
Puppeteer का उपयोग करके Cloudflare को कैसे बायपास करें
Advanced Data Extraction Specialist
डेटा संग्रहण और वेब क्रॉलिंग के क्षेत्र में, डेवलपर्स को अक्सर एक कठिन समस्या का सामना करना पड़ता है: क्लाउडफ्लेयर के सुरक्षा तंत्र को प्रभावी ढंग से कैसे बायपास किया जाए। दुनिया में व्यापक रूप से उपयोग की जाने वाली वेबसाइट सुरक्षा और प्रदर्शन अनुकूलन सेवा के रूप में, क्लाउडफ्लेयर के एंटी-क्रॉलर और फ़ायरवॉल फ़ंक्शन डेटा क्रॉलिंग के लिए काफी चुनौतियाँ लाते हैं। यह समस्या विशेष रूप से तब प्रमुख होती है जब वेब क्रॉलिंग के लिए पपेटियर का उपयोग किया जाता है। यह लेख गहराई से तलाश करेगा कि कैसे स्क्रैपलेस स्क्रैपिंग ब्राउज़र का उपयोग करें, पपेटियर के साथ मिलकर, क्लाउडफ्लेयर की सीमाओं को आसानी से तोड़ने और एक कुशल और स्थिर डेटा संग्रह यात्रा शुरू करने के लिए।
क्लाउडफ्लेयर बॉट्स का कैसे पता लगाता है
क्लाउडफ्लेयर कई तकनीकों के संयोजन का उपयोग करके बॉट्स का पता लगाता है, जिनमें शामिल हैं:
- व्यवहार विश्लेषण - मानव उपयोगकर्ताओं को बॉट्स से अलग करने के लिए माउस मूवमेंट, कीस्ट्रोक, स्क्रॉलिंग व्यवहार और इंटरैक्शन पैटर्न की निगरानी करता है।
- आईपी प्रतिष्ठा - पिछली गतिविधि के आधार पर संदिग्ध आईपी पते की पहचान करने के लिए एक वैश्विक खतरा खुफिया डेटाबेस का उपयोग करता है।
- चुनौती-प्रतिक्रिया परीक्षण - यह सत्यापित करने के लिए कि क्या कोई आगंतुक मानव है, CAPTCHA या जावास्क्रिप्ट चुनौतियों को तैनात करता है।
- फ़िंगरप्रिंटिंग - स्वचालन का पता लगाने के लिए ब्राउज़र विशेषताओं, HTTP हेडर और डिवाइस विशेषताओं का विश्लेषण करता है।
- दर सीमित करना - असामान्य अनुरोध पैटर्न को फ़्लैग करता है, जैसे कि उच्च-आवृत्ति या गैर-मानव ब्राउज़िंग व्यवहार।
- मशीन लर्निंग - बॉट जैसे व्यवहारों की पहचान करने के लिए बड़ी मात्रा में ट्रैफ़िक डेटा पर प्रशिक्षित AI मॉडल का उपयोग करता है।
- TLS फ़िंगरप्रिंटिंग - वास्तविक ब्राउज़र और स्वचालित स्क्रिप्ट के बीच अंतर करने के लिए TLS कनेक्शन कैसे स्थापित किए जाते हैं, इसकी जांच करता है।
- जावास्क्रिप्ट निष्पादन निगरानी - हेडलेस ब्राउज़र और बॉट्स का पता लगाने के लिए जावास्क्रिप्ट ठीक से निष्पादित किया गया है या नहीं, इसकी जाँच करता है जो स्क्रिप्ट को अक्षम करते हैं।
केवल पपेटियर क्लाउडफ्लेयर को बायपास क्यों नहीं कर सकता
यहाँ मुख्य कीवर्ड "बायपास क्लाउडफ्लेयर" के साथ अनुवाद दिया गया है:
1. क्लाउडफ्लेयर के जटिल पता लगाने के तंत्र
क्लाउडफ्लेयर मानव उपयोगकर्ताओं और पपेटियर जैसे स्वचालित उपकरणों के बीच अंतर करने के लिए कई तरीकों का उपयोग करता है, जिसमें व्यवहार विश्लेषण, आईपी प्रतिष्ठा जांच और HTTP फ़िंगरप्रिंटिंग शामिल हैं। ये तंत्र पपेटियर को अकेले क्लाउडफ्लेयर को बायपास करना मुश्किल बनाते हैं।
2. पपेटियर का डिफ़ॉल्ट व्यवहार आसानी से पहचाना जाता है
डिफ़ॉल्ट रूप से, पपेटियर ऐसे व्यवहार प्रदर्शित करता है जो मानव उपयोगकर्ताओं से भिन्न होते हैं, जैसे:
- निश्चित उपयोगकर्ता-एजेंट स्ट्रिंग जो विशिष्ट ब्राउज़रों से मेल नहीं खाते हैं।
- मानव जैसे इंटरैक्शन का अभाव, जैसे कि अप्राकृतिक माउस मूवमेंट या क्लिक पैटर्न।
- विशिष्ट अनुरोध शीर्षलेख जो इसे एक स्वचालित उपकरण के रूप में प्रकट करते हैं।
3. क्लाउडफ्लेयर के चुनौती तंत्र
जब क्लाउडफ्लेयर संदिग्ध ट्रैफ़िक का पता लगाता है, तो यह CAPTCHA या सत्यापन चरणों जैसी चुनौतियों को ट्रिगर करता है। पपेटियर अकेले इन चुनौतियों को हल नहीं कर सकता है, जिससे अतिरिक्त उपकरणों के बिना क्लाउडफ्लेयर को बायपास करना असंभव हो जाता है।
4. अतिरिक्त कॉन्फ़िगरेशन और उपकरणों की आवश्यकता
क्लाउडफ्लेयर को बायपास करने के लिए, पपेटियर को अतिरिक्त सेटअप की आवश्यकता होती है, जैसे:
- यादृच्छिक देरी और यथार्थवादी इंटरैक्शन के साथ मानव व्यवहार का अनुकरण करना।
- आईपी प्रतिबंध से बचने के लिए प्रॉक्सी आईपी का उपयोग करना।
- वास्तविक ब्राउज़रों की नकल करने के लिए अनुरोध शीर्षलेखों को संशोधित करना।
- 2 कैप्चा जैसी CAPTCHA-समाधान सेवाओं को एकीकृत करना।
5. लगातार अपडेट किए गए पता लगाने के नियम
क्लाउडफ्लेयर नियमित रूप से अपने पता लगाने वाले एल्गोरिदम को अपडेट करता है, जिससे पुराने बायपास तरीके समय के साथ अप्रभावी हो जाते हैं।
संक्षेप में, पपेटियर अकेले क्लाउडफ्लेयर के पता लगाने को बायपास करने के लिए संघर्ष करता है। मानव व्यवहार का अनुकरण करने और क्लाउडफ्लेयर की चुनौतियों को प्रभावी ढंग से संभालने के लिए इसे अन्य तकनीकों और उपकरणों के साथ जोड़ने की आवश्यकता है।
विधि #1: पपेटियर-एक्स्ट्रा-प्लगइन-स्टील्थ का उपयोग करके क्लाउडफ्लेयर को बायपास करें
पपेटियर-एक्स्ट्रा-प्लगइन-स्टील्थ एक पैच है जो पपेटियर के स्वचालित ब्राउज़र गुणों को मास्क करके क्लाउडफ्लेयर को बायपास करने में मदद करता है, जिससे यह एक वास्तविक ब्राउज़र की तरह दिखाई देता है।
उदाहरण के लिए, स्टील्थ प्लगिन वेबड्राइवर संपत्ति को ओवरराइड करता है और स्वचालन संकेतों को मास्क करने के लिए हेडलेसक्रोम फ़्लैग को क्रोम से बदल देता है। यह अन्य वैध ब्राउज़र गुणों, जैसे क्रोम.रनटाइम का भी मजाक उड़ाता है, जिससे यह हेडलेस मोड में भी हेडफुल दिखाई देता है।
पपेटियर स्टील्थ प्लगिन बेस पपेटियर के समान एपीआई का उपयोग करता है, इसलिए पहले से ही पपेटियर का उपयोग कर रहे डेवलपर्स के लिए कोई लर्निंग कर्व नहीं है।
आइए देखें कि पपेटियर स्टील्थ कैसे काम करता है, यह देखने के लिए एक साधारण क्लाउडफ्लेयर सुरक्षा वाली वेबसाइट, कॉइनट्रैकर को बायपास करें।
सबसे पहले, प्लगइन स्थापित करें:
npm install puppeteer-extra puppeteer-extra-plugin-stealthअब, आवश्यक पुस्तकालयों को आयात करें और स्टील्थ प्लगइन जोड़ें। फिर, संरक्षित वेबसाइट का अनुरोध करें और इसके होमपेज का स्क्रीनशॉट लें:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'load',
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();पपेटियर स्टील्थ प्लगइन क्लाउडफ्लेयर को बायपास करता है और वेबसाइट के होमपेज का स्क्रीनशॉट लेता है, जैसा कि दिखाया गया है:
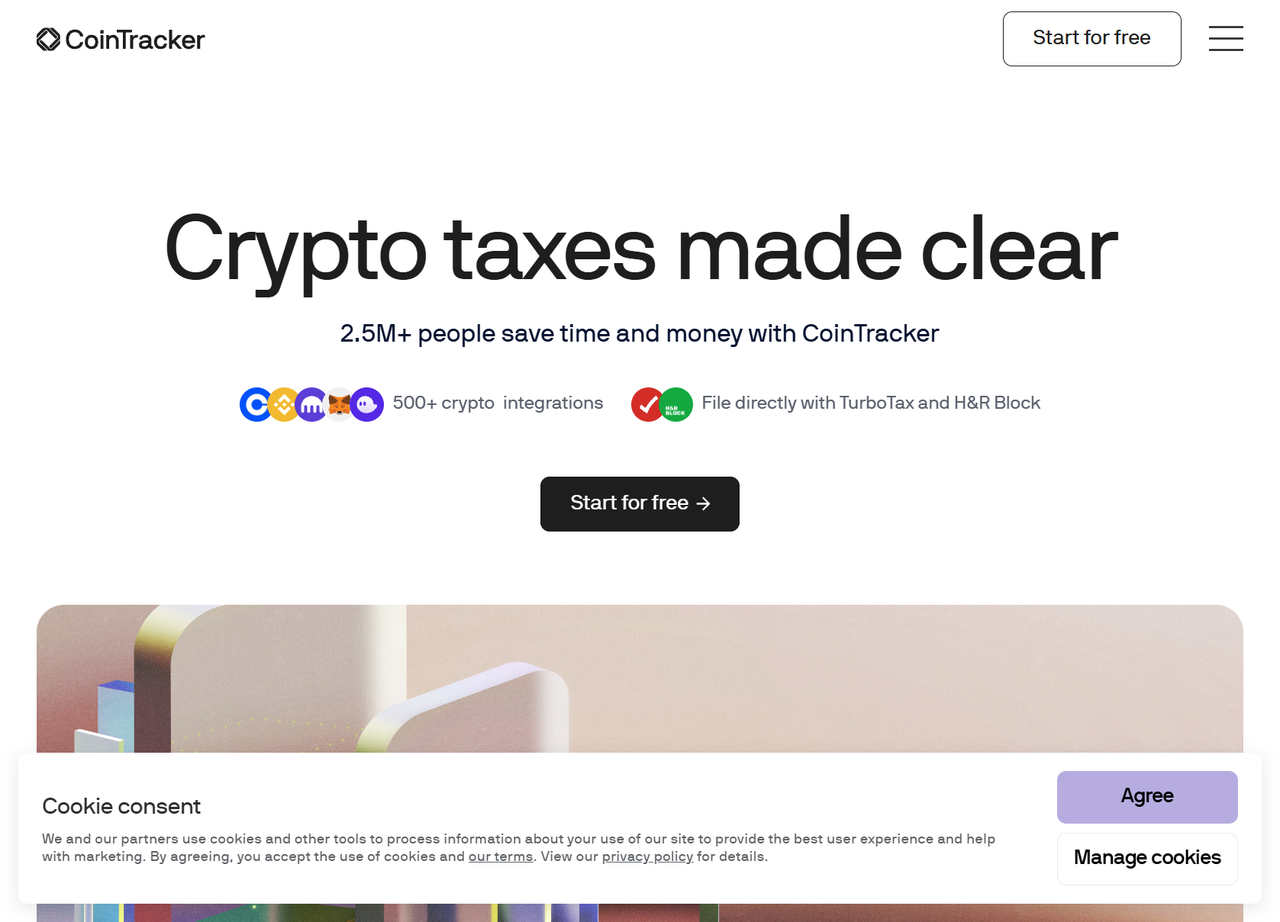
आपने सफलतापूर्वक क्लाउडफ्लेयर के पता लगाने से बच निकला है।
निश्चित रूप से, वर्तमान लक्षित वेबसाइट तक पहुँचना आसान है क्योंकि यह किसी भी परिष्कृत पता लगाने की तकनीकों को लागू नहीं करता है।
क्या पपेटियर स्टील्थ प्लगइन अधिक उन्नत सुरक्षा उपायों को संभाल सकता है? उत्तर है...
स्टील्थ प्लगइन ब्लॉक हो गया है, जैसा कि चित्र में दिखाया गया है।
पपेटियर स्टील्थ प्लगइन की सीमाएँ
कुछ वेबसाइटें दूसरों की तुलना में अधिक उन्नत क्लाउडफ्लेयर सुरक्षा जांच का उपयोग करती हैं। ऐसे मामलों में, पपेटियर-एक्स्ट्रा-प्लगइन-स्टील्थ क्लाउडफ्लेयर चोरी तकनीक का उपयोग करके पपेटियर के स्वचालन गुणों को मास्क करना पार पाने के लिए अपर्याप्त है।
उदाहरण के लिए, क्लाउडफ्लेयर चुनौती पृष्ठ तक पहुँचने का प्रयास करते समय पपेटियर स्टील्थ ब्लॉक हो गया।
पिछले लक्षित URL को चुनौती पृष्ठ URL से बदलकर इसे स्वयं आज़माएँ:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();स्टील्थ प्लगइन ब्लॉक हो गया, जैसा कि दिखाया गया है:
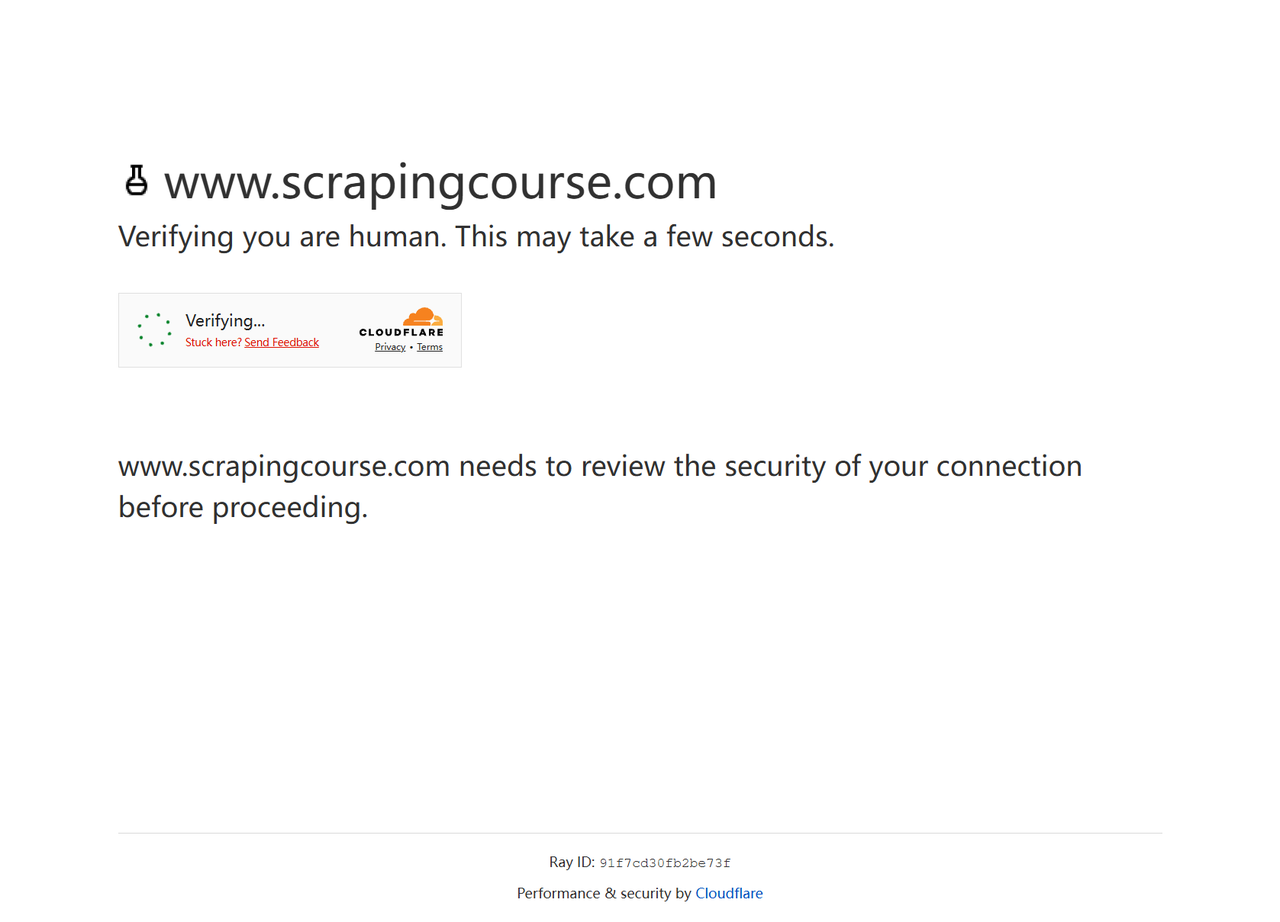
परिणाम बताते हैं कि एक अधिक उन्नत क्लाउडफ्लेयर एंटी-बॉट सिस्टम ने स्टील्थ प्लगइन को बॉट के रूप में पहचाना। स्टील्थ प्लगइन में अभी भी कुछ पता लगाने योग्य लक्षण हैं, जैसे असंगत WebGL या कैनवस रेंडरिंग, जो इसे बॉट के रूप में दे रहा है।
आप इन सीमाओं को कैसे हल कर सकते हैं और जटिल वेबसाइटों से डेटा निकाल सकते हैं? उत्तर है स्क्रैपलेस।
विधि 2: स्क्रैपलेस और पपेटियर का उपयोग करके क्लाउडफ्लेयर को बायपास करें
पपेटियर और इसके स्टील्थ प्लगइन की सीमाओं से बचने का सबसे आसान तरीका लाइब्रेरी को स्क्रैपलेस स्क्रैपिंग ब्राउज़र के साथ एकीकृत करना है। स्क्रैपलेस स्क्रैपिंग ब्राउज़र के साथ, आपका पपेटियर स्क्रैपर मानव के रूप में दिखाई देने और एंटी-बॉट डिटेक्शन को बायपास करने के लिए उन्नत चोरी से मजबूत हो जाता है।
आपको बस अपने मौजूदा पपेटियर स्क्रिप्ट में कोड की एक पंक्ति जोड़नी है, और स्क्रैपिंग ब्राउज़र आपको कोर ब्राउज़र फ़िंगरप्रिंटिंग को संभालने, लापता प्लगइन्स और एक्सटेंशन जोड़ने, आवासीय प्रॉक्सी रोटेशन का प्रबंधन करने और बहुत कुछ करने में मदद करेगा।
स्क्रैपिंग ब्राउज़र क्लाउड में भी चलता है, जिससे स्थानीय ब्राउज़र उदाहरणों को चलाने के मेमोरी ओवरहेड को रोका जा सकता है। यह सुविधा इसे अत्यधिक स्केलेबल बनाती है।
स्क्रैपलेस स्क्रैपिंग ब्राउज़र की मुख्य विशेषताएँ
स्क्रैपलेस स्क्रैपिंग ब्राउज़र एक उपकरण है जिसे कुशल और बड़े पैमाने पर वेब डेटा निष्कर्षण के लिए डिज़ाइन किया गया है:
- ब्राउज़र फ़िंगरप्रिंटिंग और TLS फ़िंगरप्रिंटिंग डिटेक्शन जैसे उन्नत एंटी-क्रॉलर तंत्र को बायपास करने के लिए वास्तविक मानव संपर्क व्यवहारों का अनुकरण करें।
- निर्बाध क्रॉलिंग प्रक्रिया सुनिश्चित करने के लिए cf_challenge सहित कई प्रकार के सत्यापन कोड के स्वचालित समाधान का समर्थन करें।
- विकास प्रक्रिया को सरल बनाने और एक पंक्ति कोड के साथ स्वचालित कार्य शुरू करने के समर्थन के लिए पपेटियर और प्लेराइट जैसे लोकप्रिय उपकरणों का सहज एकीकरण।
पपेटियर के साथ स्क्रैपिंग ब्राउज़र को कैसे एकीकृत करें
स्क्रैपलेस को पपेटियर-कोर की आवश्यकता होती है, पपेटियर का एक संस्करण जो क्रोम बाइनरी डाउनलोड नहीं करता है। इसलिए, सुनिश्चित करें कि आप इसे स्थापित करें:
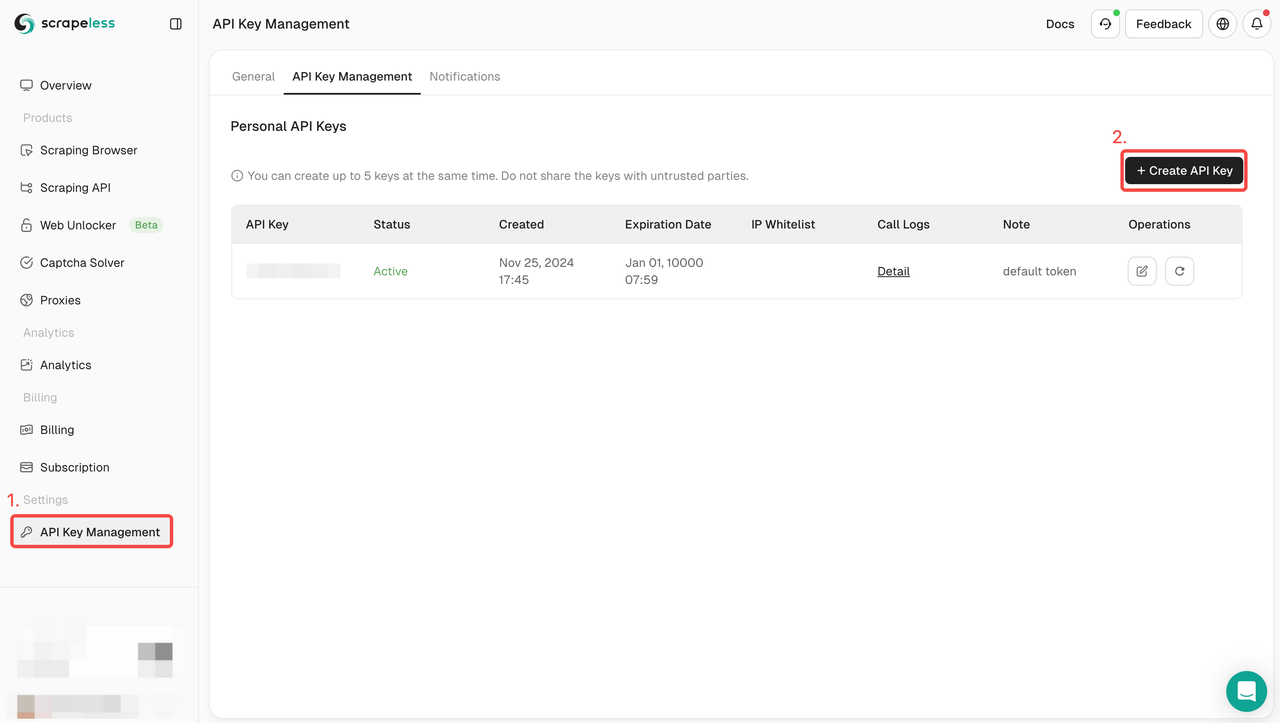
npm install puppeteer-coreचरण 1. स्क्रैपलेस के लिए साइन अप करें, अपनी स्क्रैपलेस एपीआई कुंजी बनाने के लिए एपीआई कुंजी प्रबंधन> एपीआई कुंजी बनाएँ पर क्लिक करें।
स्क्रैपलेस के लिए साइन अप करें और एक मुफ्त परीक्षण प्राप्त करें। यदि आपके कोई प्रश्न हैं, तो आप डिस्कॉर्ड के माध्यम से लियाम से भी संपर्क कर सकते हैं
चरण 2. फिर, स्क्रैपिंग ब्राउज़र पर जाएँ और अपना ब्राउज़र URL कॉपी करें।
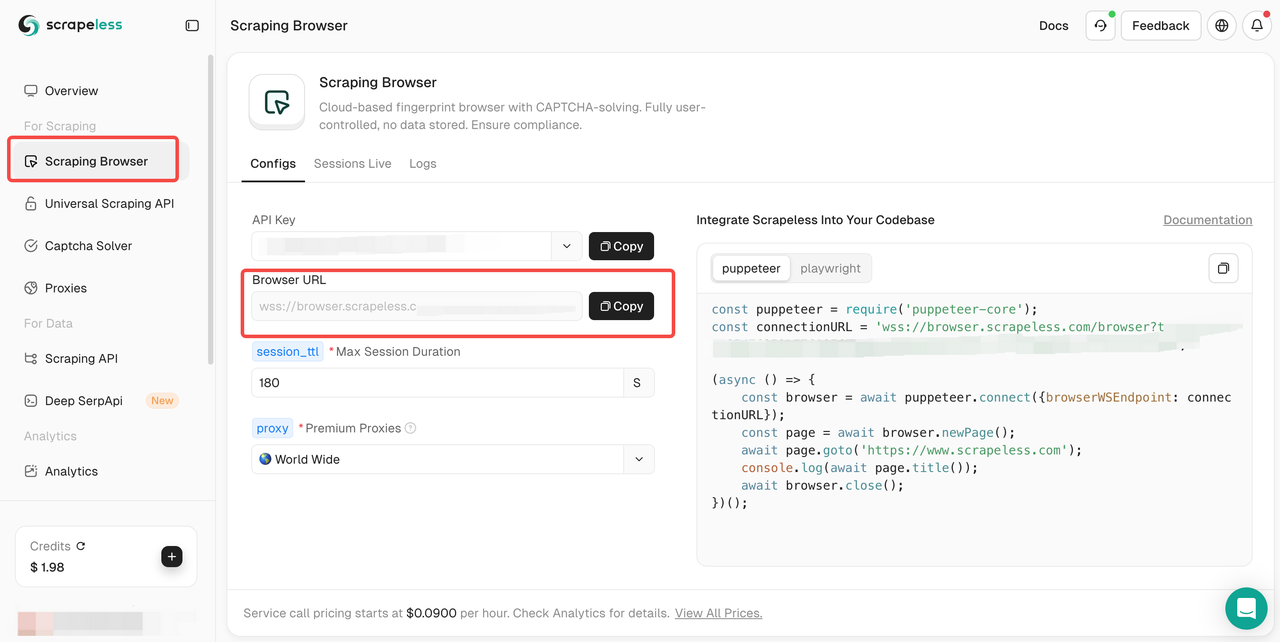
कॉपी किए गए ब्राउज़र URL को अपनी पपेटियर स्क्रिप्ट में इस प्रकार एकीकृत करें:
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// set up browser environment
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// create a new page
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
//take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();आपको https://www.scrapingcourse.com/cloudflare-challenge को किसी भी वेबसाइट के साथ बदलने की आवश्यकता है जिसमें cloudflare-challenge है;
टोकन भाग में अपनी स्क्रैपलेस एपीआई कुंजी भी बदलें।
उपरोक्त कोड संरक्षित पृष्ठ तक पहुँचता है और उसका स्क्रीनशॉट लेता है। नीचे परिणाम देखें:
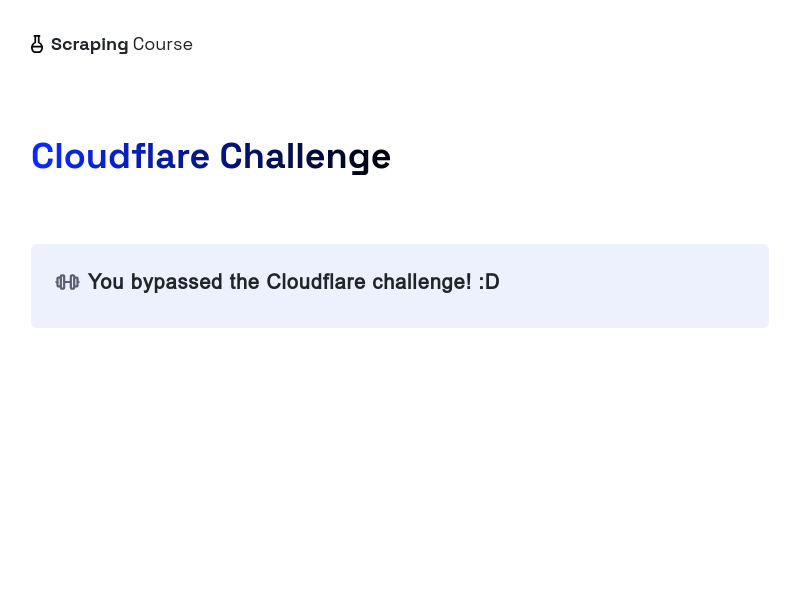
बधाई 🎉! आपने पपेटियर और स्क्रैपलेस का उपयोग करके क्लाउडफ्लेयर को सफलतापूर्वक बायपास कर लिया है।
क्लाउडफ्लेयर को बायपास करने के लिए पपेटियर में स्क्रैपलेस स्क्रैपिंग ब्राउज़र को एकीकृत करने के लाभ
क्लाउडफ्लेयर को बायपास करने के लिए पपेटियर में स्क्रैपलेस स्क्रैपिंग ब्राउज़र को एकीकृत करने से निम्नलिखित लाभ होते हैं:
- बूस्ट एंटी - डिटेक्शन
पपेटियर अकेले में स्पष्ट स्वचालन सुविधाएँ हैं (जैसे, नेविगेटर.वेबड्राइवर विशेषता, हेडलेसक्रोम उपयोगकर्ता - एजेंट ध्वज), जिससे क्लाउडफ्लेयर को बॉट के रूप में पहचानना आसान हो जाता है। स्क्रैपलेस स्क्रैपिंग ब्राउज़र वास्तविक - ब्राउज़र फ़िंगरप्रिंट्स (प्रकार, उपयोगकर्ता - एजेंट, स्क्रीन रिज़ॉल्यूशन, आदि) की नकल कर सकता है, प्रभावी ढंग से पपेटियर की स्वचालन सुविधाओं को छिपा सकता है, क्लाउडफ्लेयर डिटेक्शन के जोखिम को कम कर सकता है और स्क्रैपिंग सफलता दरों को बढ़ा सकता है।
- कॉन्फ़िगरेशन और एकीकरण को सरल बनाएँ
स्क्रैपलेस स्क्रैपिंग ब्राउज़र उपयोग में आसान एपीआई और एकीकरण विधियाँ प्रदान करता है। डेवलपर्स अपनी शक्तिशाली एंटी - डिटेक्शन सुविधाओं का लाभ उठाने के लिए मौजूदा पपेटियर स्क्रिप्ट में कोड की एक छोटी मात्रा जोड़ सकते हैं, बिना पपेटियर के आंतरिक या क्लाउडफ्लेयर के एंटी - क्रॉलिंग तंत्र को समझने की आवश्यकता के। यह विकास बाधाओं और कार्यभार को कम करता है।
- कोड रखरखाव में वृद्धि
स्क्रैपलेस स्क्रैपिंग ब्राउज़र का उपयोग करने से पपेटियर के अंतर्निहित कॉन्फ़िगरेशन और कस्टम स्क्रिप्ट पर निर्भरता कम हो जाती है। यह कोड को साफ और स्पष्ट बनाता है, भविष्य के रखरखाव और उन्नयन की सुविधा प्रदान करता है।
अतिरिक्त संसाधन
क्लाउडफ्लेयर चुनौती पूर्ण गाइड को कैसे बायपास करें
TCP/IP फ़िंगरप्रिंटिंग क्या है?
पायथन के साथ Google समाचार को कैसे स्क्रैप करें
स्क्रैपलेस एपीआई आधिकारिक दस्तावेज़ीकरण
निष्कर्ष
संक्षेप में, पपेटियर के साथ क्लाउडफ्लेयर को बायपास करने के लिए प्रभावी उपकरणों और विधियों की आवश्यकता होती है। स्क्रैपलेस स्क्रैपिंग ब्राउज़र एंटी-डिटेक्शन को बढ़ाकर, एकीकरण को सरल बनाकर और रखरखाव में सुधार करके एक सरल लेकिन शक्तिशाली समाधान प्रदान करता है। स्क्रैपिंग करते समय हमेशा कानूनी अनुपालन सुनिश्चित करें।
अपनी व्यावसायिक दक्षता में सुधार करें और स्क्रैपलेस स्क्रैपिंग ब्राउज़र के उद्यम-स्तरीय अनुकूलित समाधानों का चयन करें। हम पेशेवर और कुशल डेटा संग्रह सेवाएँ प्रदान करते हैं।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


