
Python से Google उत्पाद ऑनलाइन विक्रेताओं को कैसे स्क्रैप करें
Advanced Data Extraction Specialist
परिचय
आज के प्रतिस्पर्धी ईकॉमर्स परिदृश्य में, उत्पाद लिस्टिंग की निगरानी करना और Google जैसे प्लेटफॉर्म पर ऑनलाइन विक्रेताओं के प्रदर्शन का विश्लेषण करना बहुमूल्य अंतर्दृष्टि प्रदान कर सकता है। Google उत्पाद लिस्टिंग को स्क्रैप करने से व्यवसायों को कीमतों की तुलना करने, रुझानों पर नज़र रखने और प्रतियोगियों का विश्लेषण करने के लिए वास्तविक समय का डेटा इकट्ठा करने की अनुमति मिलती है। इस लेख में, हम आपको विभिन्न विधियों का उपयोग करके, Python का उपयोग करके Google उत्पाद ऑनलाइन विक्रेताओं को स्क्रैप करने का तरीका दिखाएंगे। हम यह भी बताएंगे कि विश्वसनीय, स्केलेबल और कानूनी समाधानों की तलाश करने वाले व्यवसायों के लिए Scrapeless सबसे अच्छा विकल्प क्यों है।
Google उत्पाद ऑनलाइन विक्रेताओं को स्क्रैप करने की चुनौतियों को समझना
Google उत्पाद ऑनलाइन विक्रेताओं को स्क्रैप करने का प्रयास करते समय, कई महत्वपूर्ण चुनौतियाँ उत्पन्न हो सकती हैं:
- एंटी-स्क्रैपिंग उपाय: वेबसाइट स्वचालित स्क्रैपिंग को रोकने के लिए CAPTCHA और IP ब्लॉकिंग लागू करती हैं, जिससे डेटा निष्कर्षण कठिन हो जाता है।
- डायनामिक सामग्री: Google उत्पाद पृष्ठ अक्सर JavaScript का उपयोग करके डेटा लोड करते हैं, जिसे अनुरोध और BeautifulSoup या Selenium जैसे पारंपरिक स्क्रैपिंग विधियों द्वारा याद किया जा सकता है।
- रेट-लिमिटिंग: कम समय में अत्यधिक अनुरोधों से थ्रॉटल्ड एक्सेस हो सकता है, जिससे स्क्रैपिंग प्रक्रिया में देरी और रुकावट आती है।
गोपनीयता सूचना: हम वेबसाइट की गोपनीयता की दृढ़ता से रक्षा करते हैं। इस ब्लॉग में सभी डेटा सार्वजनिक हैं और केवल क्रॉलिंग प्रक्रिया के प्रदर्शन के रूप में उपयोग किए जाते हैं। हम कोई भी जानकारी और डेटा सहेजते नहीं हैं।
विधि 1: Scrapeless API के साथ Google उत्पाद ऑनलाइन विक्रेताओं को स्क्रैप करना (अनुशंसित समाधान)
Scrapeless एक बेहतरीन उपकरण क्यों है:
- कुशल डेटा निष्कर्षण: Scrapeless CAPTCHA और एंटी-बॉट उपायों को बायपास कर सकता है, जिससे सुचारू, निर्बाध डेटा स्क्रैपिंग सक्षम हो सकती है।
- किफायती मूल्य: केवल $0.1 प्रति 1,000 क्वेरी पर, Scrapeless Google स्क्रैपिंग के लिए सबसे किफायती समाधानों में से एक प्रदान करता है।
- मल्टी-सोर्स स्क्रैपिंग: Google उत्पाद ऑनलाइन विक्रेताओं को स्क्रैप करने के अलावा, Scrapeless आपको Google मानचित्र, Google होटल, Google फ़्लाइट्स, Google समाचार और बहुत कुछ से डेटा एकत्र करने की अनुमति देता है।
- गति और स्केलेबिलिटी: बड़े पैमाने पर स्क्रैपिंग कार्यों को जल्दी से संभालें, बिना धीमा किए, यह छोटे और उद्यम-स्तरीय दोनों परियोजनाओं के लिए आदर्श बनाता है।
- संरचित डेटा: यह उपकरण आपके विश्लेषण, रिपोर्ट या आपके सिस्टम में एकीकरण में उपयोग के लिए तैयार, संरचित, स्वच्छ डेटा प्रदान करता है।
- उपयोग में आसानी: कोई जटिल सेटअप नहीं—बस अपनी API कुंजी को एकीकृत करें और मिनटों में डेटा स्क्रैप करना शुरू करें।
Scrapeless API का उपयोग कैसे करें:
- साइन अप करें: Scrapeless पर रजिस्टर करें और अपनी API कुंजी प्राप्त करें। साथ ही, आप डैशबोर्ड के शीर्ष पर एक निःशुल्क परीक्षण भी प्राप्त कर सकते हैं।
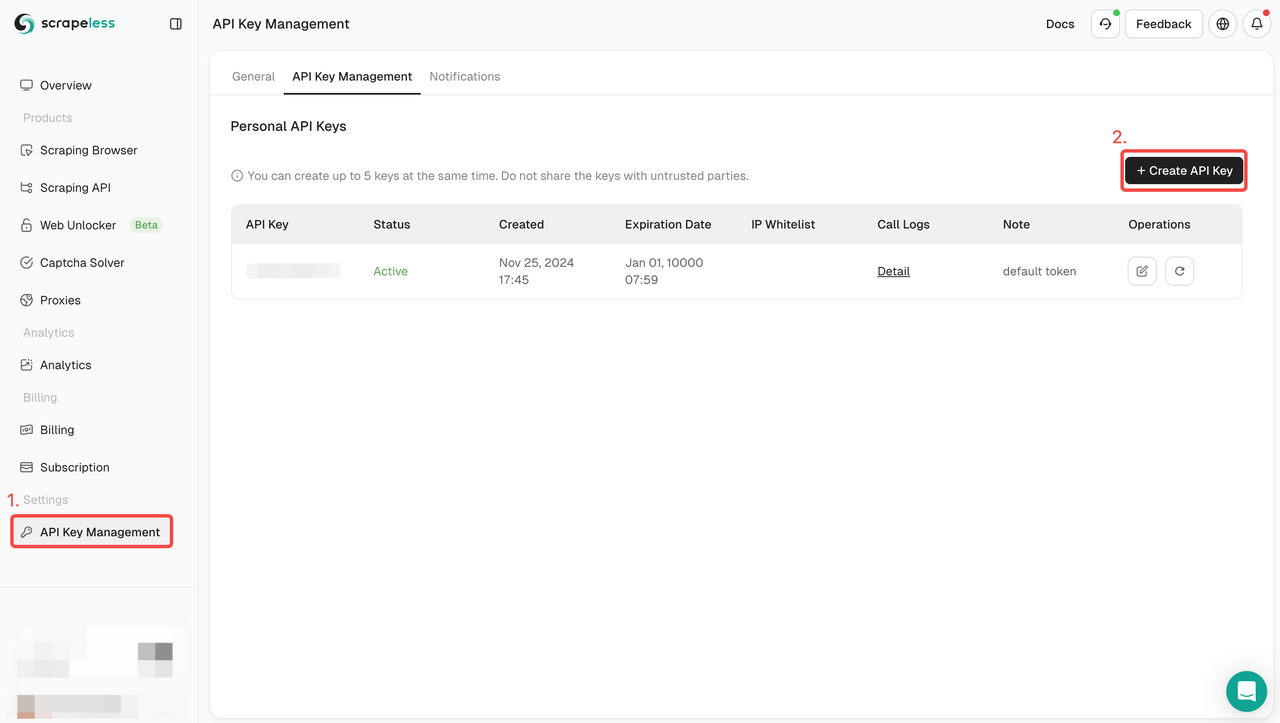
- API को एकीकृत करें: सेवा के लिए अनुरोध शुरू करने के लिए अपनी कोड में API कुंजी शामिल करें।
- स्क्रैपिंग शुरू करें: अब आप उत्पाद URL या खोज क्वेरी के साथ GET अनुरोध भेज सकते हैं, और Scrapeless उत्पाद नाम, कीमतें, समीक्षाएँ और बहुत कुछ सहित संरचित डेटा वापस कर देगा।
- डेटा का उपयोग करें: प्रतियोगी विश्लेषण, प्रवृत्ति ट्रैकिंग, या किसी अन्य परियोजना के लिए पुनर्प्राप्त डेटा का लाभ उठाएँ जिसके लिए Google डेटा अंतर्दृष्टि की आवश्यकता होती है।
पूर्ण कोड उदाहरण:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()निःशुल्क Scrapeless आज़माएँ और अनुभव करें कि हमारा API आपकी Google उत्पाद ऑनलाइन विक्रेता स्क्रैपिंग प्रक्रिया को कैसे सरल बना सकता है। यहां अपना निःशुल्क परीक्षण शुरू करें।
सहायता प्राप्त करने, अंतर्दृष्टि साझा करने और नवीनतम सुविधाओं पर अपडेट रहने के लिए हमारे Discord समुदाय में शामिल हों। जुड़ने के लिए यहां क्लिक करें!
विधि 2: अनुरोध और BeautifulSoup के साथ Google उत्पाद लिस्टिंग को स्क्रैप करना
इस दृष्टिकोण में, हम गहराई से देखेंगे कि दो शक्तिशाली Python पुस्तकालयों: अनुरोध और BeautifulSoup का उपयोग करके Google उत्पाद लिस्टिंग को कैसे स्क्रैप किया जाए। ये पुस्तकालय हमें Google उत्पाद पृष्ठों पर HTTP अनुरोध करने और मूल्यवान जानकारी निकालने के लिए HTML संरचना को पार्स करने की अनुमति देते हैं।
चरण 1. वातावरण स्थापित करना
सबसे पहले, सुनिश्चित करें कि आपके सिस्टम पर Python स्थापित है। और इस प्रोजेक्ट के लिए कोड संग्रहीत करने के लिए एक नई निर्देशिका बनाएँ। इसके बाद आपको beautifulsoup4 और requests को स्थापित करने की आवश्यकता है। आप इसे PIP के माध्यम से कर सकते हैं:
language
$ pip install requests beautifulsoup4चरण 2. एक साधारण अनुरोध करने के लिए अनुरोधों का उपयोग करें
अब, हमें Google उत्पादों के डेटा को क्रॉल करने की आवश्यकता है। आइए product_id 4172129135583325756 वाले उत्पाद को उदाहरण के रूप में लें और OnlineSeller के कुछ डेटा को क्रॉल करें।
आइए सबसे पहले अनुरोधों का उपयोग करके एक GET अनुरोध भेजें:
def google_product():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get('https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8', headers=headers)जैसा कि अपेक्षित है, अनुरोध एक पूर्ण HTML पृष्ठ देता है। अब हमें निम्न पृष्ठ से कुछ डेटा निकालने की आवश्यकता है:
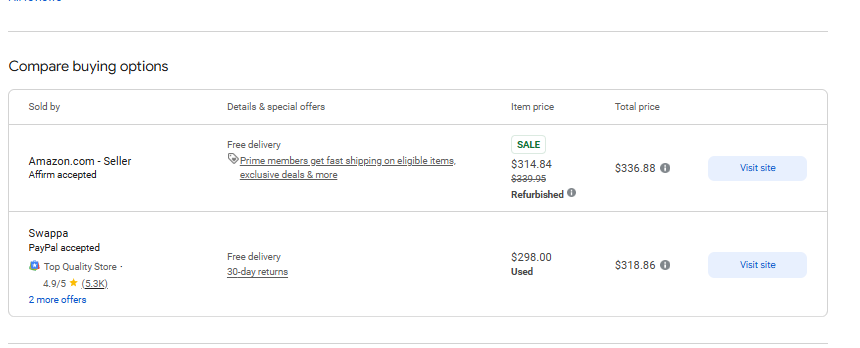
चरण 3. विशिष्ट डेटा प्राप्त करें
जैसा कि चित्र में दिखाया गया है, हमें जो डेटा चाहिए वह tr[jscontroller='d5bMlb'] के अंतर्गत है:
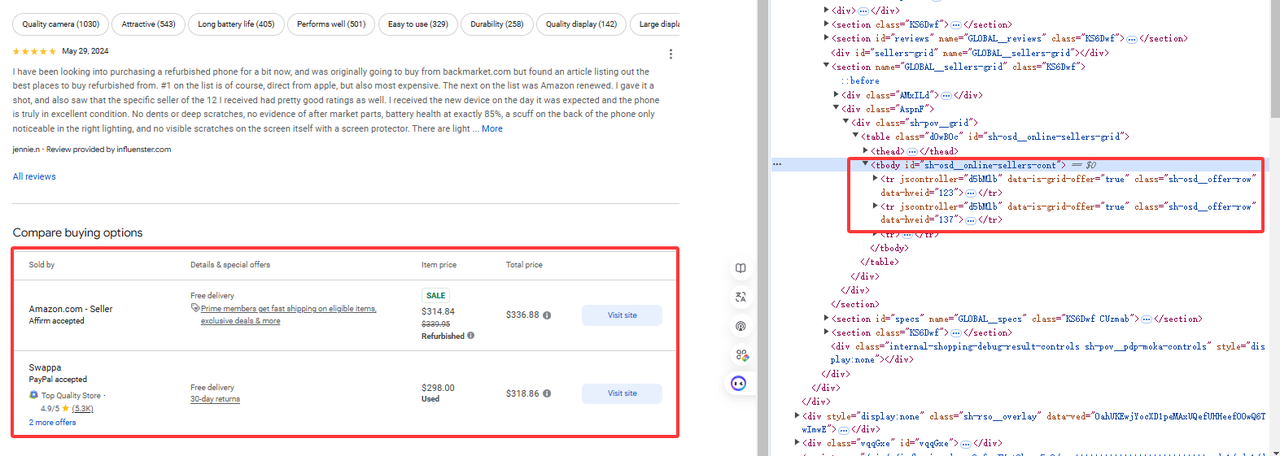
online_sellers = []
soup = BeautifulSoup(response.content, 'html.parser')
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})फिर HTML पृष्ठ को पार्स करने और प्रासंगिक तत्व प्राप्त करने के लिए BeautifulSoup का उपयोग करें:
पूर्ण कोड
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price,
additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
online_sellers = []
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})
return online_sellers
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)कंसोल प्रिंट परिणाम इस प्रकार हैं:

सीमा
निश्चित रूप से, हम आंशिक डेटा प्राप्त करने के उपरोक्त उदाहरण का उपयोग करके डेटा वापस प्राप्त कर सकते हैं, लेकिन IP ब्लॉकिंग का जोखिम है। हम बड़े अनुरोध नहीं कर सकते हैं, जो Google के उत्पाद जोखिम नियंत्रण को ट्रिगर करेगा।
विधि 3: Selenium के साथ Google उत्पाद ऑनलाइन विक्रेताओं को स्क्रैप करना
इस विधि में, हम देखेंगे कि कैसे Selenium, एक शक्तिशाली वेब स्वचालन उपकरण, का उपयोग करके ऑनलाइन विक्रेताओं से Google उत्पाद लिस्टिंग को स्क्रैप किया जाए। अनुरोध और BeautifulSoup के विपरीत, Selenium हमें गतिशील पृष्ठों के साथ बातचीत करने की अनुमति देता है जिन्हें निष्पादित करने के लिए JavaScript की आवश्यकता होती है, जो Google उत्पाद लिस्टिंग को गतिशील रूप से लोड करने वाली सामग्री को स्क्रैप करने के लिए एकदम सही बनाता है।
चरण 1: वातावरण सेट करें
सबसे पहले, सुनिश्चित करें कि आपके सिस्टम पर Python स्थापित है। और इस प्रोजेक्ट के लिए कोड संग्रहीत करने के लिए एक नई निर्देशिका बनाएँ। इसके बाद, आपको selenium और webdriver_manager स्थापित करने की आवश्यकता है। आप इसे PIP के माध्यम से कर सकते हैं:
pip install selenium
pip install webdriver_managerचरण 2: सेलेनियम वातावरण को इनिशियलाइज़ करें
अब, हमें सेलेनियम के कुछ कॉन्फ़िगरेशन आइटम जोड़ने और पर्यावरण को इनिशियलाइज़ करने की आवश्यकता है।
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)चरण 3: विशिष्ट डेटा प्राप्त करें
हम product_id 4172129135583325756 वाले उत्पाद को प्राप्त करने और OnlineSeller का कुछ डेटा प्राप्त करने के लिए selenium का उपयोग करते हैं
driver.get(url)
time.sleep(5) #wait page
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""पूर्ण कोड
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price, additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
driver.get(url)
time.sleep(5)
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_seller = {
'name': name,
'payment_methods': payment_methods,
'link': link,
'direct_link': direct_link,
'details_and_offers': [{"text": details_and_offers_text}],
'base_price': base_price,
'badge': badge
}
online_sellers.append(online_seller)
return online_sellers
finally:
driver.quit()
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)कंसोल प्रिंट परिणाम इस प्रकार हैं:

सीमाएँ
Selenium वेब ब्राउज़र संचालन को स्वचालित करने के लिए एक शक्तिशाली उपकरण है और इसका व्यापक रूप से स्वचालित परीक्षण और वेब डेटा क्रॉलिंग में उपयोग किया जाता है। हालाँकि, इसे पृष्ठ के लोड होने की प्रतीक्षा करने की आवश्यकता है, इसलिए यह डेटा क्रॉलिंग प्रक्रिया में अपेक्षाकृत धीमा है।
अक्सर पूछे जाने वाले प्रश्न
बड़े पैमाने पर Google उत्पाद लिस्टिंग को स्क्रैप करने के सर्वोत्तम तरीके क्या हैं?
बड़े पैमाने पर Google उत्पाद स्क्रैपिंग के लिए सबसे प्रभावी तरीका Scrapeless का उपयोग करना है। यह एक तेज और स्केलेबल API प्रदान करता है, जो डायनामिक सामग्री, IP ब्लॉकिंग और CAPTCHA को कुशलतापूर्वक संभालता है, जिससे यह व्यवसायों के लिए आदर्श बन जाता है।
उत्पाद लिस्टिंग को स्क्रैप करते समय मैं Google के एंटी-स्क्रैपिंग उपायों को कैसे बायपास करूँ?
Google CAPTCHA और IP ब्लॉकिंग सहित कई एंटी-स्क्रैपिंग उपायों को नियोजित करता है। Scrapeless एक API प्रदान करता है जो इन उपायों को बायपास करता है और सुचारू, निर्बाध डेटा निष्कर्षण सुनिश्चित करता है।
क्या मैं Google उत्पाद लिस्टिंग को स्क्रैप करने के लिए BeautifulSoup या Selenium जैसे Python पुस्तकालयों का उपयोग कर सकता हूँ?
जबकि Google उत्पाद लिस्टिंग को स्क्रैप करने के लिए BeautifulSoup और Selenium का उपयोग किया जा सकता है, वे धीमे प्रदर्शन, पता लगाने के जोखिम और स्केल करने में असमर्थता जैसी सीमाओं के साथ आते हैं। Scrapeless एक अधिक कुशल समाधान प्रदान करता है जो इन सभी मुद्दों को संभालता है।
निष्कर्ष
इस लेख में, हमने Google उत्पाद ऑनलाइन विक्रेताओं को स्क्रैप करने के तीन तरीकों पर चर्चा की है: अनुरोध और BeautifulSoup, Selenium और Scrapeless। प्रत्येक विधि अलग-अलग लाभ प्रदान करती है, लेकिन जब बड़े पैमाने पर स्क्रैपिंग की बात आती है, तो व्यवसायों के लिए Scrapeless निस्संदेह सबसे अच्छा विकल्प है।
- अनुरोध और BeautifulSoup छोटे पैमाने पर स्क्रैपिंग कार्यों के लिए उपयुक्त हैं, लेकिन गतिशील सामग्री से निपटने या बड़े पैमाने पर स्केल करने पर सीमाओं का सामना करते हैं। ये उपकरण एंटी-स्क्रैपिंग उपायों द्वारा अवरुद्ध होने का जोखिम भी उठाते हैं।
- Selenium JavaScript-रेंडर किए गए पृष्ठों के लिए प्रभावी है, लेकिन यह संसाधन-गहन और अन्य विकल्पों की तुलना में धीमा है, जिससे यह Google उत्पाद लिस्टिंग के बड़े पैमाने पर स्क्रैपिंग के लिए कम आदर्श है।
दूसरी ओर, Scrapeless पारंपरिक स्क्रैपिंग विधियों से जुड़ी सभी चुनौतियों का समाधान करता है। यह तेज, विश्वसनीय और कानूनी है, यह सुनिश्चित करता है कि आप बड़े पैमाने पर Google उत्पाद ऑनलाइन विक्रेताओं को कुशलतापूर्वक स्क्रैप कर सकते हैं बिना अवरुद्ध होने या अन्य बाधाओं में भाग लिए।
व्यवसायों के लिए एक सुव्यवस्थित, स्केलेबल समाधान की तलाश में, Scrapeless सबसे अच्छा उपकरण है। यह पारंपरिक विधियों की सभी बाधाओं को दूर करता है और Google उत्पाद डेटा एकत्र करने के लिए एक सुचारू, परेशानी मुक्त अनुभव प्रदान करता है।
आज ही निःशुल्क परीक्षण के साथ Scrapeless आज़माएँ और जानें कि आपके Google उत्पाद स्क्रैपिंग कार्यों को स्केल करना कितना आसान है। अभी अपना निःशुल्क परीक्षण शुरू करें.
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


