
Amazon वेब स्क्रैपर विद Node.JS - JavaScript ट्यूटोरियल 2025
Expert Network Defense Engineer
Amazon एक प्रमुख वैश्विक ई-कॉमर्स प्लेटफ़ॉर्म है जिसमें मार्केट रिसर्च और मूल्य निगरानी के लिए मूल्यवान उत्पाद डेटा है। Playwright के साथ JavaScript और Node.js का उपयोग करके, हम इस डेटा को निकालने के लिए एक JavaScript वेब स्क्रैपर बना सकते हैं, लेकिन JavaScript रेंडरिंग, एंटी-बॉट डिटेक्शन और CAPTCHAs जैसी चुनौतियाँ मैनुअल स्क्रैपिंग को मुश्किल बनाती हैं।
Scrapeless का Amazon Scraping API CAPTCHAs, प्रॉक्सी और वेबसाइट अनलॉकिंग को संभालकर एक तेज, अधिक विश्वसनीय समाधान प्रदान करता है, जो बिना पता लगाए वास्तविक समय, सटीक डेटा सुनिश्चित करता है। यह ट्यूटोरियल दोनों दृष्टिकोणों को कवर करेगा, यह दिखाते हुए कि कुशल Amazon डेटा स्क्रैपिंग के लिए Scrapeless सबसे अच्छा विकल्प क्यों है। 🚀
Amazon स्क्रैपिंग में चुनौतियाँ
इसके मजबूत एंटी-बॉट सुरक्षा के कारण Amazon स्क्रैपिंग कई चुनौतियों के साथ आता है:
- JavaScript रेंडरिंग: Amazon JavaScript पर बहुत अधिक निर्भर करता है, जिससे साधारण HTTP अनुरोधों के साथ डेटा निकालना मुश्किल हो जाता है। गतिशील सामग्री को प्रस्तुत करने के लिए Playwright या समान टूल का उपयोग करने वाला JavaScript स्क्रैपर आवश्यक है।
- CAPTCHA सुरक्षा: बार-बार CAPTCHA चुनौतियाँ स्क्रैपिंग को बाधित करती हैं और डेटा निष्कर्षण जारी रखने के लिए तंत्र को हल करने की आवश्यकता होती है।
- IP ब्लॉकिंग और दर सीमाएँ: Amazon एक ही IP से बार-बार आने वाले अनुरोधों का पता लगाता है और उन्हें ब्लॉक करता है, जिससे प्रॉक्सी या अन्य चोरी तकनीकों को घुमाने की आवश्यकता होती है।
- बार-बार वेबसाइट परिवर्तन: Amazon अपनी वेबसाइट संरचना को नियमित रूप से अपडेट करता है, जो स्क्रैपिंग स्क्रिप्ट को तोड़ सकता है और निरंतर रखरखाव की आवश्यकता होती है।
Node.js के साथ अपना JavaScript स्क्रैपर कैसे बनाएँ?
निम्नलिखित उदाहरण में, हम Amazon को स्क्रैप करने और निकाले गए डेटा को स्थानीय JSON फ़ाइल में संग्रहीत करने के लिए JavaScript का उपयोग करेंगे।
स्क्रैपिंग की तैयारी
हमें शुरुआत में ही आवश्यक Node.js वेब स्क्रैपर टूल सेट अप करने की आवश्यकता है:
इस लेख में, मैं Playwright का उपयोग करूँगा, जो कई योगदानकर्ताओं के साथ एक उच्च सक्रिय ओपन-सोर्स प्रोजेक्ट है। Microsoft द्वारा विकसित, यह कई ब्राउज़रों (Chromium, Firefox और WebKit) और कई प्रोग्रामिंग भाषाओं (Node.js, Python, .NET और Java) का समर्थन करता है, जिससे यह आज के सबसे लोकप्रिय JavaScript स्क्रैपिंग ढाँचों में से एक बन गया है।
यहाँ, सुनिश्चित करें कि आपका Node.js संस्करण 18 या उच्चतर है, फिर Playwright स्थापित करने के लिए निम्न स्क्रिप्ट चलाएँ:
Bash
# pnpm
pnpm create playwright
# yarn
yarn create playwright
# npm
npm init playwright@latestवेब ब्लॉकिंग और सिरदर्द परियोजना निर्माण पर निराश?
हमारे समुदाय में शामिल हों और मुफ़्त परीक्षण के साथ प्रभावी समाधान प्राप्त करें!
चरण 1. लक्ष्य पृष्ठ का निरीक्षण करें
स्क्रैपिंग से पहले, https://www.amazon.com/ पर जाने का प्रयास करें। यदि यह साइट तक पहुँचने का आपका पहला प्रयास है, तो आपको CAPTCHA का सामना करना पड़ सकता है।
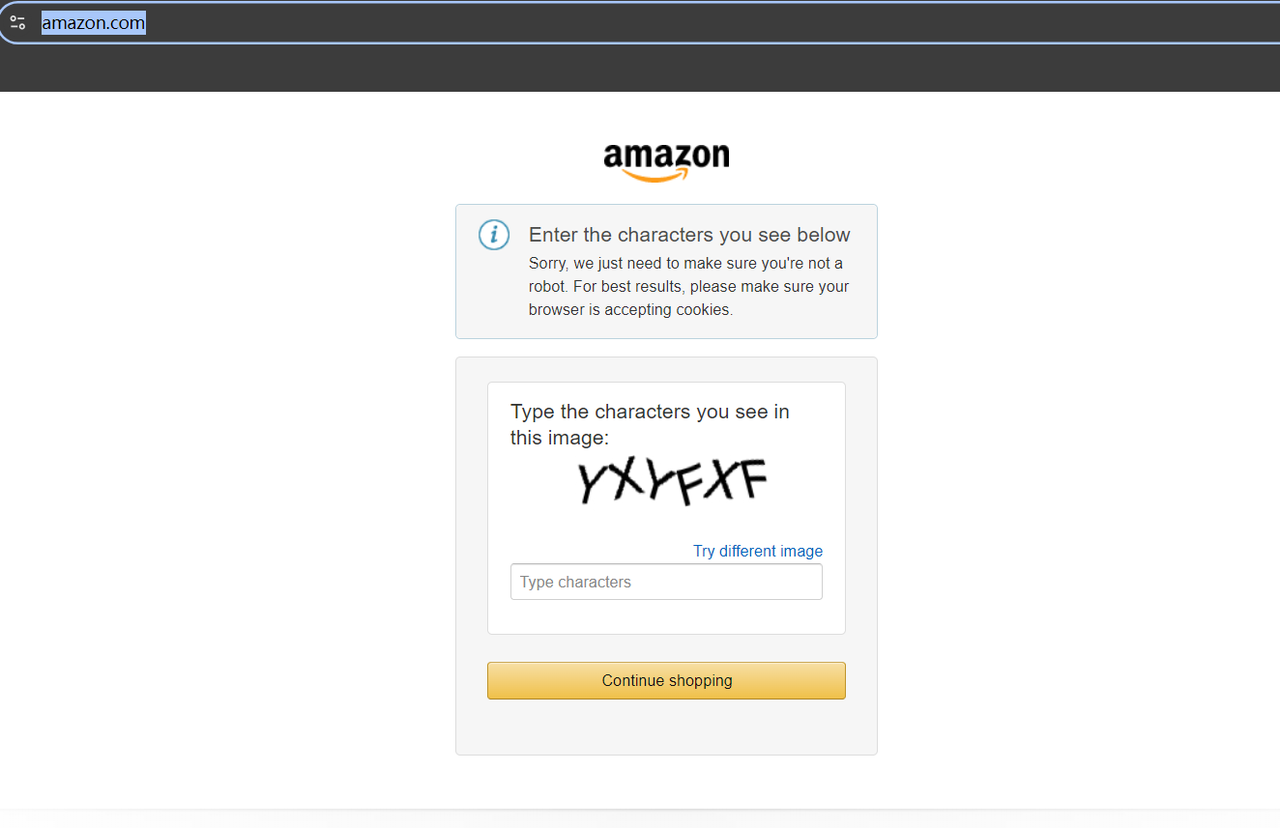
लेकिन चिंता न करें—हमें CAPTCHA-समाधान उपकरण खोजने की परेशानी से गुजरने की आवश्यकता नहीं है। इसके बजाय, बस अपने क्षेत्र या अपने प्रॉक्सी के स्थान के लिए विशिष्ट Amazon डोमेन तक पहुँचें, और आप CAPTCHA को ट्रिगर नहीं करेंगे।
उदाहरण के लिए, आइए https://www.amazon.co.uk/ पर जाएँ, जो यूके Amazon डोमेन है। आप देखेंगे कि पृष्ठ सुचारू रूप से लोड होता है। अब, शीर्ष पर स्थित खोज बार में अपनी वांछित उत्पाद कीवर्ड दर्ज करने का प्रयास करें या किसी URL के माध्यम से सीधे खोज परिणामों तक पहुँचें, जैसे:
Bash
https://www.amazon.co.uk/s?k=jacketURL में, /s?k= के बाद का मान उत्पाद कीवर्ड का प्रतिनिधित्व करता है। उपरोक्त URL तक पहुँचने से, आपको Amazon पर शर्ट से संबंधित उत्पाद दिखाई देंगे।
अब, पृष्ठ के HTML ढाँचे का निरीक्षण करने के लिए डेवलपर टूल (F12) खोलें। तत्वों को हाइलाइट करने और उस डेटा की पहचान करने के लिए कर्सर का उपयोग करें जिसे हमें बाद में स्क्रैप करने की आवश्यकता होगी।
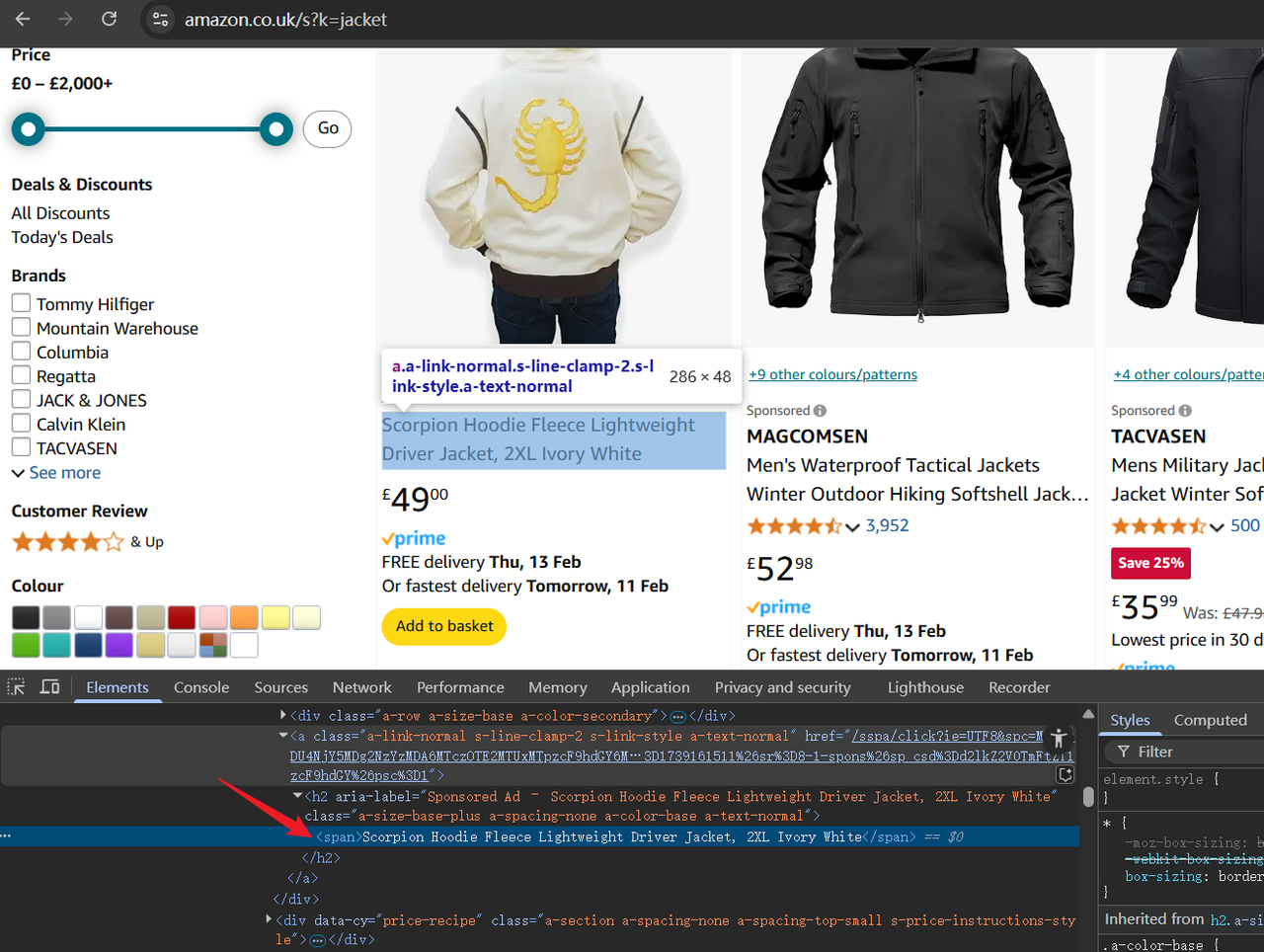
चरण 2. स्क्रिप्ट लिखना
सबसे पहले, स्क्रिप्ट के शीर्ष पर कोड का एक प्रारंभिक भाग जोड़ते हैं। निम्नलिखित कोड पहली स्क्रिप्ट तर्क को Amazon उत्पाद कीवर्ड के रूप में लेता है, जिसका उपयोग बाद में स्क्रैपिंग के लिए किया जाएगा:
JavaScript
const productName = process.argv.slice(2);
if (productName.length !== 1) {console.error('product name CLI arguments missing!');
process.exit(2);
}अगला, हमें चाहिए:
- ब्राउज़र के साथ इंटरैक्ट करने के लिए Playwright आयात करें।
- Amazon खोज परिणाम पृष्ठ पर नेविगेट करें।
- सफल पहुँच को सत्यापित करने के लिए एक स्क्रीनशॉट जोड़ें।
JavaScript
import playwright from "playwright";
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// डिबगिंग के लिए एक स्क्रीनशॉट जोड़ें
await page.screenshot({ path: 'amazon_page.png' })अब, हम सभी उत्पाद कंटेनरों को लाने, उनके माध्यम से लूप करने और प्रासंगिक डेटा निकालने के लिए page.$$ का उपयोग करेंगे। यह डेटा तब productDataList सरणी में संग्रहीत किया जाता है और मुद्रित किया जाता है:
JavaScript
// सभी खोज परिणाम कंटेनर प्राप्त करें
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// उत्पाद विवरण निकालें: शीर्षक, रेटिंग, छवि URL और मूल्य
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
await browser.close();स्क्रिप्ट इस प्रकार चलाएँ:
Bash
node amazon.js jacketयदि सफल होता है, तो कंसोल निकाले गए उत्पाद डेटा को प्रिंट करेगा।
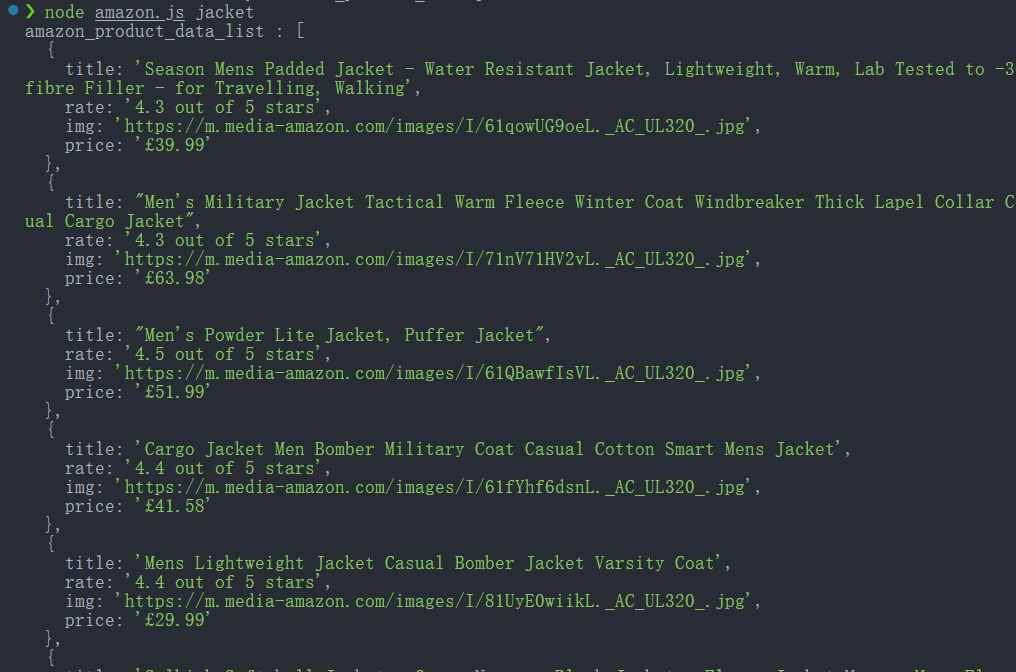
चरण 3. स्क्रैप किए गए डेटा को JSON फ़ाइल के रूप में सहेजना
उचित विश्लेषण के लिए केवल डेटा को कंसोल में प्रिंट करना पर्याप्त नहीं है। आइए Node.js के fs मॉड्यूल का उपयोग करके निकाले गए डेटा को JSON फ़ाइल में सहेजें:
JavaScript
import fs from 'fs'
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')ठीक है, आइए पूरी स्क्रिप्ट का पता लगाते हैं:
JavaScript
import playwright from "playwright";
import fs from 'fs'
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// डिबगिंग के लिए एक स्क्रीनशॉट जोड़ें
await page.screenshot({ path: 'amazon_page.png' })
// सभी खोज परिणाम कंटेनर प्राप्त करें
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// उत्पाद विवरण निकालें: शीर्षक, रेटिंग, छवि URL और मूल्य
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > a > h2 > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')
await browser.close();अब, स्क्रिप्ट चलाने के बाद, डेटा न केवल कंसोल पर मुद्रित होगा बल्कि JSON फ़ाइल (amazon_product_data.json) के रूप में भी सहेजा जाएगा।
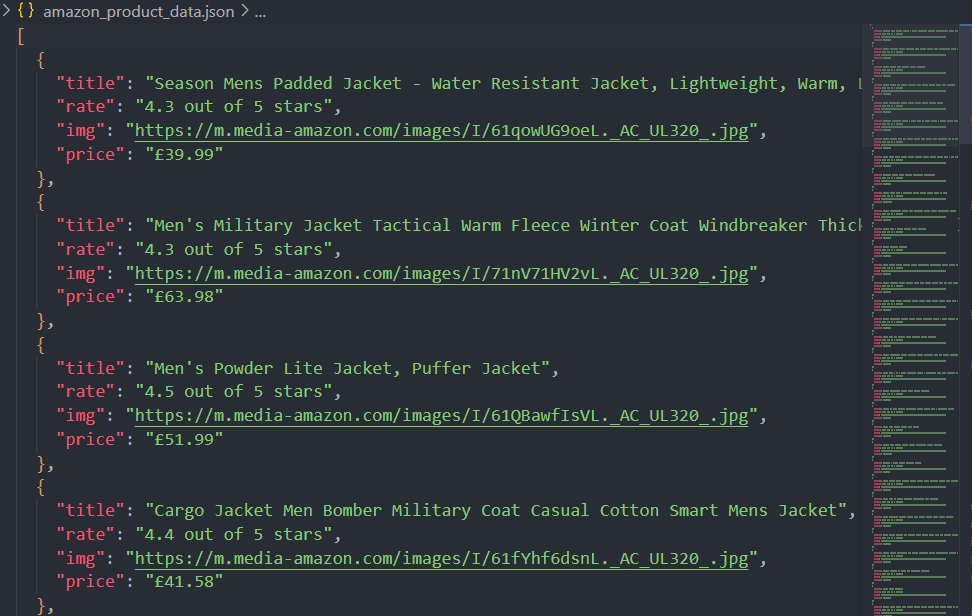
Amazon स्क्रैपिंग करते समय ब्लॉक होने से बचें
Amazon से डेटा स्क्रैप करना इसके सख्त एंटी-बॉट उपायों के कारण चुनौतीपूर्ण हो सकता है, लेकिन Scrapeless के वेब अनलॉकर का उपयोग इन प्रतिबंधों को प्रभावी ढंग से बायपास करने में मदद करता है।
Amazon स्वचालित पहुँच को रोकने के लिए IP दर सीमा, ब्राउज़र फ़िंगरप्रिंटिंग और CAPTCHA सत्यापन जैसी बॉट पहचान तकनीकों का उपयोग करता है। Scrapeless का वेब अनलॉकर आवासीय प्रॉक्सी को घुमाकर, वास्तविक उपयोगकर्ता व्यवहार की नकल करके और गतिशील सामग्री रेंडरिंग को संभालकर इन बाधाओं को दूर करता है।
Playwright या Playwright जैसे हेडलेस ब्राउज़रों के साथ Scrapeless को एकीकृत करके, उपयोगकर्ता बिना ब्लॉक किए Amazon के उत्पाद डेटा को स्क्रैप कर सकते हैं, जिससे एक सहज और कुशल डेटा निष्कर्षण प्रक्रिया सुनिश्चित होती है।
JavaScript स्क्रैपिंग सर्वोत्तम अभ्यास और विचार
JavaScript में वेब स्क्रैपर बनाते समय, दक्षता को अनुकूलित करना, गतिशील सामग्री को संभालना और सामान्य नुकसान से बचना महत्वपूर्ण है। यहाँ कुछ प्रमुख सर्वोत्तम अभ्यास और विचार दिए गए हैं:
- JavaScript-रेंडर किए गए पृष्ठों को संभालना
कई आधुनिक वेबसाइटें JavaScript का उपयोग करके सामग्री को गतिशील रूप से लोड करती हैं। पारंपरिक HTTP अनुरोध (जैसे Axios या Fetch) ऐसी सामग्री को कैप्चर नहीं करेंगे। इसके बजाय, JavaScript-भारी पृष्ठों से डेटा को प्रस्तुत करने और निकालने के लिए Playwright, Playwright या Selenium जैसे हेडलेस ब्राउज़र का उपयोग करें। - तेज़ स्क्रैपिंग के लिए समवर्ती प्रबंधन
स्क्रैपर को क्रमिक रूप से चलाना धीमा हो सकता है। प्रदर्शन में सुधार के लिए कई समानांतर स्क्रैप कार्यों को लॉन्च करके समवर्ती लागू करें। वादों के साथ async/await का उपयोग करें और स्क्रैप लोड को कुशलतापूर्वक संतुलित करने के लिए एक कतार प्रणाली का प्रबंधन करें। - Robots.txt और वेबसाइट नीतियों का सम्मान करना
स्क्रैपिंग से पहले, किसी वेबसाइट केrobots.txtफ़ाइल की जाँच करें ताकि उसके स्क्रैपिंग नियम निर्धारित किए जा सकें। इन नियमों की उपेक्षा करने से IP प्रतिबंध या कानूनी समस्याएँ हो सकती हैं। इसके अतिरिक्त, लक्ष्य सर्वर पर प्रभाव को कम करने के लिए उपयोगकर्ता-एजेंट रोटेशन और अनुरोध थ्रॉटलिंग का उपयोग करने पर विचार करें। - वेब एप्लिकेशन फ़ायरवॉल (WAFs) से बचना
वेबसाइटें स्वचालित ट्रैफ़िक को ब्लॉक करने के लिए Akamai, Cloudflare और PerimeterX जैसे WAFs को तैनात करती हैं। सत्र दृढ़ता, ब्राउज़र फ़िंगरप्रिंटिंग चोरी और CAPTCHA-समाधान उपकरण जैसी तकनीकें पता लगाने और अवरुद्ध करने को कम करने में मदद कर सकती हैं। - कुशल URL प्रबंधन और डुप्लीकेशन
सुनिश्चित करें कि आपका स्क्रैपर एक ही URL पर कई बार पुनः जाँच नहीं करता है, इसके लिए किसी URL सेट का उपयोग करें। URL को सामान्य बनाने और डुप्लिकेट डेटा संग्रह को रोकने के लिए कैनोनिकलाइज़ेशन तकनीकों को लागू करें। - पृष्ठांकन और अनंत स्क्रॉलिंग को संभालना
वेबसाइटें अक्सर सामग्री को गतिशील रूप से लोड करने के लिए पृष्ठांकन या अनंत स्क्रॉलिंग का उपयोग करती हैं। पृष्ठांकन संरचना की पहचान करें (जैसे,?page=2) या स्क्रॉलिंग अनुकरण करने और सभी सामग्री निकालने के लिए हेडलेस ब्राउज़र का उपयोग करें। - डेटा निष्कर्षण और संग्रहण अनुकूलन
डेटा निकालने के बाद, इसे ठीक से स्वरूपित करें और इसे कुशलतापूर्वक संग्रहीत करें। बेहतर प्रसंस्करण और विश्लेषण के लिए संरचित डेटा को JSON, CSV या MongoDB या PostgreSQL जैसे डेटाबेस में सहेजें। - बड़े पैमाने पर स्क्रैपिंग के लिए वितरित स्क्रैपिंग
बड़े पैमाने पर स्क्रैपिंग कार्यों के लिए, कतार-आधारित स्क्रैपिंग ढाँचे या क्लाउड ब्राउज़र समाधान का उपयोग करके कई मशीनों या क्लाउड उदाहरणों में वर्कलोड को वितरित करें। यह एक ही सिस्टम को अधिभारित करने से रोकता है और गलती सहनशीलता में सुधार करता है।
तेज, अधिक विश्वसनीय समाधान के लिए Scrapeless Scraping API का उपयोग करना
Playwright जैसे हेडलेस ब्राउज़रों के साथ Scrapeless को एकीकृत करके, उपयोगकर्ता बिना ब्लॉक किए Amazon उत्पाद डेटा निकालने के लिए JavaScript में स्क्रैपर बना सकते हैं, जिससे एक सहज और कुशल डेटा निष्कर्षण प्रक्रिया सुनिश्चित होती है।
विशेषताएँ:
✅ केवल एक API कॉल के साथ नवीनतम डेटा तक तुरंत पहुँच प्राप्त करें।
✅ प्रति माह 100M से अधिक अनुरोधों के साथ प्रति सेकंड 200 से अधिक समवर्ती अनुरोध।
✅ प्रत्येक अनुरोध में औसतन 5 सेकंड लगते हैं, जो कैशिंग के बिना वास्तविक समय डेटा पुनर्प्राप्ति सुनिश्चित करता है।
✅ विभिन्न आवश्यकताओं को पूरा करने के लिए अनुकूलित स्क्रैपिंग नियमों का समर्थन करता है।
✅ Amazon के अलावा, यह अन्य ई-कॉमर्स प्लेटफ़ॉर्म का भी समर्थन कर सकता है, मल्टी-प्लेटफ़ॉर्म स्क्रैपिंग का समर्थन करता है: Shopee, Shein, आदि।
✅ केवल सफल खोजों के लिए भुगतान करें
Scrapeless क्यों चुनें?
- वास्तविक समय डेटा: अद्यतित और सटीक उत्पाद लिस्टिंग सुनिश्चित करता है।
- एकीकृत वेबसाइट अनलॉकिंग: स्वचालित रूप से प्रतिबंधों और CAPTCHAs को बायपास करता है।
- वैधता: Scrapeless खोज परिणामों तक पहुँचने का एक कानूनी और अनुपालन तरीका प्रदान करता है।
- विश्वसनीयता: API बिना रुके डेटा संग्रह सुनिश्चित करते हुए, पता लगाने से बचने के लिए परिष्कृत तकनीकों का उपयोग करता है।
- उपयोग में आसानी: Scrapeless एक सरल API प्रदान करता है जो Python के साथ आसानी से एकीकृत होता है, जिससे यह उन डेवलपर्स के लिए आदर्श है जिन्हें खोज परिणाम डेटा तक त्वरित पहुँच की आवश्यकता होती है।
- अनुकूलन योग्य: आप परिणामों को अपनी आवश्यकताओं के अनुसार तैयार कर सकते हैं, जैसे कि सामग्री के प्रकार को निर्दिष्ट करना (जैसे, ऑर्गेनिक लिस्टिंग, विज्ञापन, आदि)।
क्या Scrapeless Scraping API महंगा है?
Scrapeless प्रतिस्पर्धी कीमतों (Zenrows और Apify के मुकाबले) पर एक विश्वसनीय और स्केलेबल वेब स्क्रैपिंग प्लेटफ़ॉर्म प्रदान करता है, जो अपने उपयोगकर्ताओं के लिए उत्कृष्ट मूल्य सुनिश्चित करता है:
- स्क्रैपिंग ब्राउज़र: प्रति घंटे $0.09 से
- स्क्रैपिंग API: प्रति 1k URL $0.8 से
- वेब अनलॉकर: प्रति 1k URL $0.20
- CAPTCHA सॉल्वर: प्रति 1k URL $0.80 से
- प्रॉक्सी: प्रति GB $2.80
सदस्यता लेकर, आप प्रत्येक सेवा पर 20% तक की छूट का आनंद ले सकते हैं।
Scrapeless का Amazon Scraping API कैसे लागू करें
यदि आप Amazon उत्पाद पृष्ठों से ASIN नंबर निकालना चाहते हैं, तो Scrapeless ऐसा करने का एक सरल और प्रभावी तरीका प्रदान करता है। Scrapeless के Amazon Scraper API का उपयोग करके, आप आसानी से अन्य प्रमुख उत्पाद विवरणों के साथ ASIN नंबर प्राप्त कर सकते हैं।
चरण 1। Scrapeless में लॉग इन करें।
चरण 2। स्क्रैपिंग API पर क्लिक करें > Shopee स्क्रैपिंग पृष्ठ दर्ज करने के लिए Amazon चुनें।
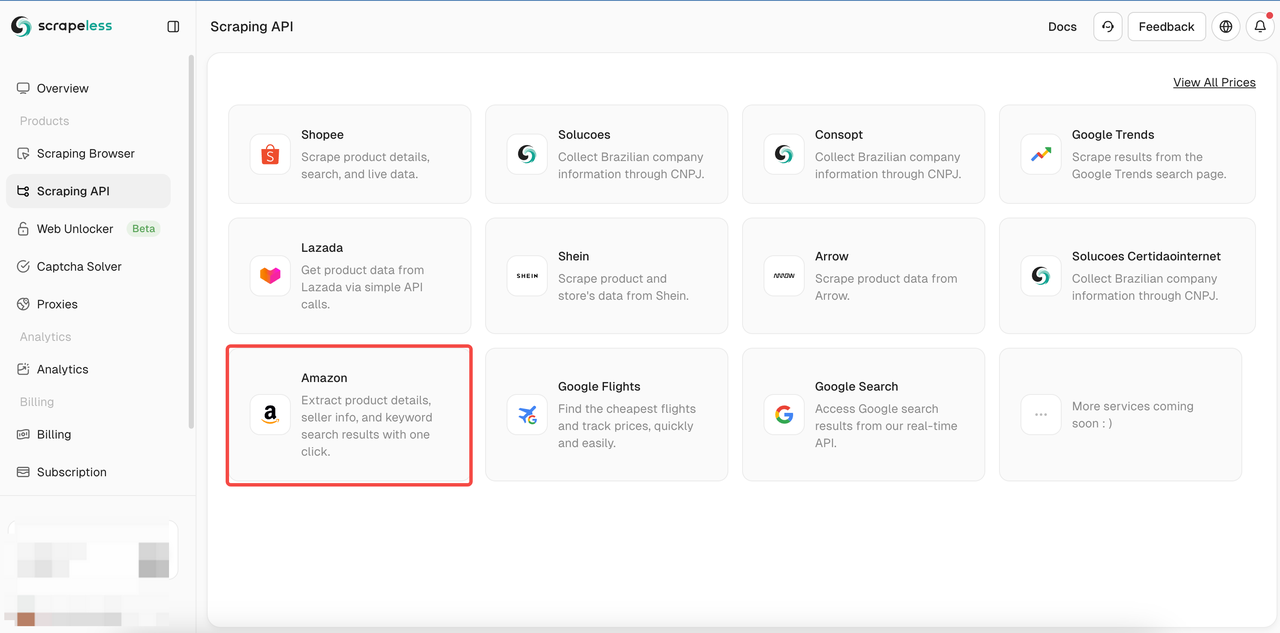
चरण 3। उस Amazon उत्पाद पृष्ठ का लिंक पेस्ट करें जिसे आप इनपुट बॉक्स में क्रॉल करना चाहते हैं। और क्रॉल करने के लिए डेटा के प्रकार का चयन करें।
टूल पेज पर, आप क्रॉल करने के लिए डेटा के प्रकार का चयन कर सकते हैं:
- विक्रेता: विक्रेता की जानकारी क्रॉल करें, जिसमें विक्रेता का नाम, रेटिंग, संपर्क जानकारी आदि शामिल हैं।
- उत्पाद: उत्पाद विवरण क्रॉल करें जैसे शीर्षक, मूल्य, रेटिंग, टिप्पणियाँ, आदि।
- कीवर्ड: उत्पाद से संबंधित कीवर्ड क्रॉल करें ताकि आप उत्पाद के SEO और बाजार के रुझानों का विश्लेषण कर सकें।
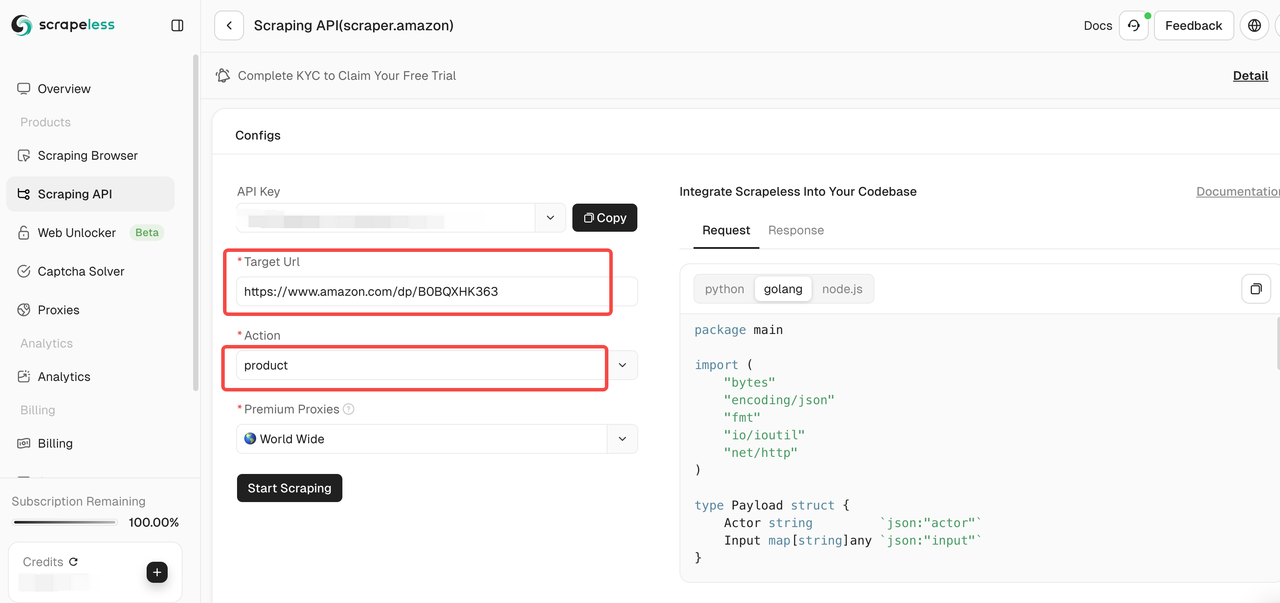
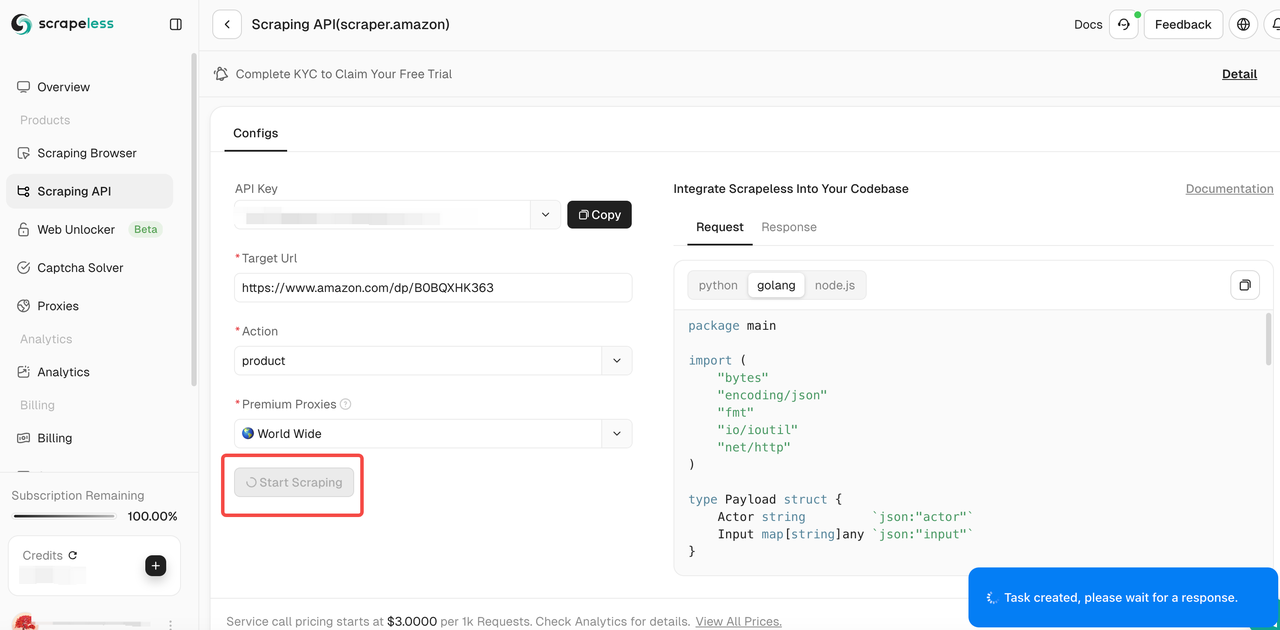
चरण 4। यह पुष्टि करने के बाद कि इनपुट लिंक और चयनित डेटा प्रकार सही हैं, "स्क्रैपिंग प्रारंभ करें" बटन पर क्लिक करें। सिस्टम डेटा क्रॉल करना शुरू कर देगा और पृष्ठ के दाईं ओर स्थित पैनल पर क्रॉल किए गए परिणाम प्रदर्शित करेगा।
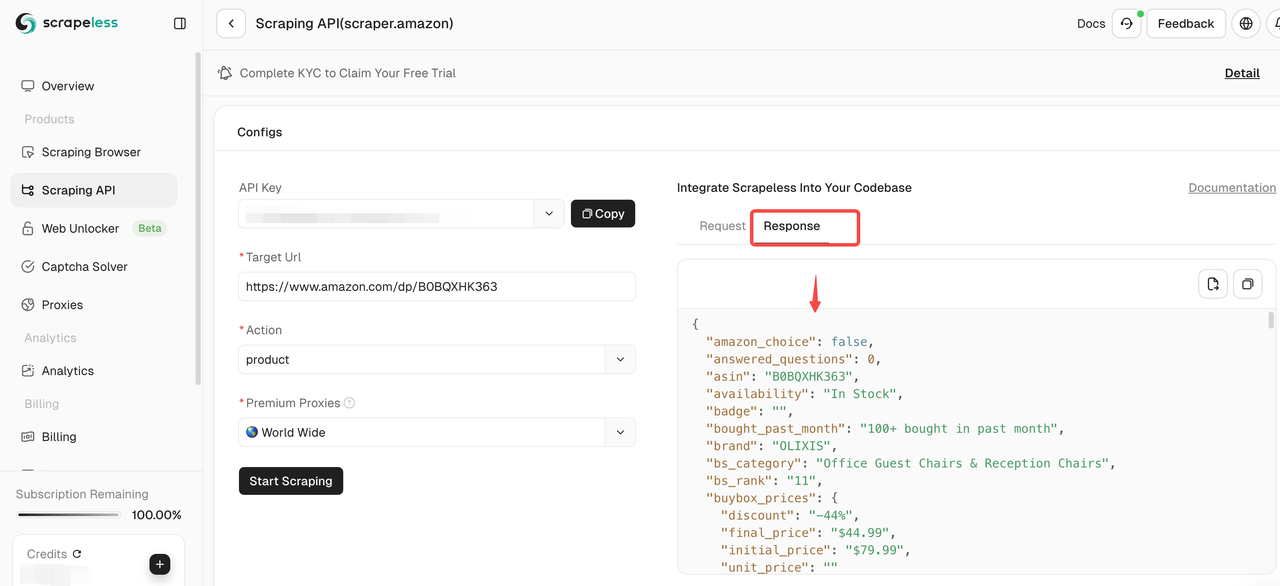
चरण 5। क्रॉलिंग पूरा होने के बाद, आप दाईं ओर स्थित पैनल में क्रॉल किए गए डेटा को देख सकते हैं। आसान विश्लेषण के लिए परिणाम स्पष्ट प्रारूप में प्रदर्शित किए जाएँगे।
यदि आपको अन्य उत्पादों को क्रॉल करने की आवश्यकता है, तो एक नया Amazon लिंक दर्ज करने के लिए जारी रखें पर क्लिक करें और उपरोक्त चरणों को दोहराएँ!
आप अपने प्रोजेक्ट में **हमारे कोड को सीधे एकीकृत** भी कर सकते हैं:
Node.js
JavaScript
const https = require('https');
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/scraper/request`;
const token = " "; // API टोकन
const inputData = {
action: "product",
url: " " // उत्पाद URL
};
const payload = new Payload("scraper.amazon", inputData);
const jsonPayload = JSON.stringify(payload);
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token
}
};
const req = https.request(url, options, (res) => {
let body = '';
res.on('data', (chunk) => {
body += chunk;
});
res.on('end', () => {
console.log("body", body);
});
});
req.on('error', (error) => {
console.error('Error:', error);
});
req.write(jsonPayload);
req.end();
}
sendRequest();Python
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " ## API टोकन
headers = {
"x-api-token": token
}
input_data = {
"action": "product",
"url": " " ## उत्पाद URL
}
payload = Payload("scraper.amazon", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Golang
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := " " // API टोकन
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"action": "product",
"url": " ", // उत्पाद URL
}
payload := Payload{
Actor: "scraper.amazon",
Input: inputData,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}निष्कर्ष: 2025 में Amazon को स्क्रैप करने का सबसे अच्छा तरीका
Node.js के साथ JavaScript स्क्रैपर बनाने से स्क्रैपिंग प्रक्रिया पर पूर्ण नियंत्रण मिलता है, लेकिन गतिशील सामग्री को संभालने, CAPTCHAs को हल करने, प्रॉक्सी का प्रबंधन करने और पता लगाने से बचने जैसी चुनौतियाँ आती हैं। इसके लिए महत्वपूर्ण तकनीकी प्रयास और चल रहे रखरखाव की आवश्यकता होती है।
बड़े पैमाने पर, कुशल और अस्पष्टीकृत स्क्रैपिंग के लिए, Scrapeless का API सबसे अच्छा विकल्प है। यह बॉट डिटेक्शन की जटिलताओं को समाप्त करता है, जिससे डेटा निष्कर्षण सहज और स्केलेबल हो जाता है!
🚀 एक तेज़, विश्वसनीय और चिंता मुक्त स्क्रैपिंग अनुभव के लिए आज ही Scrapeless का Amazon Scraping API आज़माएँ!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


