
वेब स्क्रैपिंग करते समय CAPTCHA को बायपास करने के 7 तरीके
Web Data Collection Specialist
क्या आप किसी वेबसाइट को स्क्रैप करने का प्रयास कर रहे हैं, लेकिन CAPTCHA आपको रोक रहा है? किसी भी वेब स्क्रैपिंग प्रयास को CAPTCHA द्वारा बाधित किया जा सकता है, जिसे हल करना कठिन होता जा रहा है।
शुक्र है, वेब स्क्रैपिंग करते समय CAPTCHA को बायपास करने के कुछ तरीके हैं, और हम इस लेख में 7 आजमाए हुए और सही तरीकों पर चर्चा करेंगे।
CAPTCHA: यह क्या है?
CAPTCHA का मतलब है "कंप्यूटर और इंसानों को अलग-अलग बताने के लिए पूरी तरह से स्वचालित सार्वजनिक ट्यूरिंग टेस्ट।" वेबसाइटों को संभावित नुकसान और स्क्रैपिंग जैसे बॉट-जैसे व्यवहारों से बचाने के लिए, यह स्वचालित प्रोग्राम को उन तक पहुँचने से रोकने का प्रयास करता है। सुरक्षित वेबसाइट पर जाने से पहले, उपयोगकर्ता को अक्सर CAPTCHA नामक एक परीक्षण पूरा करना होता है।
वेब स्क्रैपर्स को CAPTCHA को बायपास करने में कठिनाई होती है क्योंकि उन्हें रोबोट के लिए समझना मुश्किल होता है लेकिन मनुष्यों के लिए पार करना आसान होता है। उदाहरण के लिए, उपयोगकर्ता को नीचे दी गई छवि में बॉक्स को चेक करके अपनी मानवीय पहचान सत्यापित करनी होगी। यह आदेश बॉट द्वारा सहज रूप से पालन करने योग्य नहीं है।
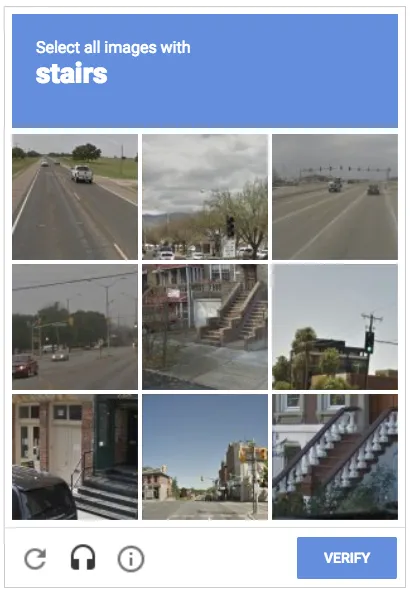
CAPTCHA द्वारा वेब स्क्रैपिंग को कैसे ब्लॉक किया जाता है?
किसी वेबसाइट का कार्यान्वयन CAPTCHA के विभिन्न आकार निर्धारित करता है। जब आप किसी वेबसाइट पर जाते हैं तो कुछ हमेशा मौजूद होते हैं, लेकिन अधिकांश वेब स्क्रैपिंग जैसी स्वचालित क्रियाओं का परिणाम होते हैं।
वेब स्क्रैपिंग के दौरान कैप्चा निम्न में से किसी भी कारण से दिखाई दे सकता है:
- एक ही IP से कम समय में कई क्वेरी भेजना
- स्वचालित क्रियाएँ जो दोहराई जाती हैं, जैसे कि एक ही लिंक पर क्लिक करना या एक ही पेज पर जाना
- संदिग्ध स्वचालित इंटरैक्शन, जिसमें बिना इंटरैक्ट किए बहुत सारे पेज जल्दी-जल्दी सर्फ करना, जल्दी-जल्दी क्लिक करना या फ़ॉर्म को जल्दी-जल्दी पूरा करना शामिल है
- निषिद्ध वेबसाइट का उपयोग करना और robots.txt फ़ाइल को अनदेखा करना।
क्या कैप्चा को बायपास करना संभव है?
हालाँकि यह कोई आसान ऑपरेशन नहीं है, लेकिन आप कैप्चा को बायपास भी कर सकते हैं। यदि कैप्चा ब्लॉक हो गया है और इसे पहली जगह में दिखाई देने से बचने के लिए अनुरोध को फिर से सबमिट करने का प्रयास करने की सलाह दी जाती है।
आप कैप्चा का उत्तर भी दे सकते हैं, लेकिन ऐसा करने पर आपको बहुत अधिक पैसे खर्च करने पड़ेंगे और सफलता दर बहुत कम होगी। अधिकांश कैप्चा-सॉल्विंग सेवाएँ क्वेरी को प्रोसेस करने और फिर उत्तर देने के लिए मानव सॉल्वर का उपयोग करती हैं। यह विधि आपके स्क्रैपर की प्रभावशीलता को काफी कम कर देती है और इसे धीमा कर देती है।
कैप्चा को बायपास करना अधिक भरोसेमंद है क्योंकि यह उन्हें उत्पन्न करने वाले स्वचालित व्यवहारों को रोकने के लिए सभी आवश्यक सावधानियों को पूरा करता है। हम नीचे वेब स्क्रैपिंग करते समय कैप्चा को बायपास करने के सर्वोत्तम तरीकों पर चर्चा करेंगे ताकि आप अपनी ज़रूरत की जानकारी प्राप्त कर सकें।
वेब स्क्रैपिंग करते समय कैप्चा को बायपास कैसे करें
यह अनुभाग पायथन में वेब स्क्रैपिंग करते समय कष्टप्रद कैप्चा बाधाओं को बायपास करने के लिए सात तरीकों पर चर्चा करेगा।
विधि1. IP घुमाएँ
URL और डेटा निष्कर्षण के लिए क्रॉलर विकसित करते समय पहुँच को रोकने के लिए एक रक्षात्मक प्रणाली के लिए सबसे आसान तकनीक IP को प्रतिबंधित करना है। यदि सर्वर को थोड़े समय में एक ही IP पते से बहुत सारे अनुरोध प्राप्त होते हैं, तो वे उस पते को फ़्लैग कर देंगे।
इससे बचने के लिए, कई IP पतों का उपयोग करना सबसे सरल उपाय है। हालाँकि, सर्वर की बात करें तो इसे संशोधित करना मुश्किल है, यदि असंभव नहीं है। इसलिए, आपको IP को चक्रित करने के लिए अपने अनुरोधों को संसाधित करने के लिए एक प्रॉक्सी सर्वर का उपयोग करना होगा। उनके साथ, आपके शुरुआती अनुरोधों में बदलाव नहीं किया जाएगा, लेकिन गंतव्य सर्वर आपके बजाय अपना IP पता देखेगा।
विधि2. उपयोगकर्ता एजेंट घुमाएँ
एक स्ट्रिंग जिसे उपयोगकर्ता का वेब ब्राउज़र सर्वर को भेजता है उसे उपयोगकर्ता एजेंट (UA) कहा जाता है। यह HTTP हेडर में पाया जाता है और ब्राउज़र के ऑपरेटिंग सिस्टम और प्रकार और संस्करण के बारे में जानकारी प्रदान करता है। क्लाइंट साइड और जावास्क्रिप्ट पर नेविगेटर का उपयोग करके एक्सेस किया जाता है। सामग्री की पहचान की जाती है और उसे इस तरह से प्रस्तुत किया जाता है कि वह उपयोगकर्ता के विनिर्देशों के अनुरूप हो, जो कि userAgent विशेषता का उपयोग करके दूरस्थ वेब सर्वर द्वारा किया जाता है।
भले ही उनमें विभिन्न संरचनाएँ और डेटा शामिल हों, लेकिन अधिकांश वेब ब्राउज़र आमतौर पर एक ही प्रारूप का पालन करते हैं:
(<system-information>) Mozilla/5.0 <extensions> <platform> (<platform-details>)
उदाहरण के लिए, Chrome (Chromium) के लिए, उपयोगकर्ता एजेंट स्ट्रिंग Mozilla/5.0 (Windows NT 10.0; Win64; x64) हो सकती है। AppleWebKit/537.36 (KHTML में Gecko के समान) 109.0.0.0 Safari/537.36; Chrome. इसे तोड़कर देखें, तो यह बताता है कि ब्राउज़र का नाम क्या है (Chrome), यह किस संस्करण पर चल रहा है (109.0.0.0), और यह किस ऑपरेटिंग सिस्टम पर चल रहा है (Windows NT 10.0, 64-बिट CPU).
स्क्रैपिंग के लिए UA स्ट्रिंग का उपयोग करने से आपके स्पाइडर को वेब ब्राउज़र के रूप में छिपाने में सहायता मिल सकती है क्योंकि वे ब्राउज़र (और बॉट्स) से अनुरोधों के प्रकार की पहचान करने में वेब सर्वर की सहायता करते हैं.
सावधानी बरतें: यदि आप गलत तरीके से गठित उपयोगकर्ता एजेंट को नियोजित करते हैं, तो आपकी डेटा निष्कर्षण स्क्रिप्ट रोक दी जाएगी.
विधि3. CAPTCHA सॉल्वर का उपयोग करें
CAPTCHA सॉल्वर के रूप में जानी जाने वाली सेवाएँ आपको CAPTCHA को स्वचालित रूप से हल करके लगातार वेबपेजों को स्क्रैप करने की अनुमति देती हैं। एक प्रसिद्ध उदाहरण Scarpeless है.
क्या आप CAPTCHA और लगातार वेब स्क्रैपिंग ब्लॉक से थक चुके हैं?
Scarpeless: सबसे अच्छा ऑल-इन-वन ऑनलाइन स्क्रैपिंग समाधान उपलब्ध है!
अपने डेटा निष्कर्षण की पूरी क्षमता को उजागर करने के लिए हमारे दुर्जेय टूलकिट का उपयोग करें:
सर्वश्रेष्ठ CAPTCHA सॉल्वर
जटिल CAPTCHA का स्वचालित समाधान निरंतर और सुचारू स्क्रैपिंग सुनिश्चित करने के लिए।
इसे निःशुल्क आज़माएँ!
विधि4. छिपे हुए जाल से बचें
आपकी जानकारी के बिना, वेबसाइटें बॉट की पहचान करने के लिए चालाक जाल का इस्तेमाल करती हैं। उदाहरण के लिए, हनीपोट जाल मशीनों को छिपे हुए फ़ीचर, जैसे लिंक या अदृश्य फ़ॉर्म फ़ील्ड के साथ बातचीत करने के लिए धोखा देता है।
मानव उपयोगकर्ता इन जालों को नहीं देख सकते हैं; केवल बॉट ही उन्हें देख सकते हैं। जब उपयोगकर्ता इन जालों के साथ बातचीत करते हैं, तो वेबसाइट असामान्य गतिविधि की पहचान कर सकती है और बॉट के आईपी पते को सचेत कर सकती है।
हालाँकि, आप इन जालों को पहचानना और संचालित करना सीख सकते हैं। एक तरीका वेबसाइट के HTML में छिपे हुए तत्वों की तलाश करना और विषम नामों या मूल्यों वाले तत्वों से दूर रहना है।
विधि5. मानव व्यवहार का अनुकरण करें
वेब स्क्रैपिंग करते समय CAPTCHA को बायपास करने के लिए मानव व्यवहार को सटीक रूप से दोहराना आवश्यक है। उदाहरण के लिए, मिलीसेकंड के मामले में कई अनुरोध सबमिट करने से दर सीमा के साथ IP प्रतिबंध लग सकता है।
अपने प्रश्नों की आवृत्ति को कम करने के लिए अनुरोधों के बीच समय जोड़ना मानव व्यवहार की नकल करने का एक तरीका है। इसे और अधिक तार्किक बनाने के लिए, आप समय बदल सकते हैं। प्रत्येक असफल अनुरोध के बाद प्रतीक्षा अवधि को लंबा करने के लिए घातीय बैकऑफ़ का उपयोग करना एक अतिरिक्त रणनीति है।
विधि6. कुकीज़ सहेजें
वेब स्क्रैपिंग के लिए आपकी पसंद का छिपा हुआ हथियार कुकीज़ हो सकता है। ये छोटी फ़ाइलें इस बारे में जानकारी रखती हैं कि आप किसी वेबसाइट के साथ कैसे इंटरैक्ट करते हैं, जैसे कि आपकी प्राथमिकताएँ और लॉगिन स्थिति।
यदि आप लॉगिन के पीछे स्क्रैपिंग कर रहे हैं तो कुकीज़ मददगार हो सकती हैं क्योंकि वे आपको बार-बार साइन इन करने की परेशानी से बचाती हैं और इस संभावना को कम करती हैं कि आपको खोजा जाएगा। इसके अतिरिक्त, कुकीज़ आपको बाद में वेब स्क्रैपिंग सत्र को रोकने या जारी रखने की अनुमति देती हैं।
सेलेनियम जैसे हेडलेस ब्राउज़र और अनुरोध जैसे HTTP क्लाइंट का उपयोग करके, आप प्रोग्रामेटिक रूप से कुकीज़ को सहेज और लोड कर सकते हैं और बिना देखे डेटा प्राप्त कर सकते हैं।
विधि7. ऑटोमेशन संकेतक छिपाएँ
हेडलेस ब्राउज़र का उपयोग करते हुए भी, आपको सावधानी बरतनी चाहिए क्योंकि वेबसाइटें ऑटोमेशन के संकेत संकेतों, जैसे ब्राउज़र फ़िंगरप्रिंट के लिए स्कैन करके स्वचालित ट्रैफ़िक का पता लगा सकती हैं।
दूसरी ओर, सेलेनियम स्टील्थ जैसे प्लगइन्स का उपयोग माउस और कीबोर्ड की हरकतों को स्वचालित करने के लिए किया जा सकता है जो किसी व्यक्ति की हरकतों से मिलते जुलते हैं, बिना खुद पर ध्यान आकर्षित किए।
संक्षेप में
हालाँकि CAPTCHA को वेब स्क्रैपिंग में बाधा डालने से रोकना एक कठिन काम है, लेकिन अब आपके पास इस समस्या से निपटने के लिए आवश्यक उपकरण हैं। हालाँकि, बड़े पैमाने की पहलों को उपरोक्त रणनीतियों को पूरी तरह से निष्पादित करने के लिए अधिक समय और काम की आवश्यकता हो सकती है।
स्क्रैपलेस के साथ, आपको कैप्चा और अन्य एंटी-बॉट्स से कुशलतापूर्वक निपटने के लिए आवश्यक सभी उपकरण मिल सकते हैं।
स्क्रैपलेस का निःशुल्क उपयोग करके स्वयं देखें!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


