
डेटा को स्वचालित रूप से कैसे स्क्रैप करें?
Senior Web Scraping Engineer
हमने हाल ही में एक आधिकारिक Make पर एकीकरण लॉन्च किया है, जो अब एक सार्वजनिक ऐप के रूप में उपलब्ध है। यह ट्यूटोरियल आपको एक शक्तिशाली स्वचालित कार्यप्रवाह बनाने का तरीका दिखाएगा जो हमारी Google सर्च API को वेब अनलॉकर के साथ मिलाकर खोज परिणामों से डेटा निकालता है, इसे क्लॉड एआई के साथ प्रोसेस करता है और इसे एक वेबहुक पर भेजता है।
हम क्या बनाएंगे
इस ट्यूटोरियल में, हम एक कार्यप्रवाह बनाएंगे जो:
- एकीकृत अनुसूची का उपयोग करके हर दिन स्वचालित रूप से ट्रिगर होता है
- Scrapeless Google Search API का उपयोग करके विशिष्ट क्वेरियों के लिए Google खोजता है
- प्रत्येक URL को व्यक्तिगत रूप से इटेरेटर के साथ प्रोसेस करता है
- Scrapeless WebUnlocker के साथ प्रत्येक URL को स्क्रैप करता है ताकि सामग्री निकाली जा सके
- सामग्री का विश्लेषण करने के लिए एंथ्रोपिक क्लॉड एआई का उपयोग करता है
- प्रोसेस किए गए डेटा को एक वेबहुक (डिस्कॉर्ड, स्लैक, डेटाबेस आदि) पर भेजता है
पूर्वापेक्षाएँ
- एक Make.com खाता
- एक Scrapeless API कुंजी (एक प्राप्त करें scrapeless.com)
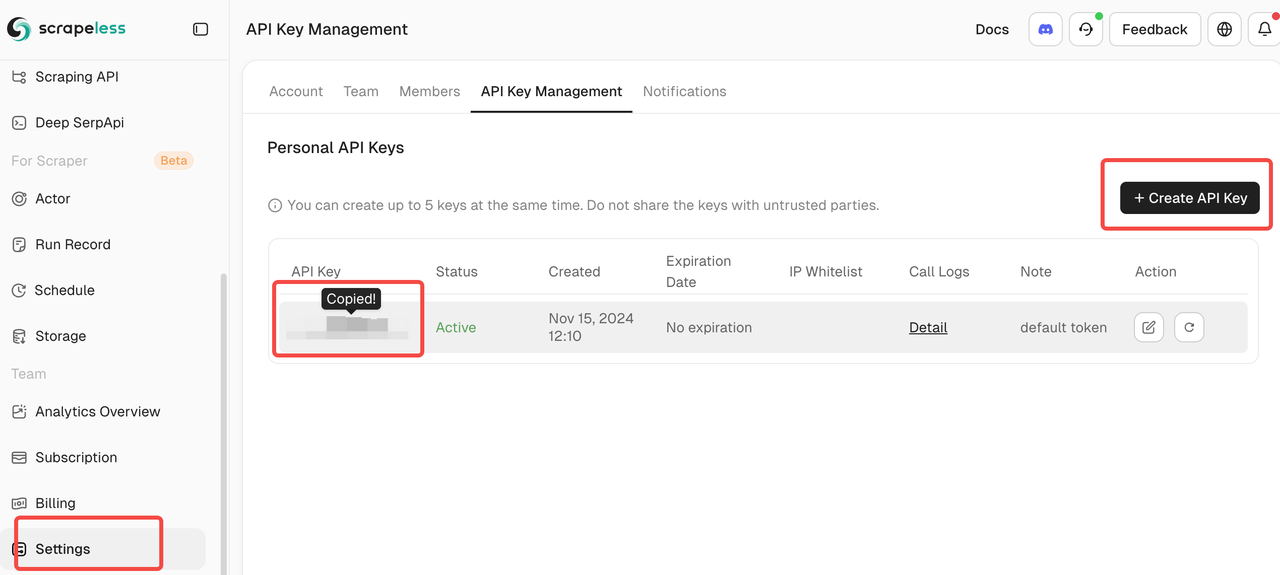
- एक एंथ्रोपिक क्लॉड एपीआई कुंजी
- एक वेबहुक अंत बिंदु (डिस्कॉर्ड वेबहुक, ज़ैपियर, डेटाबेस अंत बिंदु, आदि)
- Make.com कार्यप्रवाहों की मूल समझ
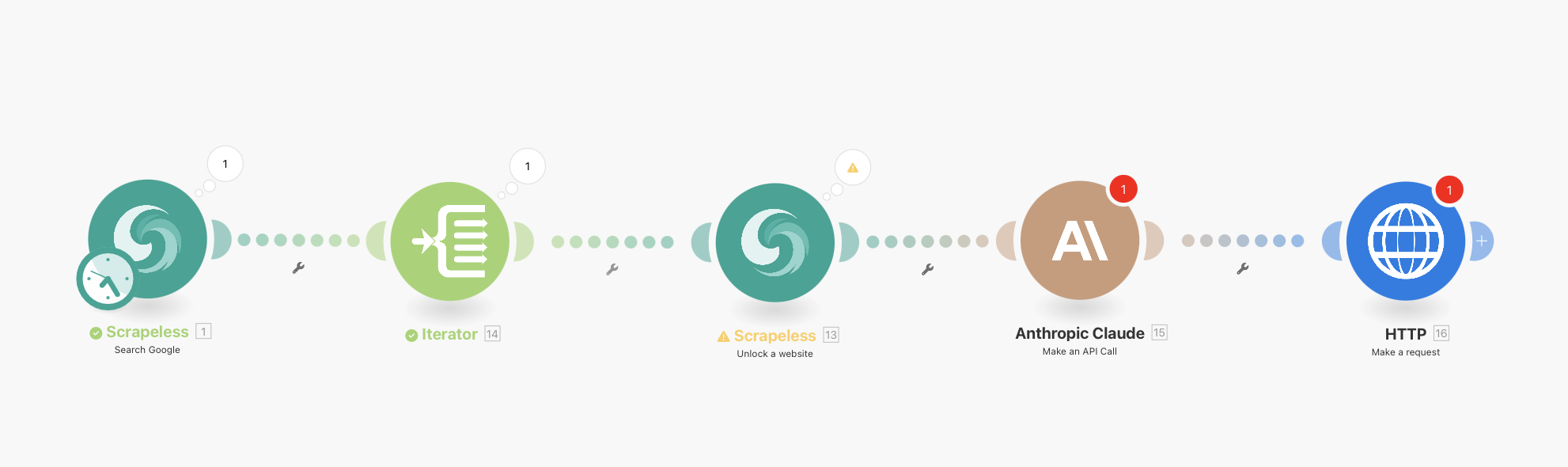
पूर्ण कार्यप्रवाह अवलोकन
आपका अंतिम कार्यप्रवाह इस प्रकार होगा:
Scrapeless Google Search (एकीकृत अनुसूची के साथ) → Iterator → Scrapeless WebUnlocker → Anthropic Claude → HTTP Webhook
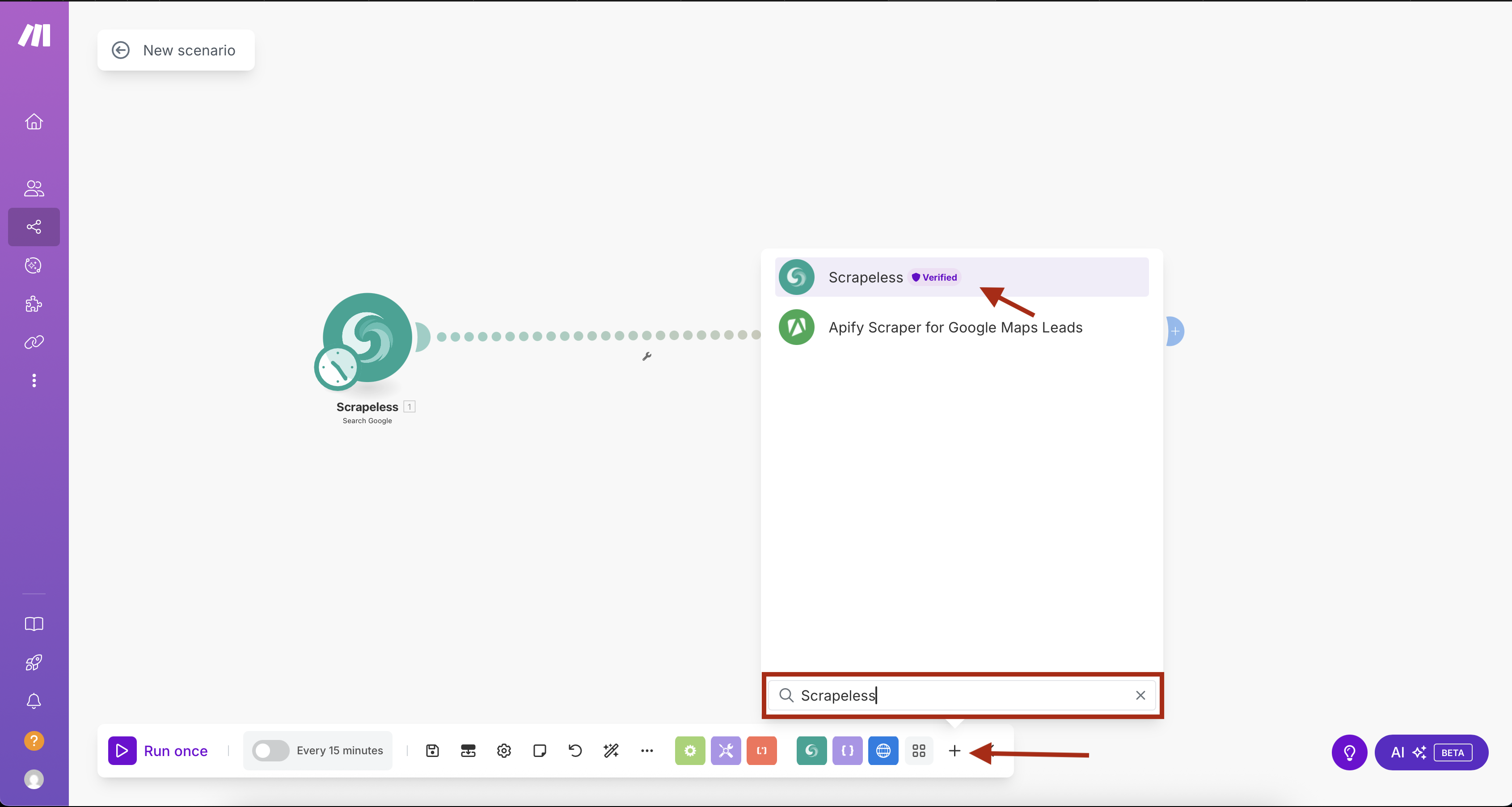
चरण 1: एकीकृत अनुसूची के साथ Scrapeless Google Search जोड़ना
हम Scrapeless Google Search मॉड्यूल को अंतर्निर्मित अनुसूचन के साथ जोड़ने से शुरू करेंगे।
- Make.com में एक नया परिदृश्य बनाएँ
- पहले मॉड्यूल को जोड़ने के लिए "+" बटन पर क्लिक करें
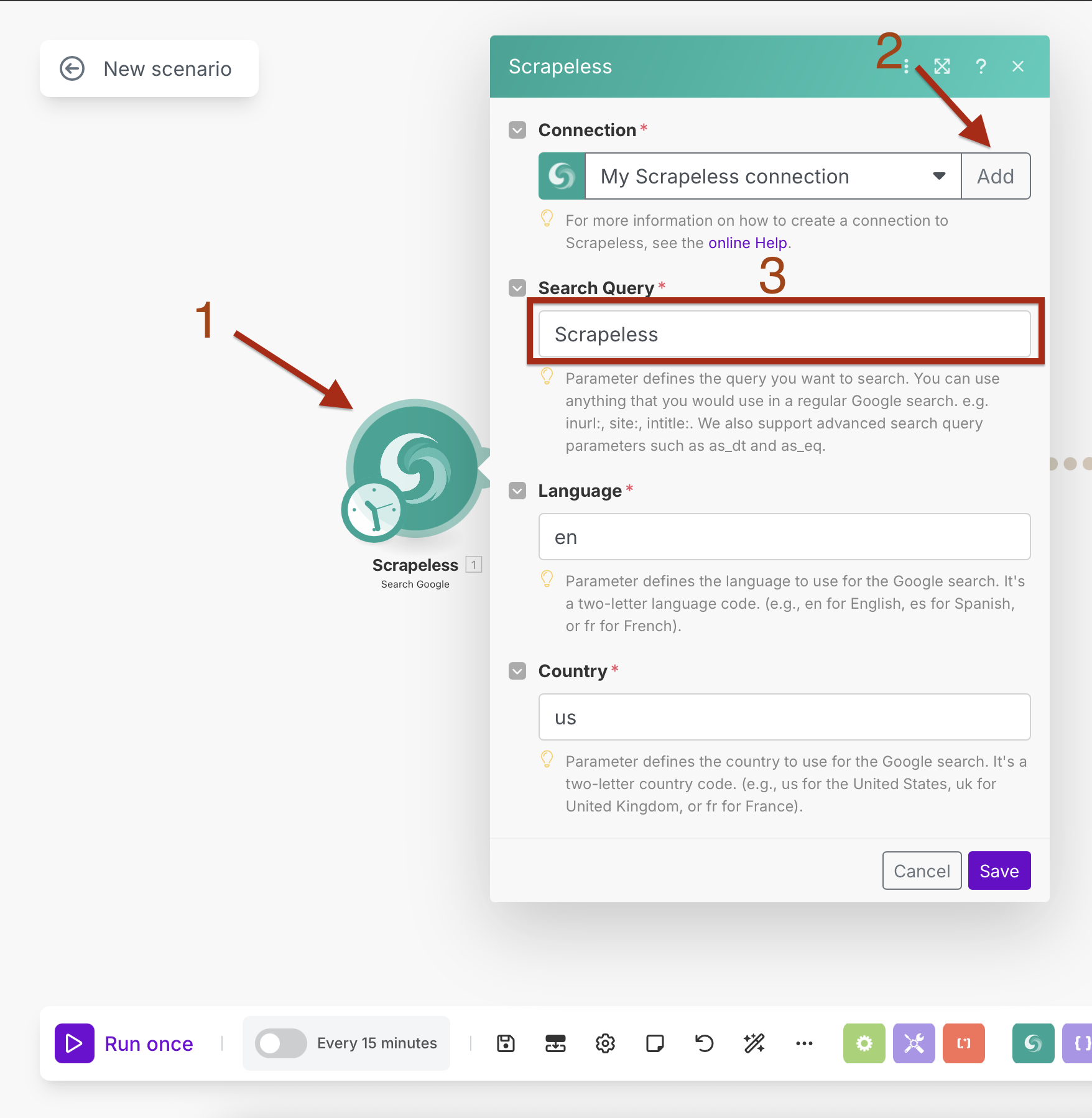
- मॉड्यूल पुस्तकालय में "Scrapeless" खोजें
- Scrapeless का चयन करें और Google खोजें क्रिया चुनें
अनुसूचि के साथ Google खोज को कॉन्फ़िगर करना
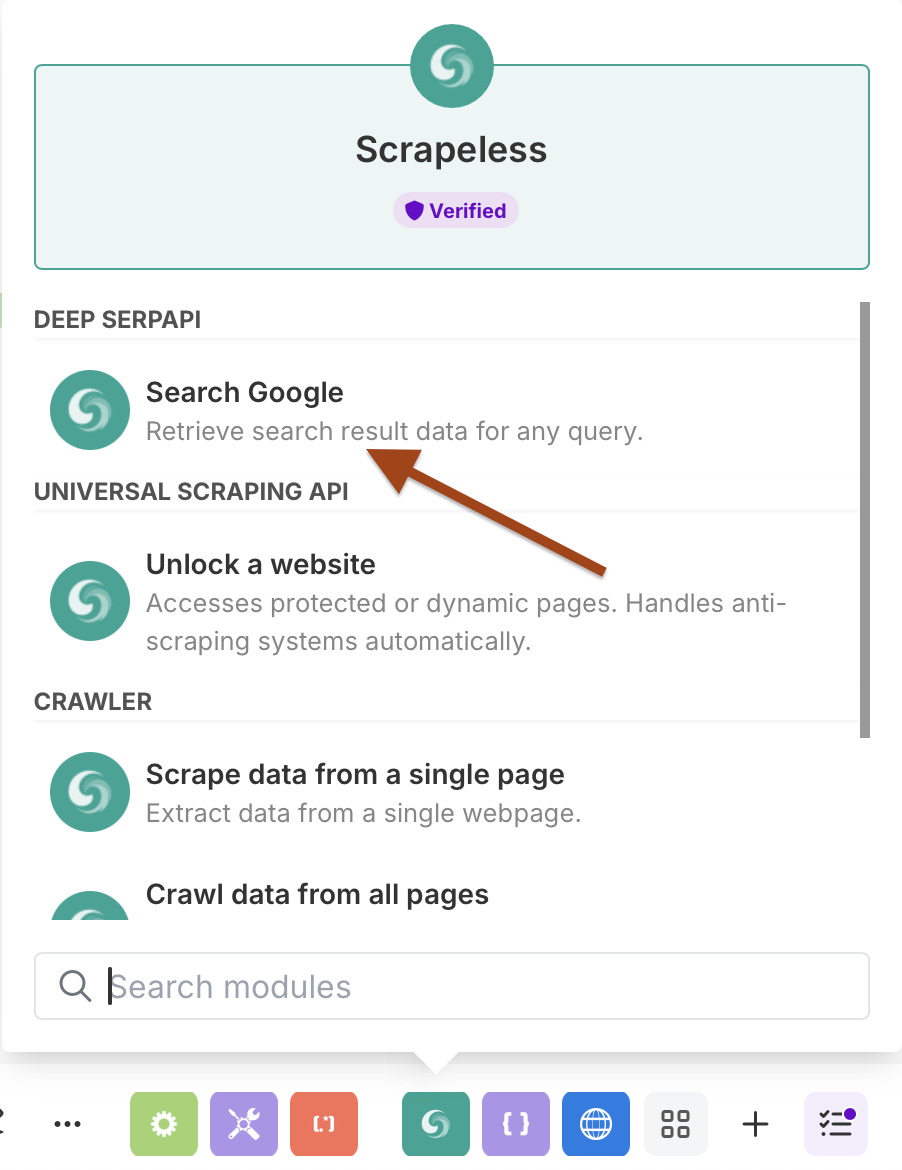
संयोग सेटअप:
- संयोग बनाएँ अपनी Scrapeless API कुंजी दर्ज करके
- "जोड़ें" पर क्लिक करें और संयोग सेटअप का पालन करें
खोज पैरामीटर:
- खोज क्वेरी: अपना लक्षित क्वेरी दर्ज करें (जैसे, "आर्टिफिशियल इंटेलिजेंस न्यूज़")
- भाषा:
en(अंग्रेज़ी) - देश:
US(संयुक्त राज्य अमेरिका)
अनुसूचि सेटअप:
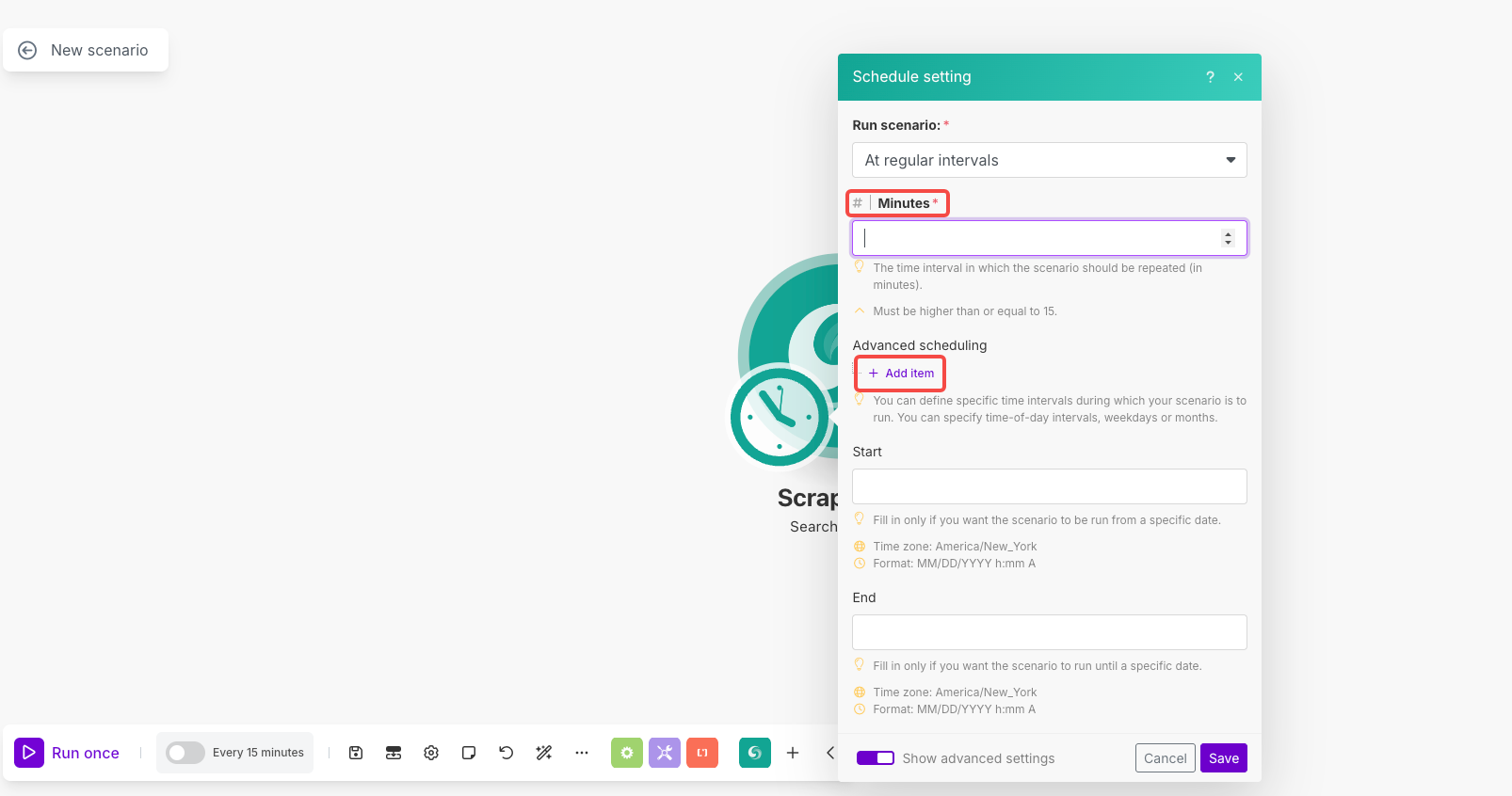
- अनुसूची खोलने के लिए मॉड्यूल पर घड़ी के आइकन पर क्लिक करें
- परिदृश्य चलाएँ: "नियमित अंतराल पर" चुनें
- मिनट: इसे
1440(दैनिक निष्पादन के लिए) या अपनी इच्छित अंतराल पर सेट करें - उन्नत अनुसूची: यदि आवश्यक हो तो विशिष्ट समय/दिन सेट करने के लिए "आइटम जोड़ें" का उपयोग करें
चरण 2: Iterator के साथ परिणामों को प्रोसेस करना
Google सर्च एक array में कई URLs लौटाता है। हम प्रत्येक परिणाम को व्यक्तिगत रूप से प्रोसेस करने के लिए Iterator का उपयोग करेंगे।
- Google Search के बाद एक Iterator मॉड्यूल जोड़ें
- खोज परिणामों को प्रोसेस करने के लिए Array फ़ील्ड को कॉन्फ़िगर करें
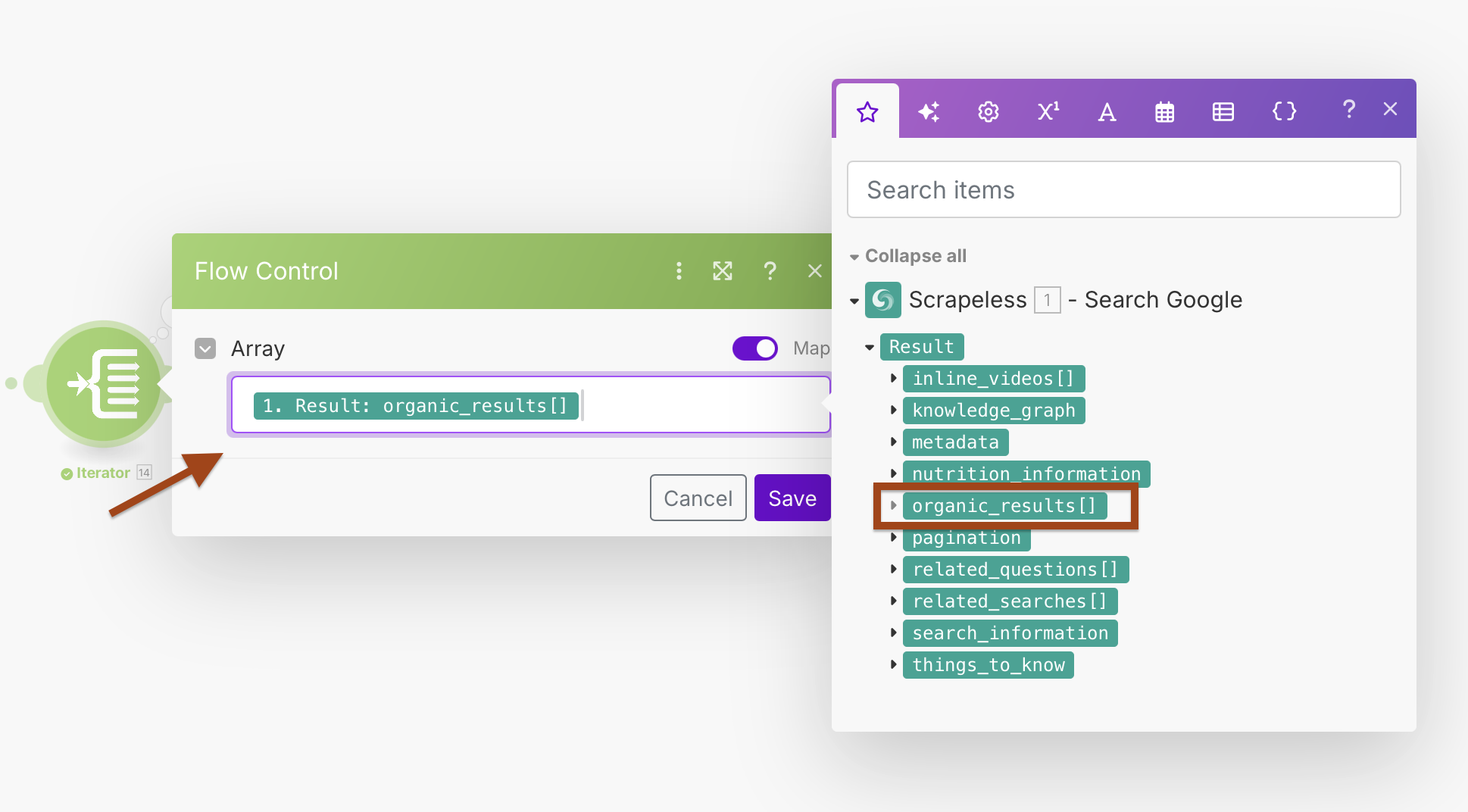
Iterator कॉन्फ़िगरेशन:
- Array:
{{1.result.organic_results}}
यह प्रत्येक खोज परिणाम को अलग-अलग प्रोसेस करने के लिए एक लूप बनाएगा, जिससे बेहतर त्रुटि हैंडलिंग और व्यक्तिगत प्रोसेसिंग की अनुमति मिलती है।
चरण 3: Scrapeless WebUnlocker जोड़ना
अब हम प्रत्येक URL से सामग्री खींचने के लिए वेब अनलॉकर मॉड्यूल जोड़ेंगे।
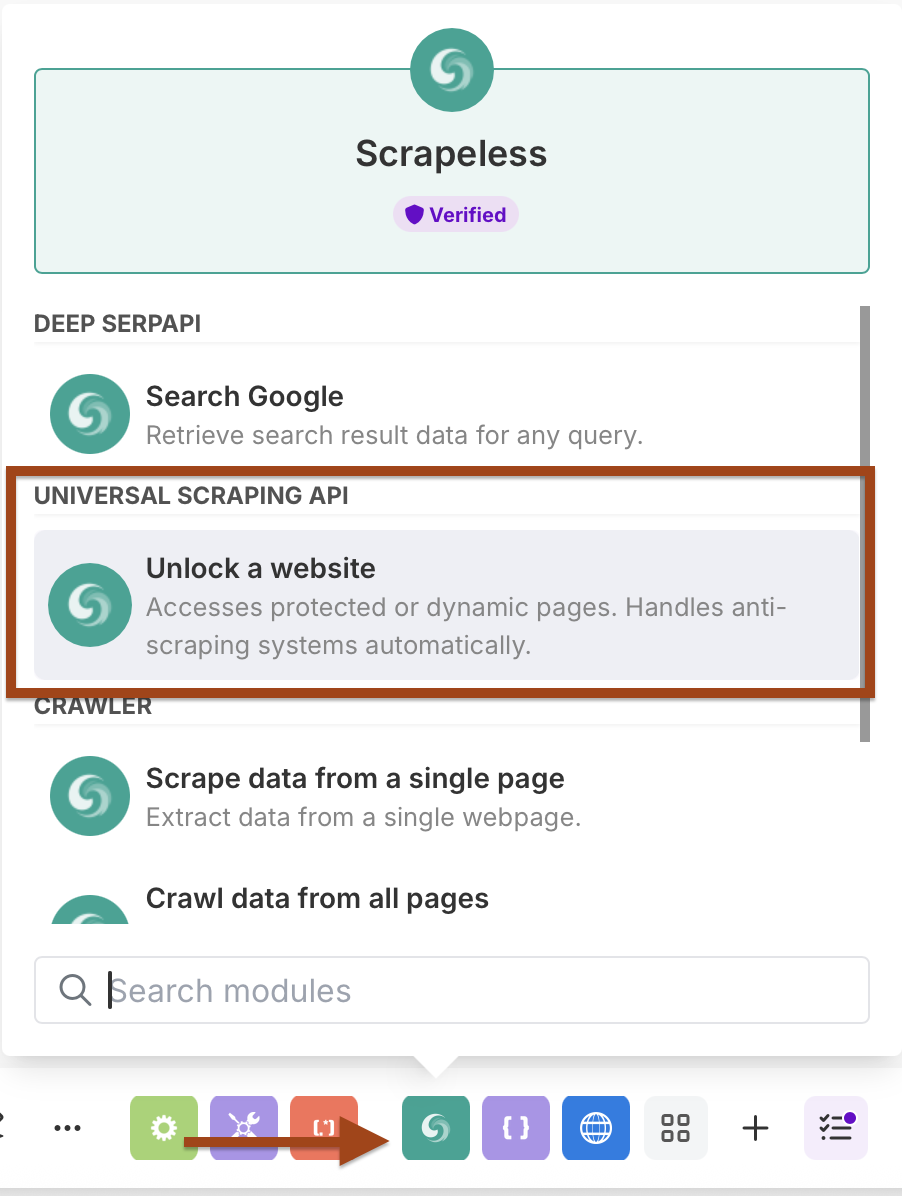
- एक और Scrapeless मॉड्यूल जोड़ें
- Scrape URL (WebUnlocker) क्रिया का चयन करें
- उसी Scrapeless कनेक्शन का उपयोग करें
WebUnlocker कॉन्फ़िगरेशन:
- संयोग: अपने मौजूदा Scrapeless कनेक्शन का उपयोग करें
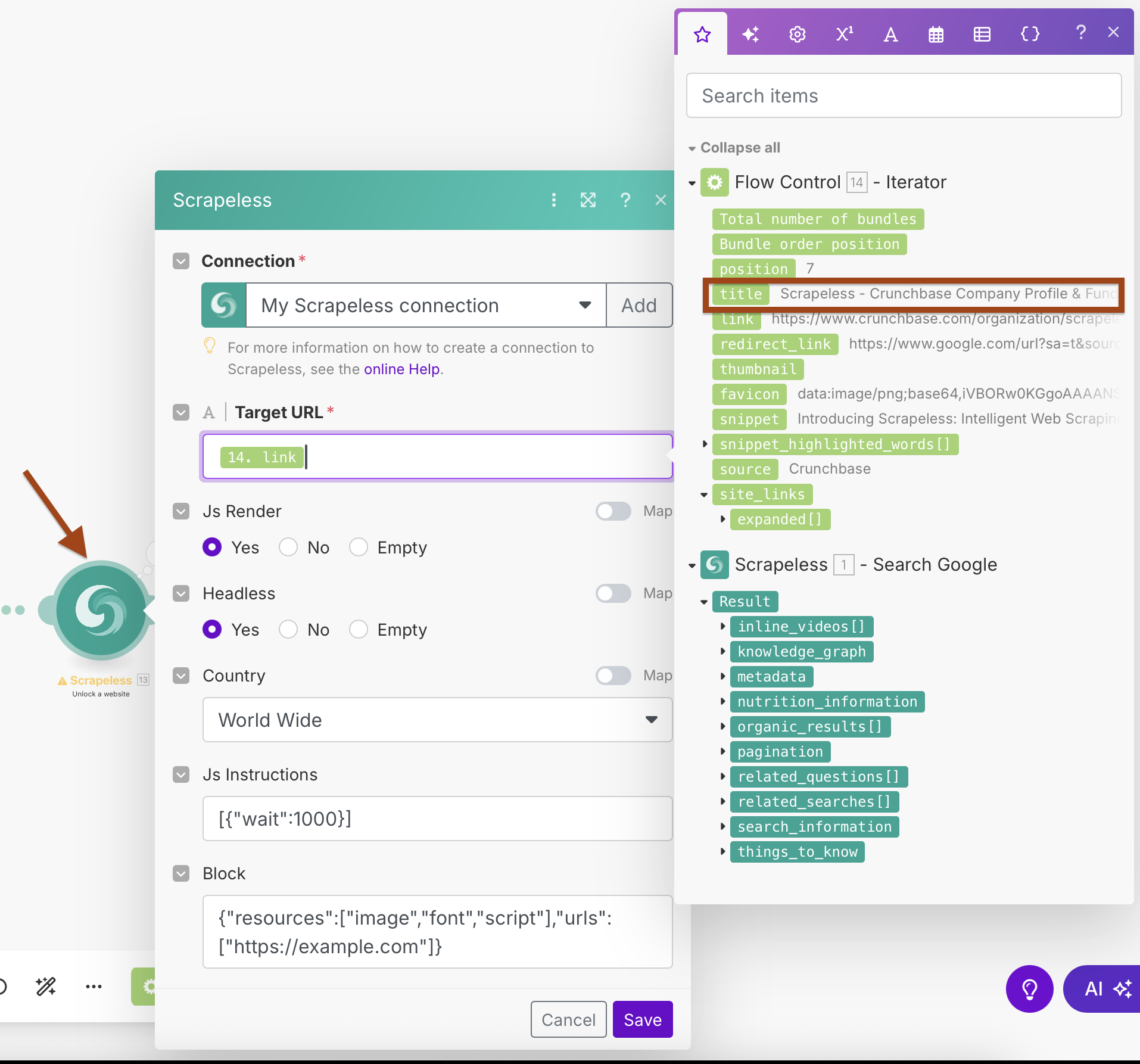
- लक्षित URL:
{{2.link}}(Iterator के आउटपुट से मानचित्रित) - Js Render: हाँ
- Headless: हाँ
- देश: विश्वव्यापी
- Js निर्देश:
[{"wait":1000}](पृष्ठ लोड होने की प्रतीक्षा करें) - ब्लॉक: तेज़ स्क्रैपिंग के लिए अनावश्यक संसाधनों को ब्लॉक करने के लिए कॉन्फ़िगर करें
चरण 4: एंथ्रोपिक क्लॉड के साथ एआई प्रोसेसिंग
स्क्रैप की गई सामग्री का विश्लेषण और संक्षेपण करने के लिए क्लॉड एआई जोड़ें।
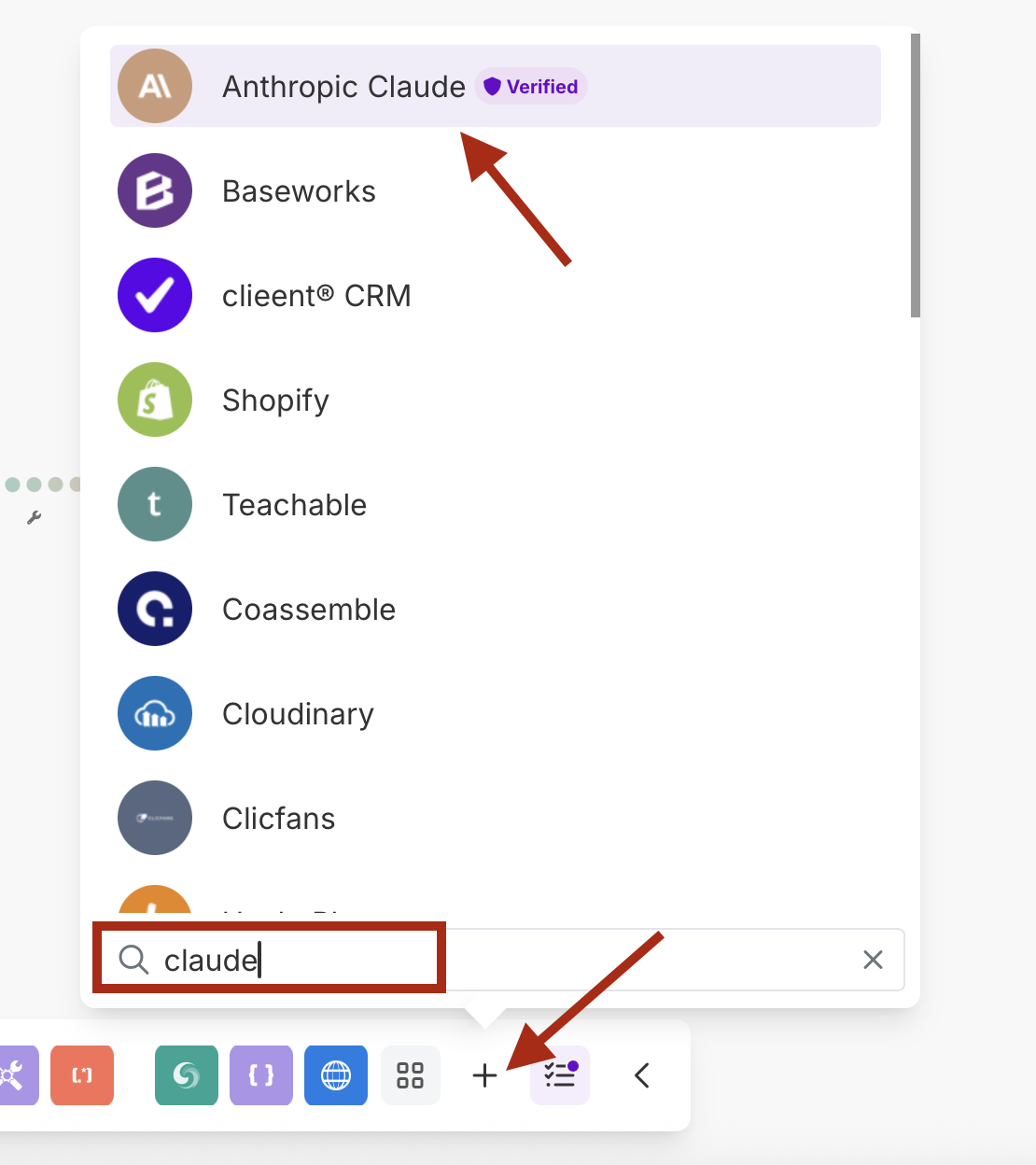
- एक Anthropic Claude मॉड्यूल जोड़ें
- Make an API Call क्रिया का चयन करें
- अपनी क्लॉड एपीआई कुंजी के साथ एक नया कनेक्शन बनाएं
क्लॉड कॉन्फ़िगरेशन:
-
संयोग: अपनी एंथ्रोपिक एपीआई कुंजी के साथ कनेक्शन बनाएं
Here is the translation of your request into Hindi: -
प्रांप्प्ट: स्क्रैप की गई सामग्री का विश्लेषण करने के लिए कॉन्फ़िगर करें
-
मॉडल: claude-3-sonnet-20240229 / claude-3-opus-20240229 या आपका पसंदीदा मॉडल
-
अधिकतम टोकन: 1000-4000 आपकी जरूरतों के अनुसार
यूआरएल
/v1/messagesहेडर 1
की : सामग्री-प्रकारमूल्य : application/json
हेडर 2
की : anthropic-versionमूल्य : 2023-06-01
उदाहरण प्रांप्प्ट बॉडी में कॉपी पेस्ट करें:
{
"model": "claude-3-sonnet-20240229",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "इस वेब सामग्री का विश्लेषण करें और प्रमुख बिंदुओं के साथ अंग्रेजी में एक संक्षेप प्रदान करें:\n\nशीर्षक: {{14.title}}\nयूआरएल: {{14.link}}\nविवरण: {{14.snippet}}\nसामग्री: {{13.content}}\n\nखोज प्रश्न: {{1.result.search_information.query_displayed}}"
}
]
}- संख्या
14को अपने मॉड्यूल संख्या से बदलना न भूलें।
चरण 5: वेबहुक एकीकरण
अंत में, संसाधित डेटा को अपने वेबहुक अंत बिंदु पर भेजें।
- एक HTTP मॉड्यूल जोड़ें
- इसे अपने वेबहुक के लिए POST अनुरोध भेजने के लिए कॉन्फ़िगर करें
HTTP कॉन्फ़िगरेशन:
- यूआरएल: आपका वेबहुक अंत बिंदु (Discord, Slack, डेटाबेस, आदि)
- विधि: POST
- हेडर:
सामग्री-प्रकार: application/json - शरीर प्रकार: कच्चा (JSON)
उदाहरण वेबहुक लोड:
{
"embeds": [
{
"title": "{{14.title}}",
"description": "*{{15.body.content[0].text}}*",
"url": "{{14.link}}",
"color": 3447003,
"footer": {
"text": "विश्लेषण पूरा"
}
}
]
}परिणाम चलाना
मॉड्यूल संदर्भ और डेटा प्रवाह
मॉड्यूल के माध्यम से डेटा प्रवाह:
- मॉड्यूल 1 (Scrapeless Google खोज):
result.organic_results[]लौटाता है - मॉड्यूल 14 (आईटरटर): प्रत्येक परिणाम को संसाधित करता है, व्यक्तिगत आइटम आउटपुट करता है
- मॉड्यूल 13 (WebUnlocker):
{{14.link}}को स्क्रैप करता है, सामग्री लौटाता है - मॉड्यूल 15 (Claude AI):
{{13.content}}का विश्लेषण करता है, संक्षेप लौटाता है - मॉड्यूल 16 (HTTP वेबहुक): अंतिम संरचित डेटा भेजता है
प्रमुख मैपिंग:
- आईटरटर ऐरे:
{{1.result.organic_results}} - WebUnlocker यूआरएल:
{{14.link}} - Claude सामग्री:
{{13.content}} - Webhook डेटा: सभी पिछले मॉड्यूल का संयोजन
अपने वर्कफ़्लो का परीक्षण करें
- एक बार चलाएँ संपूर्ण परिदृश्य परीक्षण करने के लिए
- प्रत्येक मॉड्यूल की जांच करें:
- Google खोज जैविक परिणाम लौटाता है
- आईटरटर प्रत्येक परिणाम को व्यक्तिगत रूप से संसाधित करता है
- WebUnlocker सफलतापूर्वक सामग्री को स्क्रैप करता है
- Claude महत्वपूर्ण विश्लेषण प्रदान करता है
- वेबहुक संरचित डेटा प्राप्त करता है
- अपने वेबहुक गंतव्य में डेटा गुणवत्ता की पुष्टि करें
- अनुसूची की जांच करें - सुनिश्चित करें कि यह आपकी पसंदीदा अंतराल पर चलता है
उन्नत कॉन्फ़िगरेशन सुझाव
त्रुटि हैंडलिंग
- प्रत्येक मॉड्यूल के बाद त्रुटि हैंडलर रूट्स जोड़ें
- अवैध यूआरएल या खाली सामग्री को छोड़ने के लिए फ़िल्टर का उपयोग करें
- अस्थायी विफलताओं के लिए रीट्री लॉजिक सेट करें
इस वर्कफ़्लो के लाभ
- पूर्णतः स्वचालित: बिना मैनुअल हस्तक्षेप के दैनिक चलता है
- एआई-संवर्धित: सामग्री का स्वचालित विश्लेषण और संक्षेपण किया जाता है
- लचीला आउटपुट: वेबहुक किसी भी सिस्टम के साथ एकीकृत हो सकता है
- स्केलेबल: कई यूआरएल को प्रभावशाली तरीके से संसाधित करता है
- गुणवत्ता नियंत्रित: कई फ़िल्टरिंग और मान्यता चरण होते हैं
- वास्तविक समय सूचनाएँ: आपके पसंदीदा मंच पर त्वरित डिलीवरी
उपयोग के मामले
परफेक्ट के लिए:
- सामग्री मॉनिटरिंग: अपने ब्रांड या प्रतिस्पर्धियों का उल्लेख ट्रैक करें
- समाचार एकत्रित करना: विशिष्ट विषयों पर स्वचालित समाचार संक्षेप
- मार्केट रिसर्च: उद्योग के रुझान और विकास की निगरानी करें
- लीड जनरेशन: संभावित व्यावसायिक अवसरों का पता लगाएँ और उनका विश्लेषण करें
- SEO मॉनिटरिंग: लक्षित कीवर्ड के लिए खोज परिणाम परिवर्तनों को ट्रैक करें
- शोध स्वचालन: शैक्षणिक या उद्योग सामग्री एकत्र करें और संक्षेप करें
निष्कर्ष
यह स्वचालित वर्कफ़्लो Scrapeless की Google खोज और WebUnlocker की शक्ति को Claude AI के विश्लेषणात्मक क्षमताओं के साथ जोड़ता है, सभी Make के दृश्य इंटरफ़ेस के माध्यम से समन्वयित होता है। परिणाम एक बुद्धिमान सामग्री खोज प्रणाली है जो स्वचालित रूप से चलती है और समृद्ध, विश्लेषित डेटा को सीधे आपके पसंदीदा प्लेटफॉर्म पर वेबहुक के माध्यम से प्रदान करती है।
यह वर्कफ़्लो आपके कार्यक्रम पर चलेगा, स्वचालित रूप से प्रासंगिक सामग्री अंतर्दृष्टियाँ खोजता, स्क्रैप करता, विश्लेषण करता और वितरित करता है बिना किसी मैनुअल हस्तक्षेप के।
अपने पहले एआई एजेंट का निर्माण करने का समय है Make का उपयोग करते हुए Scrapeless!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


