
आप स्क्रैपलेस पर कौन से उत्तर पैरामीटर प्राप्त कर सकते हैं?
Senior Web Scraping Engineer
आधुनिक वेब डेटा स्क्रैपिंग परिदृश्यों में, बस HTML पृष्ठों को पुनः प्राप्त करना अक्सर व्यवसाय की आवश्यकताओं को पूरा करने में अपर्याप्त साबित होता है जब इसे जटिल एंटी-स्क्रैपिंग तंत्रों का सामना करना पड़ता है। Scrapeless में, हम डेवलपर के दृष्टिकोण से अपने उत्पाद क्षमताओं को बढ़ावा देने के लिए प्रतिबद्ध हैं।
आज, हम Scrapeless की एक मुख्य सेवा — यूनिवर्सल स्क्रैपिंग API में एक बड़ा अपडेट घोषित करते हुए रोमांचित हैं। वेब अनलॉकर अब कई प्रतिक्रिया स्वरूपों का समर्थन करता है! यह सुधार API की लचीलापन को काफी बढ़ाता है, उद्यम उपयोगकर्ताओं और डेवलपर्स के लिए डेटा स्क्रैपिंग अनुभव को अधिक अनुकूलनीय और प्रभावी बनाता है।
हम अपडेट क्यों करते हैं?
पहले, यूनिवर्सल स्क्रैपिंग API HTML पृष्ठ सामग्री को लौटाने के लिए डिफॉल्ट था, जो अनएन्क्रिप्टेड पृष्ठों या कमजोर एंटी-स्क्रैपिंग उपायों वाले वेबसाइटों को तेजी से एक्सेस करने के लिए अच्छा काम करता था। हालाँकि, जैसे-जैसे ऑटोमेशन की मांग बढ़ी, हमने देखा कि कई उपयोगकर्ताओं को HTML प्राप्त करने के बाद भी डेटा संरचनाओं को मैन्युअल रूप से प्रोसेस करने, सामग्री को साफ करने, और तत्वों को निकालने की आवश्यकता थी—जिससे अनावश्यक विकास ओवरहेड बढ़ गया। क्या हम इस प्रक्रिया को एक ही कदम में पूर्व-प्रसंस्कृत सामग्री प्रदान करने के लिए चिकना कर सकते हैं?
अब आप ऐसा कर सकते हैं!
हमने प्रतिक्रिया तर्क (response logic) को पुनर्निर्मित किया है। response_type पैरामीटर को कॉन्फ़िगर करके, डेवलपर इच्छित डेटा स्वरूप को लचीले ढंग से निर्दिष्ट कर सकते हैं। चाहे आपको कच्चा HTML, साधारण पाठ, या संरचित मेटाडेटा चाहिए, बस एक सरल पैरामीटर कॉन्फ़िगरेशन की आवश्यकता है।
अब, आप जो प्रतिक्रिया स्वरूप प्राप्त कर सकते हैं:
वर्तमान में समर्थित स्वरूपों में निम्नलिखित शामिल हैं, लेकिन इन्हीं तक सीमित नहीं हैं:
- JSON आउटपुट फ़िल्टर: JSON स्वरूपित डेटा को फ़िल्टर करने के लिए
outputsपैरामीटर का उपयोग करें। अनुमति प्राप्त फ़िल्टर प्रकारईमेल,फोन नंबर,हेडिंग, और 9 अन्य शामिल हैं, और परिणाम संरचित JSON में लौटाए जाते हैं। - कई वापस लौटने वाले स्वरूप: JSON फ़िल्टरिंग के अलावा, आप अनुरोध में
response_typeपैरामीटर को जोड़कर प्रतिक्रिया स्वरूप को सीधे निर्दिष्ट कर सकते हैं (जैसे,response_type=plaintext)।
वर्तमान में समर्थित स्वरूपों में शामिल हैं:
HTML: HTML स्वरूप में पृष्ठ सामग्री को निकाले (स्थिर पृष्ठों के लिए आदर्श)।Plaintext: स्क्रैप की गई सामग्री को साधारण पाठ के रूप में लौटाता है, HTML टैग या मार्कडाउन प्रारूपण के बिना—पाठ प्रसंस्करण या विश्लेषण के लिए आदर्श।Markdown: मार्कडाउन स्वरूप में पृष्ठ सामग्री को निकालता है (स्थिर मार्कडाउन-आधारित पृष्ठों के लिए सर्वोत्तम), पढ़ने और प्रोसेस करने में आसान बनाता है।PNG/JPEG:response_type=pngसेट करके, लक्षित पृष्ठ का स्क्रीनशॉट कैप्चर करता है और इसे PNG या JPEG स्वरूप में लौटाता है (पूर्ण-पृष्ठ स्क्रीनशॉट के विकल्पों के साथ)।
नोट: डिफॉल्ट response_type है html।
चलिए उदाहरणों पर विचार करते हैं
1. JSON लौटाने वाले मूल्य फ़िल्टरिंग:
आप JSON स्वरूप में डेटा को फ़िल्टर करने के लिए outputs पैरामीटर का उपयोग कर सकते हैं। एक बार यह पैरामीटर सेट हो जाने पर, प्रतिक्रिया प्रकार JSON पर फिक्स हो जाएगा।
पैरामीटर कॉमा द्वारा अलग किए गए फ़िल्टर नामों की एक सूची स्वीकार करता है और डेटा को संरचित JSON प्रारूप में लौटाता है। समर्थित फ़िल्टर प्रकारों में शामिल हैं: फोन नंबर, हेडिंग, चित्र, ऑडियो, वीडियो, लिंक, मेनू, हैशटैग, ईमेल, मेटाडेटा, टेबल, और फेविकॉन।
निम्नलिखित नमूना कोड Scrapeless साइट के होमपृष्ठ पर सभी चित्रों की जानकारी प्राप्त करने का तरीका दर्शाता है:
जावास्क्रिप्ट
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com",
js_render: true,
outputs: "images"
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('outputs.json', response.data.data, 'utf8');
}
})();पायथन
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com",
"js_render": True,
"outputs": "images",
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('outputs.json', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- परिणाम:
JSON
{
"images": [
"data:image/svg+xml;base64,PHN2ZyBzdHJva2U9IiNGRkZGRkYiIGZpbGw9IiNGRkZGRkYiIHN0cm9rZS13aWR0aD0iMCIgdmlld0JveD0iMCAwIDI0IDI0IiBoZWlnaHQ9IjIwMHB4IiB3aWR0aD0iMjAwcHgiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PHJlY3Qgd2lkdGg9IjIwIiBoZWlnaHQ9IjIwIiB4PSIyIiB5PSIyIiBmaWxsPSJub25lIiBzdHJva2Utd2lkdGg9IjIiIHJ4PSIyIj48L3JlY3Q+PC9zdmc+Cg==",
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fcode%2Fcode-l.jpg&w=3840&q=75",
plaintext
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fregulate-compliance.png&w=640&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Falex-johnson.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fdeep-serp-api-online%2Fd723e1e516e3dd956ba31c9671cde8ea.jpeg&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fscrapeless-web-scraping-toolkit%2Fac20e5f6aaec5c78c5076cb254c2eb78.png&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Femily-chen.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fgoogle-shopping-scrape%2F251f14aedd946d0918d29ef710a1b385.png&w=3840&q=75"
Plain Text
# Scrapeless API
## डॉक्यूमेंटेशन
- स्क्रैपिंग ब्राउज़र [CDP API](https://apidocs.scrapeless.com/doc-801748.md):
- स्क्रैपिंग API > शॉपिंग [एक्टर सूची](https://apidocs.scrapeless.com/doc-754333.md):
- स्क्रैपिंग API > अमेज़न [API पैरामीटर](https://apidocs.scrapeless.com/doc-857373.md):
- स्क्रैपिंग API > गूगल सर्च [API पैरामीटर](https://apidocs.scrapeless.com/doc-800321.md):
- स्क्रैपिंग API > गूगल ट्रेंड्स [API पैरामीटर](https://apidocs.scrapeless.com/doc-796980.md):
- स्क्रैपिंग API > गूगल फ्लाइट्स [API पैरामीटर](https://apidocs.scrapeless.com/doc-796979.md):
- स्क्रैपिंग API > गूगल फ्लाइट्स चार्ट [API पैरामीटर](https://apidocs.scrapeless.com/doc-908741.md):
- स्क्रैपिंग API > गूगल मानचित्र [API पैरामीटर (Google मानचित्र)](https://apidocs.scrapeless.com/doc-834792.md):
- स्क्रैपिंग API > गूगल मानचित्र [API पैरामीटर (Google मानचित्र ऑटोपूर्ण)](https://apidocs.scrapeless.com/doc-834799.md):
- स्क्रैपिंग API > गूगल मानचित्र [API पैरामीटर (Google मानचित्र योगदानकर्ता समीक्षाएं)](https://apidocs.scrapeless.com/doc-834806.md):
- स्क्रैपिंग API > गूगल मानचित्र [API पैरामीटर (Google मानचित्र दिशा-निर्देश)](https://apidocs.scrapeless.com/doc-834821.md):
- स्क्रैपिंग API > गूगल मानचित्र [API पैरामीटर (Google मानचित्र समीक्षाएं)](https://apidocs.scrapeless.com/doc-834831.md):
- स्क्रैपिंग API > गूगल स्कॉलर [API पैरामीटर (Google स्कॉलर)](https://apidocs.scrapeless.com/doc-842638.md):
- स्क्रैपिंग API > गूगल स्कॉलर [API पैरामीटर (Google स्कॉलर लेखक)](https://apidocs.scrapeless.com/doc-842645.md):
- स्क्रैपिंग API > गूगल स्कॉलर [API पैरामीटर (Google स्कॉलर उद्धरण)](https://apidocs.scrapeless.com/doc-842647.md):
- स्क्रैपिंग API > गूगल स्कॉलर [API पैरामीटर (Google स्कॉलर प्रोफाइल)](https://apidocs.scrapeless.com/doc-842649.md):
- स्क्रैपिंग API > गूगल जॉब्स [API पैरामीटर](https://apidocs.scrapeless.com/doc-850038.md):
- स्क्रैपिंग API > गूगल शॉपिंग [API पैरामीटर](https://apidocs.scrapeless.com/doc-853695.md):
- स्क्रैपिंग API > गूगल होटेल्स [API पैरामीटर](https://apidocs.scrapeless.com/doc-865231.md):
- स्क्रैपिंग API > गूगल होटेल्स [समर्थित Google छुट्टियों के किराए की संपत्ति प्रकार](https://apidocs.scrapeless.com/doc-890578.md):
- स्क्रैपिंग API > गूगल होटेल्स [समर्थित Google होटेल संपत्ति प्रकार](https://apidocs.scrapeless.com/doc-890580.md):
- स्क्रैपिंग API > गूगल होटेल्स [समर्थित Google छुट्टियों के किराए की सुविधाएं](https://apidocs.scrapeless.com/doc-890623.md):
- स्क्रैपिंग API > गूगल होटेल्स [समर्थित Google होटेल सुविधाएं](https://apidocs.scrapeless.com/doc-890631.md):
- स्क्रैपिंग API > गूगल न्यूज़ [API पैरामीटर](https://apidocs.scrapeless.com/doc-866643.md):
- स्क्रैपिंग API > गूगल लेंस [API पैरामीटर](https://apidocs.scrapeless.com/doc-866644.md):
- स्क्रैपिंग API > गूगल फाइनेंस [API पैरामीटर](https://apidocs.scrapeless.com/doc-873763.md):
- स्क्रैपिंग API > गूगल प्रोडक्ट [API पैरामीटर](https://apidocs.scrapeless.com/doc-880407.md):
- स्क्रैपिंग API [गूगल प्ले स्टोर](https://apidocs.scrapeless.com/folder-3277506.md):
- स्क्रैपिंग API > गूगल प्ले स्टोर [API पैरामीटर](https://apidocs.scrapeless.com/doc-882690.md):
- स्क्रैपिंग API > गूगल प्ले स्टोर [समर्थित Google प्ले श्रेणियां](https://apidocs.scrapeless.com/doc-882822.md):
- स्क्रैपिंग API > गूगल विज्ञापन [API पैरामीटर](https://apidocs.scrapeless.com/doc-881439.md):
- यूनिवर्सल स्क्रैपिंग API [JS रेंडर डॉक](https://apidocs.scrapeless.com/doc-801406.md):
## API डॉक
- उपयोगकर्ता [उपयोगकर्ता जानकारी प्राप्त करें](https://apidocs.scrapeless.com/api-11949851.md): वर्तमान में प्रमाणित उपयोगकर्ता के बारे में बुनियादी जानकारी प्राप्त करें, जिसमें उनके खाते का बैलेंस और सब्सक्रिप्शन योजना की जानकारी शामिल है।
- स्क्रैपिंग ब्राउज़र [संयोग](https://apidocs.scrapeless.com/api-11949901.md):
- स्क्रैपिंग ब्राउज़र [चल रहे सत्र](https://apidocs.scrapeless.com/api-16890953.md): सभी चल रहे सत्र प्राप्त करें
- स्क्रैपिंग ब्राउज़र [लाइव यूआरएल](https://apidocs.scrapeless.com/api-16891208.md): सत्र कार्य आईडी द्वारा किसी चल रहे सत्र का लाइव यूआरएल प्राप्त करें
- स्क्रैपिंग API > शॉपिंग [शॉपिंग उत्पाद](https://apidocs.scrapeless.com/api-11953650.md):
- स्क्रैपिंग API > शॉपिंग [शॉपिंग खोज](https://apidocs.scrapeless.com/api-11954010.md):
- स्क्रैपिंग API > शॉपिंग [शॉपिंग सिफारिश](https://apidocs.scrapeless.com/api-11954111.md):
- स्क्रैपिंग API > ब्राज़ील साइटें [Solucoes cnpjreva](https://apidocs.scrapeless.com/api-11954435.md): लक्षित यूआरएल `https://solucoes.receita.fazenda.gov.br/servicos/cnpjreva/valida_recaptcha.asp`
- स्क्रैपिंग API > ब्राज़ील साइटें [Solucoes certidaointernet](https://apidocs.scrapeless.com/api-12160439.md): लक्षित यूआरएल `https://solucoes.receita.fazenda.gov.br/Servicos/certidaointernet/pj/emitir`Here is the translated text in Hindi:
- स्क्रैपिंग एपीआई > ब्राजील की साइटें सेविकॉस receitas: लक्ष्य यूआरएल
https://servicos.receita.fazenda.gov.br/servicos/cpf/consultasituacao/ConsultaPublica.asp - स्क्रैपिंग एपीआई > ब्राजील की साइटें कन्सॉप्ट: लक्ष्य यूआरएल
https://consopt.www8.receita.fazenda.gov.br/consultaoptantes - स्क्रैपिंग एपीआई > अमेज़ॅन उत्पाद:
- स्क्रैपिंग एपीआई > अमेज़ॅन बेचने वाला:
- स्क्रैपिंग एपीआई > अमेज़ॅन कीवर्ड:
- स्क्रैपिंग एपीआई > गूगल खोज गूगल खोज:
- स्क्रैपिंग एपीआई > गूगल खोज गूगल इमेजेस:
- स्क्रैपिंग एपीआई > गूगल खोज गूगल लोकल:
- स्क्रैपिंग एपीआई > गूगल ट्रेंड्स ऑटो komplite:
- स्क्रैपिंग एपीआई > गूगल ट्रेंड्स समय के साथ रुचि:
- स्क्रैपिंग एपीआई > गूगल ट्रेंड्स क्षेत्र के अनुसार तुलना:
- स्क्रैपिंग एपीआई > गूगल ट्रेंड्स उपक्षेत्र द्वारा रुचि:
- स्क्रैपिंग एपीआई > गूगल ट्रेंड्स संबंधित खोजें:
- स्क्रैपिंग एपीआई > गूगल ट्रेंड्स संबंधित विषय:
- स्क्रैपिंग एपीआई > गूगल ट्रेंड्स अभी ट्रेंडिंग:
- स्क्रैपिंग एपीआई > गूगल फ्लाइट्स राउंड ट्रिप:
- स्क्रैपिंग एपीआई > गूगल फ्लाइट्स वन वे:
- स्क्रैपिंग एपीआई > गूगल फ्लाइट्स मल्टी-सिटी:
- स्क्रैपिंग एपीआई > गूगल फ्लाइट्स चार्ट चार्ट:
- स्क्रैपिंग एपीआई > गूगल मैप्स गूगल मैप्स:
- स्क्रैपिंग एपीआई > गूगल मैप्स गूगल मैप्स ऑटो कम्प्लीट:
- स्क्रैपिंग एपीआई > गूगल मैप्स गूगल मैप्स योगदानकर्ता समीक्षाएँ:
- स्क्रैपिंग एपीआई > गूगल मैप्स गूगल मैप्स दिशाएँ:
- स्क्रैपिंग एपीआई > गूगल मैप्स गूगल मैप्स समीक्षाएँ:
- स्क्रैपिंग एपीआई > गूगल स्कॉलर गूगल स्कॉलर:
- स्क्रैपिंग एपीआई > गूगल स्कॉलर गूगल स्कॉलर लेखक:
- स्क्रैपिंग एपीआई > गूगल स्कॉलर गूगल स्कॉलर उद्धरण:
- स्क्रैपिंग एपीआई > गूगल स्कॉलर गूगल स्कॉलर प्रोफाइल:
- स्क्रैपिंग एपीआई > गूगल जॉब्स गूगल जॉब्स:
- स्क्रैपिंग एपीआई > गूगल शॉपिंग गूगल शॉपिंग:
- स्क्रैपिंग एपीआई > गूगल होटल्स गूगल होटल्स:
- स्क्रैपिंग एपीआई > गूगल न्यूज़ गूगल न्यूज़:
- स्क्रैपिंग एपीआई > गूगल लेंस गूगल लेंस:
- स्क्रैपिंग एपीआई > गूगल फाइनेंस गूगल फाइनेंस:
- स्क्रैपिंग एपीआई > गूगल फाइनेंस गूगल फाइनेंस मार्केट्स:
- स्क्रैपिंग एपीआई > गूगल उत्पाद गूगल उत्पाद:
- स्क्रैपिंग एपीआई > गूगल प्ले स्टोर गूगल प्ले गेम्स:
- स्क्रैपिंग एपीआई > गूगल प्ले स्टोर गूगल प्ले किताबें:
- स्क्रैपिंग एपीआई > गूगल प्ले स्टोर गूगल प्ले फ़िल्में:
- स्क्रैपिंग एपीआई > गूगल प्ले स्टोर गूगल प्ले उत्पाद:
- स्क्रैपिंग एपीआई > गूगल प्ले स्टोर गूगल प्ले ऐप्स:
- स्क्रैपिंग एपीआई > गूगल विज्ञापन गूगल विज्ञापन:
- स्क्रैपिंग एपीआई स्क्रैपर अनुरोध:
- स्क्रैपिंग एपीआई स्क्रैपर परिणाम प्राप्त करें:
- यूनिवर्सल स्क्रैपिंग एपीआई जेएस रेंडर:
- यूनिवर्सल स्क्रैपिंग एपीआई वेब अनलॉकर:
- यूनिवर्सल स्क्रैपिंग एपीआई एकामाईवेब कुकी:
- यूनिवर्सल स्क्रैपिंग एपीआई एकामाईवेब सेंसर:
- क्रॉलर > स्क्रैप एकल URL स्क्रैप करें:
- क्रॉलर > स्क्रैप एकाधिक URL स्क्रैप करें:
- क्रॉलर > स्क्रैप एक बैच स्क्रैप नौकरी रद्द करें:
- क्रॉलर > स्क्रैप एक स्क्रैप का स्थिति प्राप्त करें:
- क्रॉलर > स्क्रैप एक बैच स्क्रैप नौकरी की स्थिति प्राप्त करें:
- क्रॉलर > स्क्रैप एक बैच स्क्रैप नौकरी की त्रुटियाँ प्राप्त करें:
- क्रॉलर > क्रॉल विकल्पों के आधार पर एकाधिक URL क्रॉल करें:
- क्रॉलर > क्रॉल एक क्रॉल नौकरी रद्द करें:
- क्रॉलर > क्रॉल एक क्रॉल नौकरी की स्थिति प्राप्त करें:
- क्रॉलर > क्रॉल एक क्रॉल नौकरी की त्रुटियाँ प्राप्त करें:
- सार्वजनिक कार्यकर्ता की स्थिति:
- सार्वजनिक कार्यकर्ता की स्थिति:
4. मार्कडाउन
response_type=markdown को अनुरोध मापदंडों में जोड़ने से, Scrapeless यूनिवर्सल स्क्रैपिंग API किसी विशेष पृष्ठ की सामग्री को मार्कडाउन प्रारूप में लौटाएगा।
निम्नलिखित उदाहरण स्क्रैपिंग ब्राउज़र क्विकस्टार्ट पृष्ठ के मार्कडाउन प्रभाव को दिखाता है। हम पहले पृष्ठ निरीक्षण का उपयोग करके तालिका का CSS चयनकर्ता प्राप्त करते हैं।
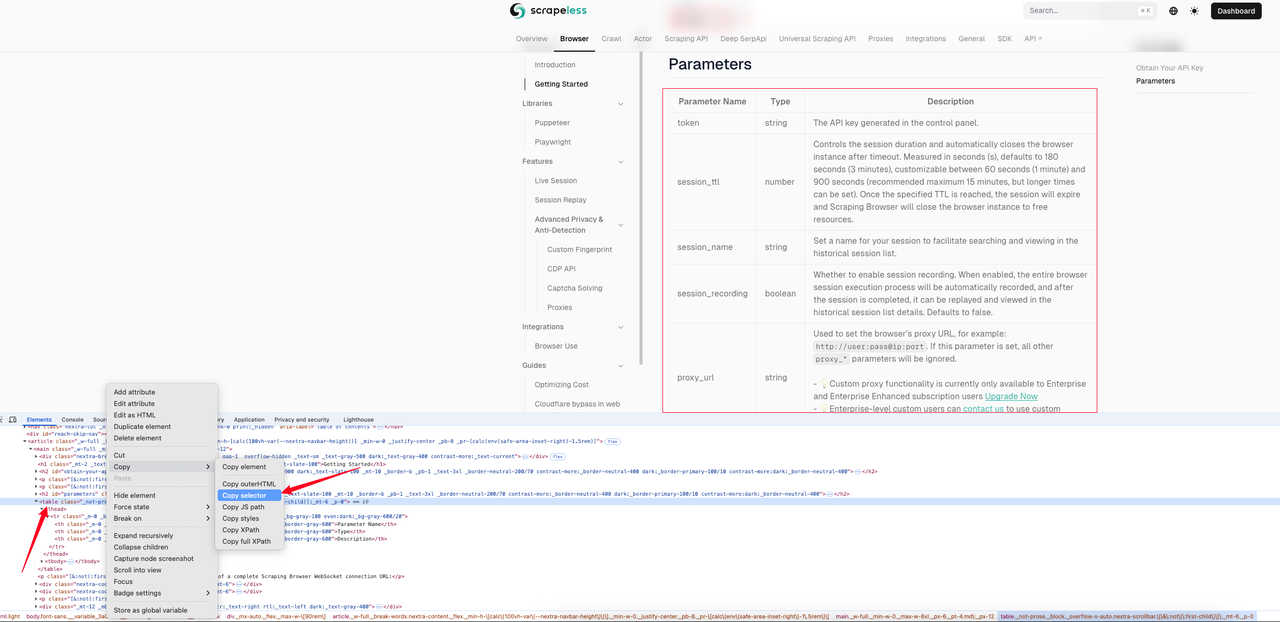
इस उदाहरण में, हमें जो CSS चयनकर्ता मिला है वह है: #__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table। निम्नलिखित संपूर्ण नमूना कोड है।
जावास्क्रिप्ट
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
js_render: true,
response_type: "markdown",
selector: "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", // पृष्ठ तालिका तत्व का CSS चयनकर्ता
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.md', response.data.data, 'utf8');
}
})();पायथन
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
"js_render": True,
"response_type": "markdown",
"selector": "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", # पृष्ठ तालिका तत्व का CSS चयनकर्ता
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.md', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])क्रॉल की गई तालिका के मार्कडाउन पाठ की प्रदर्शनी:
Markdown
| पैरामीटर नाम | प्रकार | विवरण |
| --- | --- | --- |
| token | string | नियंत्रण पैनल में उत्पन्न API कुंजी। |
| session_ttl | number | सत्र की अवधि को नियंत्रित करता है और समय सीमा के बाद स्वचालित रूप से ब्राउज़र उदाहरण को बंद कर देता है। सेकंड (s) में मापा गया, डिफ़ॉल्ट 180 सेकंड (3 मिनट), 60 सेकंड (1 मिनट) और 900 सेकंड के बीच कस्टमाईज़ेबल (अनुशंसित अधिकतम 15 मिनट, लेकिन लंबे समय सीमा सेट किए जा सकते हैं)। एक बार जब निर्दिष्ट TTL पूरा हो जाता है, तो सत्र समय समाप्त हो जाएगा और स्क्रैपिंग ब्राउज़र ब्राउज़र उदाहरण को बंद कर देगा ताकि स्रोत मुक्त हो सके। |
| session_name | string | अपने सत्र का एक नाम सेट करें ताकि ऐतिहासिक सत्र सूची में खोजने और देखने में सहजता हो। |
| session_recording | boolean | क्या सत्र रिकॉर्डिंग सक्षम करना है। जब सक्षम किया जाता है, तो पूरे ब्राउज़र सत्र कार्यान्वयन प्रक्रिया को स्वचालित रूप से रिकॉर्ड किया जाएगा, और सत्र पूरा होने के बाद इसे फिर से चलाया जा सकता है और ऐतिहासिक सत्र सूची विवरण में देखा जा सकता है। डिफ़ॉल्ट सच नहीं है। |
| proxy_url | string | ब्राउज़र के प्रॉक्सी URL को सेट करने के लिए उपयोग किया जाता है, उदाहरण के लिए: http://user:pass@ip:port। यदि यह पैरामीटर सेट किया गया है, तो सभी अन्य proxy_* पैरामीटर की अनदेखी की जाएगी। - 💡कस्टम प्रॉक्सी कार्यक्षमता वर्तमान में केवल एंटरप्राइज और एंटरप्राइज एन्हांस्ड सब्सक्रिप्शन उपयोगकर्ताओं के लिए उपलब्ध है। अभी अपग्रेड करें - 💡एंटरप्राइज स्तर के कस्टम उपयोगकर्ता कस्टम प्रॉक्सी का उपयोग करने के लिए हमसे संपर्क कर सकते हैं। |Here is the translation to Hindi:
| प्रॉक्सी_देश | स्ट्रिंग | प्रॉक्सी के लिए लक्ष्य देश / क्षेत्र सेट करता है, उस क्षेत्र से आईपी पते के माध्यम से अनुरोध भेजता है। आप एक देश कोड निर्दिष्ट कर सकते हैं (जैसे, अमेरिका के लिए US, यूनाइटेड किंगडम के लिए GB, किसी भी देश के लिए ANY)। सभी समर्थित विकल्पों के लिए देश कोड देखें। |
| फिंगरप्रिंट | स्ट्रिंग | एक ब्राउज़र फिंगरप्रिंट आपके ब्राउज़र और डिवाइस कॉन्फ़िगरेशन सूचना का उपयोग करके बनाया गया एक लगभग अद्वितीय “डिजिटल फिंगरप्रिंट” है, जिसका उपयोग बिना कुकीज़ के भी आपके ऑनलाइन क्रियाकलापों को ट्रैक करने के लिए किया जा सकता है। सौभाग्य से, स्क्रैपिंग ब्राउज़र में फिंगरप्रिंट को कॉन्फ़िगर करना वैकल्पिक है। हम ब्राउज़र फिंगरप्रिंट के गहरे अनुकूलन की पेशकश करते हैं, जैसे कि कोर पैरामीटर जैसे ब्राउज़र उपयोगकर्ता एजेंट, समय क्षेत्र, भाषा, और स्क्रीन रिज़ॉल्यूशन, और कस्टम लॉन्च पैरामीटर के माध्यम से कार्यक्षमता का विस्तार करने का समर्थन करते हैं। मल्टी-खाता प्रबंधन, डेटा संग्रहण, और गोपनीयता संरक्षण परिदृश्य के लिए उपयुक्त, स्क्रैपलेस का अपना क्रोमियम ब्राउज़र पूरी तरह से डिटेक्शन से बचता है। डिफ़ॉल्ट रूप से, हमारी स्क्रैपिंग ब्राउज़र सेवा प्रत्येक सत्र के लिए एक यादृच्छिक फिंगरप्रिंट उत्पन्न करती है। संदर्भ |
### 5. PNG/JPEG
प्रतिक्रिया_प्रकार=PNG अनुरोध में जोड़ने से, आप लक्षित पृष्ठ का स्क्रीनशॉट ले सकते हैं और PNG या JPEG छवि वापस कर सकते हैं। जब प्रतिक्रिया परिणाम PNG या JPEG में सेट होता है, तो आप यह सेट कर सकते हैं कि क्या लौटाया गया परिणाम फुल स्क्रीन है या नहीं, `response_image_full_page=true` पैरामीटर का उपयोग करके। इस पैरामीटर का डिफ़ॉल्ट मान फॉल्स है।
निम्नलिखित कोड उदाहरण [स्क्रैपलेस वेबपृष्ठ](https://www.scrapeless.com/?utm_source=official&utm_medium=blog&utm_campaign=response-formats-update) पर निर्दिष्ट क्षेत्र का स्क्रीनशॉट प्राप्त करने का तरीका दिखाता है। पहले, हम उस क्षेत्र के लिए CSS चयनकर्ता को खोजते हैं जिसे हम छवि में कैप्चर करना चाहते हैं।
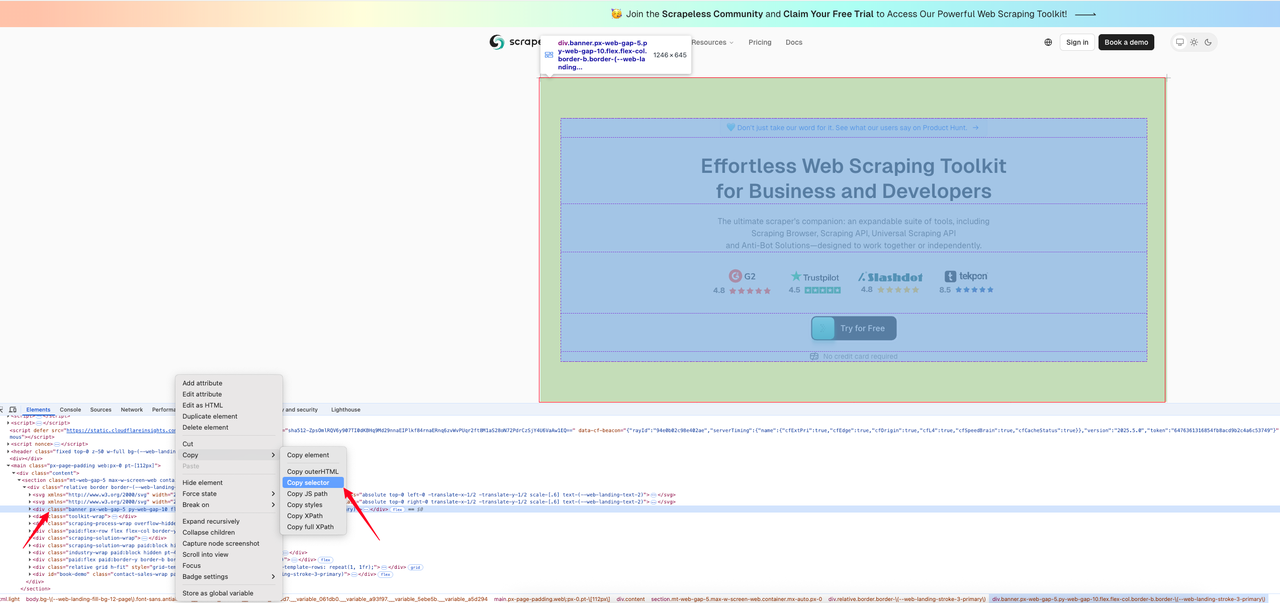
नीचे इंटरसेप्शन कोड है:
> जावास्क्रिप्ट
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com/en",
js_render: true,
response_type: "png",
selector: "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", // पृष्ठ तालिका तत्व का CSS चयनकर्ता
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.png',Buffer.from(response.data.data, 'base64'));
}
})(); पायथन
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com/en",
"js_render": True,
"response_type": "png",
"selector": "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", # पृष्ठ तालिका तत्व का CSS चयनकर्ता
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.png', 'wb') as f:
content = base64.b64decode(response.json()["data"])
f.write(content)- PNG लौटाने का परिणाम:

👉 स्क्रैपलेस दस्तावेज़ पर और जानें
👉 अभी API दस्तावेज़ देखें: JS रेंडर
उपयोग परिदृश्य पूरी तरह से कवर किए गए हैं
यह अपडेट विशेष रूप से निम्नलिखित के लिए उपयुक्त है:
- कंटेंट निकासी अनुप्रयोग (जैसे संक्षेपण उत्पन्न करना, इंटेलिजेंस संग्रह)
- SEO डेटा क्रॉवलिंग (जैसे मेटा, संरचित डेटा विश्लेषण)
- समाचार संग्रहण प्लेटफ़ॉर्म (टेक्स्ट और लेखक को जल्दी से निकालना)
- लिंक विश्लेषण और निगरानी उपकरण (href, nofollow जानकारी निकालना)
चाहे आप टेक्स्ट को जल्दी से क्रॉल करना चाहते हों या संरचित डेटा चाहते हों, यह अपडेट आपको कम प्रयास में अधिक परिणाम प्राप्त करने में मदद कर सकता है।
इसे अभी अनुभव करें
यह फ़ंक्शन स्क्रैपलेस पर पूरी तरह से लॉन्च हो चुका है। कोई अतिरिक्त प्राधिकरण या अपग्रेड योजना की आवश्यकता नहीं है। बस आउटपुट पैरामीटर को सीमित करें या प्रतिक्रिया_प्रकार पैरामीटर को पास करें और नए डेटा लौटाने के प्रारूप का अनुभव करें!
Scrapeless हमेशा एक बुद्धिमान, स्थिर और उपयोग में आसान वेब डेटा प्लेटफ़ॉर्म बनाने के प्रति प्रतिबद्ध रहा है। यह अपडेट बस एक और कदम आगे है। आपके अनुभव और फीडबैक का स्वागत है, आइए मिलकर वेब डेटा अधिग्रहण को सरल बनाते हैं।
🔗 अभी Scrapeless यूनिवर्सल स्क्रैपिंग एपीआई का प्रयास करें
📣 समुदाय में शामिल हों ताकि आप सबसे पहले अपडेट्स और व्यावहारिक टिप्स प्राप्त कर सकें!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


