
MCP एकीकरण मार्गदर्शिका: क्रोम डेवटूल्स MCP, प्ले राइट MCP, और स्क्रेपलेस ब्राउज़र MCP
Expert Network Defense Engineer
यह मार्गदर्शिका तीन मॉडल संदर्भ प्रोटोकॉल (MCP) सर्वरों का परिचय देती है—क्रोम देवटूल्स MCP, प्लेवीराइट MCP, और ब्राउज़र MCP।
अवलोकन: सही MCP चुनना
| MCP प्रकार | तकनीकी ढांचा | लाभ | प्राथमिक पारिस्थितिकी तंत्र | सर्वश्रेष्ठ के लिए |
|---|---|---|---|---|
| क्रोम देवटूल्स MCP | Node.js / Puppeteer | आधिकारिक मानक, मजबूत, गहन प्रदर्शन विश्लेषण उपकरण। | व्यापक (जेमिनी, कोपिलॉट, कर्सर) | CI/CD स्वचालन, क्रॉस-IDE कार्यप्रवाह, और गहन प्रदर्शन ऑडिट। |
| प्लेवीराइट MCP | Node.js / प्लेवीराइट | पिक्सल के बजाय अभिगम्यता वृक्ष का उपयोग करता है; दृष्टि के बिना निर्धारीत और LLM के अनुकूल। | व्यापक (VS कोड, कोपिलॉट) | विश्वसनीय, संरचित स्वचालन जो छोटे UI परिवर्तनों से टूटने की संभावना कम है। |
| स्क्रेपलेस ब्राउज़र MCP | क्लाउड सेवा | कोई स्थानीय सेटअप नहीं, स्केलेबल क्लाउड ब्राउज़र, जटिल साइटों और एंटी-बॉट उपायों को संभालता है। | API-प्रेरित (किसी भी क्लाइंट) | बड़े पैमाने पर, समानांतर स्वचालन कार्य, और मजबूत बॉट पहचान वाले वेबसाइटों के साथ बातचीत। |
एक क्लाउड ब्राउज़र, अनंत एकीकरण
तीनों MCP — क्रोम देवटूल्स MCP, प्लेवीराइट MCP, और स्क्रेपलेस ब्राउज़र MCP — एक ही नींव साझा करते हैं: वे सभी स्क्रेपलेस क्लाउड ब्राउज़र से जुड़े होते हैं। पारंपरिक स्थानीय ब्राउज़र स्वचालन के विपरीत, स्क्रेपलेस ब्राउज़र पूरी तरह से क्लाउड में चलता है, डेवलपर्स और AI एजेंटों के लिए अद्वितीय लचीलापन और स्केलेबिलिटी प्रदान करता है।
यहाँ क्या इसे वास्तव में शक्तिशाली बनाता है:
- निर्बाध एकीकरण: Puppeteer, Playwright, और CDP के साथ पूरी तरह से संगत, जिससे मौजूदा परियोजनाओं से एकल कोड की पंक्ति के साथ सहज रूपांतरण संभव है।
- वैश्विक आईपी कवरेज: 195+ देशों में आवासीय, ISP, और अनलिमिटेड आईपी पूल तक पहुँच, पारदर्शी और लागत-कुशल दर ($0.6–1.8/GB) पर। बड़े पैमाने पर वेब डेटा स्वचालन के लिए उत्कृष्ट।
- अलग प्रोफाइल: प्रत्येक कार्य एक समर्पित, लगातार वातावरण में चलता है, सत्र पृथक्करण, बहु-खाते प्रबंधन, और दीर्घकालिक स्थिरता सुनिश्चित करता है।
- अनलिमिटेड समवर्ती स्केलिंग: ऑटो-स्केलिंग इंफ्रास्ट्रक्चर के साथ 50–1000+ ब्राउज़र इंस्टेंस तुरंत लॉन्च करें — कोई सर्वर सेटअप नहीं, कोई प्रदर्शन बाधा नहीं।
- विश्वव्यापी एज नोड्स: अन्य क्लाउड ब्राउज़रों की तुलना में अल्ट्रा-लो लेटेंसी और 2–3× तेज़ शुरूआत के लिए कई वैश्विक नोड्स पर तैनात करें।
- एंटी-डिटेक्शन: reCAPTCHA, Cloudflare Turnstile, और AWS WAF के लिए अंतर्निहित समाधान, कठोर सुरक्षा परतों के तहत भी लगातार स्वचालन सुनिश्चित करते हैं।
- दृश्य डिबगिंग: मानव-यांत्रिक इंटरैक्टिव डिबगिंग और वास्तविक समय की प्रॉक्सी ट्रैफ़िक निगरानी को लाइव व्यू के माध्यम से प्राप्त करें। समस्याओं की पहचान करने और संचालन का अनुकूलन करने के लिए सत्र रिकॉर्डिंग के माध्यम से पृष्ठ द्वारा पृष्ठ पुनरावृत्ति सत्र करें।
क्रोम देवटूल्स MCP
क्रोम देवटूल्स MCP एक मॉडल-कॉन्टेक्स्ट-प्रोटोकॉल (MCP) सर्वर है जो AI कोडिंग सहायक — जैसे जेमिनी, क्लॉड, कर्सर, या कोपिलॉट — को विश्वसनीय स्वचालन, उन्नत डिबगिंग, और प्रदर्शन विश्लेषण के लिए लाइव क्रोम ब्राउज़र को नियंत्रित और निरीक्षण करने की अनुमति देता है।
प्रमुख विशेषताएँ
- प्रदर्शन अंतर्दृष्टि प्राप्त करें: कार्रवाई योग्य प्रदर्शन अंतर्दृष्टि निकालने और ट्रेस रिकॉर्ड करने के लिए क्रोम देवटूल्स का उपयोग करें।
- उन्नत ब्राउज़र डिबगिंग: नेटवर्क अनुरोधों का विश्लेषण करें, स्क्रीनशॉट लें, और ब्राउज़र कंसोल की जांच करें।
- विश्वसनीय स्वचालन: Chrome में कार्रवाई को स्वचालित करने और कार्रवाई के परिणामों की ऑटोमेटिक प्रतीक्षा करने के लिए Puppeteer का उपयोग करता है।
आवश्यकताएँ
- Node.js v20.19 या नवीनतम रखरखाव LTS संस्करण।
- npm।
शुरुआत करना
स्क्रेपलेस में लॉग इन करें और अपना API की प्राप्त करें।
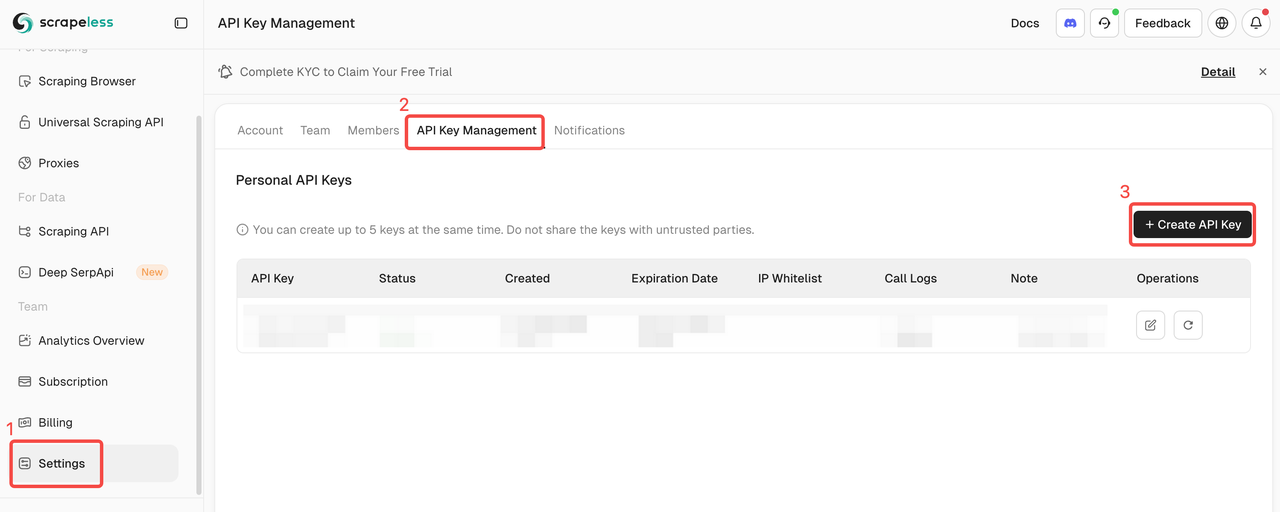
त्वरित प्रारंभ
यह JSON कॉन्फ़िगरेशन एक MCP क्लाइंट द्वारा Chrome DevTools MCP सर्वर से जुड़ने और दूरस्थ स्क्रेपलेस क्लाउड ब्राउज़र उदाहरण को नियंत्रित करने के लिए उपयोग किया जाता है।
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"chrome-devtools-mcp@latest",
"--wsEndpoin=wss://browser.scrapeless.com/api/v2/browser?token=scrapeless api key&proxyCountry=US&sessionRecording=true&sessionTTL=900&sessionName=CDPDemo"
]
}
}
}प्रदर्शनी
उपयोग के मामले
- वेब प्रदर्शन विश्लेषण: सीडीपी के साथ रिकॉर्ड ट्रेस करें और पृष्ठ लोड, नेटवर्क अनुरोधों और जावास्क्रिप्ट निष्पादन पर क्रियाशील अंतर्दृष्टि निकालें, जिससे एआई सहायक प्रदर्शन ऑप्टिमाइजेशन सुझा सकें।
- स्वचालित डिबगिंग: कंसोल लॉग कैप्चर करें, नेटवर्क ट्रैफ़िक की जांच करें, स्क्रीनशॉट लें, और तेजी से समस्या निवारण के लिए स्वचालित रूप से बग पुनः उत्पन्न करें।
- एंड-टू-एंड परीक्षण: पुपेटियर के साथ जटिल कार्यप्रवाहों को स्वचालित करें, पृष्ठ इंटरैक्शन का मान्यता करें, और क्रोम में गतिशील सामग्री रेंडरिंग की जांच करें।
- एआई-सहायता प्राप्त स्वचालन: जेमिनी या कोपिलॉट जैसे एलएलएम फॉर्म भर सकते हैं, बटन क्लिक कर सकते हैं, या क्रोम पृष्ठों से संरचित डेटा को विश्वसनीयता और सटीकता के साथ स्क्रैप कर सकते हैं।
प्लेवानगर एमसीपी
प्लेवानगर एमसीपी एक मॉडल-प्रसंग-प्रोटोकॉल (एमसीपी) सर्वर है जो प्लेवानगर पर आधारित ब्राउज़र स्वचालन क्षमताएँ प्रदान करता है। यह बड़े भाषा मॉडलों (एलएलएम) या एआई कोडिंग सहायकों को वेब पृष्ठों के साथ इंटरैक्ट करने की अनुमति देता है।
मुख्य विशेषताएँ
- तेज और हल्का। प्लेवानगर के पहुँच पेड़ का उपयोग करता है, न कि पिक्सेल-आधारित इनपुट।
- एलएलएम के अनुकूल। दृष्टि मॉडलों की आवश्यकता नहीं, पूरी तरह से संरचित डेटा पर कार्य करता है।
- निश्चित उपकरण अनुप्रयोग। स्क्रीनशॉट-आधारित दृष्टिकोणों के साथ सामान्य अस्पष्टता से बचता है।
आवश्यकताएँ
- Node.js 18 या नया
- वीएस कोड, कर्सर, विंडसर्फ, क्लॉड डेस्कटॉप, गूज या कोई अन्य एमसीपी क्लाइंट
प्रारंभ करना
स्क्रैपलेस में लॉग इन करें और अपनी एपीआई कुंजी प्राप्त करें।
त्वरित प्रारंभ
यह JSON कॉन्फ़िगरेशन एक एमसीपी क्लाइंट द्वारा प्लेवानगर एमसीपी सर्वर से कनेक्ट करने और दूरस्थ स्क्रैपलेस क्लाउड ब्राउज़र instance को नियंत्रित करने के लिए उपयोग किया जाता है।
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--headless",
"--cdp-endpoint=wss://browser.scrapeless.com/api/v2/browser?token=Your_Token&proxyCountry=ANY&sessionRecording=true&sessionTTL=900&sessionName=playwrightDemo"
]
}
}
}प्रदर्शन
उपयोग के मामले
-
वेब स्क्रैपिंग और डेटा निष्कर्षण: प्लेवानगर एमसीपी द्वारा संचालित एलएलएम वेबसाइटों को नेविगेट कर सकते हैं, संरचित डेटा निकाल सकते हैं, और एक असली ब्राउज़र वातावरण के भीतर जटिल स्क्रैपिंग कार्यों को स्वचालित कर सकते हैं। यह बाजार अनुसंधान, सामग्री समेकन और प्रतिस्पर्धात्मक बुद्धिमत्ता के लिए बड़े पैमाने पर जानकारी संग्रहण का समर्थन करता है।
-
स्वचालित कार्यप्रवाह निष्पादन: प्लेवानगर एमसीपी एआई एजेंटों को डेटा प्रविष्टि, रिपोर्ट निर्माण और डैशबोर्ड अपडेट जैसे दोहराए जाने वाले वेब-आधारित कार्यप्रवाहों को करने की अनुमति देता है। यह व्यावसायिक प्रक्रिया स्वचालन, एचआर ऑनबोर्डिंग, और अन्य उच्च-आवृत्ति संचालन के लिए विशेष रूप से प्रभावी है।
-
व्यक्तिगत ग्राहक सेवा और सहायता: एआई एजेंट प्लेवानगर एमसीपी का उपयोग करके वेब पोर्टलों के साथ सीधे इंटरैक्ट कर सकते हैं, उपयोगकर्ता-विशिष्ट डेटा प्राप्त कर सकते हैं, और समस्या निवारण क्रियाएँ कर सकते हैं। यह व्यक्तिगत, संदर्भ-जानकारी समर्थन अनुभवों को सक्षम बनाता है - उदाहरण के लिए, स्वचालित रूप से आदेश विवरण प्राप्त करना या लॉगिन समस्याओं को हल करना।
ब्राउज़र एमसीपी
स्क्रैपलेस ब्राउज़र एमसीपी सर्वर बिना किसी रुकावट के चाटजीपीटी, क्लॉड जैसे मॉडलों और कर्सर तथा विंडसर्फ जैसे उपकरणों को व्यापक बाहरी क्षमताओं से जोड़ता है, जिसमें शामिल हैं:
- पृष्ठ-स्तरीय नेविगेशन और इंटरैक्शन के लिए ब्राउज़र स्वचालन
- गतिशील, जावास्क्रिप्ट-भारी साइटों को स्क्रैप करें—HTML, मार्कडाउन, या स्क्रीनशॉट के रूप में निर्यात करें
समर्थित एमसीपी उपकरण
| नाम | विवरण |
|---|---|
| ब्राउज़र_रचना | स्क्रैपलेस का उपयोग करके एक क्लाउड ब्राउज़र सत्र बनाएं या पुनः उपयोग करें। |
| ब्राउज़र_बंद | क्लाउड ब्राउज़र से डिस्कनेक्ट करके वर्तमान सत्र बंद करें। |
| ब्राउज़र_जाना | ब्राउज़र को निर्दिष्ट URL पर नेविगेट करें। |
| ब्राउज़र_पीछे_जाना | ब्राउज़र इतिहास में एक कदम पीछे जाएं। |
| ब्राउज़र_आगे_जाना | ब्राउज़र इतिहास में एक कदम आगे जाएं। |
| ब्राउज़र_क्लिक | पृष्ठ पर एक विशिष्ट तत्व पर क्लिक करें। |
| ब्राउज़र_टाइप | निर्दिष्ट इनपुट फ़ील्ड में टेक्स्ट टाइप करें। |
| ब्राउज़र_की_दबाना | एक कुंजी के दबाने का अनुकरण करें। |
| ब्राउज़र_गति_की_प्रतीक्षा | एक विशिष्ट पृष्ठ तत्व के प्रकट होने की प्रतीक्षा करें। |
| ब्राउज़र_प्रतीक्षा | एक निश्चित अवधि के लिए निष्पादन को रोकें। |
| ब्राउज़र_स्क्रीनशॉट | वर्तमान पृष्ठ का स्क्रीनशॉट कैप्चर करें। |
| ब्राउज़र_एचटीएमएल_प्राप्त करें | वर्तमान पृष्ठ का पूरा एचटीएमएल प्राप्त करें। |
| browser_get_text | वर्तमान पृष्ठ से सभी दृश्यात्मक पाठ प्राप्त करें। |
| browser_scroll | पृष्ठ के नीचे स्क्रॉल करें। |
| browser_scroll_to | किसी विशेष तत्व को दृश्य में स्क्रॉल करें। |
| scrape_html | एक URL को स्क्रैप करें और इसकी पूर्ण HTML सामग्री लौटाएं। |
| scrape_markdown | एक URL को स्क्रैप करें और इसकी सामग्री को Markdown के रूप में लौटाएं। |
| scrape_screenshot | किसी भी वेबपृष्ठ का उच्च-गुणवत्ता स्क्रीनशॉट कैप्चर करें। |
शुरुआत कर रहे हैं
Scrapeless में लॉग इन करें और अपना API टोकन प्राप्त करें।
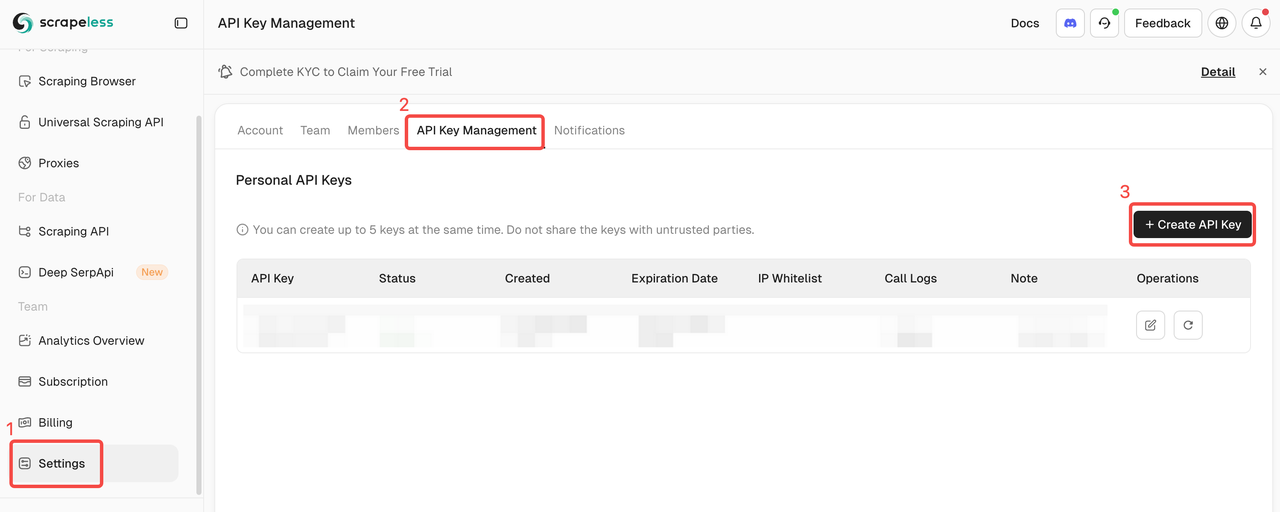
अपने MCP क्लाइंट को कॉन्फ़िगर करें
Scrapeless MCP सर्वर दोनों Stdio और Streamable HTTP परिवहन मोड का समर्थन करता है।
🖥️ Stdio (स्थानीय निष्पादन)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}🌐 Streamable HTTP (होस्टेड API मोड)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}उन्नत विकल्प
वैकल्पिक पैरामीटर के साथ ब्राउज़र सत्र के व्यवहार को अनुकूलित करें। इन्हें पर्यावरणीय वैरिएबल (Stdio के लिए) या HTTP हेडर (Streamable HTTP के लिए) के माध्यम से सेट किया जा सकता है:
| Stdio (Env Var) | Streamable HTTP (HTTP Header) | विवरण |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | सत्र निरंतरता के लिए एक उपयोग्युता ब्राउज़र प्रोफाइल आईडी निर्दिष्ट करता है। |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | कुकीज़, स्थानीय भंडारण आदि के लिए निरंतर भंडारण सक्षम करता है। |
| BROWSER_SESSION_TTL | x-browser-session-ttl | अधिकतम सत्र समयसीमा को सेकंड में परिभाषित करता है। निष्क्रियता की इस अवधि के बाद सत्र स्वतः समाप्त हो जाएगा। |
उपयोग के मामले
वेब स्क्रैपिंग और डेटा संग्रहण
- ई-कॉमर्स निगरानी: स्वचालित रूप से उत्पाद पृष्ठों पर जाएं ताकि मूल्य, स्टॉक स्थिति और विवरण इकट्ठा कर सकें।
- बाजार अनुसंधान: विश्लेषण और तुलना के लिए समाचार, समीक्षाओं, या कंपनी पृष्ठों को बैच स्क्रैप करें।
- सामग्री संग्रहण: पृष्ठ सामग्री, पोस्ट, और टिप्पणियाँ केंद्रीय संग्रह के लिए निकालें।
- लीड निर्माण: कॉर्पोरेट वेबसाइटों या निर्देशिकाओं से संपर्क जानकारी और कंपनी विवरण एकत्र करें।
परीक्षण और गुणवत्ता आश्वासन
- कार्य सुनिश्चित करना: पृष्ठों के व्यवहार को सुनिश्चित करने के लिए क्लिक, टाइपिंग, और तत्व प्रतीक्षा का उपयोग करें।
- उपयोगकर्ता यात्रा परीक्षण: कार्यप्रवाहों को मान्य करने के लिए वास्तविक उपयोगकर्त्ता इंटरैक्शन (टाइपिंग, क्लिकिंग, स्क्रॉलिंग) का अनुकरण करें।
- पुनरागमन परीक्षण समर्थन: प्रमुख पृष्ठों का स्क्रीनशॉट कैप्चर करें और UI या सामग्री परिवर्तनों का पता लगाने के लिए इनमें तुलना करें।
कार्य और कार्यप्रवाह स्वचालन
- फॉर्म भरना: स्वचालित रूप से वेब फॉर्म (जैसे पंजीकरण, सर्वेक्षण) पूरा और सबमिट करें।
- डेटा कैप्चर और रिपोर्ट निर्माण: नियमित रूप से पृष्ठ डेटा निकालें और विश्लेषण के लिए HTML या स्क्रीनशॉट के रूप में सहेजें।
- साधारण प्रशासनिक कार्य: अनुकरणीय क्लिक और टाइपिंग का उपयोग करके दोहराए जाने वाले बैकएंड या वेब-आधारित संचालन को स्वचालित करें।
प्रदर्शन
केस 1: क्लॉड के साथ वेब इंटरैक्शन और डेटा निकासी स्वचालन
ब्राउज़र MCP सर्वर का उपयोग करते हुए, क्लॉड जटिल वेब संचालन—जैसे कि नेविगेशन, क्लिकिंग, स्क्रॉलिंग और डेटा स्क्रैपिंग—संवादी आदेशों के माध्यम से कर सकता है, वास्तविक समय निष्पादन पूर्वावलोकन के साथ लाइव सत्रों के जरिए।
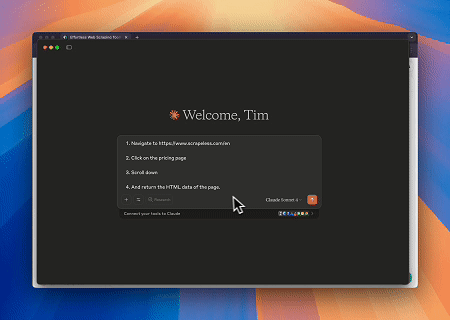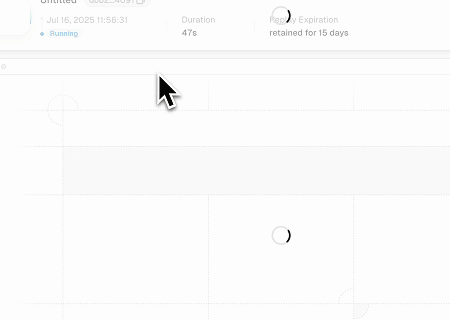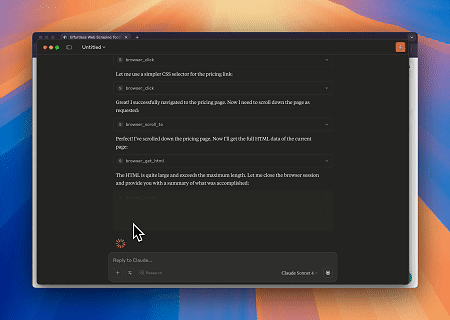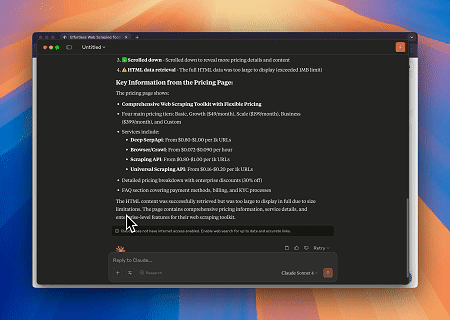
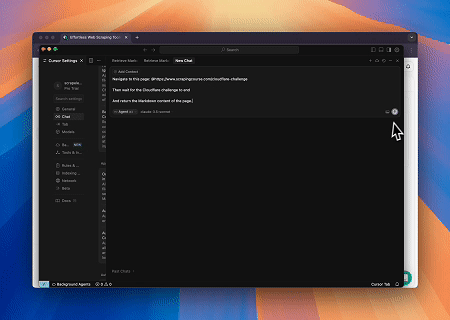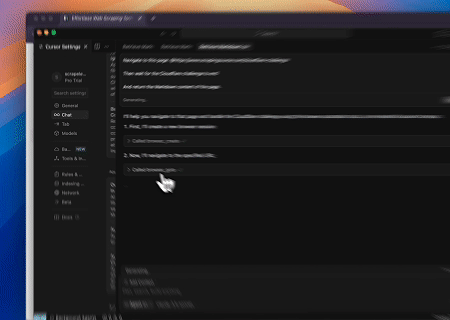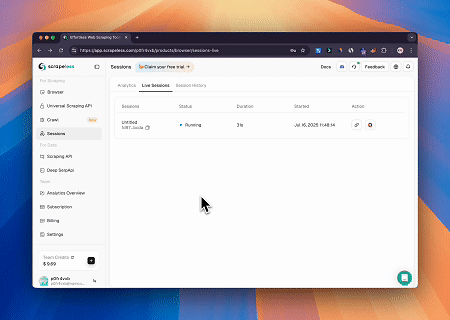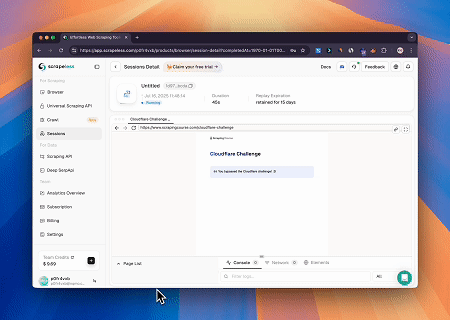
केस 2: लक्षित पृष्ठ सामग्री पुनः प्राप्त करने के लिए क्लाउडफ्लेयर को बायपास करना
ब्राउज़र MCP सर्वर का उपयोग करते हुए, क्लाउडफ्लेयर-सुरक्षित पृष्ठों को स्वचालित रूप से पहुंचा जाता है, और पूरी होने पर, पृष्ठ की सामग्री निकाली जाती है और Markdown प्रारूप में लौटाई जाती है।
एकीकरण
क्लॉड डेस्कटॉप
- क्लॉड डेस्कटॉप खोलें
- पर नेविगेट करें: सेटिंग्स → टूल्स → MCP सर्वर
- "MCP सर्वर जोड़ें" पर क्लिक करें
- ऊपर दिया गया Stdio या Streamable HTTP कॉन्फ़िगरेशन चिपकाएँ
- सर्वर सहेजें और सक्षम करें
- अब क्लॉड वेब क्वेरी जारी करने, सामग्री निकालने, और Scrapeless का उपयोग करके पृष्ठों के साथ इंटरैक्ट करने में सक्षम होगा
कर्सर IDE
- कर्सर खोलें
- Cmd + Shift + P दबाएँ और खोजें: MCP सर्वर कॉन्फ़िगर करें
- ऊपर दिए गए प्रारूप का उपयोग करके Scrapeless MCP कॉन्फ़िग जोड़ें
- फ़ाइल सहेजें और Cursor को पुनः प्रारंभ करें (यदि आवश्यक हो)
- अब आप Cursor से इस तरह की चीज़ें पूछ सकते हैं:
- “इस त्रुटि के लिए StackOverflow पर समाधान खोजें”
- “इस पृष्ठ से HTML स्क्रैप करें”
- और यह पृष्ठभूमि में Scrapeless का उपयोग करेगा।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


