
Python से Google Search Results कैसे Scrape करें - सबसे अच्छा Google Search Scraper?
Specialist in Anti-Bot Strategies
Google SERP क्या है?
जब भी वेब स्क्रैपिंग Google खोज परिणामों पर चर्चा की जाती है, तो आपको सबसे अधिक संभावना है कि "SERP" संक्षिप्त नाम मिलेगा। SERP का अर्थ है सर्च इंजन रिजल्ट पेज। यह वह पृष्ठ है जो आपको सर्च बार में कोई क्वेरी दर्ज करने के बाद मिलता है।
अतीत में, Google आपकी क्वेरी के लिए लिंक की एक सूची देता था। आज, यह पूरी तरह से अलग दिखता है - SERP में कई तरह की सुविधाएँ और तत्व शामिल हैं जो आपके खोज अनुभव को तेज़ और सुविधाजनक बनाते हैं।
आमतौर पर, पृष्ठ में शामिल होते हैं:
- ऑर्गेनिक सर्च रिजल्ट्स
- पेड सर्च रिजल्ट्स
- फीचर्ड स्निपेट्स
- नॉलेज ग्राफ
- अन्य तत्व: जैसे मानचित्र, चित्र, या समाचार कहानियाँ जो क्वेरी के आधार पर दिखाई देती हैं।
क्या Google खोज परिणामों को स्क्रैप करना कानूनी है?
Google खोज परिणामों को स्क्रैप करने से पहले, कानूनी निहितार्थों को समझना आवश्यक है। Google की सेवा की शर्तें उनके खोज परिणामों को स्क्रैप करने पर रोक लगाती हैं, जैसा कि उनकी नीतियों में बताया गया है:
"आप किसी भी उद्देश्य के लिए सेवाओं तक पहुँचने के लिए स्क्रैप, क्रॉल या किसी भी स्वचालित साधनों का उपयोग नहीं करेंगे।"
इन शर्तों का उल्लंघन करने से Google द्वारा IP प्रतिबंध या कानूनी कार्रवाई भी हो सकती है। हालाँकि, स्क्रैपिंग की वैधता अधिकार क्षेत्र, आपके द्वारा स्क्रैप किए जा रहे डेटा और आप इसके उपयोग पर निर्भर करती है।
Google स्क्रैपिंग के विकल्प:
- Google कस्टम सर्च API: Google खोज परिणामों को पुनः प्राप्त करने के लिए एक आधिकारिक API प्रदान करता है, जो उनकी नीतियों का उल्लंघन किए बिना डेटा तक पहुँचने का एक कानूनी और संरचित तरीका प्रदान करता है।
- अन्य खोज API: यदि आप Google का उपयोग करने के लिए तैयार नहीं हैं, तो अन्य खोज इंजन और सेवाएँ हैं जो खोज परिणामों तक पहुँचने के लिए API प्रदान करती हैं, जैसे कि Bing, और Scrapeless।
Google SERP को स्क्रैप करने की 4 मुख्य कठिनाइयाँ
Google SERP को स्क्रैप करने में कई चुनौतियाँ हैं, यही कारण है कि इसे कठिन माना जाता है। इसमें शामिल हैं:
- बॉट डिटेक्शन: Google बॉट्स का पता लगाने और उन्हें ब्लॉक करने के लिए कई तकनीकों का उपयोग करता है, जिनमें शामिल हैं:
- CAPTCHA
- IP ब्लॉकिंग
- रेट लिमिटिंग
- डायनामिक कंटेंट: Google खोज परिणाम अक्सर जावास्क्रिप्ट का उपयोग करके गतिशील रूप से उत्पन्न होते हैं, जो स्क्रैपिंग को जटिल बना सकते हैं। प्रारंभिक पृष्ठ लोड के बाद सामग्री लोड हो सकती है, जिसके लिए पृष्ठ को पूरी तरह से रेंडर करने के लिए सेलेनियम जैसे टूल की आवश्यकता होती है।
- HTML संरचना परिवर्तन: Google अक्सर अपने खोज परिणामों के लेआउट और संरचना को बदलता रहता है, जिसका अर्थ है कि स्क्रैपर्स को कोड को तोड़ने से बचने के लिए जल्दी से अनुकूलित करने की आवश्यकता होती है।
- जटिल डेटा: SERP में विज्ञापन, चित्र, वीडियो और समृद्ध स्निपेट जैसे विभिन्न जटिल तत्व शामिल हैं, जिससे लगातार सार्थक डेटा निकालना चुनौतीपूर्ण हो जाता है।
इन चुनौतियों के बावजूद, सही तकनीकों और उपकरणों के साथ Google खोज परिणामों को स्क्रैप करना अभी भी संभव है।
आइए Python के साथ Google खोज परिणामों को स्क्रैप करने के लिए प्रक्रिया को निम्न चरणों में विभाजित करें:
Python का उपयोग करके Google खोज परिणामों को कैसे स्क्रैप करें?
चरण 1: Google को अनुरोध भेजें
स्क्रैपिंग शुरू करने से पहले, आपको Google के खोज पृष्ठ पर एक अनुरोध भेजना होगा। चूँकि Google अधिकांश बॉट्स से अनुरोधों को ब्लॉक करता है, इसलिए उचित User-Agent हेडर सेट करके वास्तविक उपयोगकर्ता का अनुकरण करना आवश्यक है।
Python
import requests
from fake_useragent import UserAgent
# Generate a random user-agent
ua = UserAgent()
headers = {'User-Agent': ua.random}
# Google search query
query = "How to scrape Google search results with Python"
url = f"https://www.google.com/search?q={query}"
# Send the GET request
response = requests.get(url, headers=headers)
# Check if the request was successful
if response.status_code == 200:
print(response.text)
else:
print("Failed to retrieve the page")चरण 2: HTML सामग्री पार्स करें
एक बार जब आपके पास Google SERP की HTML सामग्री हो जाती है, तो आप आवश्यक डेटा निकालने के लिए BeautifulSoup का उपयोग कर सकते हैं।
Python
from bs4 import BeautifulSoup
# Parse the page content
soup = BeautifulSoup(response.text, 'html.parser')
# Find all the search result containers
search_results = soup.find_all('div', class_='BVG0Nb')
for result in search_results:
title = result.text
link = result.find('a')['href']
print(f"Title: {title}")
print(f"Link: {link}\n")चरण 3: जावास्क्रिप्ट को हैंडल करना (सेलेनियम का उपयोग करके)
सेलेनियम उन पृष्ठों को संभालने के लिए एक बेहतरीन उपकरण है जो सामग्री को प्रस्तुत करने के लिए जावास्क्रिप्ट पर निर्भर करते हैं। यह एक ब्राउज़र को स्वचालित करता है और उपयोगकर्ता की बातचीत का अनुकरण करता है, जिससे इसे गतिशील रूप से उत्पन्न सामग्री को स्क्रैप करने के लिए आदर्श बनाया जाता है।
Python
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# Set up Selenium WebDriver
driver = webdriver.Chrome(ChromeDriverManager().install())
# Open Google and perform the search
driver.get("https://www.google.com/")
search_box = driver.find_element(By.NAME, 'q')
search_box.send_keys("How to scrape Google search results with Python")
search_box.submit()
# Wait for results to load and extract the links
driver.implicitly_wait(5)
# Get search results
search_results = driver.find_elements(By.CLASS_NAME, 'BVG0Nb')
for result in search_results:
title = result.text
link = result.find_element(By.TAG_NAME, 'a').get_attribute('href')
print(f"Title: {title}")
print(f"Link: {link}\n")
driver.quit()चरण 4: पता लगाने से बचें
Google द्वारा पता लगाए जाने और ब्लॉक किए जाने की संभावना को कम करने के लिए, आपको यह करना चाहिए:
- यूज़र एजेंट्स को घुमाएँ: विभिन्न ब्राउज़रों से अनुरोधों का अनुकरण करने के लिए विभिन्न उपयोगकर्ता एजेंटों का उपयोग करें।
- देरी जोड़ें: मानव जैसे ब्राउज़िंग व्यवहार की नकल करने के लिए अनुरोधों के बीच यादृच्छिक देरी शुरू करें।
- प्रॉक्सी का उपयोग करें: अपने अनुरोधों को वितरित करने और पता लगाने से बचने के लिए IP पते घुमाएँ।
- Robots.txt का सम्मान करें: हमेशा Google की robots.txt फ़ाइल की जाँच करें और नैतिक स्क्रैपिंग प्रथाओं का पालन करें।
सबसे अच्छा Google खोज स्क्रैपिंग API - Scrapeless
जबकि Google को सीधे स्क्रैप करना संभव है, यह थकाऊ और त्रुटि-प्रवण हो सकता है, और इसके परिणामस्वरूप अक्सर अवरुद्ध हो जाता है। यहीं पर Scrapeless आता है। शक्तिशाली CAPTCHA सॉल्वर, IP रोटेशन, इंटेलिजेंट प्रॉक्सी और वेब अनलॉकर के साथ, Scrapeless एक शक्तिशाली API है जिसे विशेष रूप से उपयोगकर्ताओं को बिना अवरुद्ध किए खोज परिणामों को स्क्रैप करने में मदद करने के लिए डिज़ाइन किया गया है।
Scrapeless क्यों चुनें?
- वैधता: Scrapeless खोज परिणामों तक पहुँचने का एक कानूनी और अनुपालन तरीका प्रदान करता है।
- विश्वसनीयता: API पता लगाने से बचने के लिए परिष्कृत तकनीकों का उपयोग करता है, जिससे निर्बाध डेटा संग्रह सुनिश्चित होता है।
- उपयोग में आसानी: Scrapeless एक सरल API प्रदान करता है जो Python के साथ आसानी से एकीकृत होता है, जिससे यह उन डेवलपर्स के लिए आदर्श है जिन्हें खोज परिणाम डेटा तक त्वरित पहुँच की आवश्यकता होती है।
- अनुकूलन योग्य: आप अपनी आवश्यकताओं के अनुसार परिणामों को तैयार कर सकते हैं, जैसे कि सामग्री के प्रकार को निर्दिष्ट करना (जैसे, ऑर्गेनिक लिस्टिंग, विज्ञापन, आदि)।
Scrapeless Google खोज स्क्रैपर API - चरणों का उपयोग करना:
डेटा को लक्षित और विशिष्ट बनाने के लिए, हम इस लेख में Google रुझानों को एक प्रदर्शन के रूप में क्रॉल करते हैं।
वेब ब्लॉकिंग और Google खोज स्क्रैपिंग पर निराश?
हमारे समुदाय में शामिल हों और निःशुल्क परीक्षण के साथ प्रभावी समाधान प्राप्त करें!
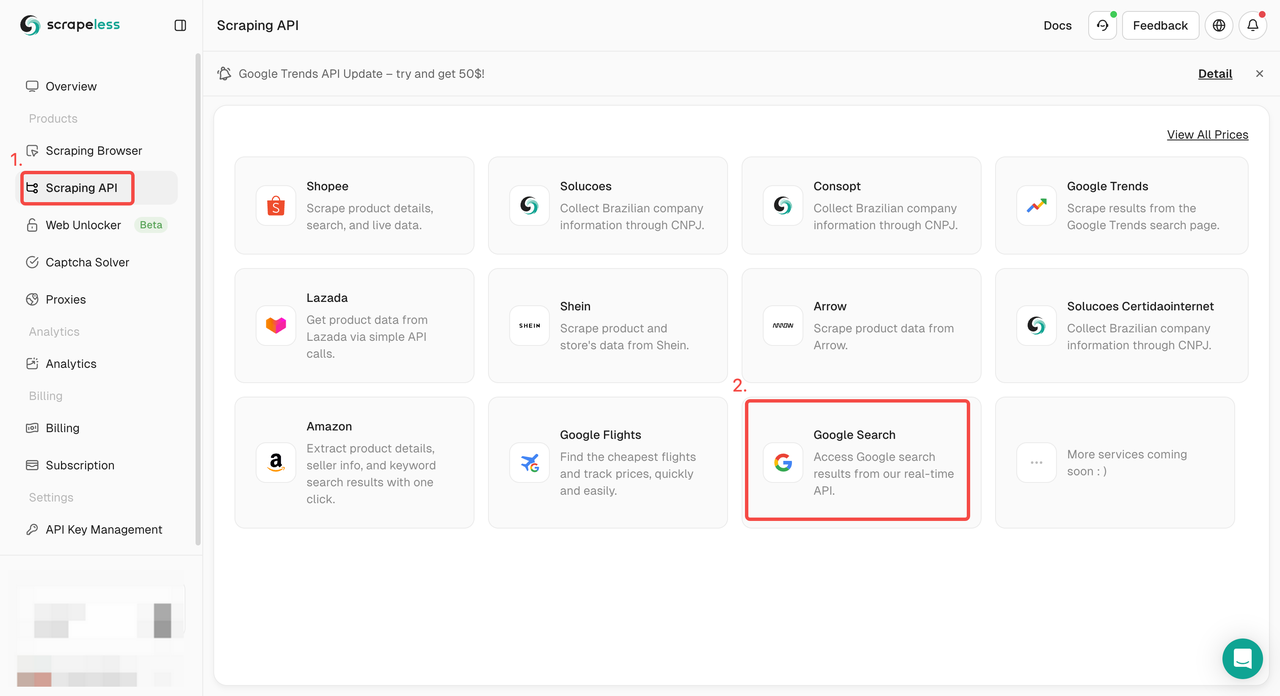
चरण 1। Scrapeless डैशबोर्ड में लॉग इन करें और "Google खोज API" पर जाएँ।
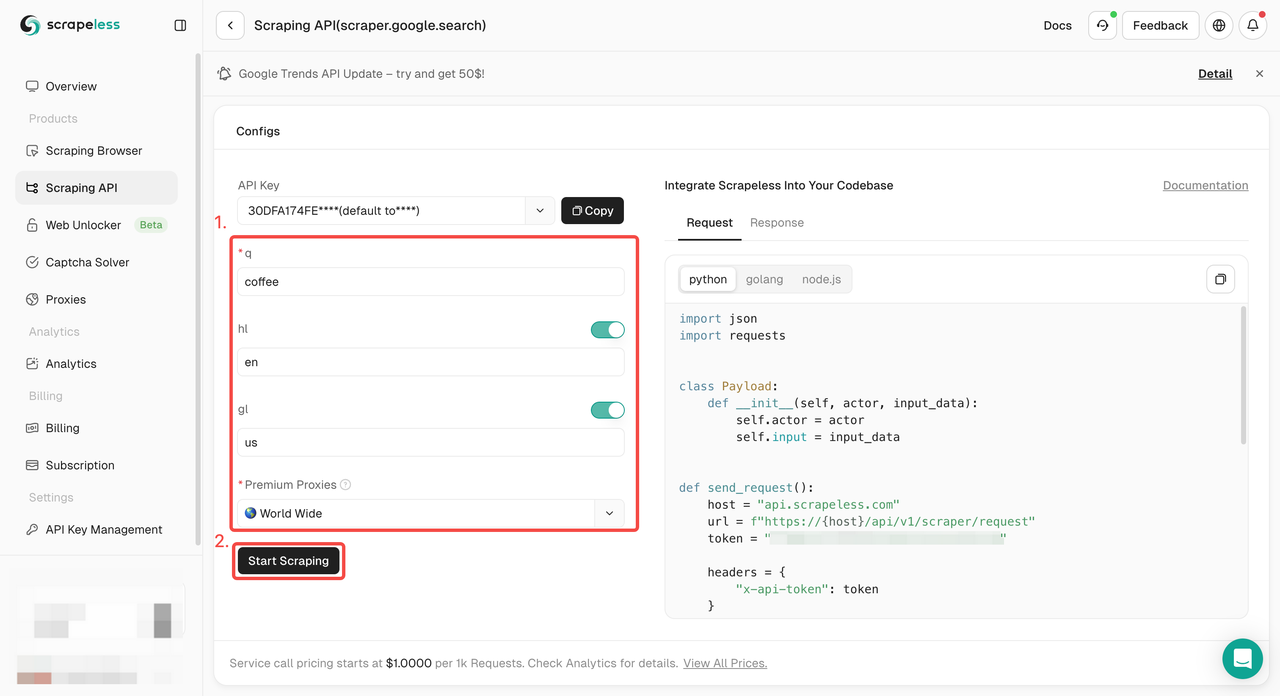
चरण 2। बाईं ओर आपको आवश्यक कीवर्ड, क्षेत्र, भाषा, प्रॉक्सी और अन्य जानकारी कॉन्फ़िगर करें। यह सुनिश्चित करने के बाद कि सब कुछ ठीक है, "स्क्रैपिंग शुरू करें" पर क्लिक करें।
q: पैरामीटर उस क्वेरी को परिभाषित करता है जिसे आप खोजना चाहते हैं।gl: पैरामीटर Google खोज के लिए उपयोग किए जाने वाले देश को परिभाषित करता है।hl: पैरामीटर Google खोज के लिए उपयोग की जाने वाली भाषा को परिभाषित करता है।
चरण 3। क्रॉलिंग परिणाम प्राप्त करें और उन्हें निर्यात करें।
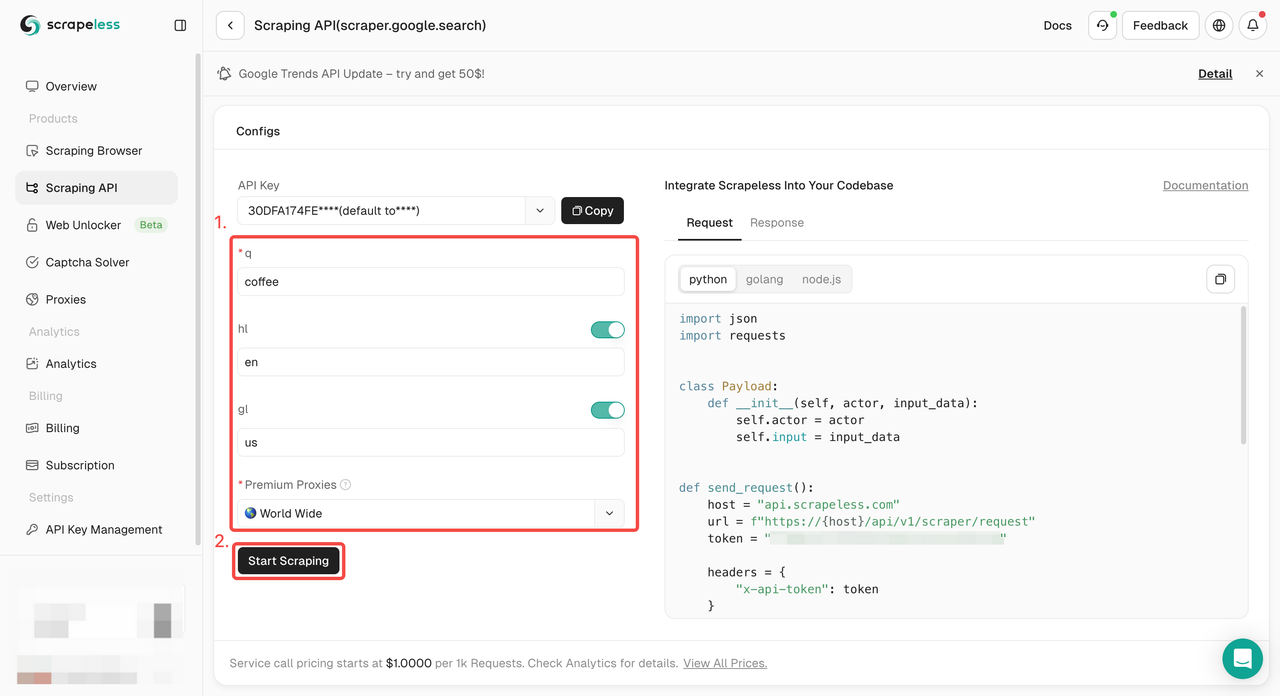
बस अपनी परियोजना में एकीकृत करने के लिए नमूना कोड की आवश्यकता है? हमने आपको कवर कर लिया है! या आप अपनी ज़रूरत की किसी भी भाषा के लिए हमारे API दस्तावेज़ीकरण पर जा सकते हैं।
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}अंत शब्द
Google खोज परिणामों को स्क्रैप करना मुश्किल हो सकता है, लेकिन सही उपकरणों और तकनीकों के साथ, यह निश्चित रूप से प्राप्त करने योग्य है! बस याद रखें: यह सब कोड लिखने के बारे में नहीं है - यह जानने के बारे में है कि पता लगाने से कैसे बचा जाए, कानूनी सीमाओं का सम्मान करें, और जब आवश्यक हो तो विकल्प खोजें।
Scrapeless स्क्रैपिंग API Google खोज परिणामों को स्क्रैप करने की दुनिया में आपका सबसे अच्छा दोस्त हो सकता है!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


