
Python से Google News कैसे Scrape करें
Advanced Data Extraction Specialist
Google News क्या है?
Google News Google द्वारा शुरू की गई एक समाचार समेकन सेवा है। यह दुनिया भर की प्रमुख समाचार वेबसाइटों से नवीनतम समाचार रिपोर्टों को एकत्रित, व्यवस्थित और प्रदर्शित करती है। उपयोगकर्ता कीवर्ड, विषय, क्षेत्र, प्रकाशन स्रोत आदि द्वारा फ़िल्टर कर सकते हैं, और Google News एल्गोरिथम उपयोगकर्ताओं के हितों और ब्राउज़िंग आदतों के आधार पर व्यक्तिगत समाचार सामग्री की सिफारिश करेगा।
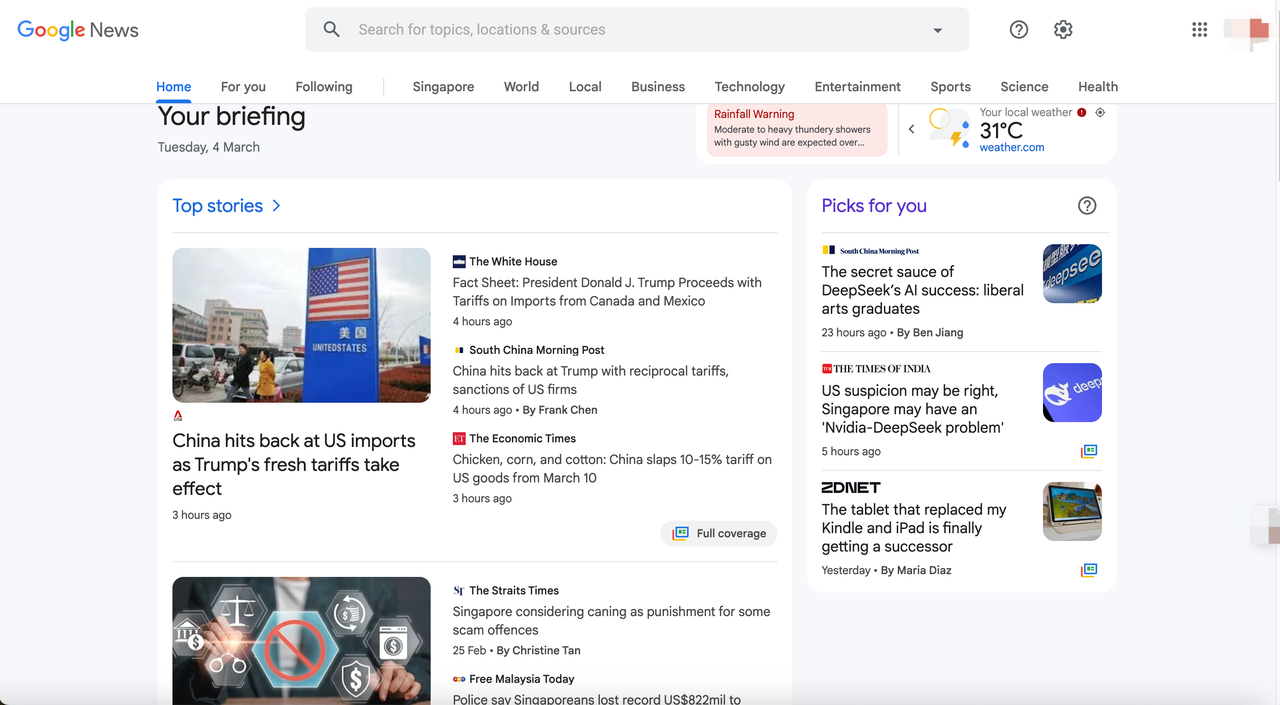
Google News डेटा मुख्य रूप से आधिकारिक समाचार संगठनों, ब्लॉग, सरकारी घोषणाओं आदि से आता है, इसलिए यह वैश्विक वास्तविक समय की जानकारी का एक महत्वपूर्ण स्रोत है।
Google News से आप कौन सा डेटा प्राप्त कर सकते हैं?
-
समाचार शीर्षक (शीर्षक) - लेख की मुख्य सामग्री
-
समाचार लिंक (लिंक) - लेख का मूल स्रोत URL
-
प्रकाशित तिथि (तिथि) - वह समय जब लेख प्रकाशित हुआ था (कुछ मिनट पहले, कुछ घंटे पहले या एक विशिष्ट समय)
-
समाचार स्निपेट (स्निपेट) - लेख की सामग्री का संक्षिप्त पूर्वावलोकन
-
समाचार स्रोत (स्रोत) - वह मीडिया संगठन जहाँ लेख प्रकाशित हुआ था, जैसे CNN, BBC, NYTimes
-
समाचार श्रेणी (श्रेणी) - वह श्रेणी जिससे लेख संबंधित है, जैसे प्रौद्योगिकी, खेल, वित्त, स्वास्थ्य, आदि।
-
छवि लिंक (थंबनेल) - लेख के साथ आने वाली तस्वीर का लिंक
-
संबंधित समाचार (संबंधित समाचार) - समान या संबंधित रिपोर्टों के लिंक
-
वीडियो सामग्री (वीडियो) - शामिल वीडियो समाचार
....
Google News डेटा क्रॉल करने का कारण?
Google News डेटा क्रॉल करने के कई व्यावहारिक अनुप्रयोग परिदृश्य हैं। यहाँ कुछ सबसे सामान्य उपयोग दिए गए हैं:
- बाजार विश्लेषण और व्यावसायिक बुद्धिमत्ता
- वित्तीय और निवेश विश्लेषण
- एसईओ और सामग्री विपणन
- मशीन लर्निंग और एआई अनुसंधान
- मीडिया और समाचार समेकन अनुप्रयोग
Python के साथ Google News को कैसे स्क्रैप करें
चरण 1: Google News डेटा क्रॉलिंग वातावरण बनाएँ
सबसे पहले, हमें एक डेटा क्रॉलिंग वातावरण बनाने और निम्नलिखित उपकरण तैयार करने की आवश्यकता है:
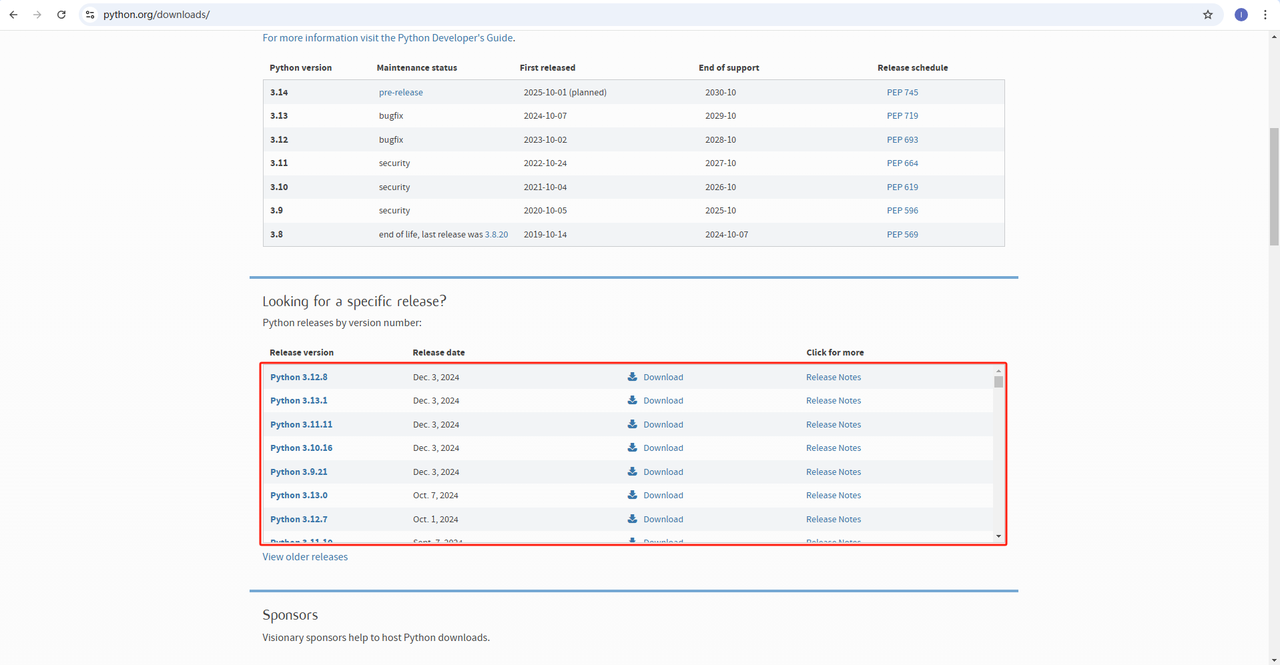
- Python: https://www.python.org/downloads/ यह Python चलाने के लिए कोर सॉफ्टवेयर है। आप आधिकारिक वेबसाइट लिंक से हमारी ज़रूरत के संस्करण को डाउनलोड कर सकते हैं, जैसा कि नीचे दिए गए चित्र में दिखाया गया है, लेकिन नवीनतम संस्करण डाउनलोड न करने की सलाह दी जाती है। आप नवीनतम संस्करण से पहले 1-2 संस्करण डाउनलोड कर सकते हैं।
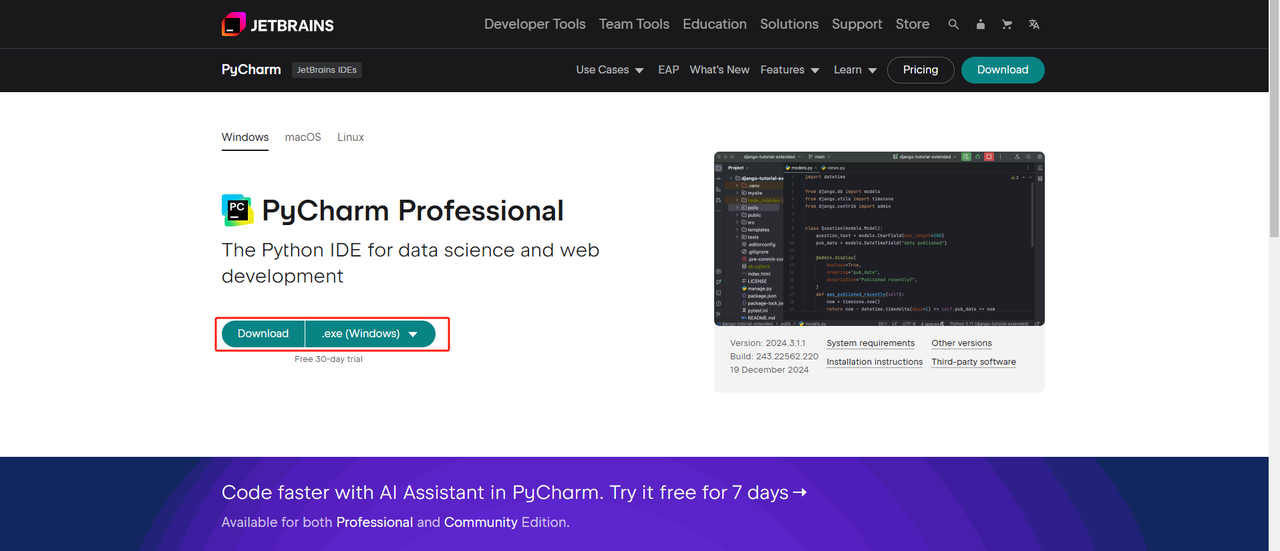
- Python IDE: Python को सपोर्ट करने वाला कोई भी IDE काम करेगा, लेकिन हम PyCharm की सलाह देते हैं, जो विशेष रूप से Python के लिए डिज़ाइन किया गया एक IDE विकास उपकरण सॉफ़्टवेयर है। PyCharm संस्करण के संबंध में, हम मुफ्त PyCharm कम्युनिटी संस्करण की सलाह देते हैं।
- Pip: आप अपने प्रोग्राम को एक ही कमांड से चलाने के लिए आवश्यक लाइब्रेरी को स्थापित करने के लिए Python पैकेज इंडेक्स का उपयोग कर सकते हैं।
नोट: यदि आप विंडोज़ उपयोगकर्ता हैं, तो इंस्टॉलेशन विज़ार्ड में "Add python.exe to PATH" विकल्प को चेक करना न भूलें। यह विंडोज़ को टर्मिनल में Python और कमांड का उपयोग करने की अनुमति देगा। चूँकि Python 3.4 या बाद के संस्करण में यह डिफ़ॉल्ट रूप से शामिल है, इसलिए आपको इसे मैन्युअल रूप से स्थापित करने की आवश्यकता नहीं है।
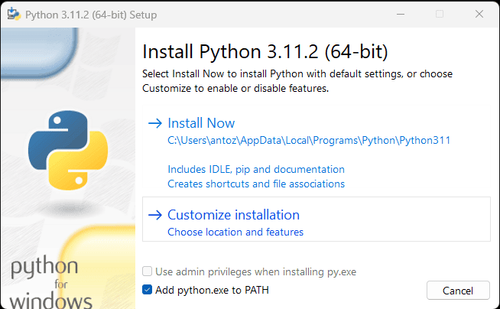
उपरोक्त चरणों के माध्यम से, Google News डेटा क्रॉल करने के लिए वातावरण स्थापित हो गया है। इसके बाद, आप डाउनलोड किए गए PyCharm को Scraperless के साथ मिलाकर Google News डेटा क्रॉल कर सकते हैं।
चरण 2: Google News डेटा को स्क्रैप करने के लिए PyCharm और Scrapeless का उपयोग करें
- PyCharm लॉन्च करें और मेनू बार से File>New Project… चुनें।
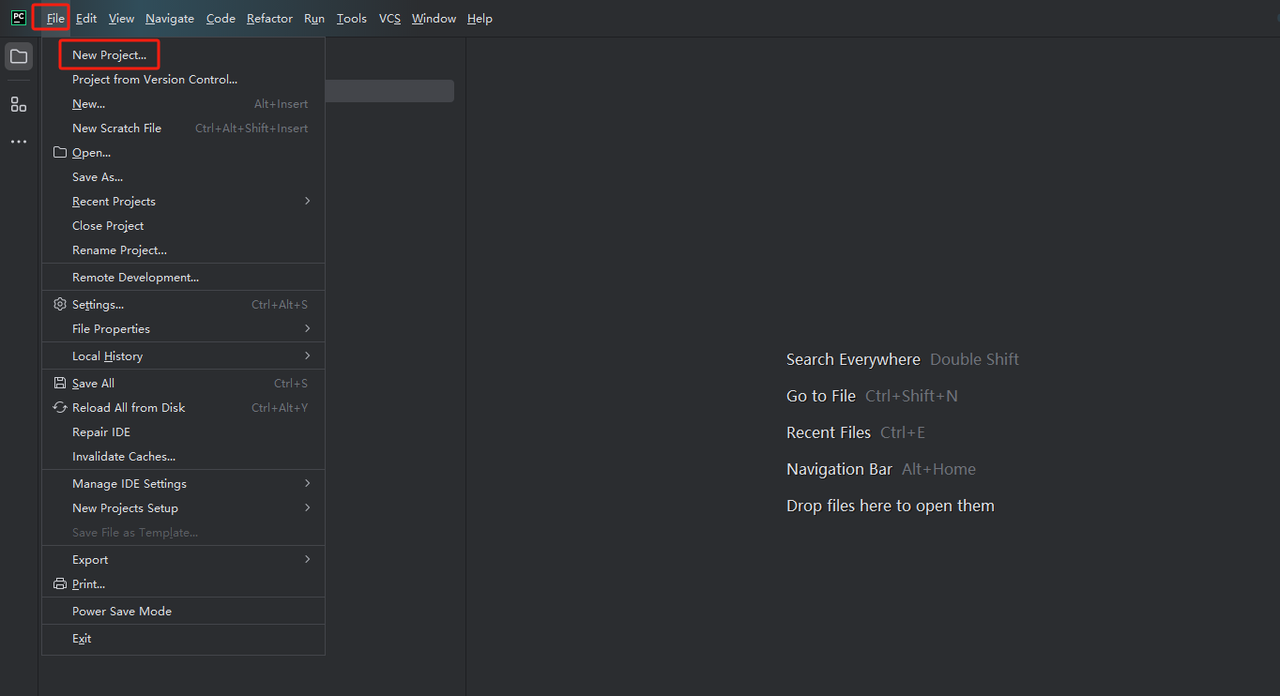
- फिर, पॉप अप होने वाली विंडो में, बाएँ मेनू से Pure Python चुनें और अपनी प्रोजेक्ट को इस प्रकार सेट करें:
नोट: नीचे दिए गए लाल बॉक्स में, पहले चरण में वातावरण कॉन्फ़िगरेशन के दौरान डाउनलोड किए गए Python इंस्टॉलेशन पथ का चयन करें
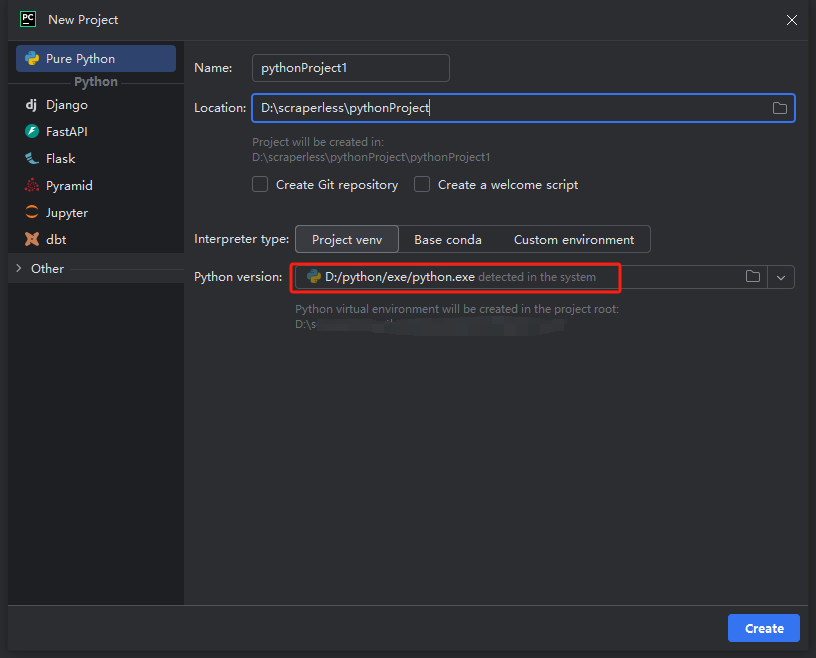
- आप python-scraper नामक एक प्रोजेक्ट बना सकते हैं, "Create main.py welcome script option in the folder" को चेक करें और "Create" बटन पर क्लिक करें। PyCharm थोड़ी देर के लिए प्रोजेक्ट सेट करने के बाद, आपको निम्नलिखित दिखाई देना चाहिए:
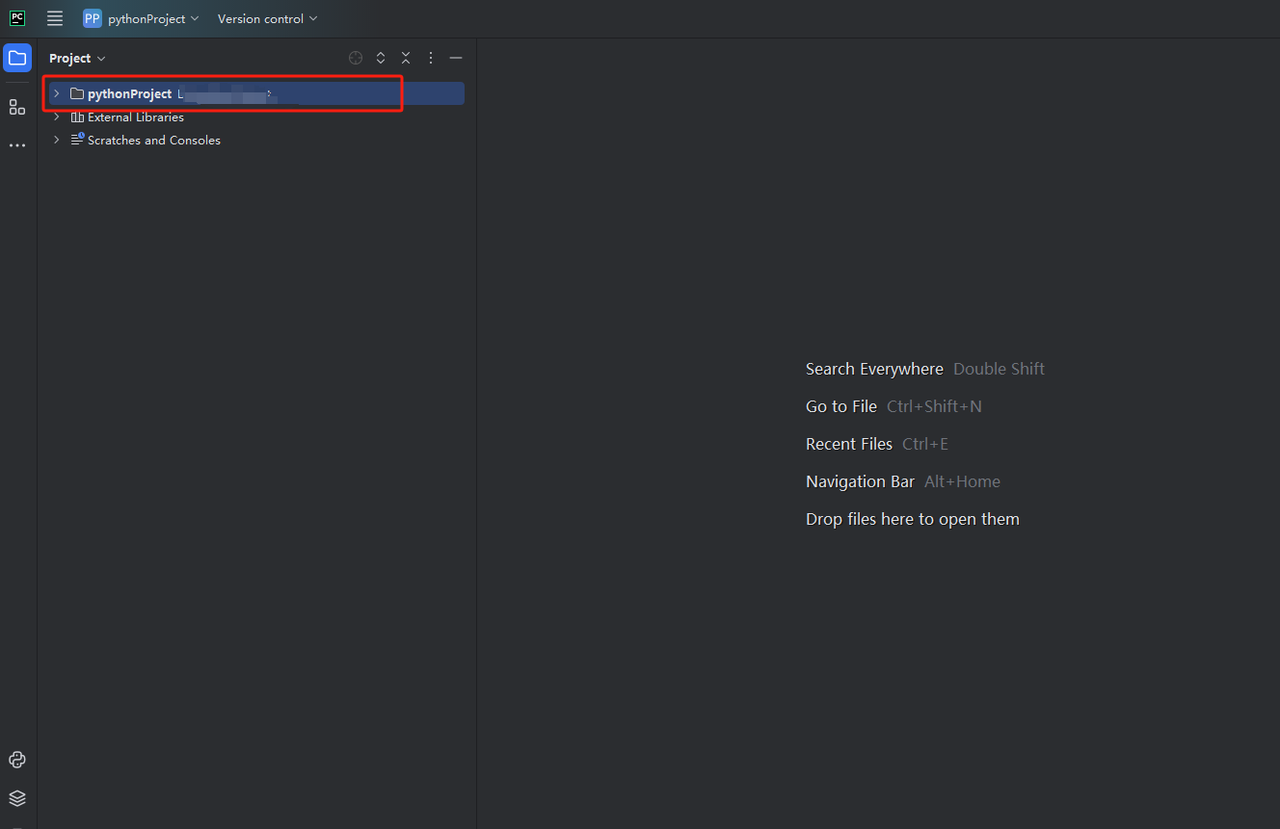
- फिर, एक नई Python फ़ाइल बनाने के लिए राइट-क्लिक करें।
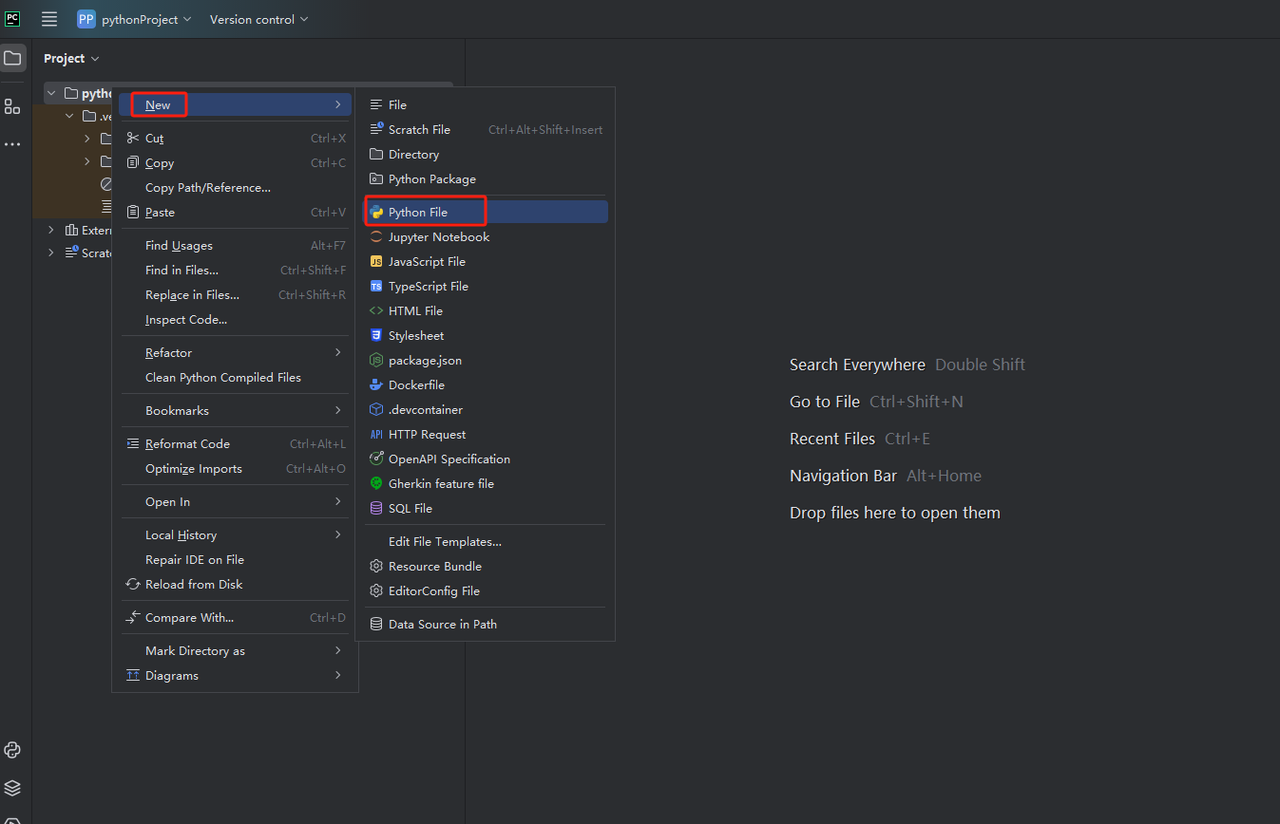
- यह सत्यापित करने के लिए कि सब कुछ सही ढंग से काम कर रहा है, स्क्रीन के नीचे टर्मिनल टैब खोलें और टाइप करें: python main.py। इस कमांड को लॉन्च करने के बाद आपको मिलना चाहिए: Hi, PyCharm.
चरण 3: Scrapeless API कुंजी प्राप्त करें
अब आप Scrapeless कोड को सीधे PyCharm में कॉपी और चला सकते हैं, ताकि आपको Google News का JSON प्रारूप डेटा मिल सके। हालाँकि, आपको पहले Scrapeless API कुंजी प्राप्त करने की आवश्यकता है। चरण इस प्रकार हैं:
यदि आपके पास अभी तक खाता नहीं है, तो कृपया Scrapeless के लिए साइन अप करें। साइन अप करने के बाद, अपने डैशबोर्ड में लॉग इन करें।
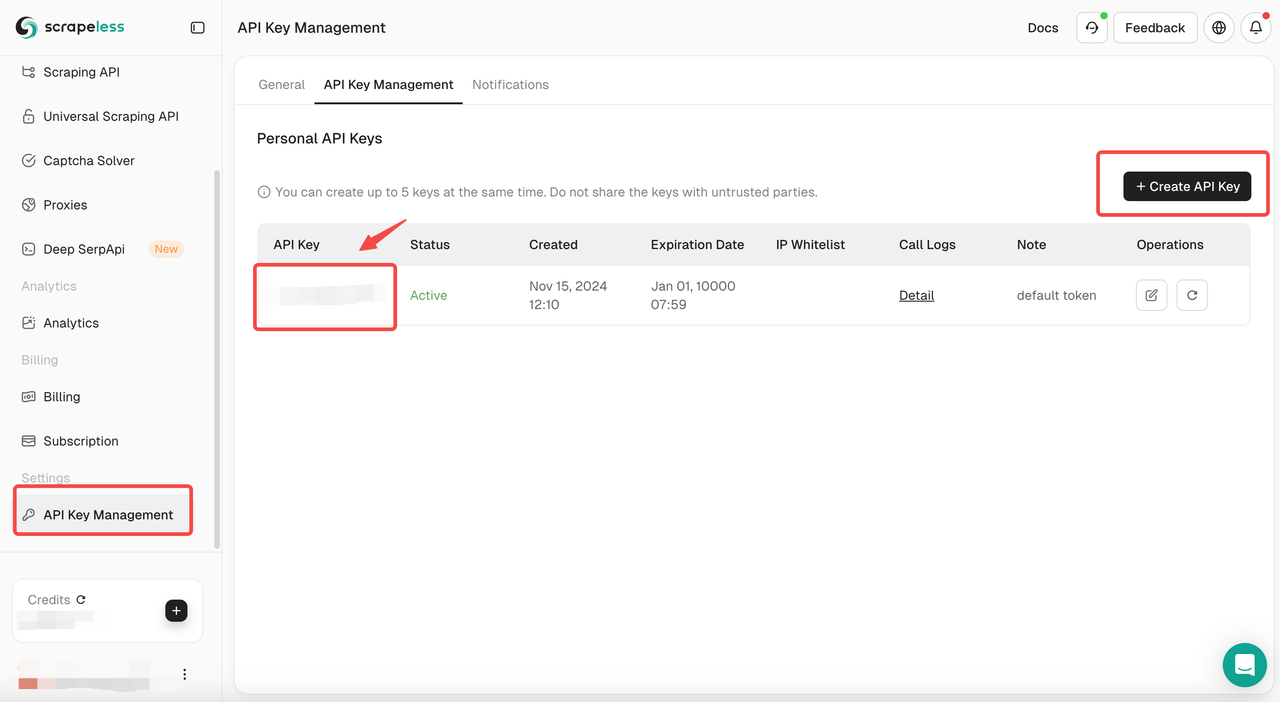
अपने Scrapeless डैशबोर्ड में, API Key Management पर जाएँ और Create API Key पर क्लिक करें। आपको अपनी API कुंजी मिल जाएगी। इसे कॉपी करने के लिए बस उस पर माउस रखें और क्लिक करें। Scrapeless API को कॉल करते समय इस कुंजी का उपयोग आपके अनुरोध को प्रमाणित करने के लिए किया जाएगा।
चरण 4: अपने स्क्रैपिंग टूल में Scrapeless API को कैसे एकीकृत करें
एक बार जब आपके पास API कुंजी हो जाती है, तो आप अपने स्वयं के स्क्रैपिंग टूल में Scrapeless API को एकीकृत करना शुरू कर सकते हैं। यहाँ बताया गया है कि कैसे Scrapeless API को कॉल करें और Python और requests का उपयोग करके डेटा प्राप्त करें।
Scrapeless API का उपयोग करके Google News जानकारी क्रॉल करने के लिए नमूना कोड:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_news",
"q": "pizza",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.news", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()IP ब्लॉक, CAPTCHA और लगातार बदलते HTML संरचनाओं से निपटने से थक गए हैं?
Scrapeless Google News API के साथ, आप प्रतिबंधों को दरकिनार कर सकते हैं, वास्तविक समय के समाचार डेटा निकाल सकते हैं, और विकास के समय को बचा सकते हैं-यह सब एक साधारण API कॉल के साथ!
खुद इसे स्क्रैप करने के बजाय Scrapeless क्यों चुनें?
✅ बहुत कम कीमत, केवल $0.1 प्रति 1,000 क्वेरी
अपना खुद का क्रॉलर बनाने, प्रॉक्सी IP को बनाए रखने और एंटी-क्रॉलिंग तंत्र को दरकिनार करने की तुलना में, SerpApi की कीमत बहुत प्रतिस्पर्धी है, केवल $0.1 प्रति 1,000 क्वेरी, जो डेटा अधिग्रहण की लागत को बहुत कम कर देती है।
✅ सुपर तेज प्रतिक्रिया, 3 सेकंड के भीतर डेटा वापस करें
Scrapeless में सुपर तेज डेटा क्रॉलिंग क्षमताएँ हैं, और अनुरोध के 3 सेकंड के भीतर संरचित JSON डेटा वापस कर सकता है, जो पारंपरिक क्रॉलर की प्रसंस्करण गति से बहुत तेज है।
✅ रखरखाव-मुक्त, IP ब्लॉकिंग और एंटी-क्रॉलिंग तंत्र के बारे में चिंता करने की आवश्यकता नहीं है
Google असामान्य ट्रैफ़िक का पता लगाएगा और IP को ब्लॉक करेगा, और यहाँ तक कि सत्यापन कोड सत्यापन की भी आवश्यकता होगी। Scrapeless सभी एंटी-क्रॉलिंग समस्याओं को संभालता है ताकि यह सुनिश्चित हो सके कि API अनुरोध हमेशा उपलब्ध हों और CAPTCHA या IP प्रतिबंधों को ट्रिगर न करें।
✅ सटीक खोज, मांग पर समाचार डेटा फ़िल्टर करें
आप सबसे प्रासंगिक डेटा प्राप्त करने और बेकार जानकारी से हस्तक्षेप से बचने के लिए कीवर्ड, रिलीज़ समय, समाचार स्रोत और अन्य शर्तों के आधार पर समाचार को फ़िल्टर कर सकते हैं।
Scrapeless Google News API
🔹 बहुत कम कीमत – केवल $0.1 प्रति 1,000 क्वेरी
🔹 सुपर तेज गति – 3 सेकंड के भीतर डेटा वापस किया गया
🔹 स्थिर और कुशल – कोई IP ब्लॉकिंग नहीं, कोई रखरखाव की आवश्यकता नहीं
👉 Google News डेटा को आसानी से स्क्रैप करने के लिए अभी Scrapeless आज़माएँ!
Scrapeless डीप SerpAPI: एक तेज और व्यापक डेटा क्रॉलिंग समाधान

यदि आपको अधिक व्यापक और कुशल डेटा अधिग्रहण समाधान की आवश्यकता है, तो Scrapeless डीप SerpAPI निश्चित रूप से आजमाने लायक है!
✅ व्यापक डेटा कवरेज – 20+ Google खोज API परिदृश्य इंटरफ़ेस
✅ वास्तविक समय डेटा अपडेट – पिछले 24 घंटों का डेटा किसी भी समय उपलब्ध है
✅ अल्ट्रा-लो कॉस्ट – केवल $0.10 प्रति 1,000 क्वेरी
✅ सुपर तेज प्रतिक्रिया – डेटा 1-2 सेकंड में वापस आ जाता है, पारंपरिक API से कहीं अधिक
👉 अभी Scrapeless डीप SerpAPI आज़माएँ और आसानी से Google खोज डेटा क्रॉल करें!
मुफ़्त डेवलपर सपोर्ट:
अपने AI टूल, एप्लिकेशन या प्रोजेक्ट में Scrapeless डीप SerpApi को एकीकृत करें (हम पहले से ही Dify को सपोर्ट करते हैं, और भविष्य में Langchain, Langflow, FlowiseAI और अन्य फ्रेमवर्क को सपोर्ट करेंगे)।
सोशल मीडिया पर अपने एकीकरण परिणाम साझा करें और आपको प्रति माह 500K उपयोग तक, 1 से 12 महीने का मुफ़्त डेवलपर सपोर्ट मिलेगा।
अपने प्रोजेक्ट को बेहतर बनाने और अधिक विकास सहायता का आनंद लेने के इस अवसर का लाभ उठाएँ!
निष्कर्ष
इस लेख में, हमने पता लगाया कि Python का उपयोग करके Google News को कैसे स्क्रैप किया जाए। यह ध्यान दिया जाना चाहिए कि सामग्री को स्क्रैप करते समय, आपको कानूनी अनुपालन सुनिश्चित करने के लिए Google की उपयोग नीतियों और प्रतिबंधों का पालन करना होगा।
संबंधित संसाधन
Kayak से फ़्लाइट डेटा कैसे स्क्रैप करें
PowerShell के साथ Selenium का उपयोग कैसे करें
Scrapeless का उपयोग करके आसानी से जॉब सूचियाँ बनाने के लिए Google जॉब स्क्रैप करें
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


