
पायथन का उपयोग करके वेब स्क्रैपिंग में कैप्चा को कैसे बायपास करें
Advanced Bot Mitigation Engineer
परिचय
बहुत कम लोग जानते हैं कि CAPTCHA का पूरा नाम क्या है।
वास्तव में, CAPTCHA का संक्षिप्त नाम "कंप्यूटर और मनुष्यों को अलग-अलग बताने के लिए पूरी तरह से स्वचालित सार्वजनिक ट्यूरिंग परीक्षण" है। CAPTCHA को कंप्यूटर के सामने मुश्किल-से-सुलझाने वाली समस्याएँ पेश करके संदिग्ध उपयोगकर्ताओं और समकालीन बॉट्स की पहचान करने के लिए डिज़ाइन किया गया है, जो वेबसाइट मालिकों को स्क्रैपिंग और क्रॉलिंग को रोकने में सहायता करता है।
बड़ी संख्या में थर्ड-पार्टी लाइब्रेरीज़ के कारण जो टेक्स्ट पढ़ सकती हैं, HTML फ़ॉर्म के साथ इंटरैक्ट कर सकती हैं और परिष्कृत HTML संरचनाओं को स्क्रैप कर सकती हैं, पायथन वेब स्क्रैपिंग के लिए एक लोकप्रिय विकल्प है। इसलिए, इस लेख में हम बताएंगे कि पायथन का उपयोग करके वेब स्क्रैपिंग के दौरान CAPTCHA समस्याओं को कैसे दूर किया जाए।
आपके डेटा संग्रह प्रक्रियाओं में शामिल करने के लिए व्यावहारिक एंटी-CAPTCHA समाधानों पर चर्चा करने के अलावा, हम विभिन्न CAPTCHA प्रकारों को कवर करेंगे जो आज के ऑनलाइन वातावरण में पाए जा सकते हैं।
reCAPTCHA
यह Google द्वारा विकसित एक निःशुल्क CAPTCHA समाधान है जो वेबसाइट सुरक्षा प्रदान करता है, जो hCAPTCHA की तरह ही बॉट-जैसे व्यवहार की पहचान करने के लिए अत्याधुनिक तरीकों का उपयोग करता है। Google reCAPTCHA अब उपयोगकर्ता से किसी भी इनपुट के बिना मानव उपयोगकर्ताओं की पहचान कर सकता है। यह पहचान के आधार के रूप में केवल अन्य वेबसाइटों के साथ उपयोगकर्ता के पिछले अनुभवों का उपयोग करता है। Google खोज, मैप्स, प्ले, शॉपिंग, और कई अन्य सेवाएँ और उत्पाद बड़े पैमाने पर reCAPTCHA का उपयोग करते हैं।
ImageToText CAPTCHA

आमतौर पर, ImageToText CAPTCHA असंबंधित अक्षरों और वर्णों का एक समूह होता है, जो एक अस्पष्ट शैली में प्रदर्शित होता है, जिसमें वर्णों को अलग-अलग तरीकों से घुमाया, आकार बदला और विकृत किया गया होता है।
ऑडियो कैप्चा
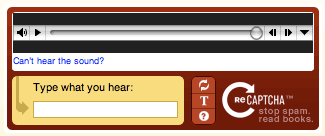
इसे "ध्वनि-आधारित कैप्चा" भी कहा जाता है, इसके लिए उपयोगकर्ताओं को ऑडियो रिकॉर्डिंग के माध्यम से अक्षरों या संख्याओं की एक श्रृंखला इनपुट करने की आवश्यकता होती है। चीजों को और अधिक चुनौतीपूर्ण बनाने के लिए, ऑडियो को अक्सर पृष्ठभूमि शोर द्वारा पूरक किया जाता है।
hCAPTCHA
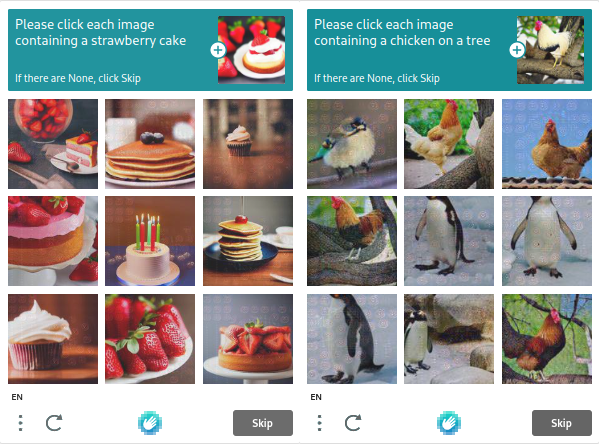
Intuition Machines hCaptcha का मालिक है, जो उपयोगकर्ता की गोपनीयता को महत्व देता है और अनावश्यक डेटा एकत्र नहीं करता है। परिणामस्वरूप, इसकी लोकप्रियता बढ़ रही है। मानक बॉट मूल्यांकन कार्य, जैसे कि बॉक्स-चेकिंग और चित्र पहचान, hCaptcha का उपयोग करके किए जाते हैं। hCaptcha में परीक्षण reCAPTCHA की तुलना में अधिक जटिल हैं, लेकिन आप उन्हें कठिन या आसान बनाने के लिए पैरामीटर बदल सकते हैं।
वेब स्क्रैपिंग: यह क्या है?
वेबसाइटों से डेटा प्राप्त करने की तकनीक को वेब स्क्रैपिंग के रूप में जाना जाता है। इसमें वेबसाइटों से डेटा निकालने के लिए स्वचालित उपकरणों का उपयोग करना शामिल है, जिन्हें कभी-कभी वेब स्क्रैपर या क्रॉलर कहा जाता है। ये प्रोग्राम वेबसाइट के पदानुक्रम के माध्यम से आगे बढ़ते हैं, HTML कोड प्राप्त करते हैं, और फिर आवश्यक डेटा निकालने के लिए पूर्वनिर्धारित पैटर्न या दिशानिर्देशों का उपयोग करते हैं।
वेब स्क्रैपिंग के कई उपयोग हैं, जिनमें शामिल हैं:
-
प्रतियोगी विश्लेषण: प्रतिद्वंद्वियों की इंटरनेट उपस्थिति और रणनीति पर नज़र रखना
-
डेटा संग्रह: वेबसाइटों से पाठ, चित्र और अन्य मीडिया सामग्री संकलित करना
-
मूल्य निगरानी: विभिन्न इंटरनेट व्यापारियों से उत्पाद की लागत पर नज़र रखना और तुलना करना
-
सामग्री एकत्रीकरण: कई स्रोतों से सामग्री एकत्र करके एक समेकित डेटाबेस या वेबसाइट बनाना
-
बाजार अनुसंधान: बाजार की गतिशीलता, रुझान, उपभोक्ता प्रतिक्रिया और अन्य प्रासंगिक डेटा का विश्लेषण करना।
यह ध्यान देने योग्य है कि वेब स्क्रैपिंग, डेटा एकत्र करने के लिए एक शक्तिशाली साधन होने के बावजूद, नैतिक और वैध तरीके से निष्पादित किया जाना चाहिए। निजी या संवेदनशील जानकारी को स्क्रैप करना कानून के विरुद्ध हो सकता है, और कई वेबसाइटों ने अपनी सेवा की शर्तों में इसके विरुद्ध स्पष्ट निषेधाज्ञाएँ दी हैं। ऑनलाइन स्क्रैपिंग गतिविधियों में भाग लेते समय, सुनिश्चित करें कि आप हमेशा वेबसाइट के उपयोग की शर्तों और किसी भी लागू कानून के अनुसार हों।
वेब स्क्रैपिंग का उदाहरण
वेब स्क्रैपिंग वेबसाइटों से डेटा प्राप्त करने की प्रक्रिया है, जो आमतौर पर टूल या प्रोग्रामिंग स्क्रिप्ट के उपयोग से स्वचालित रूप से होती है। यह एक बुनियादी उदाहरण है जो ब्यूटीफुलसूप पैकेज का उपयोग करता है, जो वेब स्क्रैपिंग गतिविधियों और पायथन के लिए एक लोकप्रिय विकल्प है।
फिलहाल मान लें कि हम एक काल्पनिक समाचार स्रोत से सबसे हाल के लेखों के नाम प्राप्त करना चाहते हैं। HTML की संरचना कुछ इस तरह हो सकती है:
language
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sample News Website</title>
</head>
<body>
<div class="article">
<h2 class="title">Breaking News 1</h2>
<p class="content">This is the content of the first article.</p>
</div>
<div class="article">
<h2 class="title">Latest Update: Important Event</h2>
<p class="content">Details about the important event.</p>
</div>
</body>
</html>आइए अब इन लेखों की हेडलाइन को स्क्रैप करने के लिए BeautifulSoup और Python का उपयोग करें:
language
import requests
from bs4 import BeautifulSoup
# URL of the sample news website
url = 'https://www.example-news-website.com'
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all div elements with the class 'article' and extract the titles
article_divs = soup.find_all('div', class_='article')
# Extract and print the titles
for article_div in article_divs:
title = article_div.find('h2', class_='title').text
print(f"Title: {title}")HTML सामग्री प्राप्त करने के लिए, हम GET निष्पादित करने के लिए अनुरोध लाइब्रेरी का उपयोग करते हैं वेबसाइट पर अनुरोध करें। इसके बाद, HTML सामग्री को पार्स करने के लिए BeautifulSoup का उपयोग किया जाता है (इस मामले में 'html.parser' का उपयोग किया जाता है)। क्लास आर्टिकल वाले हर div तत्व को खोजने के लिए, हम find_all का उपयोग करते हैं। हम हर लेख के लिए क्लास शीर्षक के साथ h2 तत्व का पता लगाते हैं और इसकी टेक्स्ट सामग्री को पुनः प्राप्त करते हैं।
वेब स्क्रैपिंग करते समय CAPTCHA को बायपास करने के लिए Scrapeless का उपयोग कैसे करें
क्या आप लगातार वेब स्क्रैपिंग ब्लॉक और CAPTCHA से तंग आ चुके हैं?
Scrapeless का परिचय - बेहतरीन ऑल-इन-वन वेब स्क्रैपिंग समाधान!
हमारे शक्तिशाली टूल के साथ अपने डेटा निष्कर्षण की पूरी क्षमता को अनलॉक करें:
सर्वश्रेष्ठ CAPTCHA सॉल्वर
अपने स्क्रैपिंग को सहज और निर्बाध रखते हुए उन्नत CAPTCHA को स्वचालित रूप से हल करें।
अंतर का अनुभव करें - इसे निःशुल्क आज़माएँ!
समापन टिप्पणी
सार्वजनिक डेटा संग्रह में सबसे आम बाधाओं में से एक CAPTCHA है, इसलिए उन्हें दूर करने के लिए एक भरोसेमंद और बेहतर तरीका खोजना महत्वपूर्ण है। इस लेख में विभिन्न CAPTCHA प्रकारों को शामिल किया गया है जो वर्तमान में उपलब्ध हैं और कुछ एंटी-CAPTCHA समाधान प्रदान किए गए हैं जिन्हें आप अपनी वेब स्क्रैपिंग गतिविधियों में उपयोग करने का प्रयास कर सकते हैं।
यदि आपके पास इस विषय के बारे में कोई प्रश्न हैं या आप वेब अनलॉकर या CAPTCHA सॉल्वर जैसे CAPTCHA से बचने के लिए Scrapeless के सर्वोत्तम तरीकों के बारे में अधिक जानकारी चाहते हैं, तो कृपया हमसे संपर्क करने के लिए हमारी आधिकारिक वेबसाइट का उपयोग करें।
FAQ
वेब स्क्रैपिंग के दौरान CAPTCHA से कैसे बचा जा सकता है?
वेब डेटा प्राप्त करते समय, CAPTCHA से बचने के लिए कई तकनीकें हैं। एक उपयोगी तरकीब यह है कि यूजर-एजेंट हेडर को संशोधित करके अपने स्क्रैपर के फिंगरप्रिंट को ठीक करें। इसके अलावा, आप वेब अनलॉकर जैसे स्वचालित प्रोग्राम को नियोजित करने के बारे में सोच सकते हैं, जो आपको CAPTCHA समस्याओं से निपटने में मदद कर सकता है।
वेबसाइट के मालिक स्क्रैपिंग को रोकने के लिए CAPTCHA का उपयोग क्यों करते हैं?
CAPTCHA का उपयोग वेबसाइटों पर खतरनाक बॉट और वास्तविक विज़िटर के बीच अंतर करने के लिए किया जाता है। वे स्पैमिंग या धोखाधड़ी वाले लेनदेन जैसे शत्रुतापूर्ण या संभावित रूप से विनाशकारी बॉट व्यवहार को रोकने के लिए सुरक्षा उपाय के रूप में काम करते हैं। ### क्या वेब स्क्रैपिंग के दौरान CAPTCHA को बायपास करने का कोई तरीका है? हाँ, बाज़ार में कई तरह की सेवाएँ उपलब्ध हैं जो विशेष रूप से CAPTCHA को बायपास करने के लिए बनाई गई हैं। उदाहरणों में वेब अनलॉकर और CAPTCHA सॉल्वर शामिल हैं। उदाहरण के लिए, स्क्रैपलेस का टूल वैध उपयोगकर्ता के रूप में दिखने के लिए हेडर, कुकीज़, ब्राउज़र प्रॉपर्टी आदि के उचित सेट का चयन करता है और अंततः सभी लक्षित वेबसाइट बाधाओं को पार कर जाता है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


