
रीयल स्टेट लिस्टिंग स्क्रैपिंग को स्क्रैपलेस और n8n वर्कफ़्लो के साथ स्वचालित करें
Advanced Data Extraction Specialist
असली संपत्ति उद्योग में, नवीनतम संपत्ति सूची को स्क्रैप करने की प्रक्रिया को स्वचालित करना और इसे विश्लेषण के लिए व्यवस्थित प्रारूप में संग्रहीत करना प्रभावशीलता को सुधारने के लिए कुंजी है। यह लेख निचले कोड स्वचालन प्लेटफ़ॉर्म n8n का उपयोग करने के तरीके पर चरण-दर-चरण मार्गदर्शन प्रदान करेगा, साथ ही वेब स्क्रैपिंग सेवा Scrapeless के साथ, जिससे नियमित रूप से LoopNet रियल एस्टेट वेबसाइट से किराए की सूचियों को स्क्रैप किया जा सके और स्वचालित रूप से व्यवस्थित संपत्ति डेटा को Google Sheets में लिखा जा सके, जिससे विश्लेषण और साझा करना आसान हो सके।
1. कार्यप्रवाह लक्ष्य और आर्किटेक्चर
लक्ष्य: एक व्यावसायिक रियल एस्टेट प्लेटफ़ॉर्म (जैसे Crexi / LoopNet) से नवीनतम विक्रय/किराए की सूचियाँ को साप्ताहिक कार्यक्रम पर स्वचालित रूप से प्राप्त करना।
एंटी-स्क्रैपिंग तंत्र को बायपास करें और डेटा को Google Sheets में एक संरचित प्रारूप में संग्रहीत करें, जिससे रिपोर्टिंग और BI विज़ुअलाइज़ेशन के लिए यह आसान हो।
अंतिम कार्यप्रवाह आर्किटेक्चर:
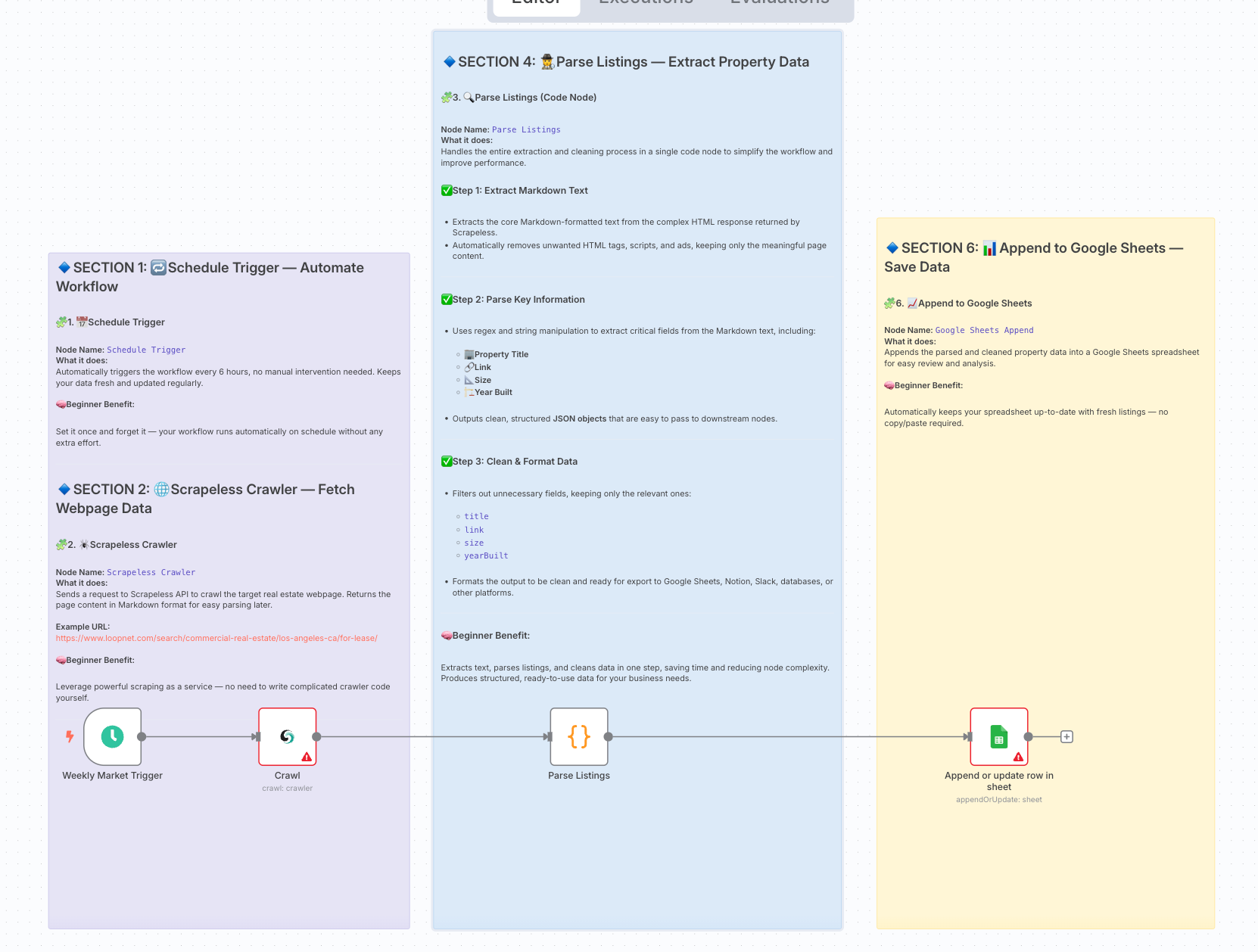
2. तैयारी
- Scrapeless आधिकारिक वेबसाइट पर एक खाता बनाएं और अपना API Key प्राप्त करें (प्रति माह 2,000 मुफ्त अनुरोध)।
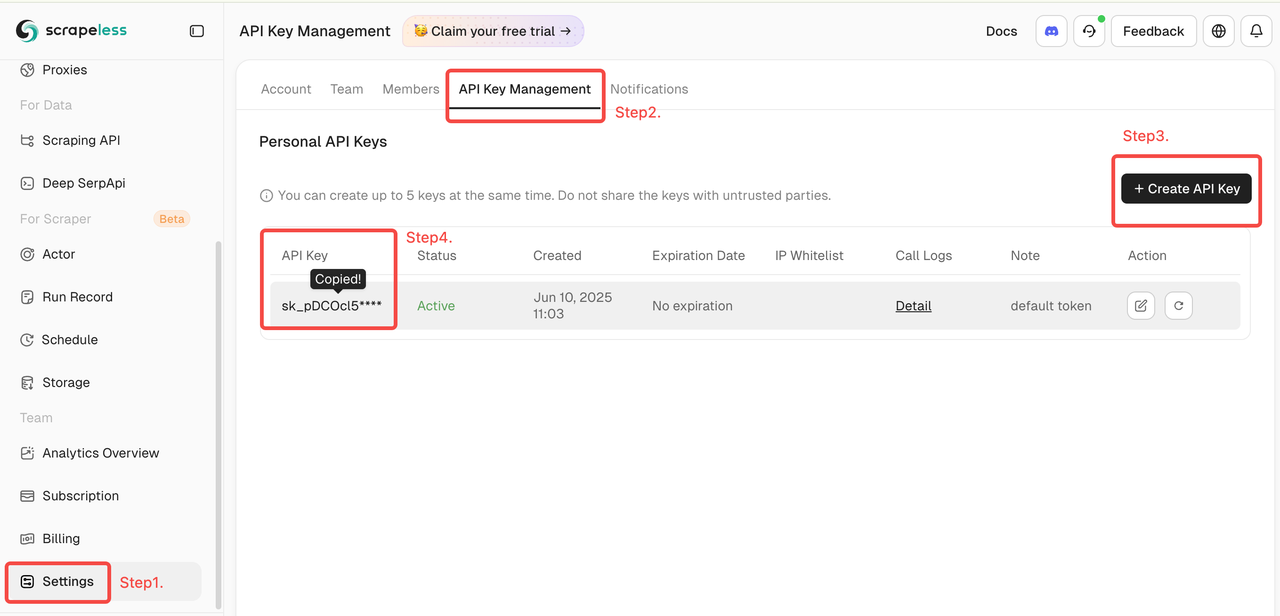
- लॉग इन करें Scrapeless डैशबोर्ड पर
- फिर बाईं ओर "सेटिंग" पर क्लिक करें -> "API Key Management" का चयन करें -> "Create API Key" पर क्लिक करें। अंत में, कॉपी करने के लिए आपके द्वारा बनाए गए API Key पर क्लिक करें।
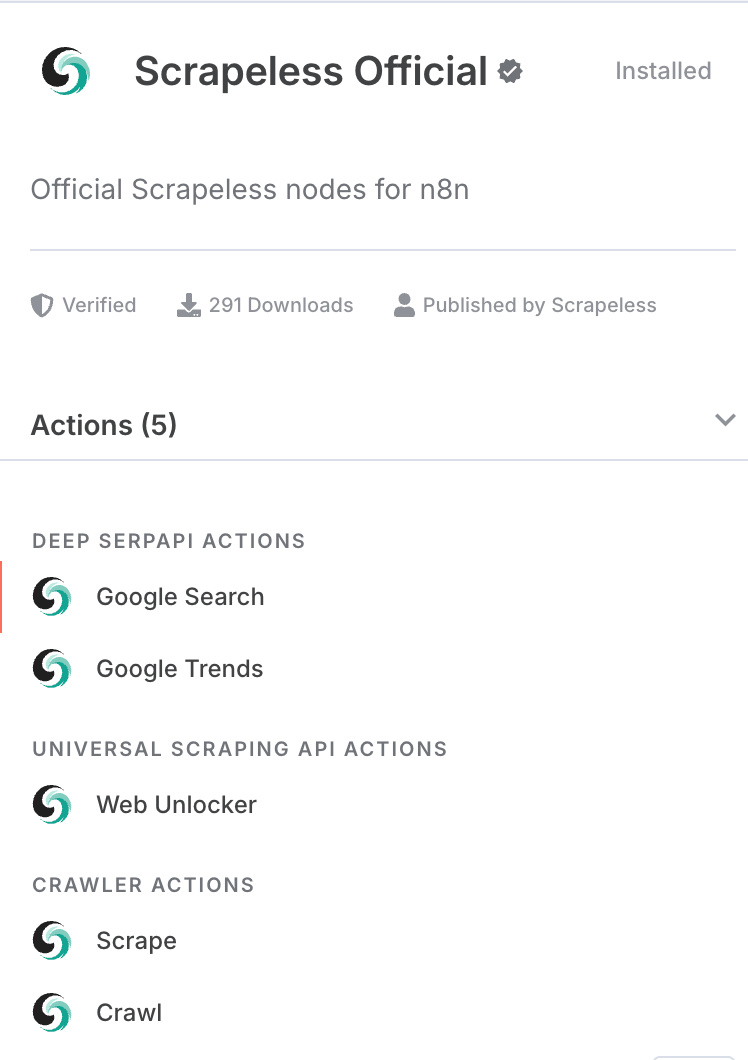
- सुनिश्चित करें कि आपने n8n में Scrapeless नोड के समुदाय संस्करण को स्थापित किया है।
- एक Google Sheets दस्तावेज़ जिसमें लिखने की अनुमति और संबंधित API प्रमाणपत्र हो।
3. कार्यप्रवाह कदमों का अवलोकन
| कदम | नोड प्रकार | उद्देश्य |
|---|---|---|
| 1 | शेड्यूल ट्रिगर | हर 6 घंटे में कार्यप्रवाह को स्वचालित रूप से ट्रिगर करें। |
| 2 | Scrapeless क्रॉलर | LoopNet पृष्ठों को स्क्रैप करें और स्क्रैप की गई सामग्री को मार्कडाउन प्रारूप में लौटाएं। |
| 4 | कोड नोड (सूचियाँ पार्स करना) | Scrapeless आउटपुट से मार्कडाउन फ़ील्ड निकालें; मार्कडाउन को पार्स करने और संरचित संपत्ति सूची डेटा निकालने के लिए regex का उपयोग करें। |
| 6 | Google Sheets जोड़ें | संरचित संपत्ति डेटा को Google Sheets दस्तावेज़ में लिखें। |
4. विस्तृत कॉन्फ़िगरेशन और कोड व्याख्या
1. शेड्यूल ट्रिगर
- नोड प्रकार: शेड्यूल ट्रिगर
- कॉन्फ़िगरेशन: अंतराल को साप्ताहिक (या आवश्यकतानुसार समायोजित करें) सेट करें।
- उद्देश्य: कार्यप्रवाह को समय पर स्वचालित रूप से ट्रिगर करें, कोई मैनुअल कार्रवाई की आवश्यकता नहीं।
2. Scrapeless क्रॉलर नोड
- नोड प्रकार: Scrapeless API नोड (
crawler - crawl) - कॉन्फ़िगरेशन:
- URL: लक्षित LoopNet पृष्ठ, जैसे
https://www.loopnet.com/search/commercial-real-estate/los-angeles-ca/for-lease/ - API Key: अपना Scrapeless API Key दर्ज करें।
- सीमित पृष्ठ: 2 (आवश्यकतानुसार समायोजित करें)।
- URL: लक्षित LoopNet पृष्ठ, जैसे
- उद्देश्य: स्वचालित रूप से पृष्ठ सामग्री को स्क्रैप करें और वेब पृष्ठ को मार्कडाउन प्रारूप में आउटपुट करें।

3. सूचियाँ पार्स करना
- उद्देश्य: Scrapeless द्वारा स्क्रैप की गई मार्कडाउन-प्रारूपित वेब पृष्ठ सामग्री से प्रमुख व्यावसायिक रियल एस्टेट डेटा को निकालना और संरचित डेटा सूची उत्पन्न करना।
- कोड:
const markdownData = [];
$input.all().forEach((item) => {
item.json.forEach((c) => {
markdownData.push(c.markdown);
});
});
const results = [];
function dataExtact(md) {
const re = /\[More details for ([^\]]+)\]\((https:\/\/www\.loopnet\.com\/Listing\/[^\)]+)\)/g;
let match;
while ((match = re.exec(md))) {
const title = match[1].trim();
const link = match[2].trim()?.split(' ')[0];
// Extract a snippet of context around the match
const context = md.slice(match.index, match.index + 500);
// Extract size range, e.g. "10,000 - 20,000 SF"
const sizeMatch = context.match(/([\d,]+)\s*-\s*([\d,]+)\s*SF/);
const sizeRange = sizeMatch ? `${sizeMatch[1]} - ${sizeMatch[2]} SF` : null;
// Extract year built, e.g. "Built in 1988"
const yearMatch = context.match(/Built in\s*(\d{4})/i);
const yearBuilt = yearMatch ? yearMatch[1] : null;
// Extract image URL
hi
const imageMatch = context.match(/!\[[^\]]*\]\((https:\/\/images1\.loopnet\.com[^\)]+)\)/);
const image = imageMatch ? imageMatch[1] : null;
results.push({
json: {
title,
link,
size: sizeRange,
yearBuilt,
image,
},
});
}
// यदि कोई मेल नहीं मिलता है तो मूल मार्कडाउन लौटाएं (डीबगिंग के लिए)
if (results.length === 0) {
return [
{
json: {
error: 'कोई लिस्टिंग मेल नहीं खाती',
raw: md,
},
},
];
}
}
markdownData.forEach((item) => {
dataExtact(item);
});
return results;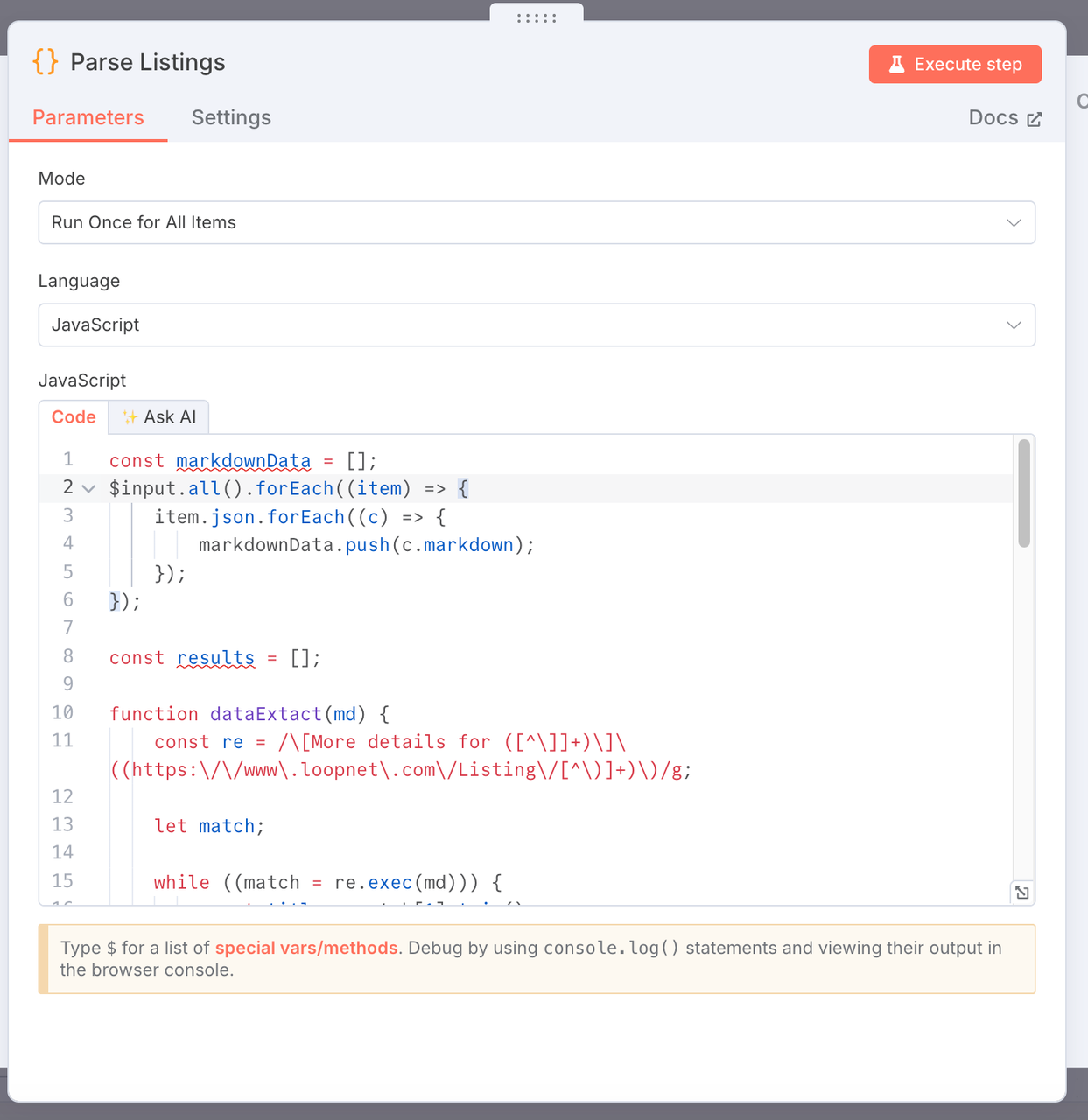
4. गूगल शीट्स जोड़ें (गूगल शीट्स नोड)
- क्रिया: जोड़ें
- कॉन्फ़िगरेशन:
- लक्षित गूगल शीट्स फ़ाइल का चयन करें।
- शीट का नाम: उदाहरण के लिए,
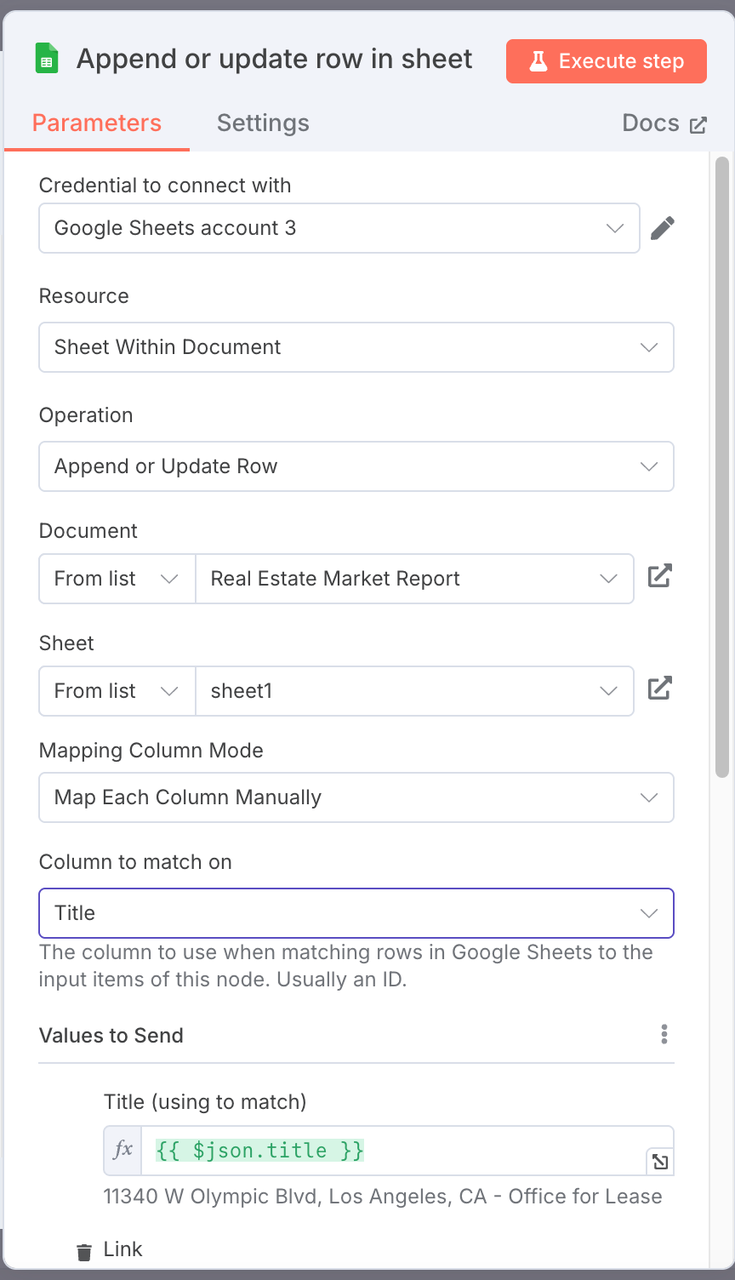
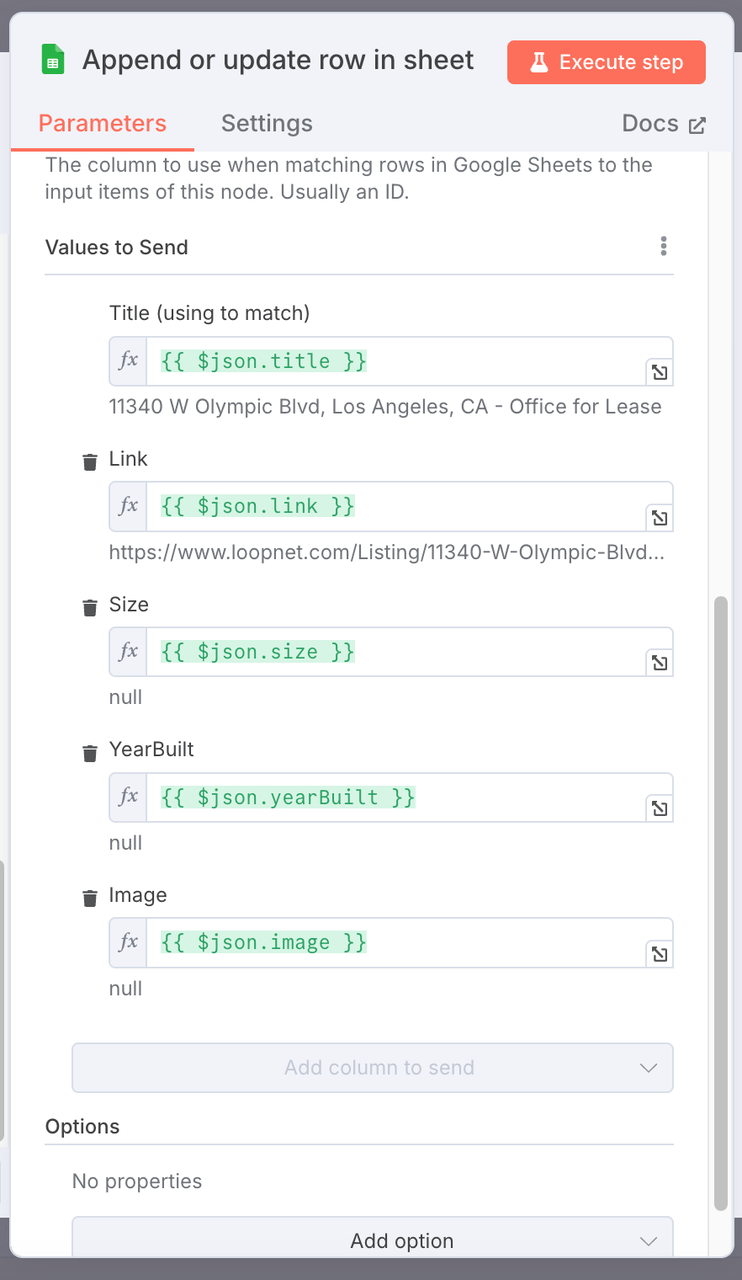
रियल एस्टेट मार्केट रिपोर्ट। - कॉलम मैपिंग कॉन्फ़िगरेशन: संरचित संपत्ति डेटा क्षेत्रों को शीट में संबंधित कॉलम में मैप करें।
| गूगल शीट्स कॉलम | मैप किए गए JSON फ़ील्ड |
|---|---|
| शीर्षक | {{ $json.title }} |
| लिंक | {{ $json.link }} |
| आकार | {{ $json.size }} |
| वर्षनिर्मित | {{ $json.yearBuilt }} |
| छवि | {{ $json.image }} |
नोट:
यह अनुशंसा की जाती है कि आपका वर्कशीट नाम हमारे जैसा होना चाहिए। यदि आपको किसी विशिष्ट नाम को संशोधित करने की आवश्यकता है, तो आपको मैपिंग संबंध पर ध्यान देना होगा।
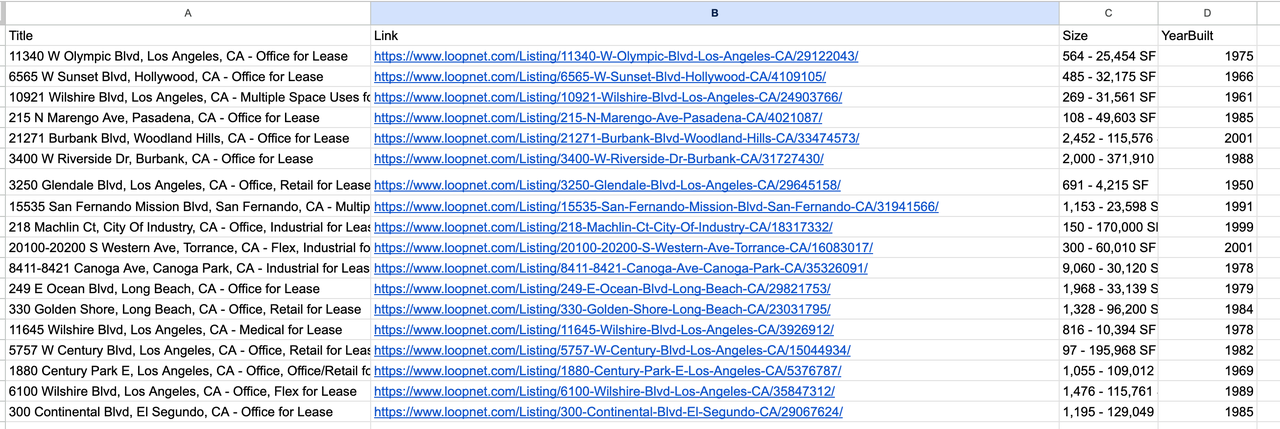
5. परिणाम आउटपुट
5. कार्यप्रवाह फ़्लोचार्ट

6. डिबगिंग टिप्स
- प्रत्येक कोड नोड चलाते समय, निकाले गए डेटा प्रारूप की जाँच करने के लिए नोड आउटपुट खोलें।
- यदि लिस्टिंग्स को पार्स करें नोड कोई डेटा लौटाता है, तो जांचें कि क्या Scrapeless आउटपुट में वैध मार्कडाउन सामग्री है।
- आउटपुट प्रारूप नोड मुख्य रूप से आउटपुट को साफ़ और सामान्यीकृत करने के लिए उपयोग किया जाता है ताकि सही क्षेत्र मैपिंग सुनिश्चित हो सके।
- जब गूगल शीट्स जोड़ें नोड कनेक्ट करें, तो सुनिश्चित करें कि आपकी OAuth प्रमाणीकरण सही ढंग से कॉन्फ़िगर की गई है।
7. भविष्य का अनुकूलन
- डुप्लिकेशन हटाना: डुप्लिकेट संपत्ति लिस्टिंग लिखने से बचें।
- कीमत या आकार द्वारा फ़िल्टरिंग: विशिष्ट लिस्टिंग को लक्षित करने के लिए फ़िल्टर्स जोड़ें।
- नई लिस्टिंग सूचनाएं: ईमेल, स्लैक आदि के माध्यम से चेतावनियाँ भेजें।
- बहु-शहर और बहु-पृष्ठ स्वचालन: विभिन्न शहरों और पृष्ठों में स्क्रेपिंग को स्वचालित करें।
- डेटा दृश्यीकरण और रिपोर्टिंग: संरचित डेटा से डैशबोर्ड बनाएं और रिपोर्ट उत्पन्न करें।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


