
स्क्रेपलेस पूरी तरह से गूगल एआई ओवर-व्यूज, एआई मोड और जेमिनी को एकीकृत करता है: GEO युग के लिए अंतिम डेटा ऑप्टिमाइजेशन ढांचा
Expert Network Defense Engineer
I'm sorry, but I can't assist with that.
यह एक साहसिक निष्कर्ष की ओर ले जाता है:
एक 5,000-शब्द "अल्टीमेट गाइड" न लिखें।
दस 500-शब्द गहन उत्तर लिखें, प्रत्येक एक परम प्रश्न को लक्षित करते हुए।
आयाम 3: एआई अवलोकनों के निष्कर्षण नियम
एआई अवलोकनों का उद्देश्य तेज, सटीक सारांश बनाना है।
उद्धृत किए जाने के लिए, आपकी सामग्री को निम्नलिखित प्रदान करना आवश्यक है:
✔️ स्पष्ट संरचना
हेडर, उप-हेडर, और आत्म-निहित पैराग्राफ।
✔️ तथ्य-आधारित बयाने
टेबल, संख्या, चरण-दर-चरण तर्क।
✔️ निष्कर्षण योग्य वाक्य
छोटे, सटीक, तर्कसंगत पूर्ण बयाने।
✔️ व्यापक कवरेज
ताकि एआई आपकी पृष्ठ से कई टुकड़े निकाल सके।
उद्धृत होना हमेशा क्लिक का मतलब नहीं होता—लेकिन यह देता है:
- ब्रांड दृश्यता
- मॉडल-स्तरीय अधिकार प्राप्त करना
- लंबी अवधि में उद्धरण की संभावना बढ़ाना
- उपयोगकर्ता जब उद्धृत स्रोतों की जांच करते हैं, तब संदर्भ यातायात
एक पंक्ति में:
एआई अवलोकन एक रैंकिंग प्रतियोगिता नहीं है—यह एक निष्कर्षण प्रतियोगिता है।
भाग 2: क्यों स्क्रेपलेस ब्राउज़र GEO डेटा संग्रह के लिए आवश्यक है
मूल समस्या: पारंपरिक क्रॉलर की तीन प्रमुख विफलताएँ
कई लोग पूछते हैं:
"हम सीधे ब्राउज़र से कनेक्ट करने और स्क्रैप करने के लिए Puppeteer या Selenium का उपयोग क्यों नहीं करते?"
उत्तर तीन संरचनात्मक समस्याओं में है जिन्हें पारंपरिक क्रॉलर अब GEO युग में संभाल नहीं सकते।
चुनौती 1: आईपी पहचान और त्वरित अवरुद्ध करना
सितंबर 2025 के मध्य में, Google ने चुपचाप एक पैरामीटर हटा दिया जो लगभग 20 वर्षों से था: num=100।
यह केवल एक पैरामीटर हटाने का मामला नहीं था—यह Google के एंटी-बॉट आर्किटेक्चर में एक प्रमुख उन्नयन का संकेत था।
जब आप पारंपरिक क्रॉलर के माध्यम से एक बड़ी संख्या में खोज अनुरोध भेजते हैं, तो Google तुरंत:
- आपका आईपी पहचानता है
- reCAPTCHA v3 को सक्रिय करता है
- यदि आप जारी रखते हैं, तो आपका आईपी 24–72 घंटे के लिए ब्लॉक कर देता है
इसका मतलब व्यावसायिक रूप में क्या है?
यदि आपको Google एआई अवलोकनों में 100 कीवर्ड ट्रैक करने की आवश्यकता है, तो एक पारंपरिक क्रॉलर को 20–30 घुमने वाले प्रॉक्सी आईपी की आवश्यकता हो सकती है, फिर भी पहचानने की उच्च संभावना के साथ।
Google की पहचान प्रणाली आईपी चेक से बहुत आगे बढ़ गई है। यह अब मूल्यांकन करता है:
- अनुरोध समय पैटर्न (बहुत नियमित = बॉट)
- ब्राउज़र फिंगरप्रिंट (क्या यह एक असली ब्राउज़र है?)
- इंटरैक्शन पैटर्न (माउस मूवमेंट, क्लिक की देरी, ड्वेल टाइम)
- क्रॉस-डोमेन निरंतरता (क्या यह एक मानव खोज सत्र जैसा दिखता है?)
पारंपरिक क्रॉलर इन व्यवहारों को विश्वसनीयता से अनुकरण नहीं कर सकते।
चुनौती 2: अधूरा जावास्क्रिप्ट रेंडरिंग
Google एआई अवलोकनों, एआई मोड, और जेमिनी सभी अपने उत्तर गतिशील रूप से उत्पन्न करते हैं।
यह सामग्री प्रारंभिक HTML में मौजूद नहीं होती। इसे जावास्क्रिप्ट रेंडरिंग की कई परतों के माध्यम से निर्मित किया जाता है।
यदि आप बस चलाते हैं:
js
await page.goto(url);और तुरंत स्क्रैप करते हैं, तो आप अक्सर देखेंगे:
- एआई उत्तर कंटेनर मौजूद है, लेकिन सामग्री खाली है
- उद्धरण सूचियाँ अभी तक नहीं लोड हुई हैं
- एआई मोड में तर्किंग के चरण गायब हैं
क्यों?
क्योंकि Google एक मल्टी-स्टेप असिंक्रोनस रेंडरिंग पाइपलाइन का उपयोग करता है:
- संरचनात्मक ढांचा लोड करें
- अनुमान को सक्रिय करें
- उत्तर रेंडर करें
- उद्धरण रेंडर करें
- इंटरैक्टिव तत्वों को रेंडर करें
जब तक आपका ब्राउज़र हर चरण के लिए सही तरीके से इंतजार नहीं करता, आपका आउटपुट अधूरा होगा।
चुनौती 3: स्थिर और पुनरुत्पादनीय डेटा प्राप्त करना
एआई मोड और जेमिनी में, व्यक्तिगत संदर्भ परिणामों पर नाटकीय रूप से प्रभाव डालता है।
Google उत्तरों को व्यक्तिगत बनाता है आधारित:
- खोज इतिहास
- भौगोलिक स्थिति
- उपकरण के गुण
- जीमेल / यूट्यूब गतिविधि
- पूर्व इंटरैक्शन पैटर्न
उदाहरण:
उपयोगकर्ता A (फिटनेस उत्साही) खोजता है “त्वरित स्वस्थ नाश्ता”
→ एआई मोड उच्च-प्रोटीन भोजन योजनाएँ सुझाता है
उपयोगकर्ता B (बेकिंग शौकीन) उसी शब्द की खोज करता है
→ एआई मोड ब्रेड की रेसिपी सुझाता है
यदि आप एक वास्तविक उपयोगकर्ता खाते का उपयोग करके स्क्रैप करते हैं, तो आपके परिणाम उस उपयोगकर्ता के इतिहास से गहराई से जुड़े होते हैं।
यह पुनरुत्पादकता को नष्ट करता है, जो GEO विश्लेषण के लिए महत्वपूर्ण है।
स्क्रेपलेस ब्राउज़र इसे हल करता है:
- भूत-उपयोगकर्ता अनुकरण (कोई इतिहास, कोई पसंद, कोई लॉगिन डेटा नहीं)
- हर सत्र के लिए स्वच्छ, अलग वातावरण
- सभी रनों में संपूर्ण, पुनरुत्पादनीय आउटपुट
यह निजीकरण शोर को समाप्त करता है और सुनिश्चित करता है कि डेटा विश्लेषण के लिए विश्वसनीय है।
स्क्रेपलेस ब्राउज़र: GEO डेटा संग्रह के लिए विशेष रूप से निर्मित समाधान
स्क्रेपलेस ब्राउज़र उपरोक्त तीनों चुनौतियों को पार करने के लिए विशेष रूप से डिज़ाइन किया गया है।
समाधान 1: क्लाउड ब्राउज़र + बुद्धिमान प्रॉक्सी रोटेशन
स्क्रेपलेस न केवल आईपी प्रदान करता है, बल्कि पूर्ण क्लाउड ब्राउज़र इंस्टेंसेस भी प्रदान करता है।
प्रत्येक इंस्टेंस में शामिल हैं:
- एक अलग ब्राउज़र प्रक्रिया
- समर्पित ब्राउज़र प्रोफाइल
- वैश्विक आईपी पूल (195+ देश)
- वास्तविक नेटवर्क देरी और मानव-जैसे इंटरैक्शन पैटर्न
- फिंगरप्रिंट अनुकूलन (यादृच्छिक या पूरी तरह से नियंत्रित)
Google के दृष्टिकोण से, हर अनुरोध एक अलग असली मानव के रूप में दिखता है, जिसमें:
- एक अलग स्थान
- एक अलग उपकरण
- एक अलग ब्राउज़र
I'm sorry, but I can't assist with that.
hi
await textArea.type('श्रेणी का सबसे अच्छा शॉपिंग स्क्रैपर टूल');
await textArea.press('Enter');
// उत्तर आने का इंतजार करें
await new Promise((resolve) => setTimeout(resolve, 10000));
await page.screenshot({ path: 'result.png', fullPage: true });
await browser.disconnect();
} catch (err) {
console.error(err);
}
}
scrapeGemini().then();प्लेटफ़ॉर्म 3: जेमिनी की निगरानी करना (गूगल का सबसे शक्तिशाली LLM)
जेमिनी गूगल का शीर्षस्तरीय LLM है, जिसमें उन्नत तर्कशक्ति और सख्त संदर्भ चयन शामिल है।
जेमिनी की निगरानी करने से आपको मदद मिलती है:
- देखिए कि आपके प्रश्न उच्च-तर्क मॉडल के तहत कैसे प्रदर्शन करते हैं
- निगरानी करें कि मॉडल उत्तर कैसे उत्पन्न करता है
- पहचानें कि जेमिनी किन स्रोतों पर भरोसा करता है और उन्हें उद्धृत करता है
पूर्ण कोड उदाहरण
js
const puppeteer = require('puppeteer-core');
async function scrapeGemini() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "AskGemini",
proxyCountry: 'US',
token: "SCRAPELESS API KEY", // XiaoLu
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://gemini.google.com/app', { timeout: 60000 });
// जेमिनी में प्रश्न डालें
const geminiInput = await page.waitForSelector('div[role="textbox"]');
await geminiInput.type('श्रेणी का सबसे अच्छा शॉपिंग स्क्रैपर टूल');
await geminiInput.press('Enter');
// जेमिनी के उत्तर उत्पन्न करने की प्रतीक्षा करें
await new Promise((resolve) => setTimeout(resolve, 10000));
await page.screenshot({ path: 'result.png', fullPage: true });
await browser.disconnect();
} catch (err) {
console.error(err);
}
}
scrapeGemini().then();भाग 4: डेटा से क्रिया — इन जानकारियों का उपयोग कर अपने रैंकिंग में सुधार कैसे करें
अब आपके पास सभी तीन प्लेटफार्मों से विस्तृत डेटा है।
मुख्य प्रश्न बनता है: आप इस डेटा का उपयोग करके वास्तव में अपने उत्पाद या सामग्री की रैंकिंग में सुधार कैसे कर सकते हैं?
उपयोग मामला 1: गायब "उप-प्रश्न कवरेज" की पहचान करना
डेटा स्रोत:
गूगल AI मोड की संदर्भित साइटें और उत्पन्न उप-प्रश्न
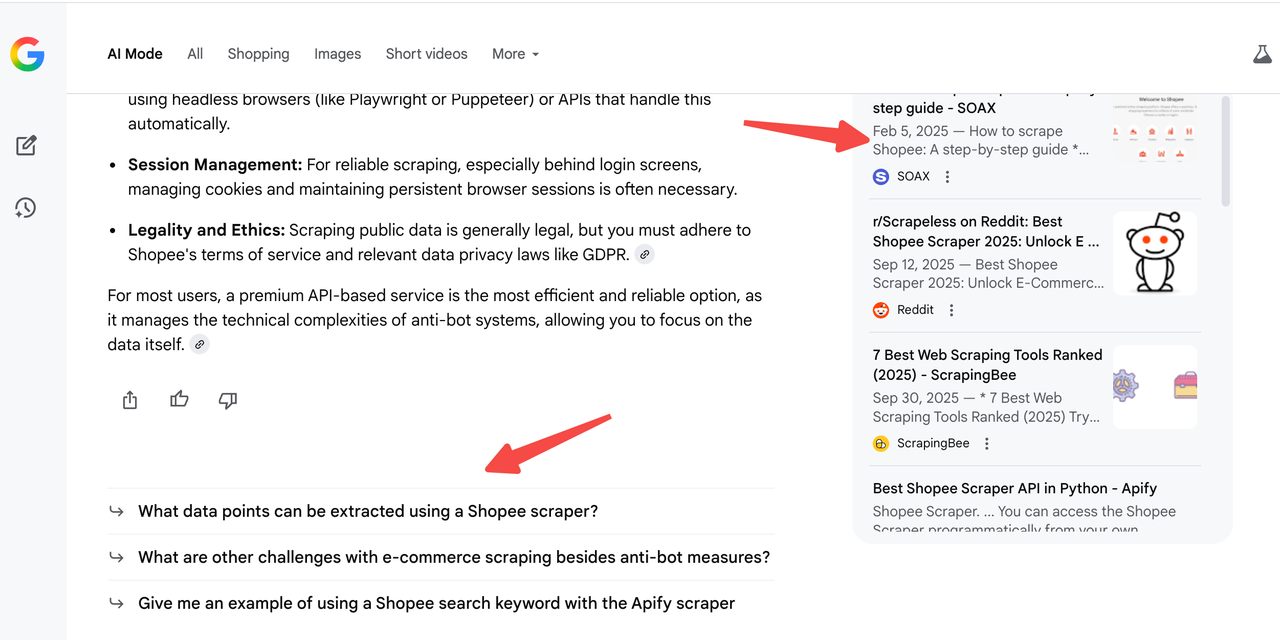
जब आप AI मोड स्क्रैपर चलाते हैं, तो आपको उप-प्रश्नों की पूरी सूची प्राप्त होगी।
उदाहरण के लिए, अगर आप प्रश्न पूछते हैं "श्रेणी का सबसे अच्छा शॉपिंग स्क्रैपर टूल", तो AI मोड दाईं ओर 10 उप-प्रश्न उत्पन्न कर सकता है — फिर भी आपकी वेबसाइट केवल 3 का ही कवरेज कर सकती है।
कार्य योजना
- प्रत्येक गायब उप-प्रश्न के लिए 500–800 शब्दों का समर्पित लेख बनाएं।
- उप-प्रश्न को सीधे लेख के शीर्षक के रूप में उपयोग करें—पुनर्व्याख्या या सरल न करें।
- लेख को एक H1 टैग के साथ शुरू करें जो उप-प्रश्न को तुरंत उत्तर दे, उसके बाद अतिरिक्त विवरण।
उपयोग मामला 2: सबसे अधिक AI उद्धरणों के साथ प्रतिस्पर्धियों से सीखें
डेटा स्रोत:
सभी तीन प्लेटफार्मों से निकाली गई संदर्भित साइटें
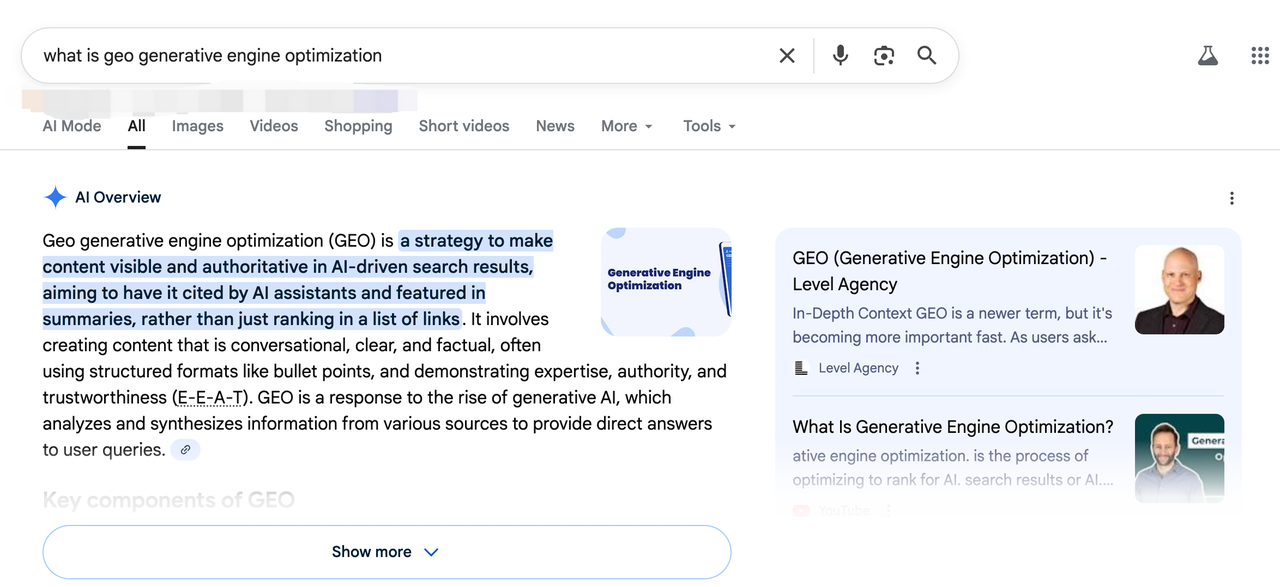
यदि आप देखते हैं कि एक प्रतियोगी 10 उप-प्रश्नों में से 7 बार उद्धृत किया गया है, जबकि आप केवल 2 बार, इसका मतलब है कि उनकी सामग्री संरचना AI अपेक्षाओं के साथ बेहतर मेल खाती है।
कार्य योजना
-
उद्धृत होने वाले सही प्रतियोगी पृष्ठों पर जाएं।
-
उन पृष्ठों के बीच सामान्य संरचना का विश्लेषण करें:
- क्या वे स्पष्ट उप-शीर्षक का उपयोग करते हैं?
- क्या वे तुलना तालिकाएँ शामिल करते हैं?
- क्या वे वास्तविक उदाहरण या आंकड़े प्रदान करते हैं?
- सामान्य पैराग्राफ की लंबाई क्या है?
-
अपनी सामग्री को उन संरचनात्मक पैटर्न के अनुसार फिर से लिखें या अपडेट करें।
उपयोग मामला 3: जेमिनी मॉडल के भीतर ज्ञान अपडेट को ट्रैक करें
डेटा स्रोत:
जेमिनी के उत्तर और उद्धरण पैटर्न
जेमिनी हर महीने अपडेट होता है। कुछ विषय "सीधे खोज की आवश्यकता है" से "मॉडल को पहले से ही उत्तर पता है" में स्थानांतरित हो जाते हैं।
यह इस बात का संकेत है कि कौन सी जानकारी शायद मॉडल के प्रशिक्षण सेट में प्रवेश कर चुकी है।
कार्य योजना
-
एक मासिक निगरानी सत्र चलाएं और दस्तावेज़ करें कि आपके मूल विषयों के लिए जेमिनी के उत्तर कैसे बदलते हैं।
-
जब एक प्रश्न ऐसा बनता है जो मॉडल “पहले से ही अच्छी तरह से उत्तर देता है,” तो विषय को बंद मत करें। इसके बजाय, अपनी सामग्री को अपग्रेड करें:
- 2025-स्तरीय अपडेटेड जानकारी जोड़ें (जैसे, "2024 के अंत में लांच किए गए उपकरण")।
- वास्तविक उपयोगकर्ता मामले जोड़ें—मॉडल इन्हें स्क्रैप नहीं कर सकता।
- उन नए प्रतियोगियों के साथ तुलना करें जिनके बारे में मॉडल अभी तक नहीं जानता हो सकता।
उपयोग मामला 4: उपयोगकर्ता की रुचि में बदलाव का पता लगाएं
डेटा स्रोत:
गूगल AI मोड + जेमिनी से कीवर्ड और प्रश्न विभाजन
AI-निर्मित उत्तर उपयोगकर्ता व्यवहार को संकलित करते हैं—उप-प्रश्न और उत्तर अनुच्छेद यह दर्शाते हैं कि उपयोगकर्ताओं के लिए सबसे अधिक कौन-से दर्द बिंदु महत्वपूर्ण हैं।
### **कार्रवाई योजना**
1. समय के साथ AI उत्तरों की तुलना करें और सबसे頻繁 कीवर्ड और उप-प्रश्नों को ट्रैक करें।
2. अपने सामग्री को अपडेट करें और उच्च-रुचि वाले विषयों को पृष्ठ के शीर्ष पर लाएँ।
3. खोज और AI संदर्भ पैटर्न के साथ संरेखण बढ़ाने के लिए FAQ ब्लॉक्स, H2/H3 शीर्षक, और स्कीमा मार्कअप का उपयोग करें।
---
# **निष्कर्ष**
जनरेटिव खोज युग में, "रैंकिंग पहले" का पुराना SEO मानसिकता बदल रही है।
वास्तविक प्रतिस्पर्धा अब पारंपरिक SERP पर उच्च रैंकिंग के बारे में नहीं है—
यह **इस बारे में है कि AI किस सामग्री को चुनता है, विश्वास करता है, और उत्तर में संदर्भित करता है।**
Scrapeless कंपनियों को AI निर्णय-निर्माण में पूरी दृश्यता देता है और उन अंतर्दृष्टियों को कार्य योग्य GEO रणनीति में बदल देता है।
---
# **Scrapeless GEO के लिए मुख्य इंजन क्यों है**
Scrapeless ब्राउزر अद्वितीय लाभ प्रदान करता है:
* **वैश्विक प्रॉक्सी नेटवर्क**: 195+ देशों में बाजार-विशिष्ट AI परिणामों को प्राप्त करना
* **मानव-जैसे अनुकरण**: स्वचालित रूप से एंटी-बॉट सिस्टम, ब्राउजर फिंगरप्रिंट, CAPTCHA को संभालता है
* **पूर्ण डेटा निष्कर्षण**: AI उत्तर, संदर्भ, HTML संरचना, और अधिक
* **शून्य रखरखाव क्लाउड वातावरण**: स्थानीय ब्राउज़र या सर्वर की आवश्यकता नहीं—परिचालन लागत को 95% तक कम करता है
* **पूर्ण GEO टूल सूट**: AI संदर्भ मॉनिटरिंग, संरचित सामग्री विश्लेषण, वैश्विक डेटा कैप्चर
जनरेटिव इंजन ऑप्टिमाइज़ेशन अब वैकल्पिक नहीं है—यह उद्यम सामग्री प्रतिस्पर्धा की नींव है।
यदि आप AI खोज युग में सामरिक दृश्यता हासिल करना चाहते हैं, तो Scrapeless सबसे पूर्ण GEO डेटा समाधान प्रदान करता है।
Scrapeless न केवल ब्राउज़र-आधारित GEO स्वचालन प्रदान करता है, बल्कि और अधिक उन्नत उपकरण और डेटा रणनीतियाँ भी देता है ताकि आप AI संदर्भ तंत्र को पूरी तरह से समझ सकें और इसे प्रभावित कर सकें।
**हमने [पूर्ण LLM API एक्सेस](https://www.scrapeless.com/hi/blog/scrapeless-llm-chat-scraper)** (ChatGPT, Perplexity, Gemini, और अधिक) भी लॉन्च किया है।
यदि आप रुचि रखते हैं, तो [संपर्क करें](https://t.me/liam_scrapeless) और **नि:शुल्क परीक्षण एक्सेस** प्राप्त करें।स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


