
Google Scholar के परिणाम कैसे स्क्रैप करें
Advanced Data Extraction Specialist
Google Scholar विश्वभर के शैक्षणिक शोधकर्ताओं के लिए साहित्य खोजने और प्राप्त करने का एक महत्वपूर्ण उपकरण है, जिसमें विभिन्न क्षेत्रों में पत्र, मोनोग्राफ और सम्मेलन पत्र शामिल हैं। हालाँकि, इसके सख्त एंटी-क्रॉलर तंत्र के कारण, Google Scholar डेटा को सीधे क्रॉल करना आसान नहीं है, खासकर उन उपयोगकर्ताओं के लिए जिन्हें बड़े पैमाने पर डेटा संग्रह की आवश्यकता होती है।
इस लेख में, हम Google Scholar डेटा क्रॉल करने के दो तरीकों का परिचय देंगे: मैनुअल क्रॉलिंग (स्क्रैपी/सेलेनियम) और स्क्रैपलेस एपीआई। मैनुअल क्रॉलिंग छोटे पैमाने पर डेटा संग्रह के लिए उपयुक्त है, लेकिन इसमें आईपी प्रतिबंध और सत्यापन कोड की समस्याएँ आ सकती हैं। स्क्रैपलेस एपीआई एक अधिक स्थिर और कुशल समाधान प्रदान करता है, खासकर बड़े पैमाने पर डेटा क्रॉलिंग के लिए, अतिरिक्त एंटी-डिटेक्शन रणनीतियों को बनाए रखने की आवश्यकता के बिना।
दोनों विधियों के लाभों और नुकसानों की तुलना करके, यह लेख आपको कुशल डेटा संग्रह प्राप्त करने के लिए सबसे उपयुक्त समाधान चुनने में मदद करेगा।
Google Scholar को स्क्रैप क्यों करें?
Google Scholar मूल्यवान शैक्षणिक संसाधन प्रदान करता है, जिसमें शोध पत्र, उद्धरण, लेखक प्रोफ़ाइल और बहुत कुछ शामिल हैं। Google Scholar को स्क्रैप करके, आप कर सकते हैं:
- किसी विशिष्ट विषय पर शोध पत्र एकत्र करें।
- शैक्षणिक प्रभाव विश्लेषण के लिए उद्धरण गणना निकालें।
- लेखक प्रोफ़ाइल और उनके प्रकाशित कार्य प्राप्त करें।
- शोध उद्देश्यों के लिए साहित्य समीक्षा स्वचालित करें।
Google Scholar को स्क्रैप करने में चुनौतियाँ
Google Scholar को स्क्रैप करने में CAPTCHA, IP ब्लॉकिंग और गतिशील सामग्री जैसी चुनौतियाँ आती हैं।
इन चुनौतियों को दूर करने के लिए, हम स्क्रैपलेस एपीआई जैसे समर्पित एपीआई का उपयोग करने की सलाह देते हैं।
विधि 1: Google Scholar को कैसे स्क्रैप करें - पारंपरिक वेब स्क्रैपिंग (सिफारिश नहीं की गई)
Google के प्रतिबंधों के कारण Python (जैसे, BeautifulSoup, Selenium) का उपयोग करके Google Scholar को मैन्युअल रूप से वेब स्क्रैप करना मुश्किल है। अनुरोधों का उपयोग करके उदाहरण:
import requests
from bs4 import BeautifulSoup
url = "https://scholar.google.com/scholar?q=machine+learning"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all("div", class_="gs_r")
for result in results:
title = result.find("h3").text if result.find("h3") else "No Title"
print(title)📌 नुकसान:
- Google के एंटी-क्रॉलिंग तंत्र को ट्रिगर करना आसान है, जिसके परिणामस्वरूप IP ब्लॉकिंग या CAPTCHA का सामना करना पड़ सकता है।
- डेटा संरचना जटिल है, और HTML को पार्स करना और गतिशील रूप से लोड की गई सामग्री को संसाधित करना आवश्यक है।
- यह बड़े पैमाने पर डेटा संग्रह के लिए उपयुक्त नहीं है और इसकी स्थिरता कम है।
Google के एंटी-बॉट उपायों के कारण यह दृष्टिकोण विश्वसनीय नहीं है। इसके बजाय, स्क्रैपलेस एपीआई जैसे एपीआई का उपयोग करना सबसे अच्छा विकल्प है।
विधि 2: स्क्रैपलेस स्क्रैपिंग एपीआई के साथ Google Scholar स्क्रैपिंग (सिफारिश की गई)
स्क्रैपलेस का Google Scholar एपीआई शैक्षणिक अनुसंधान और डेटा विश्लेषण के लिए डिज़ाइन किया गया एक उपकरण है। यह स्वचालित रूप से Google Scholar खोज परिणामों को क्रॉल करके पेपर शीर्षक, लेखक, प्रकाशन तिथियां और उद्धरण गणना जैसी महत्वपूर्ण जानकारी प्राप्त कर सकता है। यह संरचित JSON डेटा प्रदान करने, IP ब्लॉकिंग और सत्यापन कोड सत्यापन से बचने और उपयोगकर्ताओं को जटिल क्रॉलर विकास से निपटने से बचाने के लिए Google Scholar के SERP (सर्च इंजन रिजल्ट पेज) को पार्स करता है।
इसके अलावा, Scrapeless वास्तविक समय खोज, बैच क्वेरी और कस्टम पैरामीटर फ़िल्टरिंग का भी समर्थन करता है, जो शोधकर्ताओं, डेवलपर्स और डेटा विश्लेषकों के लिए उपयुक्त है।
स्क्रैपलेस के Google Scholar एपीआई की प्रमुख विशेषताएँ
- स्वचालित पार्सिंग: मैन्युअल रूप से क्रॉलर लिखने की आवश्यकता नहीं है, सीधे संरचित JSON डेटा प्राप्त करें।
- वास्तविक समय डेटा: यह सुनिश्चित करने के लिए कि प्राप्त Google Scholar परिणाम नवीनतम हैं, वास्तविक समय प्रश्नों का समर्थन करें।
- एंटी-क्रॉलिंग तंत्र: प्रॉक्सी या अतिरिक्त कॉन्फ़िगरेशन की आवश्यकता के बिना, स्वचालित रूप से Google Scholar के CAPTCHA और IP ब्लॉकिंग को बायपास करें।
- समृद्ध डेटा फ़ील्ड: पेपर शीर्षक, लेखक, प्रकाशन तिथि, उद्धरणों की संख्या, जर्नल जानकारी, संबंधित पत्र आदि जैसे विस्तृत डेटा प्रदान करें।
- बैच क्वेरी का समर्थन करें: क्रॉलिंग दक्षता में सुधार के लिए आप एक साथ कई कीवर्ड के लिए खोज परिणाम प्राप्त कर सकते हैं।
- कस्टम खोज पैरामीटर: समय, भाषा, दस्तावेज़ प्रकार आदि द्वारा डेटा फ़िल्टरिंग का समर्थन करें, और लक्षित जानकारी का सटीक पता लगाएँ।
- स्थिर API पहुँच: क्लाउड आर्किटेक्चर पर आधारित, यह उच्च समवर्ती पहुँच के दौरान स्थिरता और विश्वसनीयता सुनिश्चित करता है।
मुफ़्त साइन अप करें और अभी Google खोज परिणाम स्क्रैप करना शुरू करें!
अपने प्रोजेक्ट और विश्लेषण में मदद करने के लिए Google खोज इंजन से डेटा को आसानी से स्क्रैप करने के लिए मुफ़्त परीक्षण अवसर प्राप्त करने के लिए अभी Scrapeless में लॉग इन करें। शक्तिशाली API फ़ंक्शन आपको सटीक खोज जानकारी प्राप्त करने और दक्षता में सुधार करने में मदद कर सकते हैं। आइए इसे अनुभव करें!
📌 स्क्रैपलेस एपीआई की मुख्य विशेषताएँ:
| एपीआई | फ़ंक्शन | उपयोग केस |
|---|---|---|
| लेखक एपीआई | विद्वान जानकारी प्राप्त करता है (H-इंडेक्स, पत्रों की संख्या, आदि) | विद्वान प्रभाव विश्लेषण |
| उद्धृत करें एपीआई | पेपर उद्धरण स्वरूप प्राप्त करता है (BibTeX, APA, आदि) | पेपर प्रबंधन |
| ऑर्गेनिक परिणाम एपीआई | Google Scholar खोज परिणाम प्राप्त करता है | शैक्षणिक अनुसंधान |
| प्रोफ़ाइल एपीआई | विद्वान प्रोफ़ाइल डेटा प्राप्त करता है | सहयोगी अनुसंधान विश्लेषण |
स्क्रैपलेस Google Scholar API का उपयोग कैसे करें
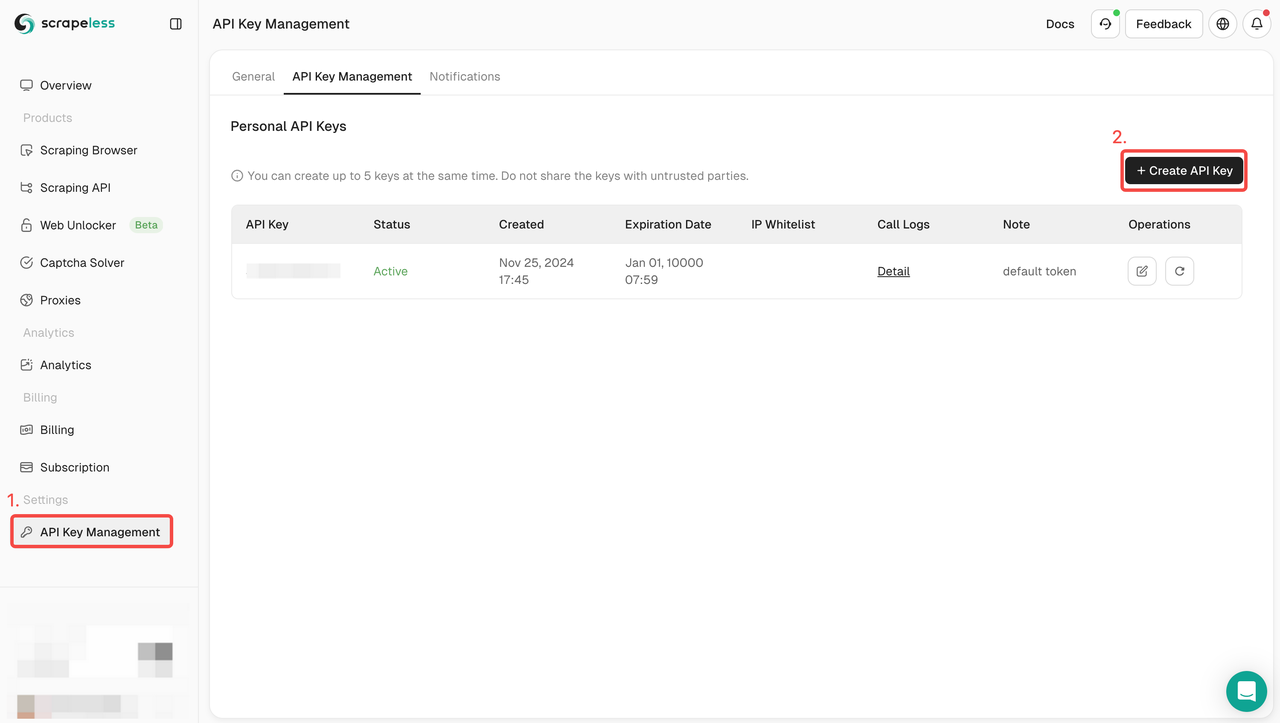
चरण 1. अपनी API कुंजी प्राप्त करें
आरंभ करने के लिए, आपको स्क्रैपलेस डैशबोर्ड से अपनी API कुंजी प्राप्त करने की आवश्यकता होगी:
- स्क्रैपलेस डैशबोर्ड में लॉग इन करें।
- API कुंजी प्रबंधन पर जाएँ।
- अपनी विशिष्ट API कुंजी उत्पन्न करने के लिए बनाएँ पर क्लिक करें।
- एक बार बनाए जाने के बाद, इसे कॉपी करने के लिए बस API कुंजी पर क्लिक करें।
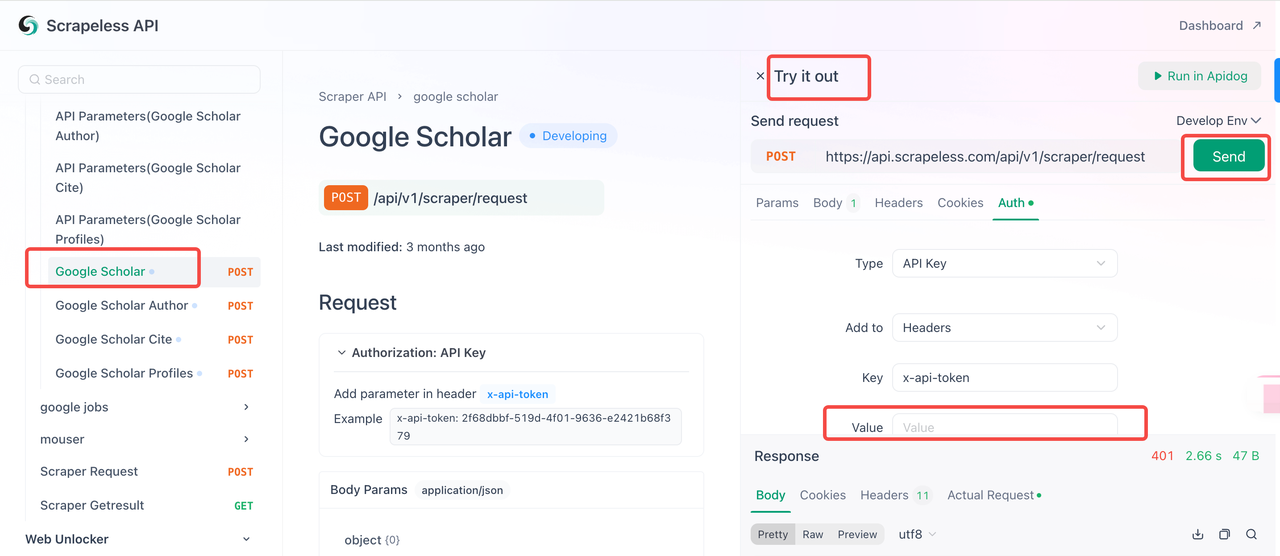
चरण 2: कोड में अपनी API कुंजी का उपयोग करें
अब आप अपनी API कुंजी का उपयोग स्क्रैपलेस को अपने प्रोजेक्ट में एकीकृत करने के लिए कर सकते हैं। API का परीक्षण और कार्यान्वयन करने के लिए इन चरणों का पालन करें:
- API प्रलेखन पर जाएँ।
- वांछित एंडपॉइंट के लिए "इसे आज़माएँ" पर क्लिक करें।
- "प्रमाणीकरण" फ़ील्ड में अपनी API कुंजी दर्ज करें।
- स्क्रैपिंग प्रतिक्रिया प्राप्त करने के लिए "भेजें" पर क्लिक करें।
नीचे एक नमूना कोड स्निपेट है जिसे आप सीधे अपने Google Scholar स्क्रैपर में एकीकृत कर सकते हैं:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar",
"q": "biology"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))इसके अलावा, स्क्रैपलेस कई स्क्रैपिंग एपीआई समाधानों का भी समर्थन करता है, जैसे: Amazon स्क्रैपिंग एपीआई, Shopee स्क्रैपिंग एपीआई, Google फ़्लाइट्स स्क्रैपिंग एपीआई, Google मैप स्क्रैपिंग एपीआई, आदि।
स्क्रैपलेस Google Scholar API
स्क्रैपलेस का Google Scholar API एक शक्तिशाली उपकरण है जो API अनुरोधों के माध्यम से Google Scholar से शैक्षणिक पत्रों, पत्रिकाओं, पुस्तकों और अन्य संसाधनों को क्रॉल कर सकता है। यह उपयोगकर्ताओं को निर्दिष्ट कीवर्ड द्वारा खोज करने और संबंधित दस्तावेजों के बारे में विस्तृत जानकारी प्राप्त करने की अनुमति देता है, जैसे शीर्षक, प्रकाशन जानकारी, उद्धरणों की संख्या, आदि।
इसके बाद, Google Scholar API पैरामीटर और उदाहरण कोड के साथ आगे बढ़ते हैं... (बाकी अनुवाद इसी तरह जारी रहेगा)
"लिंक": "https://scholar.googleusercontent.com/scholar.enw?q=info:s1QWFy06YAYJ..."
}
]
**डाटा विश्लेषण:**
- नाम: "BibTeX" इंगित करता है कि यह प्रविष्टि एक BibTeX उद्धरण निर्यात लिंक है।
- लिंक: "https://scholar.googleusercontent.com/scholar.bib?q=info:s1QWFy06YAYJ..." BibTeX उद्धरण तक पहुँचने के लिए एक सीधा URL है, जिसका उपयोग LaTeX या अन्य संदर्भ प्रबंधन उपकरणों में किया जा सकता है।
## स्क्रैपलेस गूगल स्कॉलर प्रोफाइल API
स्क्रैपलेस गूगल स्कॉलर प्रोफाइल API उपयोगकर्ताओं को लेखक के नामों के आधार पर गूगल स्कॉलर प्रोफाइल की खोज करने और उद्धरण, रुचियाँ, संबद्धताएँ और बहुत कुछ सहित विस्तृत जानकारी प्राप्त करने की अनुमति देता है। API का उपयोग कैसे करें, इसमें शामिल पैरामीटर और परिणामों की व्याख्या कैसे करें, इसका अवलोकन नीचे दिया गया है।
### गूगल स्कॉलर प्रोफाइल API पैरामीटर
| पैरामीटर | आवश्यक | विवरण |
|---------------|----------|------------------------------------------------|
| इंजन | TRUE | google_scholar_profiles पर सेट करें। |
| mauthors | TRUE | प्रोफ़ाइल खोज के लिए लेखक का नाम। |
| hl | FALSE | भाषा सेटिंग (डिफ़ॉल्ट: en)। |
| after_author | FALSE | पेजिनेशन के लिए टोकन। |
### उदाहरण: किसी लेखक प्रोफ़ाइल की खोज करना
निम्नलिखित पायथन कोड स्क्रैपलेस सेवा का उपयोग करके API अनुरोध करने का तरीका दर्शाता है:import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar_author",
"author_id": "LSsXyncAAAAJ"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
API खोज परिणामों के बारे में जानकारी के साथ एक JSON ऑब्जेक्ट देता है। यहाँ एक उदाहरण दिया गया है:{
"pagination": {
"next": "https://scholar.google.com//citations?view_op=search_authors&hl=en&mauthors=Mike&after_author=pnnfAUQM__8J&astart=10",
"next_page_token": "pnnfAUQM__8J"
},
"profiles": [
{
"name": "Mike Robb",
"link": "https://scholar.google.com//citations?hl=en&user=kq0NYnMAAAAJ",
"author_id": "kq0NYnMAAAAJ",
"affiliations": "Chemistry Department Imperial College",
"email": "imperial.ac.uk पर सत्यापित ईमेल",
"cited_by": 230346,
"interests": [
{
"title": "कम्प्यूटेशनल केमिस्ट्री",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:computational_chemistry"
},
{
"title": "सैद्धांतिक रसायन विज्ञान",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:theoretical_chemistry"
},
{
"title": "कोनिकल इंटरसेक्शन",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:conical_intersections"
},
{
"title": "गैर-एडियाबेटिक गतिशीलता",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:non_adiabatic_dynamics"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=kq0NYnMAAAAJ"
},
{
"name": "Mike A. Nalls",
"link": "https://scholar.google.com//citations?hl=en&user=ZjfgPLMAAAAJ",
"author_id": "ZjfgPLMAAAAJ",
"affiliations": "Data Tecnica International के साथ संस्थापक/सलाहकार + NIH के केंद्र में डेटा विज्ञान लीड...",
"email": "mail.nih.gov पर सत्यापित ईमेल",
"cited_by": 175760,
"interests": [
{
"title": "सांख्यिकीय आनुवंशिकी",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:statistical_genetics"
},
{
"title": "न्यूरोडीजेनेरेशन",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:neurodegeneration"
},
{
"title": "डेटा विज्ञान",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:data_science"
},
{
"title": "बायोस्टैटिस्टिक्स",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:biostatistics"
},
{
"title": "जीनोमिक्स",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:genomics"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=ZjfgPLMAAAAJ"
},
{
"name": "mike wright",
"link": "https://scholar.google.com//citations?hl=en&user=RIg9DVEAAAAJ",
"author_id": "RIg9DVEAAAAJ",
"affiliations": "इम्पीरियल कॉलेज",
"email": "imperial.ac.uk पर सत्यापित ईमेल",
"cited_by": 131474,
"interests": [
{
"title": "उद्यमिता",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:entrepreneurship"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=RIg9DVEAAAAJ"
},
{
"name": "Mike Lean (MEJ Lean)",
"link": "https://scholar.google.com//citations?hl=en&user=R8PPdbQAAAAJ",
"author_id": "R8PPdbQAAAAJ",
"affiliations": "मानव पोषण के प्रोफेसर, ग्लासगो विश्वविद्यालय",
"email": "glasgow.ac.uk पर सत्यापित ईमेल",
"cited_by": 98488,
"interests": [
{
"title": "भोजन",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:food"
},
{
"title": "पोषण",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:nutrition"
},
{
"title": "मोटापा",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:obesity"
},
{
"title": "मधुमेह",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:diabetes"
},
{
"title": "CHD",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:chd"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=R8PPdbQAAAAJ"
},
{
"name": "Mike Schuster",
"link": "https://scholar.google.com//citations?hl=en&user=L9lS9_AAAAAJ",
"author_id": "L9lS9_AAAAAJ",
"affiliations": "टू सिग्मा",
"email": "twosigma.com पर सत्यापित ईमेल",
"cited_by": 96241,
"interests": [
{
"title": "मशीन लर्निंग",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:machine_learning"
},
{
"title": "न्यूरल नेटवर्क",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:neural_networks"
},
{
"title": "डीप लर्निंग",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:deep_learning"
},
{
"title": "रीइनफोर्समेंट लर्निंग",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:reinforcement_learning"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=L9lS9_AAAAAJ"
},
{
"name": "prof dr ir Mike SM Jetten",
"link": "https://scholar.google.com//citations?hl=en&user=iXjCKTgAAAAJ",
"author_id": "iXjCKTgAAAAJ",
"affiliations": "रेडबाउड विश्वविद्यालय, माइक्रोबायोलॉजी, नीमेजेन, नीदरलैंड",
"email": "science.ru.nl पर सत्यापित ईमेल",
"cited_by": 88336,
"interests": [
{
"title": "अवायवीय माइक्रोबायोलॉजी",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:anaerobic_microbiology"
},
{
"title": "नाइट्रोजन चक्र",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:nitrogen_cycle"
},
{
"title": "मीथेन आर्किया",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:methane_archaea"
},
{
"title": "एनामॉक्स",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:anammox"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=iXjCKTgAAAAJ"
},
{
"name": "Mike Wingfield",
"link": "https://scholar.google.com//citations?hl=en&user=wT4V7isAAAAJ",
"author_id": "wT4V7isAAAAJ",
"affiliations": "प्रोफेसर, वानिकी और कृषि जैव प्रौद्योगिकी संस्थान (FABI), प्रिटोरिया विश्वविद्यालय",
"email": "fabi.up.ac.za पर सत्यापित ईमेल",
"cited_by": 82076,
"interests": [
{
"title": "वन संरक्षण",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:forest_protection"
},
{
"title": "माइकोलॉजी",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:mycology"
},
{
"title": "एंटोमोलॉजी",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:entomology"
},
{
"title": "बायोटेक्नोलॉजी",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:biotechnology"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=wT4V7isAAAAJ"
},
{
"name": "Mike Lewis",
"link": "https://scholar.google.com//citations?hl=en&user=SnQnQicAAAAJ",
"author_id": "SnQnQicAAAAJ",
"affiliations": "फेसबुक AI रिसर्च",
"email": "fb.com पर सत्यापित ईमेल",
"cited_by": 73932,
"interests": [
{
"title": "प्राकृतिक भाषा प्रसंस्करण",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:natural_language_processing"
},
{
"title": "मशीन लर्निंग",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:machine_learning"
},
{
"title": "भाषाशास्त्र",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:linguistics"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=SnQnQicAAAAJ"
},
{
"name": "Mike W. Peng",
"link": "https://scholar.google.com//citations?hl=en&user=z1Kz8gQAAAAJ",
"author_id": "z1Kz8gQAAAAJ",
"affiliations": "जिन्दल चेयर ऑफ़ ग्लोबल स्ट्रेटेजी, यूनिवर्सिटी ऑफ़ टेक्सस एट डलास",
"email": "utdallas.edu पर सत्यापित ईमेल",
"cited_by": 67576,
"interests": [
{
"title": "अंतर्राष्ट्रीय व्यापार",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:international_business"
},
{
"title": "वैश्विक रणनीति",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:global_strategy"
},
{
"title": "रणनीतिक प्रबंधन",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:strategic_management"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=z1Kz8gQAAAAJ"
},
{
"name": "Mike Hulme",
"link": "https://scholar.google.com//citations?hl=en&user=uQJsUvEAAAAJ",
"author_id": "uQJsUvEAAAAJ",
"affiliations": "कैम्ब्रिज विश्वविद्यालय",
"email": "cam.ac.uk पर सत्यापित ईमेल",
"cited_by": 62393,
"interests": [
{
"title": "जलवायु परिवर्तन",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:climate_change"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=uQJsUvEAAAAJ"
}
]
}
परिणाम इस प्रकार संरचित हैं:
- पेजिनेशन: अगला URL और next_page_token शामिल है, जिसका उपयोग पेजिनेटेड परिणामों के लिए किया जा सकता है।
- प्रोफाइल: लेखक की खोज से मेल खाने वाली प्रोफाइल की एक सरणी। प्रत्येक प्रोफ़ाइल में शामिल हैं:
- नाम: लेखक का नाम।
- लिंक: लेखक की पूरी गूगल स्कॉलर प्रोफ़ाइल का लिंक।
- author_id: लेखक के लिए एक अद्वितीय पहचानकर्ता।
- संबद्धताएँ: लेखक की संस्थागत संबद्धता।
- ईमेल: लेखक का सत्यापित ईमेल पता।
- cited_by: लेखक के लिए उद्धरणों की कुल संख्या।
- रुचियाँ: प्रासंगिक लेखक खोजों के लिंक के साथ विषयों या अनुसंधान क्षेत्रों की एक सूची।
- थंबनेल: लेखक की प्रोफ़ाइल तस्वीर का URL।
स्क्रैपलेस गूगल स्कॉलर प्रोफाइल API का उपयोग करके, डेवलपर्स आसानी से अपने अनुप्रयोगों में गूगल स्कॉलर प्रोफ़ाइल डेटा को एकीकृत कर सकते हैं, जिससे शैक्षणिक अनुसंधान और लेखक-विशिष्ट जानकारी का पता लगाया जा सकता है।
## निष्कर्ष
[गूगल के सख्त एंटी-बॉट उपायों](https://www.scrapeless.com/en/blog/get-around-anti-bot) के कारण गूगल स्कॉलर को मैन्युअल रूप से स्क्रैप करना मुश्किल है। इसके बजाय, स्क्रैपलेस गूगल स्कॉलर API गूगल स्कॉलर डेटा निकालने का एक कुशल, विश्वसनीय और CAPTCHA-मुक्त तरीका प्रदान करता है। चाहे आपको खोज परिणाम, लेखक प्रोफ़ाइल, उद्धरण विवरण या प्रकाशन मेटाडेटा की आवश्यकता हो, स्क्रैपलेस गूगल स्कॉलर API सभी उपयोग के मामलों को कवर करता है।
**🔹 स्क्रैपलेस API का उपयोग क्यों करें?**
✅ IP प्रतिबंधों और CAPTCHA से बचता है
✅ संरचित JSON आउटपुट प्रदान करता है
✅ उद्धरणों, लेखकों और खोज परिणामों के लिए विभिन्न समापन बिंदुओं का समर्थन करता है
> 🚀 गूगल स्कॉलर डेटा को सहजता से निकालने के लिए आज ही [स्क्रैपलेस API](https://www.scrapeless.com/en/product/scraping-api?utm_source=official&utm_medium=blog&utm_campaign=scrapegooglescholar) का उपयोग करना शुरू करें!
## गूगल स्कॉलर API के बारे में अक्सर पूछे जाने वाले प्रश्न
**Q1: क्या स्क्रैपलेस API मुफ़्त है?**
उत्तर: स्क्रैपलेस एक निःशुल्क परीक्षण प्रदान करता है, जिसके बाद सदस्यता की आवश्यकता होती है। आप हमारे Discord में शामिल हो सकते हैं और अपने स्क्रैपलेस के निःशुल्क परीक्षण का दावा करने के लिए हमारी टीम से संपर्क कर सकते हैं। परीक्षण के बाद, सदस्यता की आवश्यकता होगी।
**Q2: क्या मैं गूगल स्कॉलर को मैन्युअल रूप से स्क्रैप कर सकता हूँ?**
उत्तर: हाँ, लेकिन ब्लॉक होना आसान है। स्क्रैपलेस API अधिक स्थिर है।
**Q3: मैं गूगल स्कॉलर से किस प्रकार के डेटा को स्क्रैप कर सकता हूँ?**
उत्तर: सही उपकरणों के साथ, आप गूगल स्कॉलर से विभिन्न प्रकार के डेटा को स्क्रैप कर सकते हैं, जिसमें प्रकाशन शीर्षक, लेखक, उद्धरण गणना, प्रकाशन वर्ष और सार शामिल हैं। यह डेटा शोधकर्ताओं, विश्लेषकों और डेवलपर्स के लिए विशेष रूप से उपयोगी है, जिन्हें विश्लेषण, प्रवृत्ति निगरानी या उद्धरण ट्रैकिंग के लिए बड़ी मात्रा में शैक्षणिक जानकारी तक पहुँच की आवश्यकता होती है।स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


