
Node-Fetch API का उपयोग करके Node.js में HTTP अनुरोध कैसे करें?
Specialist in Anti-Bot Strategies
हमारी वर्तमान वेबसाइटें आमतौर पर दर्जनों विभिन्न संसाधनों पर निर्भर करती हैं, जैसे कि छवियों, CSS, फ़ॉन्ट्स, जावास्क्रिप्ट, JSON डेटा आदि का एक एकल संग्रह। हालाँकि, दुनिया की पहली वेबसाइट केवल HTML में लिखी गई थी।
जावास्क्रिप्ट, एक उत्कृष्ट क्लाइंट-साइड स्क्रिप्टिंग भाषा के रूप में, वेबसाइटों के विकास में एक महत्वपूर्ण भूमिका निभाई है। XMLHttpRequest या XHR ऑब्जेक्ट्स की मदद से, जावास्क्रिप्ट पेज को फिर से लोड किए बिना क्लाइंट और सर्वर के बीच संचार प्राप्त कर सकता है।
हालांकि, यह गतिशील प्रक्रिया Fetch API द्वारा चुनौती दी जाती है। Fetch API क्या है? Node.js में Fetch API का उपयोग कैसे करें? Fetch API बेहतर विकल्प क्यों है?
इस लेख से अभी उत्तर प्राप्त करना शुरू करें!
Node.js में HTTP अनुरोध क्या हैं?
Node.js में, HTTP अनुरोध वेब एप्लिकेशन बनाने या वेब सेवाओं के साथ इंटरैक्ट करने का एक मूलभूत हिस्सा हैं। वे एक क्लाइंट (जैसे ब्राउज़र या कोई अन्य एप्लिकेशन) को सर्वर पर डेटा भेजने या सर्वर से डेटा का अनुरोध करने की अनुमति देते हैं। ये अनुरोध हाइपरटेक्स्ट ट्रांसफर प्रोटोकॉल (HTTP) का उपयोग करते हैं, जो वेब पर डेटा संचार का आधार है।
- HTTP अनुरोध: एक HTTP अनुरोध एक क्लाइंट द्वारा सर्वर पर भेजा जाता है, आमतौर पर डेटा प्राप्त करने के लिए (जैसे एक वेबपेज या API प्रतिक्रिया) या सर्वर पर डेटा भेजने के लिए (जैसे कोई फॉर्म सबमिट करना)।
- HTTP विधियाँ: HTTP अनुरोधों में आमतौर पर एक विधि शामिल होती है, जो इंगित करती है कि क्लाइंट सर्वर से क्या कार्रवाई करना चाहता है। सामान्य HTTP विधियों में शामिल हैं:
- GET: सर्वर से डेटा का अनुरोध करें।
- POST: सर्वर पर डेटा भेजें (जैसे, कोई फॉर्म सबमिट करना)।
- PUT: सर्वर पर मौजूदा डेटा को अपडेट करें।
- DELETE: सर्वर से डेटा निकालें।
- Node.js HTTP मॉड्यूल: Node.js HTTP अनुरोधों को संभालने के लिए एक अंतर्निहित http मॉड्यूल प्रदान करता है। यह मॉड्यूल आपको एक HTTP सर्वर बनाने, अनुरोधों को सुनने और उनका जवाब देने में सक्षम बनाता है।
वेब स्क्रैपिंग और ऑटोमेशन के लिए Node.js आदर्श क्यों है?
अपनी अनूठी विशेषताओं, मजबूत इकोसिस्टम और एसिंक्रोनस, गैर-अवरुद्ध आर्किटेक्चर के कारण Node.js वेब स्क्रैपिंग और ऑटोमेशन कार्यों के लिए गो-टू तकनीकों में से एक बन गया है।
वेब स्क्रैपिंग और ऑटोमेशन के लिए Node.js आदर्श क्यों है? आइए उन्हें जानते हैं!
- एसिंक्रोनस और गैर-अवरुद्ध I/O
- गति और दक्षता
- पुस्तकालयों और ढाँचों का समृद्ध पारिस्थितिकी तंत्र
- हेडलेस ब्राउज़रों के साथ गतिशील सामग्री को संभालना
- क्रॉस-प्लेटफ़ॉर्म संगतता
- वास्तविक समय डेटा प्रसंस्करण
- तेजी से विकास के लिए सरल सिंटैक्स
- प्रॉक्सी रोटेशन और एंटी-डिटेक्शन के लिए समर्थन
Node-Fetch API क्या है?
Node-fetch एक हल्का मॉड्यूल है जो Node.js वातावरण में Fetch API लाता है। यह HTTP अनुरोध करने और प्रतिक्रियाओं को संभालने की प्रक्रिया को सरल करता है।
Fetch API वादों के आसपास बनाया गया है और वेबसाइट से डेटा स्क्रैप करने, RESTful API के साथ इंटरैक्ट करने या कार्यों को स्वचालित करने जैसे एसिंक्रोनस संचालन के लिए उपयुक्त है।
Node.JS में Fetch API का उपयोग कैसे करें?
Fetch API एक आधुनिक, वादा-आधारित इंटरफ़ेस है जिसे पारंपरिक XMLHttpRequest ऑब्जेक्ट की तुलना में अधिक कुशल और लचीले तरीके से नेटवर्क अनुरोधों को संभालने के लिए डिज़ाइन किया गया है।
यह समकालीन ब्राउज़रों में मूल रूप से समर्थित है, जिसका अर्थ है कि अतिरिक्त पुस्तकालयों या प्लगइन्स की कोई आवश्यकता नहीं है। इस गाइड में, हम GET और POST अनुरोधों को करने के साथ-साथ प्रतिक्रियाओं और त्रुटियों को प्रभावी ढंग से प्रबंधित करने के लिए Fetch API का उपयोग कैसे करें, इसका पता लगाएंगे।
💬 नोट: यदि आपके कंप्यूटर पर Node.js स्थापित नहीं है, तो आपको इसे पहले स्थापित करना होगा। आप अपने ऑपरेटिंग सिस्टम के लिए उपयुक्त Node.js इंस्टॉलेशन पैकेज यहाँ से डाउनलोड कर सकते हैं। अनुशंसित Node.js संस्करण 18 और ऊपर है।
चरण 1. अपने Node.js प्रोजेक्ट को इनिशियलाइज़ करें
यदि आपने अभी तक कोई प्रोजेक्ट नहीं बनाया है, तो आप निम्न कमांड के साथ एक नया प्रोजेक्ट बना सकते हैं:
Bash
mkdir fetch-api-tutorial
cd fetch-api-tutorial
npm init -ypackage.json फ़ाइल खोलें, type फ़ील्ड जोड़ें, और इसे module पर सेट करें:
JSON
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}चरण 2. node-fetch लाइब्रेरी डाउनलोड और इंस्टॉल करें
यह Node.js में Fetch API का उपयोग करने के लिए एक लाइब्रेरी है। आप निम्न कमांड के साथ node-fetch लाइब्रेरी इंस्टॉल कर सकते हैं:
Bash
npm install node-fetchडाउनलोड पूरा होने के बाद, हम नेटवर्क अनुरोध भेजने के लिए Fetch API का उपयोग करना शुरू कर सकते हैं। प्रोजेक्ट की रूट निर्देशिका में एक नई फ़ाइल index.js बनाएँ और निम्न कोड जोड़ें:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));कोड चलाने के लिए निम्न कमांड निष्पादित करें:
Bash
node index.jsहमें निम्नलिखित आउटपुट दिखाई देगा:
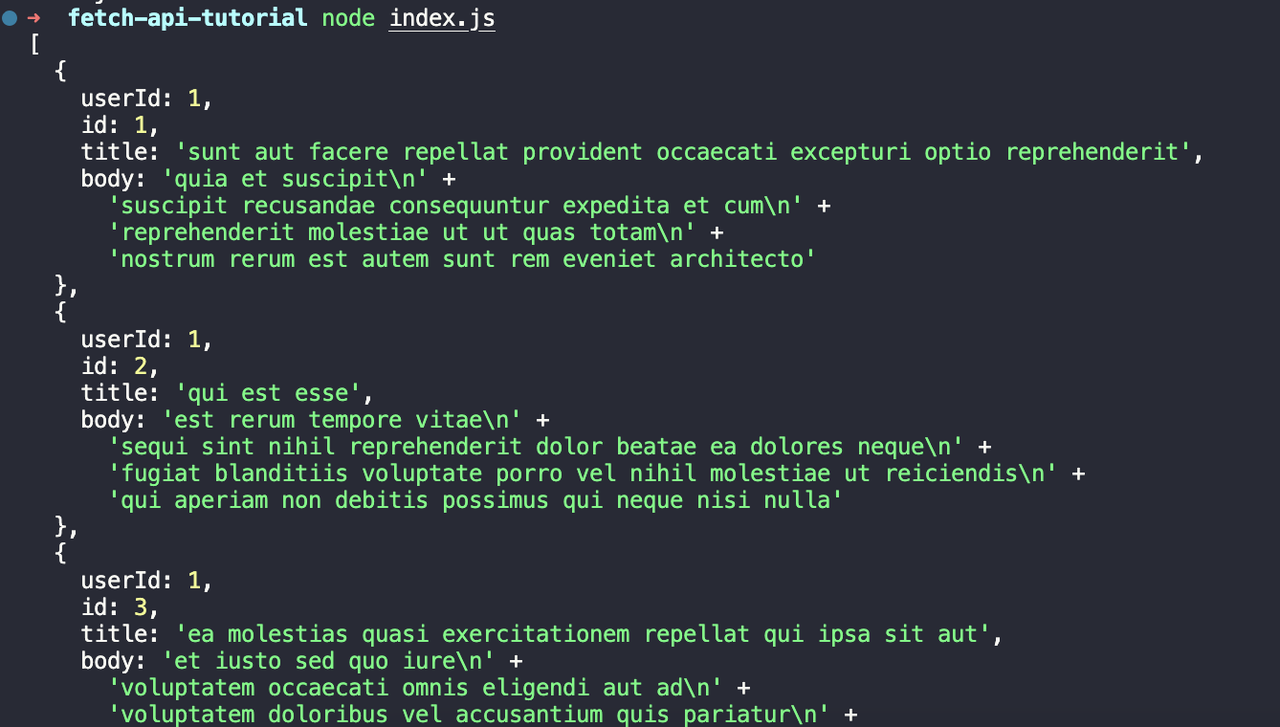
चरण 3. POST अनुरोध भेजने के लिए Fetch API का उपयोग करें
POST अनुरोध भेजने के लिए Fetch API का उपयोग कैसे करें? कृपया निम्नलिखित विधि देखें। प्रोजेक्ट की रूट निर्देशिका में एक नई फ़ाइल post.js बनाएँ और निम्न कोड जोड़ें:
JavaScript
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));आइए इस कोड का विश्लेषण करें:
- हम पहले
postDataनामक एक ऑब्जेक्ट को परिभाषित करते हैं, जिसमें वह डेटा होता है जिसे हम भेजना चाहते हैं। - फिर हम
https://jsonplaceholder.typicode.com/postsपर POST अनुरोध भेजने के लिएfetchफ़ंक्शन का उपयोग करते हैं, दूसरे पैरामीटर के रूप में एक कॉन्फ़िगरेशन ऑब्जेक्ट पास करते हैं। - कॉन्फ़िगरेशन ऑब्जेक्ट में अनुरोध
method, अनुरोधheadersऔर अनुरोधbodyशामिल हैं।
कोड चलाने के लिए निम्न कमांड निष्पादित करें:
Bash
node post.jsआपको दिखाई देने वाला आउटपुट:

चरण 4. Fetch API प्रतिक्रिया परिणामों और त्रुटियों को संभालना
हमें प्रोजेक्ट की रूट निर्देशिका में एक नई फ़ाइल response.js बनाने की आवश्यकता है और निम्न कोड जोड़ना होगा:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts-response')
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
})
.then((data) => console.log(data))
.catch((error) => console.error(error));उपरोक्त कोड में, हम पहले एक गलत URL पता भरते हैं ताकि HTTP त्रुटि उत्पन्न हो सके। फिर हम then विधि में परिणामी प्रतिक्रिया की स्थिति कोड की जांच करते हैं, और यदि स्थिति कोड 200 नहीं है तो एक त्रुटि उत्पन्न करते हैं। अंत में, हम catch विधि में त्रुटि को पकड़ते हैं और उसे प्रिंट करते हैं।
कोड चलाने के लिए निम्न कमांड निष्पादित करें:
Bash
node response.jsकोड निष्पादित होने के बाद, आपको निम्नलिखित आउटपुट दिखाई देगा:

वेब स्क्रैपिंग में 3 सामान्य चुनौतियाँ
1. CAPTCHAs
CAPTCHAs (कंप्यूटर और मनुष्यों को अलग करने के लिए पूरी तरह से स्वचालित सार्वजनिक ट्यूरिंग परीक्षण) स्वचालित सिस्टम, जैसे वेब स्क्रैपर को वेबसाइट तक पहुँचने से रोकने के लिए डिज़ाइन किए गए हैं। उन्हें आमतौर पर उपयोगकर्ताओं को यह साबित करने की आवश्यकता होती है कि वे पहेलियाँ सुलझाकर, छवियों में वस्तुओं की पहचान करके या विकृत वर्ण दर्ज करके मानव हैं।
2. गतिशील सामग्री
कई आधुनिक वेबसाइटें सामग्री को गतिशील रूप से लोड करने के लिए React, Angular, या Vue.js जैसे जावास्क्रिप्ट फ़्रेमवर्क का उपयोग करती हैं। इसका मतलब है कि आप ब्राउज़र में जो सामग्री देखते हैं वह अक्सर पृष्ठ लोड होने के बाद रेंडर की जाती है, जिससे पारंपरिक तरीकों से स्क्रैप करना मुश्किल हो जाता है जो स्थिर HTML पर निर्भर करते हैं।
3. IP प्रतिबंध
वेबसाइटें अक्सर स्क्रैपिंग गतिविधियों का पता लगाने और ब्लॉक करने के उपाय लागू करती हैं, जिनमें से सबसे सामान्य तरीका IP ब्लॉकिंग है। यह तब होता है जब थोड़े समय में एक ही IP पते से बहुत अधिक अनुरोध भेजे जाते हैं, जिससे वेबसाइट उस IP को फ्लैग और ब्लॉक कर देती है।
Scrapeless स्क्रैपिंग टूलकिट - कुशल स्क्रैपिंग उपकरण
IP ब्लॉकिंग, CAPTCHA चुनौतियों और जावास्क्रिप्ट रेंडरिंग सहित वास्तविक समय में वेबसाइट ब्लॉक को बायपास करने की क्षमता के कारण Scrapeless सर्वोत्तम व्यापक स्क्रैपिंग टूल में से एक है। यह उन्नत सुविधाओं जैसे IP रोटेशन, TLS फिंगरप्रिंट प्रबंधन और CAPTCHA सॉल्विंग का समर्थन करता है, जो इसे बड़े पैमाने पर वेब स्क्रैपिंग के लिए आदर्श बनाता है।
Scrapeless Node.js वेब स्क्रैपिंग प्रोजेक्ट्स को कैसे बढ़ाता है?
Node.js के साथ इसका आसान एकीकरण और पता लगाने से बचने की उच्च सफलता दर Scrapeless को आधुनिक एंटी-बॉट डिफेंस को बायपास करने के लिए एक विश्वसनीय और कुशल विकल्प बनाती है, जिससे सुचारू और निर्बाध स्क्रैपिंग संचालन सुनिश्चित होता है।
मैनुअल स्क्रैपिंग पर स्क्रैपलेस जैसे स्क्रैपिंग टूलकिट का उपयोग करने के लाभ
- वेबसाइट ब्लॉक का कुशल संचालन: Scrapeless वास्तविक समय में IP ब्लॉक, CAPTCHAs और जावास्क्रिप्ट रेंडरिंग जैसे सामान्य एंटी-स्क्रैपिंग डिफेंस को बायपास कर सकता है, जिसे मैनुअल स्क्रैपिंग कुशलतापूर्वक संभाल नहीं सकता है।
- विश्वसनीयता और सफलता दर: Scrapeless पता लगाने से बचने के लिए IP रोटेशन और TLS फिंगरप्रिंट प्रबंधन जैसी उन्नत सुविधाओं का उपयोग करता है, जिससे मैनुअल स्क्रैपिंग की तुलना में उच्च सफलता दर और निर्बाध स्क्रैपिंग सुनिश्चित होती है।
- आसान एकीकरण और स्वचालन: Node.js के साथ सहजता से एकीकृत होता है और संपूर्ण स्क्रैपिंग वर्कफ़्लो को स्वचालित करता है, जो मैनुअल डेटा संग्रह की तुलना में समय बचाता है और मानवीय त्रुटि को कम करता है।
कुछ आसान चरणों का पालन करें, आप अपने Node.js प्रोजेक्ट में Scrapeless को एकीकृत कर सकते हैं।
स्क्रॉल करते रहने का समय आ गया है! निम्नलिखित और भी अद्भुत होगा!
अपने Node.js प्रोजेक्ट में Scrapeless स्क्रैपिंग टूलकिट को एकीकृत करना
शुरू करने से पहले, आपको Scrapeless खाता पंजीकृत करने की आवश्यकता है। आप Scrapeless के बारे में अधिक जानने के लिए आधिकारिक वेबसाइट को भी देख सकते हैं।
चरण 1. Node.js में Scrapeless स्क्रैपिंग API तक पहुँचना
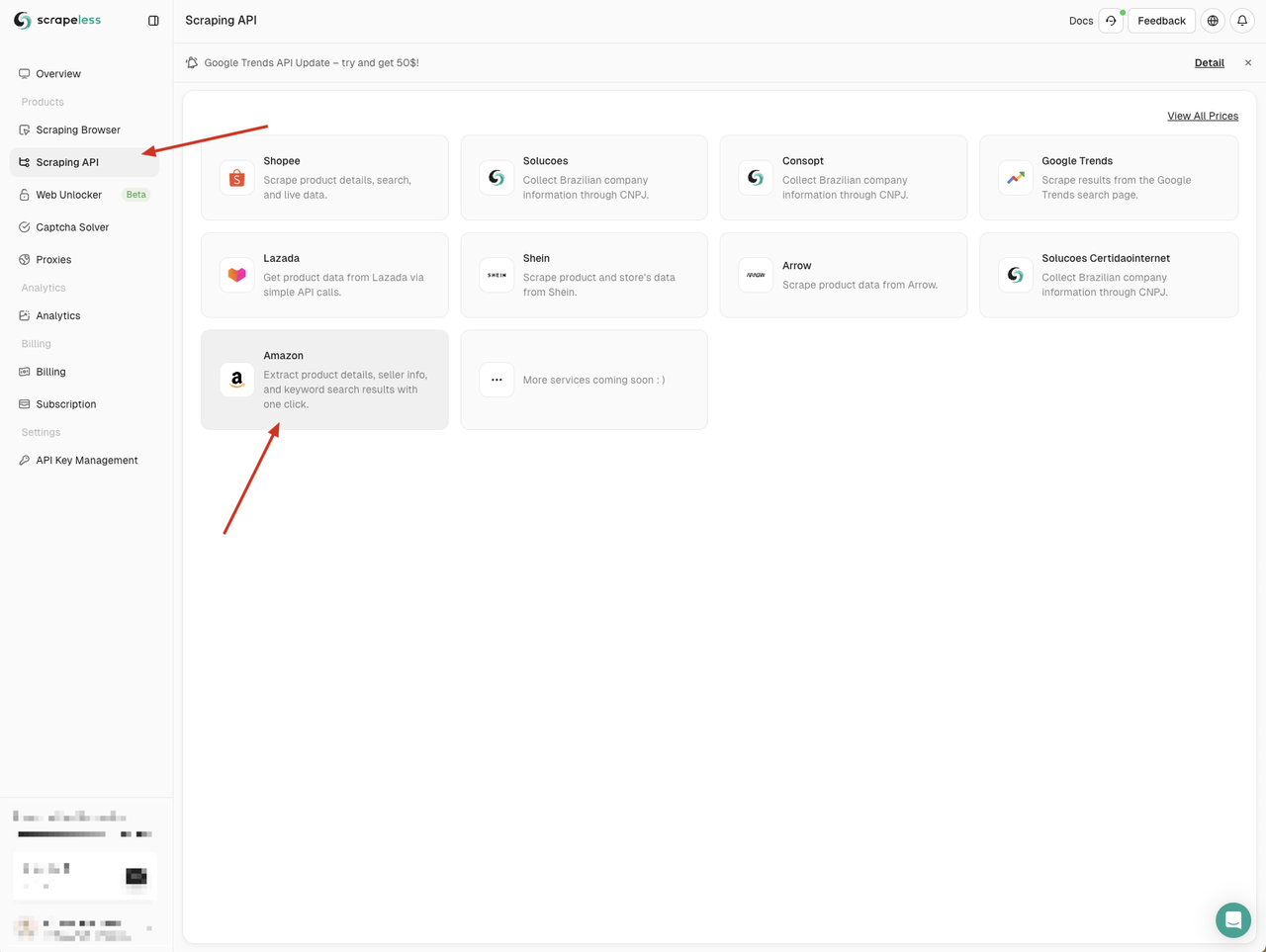
हमें Scrapeless डैशबोर्ड पर जाना होगा, बाईं ओर "स्क्रैपिंग API" मेनू पर क्लिक करें, और फिर उस सेवा का चयन करें जिसका आप उपयोग करना चाहते हैं।
यहाँ हम "Amazon" सेवा का उपयोग कर सकते हैं
Amazon API पृष्ठ में प्रवेश करने पर, हम देख सकते हैं कि Scrapeless ने हमें तीन भाषाओं में डिफ़ॉल्ट पैरामीटर और कोड उदाहरण प्रदान किए हैं:
- Python
- Go
- Node.js
यहाँ हम Node.js चुनते हैं और कोड उदाहरण को अपने प्रोजेक्ट में कॉपी करते हैं:
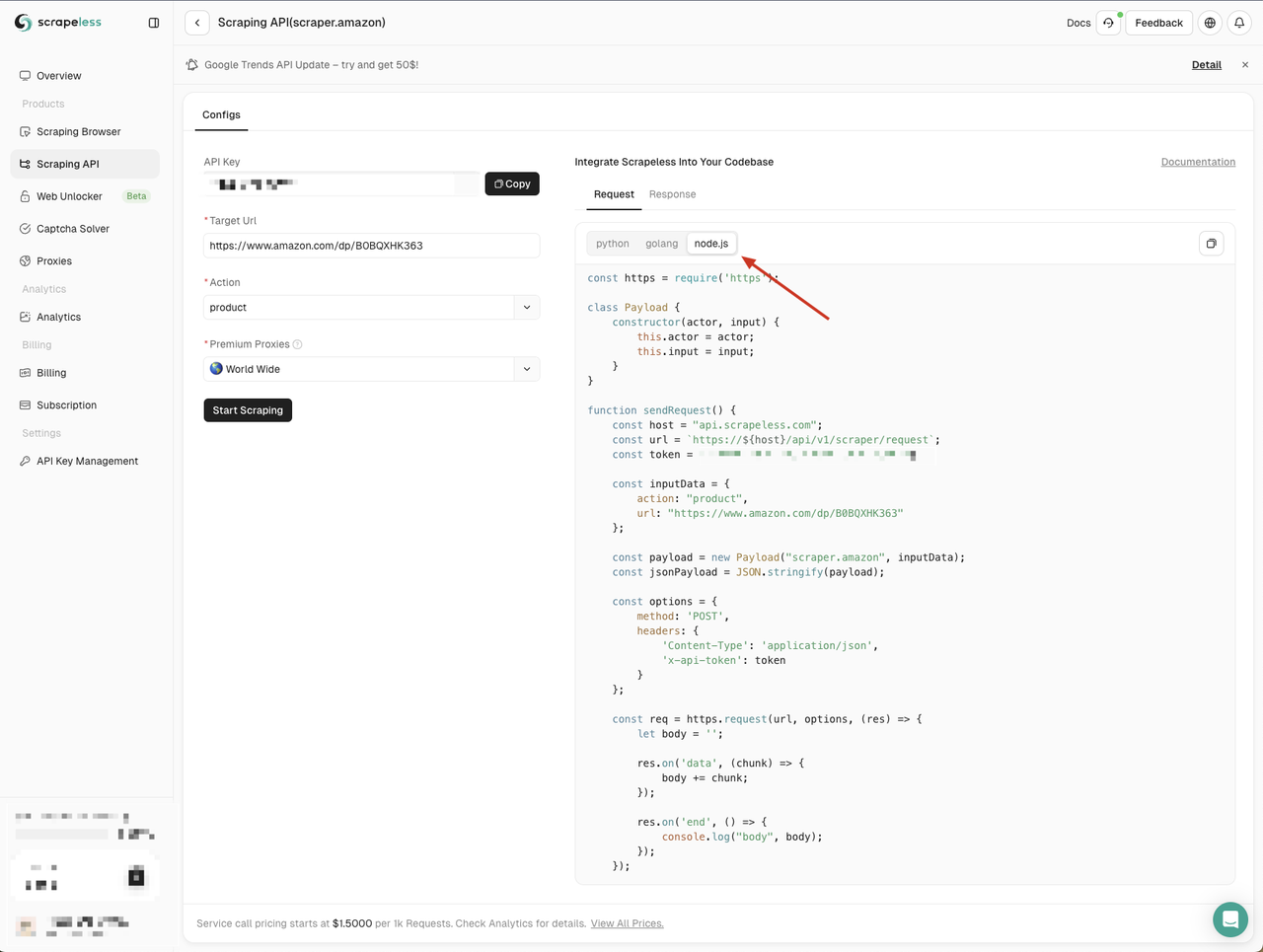
Scrapeless के Node.js कोड उदाहरण डिफ़ॉल्ट रूप से http मॉड्यूल का उपयोग करते हैं। हम node-fetch मॉड्यूल का उपयोग http मॉड्यूल को बदलने के लिए कर सकते हैं, ताकि हम नेटवर्क अनुरोध भेजने के लिए Fetch API का उपयोग कर सकें।
सबसे पहले, अपने प्रोजेक्ट में एक scraping-api-amazon.js फ़ाइल बनाएँ, और फिर Scrapeless द्वारा प्रदान किए गए कोड उदाहरणों को निम्न कोड उदाहरणों से बदलें:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/scraper/request`;
const token = ''; // Your API token
const inputData = {
action: 'product',
url: 'https://www.amazon.com/dp/B0BQXHK363',
};
const payload = new Payload('scraper.amazon', inputData);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP Error: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();निम्नलिखित कमांड निष्पादित करके कोड चलाएँ:
Bash
node scraping-api-amazon.js हमें Scrapeless API द्वारा लौटाए गए परिणाम दिखाई देंगे। यहाँ हम बस उन्हें प्रिंट करते हैं। आप अपनी आवश्यकताओं के अनुसार लौटाए गए परिणामों को संसाधित कर सकते हैं।
चरण 2. सामान्य एंटी-स्क्रैपिंग उपायों को बायपास करने के लिए वेब अनलॉकर का लाभ उठाना
Scrapeless एक वेब अनलॉकर सेवा प्रदान करता है जो आपको CAPTCHA बायपास, IP ब्लॉकिंग आदि जैसे सामान्य एंटी-स्क्रैपिंग उपायों को बायपास करने में मदद कर सकती है। वेब अनलॉकर सेवा आपको कुछ सामान्य क्रॉलिंग समस्याओं को हल करने और आपके क्रॉलिंग कार्यों को सुचारू बनाने में मदद कर सकती है।
वेब अनलॉकर सेवा की प्रभावशीलता को सत्यापित करने के लिए, हम पहले एक वेबसाइट तक पहुँचने के लिए कर्ल कमांड का उपयोग कर सकते हैं जिसके लिए CAPTCHA की आवश्यकता होती है, और फिर यह देखने के लिए कि क्या CAPTCHA को सफलतापूर्वक बायपास किया जा सकता है, उसी वेबसाइट तक पहुँचने के लिए Scrapeless वेब अनलॉकर सेवा का उपयोग कर सकते हैं।
- एक वेबसाइट तक पहुँचने के लिए कर्ल कमांड का उपयोग करें जिसके लिए सत्यापन कोड की आवश्यकता होती है, जैसे
https://identity.getpostman.com/login:
Bash
curl https://identity.getpostman.com/loginलौटाए गए परिणामों को देखकर, हम देख सकते हैं कि यह वेबसाइट Cloudflare सत्यापन तंत्र से जुड़ी हुई है, और हमें वेबसाइट तक पहुँचना जारी रखने के लिए सत्यापन कोड दर्ज करने की आवश्यकता है।

- हम उसी वेबसाइट तक पहुँचने के लिए Scrapeless वेब अनलॉकर सेवा का उपयोग करते हैं:
- Scrapeless डैशबोर्ड पर जाएँ
- बाईं ओर वेब अनलॉकर मेनू पर क्लिक करें
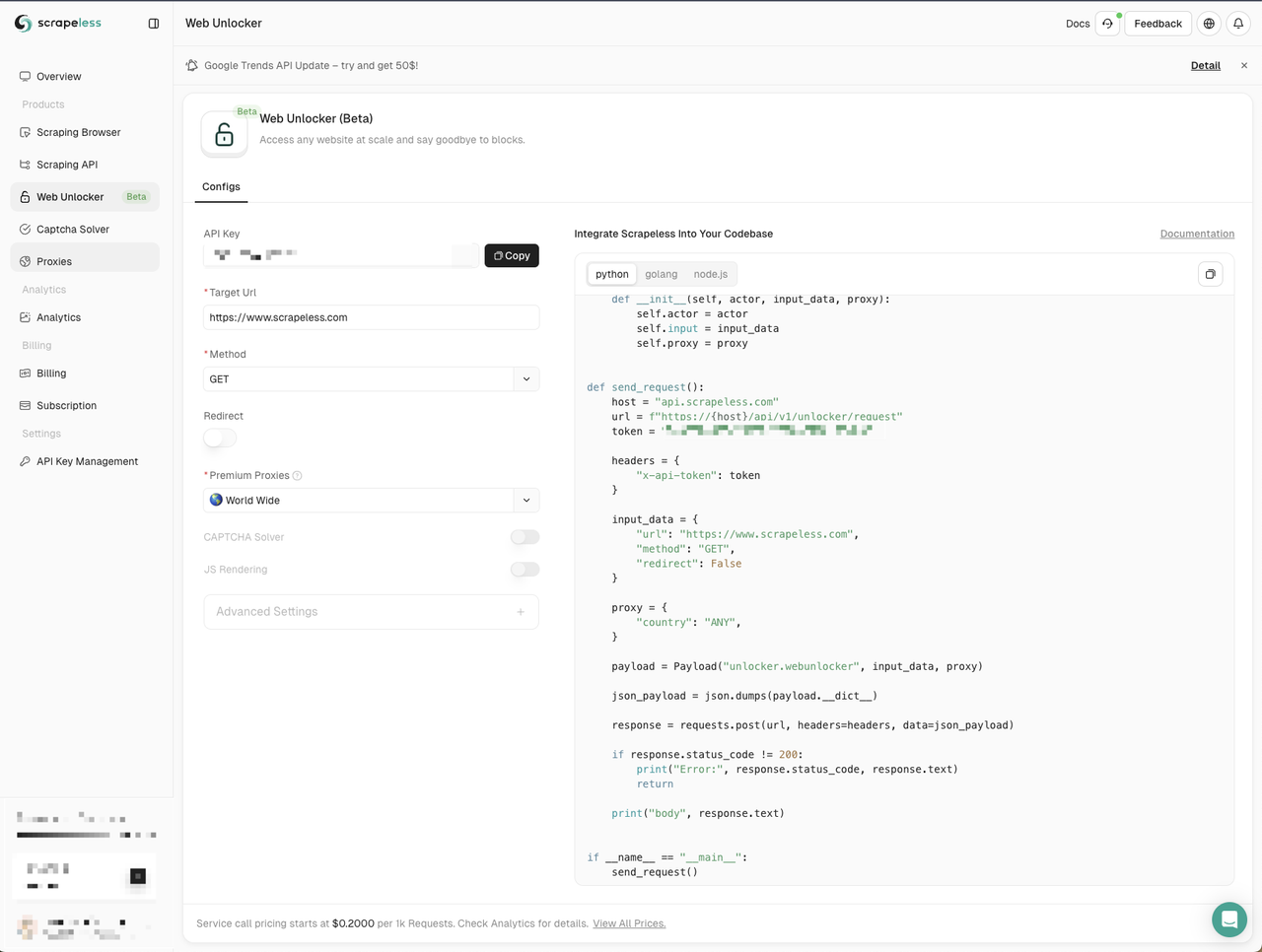
- अपने प्रोजेक्ट में Node.js कोड उदाहरण कॉपी करें
यहाँ हम एक नई web-unlocker.js फ़ाइल बनाते हैं। हमें नेटवर्क अनुरोध भेजने के लिए node-fetch मॉड्यूल का उपयोग करने की आवश्यकता है, इसलिए हमें Scrapeless द्वारा प्रदान किए गए कोड उदाहरण में http मॉड्यूल को node-fetch मॉड्यूल से बदलना होगा:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // Your API token
const inputData = {
url: 'https://identity.getpostman.com/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();स्क्रिप्ट चलाने के लिए निम्न कमांड निष्पादित करें:
JavaScript
web-unlocker.js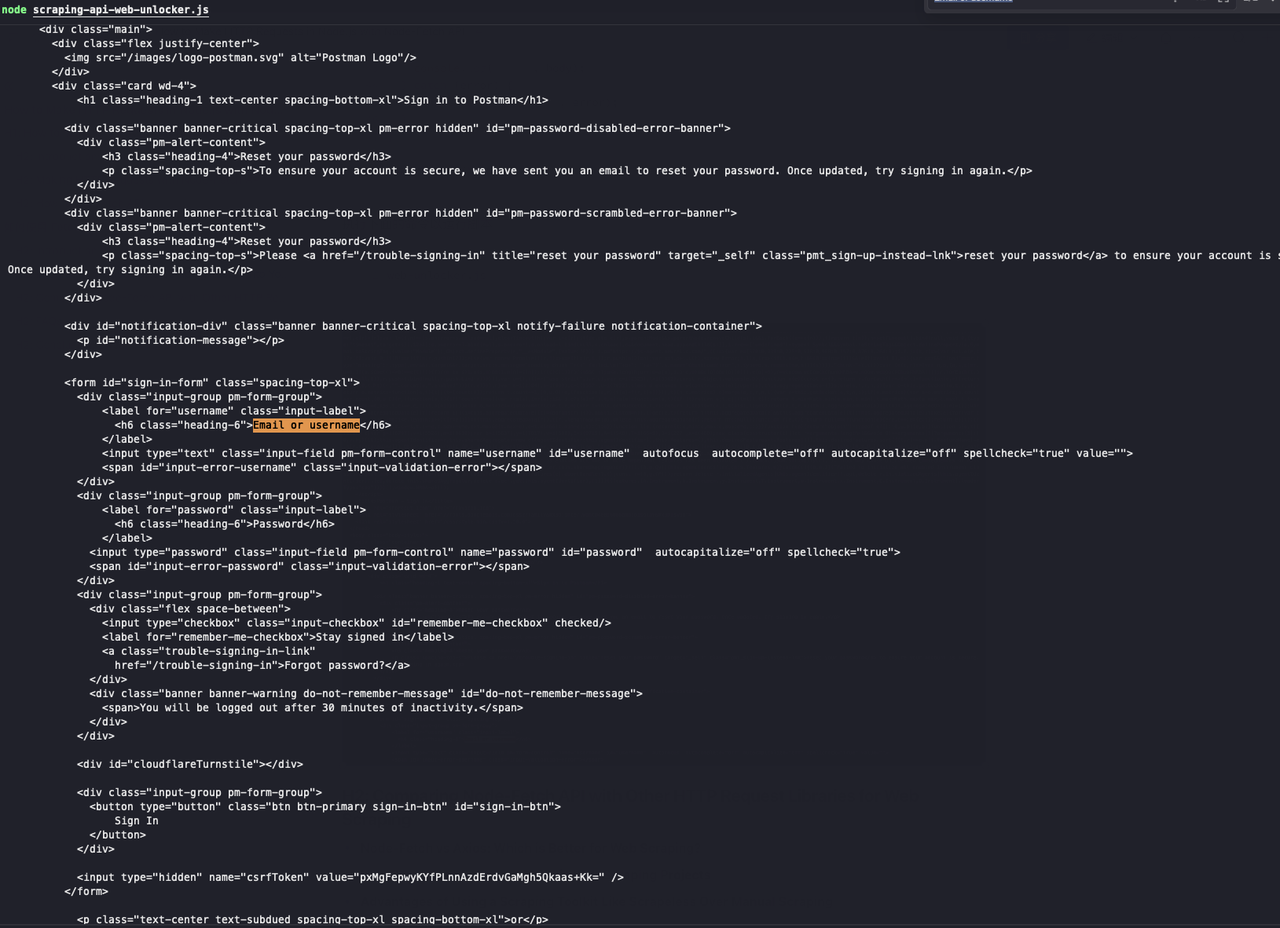
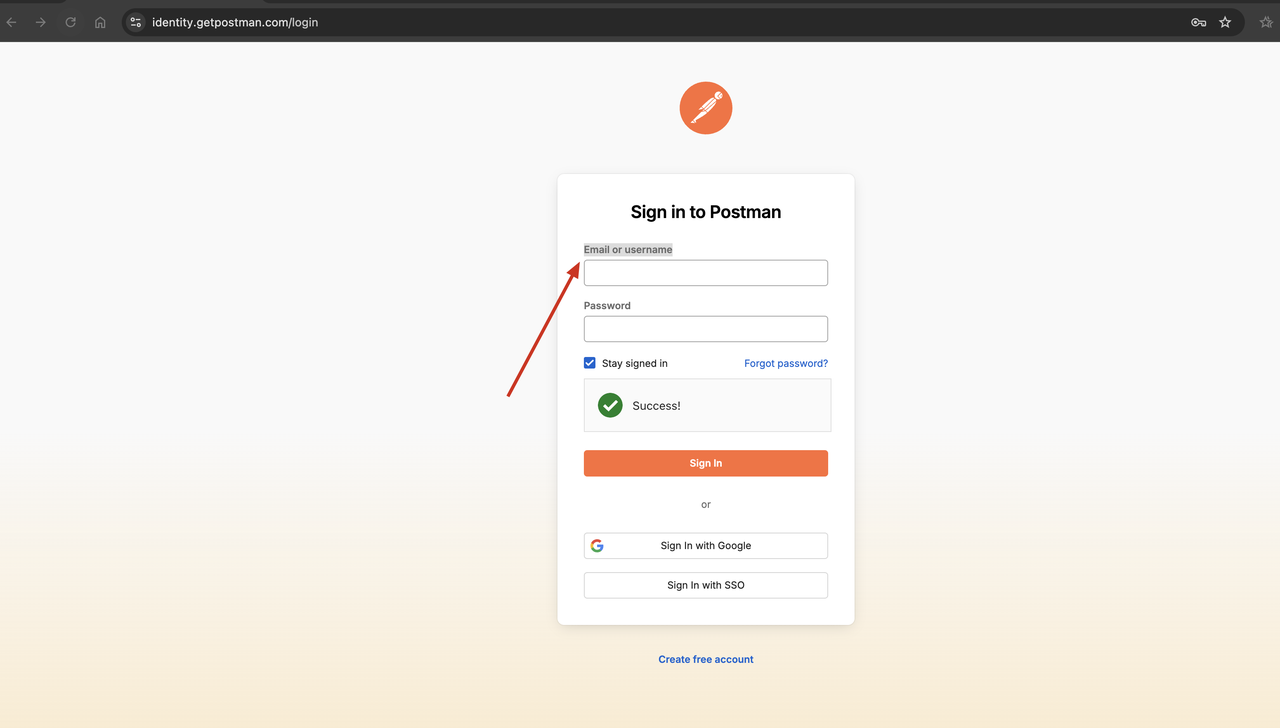
देखें! Scrapeless वेब अनलॉकर ने सत्यापन कोड को सफलतापूर्वक बायपास कर दिया, और हम देख सकते हैं कि लौटाए गए परिणामों में वह वेब पेज सामग्री है जिसकी हमें आवश्यकता है।
अक्सर पूछे जाने वाले प्रश्न
Q1. Node-Fetch बनाम Axios: वेब स्क्रैपिंग के लिए कौन सा बेहतर है?
आपका चुनाव आसान बनाने के लिए, Axios और Fetch API में निम्नलिखित अंतर हैं:
- Fetch API अनुरोध के body गुण का उपयोग करता है, जबकि Axios data गुण का उपयोग करता है।
- Axios के साथ, आप सीधे JSON डेटा भेज सकते हैं, जबकि Fetch API को स्ट्रिंग में बदलने की आवश्यकता है।
- Axios सीधे JSON को संसाधित कर सकता है। Fetch API को JSON प्रारूप में प्रतिक्रिया प्राप्त करने के लिए पहले response.json() विधि को कॉल करने की आवश्यकता होती है।
- Axios के लिए, प्रतिक्रिया डेटा चर नाम data होना चाहिए; Fetch API के लिए, प्रतिक्रिया डेटा चर नाम कुछ भी हो सकता है।
- Axios प्रगति इवेंट का उपयोग करके प्रगति की आसान निगरानी और अद्यतन की अनुमति देता है। Fetch API में कोई प्रत्यक्ष विधि नहीं है।
- Fetch API इंटरसेप्टर का समर्थन नहीं करता है, जबकि Axios करता है।
- Fetch API स्ट्रीमिंग प्रतिक्रियाओं की अनुमति देता है, जबकि Axios नहीं करता है।
Q2. क्या नोड फ़ेच स्थिर है?
Node. js v21 की सबसे उल्लेखनीय विशेषता Fetch API का स्थिरीकरण है।
Q3. क्या Fetch API AJAX से बेहतर है?
नई परियोजनाओं के लिए, इसकी आधुनिक सुविधाओं और सादगी के कारण Fetch API का उपयोग करने की अनुशंसा की जाती है। हालाँकि, यदि आपको बहुत पुराने ब्राउज़रों का समर्थन करने की आवश्यकता है या आप पुरानी कोड बनाए रख रहे हैं, तो Ajax अभी भी आवश्यक हो सकता है।
निष्कर्ष
Node.js में Fetch API का जुड़ना एक लंबे समय से प्रतीक्षित सुविधा है। Node.js में Fetch API का उपयोग यह सुनिश्चित कर सकता है कि आपका स्क्रैपिंग कार्य आसानी से हो जाए। हालाँकि, Node Fetch API का उपयोग करते समय गंभीर नेटवर्क नाकेबंदी का सामना करना अपरिहार्य है।
IP प्रतिबंध और CAPTCHA को पूरी तरह से हल करना चाहते हैं? वेबसाइट निगरानी और IP ब्लॉकिंग को आसानी से बायपास करने के लिए Scrapeless का उपयोग करना सुनिश्चित करें।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


