
क्या Node Unblocker वेब स्क्रैपिंग चुनौतियों को दरकिनार करने के लिए पर्याप्त है?
Expert Network Defense Engineer
नोड अनब्लॉकर्स को IP रोटेशन, हेडर अनुकूलन और एन्क्रिप्शन जैसी सुविधाओं को शामिल करने के लिए अनुकूलित किया जा सकता है। इसलिए हम वेबसाइट ब्लॉकिंग को बायपास करने के लिए नोड अनब्लॉकर्स बनाते हैं।
एक नोड अनब्लॉकर वेबसाइट चुनौतियों को बायपास करने में उत्कृष्टता प्राप्त करता है, लेकिन व्यवहार में हम पाते हैं कि हमें अभी भी इसकी कुछ अंतर्निहित परेशानियों से निपटने की आवश्यकता है।
अपने नोड अनब्लॉकर को अधिक शक्तिशाली कैसे बनाएं? क्या कोई ऐसी विधि या उपकरण है जो वेबसाइट चुनौतियों को सीधे पूरी तरह से दूर कर सके?
इस लेख से सबसे अच्छा उत्तर खोजने का समय आ गया है!
नोड अनब्लॉकर क्या है?
नोड अनब्लॉकर एक वेब प्रॉक्सी टूल है जिसे Node.js के साथ बनाया गया है जो नेटवर्क प्रतिबंधों या वेबसाइट एक्सेस सीमाओं को बायपास करने में मदद करता है। यह उपयोगकर्ता और लक्षित वेबसाइट के बीच एक मध्यस्थ के रूप में कार्य करता है, जिससे उपयोगकर्ता उस सामग्री के साथ बातचीत कर सकता है जिसे भौगोलिक प्रतिबंधों, नेटवर्क फ़िल्टर या फ़ायरवॉल के कारण अवरुद्ध किया जा सकता है।
अनब्लॉकर्स ऐसा उपयोगकर्ता के अनुरोध को Node.js सर्वर पर रूट करके करते हैं, जो वांछित सामग्री प्राप्त करता है और उसे उपयोगकर्ता को वापस कर देता है। यह आम तौर पर गतिशील सामग्री हैंडलिंग का समर्थन करता है, जिससे यह आधुनिक वेब अनुप्रयोगों के लिए उपयुक्त हो जाता है।
नोड अनब्लॉकर का उपयोग कैसे करें?
सबसे पहले, हम एक बुनियादी Node.js सेवा बनाएंगे। फिर, हम चर्चा करेंगे कि मिडिलवेयर बनाने के लिए नोड अनब्लॉकर का उपयोग कैसे करें, जिससे हमारी नोड सेवा के भीतर एकीकरण सक्षम हो सके। अतिरिक्त विवरण के लिए, आप सीधे नोड अनब्लॉकर दस्तावेज़ पर जा सकते हैं।
पूर्व आवश्यकताएँ
शुरू करने से पहले, आपके पास Node.js स्थापित होना चाहिए। आप Node.js यहाँ डाउनलोड कर सकते हैं।
अब आइए एक बुनियादी Node.js सेवा बनाकर शुरू करते हैं।
- एक नई Node.js प्रोजेक्ट आरंभ करें। यदि आपके पास पहले से कोई प्रोजेक्ट नहीं है, तो निम्न आदेशों का उपयोग करके एक बनाएँ:
Bash
mkdir node-unblocker-tutorial- प्रोजेक्ट निर्देशिका पर जाएँ, प्रोजेक्ट को आरंभ करें और आवश्यक निर्भरताओं को स्थापित करें:
Bash
cd node-unblocker-tutorial
npm init -y
pnpm add express unblocker- अब, अपने कोड को व्यवस्थित करने के लिए एक नई फ़ाइल, index.js बनाएँ:
Bash
touch index.jsबुनियादी Node.js सेवा की स्थापना
- आवश्यक मॉड्यूल,
expressऔरunblockerआयात करें:
JavaScript
import express from 'express';
import unblocker from 'unblocker';- इसके बाद, एक एक्सप्रेस एप्लिकेशन बनाएँ:
JavaScript
const app = express();- अनब्लॉकर का एक उदाहरण आरंभ करें और इसका प्रॉक्सी उपसर्ग सेट करें:
JavaScript
const unblocker = new Unblocker({
prefix: '/proxy/'
});app.use() विधि का उपयोग करके एक्सप्रेस एप्लिकेशन के साथ अनब्लॉकर इंस्टेंस को एकीकृत करना सुनिश्चित करें:
JavaScript
app.use(unblocker());- एक पोर्ट परिभाषित करें और
app.listen()विधि का उपयोग करके Node.js सेवा प्रारंभ करें:
JavaScript
const PORT = process.env.PORT || 9090;
app.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
});- यहाँ सेटअप के लिए पूरा कोड है:
JavaScript
import express from 'express';
import Unblocker from 'unblocker';
const app = express();
const unblocker = new Unblocker({ prefix: '/proxy/' });
app.use(unblocker);
const PORT = process.env.PORT || 9090;
app
.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
})
.on('upgrade', unblocker.onUpgrade);सेवा चलाना
पोर्ट 9090 पर सर्वर प्रारंभ करने के लिए Node का उपयोग करके index.js फ़ाइल चलाएँ। प्रॉक्सी उपसर्ग में लक्ष्य URL जोड़कर प्रॉक्सी का परीक्षण करें। इस उदाहरण के लिए, हम लक्ष्य पृष्ठ के रूप में https://ident.me/ का उपयोग करेंगे। सेवा चलाने के बाद अपने ब्राउज़र में निम्नलिखित लिंक खोलें:
node index.js
आपको वर्तमान सेवा का IP पता प्रदर्शित करने वाला एक पृष्ठ दिखाई देगा, जो यह दर्शाता है कि सेटअप सही ढंग से काम कर रहा है:

नोड अनब्लॉकर की 5 सीमाएँ
- प्रदर्शन की बाधाएँ
चूँकि नोड अनब्लॉकर वास्तविक समय में वेब अनुरोधों और प्रतिक्रियाओं को संसाधित करता है, इसलिए बड़ी संख्या में एक साथ अनुरोधों या भारी ट्रैफ़िक को संभालते समय यह प्रदर्शन की बाधा बन सकता है।
- संसाधन की खपत
नोड अनब्लॉकर को अनुरोधों को संभालने के लिए सर्वर संसाधनों की आवश्यकता होती है, खासकर बड़ी फ़ाइलों, मल्टीमीडिया सामग्री या अत्यधिक गतिशील वेब पेजों से निपटते समय। इससे CPU और मेमोरी का उपयोग बढ़ सकता है।
- सीमित बाईपास क्षमताएँ
जबकि नोड अनब्लॉकर कुछ बुनियादी प्रतिबंधों को बायपास कर सकता है, यह CAPTCHA, जावास्क्रिप्ट फ़िंगरप्रिंटिंग या IP-आधारित दर-सीमित तंत्र जैसी उन्नत एंटी-बॉट प्रणालियों से जूझता है।
- स्केलेबिलिटी चुनौतियाँ
नोड अनब्लॉकर स्वाभाविक रूप से वितरित सेटअप या उच्च स्केलेबिलिटी के लिए नहीं बनाया गया है, जो इसे महत्वपूर्ण अनुकूलन के बिना उद्यम-स्तरीय या बड़े पैमाने पर अनुप्रयोगों के लिए कम उपयुक्त बनाता है।
- HTTPS निरीक्षण का अभाव
नोड अनब्लॉकर HTTPS ट्रैफ़िक को डिक्रिप्ट या निरीक्षण नहीं करता है, जो प्रॉक्सी प्रक्रिया के दौरान एन्क्रिप्टेड डेटा को संशोधित या विश्लेषण करने की इसकी क्षमता को सीमित करता है।
नोड अनब्लॉकर का उपयोग करने के कुछ बेहतरीन अभ्यास क्या हैं?
1. उपयोगकर्ता-एजेंट हेडर घुमाएँ
अपनी वेब स्क्रैपिंग गतिविधियों को अलग-अलग उपयोगकर्ताओं से उत्पन्न होने के रूप में दिखाने के लिए, उपयोगकर्ता-एजेंट हेडर को घुमाना आवश्यक है। यह अभ्यास किसी वेबसाइट द्वारा आपके अनुरोधों को स्वचालित के रूप में पहचानने की संभावना को काफी कम करता है।
2. IP रोटेशन लागू करें
एक ही प्रॉक्सी IP पर निर्भर रहना लगभग सीधे वेबसाइट तक पहुँचने जितना ही जोखिम भरा है, क्योंकि इससे आपके IP के चिह्नित या अवरुद्ध होने की संभावना बढ़ जाती है। IP रोटेशन लागू करने से आपको पता लगाने से बचने और आवश्यक वेब डेटा एकत्र करने के लिए निर्बाध पहुँच सुनिश्चित करने में मदद मिलती है।
3. अनुरोधों की आवृत्ति सीमित करें
रेट लिमिटिंग आपके IP को चिह्नित होने से रोकने के लिए एक महत्वपूर्ण उपाय है। कम समय में एक ही IP से कई अनुरोध तेजी से भेजने से वेबसाइट की एंटी-बॉट सुरक्षा सक्रिय हो सकती है, जिससे संभावित रूप से प्रतिबंध लग सकता है। अपने स्क्रैपिंग कोड में देरी को शामिल करके, आप इन जोखिमों को कम कर सकते हैं और सुचारू संचालन बनाए रख सकते हैं।
4. त्रुटि संचालन
सफल वेब स्क्रैपिंग के लिए प्रभावी त्रुटि संचालन महत्वपूर्ण है। अपने कोड में ऐसे तंत्र को शामिल करें जो उन परिदृश्यों को संबोधित करते हैं जहाँ लक्षित वेबसाइट अपेक्षित प्रतिक्रिया नहीं देती है, यह सुनिश्चित करती है कि आपकी स्क्रैपिंग प्रक्रिया मजबूत और कुशल बनी रहे।
उन्नत सुविधाओं के लिए स्क्रैपलेस वेब अनलॉकर को एकीकृत करना
ब्लॉक से बचने में स्क्रैपलेस कितना प्रभावी है?
स्क्रैपलेस वेब अनलॉकर एक वैश्विक नेटवर्क का लाभ उठाता है जो 195 देशों में फैला हुआ है, जो 70 मिलियन से अधिक आवासीय IP तक पहुँच द्वारा समर्थित है। 99.9% अपटाइम और असाधारण सफलता दर के साथ, स्क्रैपलेस आसानी से IP ब्लॉक और CAPTCHA जैसी चुनौतियों को दूर करता है, जिससे यह जटिल वेब ऑटोमेशन और AI-संचालित डेटा संग्रह के लिए एक मजबूत समाधान बन जाता है।
क्या स्क्रैपलेस महंगा है?
स्क्रैपलेस प्रतिस्पर्धी कीमतों पर एक विश्वसनीय और स्केलेबल वेब स्क्रैपिंग प्लेटफ़ॉर्म प्रदान करता है, जो अपने उपयोगकर्ताओं के लिए उत्कृष्ट मूल्य सुनिश्चित करता है:
- स्क्रैपिंग ब्राउज़र: $0.09 प्रति घंटे से
- स्क्रैपिंग API: $1.00 प्रति 1k URL से
- वेब अनलॉकर: $0.20 प्रति 1k URL
- कैप्चा सॉल्वर: $0.80 प्रति 1k URL से
- प्रॉक्सी: $2.80 प्रति GB
सदस्यता लेने पर, आप प्रत्येक सेवा पर 20% तक की छूट का आनंद ले सकते हैं। क्या आपके पास विशिष्ट आवश्यकताएँ हैं? आज ही हमसे संपर्क करें, और हम आपकी आवश्यकताओं के अनुसार और भी अधिक बचत प्रदान करेंगे!
अपनी परियोजना में स्क्रैपलेस को एकीकृत करने के विस्तृत चरण
पूर्व आवश्यकताएँ
शुरू करने से पहले, आपको एक स्क्रैपलेस खाता पंजीकृत करने की आवश्यकता है। आप स्क्रैपलेस के बारे में अधिक जानने के लिए आधिकारिक वेबसाइट पर भी जा सकते हैं।
एक बार पंजीकृत होने के बाद, स्क्रैपलेस डैशबोर्ड पर जाएँ और बाईं ओर के पैनल पर वेब अनलॉकर मेनू पर क्लिक करें। यहाँ, आपको विभिन्न प्रकार के कॉन्फ़िगरेशन विकल्प मिलेंगे, जिनमें प्रॉक्सी, JS रेंडर, अनुरोध विधि और JS निर्देश शामिल हैं। ये सुविधाएँ नोड अनब्लॉकर की कई सीमाओं को संबोधित करती हैं, और आप अपनी आवश्यकताओं के अनुसार इन्हें अनुकूलित कर सकते हैं।
यदि आप इन कॉन्फ़िगरेशन विकल्पों से परिचित नहीं हैं, तो आप पृष्ठ पर "दस्तावेज़ीकरण" लिंक पर क्लिक करके विस्तृत दस्तावेज़ीकरण का संदर्भ ले सकते हैं।
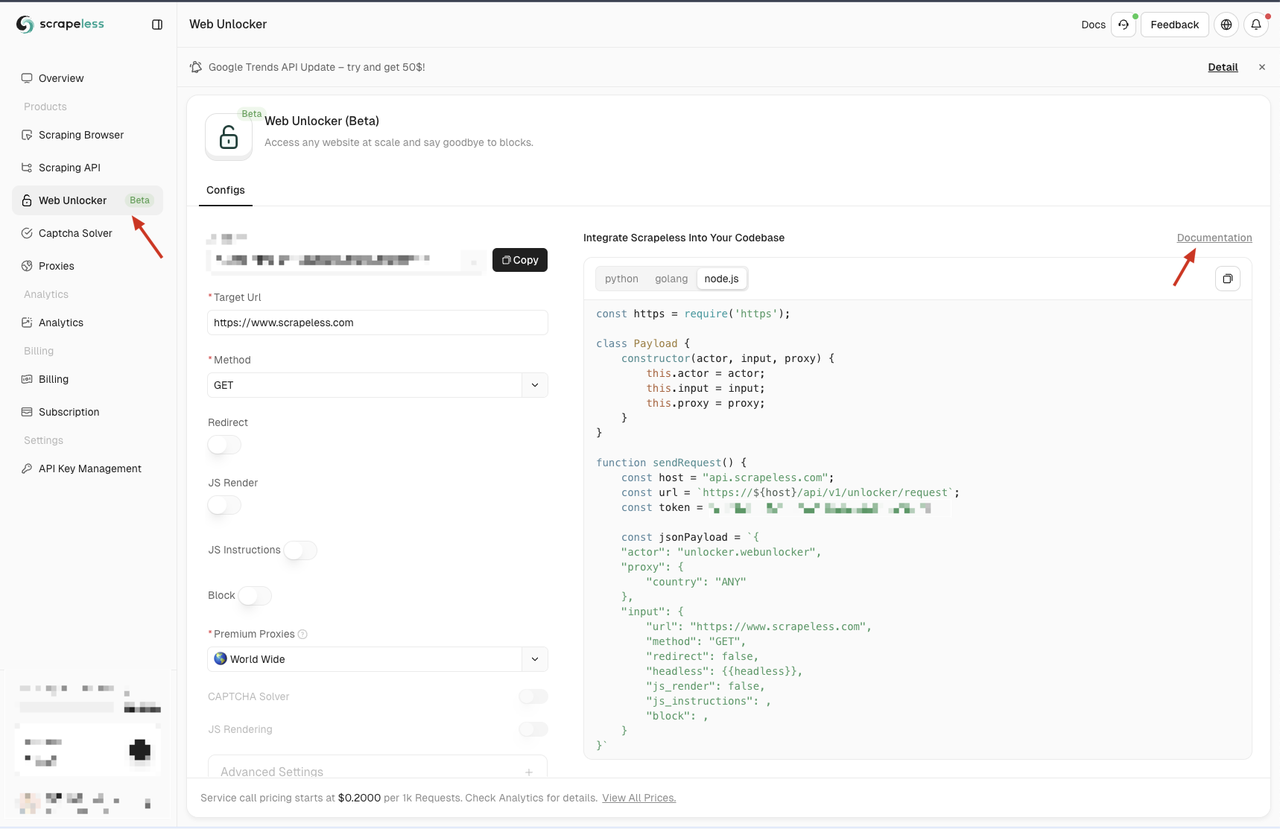
स्क्रैपलेस तीन प्रोग्रामिंग भाषाओं—पायथन, Node.js और Golang में कोड उदाहरण भी प्रदान करता है। आप अपनी आवश्यकताओं के अनुसार एकीकरण के लिए उपयुक्त भाषा चुन सकते हैं। इस उदाहरण में, हम Node.js का उपयोग करेंगे।
CAPTCHA बायपास करें
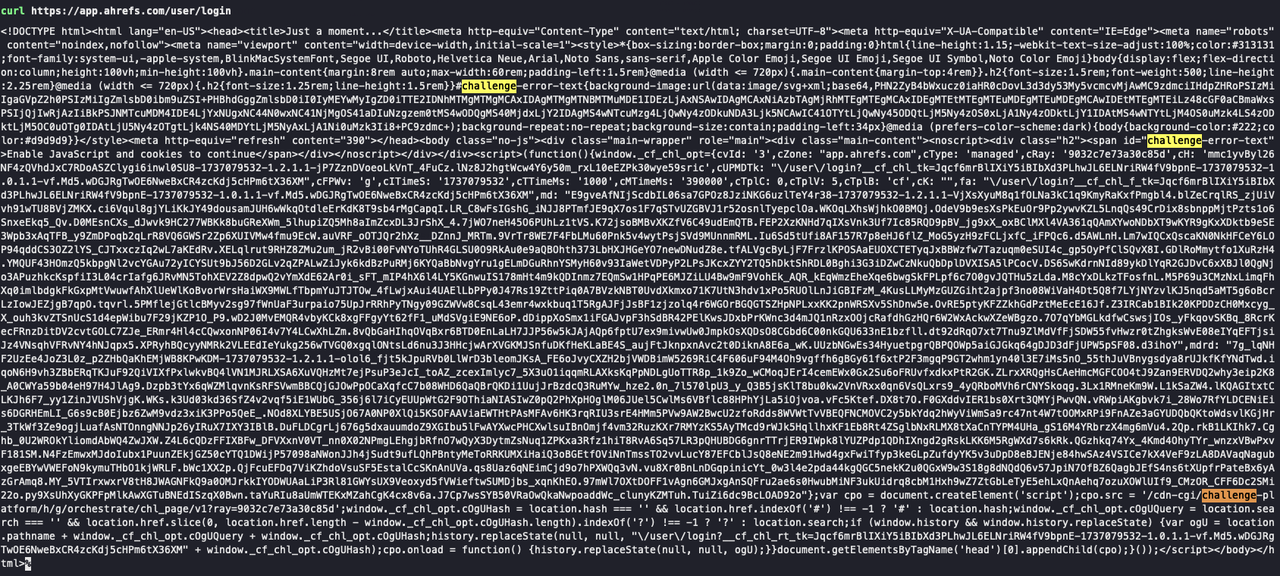
स्क्रैपलेस वेब अनलॉकर स्वचालित रूप से CAPTCHA बायपास कार्यक्षमता को सक्षम करता है, जिससे CAPTCHA चुनौतियों के बारे में चिंता दूर हो जाती है। इसे सत्यापित करने के लिए, सबसे पहले, कर्ल का उपयोग करके किसी ऐसी साइट पर अनुरोध करें जिसके लिए सत्यापन की आवश्यकता हो, जैसे:
Bash
curl https://app.ahrefs.com/user/loginनीचे दिए गए स्क्रीनशॉट में, कर्ल अनुरोध एक CAPTCHA सत्यापन पृष्ठ देता है। आप प्रतिक्रिया में Cloudflare सत्यापन विवरण देख सकते हैं:
अब, उसी साइट पर अनुरोध करने के लिए स्क्रैपलेस वेब अनलॉकर का उपयोग करना, इन चरणों का पालन करें:
- निम्नलिखित कोड के साथ एक scrapeless-web-unlocker.js फ़ाइल बनाएँ:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // आपका टोकन
const inputData = {
url: 'https://app.ahrefs.com/user/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
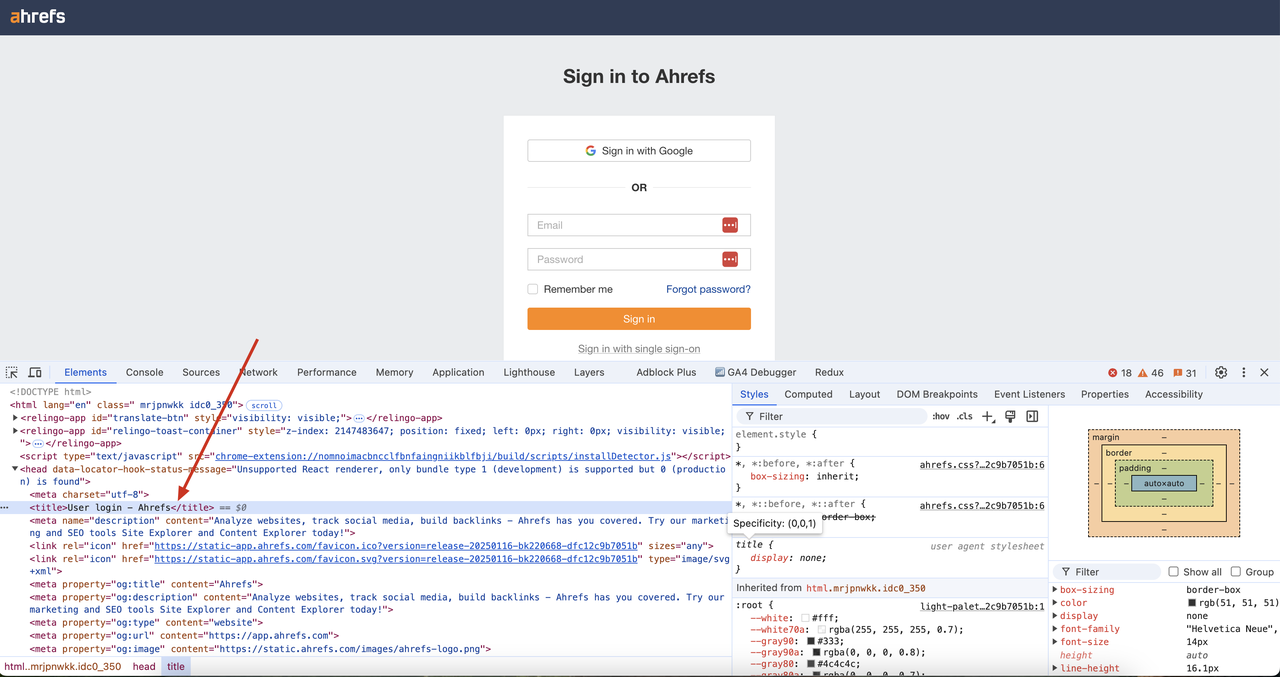
sendRequest();node scrapeless-web-unlocker.jsके साथ कोड चलाना।
हम देख सकते हैं कि लौटाए गए परिणामों में CAPTCHA सत्यापन सफलतापूर्वक बायपास कर दिया गया है, और पृष्ठ की DOM सामग्री प्राप्त हो गई है। इसके अलावा, पृष्ठ कोड में शीर्षक "उपयोगकर्ता लॉगिन - Ahrefs" भी हमारे परिणामों में सफलतापूर्वक प्राप्त किया जा सकता है।

जावास्क्रिप्ट रेंडरिंग
जावास्क्रिप्ट रेंडरिंग गतिशील रूप से लोड की गई सामग्री और सिंगल-पेज एप्लिकेशन (SPA) को संभाल सकता है। यह एक पूर्ण ब्राउज़र वातावरण को सक्षम करता है और अधिक जटिल पृष्ठ इंटरैक्शन और रेंडरिंग आवश्यकताओं का समर्थन करता है। स्क्रैपलेस की वेब अनलॉकर सेवा उस समस्या को हल कर सकती है जिसे नोड अनब्लॉकर जावास्क्रिप्ट निष्पादित नहीं कर सकता है। हम स्क्रैपलेस के वेब अनलॉकर में जावास्क्रिप्ट रेंडरिंग फ़ंक्शन को सक्षम कर सकते हैं ताकि हम जावास्क्रिप्ट द्वारा प्रदान की गई पृष्ठ सामग्री प्राप्त कर सकें।
हम जावास्क्रिप्ट रेंडरिंग का उपयोग करने वाली वेबसाइट ढूंढ सकते हैं, जैसे Cloudflare का डैशबोर्ड लॉगिन पृष्ठ। हम देख सकते हैं कि यह जिस फ़्रेमवर्क तकनीक का उपयोग करता है वह React.js है, और React.js एक सिंगल-पेज एप्लिकेशन फ़्रेमवर्क है, और इसकी सामग्री जावास्क्रिप्ट द्वारा प्रदान की जाती है।
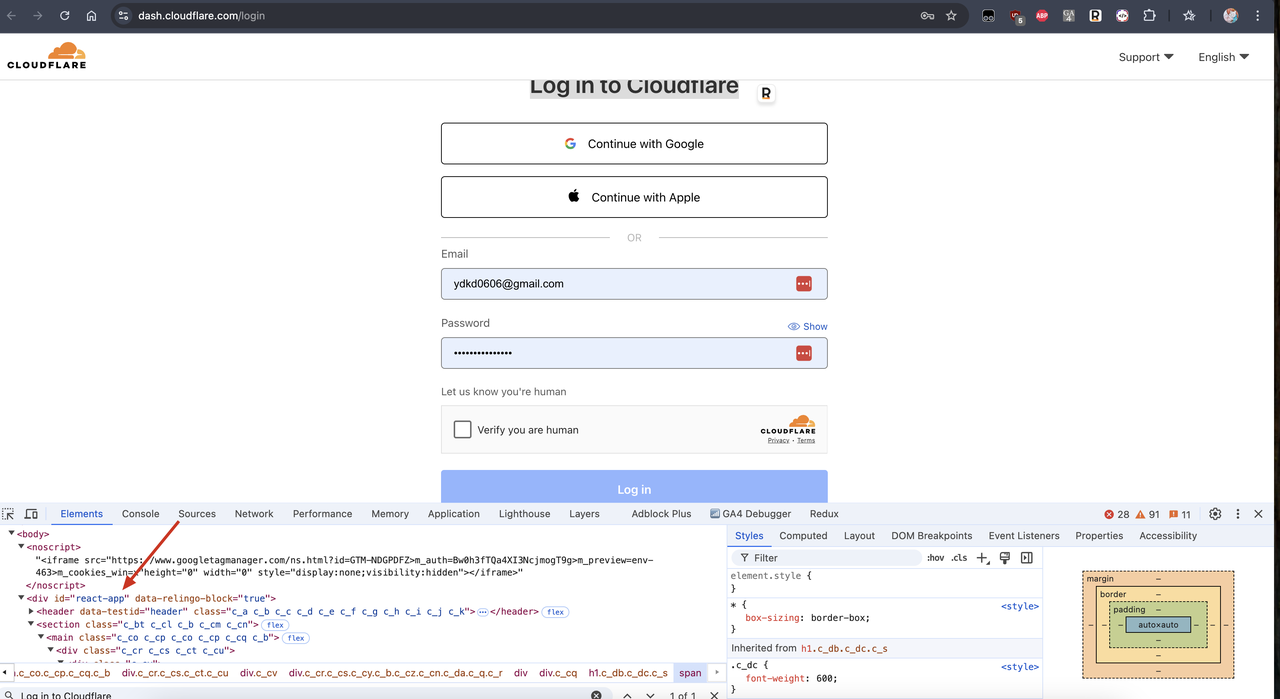
अब, आइए जावास्क्रिप्ट रेंडरिंग को सक्षम किए बिना Cloudflare के डैशबोर्ड लॉगिन पृष्ठ की सामग्री प्राप्त कर सकते हैं या नहीं, यह देखने के लिए पिछले कोड को थोड़ा संशोधित करें। कोड को इस प्रकार संशोधित करें:
JavaScript
...
url: 'https://dash.cloudflare.com/login',
...हम देख सकते हैं कि लौटाए गए परिणाम में id="react-app" वाला div खाली है, जिसका अर्थ है कि हमें जावास्क्रिप्ट रेंडरिंग के बाद पृष्ठ सामग्री नहीं मिली:
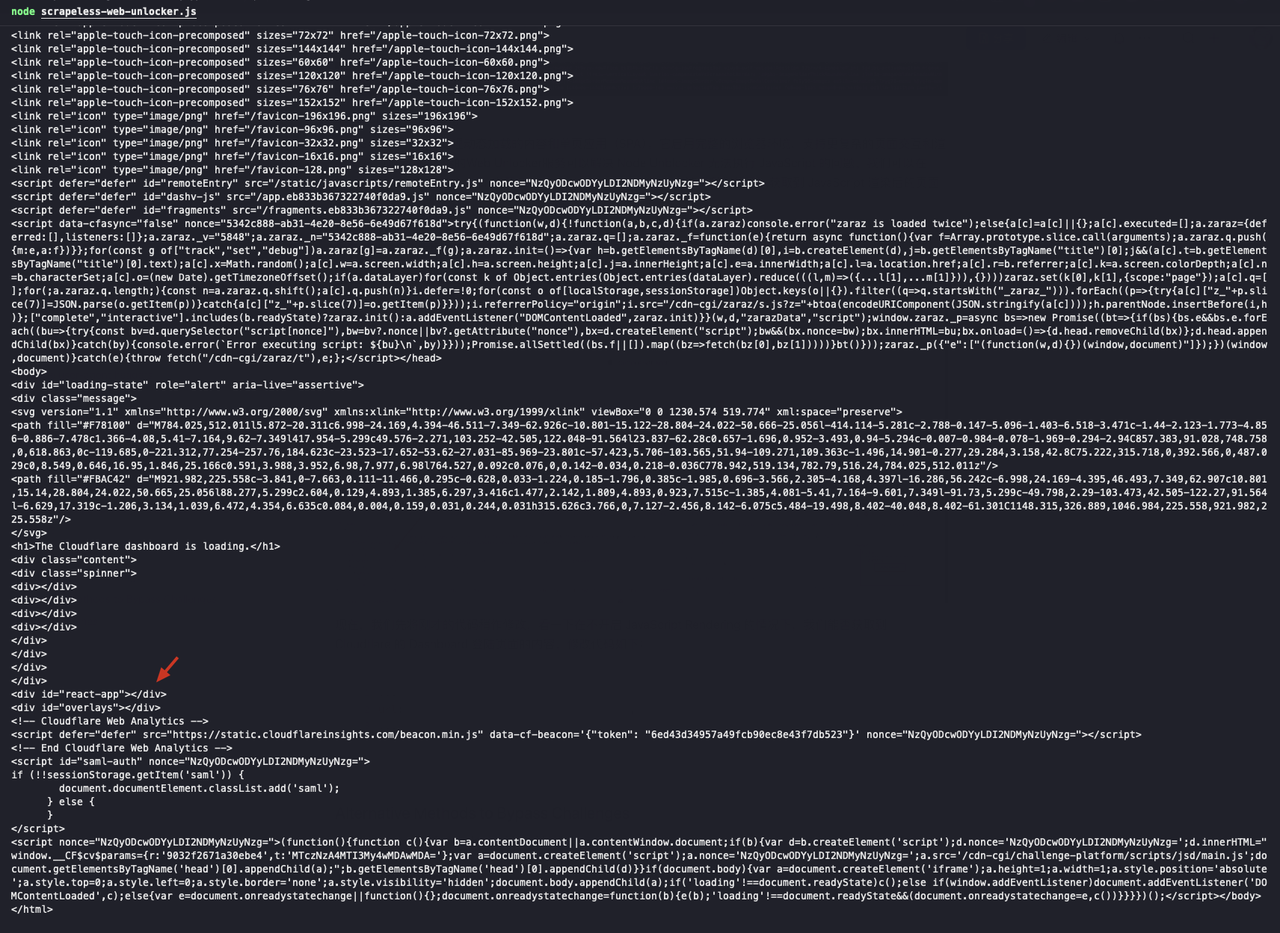
अगला, हम जावास्क्रिप्ट रेंडरिंग फ़ंक्शन को चालू करते हैं और कोड को इस प्रकार संशोधित करते हैं:
JavaScript
const inputData = {
url: 'https://dash.cloudflare.com/login',
method: 'GET',
redirect: false,
js_render: true, // नया विकल्प
js_instructions: [ // नया विकल्प
{
wait: 20000,
},
],
};उपरोक्त कोड में, हमने दो नए कॉन्फ़िगरेशन विकल्प, js_render और js_instructions जोड़े हैं। अधिक निर्देश संदर्भों के लिए, कृपया स्क्रैपलेस डॉक्स देखें:
js_renderका उपयोग जावास्क्रिप्ट रेंडरिंग फ़ंक्शन को चालू करने के लिए किया जाता हैjs_instructionsका उपयोग जावास्क्रिप्ट रेंडरिंग के लिए निर्देश सेट करने के लिए किया जाता है। यहाँ, हम पृष्ठ लोड होने के बाद परिणाम वापस करने के लिए 20 सेकंड का प्रतीक्षा निर्देश सेट करते हैं।
नोट: अब कई वेबसाइटों में डिफ़ॉल्ट रूप से लोडिंग प्रक्रिया होती है, इसलिए हमें यह सुनिश्चित करने के लिए कुछ समय प्रतीक्षा करने की आवश्यकता है कि पृष्ठ लोड होने से पहले परिणाम लौटाया जाए
अब, हम फिर से कोड चलाते हैं, और हम देख सकते हैं कि लौटाए गए परिणाम में Cloudflare के डैशबोर्ड लॉगिन पृष्ठ की सामग्री सफलतापूर्वक प्राप्त हो गई है। "Cloudflare में लॉग इन करें" का पाठ पुनर्प्राप्त करके, हम देख सकते हैं कि हमने जावास्क्रिप्ट द्वारा प्रदान की गई पृष्ठ सामग्री को सफलतापूर्वक प्राप्त कर लिया है।
Bash
node scrapeless-web-unlocker.js
निष्कर्ष
वेब सामग्री तक पहुँचने की बढ़ती चुनौतियों के लिए नए समाधानों की आवश्यकता है। इस लेख में, हमने नोड अनब्लॉकर को देखा, एक NodeJS लाइब्रेरी जो एक वेब प्रॉक्सी प्रदान करती है जो डेटा को संसाधित करती है और उसे क्लाइंट को अग्रेषित करती है।
हालांकि, इसकी सीमाएँ इसे एक लागत प्रभावी वेब स्क्रैपिंग समाधान होने से रोकती हैं। इसलिए एक अधिक कुशल और सस्ता समाधान की आवश्यकता थी। जैसा कि सभी सहमत हैं - बेहतर सर्व-दूर सेवाओं और कम कीमतों के साथ स्क्रैपलेस स्पष्ट विजेता है।
अपना मुफ़्त वेब अनलॉकर प्राप्त करने के लिए अभी साइन अप करें!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


