
Python से Google Scholar को कैसे Scrape करें?
Expert Network Defense Engineer
Google Scholar एक ऐसा सर्च इंजन है जिससे विद्वत्तापूर्ण डेटा तक पहुँचा जा सकता है। Google Scholar की मदद से आप वैज्ञानिक लेख, शोध पत्र और निबंध प्राप्त कर सकते हैं। हालाँकि, अकादमिक अनुसंधान के लिए अक्सर Google Scholar के खोज परिणामों से बड़ी मात्रा में डेटा एकत्रित करने और विश्लेषण करने की आवश्यकता होती है।
अनगिनत परिणामों के बीच मैन्युअल रूप से छानबीन करना एक कठिन काम है। इसलिए एक विश्वसनीय Google Scholar स्क्रैपर इस प्रक्रिया को आसान बनाने में मदद कर सकता है। ऑटोमेशन के साथ, आप सेकंड में Google Scholar पृष्ठ पर प्रत्येक परिणाम से शीर्षक, लेखक और उद्धरण जैसे डेटा निकालने के लिए Google Scholar को स्क्रैप कर सकते हैं।
इस ट्यूटोरियल में, आप Scrapeless Google Scholar API और Python का उपयोग करके HTTP अनुरोध करके एक प्रभावी Google Scholar स्क्रैपर कैसे बनाएँगे, यह सीखेंगे।
अधिक जानने के लिए स्क्रॉल करते रहें!
🎓 Google Scholar स्क्रैपर क्या है?
एक Google Scholar स्क्रैपर एक ऐसा उपकरण है जो Google Scholar से सार्वजनिक रूप से उपलब्ध अकादमिक डेटा, जैसे शोध पत्र, उद्धरण, लेखक और प्रकाशन विवरण निकालने के लिए डिज़ाइन किया गया है। यह शोधकर्ताओं, शिक्षाविदों और संगठनों को विश्लेषण, प्रवृत्ति ट्रैकिंग और अकादमिक अनुसंधान के लिए मूल्यवान अंतर्दृष्टि प्राप्त करने में सक्षम बनाता है। हालाँकि, इसके मजबूत एंटी-स्क्रैपिंग तंत्र के कारण Google Scholar को वेब स्क्रैपिंग करने में महत्वपूर्ण चुनौतियाँ आती हैं।
Google Scholar पर डेटा क्यों मूल्यवान है?
- समीक्षा और अनुसंधान: अकादमिक अनुसंधान या परियोजनाओं से संबंधित पत्र, लेख, थीसिस और पुस्तकें खोजें। विभिन्न विधियों और सैद्धांतिक ढाँचों की तुलना करें।
- अकादमिक विश्लेषण: अकादमिक प्रकाशनों में उभरते रुझानों और विषयों की पहचान करें और H-इंडेक्स और उद्धरण गणना जैसे अकादमिक मीट्रिक की गणना करें।
- संभावित सहयोग: संभावित सहयोग, सम्मेलनों या सहकर्मी समीक्षाओं के लिए किसी विशिष्ट क्षेत्र के विशेषज्ञों की पहचान करें।
- उत्पाद विकास: R&D पेशेवर गहन शोध, सफलताओं के लिए Google Scholar को स्क्रैप कर सकते हैं, और संबंधित वैज्ञानिक या तकनीकी क्षेत्रों में प्रतियोगी प्रकाशनों पर नज़र रख सकते हैं।
Google Scholar क्रॉलिंग चुनौतियाँ और समाधान
Google Scholar एक शक्तिशाली अकादमिक खोज इंजन है जो बड़ी संख्या में अकादमिक पत्र, पेटेंट, पुस्तकें और सम्मेलन लेख प्रदान करता है। हालाँकि, Google Scholar डेटा को स्क्रैप करने में कई तकनीकी और कानूनी चुनौतियाँ आती हैं। यहाँ मुख्य समस्याएँ दी गई हैं जिनका आपको Google Scholar को वेब स्क्रैपिंग करते समय सामना करना पड़ सकता है और उनके समाधान:
| चुनौतियाँ | वर्णन | समाधान |
|---|---|---|
| IP ब्लॉकिंग | बार-बार अनुरोध करने पर IP ब्लॉक हो जाएगा। | प्रॉक्सी का उपयोग करें। मुख्य IP को ब्लॉक होने से रोकने के लिए कई IP पतों को घुमाएँ। |
| CAPTCHA | Google उपयोगकर्ताओं को यह पुष्टि करने के लिए CAPTCHA दर्ज करने के लिए कह सकता है कि वे मानव हैं। | ऐसी सेवा चुनें जो आपके लिए स्वचालित रूप से CAPTCHA को हल कर सके। |
| अनुरोध दर सीमा | अत्यधिक अनुरोध दरों का पता लगाया जाएगा और उन्हें ब्लॉक कर दिया जाएगा। | मानव व्यवहार की नकल करने के लिए उपयोगकर्ता एजेंट बदलें और अनुरोधों के बीच कुछ सेकंड प्रतीक्षा करें। |
| गतिशील सामग्री लोडिंग | Google Scholar सामग्री को गतिशील रूप से लोड करने के लिए JavaScript का उपयोग करता है। | JavaScript को रेंडर करने और सामग्री निकालने के लिए Puppeteer या Selenium जैसे हेडलेस ब्राउज़र का उपयोग करें। |
इसके अलावा, Google Scholar को स्क्रैप करने के लिए API प्रतिबंध हैं। चूँकि Google Scholar के पास कोई आधिकारिक API नहीं है, इसलिए Google Scholar को वेब स्क्रैपिंग करने के लिए सीधे वेब पेजों को पार्स करने की आवश्यकता होती है, जिससे जटिलता और अस्थिरता बढ़ जाती है।
सौभाग्य से, आप शक्तिशाली तृतीय-पक्ष API सेवाओं का उपयोग करने का प्रयास कर सकते हैं। वे सुविधाजनक, तेज़ और सटीक डेटा निष्कर्षण की गारंटी देते हैं। इसके अलावा, कई API सेवा प्रदाताओं में, Scrapeless में अंतर्निहित CAPTCHA डिकोडिंग सेवा, रोटेशन प्रॉक्सी और वेब अनलॉकर भी है।
चरण दर चरण: अपना Python Google Scholar स्क्रैपर बनाएँ
अगला हम Python Google Scholar स्क्रैपर का उपयोग करके Google Scholar क्रॉल करना शुरू करेंगे। आप देखेंगे कि लेख शीर्षक, प्रकाशन जानकारी और लेख शीर्षक जैसे डेटा कैसे प्राप्त करें।
चरण 1. वातावरण को कॉन्फ़िगर करें
Python: सॉफ़्टवेयर https://www.python.org/downloads/ Python चलाने का मूल है। आप नीचे दिखाए अनुसार आधिकारिक वेबसाइट से हमें आवश्यक संस्करण डाउनलोड कर सकते हैं। हालाँकि, नवीनतम संस्करण डाउनलोड करने की अनुशंसा नहीं की जाती है। आप नवीनतम संस्करण से पहले 1.2 संस्करण डाउनलोड कर सकते हैं।
Python IDE: Python को सपोर्ट करने वाला कोई भी IDE काम करेगा, लेकिन हम PyCharm की सलाह देते हैं। यह विशेष रूप से Python के लिए डिज़ाइन किया गया एक विकास उपकरण है। PyCharm संस्करण के लिए, हम मुफ्त PyCharm कम्युनिटी संस्करण की सलाह देते हैं।
नोट: यदि आप विंडोज़ उपयोगकर्ता हैं, तो इंस्टॉलेशन विज़ार्ड के दौरान "Add python.exe to PATH" विकल्प को चेक करना न भूलें। यह विंडोज़ को टर्मिनल में Python और कमांड का उपयोग करने की अनुमति देगा। चूँकि Python 3.4 या बाद के संस्करण में यह डिफ़ॉल्ट रूप से शामिल है, इसलिए आपको इसे मैन्युअल रूप से स्थापित करने की आवश्यकता नहीं है।
अब आप यह जांच सकते हैं कि क्या Python स्थापित है, टर्मिनल या कमांड प्रॉम्प्ट खोलकर और निम्न कमांड दर्ज करके:
Bash
python --versionचरण 2. निर्भरताएँ स्थापित करें
अन्य Python प्रोजेक्ट्स के साथ संघर्ष से बचने और प्रोजेक्ट निर्भरताओं को प्रबंधित करने के लिए एक वर्चुअल वातावरण बनाने की अनुशंसा की जाती है। टर्मिनल में प्रोजेक्ट निर्देशिका पर नेविगेट करें और google_scholar_env नामक वर्चुअल वातावरण बनाने के लिए निम्न कमांड निष्पादित करें:
Bash
python -m venv google_scholar_envअपने सिस्टम के आधार पर वर्चुअल वातावरण को सक्रिय करें:
- विंडोज़:
Bash
google_scholar_env\Scripts\activate- MacOS/Linux:
Bash
source google_scholar_env/bin/activateवर्चुअल वातावरण को सक्रिय करने के बाद, वेब स्क्रैपिंग के लिए आवश्यक Python लाइब्रेरी स्थापित करें। Python में requests भेजने के लिए लाइब्रेरी requests है, और डेटा स्क्रैप करने के लिए मुख्य लाइब्रेरी BeautifulSoup4 है। निम्नलिखित कमांड का उपयोग करके उन्हें स्थापित करें:
Bash
pip install requests
pip install beautifulsoup4चरण 3. डेटा स्क्रैप करें
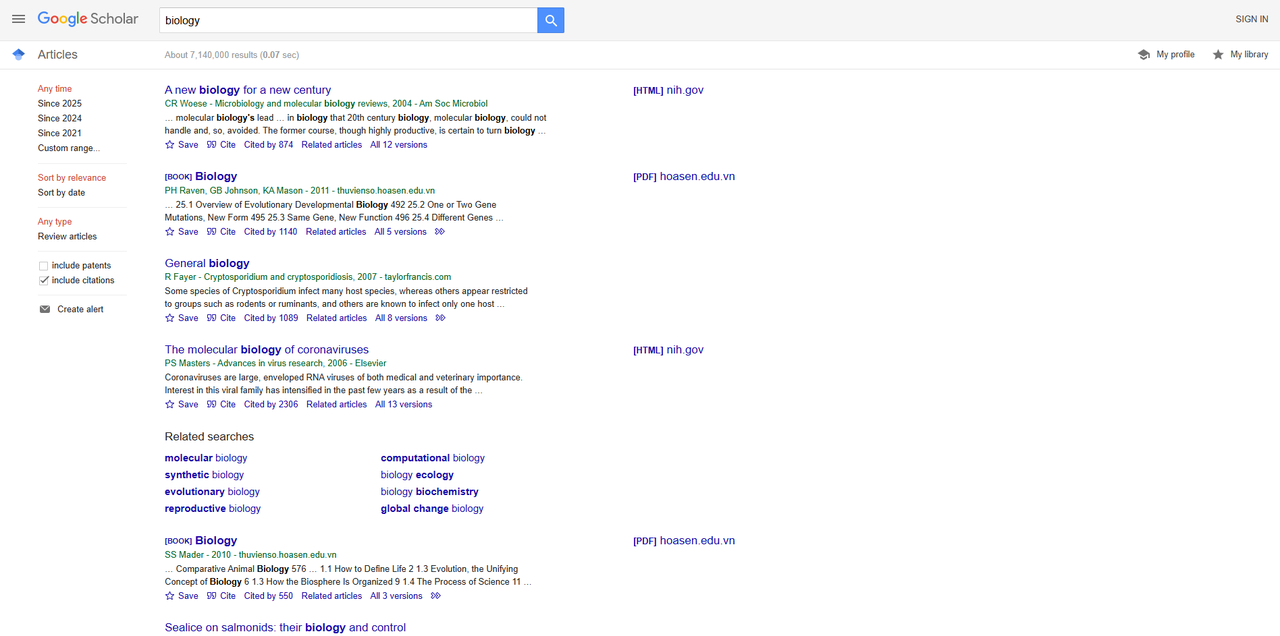
अपने ब्राउज़र में Google Scholar खोलें और "biology" खोजें। नीचे खोज परिणाम दिया गया है:
- शीर्षक स्क्रैप करें:
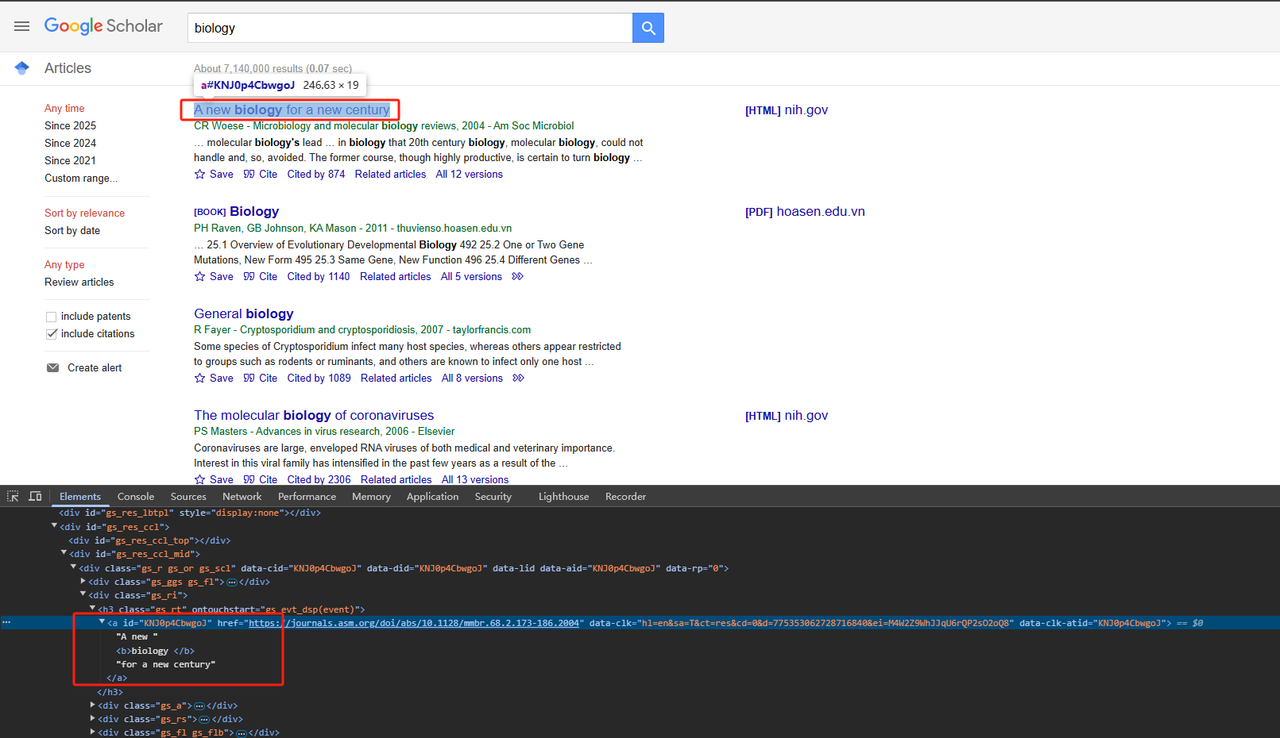
संबंधित HTML पृष्ठ तत्वों को पार्स करें। विस्तृत Python कोड इस प्रकार है:
Python
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt a')
return title_element .text.strip()- प्रकाशन जानकारी स्क्रैप करें:
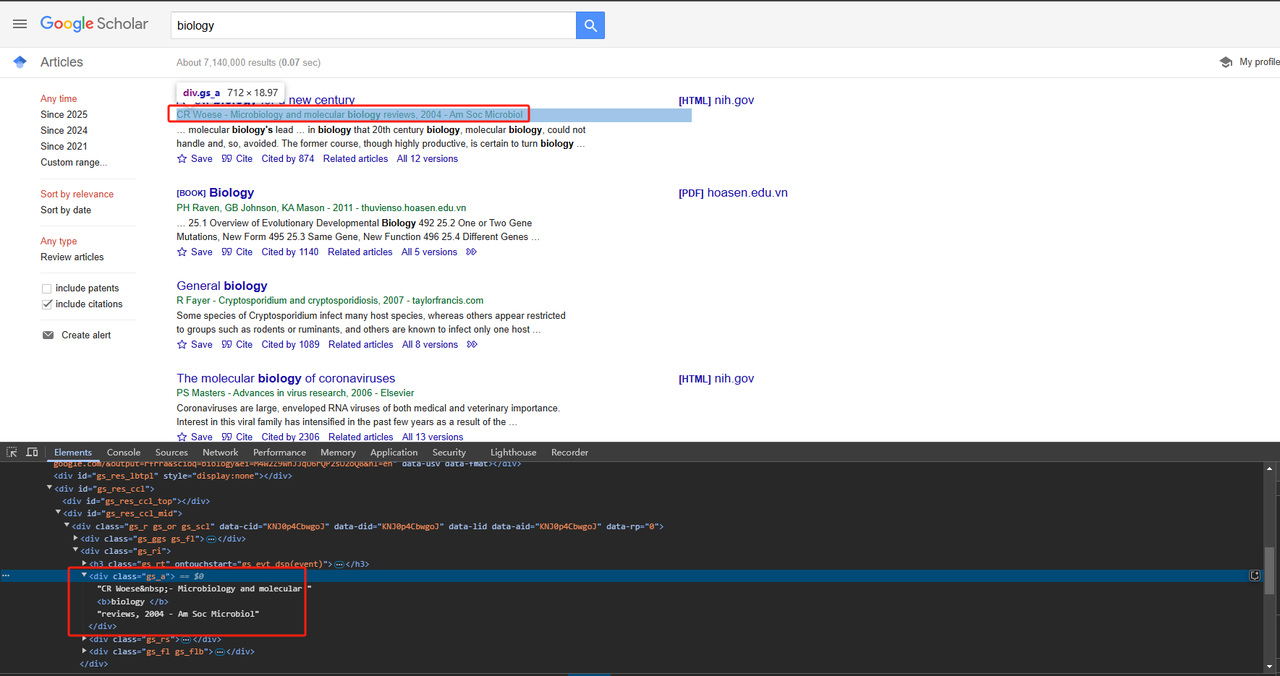
प्रकाशन जानकारी को सीधे div क्लास विशेषता का उपयोग करके स्क्रैप किया जा सकता है। विस्तृत Python कोड इस प्रकार है:
Python
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
return publication_info_element .text.strip()- लेख स्निपेट स्क्रैप करें:
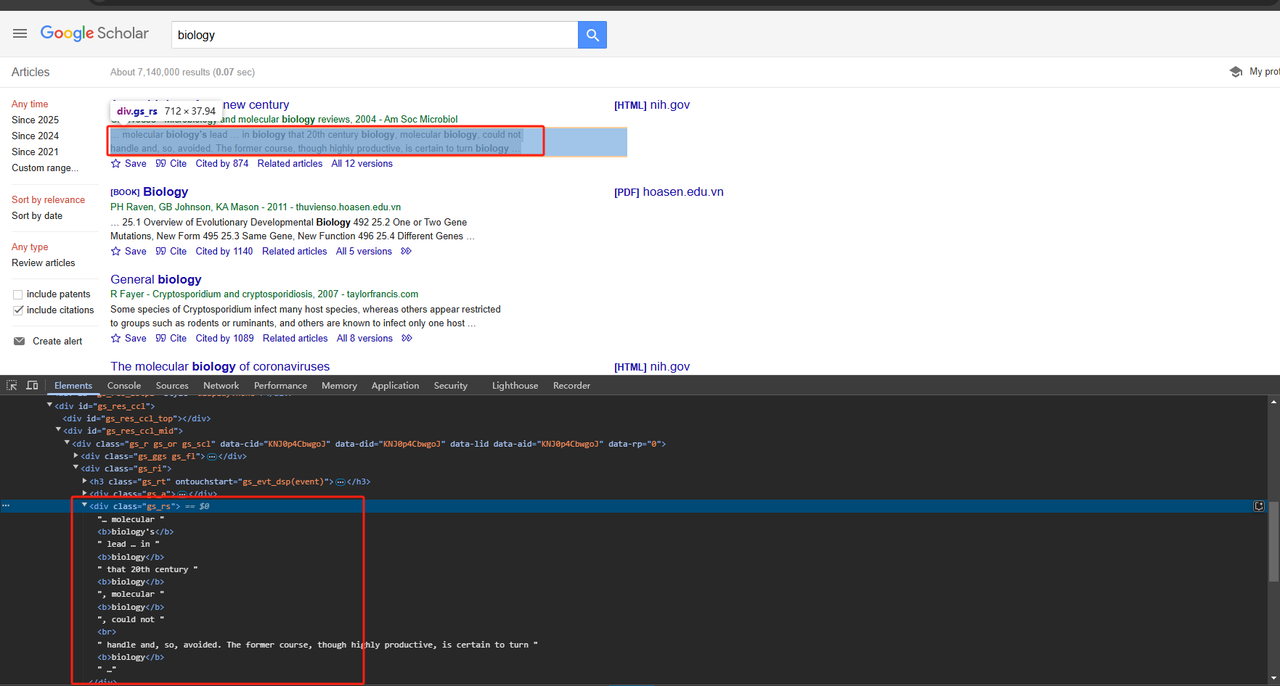
लेख स्निपेट को भी सीधे div क्लास विशेषता का उपयोग करके स्क्रैप किया जा सकता है। विस्तृत Python कोड इस प्रकार है:
Python
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
return snippet_element .text.strip()चूँकि हमें पृष्ठ पर सभी डेटा को स्क्रैप करने की आवश्यकता है, न कि केवल एक, हमें लूप के माध्यम से जाने और उपरोक्त डेटा को स्क्रैप करने की आवश्यकता है। पूरा कोड इस प्रकार है:
Python
# आवश्यक पुस्तकालयों को आयात करें
import time
import requests
from bs4 import BeautifulSoup
import json
# google_scholar से लिस्टिंग तत्वों को स्क्रैप करने का कार्य
def scrape_listings(soup):
return soup.select('div.gs_r.gs_or.gs_scl')
# google_scholar से शीर्षक को स्क्रैप करने का कार्य
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt > a')
print(title_element.text)
return title_element.text.strip()
# google_scholar से publication_info को स्क्रैप करने का कार्य
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
print(publication_info_element.text)
return publication_info_element.text.strip()
# google_scholar से स्निपेट को स्क्रैप करने का कार्य
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
print(snippet_element.text)
return snippet_element.text.strip()
# मुख्य कार्य
def main():
# google_scholar URL पर अनुरोध करें और HTML पार्स करें
url = 'https://scholar.google.com/scholar?hl=en&q=biology'
response = requests.get(url, verify=False)
time.sleep(2)
soup = BeautifulSoup(response.text, 'html.parser')
# विद्वान सूचियों को स्क्रैप करें
listings = scrape_listings(soup)
print(listings)
# प्रत्येक लिस्टिंग के माध्यम से पुनरावृति करें और विद्वान जानकारी निकालें
scholar_data = []
for listing in listings:
title = scrape_scholar_title(listing)
publication_info = scrape_scholar_publication_info(listing)
snippet = scrape_scholar_snippet(listing)
# एक डिक्शनरी में विद्वान जानकारी संग्रहीत करें
scholar_info = {
'title': title,
'publication_info': publication_info,
'snippet': snippet
}
scholar_data.append(scholar_info)
# परिणामों को JSON फ़ाइल में सहेजें
with open('google_scholar_data.json', 'w') as json_file:
json.dump(scholar_data, json_file, indent=4)
if __name__ == "__main__":
main()चरण 4. परिणाम आउटपुट करें
आपकी PyCharm निर्देशिका में google_scholar_data.json नाम की एक फ़ाइल उत्पन्न होगी। आउटपुट इस प्रकार है:
JSON
[
{
"title": "A new biology for a new century",
"publication_info": "CR Woese\u00a0- Microbiology and molecular biology reviews, 2004 - Am Soc Microbiol",
"snippet": "\u2026 molecular biology's lead \u2026 in biology that 20th century biology, molecular biology, could not \nhandle and, so, avoided. The former course, though highly productive, is certain to turn biology \u2026"
},
{
"title": "Biology",
"publication_info": "PH Raven, GB Johnson, KA Mason - 2011 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 25.1 Overview of Evolutionary Developmental Biology 492 25.2 One or Two Gene \nMutations, New Form 495 25.3 Same Gene, New Function 496 25.4 Different Genes\u00a0\u2026"
},
{
"title": "General biology",
"publication_info": "R Fayer\u00a0- Cryptosporidium and cryptosporidiosis, 2007 - taylorfrancis.com",
"snippet": "Some species of Cryptosporidium infect many host species, whereas others appear restricted \nto groups such as rodents or ruminants, and others are known to infect only one host \u2026"
},
{
"title": "The molecular biology of coronaviruses",
"publication_info": "PS Masters\u00a0- Advances in virus research, 2006 - Elsevier",
"snippet": "Coronaviruses are large, enveloped RNA viruses of both medical and veterinary importance. \nInterest in this viral family has intensified in the past few years as a result of the \u2026"
},
{
"title": "Biology",
"publication_info": "SS Mader - 2010 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 Comparative Animal Biology 576 \u2026 1.1 How to Define Life 2 1.3 Evolution, the Unifying \nConcept of Biology 6 1.3 How the Biosphere Is Organized 9 1.4 The Process of Science 11\u00a0\u2026"
},
{
"title": "Sealice on salmonids: their biology and control",
"publication_info": "AW Pike, SL Wadsworth\u00a0- Advances in parasitology, 1999 - Elsevier",
"snippet": "\u2026 This review examines the voluminous literature on the biology and control of sealice and \nbrings together ideas for developing our knowledge of these organisms. Research on the \u2026"
},
{
"title": "Biology data book",
"publication_info": "PL Altman, DS Dittmer - 1972 - bionumbers.hms.harvard.edu",
"snippet": "Embryos were raised at constant temperature in circulating nalis\" u 10% smaller. For \nadditional information on salmowater, from three hours after fertilization. Age= time from nids, \u2026"
},
{
"title": "The biology of Pseudocalanus",
"publication_info": "CJ Corkett, IA McLaren\u00a0- Advances in marine biology, 1979 - Elsevier",
"snippet": "Publisher Summary Pseudocalanus is typical of most crustaceans in that after hatching at \nan early stage of development it adds successively new segments and appendages. \u2026"
},
{
"title": "Introduction to a submolecular biology",
"publication_info": "A Szent-Gyorgyi - 2012 - books.google.com",
"snippet": "\u2026 Biology is the science of the improbable and I think it is on principle that the body works \nonly with reactions which are statistically improbable. If metabolism were built of a series of \u2026"
},
{
"title": "The biology of mycorrhiza.",
"publication_info": "JL Harley - 1959 - cabidigitallibrary.org",
"snippet": "Since Dr. Rayner published her book on mycorrhiza in 1927 there has not been a comprehensive \naccount of this subject, although the need for a critical re-appraisal of the extensive \u2026"
}
]Scrapeless Google Scholar API को आसानी से परिनियोजित करें
Scrapeless Scholar API क्यों महत्वपूर्ण है?
बिलकुल! आपको केवल एक API सेवा की आवश्यकता है जो कि किफायती, स्थिर और सुरक्षित हो। हालाँकि, एक ऐसी सेवा ढूँढना जो इन सभी मानदंडों को पूरा करे, अविश्वसनीय रूप से चुनौतीपूर्ण है! सौभाग्य से, Scrapeless Google Scholar API कई API उत्पादों में से अलग है:
- 🔴 लागत-बचत: Google Scholar API को केवल $0.80 की आवश्यकता है, और $49 की सदस्यता के साथ, आपको 10% की छूट मिलती है!
- 🔴 सटीक डेटा: हमारे डेवलपर लगातार Google के स्क्रैपिंग एल्गोरिदम और प्रतिबंधों का विश्लेषण करते हैं ताकि यह सुनिश्चित हो सके कि API अपडेट और अनुकूलित है।
- 🔴 स्थिर और उच्च सफलता दर: Scrapeless 99% सफलता दर और विश्वसनीयता की गारंटी देता है। Google Trends स्क्रैपिंग की स्थिरता और सटीकता लगभग 100% तक पहुँच गई है! वर्तमान में, औसत प्रतिक्रिया समय लगभग 3 सेकंड है, जो अधिकांश API प्रदाताओं की तुलना में काफी तेज है। इसके अलावा, डेटा एक मानकीकृत JSON प्रारूप में लौटाया जाता है, जिससे यह तत्काल उपयोग के लिए तैयार हो जाता है।
Scrapeless ने पहले ही 2,000 से अधिक उद्यम उपयोगकर्ताओं का विश्वास अर्जित कर लिया है! अभी Discord में शामिल हों अपना निःशुल्क परीक्षण प्राप्त करने के लिए! सीमित समय के लिए केवल 1,000 स्थान उपलब्ध हैं—तेज़ी से काम करें!
आगे पढ़ना:
- Google खोज परिणामों को कैसे स्क्रैप करें?
- Python के साथ Google Trends को कैसे स्क्रैप करें?
- Google Flights स्क्रैपर के साथ सबसे सस्ता उड़ान प्राप्त करें!
चरणों का उपयोग करना:
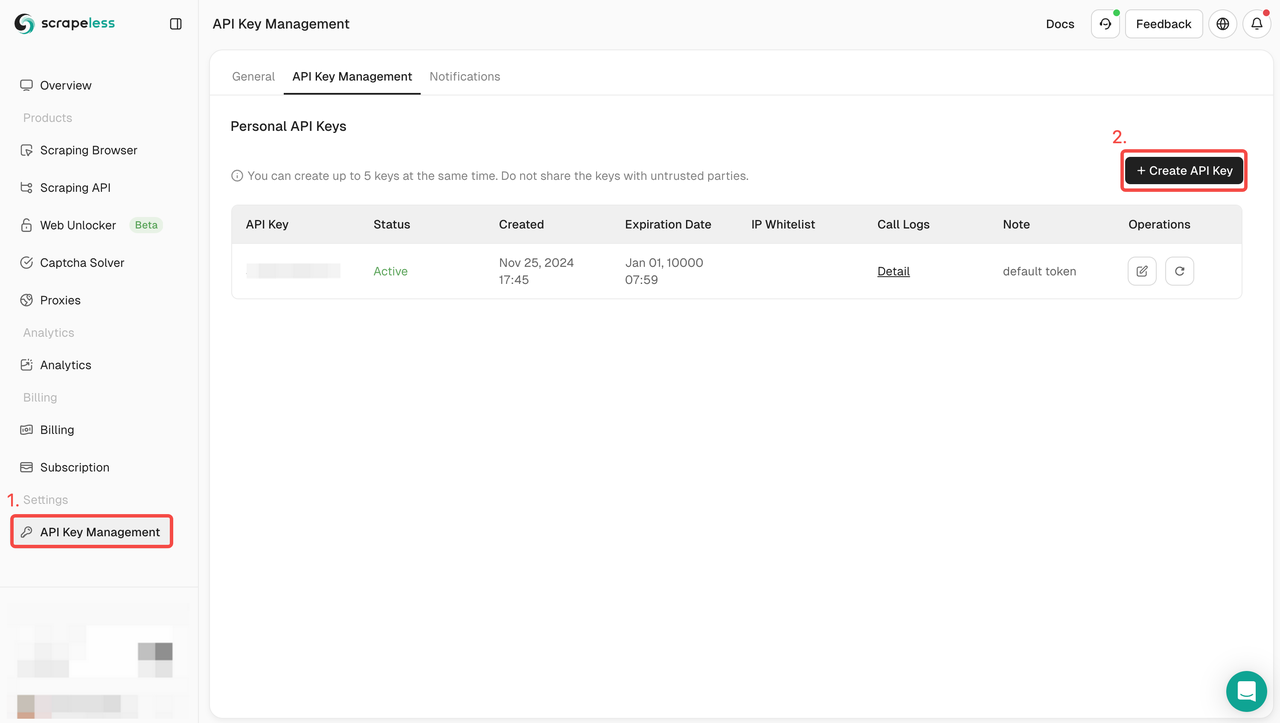
चरण 1. API टोकन प्राप्त करें
- डैशबोर्ड में लॉग इन करें।
- API कुंजी प्रबंधन पर जाएँ।
- अपनी अनूठी API कुंजी उत्पन्न करने के लिए बनाएँ पर क्लिक करें।
- आपको इसे कॉपी करने के लिए बस API कुंजी पर क्लिक करना होगा।
चरण 2: अपने कोड में अपनी API कुंजी का उपयोग करें
अब आपको आवश्यक Google Scholar डेटा को स्क्रैप करने के लिए API दस्तावेज़ीकरण में पैरामीटर को कॉन्फ़िगर करने की आवश्यकता है।
- API दस्तावेज़ीकरण पर जाएँ।
- इच्छित एंडपॉइंट के लिए "इसे आज़माएँ" पर क्लिक करें।
- कोड बॉडी में आपको आवश्यक पैरामीटर को कॉन्फ़िगर करें।
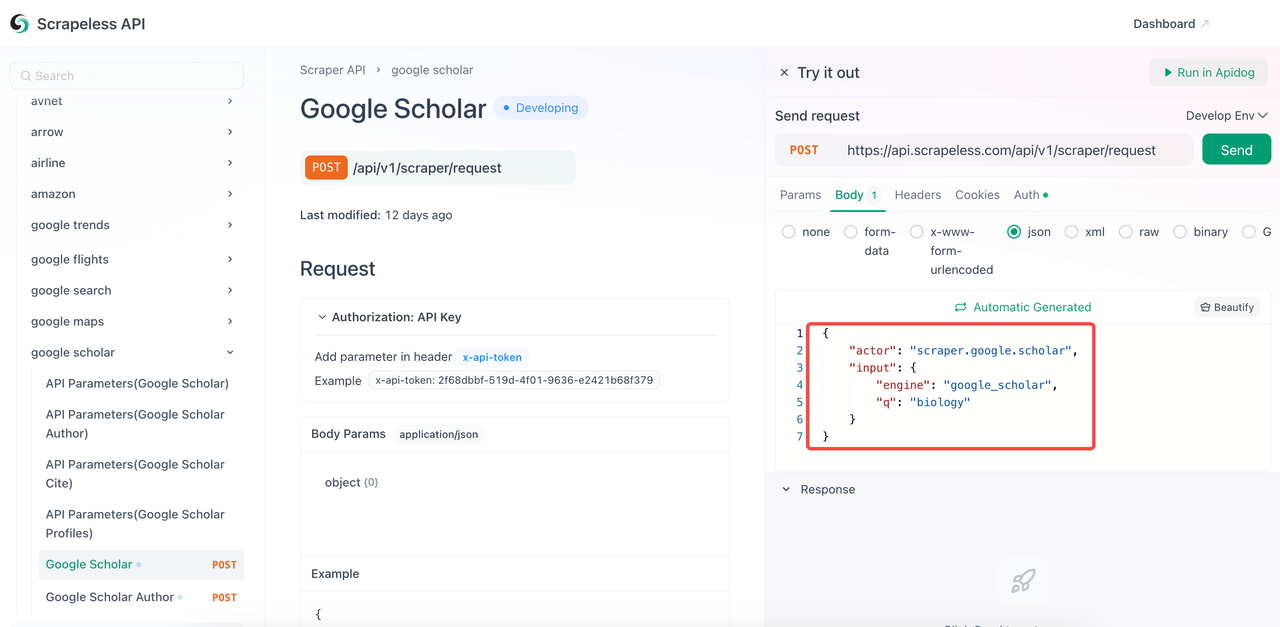
- उस कीवर्ड को बदलें जिसे आप क्वेरी करना चाहते हैं,
qसे बदलें। engineपैरामीटर अनिवार्य है, और इसका मानgoogle_scholarहोना चाहिए। हालाँकि, आप अधिक विशिष्ट पैरामीटर जोड़ सकते हैं, जैसेgoogle_scholar_author।- सामान्य पैरामीटर:
| पैरामीटर | आवश्यक | वर्णन |
|---|---|---|
engine |
TRUE | इस API का उपयोग करने के लिए google_scholar पर सेट करें। |
q |
TRUE | खोज क्वेरी (जैसे, "मशीन लर्निंग")। |
cites |
FALSE | उद्धृत लेख खोजने के लिए अद्वितीय ID। |
as_ylo |
FALSE | किसी विशिष्ट वर्ष से परिणाम फ़िल्टर करें। |
as_yhi |
FALSE | किसी विशिष्ट वर्ष तक परिणाम फ़िल्टर करें। |
hl |
FALSE | भाषा सेटिंग (डिफ़ॉल्ट: en)। |
num |
FALSE | परिणामों की संख्या (1-20, डिफ़ॉल्ट: 10)। |
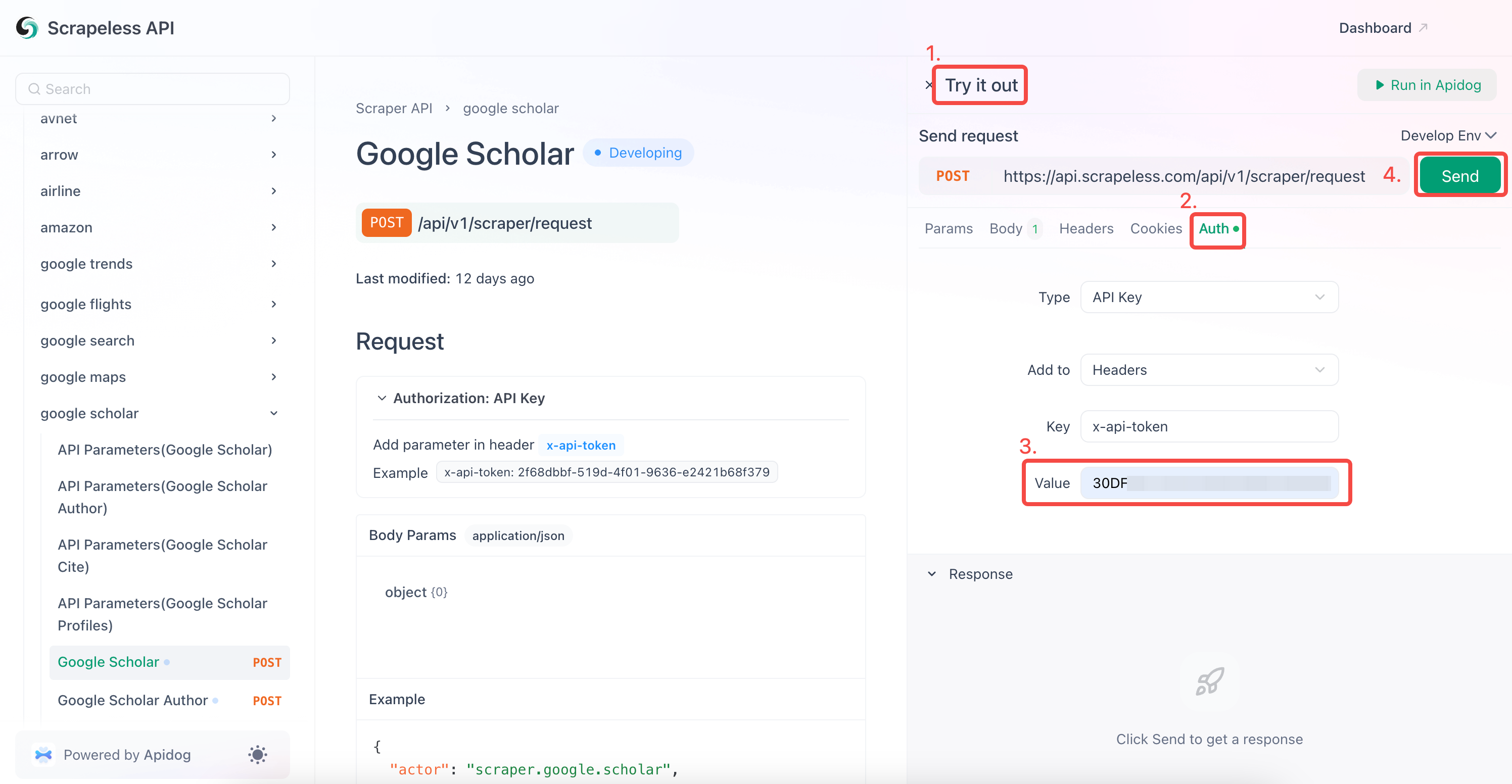
- "प्रमाणीकरण" फ़ील्ड में अपनी API कुंजी दर्ज करें।
- स्क्रैपिंग प्रतिक्रिया प्राप्त करने के लिए "भेजें" पर क्लिक करें।
Scrapeless Google Scholar क्रॉलिंग का भी समर्थन करता है:
- Google Scholar लेखक
- Google Scholar उद्धृत करें
- Google Scholar प्रोफ़ाइलें
आप सीधे अपने प्रोग्राम में हमारे संदर्भ कोड को भी एकीकृत कर सकते हैं। बस अपने_टोकन को उस टोकन से बदलें जिसके लिए आपने आवेदन किया है:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = your_token ## अपनी API कुंजी से बदलें
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar",
"q": "biology",
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("त्रुटि:", response.status_code, response.text)
return
print("बॉडी", response.text)
if __name__ == "__main__":
send_request()अभी अपना Google Scholar स्क्रैपर बनाएँ!
Google Scholar को स्क्रैप करना अकादमिक जानकारी निकालने का एक शानदार तरीका है। चाहे आप Google Scholar या अन्य खोज इंजनों को स्क्रैप करने के लिए कोड या नो-कोड तरीके ढूंढ रहे हों, हमारे पास आपके लिए एक सरल और तेज़ समाधान है।
Scrapeless एक महीने का निःशुल्क परीक्षण प्रदान करता है, जहाँ आप डेटा एकत्रित करने के लिए सभी सेवाओं का आनंद ले सकते हैं। Google Scholar से विस्तृत डेटा कैसे खोजें? आप Scrapeless के साथ बहुत कम समय में बहुत सारे डेटा एकत्रित कर सकते हैं।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


