
Scrapeless का उपयोग करके Cloudflare सुरक्षा और टर्नस्टाइल को कैसे बाईपास करें | संपूर्ण मार्गदर्शिका
Advanced Data Extraction Specialist
परिचय
क्लाउडफ्लेयर सुरक्षा और क्लाउडफ्लेयर टर्नस्टाइल जैसे उन्नत सुरक्षा तंत्रों के कारण वेब स्क्रैपिंग तेजी से कठिन होती जा रही है। इन चुनौतियों को स्वचालित पहुँच को अवरुद्ध करने और बॉट्स के लिए डेटा प्राप्त करना मुश्किल बनाने के लिए डिज़ाइन किया गया है। हालाँकि, स्क्रैपलेस स्क्रैपिंग ब्राउज़र के साथ, आप इन प्रतिबंधों को कुशलतापूर्वक दरकिनार कर सकते हैं और बिना किसी रुकावट के स्क्रैपिंग जारी रख सकते हैं।
इस गाइड में, हम क्लाउडफ्लेयर चुनौतियों को दरकिनार करने के तीन प्रमुख पहलुओं को शामिल करेंगे:
- स्क्रैपलेस ब्राउज़र का उपयोग करके क्लाउडफ्लेयर सुरक्षा को कैसे दरकिनार करें – सीखें कि CAPTCHA और बॉट डिटेक्शन जैसे सुरक्षा उपायों को कैसे दरकिनार किया जाए।
- cf_clearance कुकी और अनुरोध हेडर को कैसे प्राप्त करें और उपयोग करें – समझें कि सत्र स्थिरता बनाए रखने के लिए cf_clearance कुकीज़ को कैसे निकाला और उपयोग किया जाए।
- स्क्रैपलेस ब्राउज़र का उपयोग करके क्लाउडफ्लेयर टर्नस्टाइल को कैसे दरकिनार करें – पता करें कि टर्नस्टाइल चुनौती को कैसे दरकिनार किया जाए और अपने स्क्रैपिंग कार्यों को स्वचालित करें।
इस ट्यूटोरियल के अंत तक, आपके पास क्लाउडफ्लेयर सुरक्षा को प्रभावी ढंग से संभालने के लिए एक पूरी रणनीति होगी। आइए शुरू करते हैं!
भाग 1: स्क्रैपलेस का उपयोग करके क्लाउडफ्लेयर सुरक्षा को कैसे दरकिनार करें
यह गाइड आपको दिखाएगा कि वेबसाइटों पर क्लाउडफ्लेयर सुरक्षा को दरकिनार करने के लिए स्क्रैपलेस और पुपेटियर-कोर का उपयोग कैसे करें।
चरण 1: तैयारी
1.1 एक प्रोजेक्ट फ़ोल्डर बनाएँ
-
प्रोजेक्ट के लिए एक नया फ़ोल्डर बनाएँ, जैसे, scrapeless-bypass।
-
अपने टर्मिनल में फ़ोल्डर पर जाएँ:
cd path/to/scrapeless-bypass1.2 एक Node.js प्रोजेक्ट इनिशियलाइज़ करें
package.json फ़ाइल बनाने के लिए निम्न कमांड चलाएँ:
npm init -y1.3 आवश्यक निर्भरताएँ स्थापित करें
पुपेटियर-कोर स्थापित करें, जो ब्राउज़र इंस्टेंस से दूरस्थ कनेक्शन की अनुमति देता है:
npm install puppeteer-coreयदि पुपेटियर पहले से ही आपके सिस्टम पर स्थापित नहीं है, तो पूर्ण संस्करण स्थापित करें:
npm install puppeteer puppeteer-coreचरण 2: स्क्रैपलेस API कुंजी प्राप्त करें
2.1 स्क्रैपलेस पर रजिस्टर करें
-
स्क्रैपलेस पर जाएँ और एक खाता बनाएँ।
-
API कुंजी प्रबंधन अनुभाग पर जाएँ।
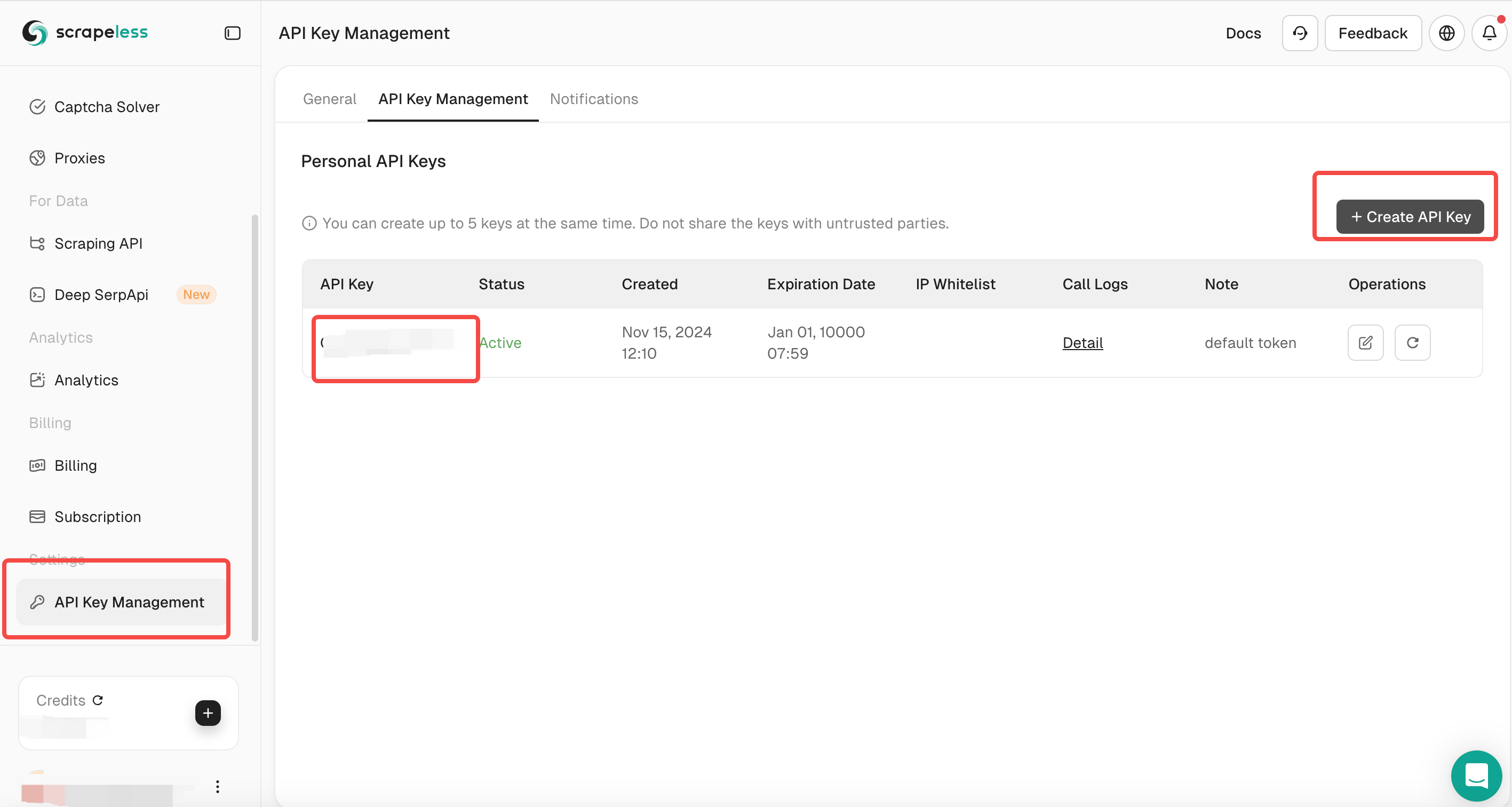
- एक नई API कुंजी उत्पन्न करें और उसे कॉपी करें।
🚀 क्लाउडफ्लेयर सुरक्षा को दरकिनार करने में गहराई से उतरने के लिए तैयार हैं?
👉 उन्नत सुविधाओं और ट्यूटोरियल तक पहुँचने के लिए अभी लॉग इन करें!
🔒 अतिरिक्त सहायता की आवश्यकता है? वास्तविक समय समर्थन और अपडेट के लिए हमारे डिस्कोर्ड समुदाय में शामिल हों!
📈 आज ही स्क्रैपलेस ब्राउज़र के साथ स्मार्ट स्क्रैपिंग शुरू करें!"
चरण 3: स्क्रैपलेस ब्राउज़रलेस से कनेक्ट करें
3.1 वेबसोकेट कनेक्शन URL प्राप्त करें
स्क्रैपलेस पुपेटियर के साथ क्लाउड-आधारित ब्राउज़र के साथ इंटरैक्ट करने के लिए एक वेबसोकेट कनेक्शन URL प्रदान करता है।
प्रारूप है:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYAPIKey को अपनी वास्तविक स्क्रैपलेस API कुंजी से बदलें।
3.2 कनेक्शन पैरामीटर सेट करें
-
टोकन: आपकी स्क्रैपलेस API कुंजी
-
session_ttl: सेकंड में ब्राउज़र सत्र की अवधि (जैसे, 180 सेकंड)
-
proxy_country: प्रॉक्सी सर्वर के लिए देश कोड (जैसे, यूके के लिए GB, यूएसए के लिए US)
चरण 4: पुपेटियर स्क्रिप्ट लिखें
4.1 स्क्रिप्ट फ़ाइल बनाएँ
अपने प्रोजेक्ट फ़ोल्डर के अंदर, bypass-cloudflare.js नाम की एक नई जावास्क्रिप्ट फ़ाइल बनाएँ।
4.2 स्क्रैपलेस से कनेक्ट करें और पुपेटियर लॉन्च करें
bypass-cloudflare.js में निम्न कोड जोड़ें:
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // अपनी वास्तविक API कुंजी से बदलें
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // सेकंड में ब्राउज़र सत्र की अवधि
proxy_country: 'GB', // प्रॉक्सी देश कोड
proxy_session_id: 'test_session', // प्रॉक्सी सत्र ID (एक ही IP रखता है)
proxy_session_duration: '5' // मिनटों में प्रॉक्सी सत्र की अवधि
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('स्क्रैपलेस से कनेक्टेड');4.3 एक वेब पेज खोलें और क्लाउडफ्लेयर को दरकिनार करें
क्लाउडफ्लेयर-सुरक्षित वेबसाइट पर एक नया पेज खोलने और नेविगेट करने के लिए स्क्रिप्ट का विस्तार करें:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });4.4 पेज तत्वों के लोड होने की प्रतीक्षा करें
आगे बढ़ने से पहले यह सुनिश्चित करें कि क्लाउडफ्लेयर सुरक्षा को दरकिनार कर दिया गया है:
await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // आवश्यकतानुसार चयनकर्ता समायोजित करें4.5 एक स्क्रीनशॉट कैप्चर करें
क्लाउडफ्लेयर सुरक्षा के सफल बाईपास को सत्यापित करने के लिए, पृष्ठ का स्क्रीनशॉट लें:
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('स्क्रीनशॉट challenge-bypass.png के रूप में सहेजा गया');4.6 पूर्ण स्क्रिप्ट
यहाँ पूरी स्क्रिप्ट दी गई है:
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // अपनी वास्तविक API कुंजी से बदलें
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = `${host}/browser?${query}`;
(async () => {
try {
// स्क्रैपलेस से कनेक्ट करें
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('स्क्रैपलेस से कनेक्टेड');
// एक नया पेज खोलें और लक्षित वेबसाइट पर नेविगेट करें
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// पेज के पूरी तरह से लोड होने की प्रतीक्षा करें
await page.waitForTimeout(5000); // यदि आवश्यक हो तो देरी समायोजित करें
await page.waitForSelector('main.page-content', { timeout: 30000 });
// एक स्क्रीनशॉट कैप्चर करें
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('स्क्रीनशॉट challenge-bypass.png के रूप में सहेजा गया');
// ब्राउज़र बंद करें
await browser.close();
console.log('ब्राउज़र बंद हो गया');
} catch (error) {
console.error('त्रुटि:', error);
}
})();चरण 5: स्क्रिप्ट चलाएँ
5.1 स्क्रिप्ट सहेजें
सुनिश्चित करें कि स्क्रिप्ट bypass-cloudflare.js के रूप में सहेजी गई है।
5.2 स्क्रिप्ट निष्पादित करें
Node.js का उपयोग करके स्क्रिप्ट चलाएँ:
node bypass-cloudflare.js5.3 अपेक्षित आउटपुट
यदि सब कुछ सही ढंग से सेट अप है, तो टर्मिनल प्रदर्शित करेगा:
स्क्रैपलेस से कनेक्टेड
स्क्रीनशॉट challenge-bypass.png के रूप में सहेजा गया
ब्राउज़र बंद हो गयाchallenge-bypass.png फ़ाइल आपके प्रोजेक्ट फ़ोल्डर में दिखाई देगी, यह पुष्टि करते हुए कि क्लाउडफ्लेयर सुरक्षा को सफलतापूर्वक दरकिनार कर दिया गया है।
🌟 आसानी से क्लाउडफ्लेयर सुरक्षा को दरकिनार करना चाहते हैं?
🔑 यहाँ लॉग इन करें और आज ही स्क्रैपलेस ब्राउज़र के शक्तिशाली उपकरणों का लाभ उठाना शुरू करें!
🚀 विशेषज्ञ मार्गदर्शन की आवश्यकता है? विशेष सुझावों और समस्या निवारण सहायता के लिए हमारे डिस्कोर्ड समुदाय में शामिल हों!
💡 स्क्रैपलेस ब्राउज़र के साथ वेब स्क्रैपिंग में आगे बढ़ें- सुरक्षित, तेज़ और विश्वसनीय!"
चरण 6: अतिरिक्त विचार
6.1 API कुंजी उपयोग
-
सुनिश्चित करें कि आपकी API कुंजी मान्य है और उसने अपनी अनुरोध कोटा पार नहीं की है।
-
सार्वजनिक रिपॉजिटरी (जैसे, GitHub) में अपनी API कुंजी को कभी भी उजागर न करें। सुरक्षा के लिए पर्यावरण चर का उपयोग करें।
6.2 प्रॉक्सी सेटिंग्स
-
एक अलग स्थान का चयन करने के लिए proxy_country पैरामीटर को समायोजित करें (जैसे, यूएसए के लिए US, जर्मनी के लिए DE)।
-
अनुरोधों में एक ही IP पते को बनाए रखने के लिए एक सुसंगत proxy_session_id का उपयोग करें।
6.3 पेज चयनकर्ता
-
लक्षित वेबसाइटों की संरचना भिन्न हो सकती है, जिसके लिए waitForSelector() को समायोजित करने की आवश्यकता होती है।
-
पृष्ठ संरचना का निरीक्षण करने और चयनकर्ताओं को तदनुसार अद्यतन करने के लिए page.evaluate() का उपयोग करें।
इस गाइड ने क्लाउडफ्लेयर सुरक्षा को दरकिनार करने के लिए स्क्रैपलेस और पुपेटियर-कोर का उपयोग करने की एक चरण-दर-चरण विधि प्रदान की है। वेबसोकेट कनेक्शन, प्रॉक्सी सेटिंग्स और तत्व निगरानी का लाभ उठाकर, आप क्लाउडफ्लेयर द्वारा अवरुद्ध किए बिना वेब स्क्रैपिंग को कुशलतापूर्वक स्वचालित कर सकते हैं।
भाग 2: cf_clearance कुकी और अनुरोध हेडर को कैसे प्राप्त करें और उपयोग करें
क्लाउडफ्लेयर चुनौती को सफलतापूर्वक दरकिनार करने के बाद, आप सफल पृष्ठ प्रतिक्रिया से अनुरोध हेडर और cf_clearance कुकी प्राप्त कर सकते हैं। सत्र स्थिरता बनाए रखने और बार-बार होने वाली चुनौतियों से बचने के लिए ये तत्व महत्वपूर्ण हैं।
1. cf_clearance कुकी प्राप्त करें
const cookies = await browser.cookies();
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.value;उद्देश्य:
-
यह कोड सभी कुकीज़ को पुनः प्राप्त करता है, जिसमें cf_clearance भी शामिल है, जो क्लाउडफ्लेयर द्वारा इसकी सुरक्षा चुनौती को पार करने के बाद जारी की जाती है।
-
cf_clearance कुकी बाद के अनुरोधों को क्लाउडफ्लेयर की सुरक्षा को दरकिनार करने की अनुमति देती है, जिससे बार-बार चुनौतियों की आवश्यकता कम हो जाती है।
2. अनुरोध अवरोधन सक्षम करें और हेडर कैप्चर करें
await page.setRequestInterception(true);
page.on('request', request => {
// क्लाउडफ्लेयर चुनौती के बाद पेज अनुरोधों का मिलान करें
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});उद्देश्य:
-
नेटवर्क अनुरोधों की निगरानी और संशोधन करने के लिए अनुरोध अवरोधन (setRequestInterception(true)) सक्षम करें।
-
अनुरोध ईवेंट सुनें, जब भी पुपेटियर एक नेटवर्क अनुरोध भेजता है, तो ट्रिगर होता है।
-
क्लाउडफ्लेयर चुनौती अनुरोधों की पहचान करें:
-
request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') सुनिश्चित करता है कि केवल प्रासंगिक अनुरोधों को ही रोका जाता है।
-
request.headers()?.['origin'] वैध पहुँच को सत्यापित करने में मदद करता है।
-
अनुरोध हेडर निकालें और प्रिंट करें, जिसका उपयोग बाद में वास्तविक ब्राउज़र अनुरोधों का अनुकरण करने के लिए किया जा सकता है।
-
पेज लोडिंग में व्यवधान को रोकने के लिए अनुरोध जारी रखें (request.continue())।
-
क्लाउडफ्लेयर की cf_clearance कुकी को प्रभावी ढंग से कैप्चर और उपयोग करना चाहते हैं?
💪 सुचारू स्क्रैपिंग के लिए सभी उन्नत सुविधाओं तक पहुँच प्राप्त करने के लिए अभी लॉग इन करें!
3. cf_clearance और हेडर पुनः प्राप्त करने का कारण क्या है?
- सत्र स्थिरता:
-
cf_clearance कुकी क्लाउडफ्लेयर चुनौतियों को छोड़कर बाद के HTTP अनुरोधों की अनुमति देती है।
-
इस कुकी का उपयोग कई अनुरोधों में किया जा सकता है, जिससे सत्यापन संकेत कम हो जाते हैं।
- वास्तविक ब्राउज़र अनुरोधों का अनुकरण करना:
-
क्लाउडफ्लेयर User-Agent, Referer और Origin जैसे अनुरोध हेडर की जांच करता है।
-
एक सफल अनुरोध से हेडर कैप्चर करने से यह सुनिश्चित होता है कि भविष्य के अनुरोध वैध ट्रैफ़िक की नकल कर सकें, जिससे पता लगाने का जोखिम कम हो जाता है।
- बढ़ी हुई क्रॉलिंग दक्षता:
- इन विवरणों को डेटाबेस या फ़ाइल में संग्रहीत किया जा सकता है और पुन: उपयोग किया जा सकता है, जिससे अनावश्यक चुनौतियों को रोका जा सकता है और अनुरोध सफलता दर को अनुकूलित किया जा सकता है।
इन तकनीकों को लागू करके, आप वेब स्क्रैपिंग की विश्वसनीयता और दक्षता में सुधार कर सकते हैं, क्लाउडफ्लेयर के सुरक्षा उपायों को प्रभावी ढंग से दरकिनार कर सकते हैं। 🚀
भाग 3: स्क्रैपलेस ब्राउज़र का उपयोग करके क्लाउडफ्लेयर टर्नस्टाइल को कैसे दरकिनार करें
ट्यूटोरियल के इस भाग में, हम सीखेंगे कि पुपेटियर के साथ स्क्रैपलेस ब्राउज़र का उपयोग करके क्लाउडफ्लेयर टर्नस्टाइल सुरक्षा को कैसे दरकिनार किया जाए। क्लाउडफ्लेयर टर्नस्टाइल एक अधिक उन्नत सुरक्षा तंत्र है जिसका उपयोग बॉट्स और स्वचालित स्क्रैपिंग को अवरुद्ध करने के लिए किया जाता है। स्क्रैपलेस ब्राउज़र की मदद से, हम इस सुरक्षा को दरकिनार कर सकते हैं ताकि वेबसाइट के साथ बातचीत कर सकें जैसे कि हम एक वास्तविक उपयोगकर्ता थे।
नोट:
"क्लाउडफ्लेयर सुरक्षा को दरकिनार करें" और "क्लाउडफ्लेयर टर्नस्टाइल बाईपास" विभिन्न सुरक्षा तंत्रों को लक्षित करते हैं।
- क्लाउडफ्लेयर सुरक्षा को दरकिनार करना में CAPTCHA, जावास्क्रिप्ट चेक और IP दर सीमा जैसे सामान्य क्लाउडफ्लेयर सुरक्षा उपायों को दरकिनार करना शामिल है।
- क्लाउडफ्लेयर टर्नस्टाइल बाईपास विशेष रूप से क्लाउडफ्लेयर के टर्नस्टाइल को लक्षित करता है, एक अनूठी एंटी-बॉट चुनौती जो पारंपरिक CAPTCHA पर निर्भर किए बिना मानव संपर्क सुनिश्चित करती है। टर्नस्टाइल को दरकिनार करने से यह विशिष्ट सुरक्षा तंत्र निष्क्रिय हो जाता है।
चरण 1: लक्षित पृष्ठ खोलें
हम एक वेबपृष्ठ खोलकर शुरू करेंगे जो क्लाउडफ्लेयर टर्नस्टाइल द्वारा सुरक्षित है, जिसके लिए आम तौर पर मानव सत्यापन की आवश्यकता होती है। नीचे वह कोड दिया गया है जो वेबपेज खोलता है।
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });यह कोड पेज पर नेविगेट करने के लिए page.goto() का उपयोग करता है और तब तक प्रतीक्षा करता है जब तक कि DOM सामग्री लोड नहीं हो जाती।
चरण 2: लॉगिन क्रेडेंशियल भरें
पृष्ठ लोड हो जाने के बाद, हम लॉगिन पृष्ठ को पास करने के लिए लॉगिन क्रेडेंशियल (जैसे उपयोगकर्ता नाम और पासवर्ड) भरने की प्रक्रिया को स्वचालित कर सकते हैं।
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');चरण 3: टर्नस्टाइल के अनलॉक होने की प्रतीक्षा करें
क्लाउडफ्लेयर टर्नस्टाइल यह सुनिश्चित करके काम करता है कि केवल मानव उपयोगकर्ता ही आगे बढ़ सकें। इस चरण में, हम यह जांचकर टर्नस्टाइल के अनलॉक होने की प्रतीक्षा करेंगे कि क्या टर्नस्टाइल सत्यापन प्रक्रिया से प्रतिक्रिया प्राप्त हुई है।
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});कोड की यह पंक्ति window.turnstile.getResponse() से प्रतिक्रिया की प्रतीक्षा करती है, जो इंगित करता है कि टर्नस्टाइल सत्यापन को सफलतापूर्वक दरकिनार कर दिया गया है।
💥 आसानी से क्लाउडफ्लेयर टर्नस्टाइल के पीछे की सामग्री को अनलॉक करें।
🔓 शक्तिशाली स्क्रैपिंग सुविधाओं तक पहुँच प्राप्त करने के लिए लॉग इन करें!
💬 व्यक्तिगत सहायता, सुझाव और उपयोगकर्ता अंतर्दृष्टि के लिए हमारे डिस्कोर्ड समुदाय में शामिल हों!
🚀 स्क्रैपलेस ब्राउज़र के साथ अपनी वेब स्क्रैपिंग को सुव्यवस्थित करें- क्लाउडफ्लेयर की सबसे कठिन चुनौतियों सहित किसी भी बाधा को पार करें!"
चरण 4: सत्यापित करने के लिए एक स्क्रीनशॉट लें
यह पुष्टि करने के लिए कि बाईपास सफल रहा, हम पेज का स्क्रीनशॉट ले सकते हैं। इससे हमें यह सत्यापित करने में मदद मिलती है कि टर्नस्टाइल सफलतापूर्वक दरकिनार हो गया है।
await page.screenshot({ path: 'challenge-bypass-success.png' });चरण 5: लॉगिन बटन पर क्लिक करें
टर्नस्टाइल चुनौती को सफलतापूर्वक दरकिनार करने के बाद, हम फॉर्म सबमिट करने के लिए उपयोगकर्ता द्वारा लॉगिन बटन पर क्लिक करने का अनुकरण कर सकते हैं।
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();यह कोड सबमिट बटन पर क्लिक करता है और लॉगिन के बाद पेज के अगले पेज पर नेविगेट करने की प्रतीक्षा करता है।
चरण 6: अगले पेज का एक और स्क्रीनशॉट लें
अंत में, एक बार जब हम लॉग इन कर लेते हैं, तो हम यह पुष्टि करने के लिए एक और स्क्रीनशॉट लेंगे कि अगले पेज पर नेविगेशन सफल रहा।
await page.screenshot({ path: 'next-page.png' });पूर्ण कोड उदाहरण
यहाँ पूर्ण कोड है जिसमें ऊपर उल्लिखित सभी चरण शामिल हैं:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');
// टर्नस्टाइल के सफलतापूर्वक अनलॉक होने की प्रतीक्षा करें
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
// बाईपास के बाद स्क्रीनशॉट लें
await page.screenshot({ path: 'challenge-bypass-success.png' });
// लॉगिन बटन पर क्लिक करें
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();
// अगले पेज का स्क्रीनशॉट लें
await page.screenshot({ path: 'next-page.png' });इस ट्यूटोरियल का पालन करके, आपने सफलतापूर्वक सीखा है कि पुपेटियर और स्क्रैपलेस ब्राउज़र का उपयोग करके क्लाउडफ्लेयर टर्नस्टाइल सुरक्षा को कैसे दरकिनार किया जाए। यह दृष्टिकोण आपको वेबसाइट के साथ बातचीत करने, लॉगिन फॉर्म भरने और क्लाउडफ्लेयर के सुरक्षा तंत्र को दरकिनार करते हुए सामग्री के माध्यम से नेविगेट करने की अनुमति देता है। आप इस तकनीक का विस्तार टर्नस्टाइल द्वारा संरक्षित अन्य वेबसाइटों के साथ काम करने के लिए कर सकते हैं।
क्लाउडफ्लेयर बाईपास और स्क्रैपलेस ब्राउज़र के साथ वेब स्क्रैपिंग में महारत हासिल करने के लिए तैयार हैं?
🚀 आज ही स्क्रैपलेस ब्राउज़र की पूरी शक्ति को अनलॉक करें और क्लाउडफ्लेयर सुरक्षा को दरकिनार करना, कुकीज़ और हेडर प्राप्त करना और आसानी से टर्नस्टाइल चुनौतियों को दरकिनार करना शुरू करें!
🔑 विशेष सुविधाओं तक पहुँच प्राप्त करने और विश्वास के साथ स्क्रैपिंग शुरू करने के लिए यहाँ लॉग इन करें।
💬 अन्य स्क्रैपिंग विशेषज्ञों से जुड़ने, समस्या निवारण सहायता प्राप्त करने और नवीनतम सुझावों और युक्तियों के साथ अपडेट रहने के लिए हमारे डिस्कोर्ड समुदाय में शामिल हों!
💡 स्क्रैपलेस ब्राउज़र के साथ अपनी वेब स्क्रैपिंग को अगले स्तर पर ले जाने के लिए शक्तिशाली उपकरणों और अंतर्दृष्टि को याद न करें।
निष्कर्ष
क्लाउडफ्लेयर सुरक्षा को सफलतापूर्वक दरकिनार करने के लिए सही उपकरणों और रणनीतियों की आवश्यकता होती है। स्क्रैपलेस ब्राउज़र के साथ, आप क्लाउडफ्लेयर के बचाव को आसानी से नेविगेट कर सकते हैं, आवश्यक कुकीज़ और हेडर पुनः प्राप्त कर सकते हैं, और मैन्युअल हस्तक्षेप के बिना टर्नस्टाइल चुनौती को पार कर सकते हैं।
🔑 अभी साइन अप करें और अपनी वेब स्क्रैपिंग को अगले स्तर पर ले जाएँ!
💬 मदद चाहिए? अन्य डेवलपर्स से जुड़ने, समस्या निवारण सहायता प्राप्त करने और नवीनतम वेब स्क्रैपिंग तकनीकों से आगे रहने के लिए हमारे डिस्कोर्ड समुदाय में शामिल हों।
क्लाउडफ्लेयर को आपको धीमा न करने दें- आज ही सहज स्क्रैपिंग को अनलॉक करें!
FAQ: क्लाउडफ्लेयर बाईपास, cf_clearance कुकी, और टर्नस्टाइल चुनौतियाँ
1. क्लाउडफ्लेयर सुरक्षा क्या है, और यह वेब स्क्रैपर को क्यों अवरुद्ध करती है?
क्लाउडफ्लेयर सुरक्षा एक सुरक्षा सेवा है जो स्वचालित ट्रैफ़िक का पता लगाती है और उसे कम करती है। यह बॉट्स को संरक्षित सामग्री तक पहुँचने से रोकने के लिए CAPTCHA, जावास्क्रिप्ट चुनौतियों और IP दर सीमा जैसी तकनीकों का उपयोग करती है।
2. cf_clearance क्या है, और यह क्लाउडफ्लेयर को दरकिनार करने में कैसे मदद करता है?
cf_clearance कुकी एक सफल क्लाउडफ्लेयर चुनौती के बाद जारी की जाती है। यह एक ब्राउज़र सत्र को एक विशिष्ट अवधि के लिए सत्यापित रहने की अनुमति देता है, जिससे आगे की चुनौतियों को रोका जा सकता है। इस कुकी को पुनः प्राप्त करके और पुन: उपयोग करके, स्क्रैपर निर्बाध पहुँच बनाए रख सकते हैं।
3. क्लाउडफ्लेयर टर्नस्टाइल मानक क्लाउडफ्लेयर सुरक्षा से कैसे अलग है?
क्लाउडफ्लेयर टर्नस्टाइल एक उन्नत चुनौती है जिसे पारंपरिक CAPTCHA के बिना मानव उपस्थिति को सत्यापित करने के लिए डिज़ाइन किया गया है। यह बॉट्स को अवरुद्ध करने के लिए व्यवहार विश्लेषण और अन्य सत्यापन तकनीकों का उपयोग करता है। टर्नस्टाइल को दरकिनार करने के लिए स्वचालित वर्कफ़्लो की आवश्यकता होती है जो वास्तविक उपयोगकर्ता इंटरैक्शन की नकल करते हैं।
4. क्या क्लाउडफ्लेयर को दरकिनार करने के लिए स्क्रैपलेस ब्राउज़र का उपयोग करना कानूनी है?
क्लाउडफ्लेयर को दरकिनार करने की वैधता वेबसाइट की सेवा की शर्तों और स्थानीय नियमों पर निर्भर करती है। हमेशा सुनिश्चित करें कि आपकी स्क्रैपिंग गतिविधियाँ वेबसाइट की नीतियों और लागू कानूनों का पालन करती हैं।
5. मैं क्लाउडफ्लेयर बाईपास के लिए स्क्रैपलेस ब्राउज़र का उपयोग करना कैसे शुरू कर सकता हूँ?
आप स्क्रैपलेस ब्राउज़र में लॉग इन करके और स्वचालित बाईपास समाधानों को लागू करने के लिए इस गाइड में दिए गए चरणों का पालन करके शुरुआत कर सकते हैं।
6. मुझे स्क्रैपलेस ब्राउज़र के लिए सहायता कहाँ मिल सकती है?
अन्य डेवलपर्स से जुड़ने, समस्या निवारण सहायता प्राप्त करने और नई सुविधाओं और सर्वोत्तम प्रथाओं के साथ अपडेट रहने के लिए हमारे डिस्कोर्ड समुदाय में शामिल हों।
अन्य संसाधन
पुपेटियर के साथ क्लाउडफ्लेयर को कैसे दरकिनार करें
क्लाउडफ्लेयर की सुरक्षा को दरकिनार करने और सुरक्षा चुनौतियों को ट्रिगर किए बिना वेब सामग्री तक पहुँचने के लिए पुपेटियर का उपयोग कैसे करें, यह जानें।
वेब स्क्रैपिंग के लिए अनडिटेक्टेड क्रोमड्राइवर का उपयोग कैसे करें
वेबसाइटों को स्क्रैप करते समय पता लगाने से बचने के लिए अनडिटेक्टेड क्रोमड्राइवर इंस्टेंस का उपयोग करने की तकनीकों की खोज करें।
Node.js के साथ Google होटल की कीमतों को कैसे स्क्रैप करें
Node.js का उपयोग करके Google होटल मूल्य डेटा को स्क्रैप करने और एंटी-बॉट तंत्र को प्रभावी ढंग से संभालने पर चरण-दर-चरण मार्गदर्शिका।
Python में Google फ़ाइनेंस टिकर कोट डेटा को कैसे स्क्रैप करें
Google फ़ाइनेंस टिकर कोट्स निकालने पर एक Python-आधारित ट्यूटोरियल, जिसमें JavaScript-र
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


