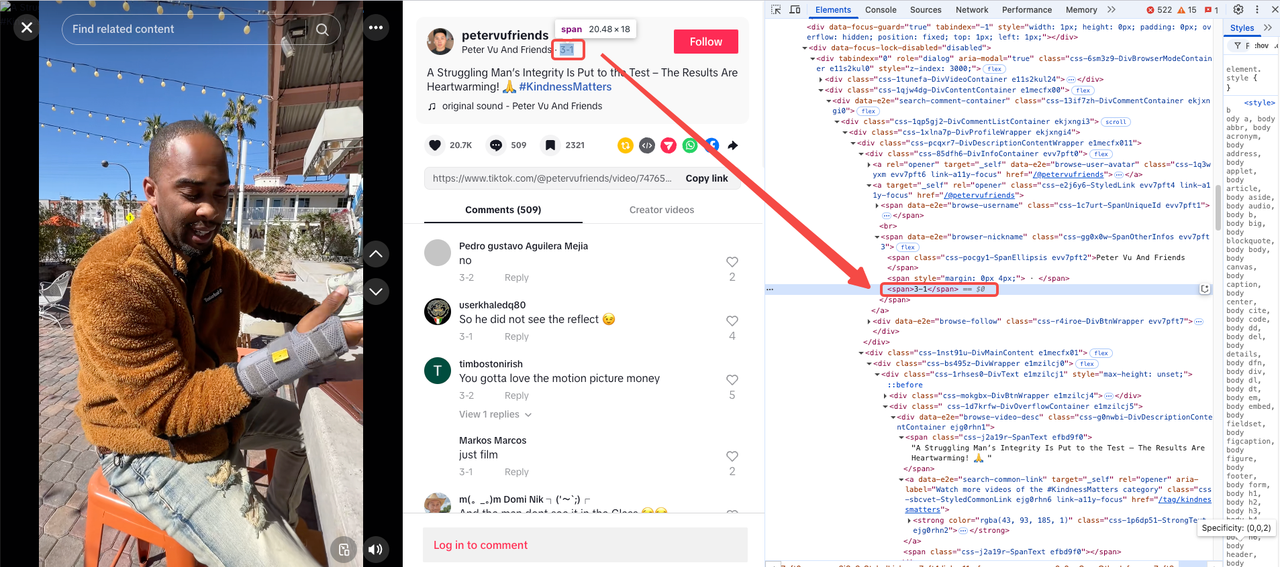
तिथि को एक पैरेंट तत्व के भीतर अंतिम <span> के रूप में अलग किया गया है जिसमें विशेषता है: data-e2e="browser-nickname"।
लाइक, कमेंट और बुकमार्क काउंट
ये मीट्रिक आमतौर पर एक साथ दिखाई देते हैं, और आप उन्हें एक ही संग्रह के तहत पा सकते हैं:
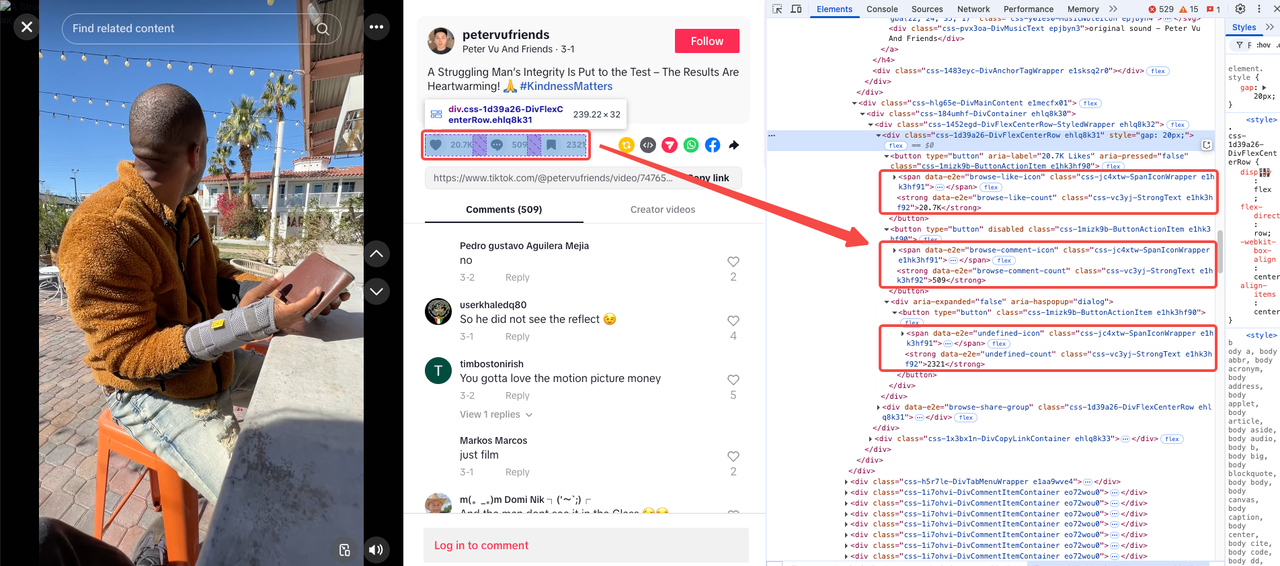
अपनी स्क्रैपिंग प्रक्रिया को सरल बनाने के लिए, यहाँ आवश्यक चयनकर्ताओं का सारांश दिया गया है:
- वीडियो URL:
<meta property="og:url"> - वीडियो विवरण:
['span.css-j2a19r-SpanText'] - संगीत शीर्षक:
['.css-pvx3oa-DivMusicText'] - अपलोड तिथि:
['span[data-e2e="browser-nickname"] span:last-child'] - टैग:
[data-e2e="search-common-link"] - व्यू काउंट:
[data-e2e="video-views"] - लाइक काउंट:
[data-e2e="like-count"] - कमेंट काउंट:
[data-e2e="comment-count"] - शेयर काउंट:
[data-e2e="share-count"] - बुकमार्क काउंट:
[data-e2e="undefined-count"]
बधाई हो! अब आप पूरी तरह से समझ गए हैं कि आवश्यक डेटा का पता कैसे लगाया जाए। इसके बाद, आइए आधिकारिक तौर पर स्क्रैपर बनाएँ!
पूर्ण स्क्रैपिंग कोड
अनावश्यक स्पष्टीकरणों को छोड़कर—यहाँ तत्काल कार्यान्वयन के लिए तैयार स्क्रैपिंग कोड है:
Python
from playwright.async_api import async_playwright
import asyncio, random, json, logging, time, os, yt_dlp
from urllib.parse import urlparse
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('tiktok_scraper.log'),
logging.StreamHandler()
]
)
class TikTokScraper:
def __init__(self):
self.DOWNLOAD_VIDEO = True
self.SAVE_DIR = "downloaded_videos"
self.USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
self.VIEWPORT = {'width': 1280, 'height': 720}
self.TIMEOUT = 300 # 5 minute timeout
async def random_sleep(self, min_seconds=1, max_seconds=3):
"""Random Delay"""
delay = random.uniform(min_seconds, max_seconds)
logging.info(f"Sleeping for {delay:.2f} seconds...")
await asyncio.sleep(delay)
async def handle_captcha(self, page):
"""Handling verification codes"""
try:
captcha_dialog = page.locator('div[role="dialog"]')
if await captcha_dialog.count() > 0 and await captcha_dialog.is_visible():
logging.warning("CAPTCHA detected. Please solve it manually.")
await page.wait_for_selector('div[role="dialog"]', state='detached', timeout=self.TIMEOUT*1000)
logging.info("CAPTCHA solved. Resuming...")
await self.random_sleep(0.5, 1)
except Exception as e:
logging.error(f"Error handling CAPTCHA: {str(e)}")
async def extract_video_info(self, page, video_url):
"""Extract video details"""
logging.info(f"Extracting info from: {video_url}")
try:
await page.goto(video_url, wait_until="networkidle")
await self.random_sleep(2, 4)
await self.handle_captcha(page)
# Waiting for key elements to load
await page.wait_for_selector('[data-e2e="like-count"]', timeout=10000)
video_info = await page.evaluate("""() => {
const getTextContent = (selectors) => {
for (let selector of selectors) {
const element = document.querySelector(selector);
if (element && element.textContent.trim()) {
return element.textContent.trim();
}
}
return 'N/A';
};
const getTags = () => {
const tagElements = document.querySelectorAll('a[data-e2e="search-common-link"]');
return Array.from(tagElements).map(el => el.textContent.trim());
};
return {
likes: getTextContent(['[data-e2e="like-count"]', '[data-e2e="browse-like-count"]']),
comments: getTextContent(['[data-e2e="comment-count"]', '[data-e2e="browse-comment-count"]']),
shares: getTextContent(['[data-e2e="share-count"]']),
bookmarks: getTextContent(['[data-e2e="undefined-count"]']),
views: getTextContent(['[data-e2e="video-views"]']),
description: getTextContent(['span.css-j2a19r-SpanText']),
musicTitle: getTextContent(['.css-pvx3oa-DivMusicText']),
date: getTextContent(['span[data-e2e="browser-nickname"] span:last-child']),
author: getTextContent(['a[data-e2e="browser-username"]']),
tags: getTags(),
videoUrl: window.location.href
};
}""")
logging.info(f"Successfully extracted info for: {video_url}")
return video_info
except Exception as e:
logging.error(f"Failed to extract info from {video_url}: {str(e)}")
return None
def download_video(self, video_url):
"""Download Video"""
if not os.path.exists(self.SAVE_DIR):
os.makedirs(self.SAVE_DIR)
ydl_opts = {
'outtmpl': os.path.join(self.SAVE_DIR, '%(id)s.%(ext)s'),
'format': 'best',
'quiet': False,
'no_warnings': False,
'ignoreerrors': True
}
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(video_url, download=True)
filename = ydl.prepare_filename(info)
logging.info(f"Video successfully downloaded: {filename}")
return filename
except Exception as e:
logging.error(f"Error downloading video: {str(e)}")
return None
async def scrape_single_video(self, video_url):
"""Scrape the single short"""
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
viewport=self.VIEWPORT,
user_agent=self.USER_AGENT,
)
page = await context.new_page()
result = {}
try:
# Extract shorts information
video_info = await self.extract_video_info(page, video_url)
if not video_info:
raise Exception("Failed to extract video info")
result.update(video_info)
# Download TikTok shorts
if self.DOWNLOAD_VIDEO:
filename = self.download_video(video_url)
if filename:
result['local_path'] = filename
except Exception as e:
logging.error(f"Error scraping video: {str(e)}")
finally:
await browser.close()
return result
def save_results(self, data, filename="tiktok_video_data.json"):
"""Save the results to a JSON file"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
logging.info(f"Results saved to {filename}")
async def main():
# Initialize the crawler
scraper = TikTokScraper()
# Target TikTok short's URL
video_url = "https://www.tiktok.com/@petervufriends/video/7476546872253893934" # Just as an reference
# scrape the short
video_data = await scraper.scrape_single_video(video_url)
# save the scraping result
if video_data:
scraper.save_results(video_data)
logging.info("\nScraping completed. Results:")
for key, value in video_data.items():
logging.info(f"{key}: {value}")
else:
logging.error("Failed to scrape video data")
if __name__ == "__main__":
asyncio.run(main())स्क्रैपिंग परिणाम
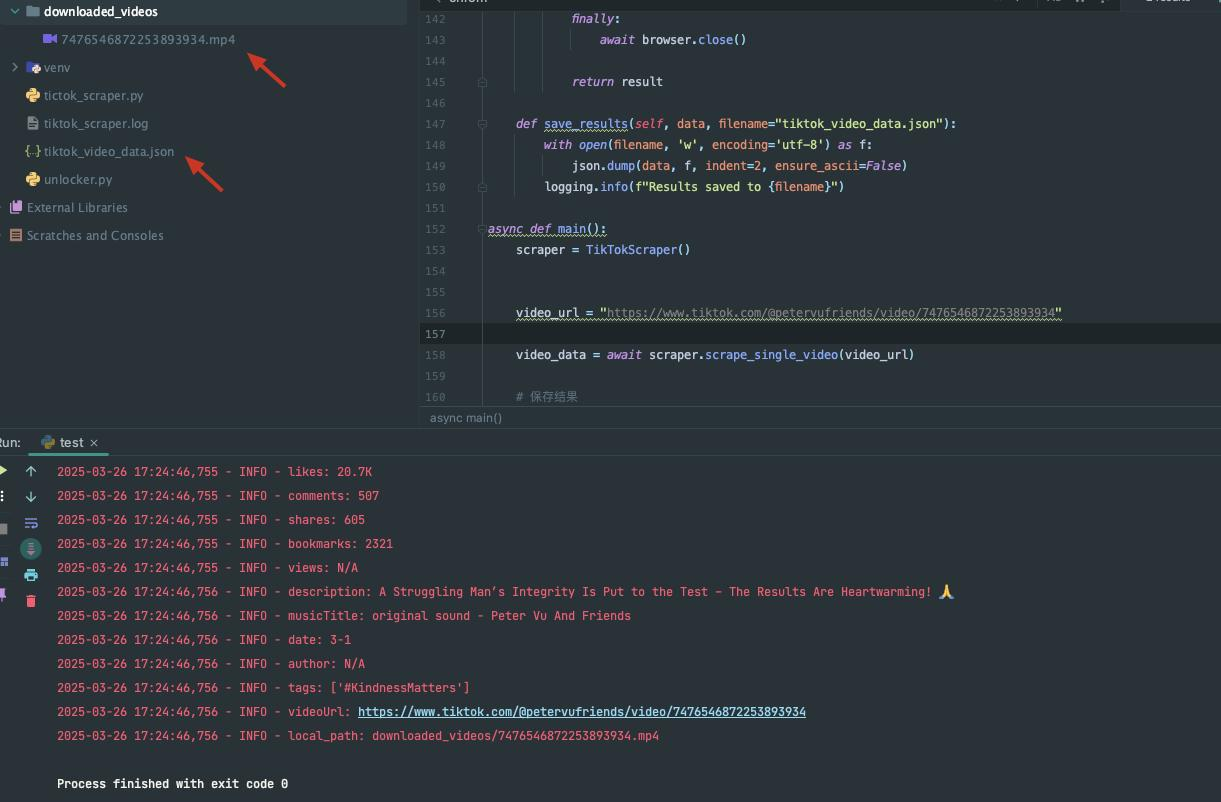
ज़ाहिर है, हमें जटिल प्रोग्रामिंग और उपायों की आवश्यकता है: देरी निर्धारित करें, CAPTCHA को बायपास करें, आदि डेटा क्रॉलिंग प्राप्त करने के लिए। तो TikTok डेटा को जल्दी से कैसे प्राप्त करें? शक्तिशाली तीसरे पक्ष का स्क्रैपिंग API आपका सबसे अच्छा विकल्प है!
स्क्रैपिंग API: आसानी से TikTok डेटा एकत्र करें
Walmart उत्पाद विवरण प्राप्त करने के लिए API का उपयोग क्यों करें?
1. बेहतर दक्षता
उत्पाद डेटा के लिए मैनुअल खोज धीमी और त्रुटिपूर्ण है। API Walmart उत्पाद जानकारी की स्वचालित पुनर्प्राप्ति की अनुमति देता है, जिससे तेज़ और सुसंगत डेटा संग्रह सुनिश्चित होता है।
2. सटीक, वास्तविक समय डेटा
Scrapeless API Walmart उत्पाद पृष्ठों से सीधे डेटा निकालता है, यह सुनिश्चित करता है कि पुनर्प्राप्त जानकारी अद्यतित और सटीक है। यह विलंबित मैनुअल प्रविष्टि या पुराने स्रोतों के कारण होने वाली त्रुटियों को रोकता है।
3. विभिन्न व्यावसायिक परिदृश्यों पर लागू होता है
- मूल्य निगरानी: प्रतियोगी कीमतों की तुलना करें और मूल्य निर्धारण रणनीतियों को समायोजित करें।
- इन्वेंट्री ट्रैकिंग: आपूर्ति श्रृंखला प्रबंधन को अनुकूलित करने के लिए उत्पाद उपलब्धता की जाँच करें।
- समीक्षा विश्लेषण: उत्पादों और सेवाओं को बेहतर बनाने के लिए ग्राहक प्रतिक्रिया का विश्लेषण करें।
- बाजार अनुसंधान: लोकप्रिय उत्पादों की पहचान करें और सूचित व्यावसायिक निर्णय लें।
TikTok स्क्रैपर क्या करता है?
यह TikTok डेटा स्क्रैपर एक शक्तिशाली अनौपचारिक TikTok API है जो आपको आपकी अपनी डेटा परियोजनाओं, व्यावसायिक रिपोर्टों और नए अनुप्रयोगों के आधार के रूप में बड़े पैमाने पर TikTok डेटा प्रदान करता है। इस सर्वश्रेष्ठ TikTok स्क्रैपर के साथ, आप प्राप्त कर सकते हैं:
- विवरण सहित चयनित हैशटैग के सभी परिणाम: लोकप्रिय वीडियो, टाइमस्टैम्प, व्यूज, शेयर, टिप्पणियाँ और वीडियो की संख्या आदि।
- विवरण सहित चयनित उपयोगकर्ता प्रोफ़ाइल से सभी पोस्ट: नाम, उपनाम, ID, बायो, अनुयायी/अनुसरण, प्ले, शेयर और टिप्पणियाँ आदि।
- विशिष्ट वीडियो URL वाले व्यक्तिगत वीडियो पोस्ट।
- वीडियो और संगीत संबंधी डेटा।
API का उपयोग करके TikTok डेटा स्क्रैप करना
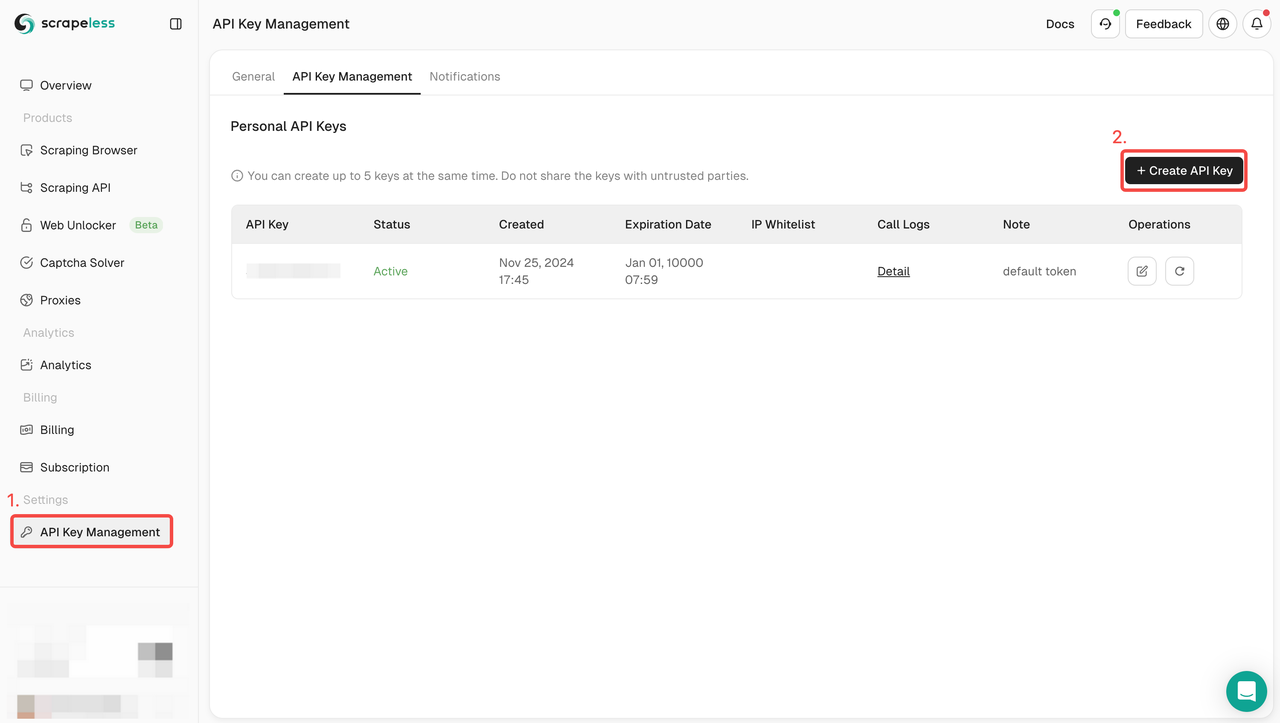
चरण 1. अपना API टोकन बनाएँ
आरंभ करने के लिए, आपको Scrapeless डैशबोर्ड से अपनी API कुंजी प्राप्त करने की आवश्यकता होगी:
- Scrapeless डैशबोर्ड में लॉग इन करें।
- API कुंजी प्रबंधन पर जाएँ।
- अपनी अनूठी API कुंजी उत्पन्न करने के लिए बनाएँ पर क्लिक करें।
- एक बार बनाए जाने के बाद, इसे कॉपी करने के लिए बस API कुंजी पर क्लिक करें।
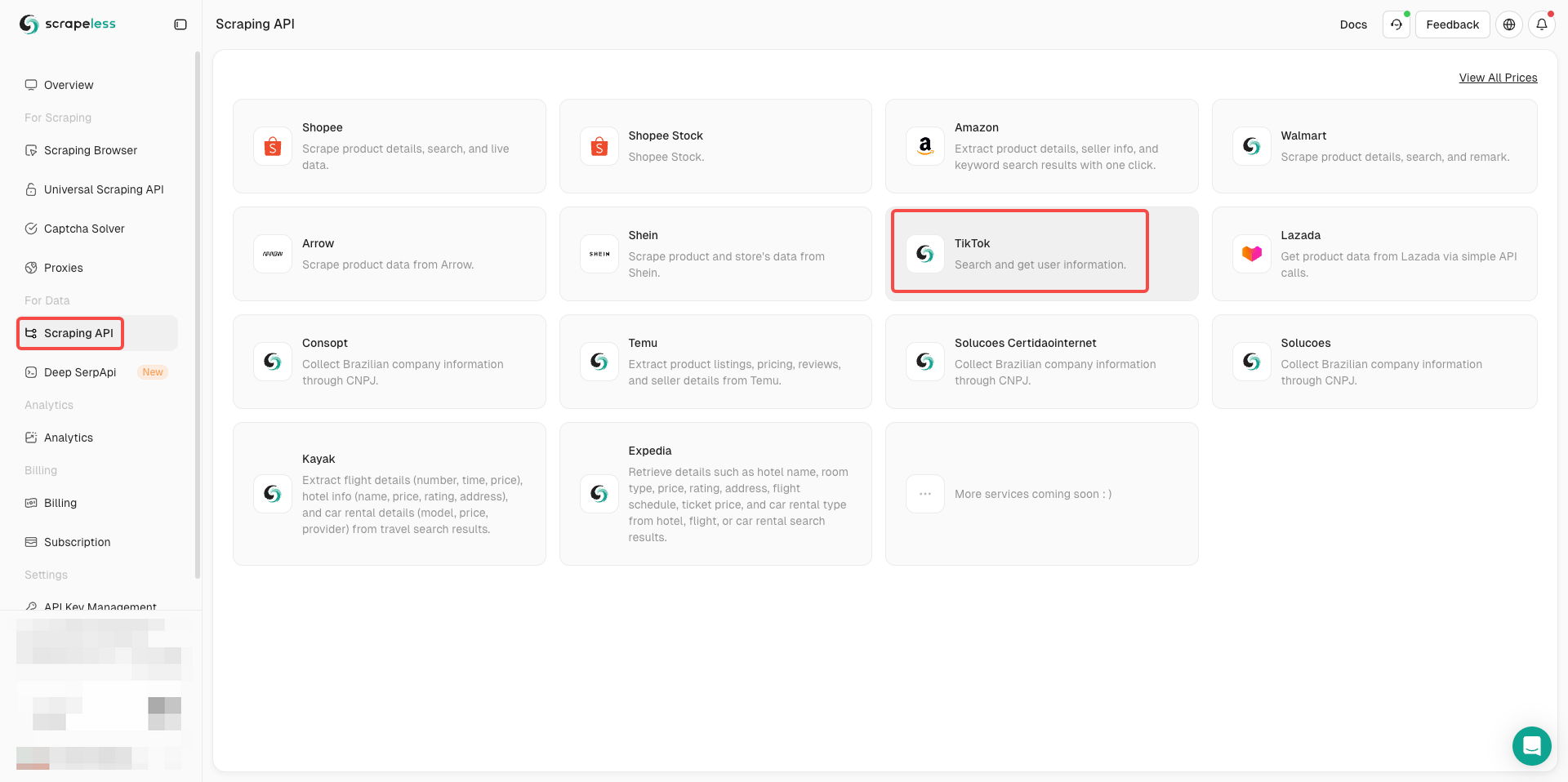
चरण 2. TikTok API दर्ज करें
- डेटा के लिए के अंतर्गत स्क्रैपिंग API पर क्लिक करें
- TikTok ढूंढें और दर्ज करें
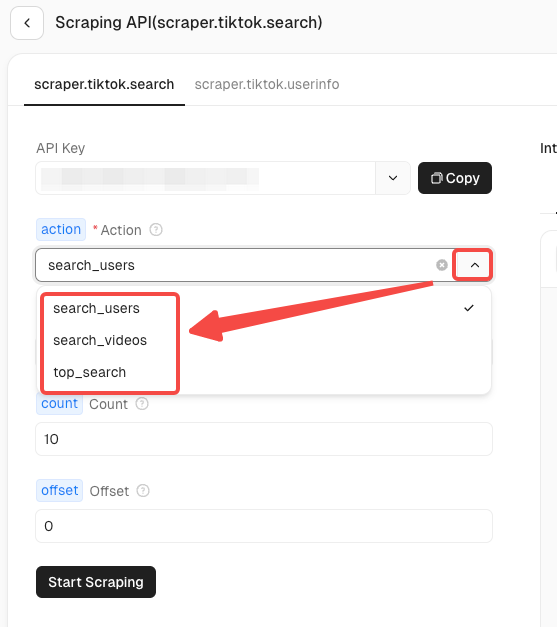
चरण 3. अनुरोध पैरामीटर कॉन्फ़िगरेशन
TikTok अभिनेता में वर्तमान में दो स्क्रैपिंग परिदृश्य हैं:
- TikTok खोज जानकारी: विशिष्ट कीवर्ड के लिए वीडियो खोज परिणाम स्क्रैप करें।
- TikTok उपयोगकर्ता जानकारी: किसी निर्दिष्ट उपयोगकर्ता की प्रोफ़ाइल जानकारी स्क्रैप करें।
प्रत्येक परिदृश्य में अलग-अलग क्रिया अनुरोध होंगे। आप सटीक रूप से स्क्रैप करने के लिए आवश्यक डेटा जानकारी खोजने के लिए तह तीर पर क्लिक कर सकते हैं। उदाहरण के लिए TikTok खोज जानकारी लें:
क्या आप तैयार हैं? बुनियादी जानकारी को समझने के बाद, हम आधिकारिक तौर पर डेटा स्क्रैप करना शुरू कर सकते हैं!
- अब आपको अपनी आवश्यकताओं के अनुसार अभिनेता के बाईं ओर पैरामीटर कॉन्फ़िगरेशन को पूरा करने की आवश्यकता है
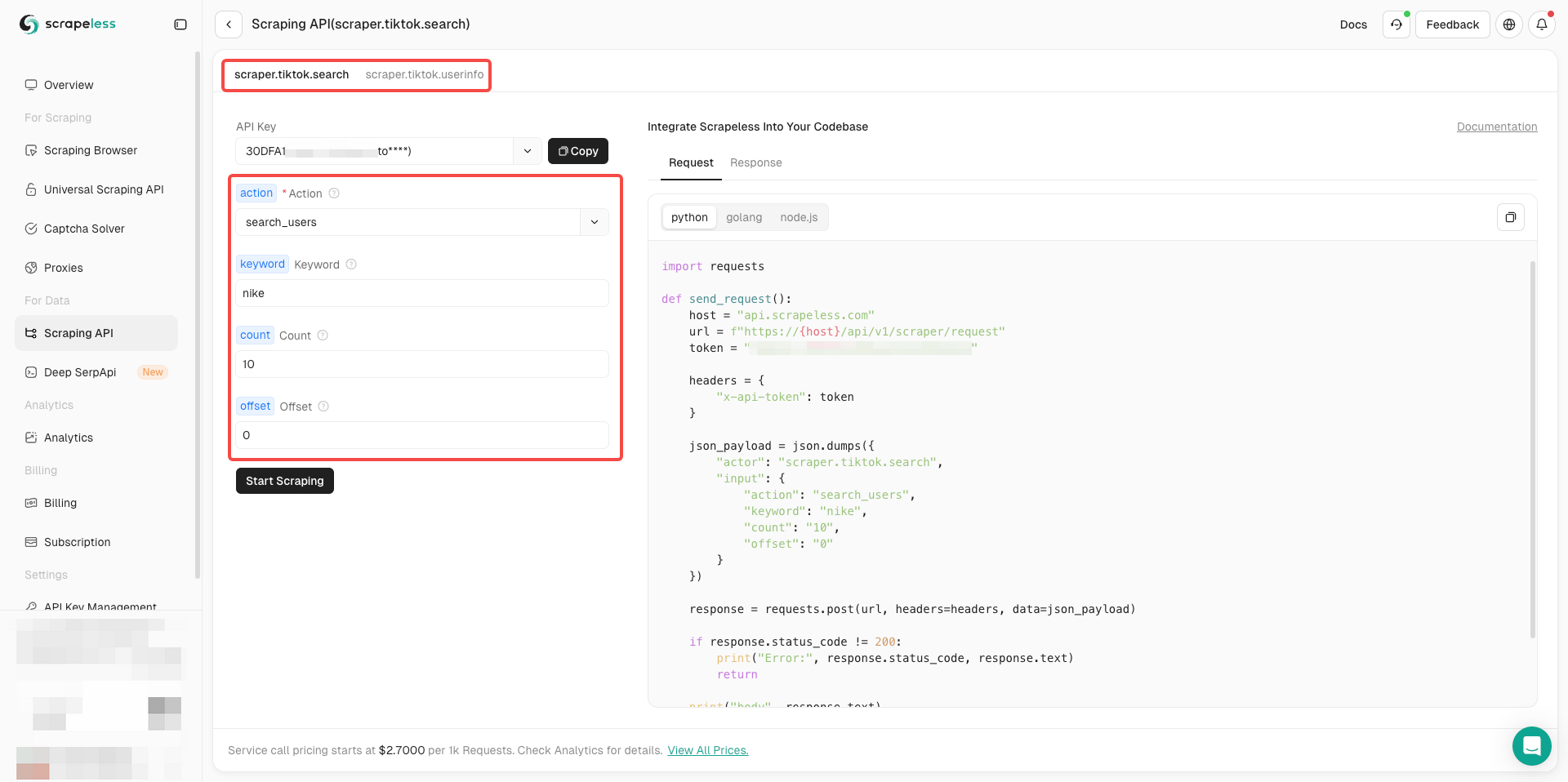
- यह पुष्टि करने के बाद कि सब कुछ सही है, स्क्रैपिंग परिणाम आसानी से प्राप्त करने के लिए बस स्टार स्क्रैपिंग पर क्लिक करें।
अभी TikTok वीडियो डेटा प्राप्त करें!
अब से, आपके पास एक कार्यशील स्क्रैपर होना चाहिए जो TikTok से डेटा निकाल सकता है। यह एक शानदार शुरुआत है, लेकिन आप निश्चित रूप से आगे बढ़ सकते हैं।
चाहे आप TikTok रुझानों का विश्लेषण कर रहे हों, शोध कर रहे हों, या अपनी डेटा जिज्ञासा को पूरा कर रहे हों, अब आपके पास कई सिरदर्द के बिना TikTok डेटा वेयरहाउस का पता लगाने के लिए शक्तिशाली उपकरण हैं।
Scrapeless स्क्रैपिंग API आपको जटिल कोड की परेशानी से बचाता है। नवीनतम डेटा तुरंत प्राप्त करने के लिए बस कुछ पैरामीटर कॉन्फ़िगर करें।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


