
Instagram प्रोफ़ाइल डेटा को जल्दी से कैसे स्क्रैप करें?
Specialist in Anti-Bot Strategies
Instagram दुनिया भर में लाखों उपयोगकर्ताओं के साथ सबसे लोकप्रिय सोशल मीडिया प्लेटफॉर्म में से एक है। Instagram प्रोफ़ाइल को स्क्रैप करना व्यवसायों, डेवलपर्स, मार्केटिंग विश्लेषण, प्रतियोगिता अनुसंधान या व्यक्तिगत डेटा प्रबंधन के लिए डेटा विश्लेषण विशेषज्ञों की मदद करने के लिए फायदेमंद है।
इस लेख में, हम आपको Instagram प्रोफ़ाइल को स्क्रैप करने की प्रक्रिया को गहराई से दिखाएंगे। हम बताएंगे कि Instagram प्रोफ़ाइल और पोस्ट पेज से डेटा निकालने के लिए Instagram स्क्रैपर कैसे बनाया जाए।
सुविधाजनक स्क्रैपिंग API का उपयोग करके Ins डेटा को जल्दी से स्क्रैप करना सीखने का समय आ गया है।
- #विधि 1। अपना पायथन इंस्टाग्राम प्रोफ़ाइल स्क्रैपर बनाएँ
- #विधि 2। स्क्रैपिंग API का उपयोग करके आसानी से डेटा एकत्र करें
Instagram प्रोफ़ाइल क्यों स्क्रैप करें?
Instagram का सार्वजनिक डेटा विशाल है और सभी प्रकार की अंतर्दृष्टि प्रदान कर सकता है। प्रोफ़ाइल डेटा को स्क्रैप करने से आपको दुनिया भर के लोकप्रिय उपयोगकर्ताओं के बारे में मूल्यवान जानकारी मिल सकती है, जिससे आप रुझानों की भविष्यवाणी करने, ब्रांड जागरूकता को ट्रैक करने, अपने Instagram प्रदर्शन को बेहतर बनाने के तरीके को समझने या समान रुचियों वाले लोकप्रिय Instagram प्रोफ़ाइल से जुड़कर व्यवसायों को नए ग्राहकों तक पहुँचने और उन तक पहुँचने में मदद कर सकते हैं।
इसके अतिरिक्त, स्क्रैप किया गया Instagram डेटा भावना विश्लेषण अध्ययनों के लिए एक व्यवहार्य संसाधन है। यह डेटा पोस्ट और टिप्पणियों में पाया जा सकता है और विशिष्ट रुझानों और समाचारों पर सार्वजनिक राय एकत्र करने के लिए उपयोग किया जा सकता है।
विधि 1. पायथन इंस्टाग्राम प्रोफ़ाइल स्क्रैपर
आइए Instagram उपयोगकर्ता प्रोफ़ाइल को स्क्रैप करके शुरुआत करें! इसके बाद, हम विस्तार से बताएंगे कि Instagram उपयोगकर्ता ladygaga की प्रोफ़ाइल जानकारी को कैसे स्क्रैप किया जाए। हम नीचे दिए गए चरणों का पालन करके इसे कर सकते हैं:
हम वेबसाइट की गोपनीयता की दृढ़ता से रक्षा करते हैं। इस ब्लॉग में सभी डेटा सार्वजनिक हैं और केवल क्रॉलिंग प्रक्रिया के प्रदर्शन के रूप में उपयोग किए जाते हैं। हम कोई भी जानकारी और डेटा सहेजते नहीं हैं।
चरण 1. लक्ष्य पृष्ठ का विश्लेषण करें
- लक्ष्य URL पर जाएँ: https://www.instagram.com/ladygaga/।
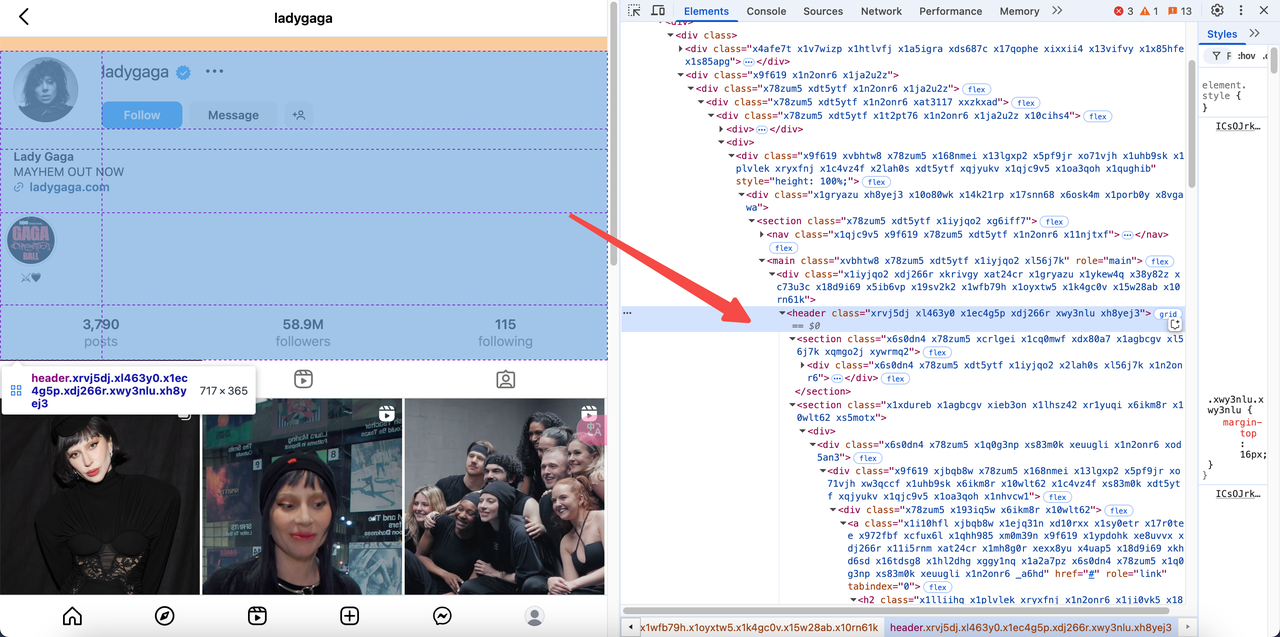
- एम्बेडेड JSON डेटा का पता लगाने के लिए पृष्ठ स्रोत कोड का निरीक्षण करें:
- Instagram उपयोगकर्ता जानकारी को
scriptटैग मेंwindow._sharedDataप्रारूप के साथ एम्बेड करता है। - हम HTML को पार्स करके इस डेटा को निकाल सकते हैं।
चरण 2. आवश्यक पुस्तकालय स्थापित करें
निम्नलिखित पायथन पुस्तकालयों के स्थापित होने का सुनिश्चित करें:
pip install requests beautifulsoup4
चरण 3. अनुरोध शीर्षलेख सेट करें
ब्राउज़र पहुँच का अनुकरण करने के लिए, एंटी-स्क्रैपिंग तंत्र द्वारा अवरुद्ध होने से बचने के लिए User-Agent और Referer शीर्षलेख सेट करें।
Python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}चरण 4. JSON डेटा पार्स करें
हमें HTML में script टैग से window._sharedData सामग्री निकालने और इसे पायथन डिक्शनरी में बदलने की आवश्यकता है।
Python
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON डेटा पृष्ठ में नहीं मिला।")
return None
# JSON डेटा पार्स करें
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: JSON डेटा पार्स करने में विफल।")
return Noneचरण 5. आवश्यक फ़ील्ड निकालें
पार्स किए गए JSON डेटा से उपयोगकर्ता नाम, जैव, अनुयायी गणना, पोस्ट गणना और अन्य प्रासंगिक जानकारी प्राप्त करें।
पूर्ण कोड
नीचे पूर्ण पायथन कोड दिया गया है, जिसका उपयोग आप सीधे लेडी गागा की प्रोफ़ाइल जानकारी को स्क्रैप करने के लिए कर सकते हैं:
Python
import requests
from bs4 import BeautifulSoup
import json
def scrape_instagram_profile(username):
url = f"https://www.instagram.com/ladygaga/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"Error: {username} के लिए डेटा प्राप्त करने में असमर्थ। स्थिति कोड: {response.status_code}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON डेटा पृष्ठ में नहीं मिला।")
return None
# JSON डेटा पार्स करें
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: JSON डेटा पार्स करने में विफल।")
return None
profile = {
"username": data["author"]["name"],
"bio": data["description"],
"follower_count": data["author"]["interactionStatistic"][0]["userInteractionCount"],
"post_count": data["author"]["interactionStatistic"][1]["userInteractionCount"]
}
return profile
# उदाहरण उपयोग
if __name__ == "__main__":
username = "ladygaga"
profile_data = scrape_instagram_profile(username)
if profile_data:
print("Instagram प्रोफ़ाइल डेटा:")
print(json.dumps(profile_data, indent=4, ensure_ascii=False))स्क्रैपिंग परिणाम
कोड चलाने के बाद, profile_data आउटपुट में निम्नलिखित फ़ील्ड शामिल होंगे:
JSON
{
"username": "ladygaga",
"bio": "Lady Gaga MAYHEM OUT NOW",
"follower_count": "58.9M",
"post_count": "3,790"
}विधि 2. स्क्रैपलेस स्क्रैपिंग API (सिफारिश)
Instagram को स्क्रैप करना बहुत आसान है। हालाँकि, Instagram अपने सार्वजनिक डेटा तक पहुँच के बारे में बेहद प्रतिबंधात्मक है। यह केवल गैर-लॉग इन उपयोगकर्ताओं के लिए प्रति दिन कुछ अनुरोधों की अनुमति देता है, जिससे परे यह अनुरोधों को लॉगिन पृष्ठ पर पुनर्निर्देशित करता है।
Instagram स्क्रेपर को अवरुद्ध करने से कैसे बचें? स्क्रैपलेस आपका आदर्श स्क्रैपिंग उपकरण है!
स्क्रैपलेस बड़े पैमाने पर डेटा संग्रह के लिए वेब स्क्रैपिंग, वेब अनब्लॉकिंग और डेटा निष्कर्षण API प्रदान करता है।
- एंटी-बॉट सुरक्षा बाईपास: वेब को स्क्रैप करते समय अवरुद्ध होने से बचें!
- घूर्णन आवासीय प्रॉक्सी: IP प्रतिबंध और भू-अवरुद्धता को रोकें।
- जावास्क्रिप्ट रेंडरिंग: क्लाउड ब्राउज़र के माध्यम से गतिशील वेब पेज स्क्रैप करें।
- पायथन और टाइपस्क्रिप्ट SDKs, साथ ही स्क्रैपी एकीकरण।
क्या यह Instagram स्क्रैपिंग API मुफ़्त है?
हाँ। स्क्रैपलेस आपको $2 का मुफ़्त क्रेडिट प्रदान करता है। आप मुफ़्त क्रेडिट का दावा करने के लिए सीधे साइन अप कर सकते हैं। Instagram प्रोफ़ाइल स्क्रैपर के साथ, आप आसानी से उपयोगकर्ता जानकारी मुफ़्त में एकत्र कर सकते हैं!
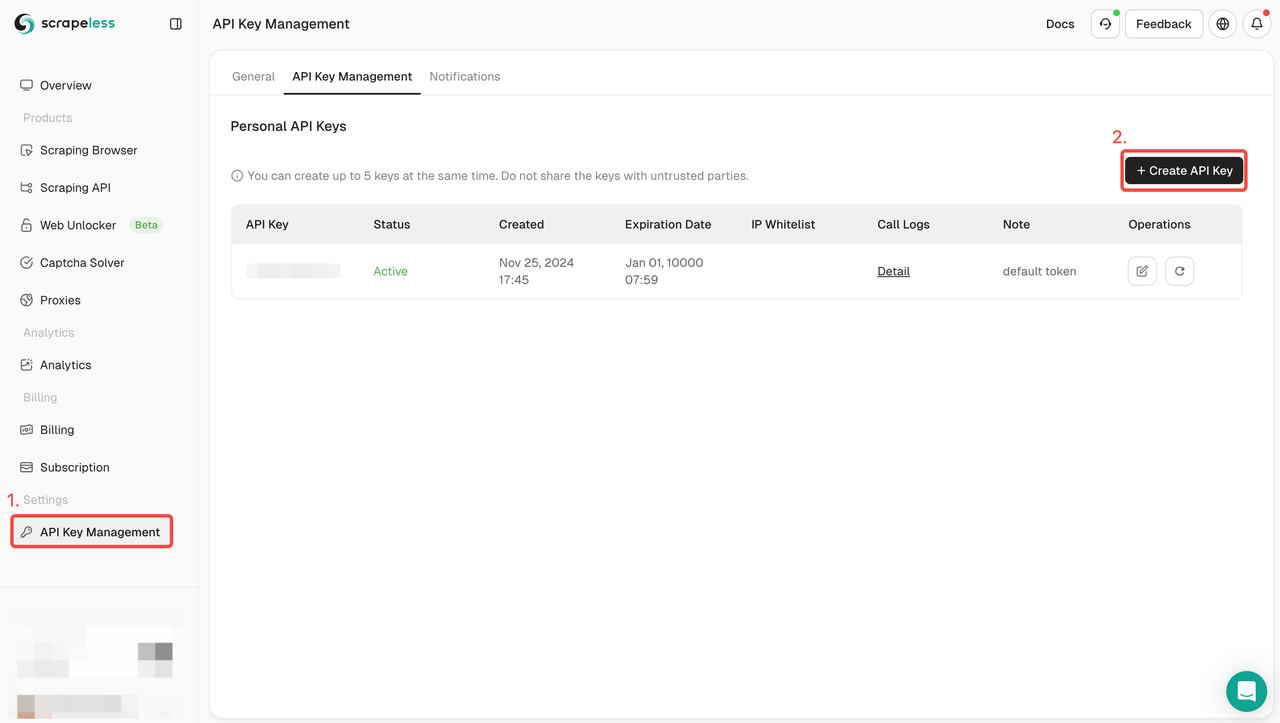
चरण 1. अपना API टोकन बनाएँ
आरंभ करने के लिए, आपको स्क्रैपलेस डैशबोर्ड से अपनी API कुंजी प्राप्त करने की आवश्यकता होगी:
- स्क्रैपलेस डैशबोर्ड में लॉग इन करें।
- API कुंजी प्रबंधन पर जाएँ।
- अपनी विशिष्ट API कुंजी उत्पन्न करने के लिए बनाएँ पर क्लिक करें।
- एक बार बनाए जाने पर, इसे कॉपी करने के लिए बस API कुंजी पर क्लिक करें।
निचली पंक्तियाँ
इस ट्यूटोरियल में, हमने Instagram प्रोफ़ाइल डेटा प्राप्त करने के 2 कुशल तरीके पेश किए। हमने दिखाया कि कैसे प्रमाणीकरण को संभालना है, अनुरोध करना है, प्रतिक्रियाओं को संभालना है और बेहतर स्थिरता और सुरक्षा के लिए प्रॉक्सी IP को एकीकृत करना है।
इस गाइड का पालन करके, आप गोपनीयता बनाए रखते हुए और दर सीमा जैसी समस्याओं से बचते हुए व्यक्तिगत या व्यावसायिक उपयोग के लिए आसानी से Instagram प्रोफ़ाइल डेटा निकालना शुरू कर सकते हैं।
डेटा संग्रह की दक्षता में सुधार करने के लिए, हम अनुशंसा करते हैं कि आप उन्नत स्क्रैपिंग API का उपयोग करें, जिसके लिए डेटा निष्कर्षण को पूरा करने के लिए केवल सरल कॉन्फ़िगरेशन पैरामीटर की आवश्यकता होती है!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


