
जीओ समाधान: स्क्रैपलेस ब्राउज़र के साथ पेचिदगी को ऑटोमेट करें ताकि एक सामग्री विश्लेषण इंजन बनाया जा सके
Expert Network Defense Engineer
AI उत्तरों को व्यावसायिक लाभ में परिवर्तित करें - Scrapeless GEO समाधानों की मदद से आप पकड़ सकते हैं, विश्लेषण कर सकते हैं और कार्य कर सकते हैं।
जनरेटिव इंजन ऑप्टिमाइज़ेशन (GEO) तेजी से खोज उद्योग में एक सबसे विघटनकारी प्रवृत्ति बनती जा रही है। जैसे-जैसे बड़े भाषा मॉडल (LLMs) उपयोगकर्ताओं के लिए जानकारी खोजने, ब्रांडों का मूल्यांकन करने और निर्णय लेने के तरीके को फिर से आकार दे रहे हैं, व्यवसायों को केवल पारंपरिक खोज परिणामों में दिखाई नहीं देना चाहिए, बल्कि यह भी सुनिश्चित करना चाहिए कि उनकी सामग्री AI-जनित उत्तरों में दिखाई दे।
हालांकि, यह एक बड़े पैराडाइम शिफ्ट का केवल एक पहलू है - हम “सर्वत्र खोज” के युग में प्रवेश कर रहे हैं: उपयोगकर्ता अब केवल Google पर निर्भर नहीं हैं, बल्कि विभिन्न AI इंजनों, सहायक अनुप्रयोगों और ऊर्ध्वाधर मॉडलों के माध्यम से उत्तर प्राप्त करते हैं। इस प्रतिस्पर्धी परिदृश्य में, Perplexity आश्चर्यजनक गति से उभर रहा है, न केवल तात्कालिक उत्तर प्रदान कर रहा है बल्कि वास्तविक समय के स्रोत संदर्भ, डेटा पाइपलाइनों, और गहन विश्लेषण को भी पेश कर रहा है, जिससे यह सामग्री अनुसंधान, बाजार अंतर्दृष्टि, और प्रतिस्पर्धी निगरानी के लिए एक आवश्यक उपकरण बन गया है।
स्रोत: Backlinko
लेकिन असली चुनौती यह है: अगर आप अभी भी Perplexity से एक बार में एक प्रश्न पूछ रहे हैं, तो आपकी दक्षता उद्योग की गति के साथ नहीं चल सकती। इसलिए, यह लेख Scrapeless Browser का उपयोग करने का तरीका बताएगा ताकि Perplexity को स्वचालित किया जा सके, इसे एक निरंतर संचालन करने वाले, स्केलेबल सामग्री विश्लेषण इंजन में परिवर्तित किया जा सके जो आपको जनरेटिव खोज के युग में बढ़त देता है।
1. GEO क्या है और यह क्यों महत्वपूर्ण है?
जनरेटिव इंजन ऑप्टिमाइजेशन (GEO) की प्रथा ऐसी सामग्री बनाने और ऑप्टिमाइज करने की है ताकि यह Google AI ओवरव्यू, AI मोड, ChatGPT, और Perplexity जैसी प्लेटफार्मों पर AI-जनित उत्तरों में दिखाई दे।
अतीत में, सफलता का मतलब था खोज इंजन परिणाम पृष्ठों (SERPs) पर उच्च रैंक करना। आगे देखते हुए, "शीर्ष पर" होने की अवधारणा अब अस्तित्व में नहीं हो सकती। इसके बजाय, आपको पसंदीदा सिफारिश बनना होगा - वह समाधान जो AI टूल अपने उत्तरों में प्रस्तुत करने के लिए चुनते हैं।
डेटा खुद के लिए बोलता है:
- Perplexity का उपयोगकर्ता आधार इस वर्ष 100 मिलियन मासिक सक्रिय उपयोगकर्ताओं को पार करते हुए तेजी से बढ़ रहा है, पहले से ही Google के पैमाने का 1/20वां हिस्सा पहुँच चुका है।
- Google AI ओवरव्यू अब प्रति माह अरबों खोजों में दिखाई देते हैं - सभी खोज परिणामों का कम से कम 13% कवर करते हैं।
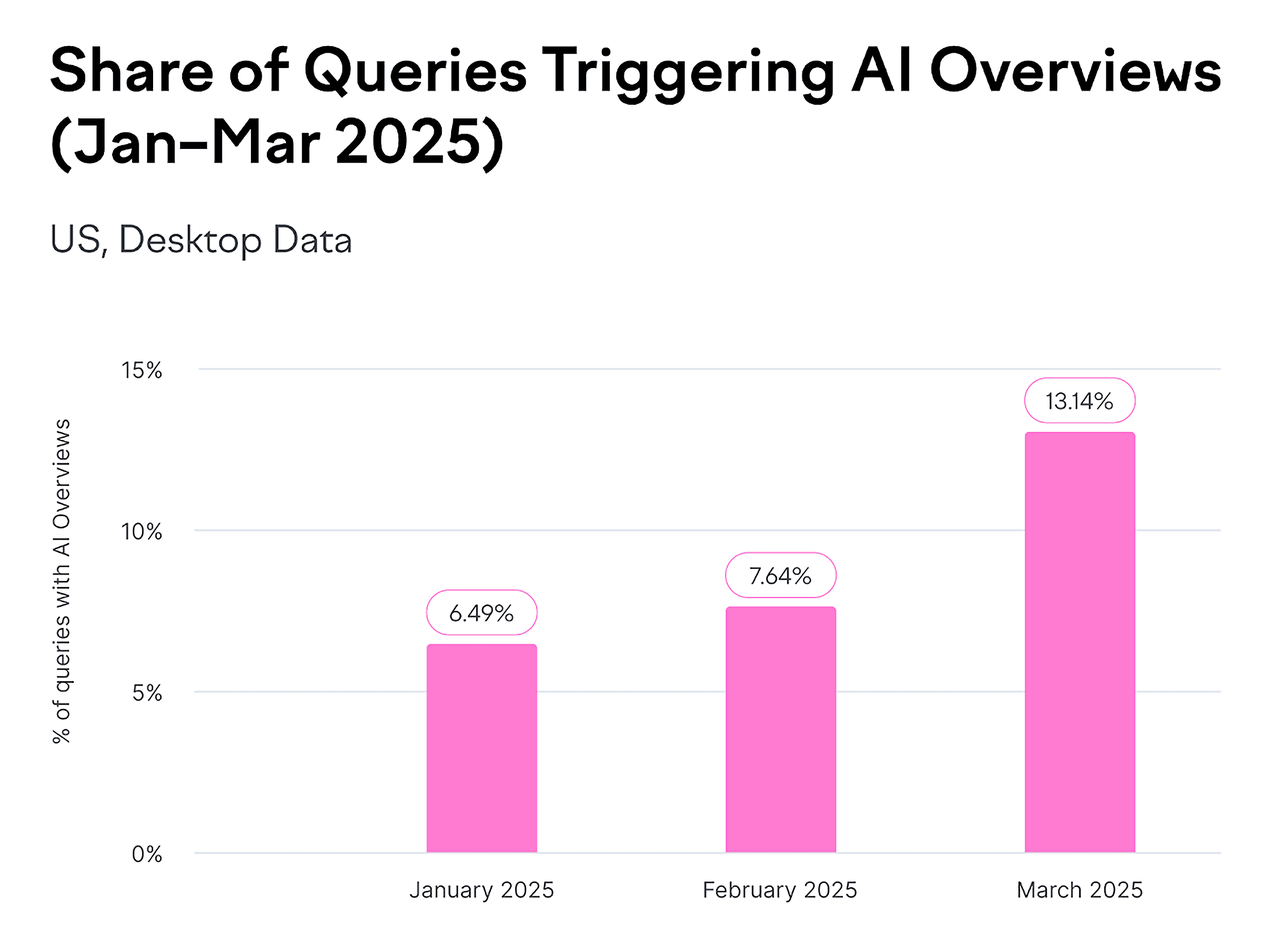
स्रोत: Backlinko
GEO ऑप्टिमाइजेशन के मुख्य लक्ष्य अब क्लिक बढ़ाने तक सीमित नहीं हैं, बल्कि तीन प्रमुख मेट्रिक्स पर ध्यान केंद्रित कर रहे हैं:
- ब्रांड दृश्यता: AI-जनित उत्तरों में आपके ब्रांड के दिखाई देने की संभावना बढ़ाना।
- स्रोत प्राधिकरण: सुनिश्चित करें कि आपका डोमेन, सामग्री, या डेटा मॉडल द्वारा एक विश्वसनीय संदर्भ के रूप में चुना गया है।
- नैरेेटिव निरंतरता और सकारात्मक स्थिति: सुनिश्चित करें कि AI आपके ब्रांड का वर्णन पेशेवर, सटीक और सकारात्मक रूप से करे।
इसका मतलब यह है कि "कीवर्ड रैंकिंग" की पारंपरिक SEO लॉजिक धीरे-धीरे AI के स्रोत संदर्भ तंत्र से स्थानांतरित हो रही है।
ब्रांडों को "खोज योग्य" होने से "विश्वसनीय, संहितांकित, और सक्रिय रूप से अनुशंसित" होने में विकसित होना चाहिए।
2. Perplexity पर ध्यान क्यों दें?
Perplexity AI के अनुमानित 15 मिलियन मासिक सक्रिय उपयोगकर्ता हैं, और इसके विकास की दरें लगातार बढ़ रही हैं। विशेष रूप से उत्तरी अमेरिका और यूरोप में, यह "AI खोज" के साथ लगभग समर्पित हो गया है।
सामग्री रणनीति, SEO, और बाजार विश्लेषण टीमों के लिए, Perplexity अब केवल एक “AI खोज इंजन” नहीं है—यह एक नए “बुद्धिमान शोध टर्मिनल” में बदल गया है।
आप इसका उपयोग कर सकते हैं:
- जनरेटिव इंजन ऑप्टिमाइजेशन में सामग्री के विभिन्न अंतर की तुलना करना
- देखें कि विभिन्न बाजारों में समान कीवर्ड के लिए कौन सी वेबसाइटें सामान्यतः संदर्भित की जाती हैं
- प्रतिस्पर्धियों की विषय रणनीतियों को जल्दी से संक्षिप्त करना
हालांकि, चुनौतियाँ हैं:
👉 Perplexity वर्तमान में केवल विदेशी पंजीकरणों का समर्थन करता है, जिससे यह चीन में अधिकांश उपयोगकर्ताओं के लिए असंभव है।
👉 मुफ्त संस्करण पूर्ण API पहुँच प्रदान नहीं करता है।
यह व्यवसायों या सामग्री टीमों के लिए एक प्राकृतिक बाधा उत्पन्न करता है: वे व्यवस्थित रूप से डेटा को बड़े पैमाने पर एकत्रित और विश्लेषण नहीं कर सकते हैं।
3. Scrapeless स्वचालन क्यों चुनें?
Scrapeless Browser एक स्मार्ट दृष्टिकोण प्रदान करता है। यह सिर्फ एक साधारण क्रॉलर नहीं है—यह एक क्लाउड में चल रहा असली ब्राउज़र उदाहरण है। आपको लोकल में क्रोम खोलने या बोट के रूप में पहचानने की चिंता करने की जरूरत नहीं है। केवल एक लाइन के Puppeteer कोड के साथ, आप वेबसाइटों के साथ ठीक उसी तरह बातचीत कर सकते हैं जैसे एक मानव करेगा।
उदाहरण के लिए, आप कर सकते हैं:
perplexity.aiखोलना- स्वचालित रूप से प्रश्न इनपुट करना
- परिणाम उत्पन्न होने का इंतजार करना
- उत्तर पाठ और उद्धरण लिंक निकालना
- पूर्ण पृष्ठ HTML,スクリーンशॉट, WebSocket संदेश, और नेटवर्क अनुरोध सहेजना
Scrapeless Browser के अद्वितीय लाभ
1. एंटरप्राइज-स्तरीय एंटी-डिटेक्शन तकनीक
आधुनिक AI साइटों जैसे Perplexity के पास मजबूत एंटी-सक्रैपिंग सुरक्षा है:
- Cloudflare Turnstile सत्यापन
- ब्राउज़र फिंगरप्रिंटिंग
- व्यवहार पैटर्न विश्लेषण
- आईपी प्रतिष्ठा जांच
Scrapeless इसे कैसे संभालता है:
ts
const CONNECTION_OPTIONS = {
proxyCountry: "US", // एक US आईपी का उपयोग करें
sessionRecording: "true", // डिबगिंग के लिए सत्र रिकॉर्ड करें
sessionTTL: "900", // 15 मिनट के लिए सत्र रखें
sessionName: "perplexity-scraper" // स्थायी सत्र
};- स्वचालित रूप से असली उपयोगकर्ता व्यवहार का अनुकरण
- यादृच्छिक रूप से ब्राउज़र फिंगरप्रिंट
- अंतर्निहित CAPTCHA हल करने वाला
- 195 देशों को कवर करने वाला प्रॉक्सी नेटवर्क
2. वैश्विक प्रॉक्सी नेटवर्क
Perplexity के उत्तर उपयोगकर्ता स्थान के अनुसार भिन्न होते हैं:
- 🇺🇸 अमेरिकी उपयोगकर्ता अमेरिकी स्थानीय सामग्री देखते हैं
- 🇬🇧 ब्रिटेन के उपयोगकर्ता ब्रिटिश दृष्टिकोण देखते हैं
- 🇯🇵 जापानी उपयोगकर्ता जापानी में सामग्री देखते हैं
Scrapeless समाधान:
ts
proxyCountry: "US" // अमेरिकी दृष्टिकोण के लिए
proxyCountry: "GB" // यूरोपीय बाजार अंतर्दृष्टि के लिए- वैश्विक तुलना के लिए विभिन्न देशों से कई प्रश्न चलाएं
- 195 देश प्रॉक्सी नोड और कस्टम ब्राउज़र प्रॉक्सी का समर्थन करता है
3. सत्र स्थायीता + रिकॉर्डिंग प्लेबैक
स्वचालन स्क्रिप्ट विकसित करते समय, सामान्य दर्द बिंदु हैं:
- ❌ नहीं जानते कि त्रुटियाँ कहां होती हैं
- ❌ समस्याओं को पुन: बनाने में असमर्थ
- ❌ डिबग करने के लिए बार-बार स्क्रिप्ट चलाना
Scrapeless लाइव सत्र:
ts
sessionRecording: "true" // सत्र रिकॉर्डिंग सक्षम करें- वास्तविक समय देखना: ब्राउज़र में स्वचालन प्रक्रिया को लाइव देखें
- प्लेबैक: अगर प्रक्रिया विफल हो जाती है तो पूरी प्रक्रिया को पुनः चलाएँ
4. शून्य रखरखाव लागत
पारंपरिक समाधान की आवश्यकता होती है:
- स्थानीय Puppeteer: सर्वर बनाए रखें, क्रोम अपडेट करें, क्रैश को संभालें
- स्व-होस्टेड क्लाउड ब्राउज़र: DevOps टीम, निगरानी, स्केलिंग
- मासिक लागत: 2 इंजीनियर × 20 घंटे ≈ $2,000
Scrapeless Browser:
- ✅ क्लाउड-होस्टेड, स्वचालित रूप से अपडेट किया गया
- ✅ 99.9% अपटाइम गारंटी
- ✅ स्वचालित स्केलिंग, कोई सह-सक्रियता की चिंता नहीं
- 💰 लागत: पे-एज़-यू-गो, लगभग $50–200/माह
आरओआई तुलना:
- पारंपरिक: $2,000 (श्रम) + $200 (सर्वर) = $2,200/माह
- Scrapeless: $100/माह
- बचत: 95%!
5. उपयोग के लिए तैयार एकीकरण
Scrapeless Browser मुख्यधारा के स्वचालन पुस्तकालयों के साथ पूरी तरह से संगत है:
- ✅ Puppeteer (Node.js)
- ✅ Playwright (Node.js / Python)
- ✅ CDP (Chrome DevTools Protocol)
स्थानांतरण लागत लगभग शून्य है:
ts
import puppeteer from "puppeteer-core"
// मूल: स्थानीय ब्राउज़र
// const browser = await puppeteer.launch();
// Scrapeless Browser में माइग्रेट करें, केवल एक लाइन बदलें:
const browser = await puppeteer.connect({
browserWSEndpoint: "wss://browser.scrapeless.com/api/v2/browser?token=YOUR_API_TOKEN"
})
const page = await browser.newPage()
await page.goto("https://google.com")4. Scrapeless Browser + Puppeteer: स्वचालित रूप से Perplexity.ai उत्तर प्राप्त करने के लिए विस्तृत गाइड
अगला, हम Scrapeless Browser + Puppeteer का उपयोग करके स्वचालित रूप से Perplexity.ai पर जाएंगे, प्रश्न प्रस्तुत करेंगे, और उत्तर, पृष्ठ लिंक, HTML स्निपेट, और नेटवर्क डेटा कैप्चर करेंगे।
किसी लोकल क्रोम इंस्टॉलेशन की आवश्यकता नहीं है—बिना किसी तैयारी के उपयोग के लिए तैयार, प्रॉक्सी, सत्र रिकॉर्डिंग, और WebSocket निगरानी के समर्थन के साथ।
चरण 1: Scrapeless कनेक्शन कॉन्फ़िगर करें
ts
const sleep = (ms) => new Promise(r => setTimeout(r, ms));
const tokenValue = process.env.SCRAPELESS_TOKEN || "YOUR_API_TOKEN";
const CONNECTION_OPTIONS = {
proxyCountry: "ANY", // सबसे तेज़ नोड अपने आप चुनें
sessionRecording: "true", // सत्र रिकॉर्डिंग सक्षम करें
sessionTTL: "900", // 15 मिनट के लिए सत्र रखें
sessionName: "perplexity-scraper", // सत्र का नाम
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}- Scrapeless में लॉगिन करें अपना API टोकन प्राप्त करने के लिए।

💡 मुख्य बिंदु:
proxyCountry: "ANY"स्वचालित रूप से सबसे तेज़ नोड का चयन करता है ताकि देरी कम हो सके।- यदि आपको किसी विशेष क्षेत्र से सामग्री की आवश्यकता हो, जैसे यूएस समाचार, तो
"US"पर बदलें। sessionRecordingकंसोल में प्लेबैक की अनुमति देता है ताकि समस्यानिवारण आसान हो सके।
const tokenValue = process.env.SCRAPELESS_TOKEN || "sk_0YEQhMuYK0izhydNSFlPZ59NMgFYk300X15oW69QY6yJxMtmo5Ewq8YwOvXT0JaW";
const CONNECTION_OPTIONS = {
proxyCountry: "ANY",
sessionRecording: "true",
sessionTTL: "900",
sessionName: "perplexity-scraper",
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}
async function findAndType(page, prompt) {
// 一组常用输入选择器(静默尝试,不打印“未找到”)
const selectors = [
'textarea[placeholder*="Ask"]',
'textarea[placeholder*="Ask anything"]',
'input[placeholder*="Ask"]',
'[contenteditable="true"]',
'div[role="textbox"]',
'div[role="combobox"]',
'textarea',
'input[type="search"]',
'[aria-label*="Ask"]',
];
for (const sel of selectors) {
try {
const el = await page.$(sel);
if (!el) continue;
// 确保可见
const visible = await el.boundingBox();
if (!visible) continue;
// 确定 contenteditable 或普通输入
const isContentEditable = await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return false;
if (e.isContentEditable) return true;
const role = e.getAttribute && e.getAttribute("role");
if (role && (role.includes("textbox") || role.includes("combobox"))) return true;
return false;
}, sel);
if (isContentEditable) {
await page.focus(sel);
// 尽可能使用 JavaScript 来写入和触发输入元素,以确保与 React/富文本编辑器的兼容性
await page.evaluate((s, t) => {
const el = document.querySelector(s);
if (!el) return;
// 如果元素可编辑,写入并分发输入
try {
el.focus();
if (document.execCommand) {
// insertText 在一些浏览器中支持
document.execCommand("selectAll", false);
document.execCommand("insertText", false, t);
} else {
// 回退
el.innerText = t;
}
} catch (e) {
el.innerText = t;
}
el.dispatchEvent(new Event("input", { bubbles: true }));
}, sel, prompt);
await page.keyboard.press("Enter");
return true;
} else {
// 普通输入/文本区域
try {
await el.click({ clickCount: 1 });
} catch (e) {}
await page.focus(sel);
// 清空并输入
await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return;
if ("value" in e) e.value = "";
}, sel);
await page.type(sel, prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
}
} catch (e) {
// 忽略并继续下一个选择器(保持安静)
}
}
// 后退:在使用键盘输入前确保页面获得焦点(安静,无警告打印)
try {
await page.mouse.click(640, 200).catch(() => {});
await sleep(200);
await page.keyboard.type(prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
} catch (e) {
return false;
}
}
(async () => {
const connectionURL = buildConnectionURL(tokenValue);
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: { width: 1280, height: 900 },
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(120000);
page.setDefaultTimeout(120000);
// 使用通用桌面用户代理(这减少了被简单保护检测的机会)
try {
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
);
} catch (e) {}
// 准备收集数据(简要)
const rawResponses = [];
const wsFrames = [];
page.on("response", async (res) => {
try {
const url = res.url();
const status = res.status();
const resourceType = res.request ? res.request().resourceType() : "unknown";
const headers = res.headers ? res.headers() : {};
let snippet = "";
try {
const t = await res.text();
snippet = typeof t === "string" ? t.slice(0, 20000) : String(t).slice(0, 20000);
} catch (e) {
snippet = "<read-failed>";
}
rawResponses.push({ url, status, resourceType, headers, snippet });
} catch (e) {}
});
// 尝试开启 CDP 会话以捕获 websocket 帧(如果不可能静默跳过)
try {
const cdp = await page.target().createCDPSession();
await cdp.send("Network.enable");
cdp.on("Network.webSocketFrameReceived", (evt) => {
try {
const { response } = evt;
hi
wsFrames.push({
timestamp: evt.timestamp,
opcode: response.opcode,
payload: response.payloadData ? response.payloadData.slice(0, 20000) : response.payloadData,
});
} catch (e) {}
});
} catch (e) {}
// परप्लेक्सिटी पर जाने के लिए (केवल domcontentloaded का इस्तेमाल करते हुए)
await page.goto("https://www.perplexity.ai/", { waitUntil: "domcontentloaded", timeout: 90000 });
// अपना सवाल दर्ज करें और सबमिट करें (चुपचाप प्रयास)
const prompt = "नमस्ते चैटजीपीटी, क्या आप जानते हैं कि Scrapeless क्या है?";
await findAndType(page, prompt);
// उत्तर पृष्ठ पर थोड़े समय के लिए प्रदर्शित होता है
await sleep(1500);
// पृष्ठ पर लंबे टेक्स्ट के प्रकट होने की प्रतीक्षा करना (लेकिन अतिरिक्त लॉग उत्पन्न किए बिना)
const start = Date.now();
while (Date.now() - start < 20000) {
const ok = await page.evaluate(() => {
const main = document.querySelector("main") || document.body;
if (!main) return false;
return Array.from(main.querySelectorAll("*")).some((el) => (el.innerText || "").trim().length > 80);
});
if (ok) break;
await sleep(500);
}
// उत्तर / लिंक / HTML अंश निकालना
const results = await page.evaluate(() => {
const pick = (el) => (el ? (el.innerText || "").trim() : "");
const out = { answers: [], links: [], rawHtmlSnippet: "" };
const selectors = [
'[data-testid*="answer"]',
'[data-testid*="result"]',
'.Answer',
'.answer',
'.result',
'article',
'main',
];
for (const s of selectors) {
const el = document.querySelector(s);
if (el) {
const t = pick(el);
if (t.length > 30) out.answers.push({ selector: s, text: t.slice(0, 20000) });
}
}
if (out.answers.length === 0) {
const main = document.querySelector("main") || document.body;
const blocks = Array.from(main.querySelectorAll("article, section, div, p")).slice(0, 8);
for (const b of blocks) {
const t = pick(b);
if (t.length > 30) out.answers.push({ selector: b.tagName, text: t.slice(0, 20000) });
}
}
const main = document.querySelector("main") || document.body;
out.links = Array.from(main.querySelectorAll("a")).slice(0, 200).map(a => ({ href: a.href, text: (a.innerText || "").trim() }));
out.rawHtmlSnippet = (main && main.innerHTML) ? main.innerHTML.slice(0, 200000) : "";
return out;
});
// आउटपुट सहेजें (चुपचाप)
try {
const pageHtml = await page.content();
await page.screenshot({ path: "./perplexity_screenshot.png", fullPage: true }).catch(() => {});
await fs.writeFile("./perplexity_results.json", JSON.stringify({ results, extractedAt: new Date().toISOString() }, null, 2));
await fs.writeFile("./perplexity_page.html", pageHtml);
await fs.writeFile("./perplexity_raw_responses.json", JSON.stringify(rawResponses, null, 2));
await fs.writeFile("./perplexity_ws_frames.json", JSON.stringify(wsFrames, null, 2));
} catch (e) {}
await browser.close();
// आवश्यक संक्षिप्त जानकारी प्रिंट करें।
console.log("हो गया - आउटपुट: perplexity_results.json, perplexity_page.html, perplexity_raw_responses.json, perplexity_ws_frames.json, perplexity_screenshot.png");
process.exit(0);
})().catch(async (err) => {
try { await fs.writeFile("./perplexity_error.txt", String(err)); } catch (e) {}
console.error("त्रुटि - perplexity_error.txt देखें");
process.exit(1);
});
## 6. इन JSON डेटा का GEO के लिए उपयोग कैसे करें? (व्यावहारिक गाइड)
Perplexity द्वारा लौटाया गया `answers` क्षेत्र आपको यह बताता है:
AI अंततः अपने उत्तर कैसे उत्पन्न करता है—किसका उल्लेख किया, किन पृष्ठों पर भरोसा किया, किन दृष्टिकोणों को मजबूत किया गया और किन सामग्री को अनदेखा किया गया।
दूसरे शब्दों में:
**`answers` को समझना = समझना कि आपकी ब्रांड का AI द्वारा उल्लेख क्यों किया गया, क्यों नहीं, और संदर्भ दरों में सुधार कैसे किया जा सकता है।**
---
### GEO का मुख्य कार्य: AI के “उद्धरण तंत्र” को नियंत्रित करना
परंपरागत SEO का उद्देश्य खोज परिणामों में पृष्ठों को उच्चतर स्थान पर स्थान देना है।
GEO का उद्देश्य मॉडल को आपके कंटेंट को **उद्धृत करने की अधिक संभावना बनाना** है जब उत्तर उत्पन्न किया जाए।
Perplexity का `answers` JSON आपको देखने की अनुमति देता है:
- कौन से URL AI द्वारा उद्धृत किए गए (`source_urls`)
- उत्तर पर प्रत्येक URL का प्रभाव वजन
- AI द्वारा प्रयुक्त सामग्री का सारांश
- AI अंतिम उत्तर को कैसे संरचना करता है (पैराग्राफ / बुलेट)
ये सभी क्षेत्र हैं जिनके लिए आप GEO के लिए अनुकूलित कर सकते हैं।
---
### ① उद्धरण स्रोतों की पहचान करें: क्या आप मॉडल की “विश्वसनीय सूची” में हैं?
उदाहरण:
```json
"title": "Web Scraper PRO - Scrapeless",
"url": "https://scrapeless.com"यदि आपकी वेबसाइट गायब है:
- आपकी सामग्री AI की विश्वसनीय डोमेन सूची में नहीं है
- आपकी संरचित जानकारी अपर्याप्त है
- यह AI की स्क्रैपिंग/समझने की आवश्यकताओं को पूरा नहीं करता है
GEO कार्रवाई: ऐसी सामग्री संरचनाएं बनाएं जो AI को क्रॉल करना पसंद करें
- FAQ ब्लॉक (AI द्वारा अत्यधिक उद्धृत)
- डेटा-आधारित सामग्री (मॉडल द्वारा अधिक विश्वसनीय)
- पुनरुत्पादित सामग्री (छोटे वाक्य, स्पष्ट तथ्य)
### ② देखिए कौन सा सामग्री/प्रतिस्पर्धी सबसे अधिक उद्धृत हैं → एआई प्राथमिकताओं का अनुमान लगाएं
उदाहरण:
```json
"title": "Scrapeless AI Browser Review 2024: एक गेम-चेंजर या बस एक और टूल?",
"url": "https://www.futuretools.io"अवलोकन:
- एआई लंबी पाठ्य सामग्री के आधारों को पसंद करता है (जैसे, विकी)
- वास्तविक चर्चाओं को पसंद करता है (रेडिट, ट्रस्टपायलट)
- संरचित समीक्षाओं को पसंद करता है (TomsGuide)
GEO क्रियाकलाप: इन साइटों की सामग्री संरचना और ज्ञान घनत्व की नकल करें
③ एआई-निकाली गई सामग्री के संक्षेपों का विश्लेषण करें → मिलती-जुलती सामग्री का निर्माण करें
answers में उदाहरण:
json
"Scrapeless एक वेब स्क्रैपिंग टूलकिट और एपीआई है जो एआई का उपयोग करता है..."यह मॉडल इन दोहराए जाने वाले तथ्यों पर सवालों का उत्तर देता है।
GEO क्रियाकलाप: समान प्रकार की स्पष्ट, मापने योग्य और पुनरुत्पादनीय सामग्री का उत्पादन करें
- छोटे वाक्यों का उपयोग करें
- स्पष्ट विषय-क्रिया-कर्ता बनाए रखें
- सामग्री को सीधे उद्धृत करने योग्य बनाएं
- सूची संरचनाओं का उपयोग करें
④ एआई के उत्तर की संरचना की जांच करें → "सीधे उद्धृत योग्य" सामग्री बनाएं
एआई के अंतिम उत्तर आमतौर पर शामिल होते हैं:
- कदम
- संक्षेप
- तुलना तालिकाएं
- लाभ / हानि
- समस्याओं का समाधान करने के कदम
GEO क्रियाकलाप: उसी संरचना में सामग्री को पूर्व-निर्मित करें।
क्योंकि: एआई ऐसी सामग्री को पसंद करता है जो संरचनात्मक रूप से समान, तार्किक रूप से स्पष्ट, और निकालने में आसान हो
⑤ जांचें कि क्या एआई आपके ब्रांड स्थिति को समझ नहीं पाता → कथा संगति को अनुकूलित करें
answers JSON में उत्तरों में आपके ब्रांड स्थिति से किस हद तक भिन्नता है, देखें।
GEO क्रियाकलाप:
- प्रामाणिक 'बारे में' पृष्ठ बनाएं
- सत्यापित ब्रांड विवरण प्रदान करें
- कई साइटों पर लगातार ब्रांड कथाएं बनाए रखें
- विश्वसनीय बैकलिंक्स प्रकाशित करें
❗ यह GEO की अनिवार्यता है:
ये रैंकिंग के बारे में नहीं है। यह एआई को आपको अपने विश्वसनीय ज्ञान आधार में शामिल करने के बारे में है।
पर्पलेक्सिटी का answers JSON आपका सबसे प्रत्यक्ष डेटा स्रोत है:
- एआई के उद्धरण तर्क को देखें
- प्रतिस्पर्धियों की सामग्री संरचनाओं की जांच करें
- समझें कि एआई किस प्रारूप को पसंद करता है
- ब्रांड स्थिति को सत्यापित करें
- अनदेखी गई सामग्री की पहचान करें
जनरेटिव खोज के युग में, "पहले रैंकिंग" का पारंपरिक एसईओ मानसिकता को फिर से परिभाषित किया जा रहा है: असली प्रतिस्पर्धा अब यह नहीं है कि कौन खोज परिणामों में उच्च रैंक पर है, बल्कि किसकी सामग्री सक्रिय रूप से उद्धृत, भरोसेमंद, और एआई द्वारा उसके उत्तरों में प्रस्तुत की जाती है।
Scrapeless पहली बार में एआई के निर्णय लेने की तर्क पर पूर्ण अंतर्दृष्टि प्राप्त करने के लिए उद्यमों को सक्षम बनाता है और इसे कार्रवाई योग्य GEO रणनीतियों में बदलता है।
Scrapeless ब्राउज़र के मुख्य लाभ:
- वैश्विक प्रॉक्सी नेटवर्क: 195 देशों में डेटा तक पहुंचने के लिए कई बाजार दृष्टिकोणों का कवरेज
- वास्तविक व्यवहार अनुकरण: स्वचालित रूप से एंटी-स्क्रैपिंग उपायों, ब्राउज़र फिंगरप्रिंट्स और CAPTCHAs को संभालता है
- व्यापक डेटा कैप्चर: उत्तर पाठ, उद्धरण लिंक, HTML, और अधिक कैप्चर करें
- क्लाउड-आधारित और शून्य रखरखाव: स्थानीय ब्राउज़र्स या सर्वरों की आवश्यकता नहीं, लागत में 95% तक बचत
- पूर्ण GEO टूलकिट: एआई उद्धरण निगरानी, संरचित सामग्री विश्लेषण, और वैश्विक डेटा स्क्रैपिंग
जनरेटिव इंजन ऑप्टिमाइजेशन (GEO) अब वैकल्पिक नहीं है—यह सामग्री प्रतिस्पर्धा का एक मुख्य स्तंभ बन गया है। यदि आप एआई खोज युग में रणनीतिक लाभ प्राप्त करना चाहते हैं, तो Scrapeless का पूर्ण GEO समाधान सबसे अच्छा प्रारंभिक बिंदु है।
Scrapeless न केवल ब्राउज़र स्वचालन और GEO डेटा स्वचालन प्रदान करता है बल्कि एआई उद्धरण तंत्र को पूरी तरह से नियंत्रित करने के लिए उन्नत उपकरण और रणनीतियां भी प्रदान करता है। हमसे संपर्क करें ताकि आप पूर्ण GEO डेटा समाधान को अनलॉक कर सकें!
भविष्य में, Scrapeless क्लाउड ब्राउज़र प्रौद्योगिकी पर ध्यान केंद्रित करना जारी रखेगा, उद्यमों को उच्च प्रदर्शन डेटा निष्कर्षण, स्वचालित कार्यप्रवाह, और एआई एजेंट अवसंरचना समर्थन प्रदान करेगा, जो वित्त, खुदरा, ई-कॉमर्स, विपणन, और अधिक उद्योगों की सेवा करेगा। Scrapeless प्रौद्योगिकी युग में व्यवसायों को आगे रखने में मदद करने के लिए अनुकूलित, परिदृश्य आधारित समाधान प्रदान करता है।
अस्वीकरण
इस खाता द्वारा प्रकाशित वेब स्क्रैपिंग, डेटा निष्कर्षण, स्वचालन स्क्रिप्ट और संबंधित तकनीकी सामग्री तकनीकी आदान-प्रदान, अध्ययन, और अनुसंधान उद्देश्यों के लिए ही है, जिसका उद्देश्य उद्योग का अनुभव और विकास तकनीकों को साझा करना है।
कानूनी उपयोग
सभी उदाहरण और विधियां पाठकों को कानूनन और अनुपालन के साथ उपयोग करने के लिए हैं। कृपया वेबसाइट की सेवा की शर्तों, गोपनीयता नीतियों और स्थानीय कानूनों के साथ अनुपालन सुनिश्चित करें।
जोखिम जिम्मेदारी
यह खाता किसी भी सीधे या अप्रत्यक्ष नुकसान के लिए जिम्मेदार नहीं है जो पाठकों द्वारा वर्णित तकनीकों या विधियों का उपयोग करने के परिणामस्वरूप होता है, जिसमें लेकिन सीमित नहीं है खाते की बैन, डेटा हानि, या कानूनी दायित्व।
सामग्री की सटीकता
हम सामग्री की सटीकता और समयबद्धता सुनिश्चित करने की कोशिश करते हैं लेकिन यह garanti नहीं कर सकते कि सभी उदाहरण हर वातावरण में काम करेंगे।
कॉपीराइट और उद्धरण
सामग्री सार्वजनिक रूप से उपलब्ध स्रोतों या लेखक के मौलिक कार्यों से आती है। कृपया पुनरुत्पादन करते समय स्रोत का उल्लेख करें, और इसे अवैध या वाणिज्यिक उद्देश्यों के लिए न उपयोग करें। यह खाता तीसरे पक्ष के डेटा या वेबसाइटों का उपयोग करने के परिणामों के लिए जिम्मेदार नहीं है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


