
कैसे n8n और Scrapeless के साथ एक बुद्धिमान B2B लीड जनरेशन वर्कफ़्लो बनाएं
Advanced Data Extraction Specialist
अपनी बिक्री संभावनाओं को एक स्वचालित कार्यप्रवाह के साथ बदलें जो Google खोज, क्रॉलर और क्लॉड एआई विश्लेषण का उपयोग करके B2B लीड को खोजता है, योग्यता प्रदान करता है और समृद्ध करता है। यह ट्यूटोरियल आपको n8n और Scrapeless का उपयोग करके एक शक्तिशाली लीड जनरेशन सिस्टम बनाने का तरीका दिखाता है।
हम क्या बनाएंगे
इस ट्यूटोरियल में, हम एक बुद्धिमान B2B लीड जनरेशन कार्यप्रवाह बनाएंगे जो:
- स्वचालित रूप से शेड्यूल पर या मैन्युअल रूप से ट्रिगर होता है
- Scrapeless का उपयोग करके आपके लक्षित बाजार में कंपनियों के लिए Google की खोज करता है
- प्रत्येक कंपनी के URL को व्यक्तिगत रूप से आइटम सूचियों के साथ संसाधित करता है
- साइटों को विस्तृत जानकारी निकालने के लिए क्रॉल करता है
- लीड डेटा को योग्यता और संरचना देने के लिए क्लॉड एआई का उपयोग करता है
- योग्यता प्राप्त लीड को Google Sheets में संगृहीत करता है
- Discord पर सूचनाएँ भेजता है (Slack, ईमेल आदि के लिए अनुकूलनीय)
पूर्वापेक्षाएँ
- एक n8n इंस्टेंस (क्लाउड या स्वयं-होस्टेड)
- एक Scrapeless API कुंजी (scrapeless.com पर प्राप्त करें)
आपको केवल Scrapeless डैशबोर्ड में लॉग इन करना है और नीचे दी गई तस्वीर का अनुसरण करना है ताकि आप अपनी API कुंजी प्राप्त कर सकें। Scrapeless आपको एक फ्री ट्रायल कोटा देगा।
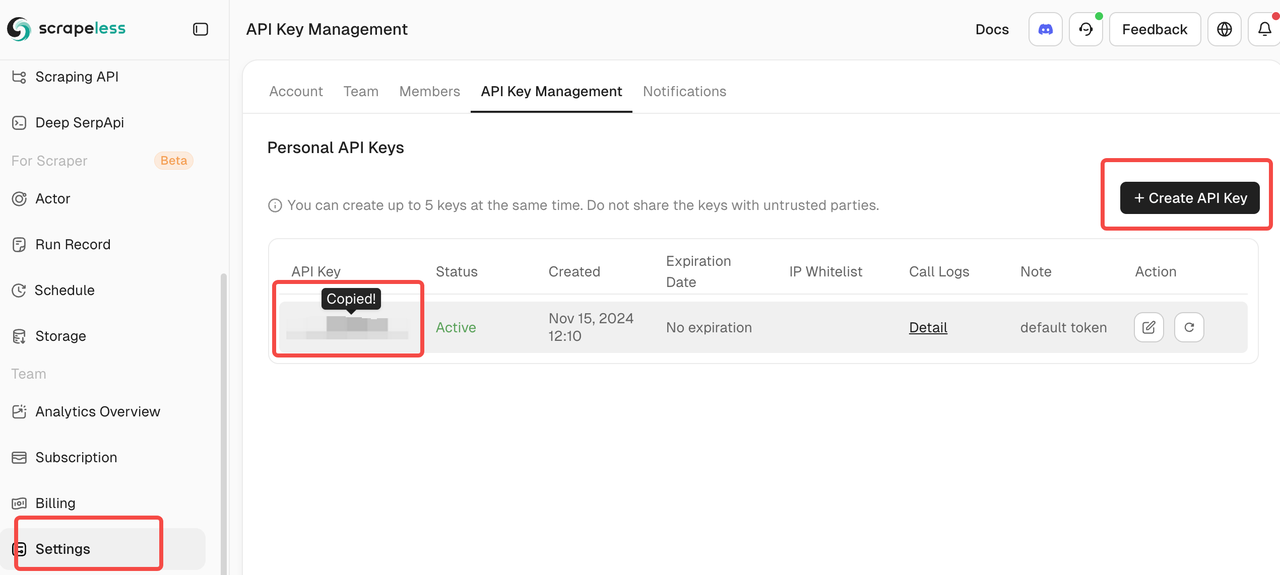
- एन्थ्रॉपिक से क्लॉड एआईपीआई कुंजी
- Google Sheets पहुंच
- Discord वेबहुक यूआरएल (या आपकी पसंदीदा सूचना सेवा)
- n8n कार्यप्रवाह की मूल समझ
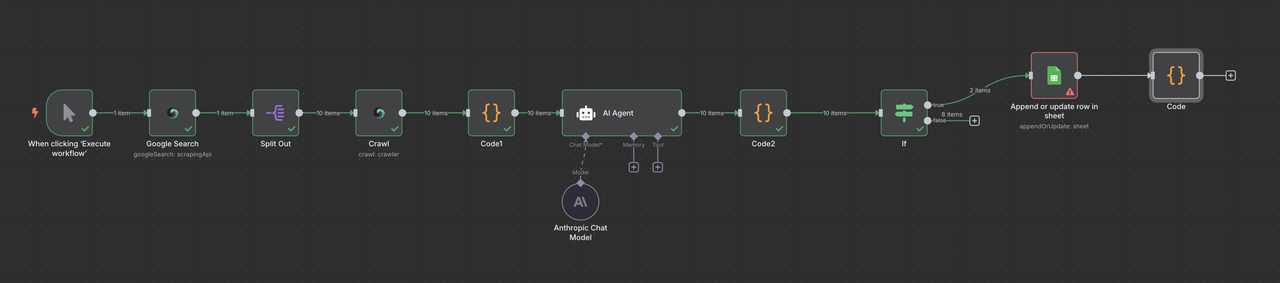
पूर्ण कार्यप्रवाह अवलोकन
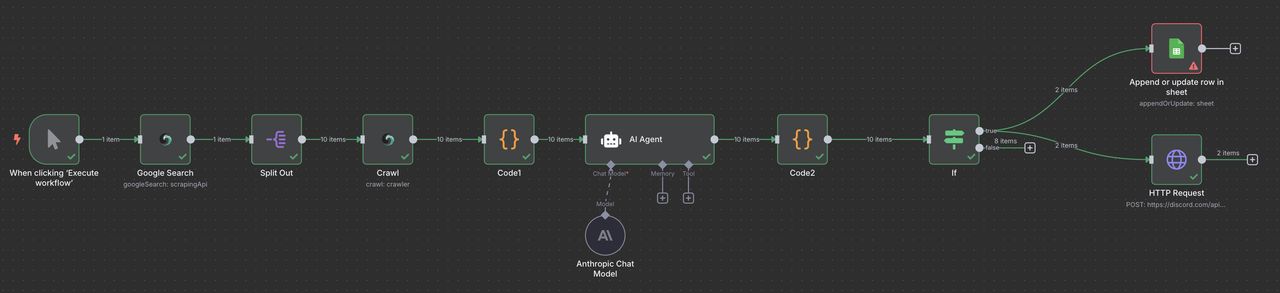
आपका अंतिम n8n कार्यप्रवाह इस प्रकार दिखेगा:
मैनुअल ट्रिगर → Scrapeless Google खोज → आइटम सूचियाँ → Scrapeless क्रॉलर → कोड (डेटा प्रोसेसिंग) → क्लॉड एआई → कोड (प्रतिक्रिया पार्सर) → फ़िल्टर → Google Sheets या/और Discord वेबहुक
चरण 1: मैनुअल ट्रिगर सेट करना
हम परीक्षण के लिए एक मैनुअल ट्रिगर के साथ शुरू करेंगे, फिर बाद में शेड्यूलिंग जोड़ेंगे।
- n8n में एक नया कार्यप्रवाह बनाएं
- मैनुअल ट्रिगर नोड को अपना प्रारंभिक बिंदु बनाएं
- यह आपको कार्यप्रवाह का परीक्षण करने की अनुमति देता है, इससे पहले कि आप इसे स्वचालित करें
क्यों मैनुअल से शुरू करें?
- प्रत्येक चरण का परीक्षण और डिबग करें
- स्वचालन से पहले डेटा की गुणवत्ता की पुष्टि करें
- प्रारंभिक परिणामों के आधार पर पैरामीटर समायोजित करें
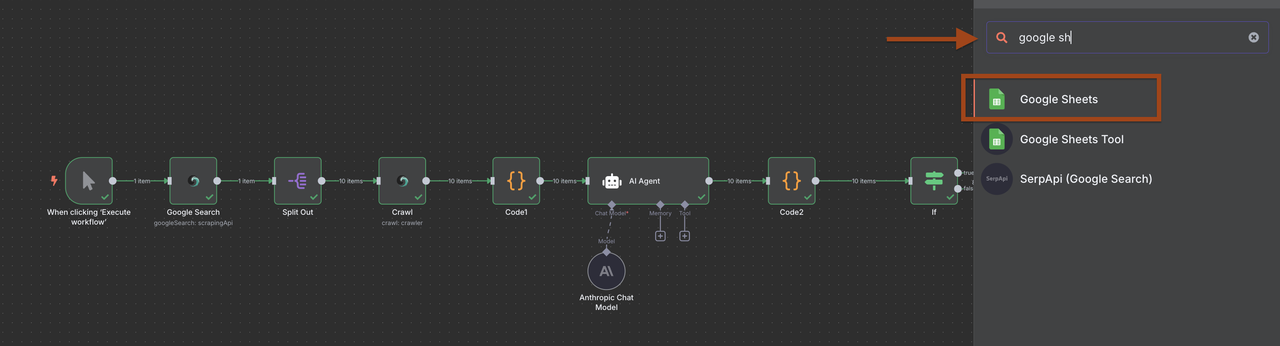
चरण 2: Scrapeless Google खोज में जोड़ना
अब हम लक्षित कंपनियों को खोजने के लिए Scrapeless Google खोज नोड जोड़ेंगे।
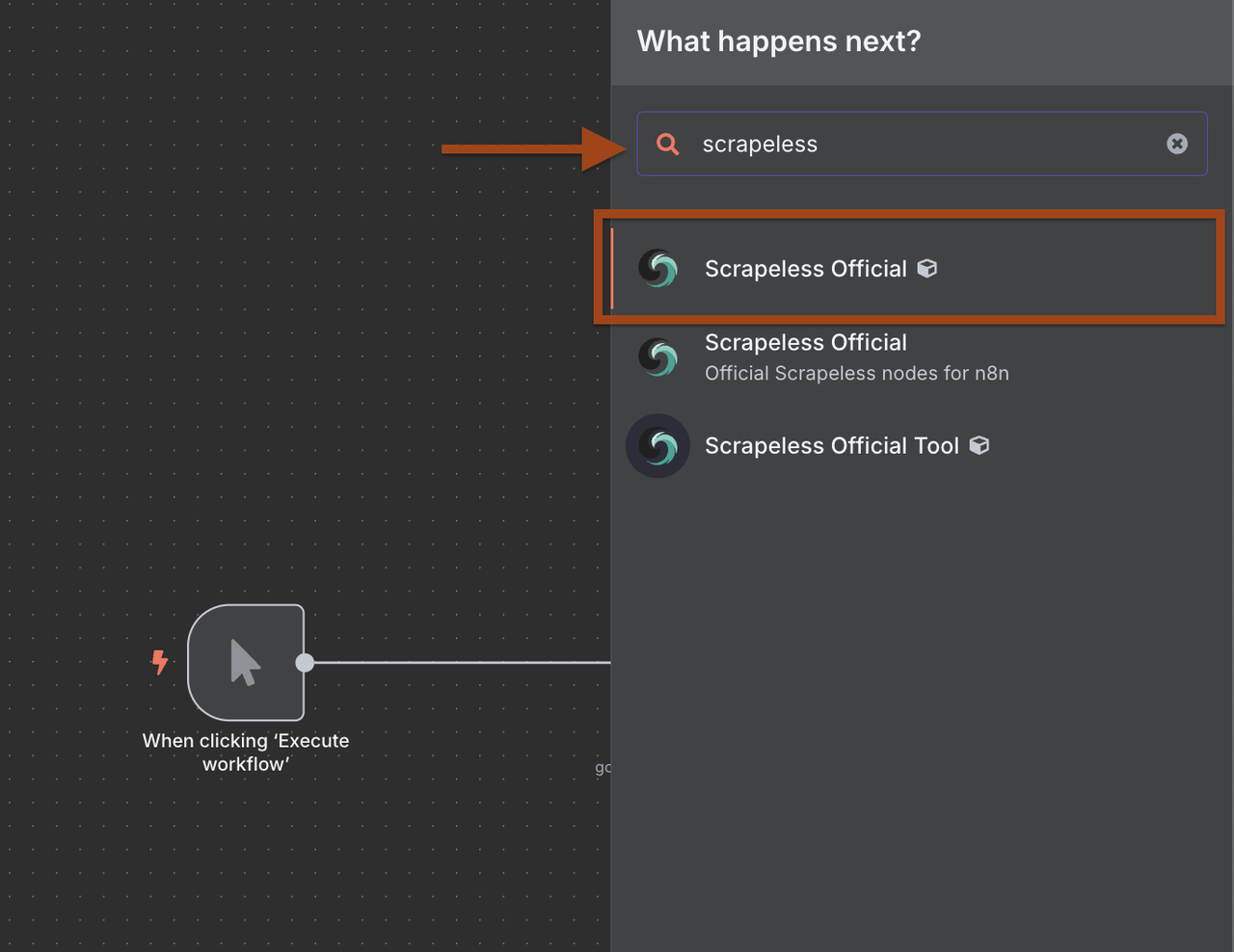
- ट्रिगर के बाद एक नया नोड जोड़ने के लिए + पर क्लिक करें
- नोड लाइब्रेरी में Scrapeless खोजें
- Scrapeless का चयन करें और Google खोज ऑपरेशन चुनें
1. n8n के साथ Scrapeless का उपयोग क्यों करें?
n8n के साथ Scrapeless को एकीकृत करना आपको कोड लिखे बिना उन्नत, संकट-प्रतिरोधी वेब स्क्रैपर्स बनाने की अनुमति देता है।
लाभों में शामिल हैं:
- एकल अनुरोध के साथ Google SERP डेटा को प्राप्त करने और निकालने के लिए गहरे SerpApi का उपयोग करें।
- किसी भी वेबसाइट तक पहुंचने और प्रतिबंधों को बायपास करने के लिए यूनिवर्सल स्क्रैपिंग एपीआई का उपयोग करें।
- व्यक्तिगत पृष्ठों की विस्तृत स्क्रैपिंग करने के लिए क्रॉलर स्क्रैप का उपयोग करें।
- सभी लिंक किए गए पृष्ठों से डेटा पुनर्प्राप्त करने और पुनरावृत्ति करने के लिए क्रॉलर क्रॉल का उपयोग करें।
ये सुविधाएँ आपको Scrapeless को n8n द्वारा समर्थित 350+ सेवाओं के साथ जोड़ने वाले अंत से अंत तक डेटा प्रवाह बनाने की अनुमति देती हैं, जिसमें Google Sheets, Airtable, Notion, Slack और अधिक शामिल हैं।
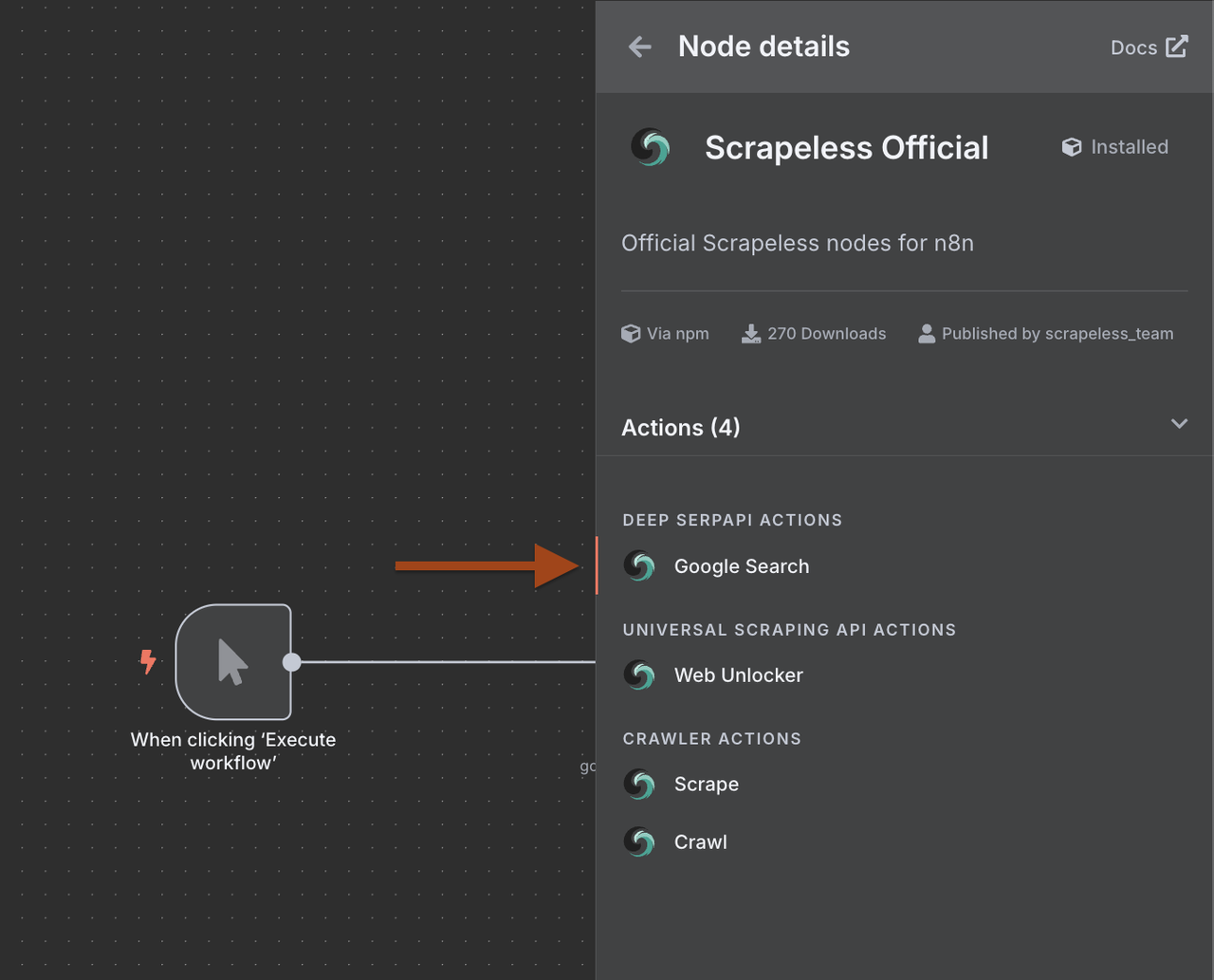
2. Google खोज नोड कॉन्फ़िगर करना
अगला, हमें Scrapeless Google खोज नोड को कॉन्फ़िगर करने की आवश्यकता है
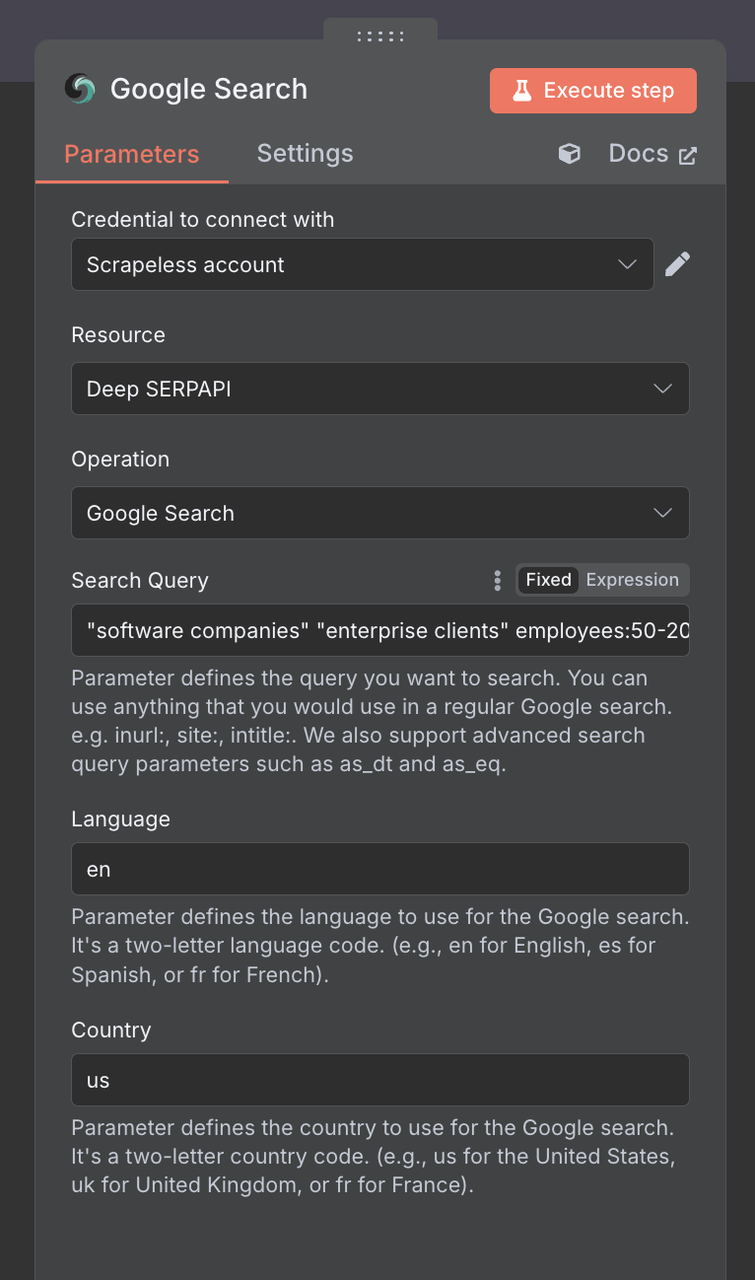
कनेक्शन सेटअप:
- अपनी Scrapeless API कुंजी के साथ एक कनेक्शन बनाएं
- "जोड़ें" पर क्लिक करें और अपने क्रेडेंशियल्स दर्ज करें
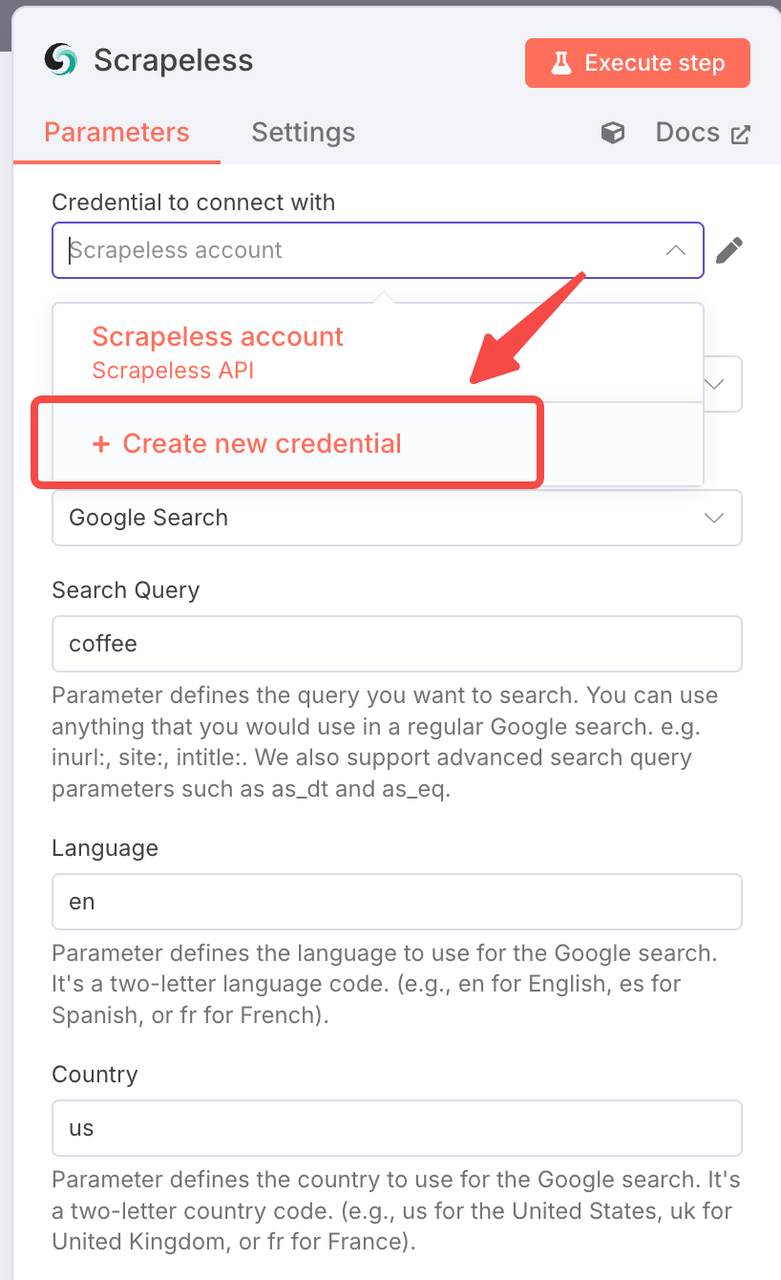
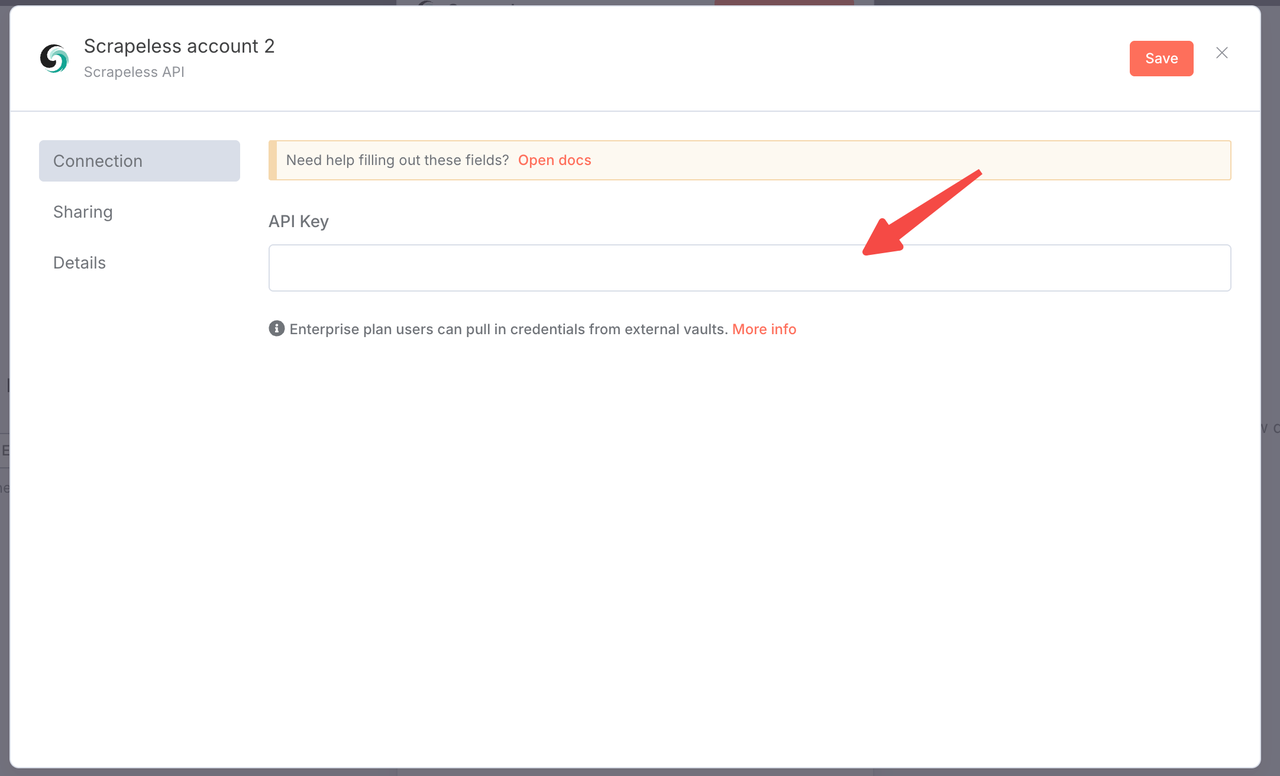
खोज पैरामीटर:
खोज क्वेरी: B2B-केंद्रित खोज शर्तों का उपयोग करें:
"सॉफ़्टवेयर कंपनियाँ" "Enterprise Clients" कर्मचारियों:50-200
"मार्केटिंग एजेंसियाँ" "B2B सेवाएँ" "डिजिटल ट्रांसफॉर्मेशन"
"SaaS स्टार्टअप्स" "सीरीज ए" "वेंचर बैक्ड"
"निर्माण कंपनियाँ" "डिजिटल समाधान" ISOदेश: अमेरिका (या आपका लक्षित बाजार)
भाषा: en
प्रो B2B खोज रणनीतियाँ:
- कंपनी के आकार को लक्षित करना: कर्मचारी:50-200, "मध्यम-मार्केट"
- फंडिंग चरण: "सीरीज ए", "वेंचर बैक्ड", "बूटस्ट्रैप्ड"
- उद्योग विशिष्ट: "फिनटेक", "हेल्थटेक", "एडटेक"
- भौगोलिक: "न्यूयॉर्क", "संफ्रांसिस्को", "लंदन"
चरण 3: आइटम सूचियों के साथ परिणामों की प्रक्रिया करना
गूगल सर्च एक परिणामों की श्रृंखला लौटाता है। हमें प्रत्येक कंपनी को व्यक्तिगत रूप से प्रोसेस करना होगा।
- गूगल सर्च के बाद एक आइटम सूचियों का नोड जोड़ें
- इससे सर्च परिणामों को व्यक्तिगत आइटम में विभाजित किया जाएगा
टिप्स: गूगल सर्च नोड चलाएँ
1. आइटम सूचियाँ कॉन्फ़िगरेशन:
- ऑपरेशन: "आइटम विभाजित करें"
- विभाजित करने के लिए फ़ील्ड: ऑर्गेनिक_रिजल्ट्स - लिंक
- बाइनरी डेटा शामिल करें: झूठा
यह प्रत्येक सर्च परिणाम के लिए एक अलग निष्पादन शाखा बनाता है, जिससे समानांतर प्रोसेसिंग की अनुमति मिलती है।
चरण 4: स्क्रैपलेस क्रॉलर जोड़ना
अब हम प्रत्येक कंपनी की वेबसाइट को क्रॉल करेंगे ताकि विस्तृत जानकारी निकाली जा सके।
- एक और स्क्रैपलेस नोड जोड़ें
- क्रॉल ऑपरेशन (वेब अनलॉकर नहीं) का चयन करें
लिंक्ड पृष्ठों से डेटा प्राप्त करने और पुनः क्रॉलिंग के लिए क्रॉलर क्रॉल का उपयोग करें।
- कंपनी डेटा निष्कर्षण के लिए कॉन्फ़िगर करें
1. क्रॉलर कॉन्फ़िगरेशन
- कनेक्शन: वही स्क्रैपलेस कनेक्शन का उपयोग करें
- यूआरएल: {{ $json.link }}
- क्रॉल गहराई: 2 (होमपेज + एक स्तर गहरा)
- अधिकतम पृष्ठ: 5 (तेज़ प्रोसेसिंग के लिए सीमा)
- शामिल पैटर्न: about|contact|team|company|services
- बाहर किए गए पैटर्न: blog|news|careers|privacy|terms
- प्रारूप: मार्कडाउन (एआई प्रोसेसिंग के लिए आसान)
2. क्रॉलर बनाम वेब अनलॉकर का उपयोग क्यों करें?
- क्रॉलर कई पृष्ठों और संरचित डेटा को प्राप्त करता है
- बी2बी के लिए बेहतर जहां संपर्क जानकारी /about या /contact पृष्ठों पर हो सकती है
- अधिक व्यापक कंपनी जानकारी
- साइट संरचना का बुद्धिमानी से पालन करता है
चरण 5: कोड नोड के साथ डेटा प्रोसेसिंग
क्रॉल किए गए डेटा को क्लॉड एआई को भेजने से पहले, हमें इसे उचित रूप से साफ और संरचित करना होगा। स्क्रैपलेस क्रॉलर एक विशिष्ट प्रारूप में डेटा लौटाता है जिसे सावधानी से पार्स करने की आवश्यकता होती है।
- स्क्रैपलेस क्रॉलर के बाद एक कोड नोड जोड़ें
- कच्चे क्रॉल डेटा को पार्स करने और साफ करने के लिए जावास्क्रिप्ट का उपयोग करें
- इससे एआई विश्लेषण के लिए डेटा की गुणवत्ता सुनिश्चित होती है
1. स्क्रैपलेस क्रॉलर डेटा संरचना को समझना
स्क्रैपलेस क्रॉलर डेटा को वस्तुओं की एक श्रृंखला के रूप में लौटाता है, एकल वस्तु नहीं:
[
{
"markdown": "# कंपनी का होमपेज\n\nहमारी कंपनी में आपका स्वागत है...",
"metadata": {
"title": "कंपनी का नाम - होमपेज",
"description": "कंपनी का विवरण",
"sourceURL": "https://company.com"
}
}
]2. कोड नोड कॉन्फ़िगरेशन
console.log("=== स्क्रैपलेस क्रॉलर डेटा PROSESSING ===");
try {
// डेटा एक श्रृंखला के रूप में आता है
const crawlerDataArray = $json;
console.log("डेटा प्रकार:", typeof crawlerDataArray);
console.log("क्या श्रृंखला है:", Array.isArray(crawlerDataArray));
console.log("श्रृंखला की लंबाई:", crawlerDataArray?.length || 0);
// जाँचना कि क्या श्रृंखला खाली है
if (!Array.isArray(crawlerDataArray) || crawlerDataArray.length === 0) {
console.log("❌ खाली या अम valide क्रॉलर डेटा");
return {
url: "अनजान",
company_name: "कोई डेटा नहीं",
content: "",
error: "खाली क्रॉलर प्रतिक्रिया",
processing_failed: true,
skip_reason: "क्रॉलर से डेटा नहीं लौटा"
};
}
// श्रृंखला से पहला तत्व लेना
const crawlerResponse = crawlerDataArray[0];
// मार्कडाउन सामग्री निकालना
const markdownContent = crawlerResponse?.markdown || "";
// मेटाडेटा निकालना (यदि उपलब्ध हो)
const metadata = crawlerResponse?.metadata || {};
// मूल जानकारी
const sourceURL = metadata.sourceURL || metadata.url || extractURLFromContent(markdownContent);
const companyName = metadata.title || metadata.ogTitle || extractCompanyFromContent(markdownContent);
const description = metadata.description || metadata.ogDescription || "";
console.log(`प्रसंस्करण: ${companyName}`);
console.log(`यूआरएल: ${sourceURL}`);
console.log(`सामग्री की लंबाई: ${markdownContent.length} अक्षर`);
// सामग्री गुणवत्ता सत्यापन
hi
if (!markdownContent || markdownContent.length < 100) {
return {
url: sourceURL,
company_name: companyName,
content: "",
error: "क्रॉलर से सामग्री अपर्याप्त है",
processing_failed: true,
raw_content_length: markdownContent.length,
skip_reason: "सामग्री बहुत छोटी या खाली"
};
}
// मार्कडाउन सामग्री को साफ़ करना और संरचना देना
let cleanedContent = cleanMarkdownContent(markdownContent);
// संपर्क जानकारी निकालना
const contactInfo = extractContactInformation(cleanedContent);
// महत्वपूर्ण व्यावसायिक अनुभागों को निकालना
const businessSections = extractBusinessSections(cleanedContent);
// क्लॉड एआई के लिए सामग्री बनाना
const contentForAI = buildContentForAI({
companyName,
sourceURL,
description,
businessSections,
contactInfo,
cleanedContent
});
// सामग्री गुणवत्ता मेट्रिक्स
const contentQuality = assessContentQuality(cleanedContent, contactInfo);
const result = {
url: sourceURL,
company_name: companyName,
content: contentForAI,
raw_content_length: markdownContent.length,
processed_content_length: contentForAI.length,
extracted_emails: contactInfo.emails,
extracted_phones: contactInfo.phones,
content_quality: contentQuality,
metadata_info: {
has_title: !!metadata.title,
has_description: !!metadata.description,
site_name: metadata.ogSiteName || "",
page_title: metadata.title || ""
},
processing_timestamp: new Date().toISOString(),
processing_status: "सफलता"
};
console.log(`✅ सफलतापूर्वक संसाधित किया गया ${companyName}`);
return result;
} catch (error) {
console.error("❌ क्रॉलर डेटा संसाधित करते समय त्रुटि:", error);
return {
url: "अज्ञात",
company_name: "प्रसंस्करण त्रुटि",
content: "",
error: error.message,
processing_failed: true,
processing_timestamp: new Date().toISOString()
};
}
// ========== उपयोगिता फंक्शन ==========
function extractURLFromContent(content) {
// मार्कडाउन सामग्री से URL निकालने की कोशिश करें
const urlMatch = content.match(/https?:\/\/[^\s\)]+/);
return urlMatch ? urlMatch[0] : "अज्ञात";
}
function extractCompanyFromContent(content) {
// सामग्री से कंपनी का नाम निकालने की कोशिश करें
const titleMatch = content.match(/^#\s+(.+)$/m);
if (titleMatch) return titleMatch[1];
// डोमेन निकालने के लिए ईमेल खोजें
const emailMatch = content.match(/@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,})/);
if (emailMatch) {
const domain = emailMatch[1].replace('www.', '');
return domain.split('.')[0].charAt(0).toUpperCase() + domain.split('.')[0].slice(1);
}
return "अज्ञात कंपनी";
}
function cleanMarkdownContent(markdown) {
return markdown
// नेविगेशन तत्वों को हटाना
.replace(/^\[Skip to content\].*$/gmi, '')
.replace(/^\[.*\]\(#.*\)$/gmi, '')
// मार्कडाउन लिंक को हटाना लेकिन पाठ बनाए रखना
.replace(/\[([^\]]+)\]\([^)]+\)/g, '$1')
// छवियों और बेस64 को हटाना
.replace(/!\[([^\]]*)\]\([^)]*\)/g, '')
.replace(/<Base64-Image-Removed>/g, '')
// कुकी/गोपनीयता उल्लेख हटाना
.replace(/.*?(cookie|privacy policy|terms of service).*?\n/gi, '')
// कई स्पेस को साफ़ करना
.replace(/\s+/g, ' ')
// कई खाली लाइनों को हटाना
.replace(/\n\s*\n\s*\n/g, '\n\n')
.trim();
}
function extractContactInformation(content) {
// ईमेल के लिए रेगुलर एक्सप्रेशन
const emailRegex = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}/g;
// फोन के लिए रेगुलर एक्सप्रेशन (अंतर्राष्ट्रीय समर्थन के साथ)
const phoneRegex = /(?:\+\d{1,3}\s?)?\d{3}\s?\d{3}\s?\d{3,4}|\(\d{3}\)\s?\d{3}-?\d{4}/g;
const emails = [...new Set((content.match(emailRegex) || [])
.filter(email => !email.includes('example.com'))
.slice(0, 3))];
const phones = [...new Set((content.match(phoneRegex) || [])
.filter(phone => phone.replace(/\D/g, '').length >= 9)
.slice(0, 2))];
return { emails, phones };
}
function extractBusinessSections(content) {
const sections = {};
// महत्वपूर्ण अनुभागों की खोज
const lines = content.split('\n');
let currentSection = '';
let currentContent = '';
for (let i = 0; i < lines.length; i++) {
const line = lines[i].trim();
// शीर्षक पहचान
if (line.startsWith('#')) {
// पिछले अनुभाग को सहेजें
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
// नया अनुभाग
const title = line.replace(/^#+\s*/, '').toLowerCase();
if (title.includes('about') || title.includes('service') ||
title.includes('contact') || title.includes('company')) {
currentSection = title.includes('about') ? 'about' :
title.includes('service') ? 'services' :
title.includes('contact') ? 'contact' : 'company';
currentContent = '';
} else {
currentSection = '';
}
} else if (currentSection && line) {
currentContent += line + '\n';
}Here is the translation of the provided text into Hindi:
}
// अंतिम अनुभाग सहेजें
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
return sections;
}
function buildContentForAI({ companyName, sourceURL, description, businessSections, contactInfo, cleanedContent }) {
let aiContent = `कंपनी विश्लेषण अनुरोध\n\n`;
aiContent += `कंपनी: ${companyName}\n`;
aiContent += `वेब साइट: ${sourceURL}\n`;
if (description) {
aiContent += `विवरण: ${description}\n`;
}
aiContent += `\nसंपर्क जानकारी:\n`;
if (contactInfo.emails.length > 0) {
aiContent += `ईमेल: ${contactInfo.emails.join(', ')}\n`;
}
if (contactInfo.phones.length > 0) {
aiContent += `फोन: ${contactInfo.phones.join(', ')}\n`;
}
aiContent += `\nव्यापार अनुभाग:\n`;
for (const [section, content] of Object.entries(businessSections)) {
if (content) {
aiContent += `\n${section.toUpperCase()}:\n${content}\n`;
}
}
// मुख्य सामग्री जोड़ें (सीमित)
aiContent += `\nपूर्ण सामग्री पूर्वावलोकन:\n`;
aiContent += cleanedContent.substring(0, 2000);
// क्लॉड API के लिए अंतिम सीमा
return aiContent.substring(0, 6000);
}
function assessContentQuality(content, contactInfo) {
const wordCount = content.split(/\s+/).length;
return {
word_count: wordCount,
has_contact_info: contactInfo.emails.length > 0 || contactInfo.phones.length > 0,
has_about_section: /about|company|who we are/gi.test(content),
has_services_section: /services|products|solutions/gi.test(content),
has_team_section: /team|leadership|staff/gi.test(content),
content_richness_score: Math.min(10, Math.floor(wordCount / 50)),
email_count: contactInfo.emails.length,
phone_count: contactInfo.phones.length,
estimated_quality: wordCount > 200 && contactInfo.emails.length > 0 ? "उच्च" :
wordCount > 100 ? "मध्यम" : "कम"
};
}3. कोड प्रोसेसिंग चरण क्यों जोड़ें?
- डेटा संरचना अनुकूलन: Scrapeless एरे प्रारूप को Claude-अनुकूल संरचना में परिवर्तित करता है
- सामग्री अनुकूलन: व्यापार से संबंधित अनुभागों को निकालता है और प्राथमिकता देता है
- संपर्क खोज: स्वचालित रूप से ईमेल और फोन नंबर पहचानता है
- गुणवत्ता आकलन: सामग्री की समृद्धि और पूर्णता का मूल्यांकन करता है
- टोकन दक्षता: महत्वपूर्ण जानकारी को बनाए रखते हुए सामग्री का आकार कम करता है
- त्रुटि प्रबंधन: विफल क्रॉल और अपर्याप्त सामग्री का प्रबंधन सुचारू रूप से करता है
- डिबगिंग समर्थन: समस्या निवारण के लिए व्यापक लॉगिंग
4. अपेक्षित आउटपुट संरचना
प्रसंस्करण के बाद, प्रत्येक लीड के पास यह संरचित प्रारूप होगा:
{
"url": "https://company.com",
"company_name": "कंपनी का नाम",
"content": "कंपनी विश्लेषण अनुरोध\n\nकंपनी: ...",
"raw_content_length": 50000,
"processed_content_length": 2500,
"extracted_emails": ["contact@company.com"],
"extracted_phones": ["+1-555-123-4567"],
"content_quality": {
"word_count": 5000,
"has_contact_info": true,
"estimated_quality": "उच्च",
"content_richness_score": 10
},
"processing_status": "सफलता"
}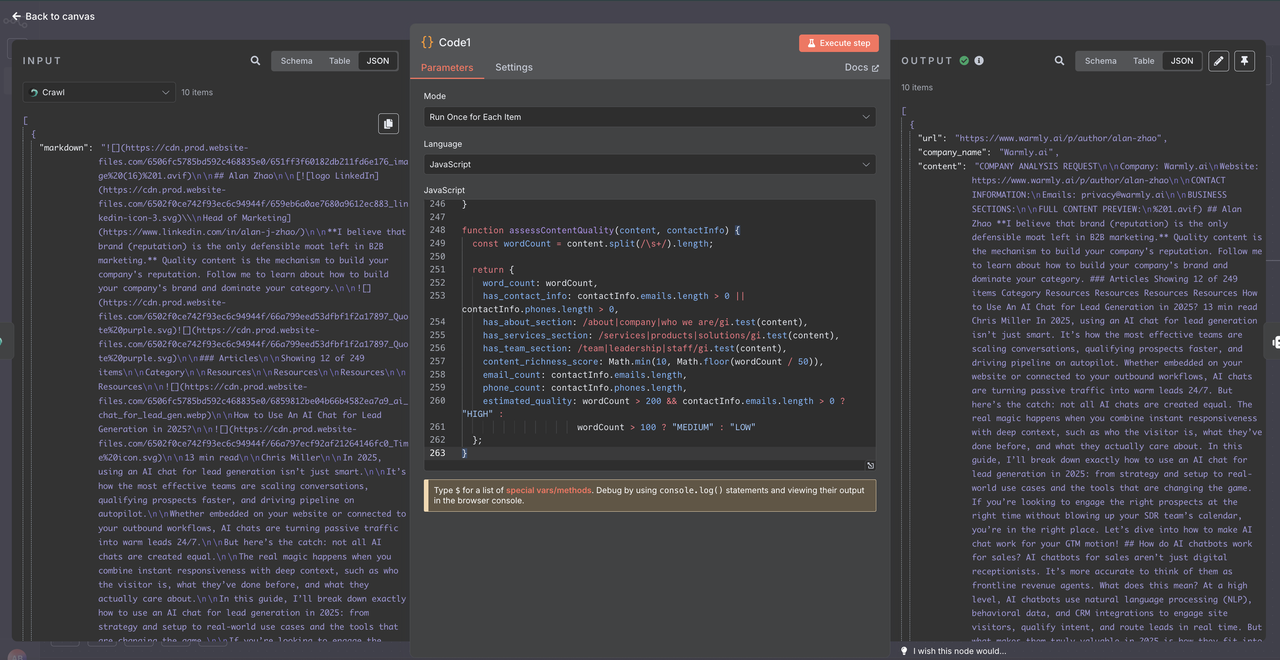
यह डेटा प्रारूप को सत्यापित करने और किसी भी प्रोसेसिंग समस्याओं का समाधान करने में मदद करता है।
5. कोड नोड के लाभ
- लागत की बचत: छोटी, साफ सामग्री = कम Claude API टोकन
- बेहतर परिणाम: केंद्रित सामग्री AI विश्लेषण की सटीकता को सुधारती है
- त्रुटि पुनर्प्राप्ति: रिक्त प्रतिक्रियाओं और विफल क्रॉल का प्रबंधन करता है
- लचीलापन: परिणामों के आधार पर पार्सिंग लॉजिक को समायोजित करना आसान
- गुणवत्ता मीट्रिक्स: लीड डेटा की पूर्णता का अंतर्निहित आकलन
चरण 6: Claude के साथ AI-संचालित लीड योग्यता
Claude AI का उपयोग करके वेब सामग्री से लीड जानकारी निकालें और गुणांकित करें जिसे हमारे कोड नोड द्वारा संसाधित और संरचित किया गया है।
- कोड नोड के बाद AI एजेंट नोड जोड़ें
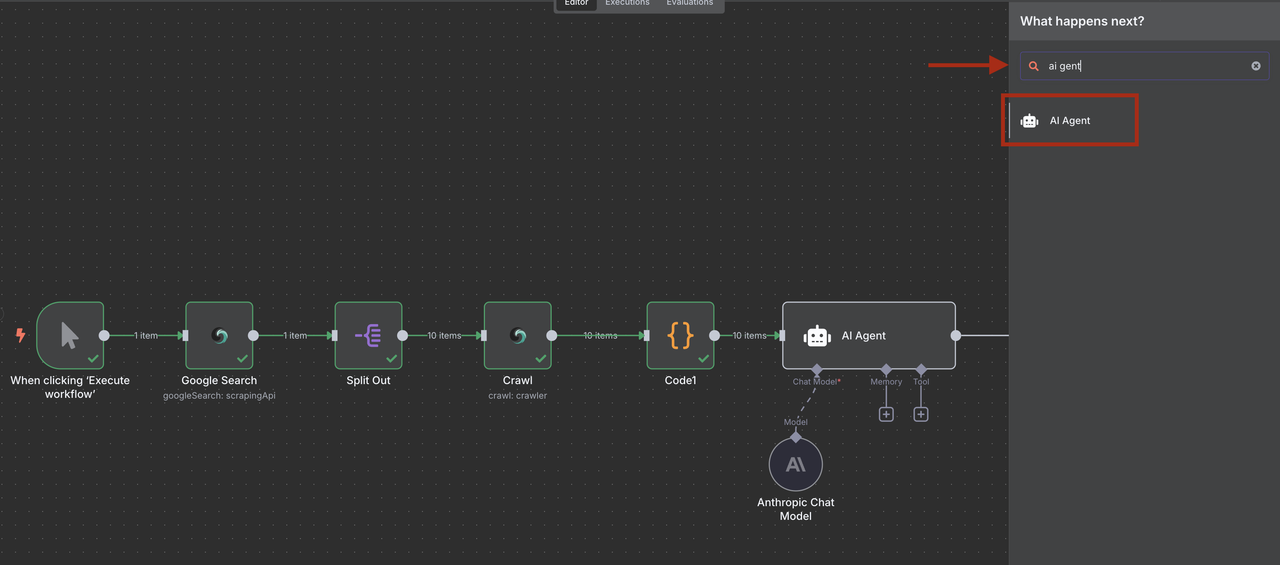
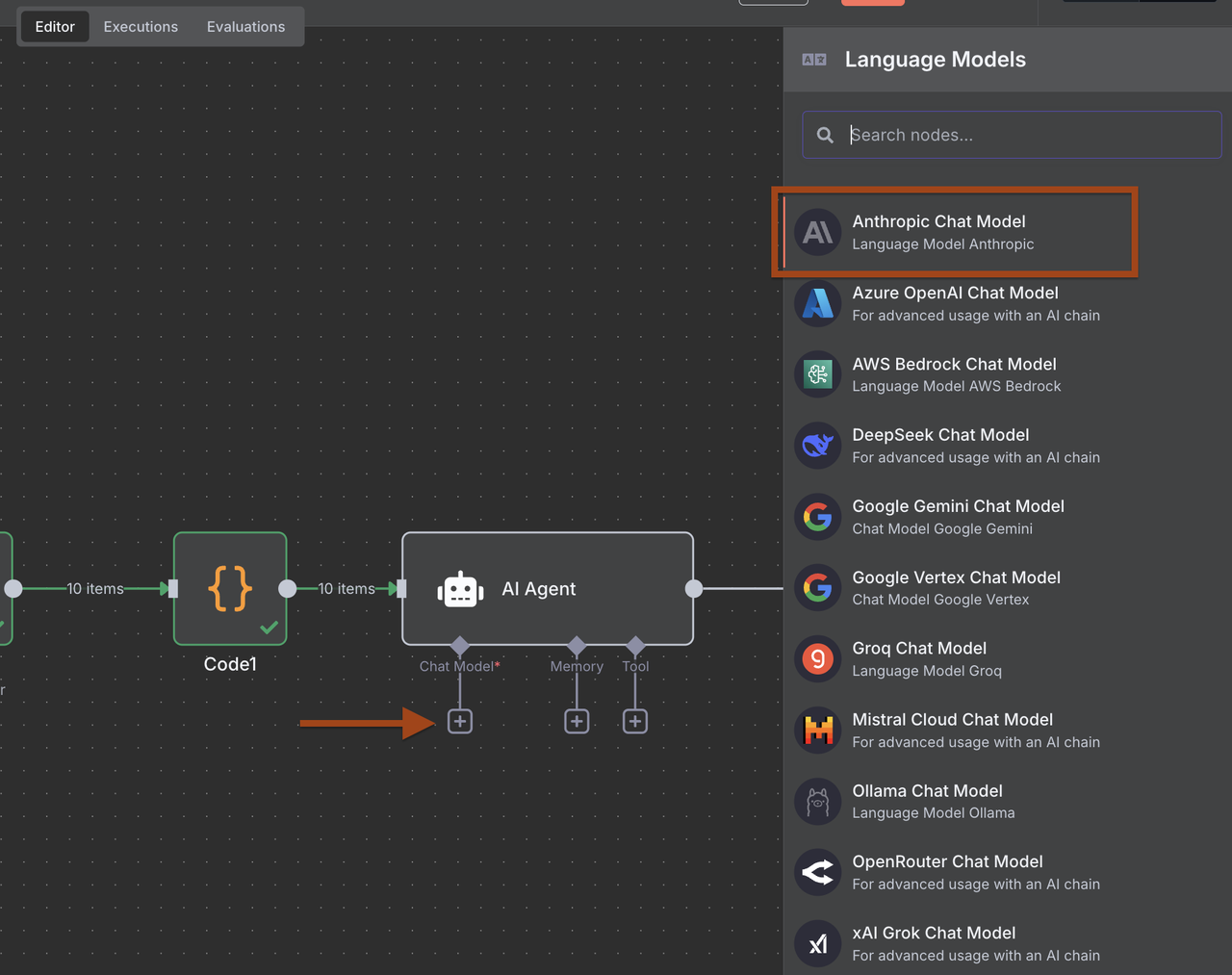
- लीड विश्लेषण के लिए Anthropic Claude नोड जोड़ें और कॉन्फ़िगर करें
- संरचित B2B लीड डेटा निकालने के लिए प्रॉम्प्ट कॉन्फ़िगर करें
AI एजेंट पर क्लिक करें -> विकल्प जोड़ें -> सिस्टम संदेश और नीचे दिए गए संदेश को कॉपी-पेस्ट करें
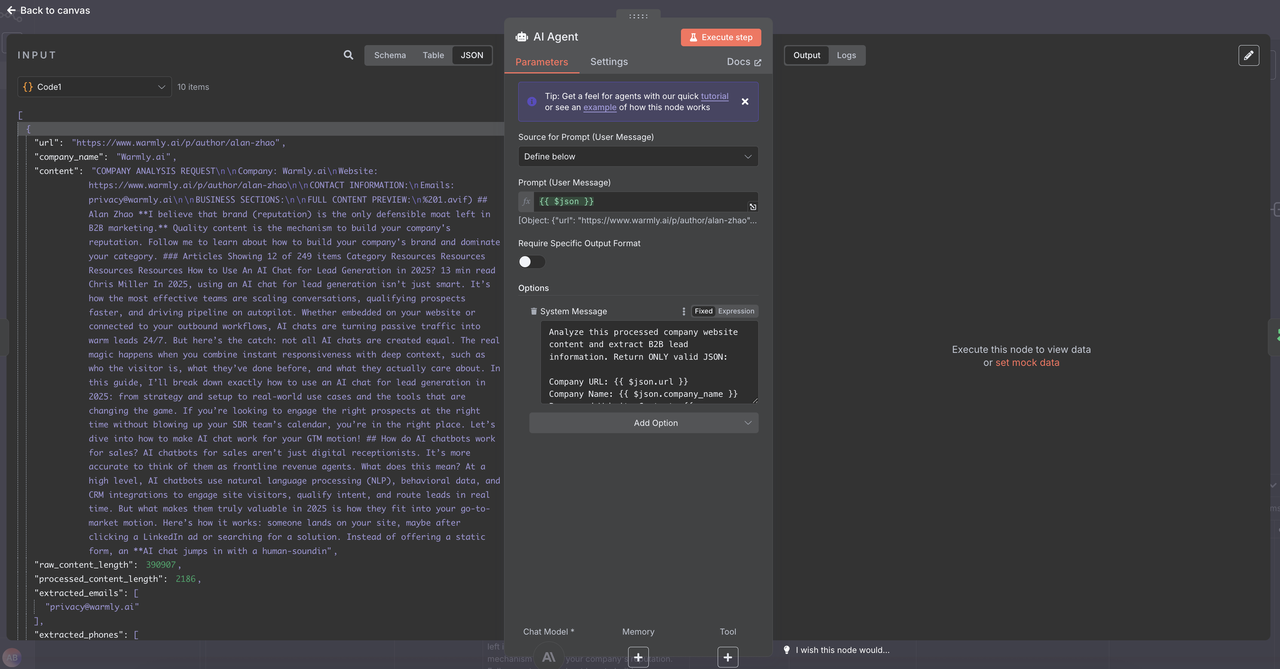
सिस्टम लीड निकासी प्रॉम्प्ट:
इस संसाधित कंपनी की वेबसाइट सामग्री का विश्लेषण करें और B2B लीड जानकारी को निकालें। केवल वैध JSON लौटाएं:
कंपनी URL: {{ $json.url }}
कंपनी का नाम: {{ $json.company_name }}
प्रसंस्कृत वेबसाइट सामग्री: {{ $json.content }}
सामग्री गुणवत्ता आकलन: {{ $json.content_quality }}
पूर्व-निकाली गई संपर्क जानकारी:
ईमेल: {{ $json.extracted_emails }}
फोन: {{ $json.extracted_phones }}
मेटाडेटा जानकारी: {{ $json.metadata_info }}Here is the translated text in Hindi:
प्रोसेसिंग विवरण:
कच्ची सामग्री की लंबाई: {{ $json.raw_content_length }} वर्ण
प्रोसेस्ड सामग्री की लंबाई: {{ $json.processed_content_length }} वर्ण
प्रोसेसिंग स्थिति: {{ $json.processing_status }}
इस संरचित डेटा के आधार पर, इस B2B लीड को निकालें और योग्य बनाएं। केवल मान्य JSON लौटाएं:
{
"company_name": "सामग्री से आधिकारिक कंपनी नाम",
"industry": "पहचान की गई प्राथमिक उद्योग/क्षेत्र",
"company_size": "कर्मचारी संख्या या आकार श्रेणी (स्टार्टअप/SMB/मिड-मार्केट/एंटरप्राइज)",
"location": "मुख्यालय का स्थान या प्राथमिक बाजार",
"contact_email": "निकाली गई ईमेल में से सबसे अच्छा सामान्य या बिक्री ईमेल",
"phone": "निकाली गई फोन में से प्राथमिक फोन नंबर",
"key_services": ["सामग्री के आधार पर मुख्य सेवाएं/उत्पाद"],
"target_market": "वे किसको सेवाएं देते हैं (B2B/B2C, SMB/एंटरप्राइज, विशिष्ट उद्योग)",
"technologies": ["तकनीकी ढांचा, प्लेटफॉर्म, या उपकरण जो उल्लेखित हैं"],
"funding_stage": "अगर उल्लेख किया गया हो तो फंडिंग स्टेज (बीज/श्रृंखला A/B/C/सार्वजनिक/निजी)",
"business_model": "राजस्व मॉडल (SaaS/परामर्श/उत्पाद/मार्केटप्लेस)",
"social_presence": {
"linkedin": "यदि सामग्री में पाया गया हो तो लिंक्डइन कंपनी URL",
"twitter": "यदि सामग्री में पाया गया हो तो ट्विटर हैंडल"
},
"lead_score": 8.5,
"qualification_reasons": ["यह लीड योग्य क्यों है, इसके विशेष कारण"],
"decision_makers": ["पाए गए मुख्य संपर्कों के नाम और शीर्षक"],
"next_actions": ["कंपनी प्रोफ़ाइल के आधार पर अनुशंसित फॉलो-अप रणनीतियाँ"],
"content_insights": {
"website_quality": "सामग्री की समृद्धि के आधार पर पेशेवर/मूल/खराब",
"recent_activity": "किसी हालिया समाचार, फंडिंग, या अपडेट का उल्लेख",
"competitive_positioning": "वे प्रतिस्पर्धियों के मुकाबले कैसे स्थिति बना रहे हैं"
}
}
वृद्धि निर्धारण मानदंड (1-10):
9-10: बिल्कुल सही ICP फिट + पूर्ण संपर्क जानकारी + उच्च विकास संकेत + पेशेवर सामग्री
7-8: अच्छा ICP फिट + कुछ संपर्क जानकारी + स्थिर कंपनी + गुणवत्ता सामग्री
5-6: मध्यम फिट + सीमित संपर्क जानकारी + बुनियादी सामग्री + शोध की आवश्यकता
3-4: खराब फिट + न्यूनतम जानकारी + निम्न गुणवत्ता की सामग्री + गलत लक्ष्य मार्केट
1-2: योग्य नहीं + कोई संपर्क जानकारी नहीं + प्रोसेसिंग विफल + अप्रासंगिक
स्कोरिंग फैक्टर पर विचार करें:
सामग्री गुणवत्ता स्कोर: {{ $json.content_quality.content_richness_score }}/10
संपर्क जानकारी: {{ $json.content_quality.email_count }} ईमेल, {{ $json.content_quality.phone_count }} फोन
सामग्री की पूर्णता: {{ $json.content_quality.has_about_section }}, {{ $json.content_quality.has_services_section }}
प्रोसेसिंग की सफलता: {{ $json.processing_status }}
सामग्री की मात्रा: {{ $json.content_quality.word_count }} शब्द
निर्देश:
निकाली गई ईमेल और निकाली गई फोन से केवल पूर्व-निकाली गई संपर्क जानकारी का उपयोग करें
कंपनी नाम को प्रोसेस्ड कंपनी नाम क्षेत्र के आधार पर बनाएं, कच्ची सामग्री नहीं
लीड स्कोर निर्धारित करने के लिए सामग्री गुणवत्ता मेट्रिक्स को ध्यान में रखें
यदि प्रोसेसिंग स्थिति "SUCCESS" नहीं है, तो स्कोर को महत्वपूर्ण रूप से कम करें
किसी भी अनुपस्थित जानकारी के लिए null का उपयोग करें - डेटा को नहीं बनाएं
स्कोरिंग में संयम बरतें - अधिक स्कोर देने से बेहतर है कम स्कोर देना
संरचित सामग्री के आधार पर B2B प्रासंगिकता और ICP फिट पर ध्यान केंद्रित करें
प्रांप्ट संरचना फ़िल्टरिंग को अधिक विश्वसनीय बनाती है क्योंकि अब क्लॉड को लगातार, संरचित इनपुट प्राप्त होता है। इससे अगली चरण की आपकी कार्यप्रणाली में लीड स्कोर और बेहतर योग्यता निर्णयों में अधिक सटीकता आती है।
## चरण 7: क्लॉड एआई प्रतिक्रिया का पर्किंग
लीड्स को फ़िल्टर करने से पहले, हमें क्लॉड की JSON प्रतिक्रिया को सही ढंग से पर्क करना होगा जो मार्कडाउन स्वरूपण में लिपटा हो सकता है।
1. एआई एजेंट (क्लॉड) के बाद एक कोड नोड जोड़ें
2. क्लॉड की JSON प्रतिक्रिया को पर्क और साफ़ करने के लिए कॉन्फ़िगर करें
### 1. कोड नोड कॉन्फ़िगरेशन// क्लॉड एआई JSON प्रतिक्रिया को पर्क करने का कोड
console.log("=== क्लॉड एआई प्रतिक्रिया पर्क कर रहा है ===");
try {
// क्लॉड की प्रतिक्रिया "आउटपुट" फ़ील्ड में आती है
const claudeOutput = $json.output || "";
console.log("क्लॉड आउटपुट लंबाई:", claudeOutput.length);
console.log("क्लॉड आउटपुट पूर्वावलोकन:", claudeOutput.substring(0, 200));
// क्लॉड के मार्कडाउन प्रतिक्रिया से JSON निकालें
let jsonString = claudeOutput;
// यदि कोई मार्कडाउन बैकटिक्स मौजूद हैं तो हटा दें
if (jsonString.includes('json')) { const jsonMatch = jsonString.match(/json\s*([\s\S]?)\s/); if (jsonMatch && jsonMatch[1]) { jsonString = jsonMatch[1].trim(); } } else if (jsonString.includes('')) {
// केवल के लिए फॉलबैक
const jsonMatch = jsonString.match(/\s*([\s\S]?)\s```/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
}
// अतिरिक्त सफाई
jsonString = jsonString.trim();
console.log("निकाली गई JSON स्ट्रिंग:", jsonString.substring(0, 300));
// JSON को पर्क करें
const leadData = JSON.parse(jsonString);
console.log("सफलतापूर्वक लीड डेटा को पर्क किया:", leadData.company_name);
console.log("लीड स्कोर:", leadData.lead_score);
Here’s the translated text in Hindi:
```javascript
console.log("संपर्क ईमेल:", leadData.contact_email);
// मान्यता और डेटा सफाई
const cleanedLead = {
company_name: leadData.company_name || "अज्ञात",
industry: leadData.industry || null,
company_size: leadData.company_size || null,
location: leadData.location || null,
contact_email: leadData.contact_email || null,
phone: leadData.phone || null,
key_services: Array.isArray(leadData.key_services) ? leadData.key_services : [],
target_market: leadData.target_market || null,
technologies: Array.isArray(leadData.technologies) ? leadData.technologies : [],
funding_stage: leadData.funding_stage || null,
business_model: leadData.business_model || null,
social_presence: leadData.social_presence || { linkedin: null, twitter: null },
lead_score: typeof leadData.lead_score === 'number' ? leadData.lead_score : 0,
qualification_reasons: Array.isArray(leadData.qualification_reasons) ? leadData.qualification_reasons : [],
decision_makers: Array.isArray(leadData.decision_makers) ? leadData.decision_makers : [],
next_actions: Array.isArray(leadData.next_actions) ? leadData.next_actions : [],
content_insights: leadData.content_insights || {},
// फ़िल्टर करने के लिए मेटा जानकारी
is_qualified: leadData.lead_score >= 6 && leadData.contact_email !== null,
has_contact_info: !!(leadData.contact_email || leadData.phone),
processing_timestamp: new Date().toISOString(),
claude_processing_status: "सफल"
};
console.log(✅ लीड प्रोसेस किया गया: ${cleanedLead.company_name} (स्कोर: ${cleanedLead.lead_score}, योग्य: ${cleanedLead.is_qualified}));
return cleanedLead;
} catch (error) {
console.error("❌ क्लॉड प्रतिक्रिया को पार्स करते समय त्रुटि:", error);
console.error("कच्चा आउटपुट:", $json.output);
// संरचित त्रुटि प्रतिक्रिया
return {
company_name: "क्लॉड पार्सिंग त्रुटि",
industry: null,
company_size: null,
location: null,
contact_email: null,
phone: null,
key_services: [],
target_market: null,
technologies: [],
funding_stage: null,
business_model: null,
social_presence: { linkedin: null, twitter: null },
lead_score: 0,
qualification_reasons: [क्लॉड पार्सिंग विफल: ${error.message}],
decision_makers: [],
next_actions: ["क्लॉड प्रतिक्रिया पार्सिंग ठीक करें", "JSON प्रारूप की जांच करें"],
content_insights: {},
is_qualified: false,
has_contact_info: false,
processing_timestamp: new Date().toISOString(),
claude_processing_status: "विफल",
parsing_error: error.message,
raw_claude_output: $json.output || "कोई आउटपुट प्राप्त नहीं हुआ"
};
}
// क्यों क्लॉड प्रतिक्रिया पार्सिंग जोड़ें?
- मार्कडाउन हैंडलिंग: क्लॉड उत्तरों से JSON प्रारूप को हटाता है
- डेटा मान्यता: सुनिश्चित करता है कि सभी क्षेत्रों के पास उचित प्रकार और डिफ़ॉल्ट हैं
- त्रुटि वसूली: JSON पार्सिंग विफलताओं को व्यवस्थित रूप से संभालता है
- फ़िल्टरिंग तैयारी: आसान फ़िल्टरिंग के लिए अनुक्रमित क्षेत्रों को जोड़ता है
- डिबग समर्थन: समस्या निवारण के लिए व्यापक लॉगिंग
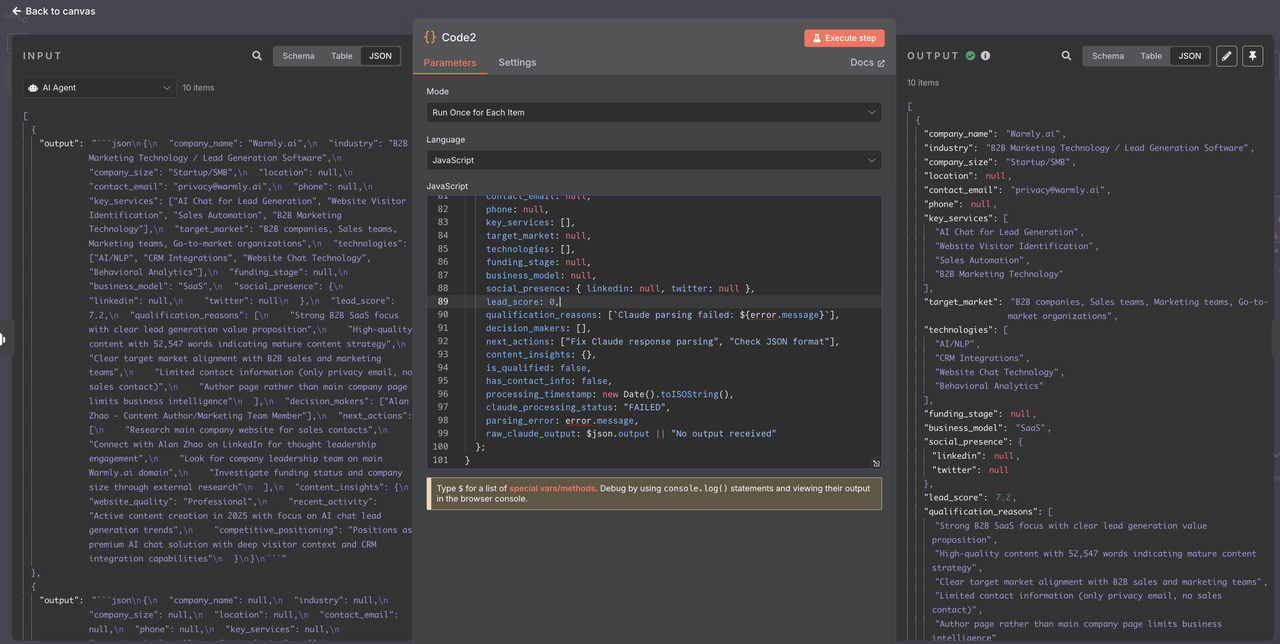
## चरण 8: लीड फ़िल्टरिंग और गुणवत्ता नियंत्रण
पार्स किए गए और मान्य डेटा का उपयोग करके योग्यता स्कोर और डेटा पूर्णता के आधार पर लीड को फ़िल्टर करें।
1. क्लॉड प्रतिक्रिया पार्सर के बाद एक IF नोड जोड़ें
2. सुधारित योग्यता मानदंड स्थापित करें
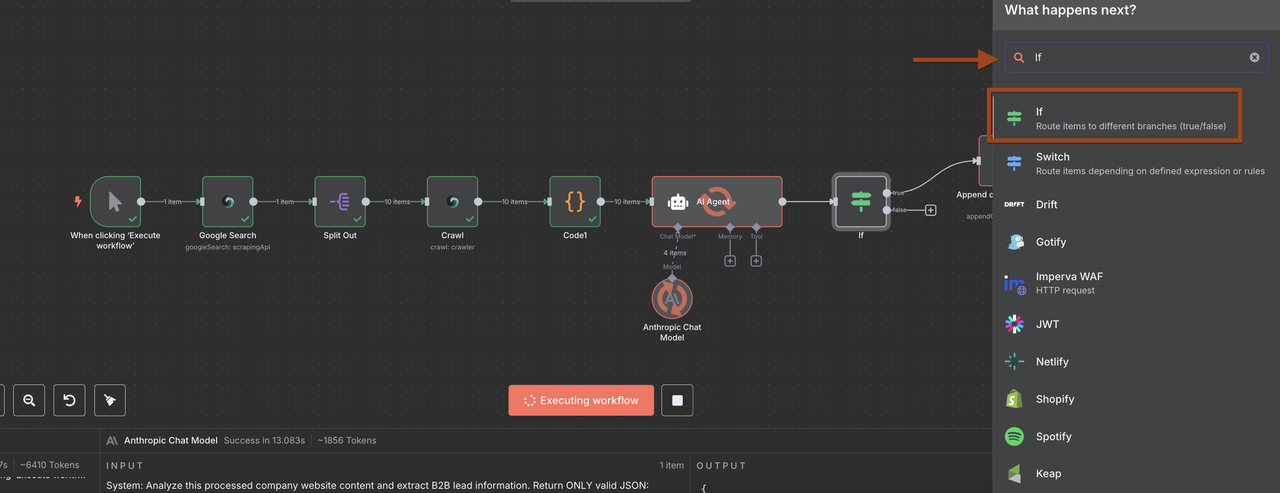
### 1. नया IF नोड कॉन्फ़िगरेशन
अब जब डेटा सही ढंग से पार्स किया गया है, तो IF नोड में इन शर्तों का उपयोग करें:
**1: कई शर्तें जोड़ें**
**शर्त 1:**
- फ़ील्ड: {{ $json.lead_score }}
- ऑपरेटर: के बराबर या अधिक
- मान: 6
**शर्त 2:**
- फ़ील्ड: {{ $json.claude_processing_status }}
- ऑपरेटर: के बराबर
- मान: सफल
विकल्प: आवश्यकतानुसार प्रकार रूपांतरित करें
- सही
### 2. फ़िल्टरिंग लाभ
- गुणवत्ता आश्वासन: केवल योग्य लीड संग्रहण के लिए आगे बढ़ते हैं
- लागत अनुकूलन: निम्न गुणवत्ता वाली लीड को संसाधित करने से रोकता है
- डेटा अखंडता: सुनिश्चित करता है कि पार्स किया गया डेटा संग्रहण से पहले मान्य है
- डिबग क्षमता: विफल पार्सिंग को पकड़ लिया गया है और लॉग किया गया है
## चरण 9: Google शीट्स में लीड संग्रहण
योग्य लीड को आसान पहुंच और प्रबंधन के लिए एक Google शीट्स डेटाबेस में संग्रहीत करें।
1. फ़िल्टर के बाद एक Google शीट्स नोड जोड़ें
2. नए लीड को जोड़ने के लिए कॉन्फ़िगर करें
हालांकि, आप चाहें तो डेटा को अपने अनुसार प्रबंधित कर सकते हैं।
**Google शीट्स सेटअप:**- "B2B लीड्स डेटाबेस" नामक एक स्प्रेडशीट बनाएँ
- कॉलम स्थापित करें:
- कंपनी का नाम
- उद्योग
- कंपनी का आकार
- स्थान
- संपर्क ईमेल
- फोन
- वेबसाइट
- लीड स्कोर
- जोड़ा गया दिनांक
- योग्यता नोट्स
- अगले क्रियाएँ
मेरी ओर से, मैं सीधे एक डिस्कॉर्ड वेबहुक का उपयोग करने का चयन करता हूँ
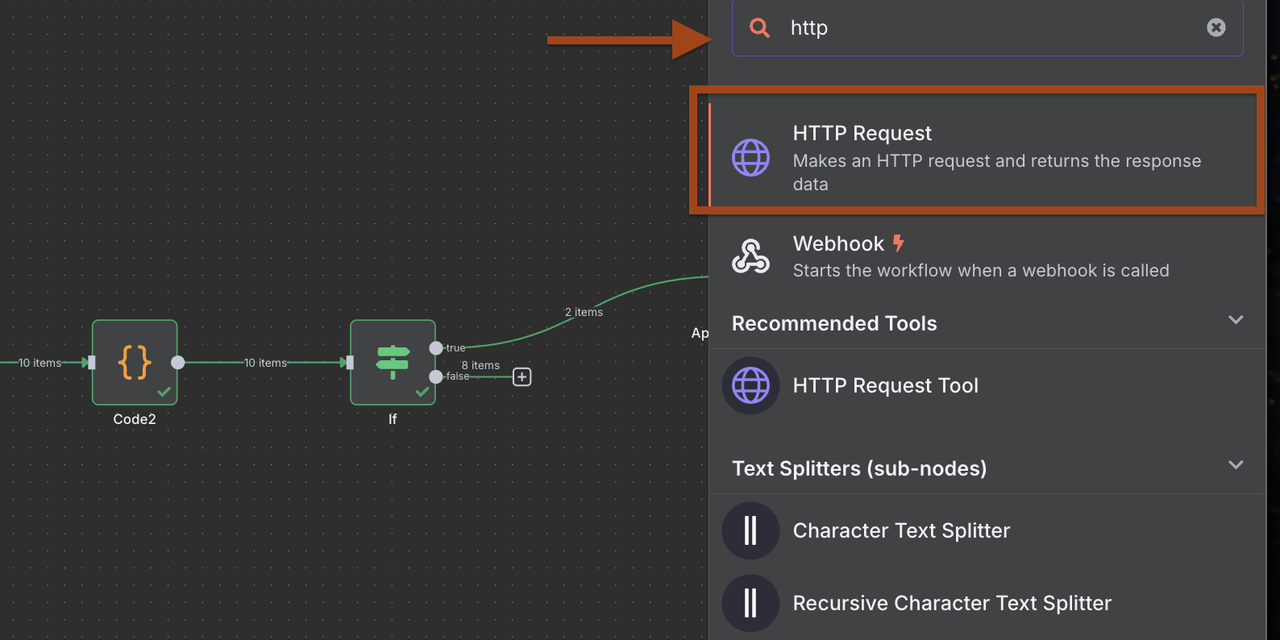
कदम 9-2: डिस्कॉर्ड सूचनाएँ (अन्य सेवाओं के लिए अनुकूलित)
नए योग्य लीड के लिए वास्तविक समय में सूचनाएँ भेजें।
- डिस्कॉर्ड वेबहुक के लिए एक HTTP अनुरोध नोड जोड़ें
- डिस्कॉर्ड-विशिष्ट पे लोड प्रारूप कॉन्फ़िगर करें
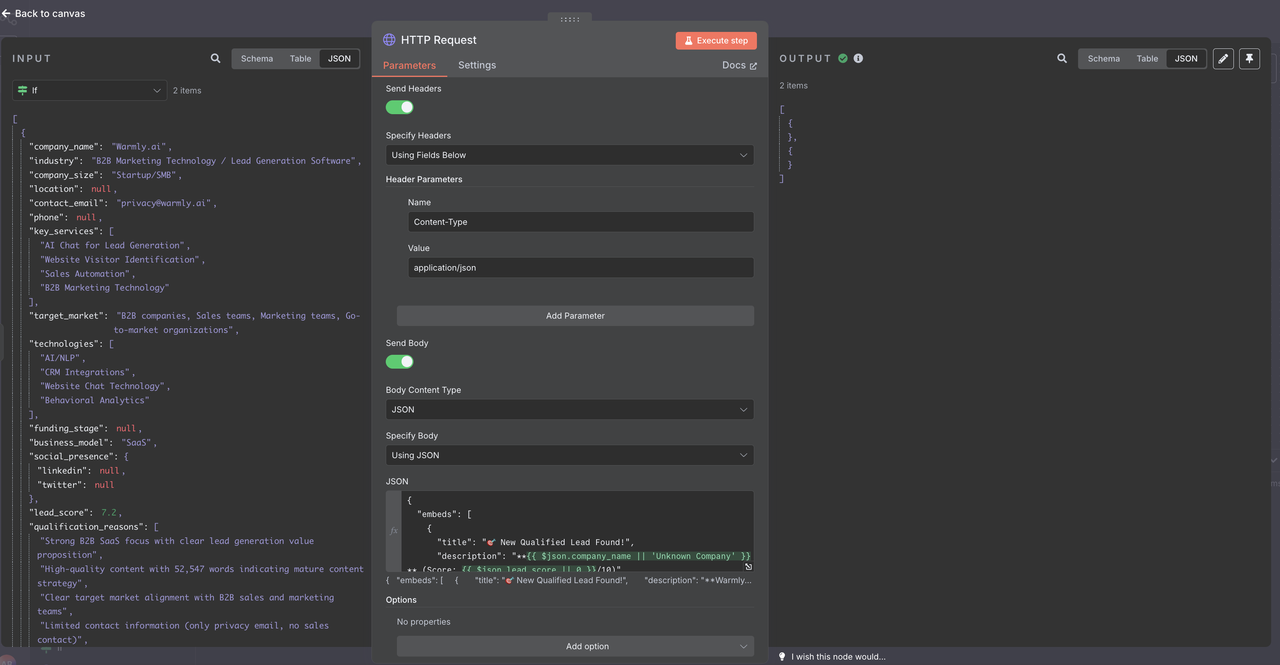
डिस्कॉर्ड वेबहुक कॉन्फ़िगरेशन:
- विधि: POST
- URL: आपका डिस्कॉर्ड वेबहुक URL
- हेडर: कंटेंट-टाइप: एप्लीकेशन/जेसन
डिस्कॉर्ड संदेश पे लोड:
{
"embeds": [
{
"title": "🎯 नया योग्य लीड मिला!",
"description": "**{{ $json.company_name || 'अज्ञात कंपनी' }}** (स्कोर: {{ $json.lead_score || 0 }}/10)",
"color": 3066993,
"fields": [
{
"name": "उद्योग",
"value": "{{ $json.industry || 'निर्दिष्ट नहीं' }}",
"inline": true
},
{
"name": "आकार",
"value": "{{ $json.company_size || 'निर्दिष्ट नहीं' }}",
"inline": true
},
{
"name": "स्थान",
"value": "{{ $json.location || 'निर्दिष्ट नहीं' }}",
"inline": true
},
{
"name": "संपर्क",
"value": "{{ $json.contact_email || 'कोई ईमेल नहीं मिला' }}",
"inline": false
},
{
"name": "फोन",
"value": "{{ $json.phone || 'कोई फोन नहीं मिला' }}",
"inline": false
},
{
"name": "सेवाएँ",
"value": "{{ $json.key_services && $json.key_services.length > 0 ? $json.key_services.slice(0, 3).join(', ') : 'निर्दिष्ट नहीं' }}",
"inline": false
},
{
"name": "वेबसाइट",
"value": "[वेबसाइट पर जाएँ]({{ $node['Code2'].json.url || '#' }})",
"inline": false
},
{
"name": "क्यों योग्य",
"value": "{{ $json.qualification_reasons && $json.qualification_reasons.length > 0 ? $json.qualification_reasons.slice(0, 2).join(' • ') : 'मानक योग्यता मापदंड पूरे हुए' }}",
"inline": false
}
],
"footer": {
"text": "n8n लीड जनरेशन वर्कफ़्लो द्वारा उत्पन्न"
},
"timestamp": ""
}
]
}परिणाम
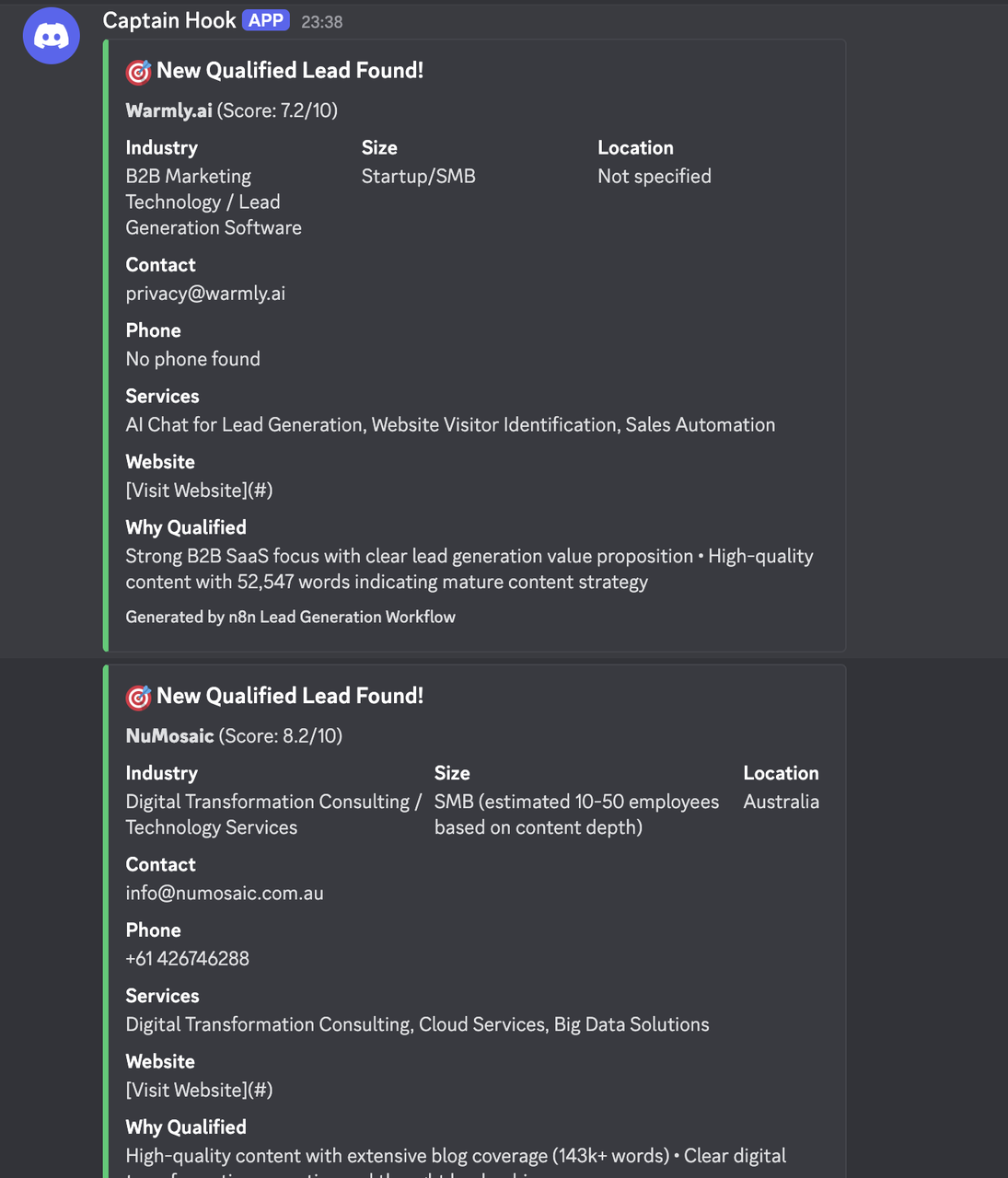
उद्योग-विशिष्ट कॉन्फ़िगरेशन
SaaS/सॉफ्टवेयर कंपनियाँ
खोज प्रश्न:
"SaaS कंपनियाँ" "B2B सॉफ्टवेयर" "Enterprise software"
"क्लाउड सॉफ्टवेयर" "API" "डेवलपर्स" "सदस्यता मॉडल"
"सॉफ्टवेयर को सेवा के रूप में" "प्लेटफ़ॉर्म" "इंटिग्रेशन"योग्यता मानदंड:
- कर्मचारी संख्या: 20-500
- आधुनिक तकनीकी ढांचा का उपयोग
- API दस्तावेज़ीकरण है
- GitHub/तकनीकी सामग्री पर सक्रिय
मार्केटिंग एजेंसियाँ
खोज प्रश्न:
"डिजिटल मार्केटिंग एजेंसी" "B2B मार्केटिंग" "Enterprise clients"
"मार्केटिंग स्वचालन" "डिमांड जनरेशन" "लीड जनरेशन"
"सामग्री मार्केटिंग एजेंसी" "विकास मार्केटिंग" "प्रदर्शन मार्केटिंग"योग्यता मानदंड:
- ग्राहक केस अध्ययन उपलब्ध
- टीम का आकार: 10-100
- B2B में विशेषज्ञता
- सक्रिय सामग्री विपणन
ई-कॉमर्स/रिटेल
खोज प्रश्न:
"ईकॉमर्स कंपनियाँ" "ऑनलाइन रिटेल" "D2C ब्रांड"
"Shopify स्टोर" "WooCommerce" "ईकॉमर्स प्लेटफॉर्म"
"ऑनलाइन मार्केटप्लेस" "डिजिटल वाणिज्य" "रिटेल तकनीक"योग्यता मानदंड:
- राजस्व संकेतक
- मल्टी-चैनल उपस्थिति
- प्रौद्योगिकी प्लेटफॉर्म का उल्लेख
- विकास की प्रवृत्तियों के संकेत
डेटा प्रबंधन और विश्लेषण
लीड डेटाबेस स्कीमा
अपने गूगल शीट्स को अधिकतम उपयोगिता के लिए संरचना करें:
मुख्य लीड जानकारी:
- कंपनी का नाम, उद्योग, आकार, स्थान
- संपर्क ईमेल, फोन, वेबसाइट
- लीड स्कोर, जोड़ा गया दिनांक, स्रोत प्रश्न
योग्यता डेटा:
- योग्यता कारण, निर्णय निर्माता
- अगले क्रियाएँ, फॉलो-अप दिनांक
- बिक्री प्रतिनिधि असाइन, लीड स्थिति
समृद्धि क्षेत्र:
- LinkedIn URL, सोशल मीडिया उपस्थिति
- उपयोग की गई तकनीकें, फंडिंग चरण
- प्रतियोगी, हाल की खबरें
विश्लेषण और रिपोर्टिंग
कार्यप्रवाह प्रदर्शन को अतिरिक्त शीट्स के साथ ट्रैक करें:
दैनिक सारांश शीट:
- प्रति दिन उत्पन्न लीड
- औसत लीड स्कोर
- शीर्ष उद्योग पाए गए
- रूपांतरण दरें
खोज प्रदर्शन:
- सबसे अच्छे प्रदर्शन वाले प्रश्न
- भौगोलिक वितरण
- कंपनी के आकार का ब्रेकडाउन
- उद्योग के अनुसार सफलता दर
आरओआई ट्रैकिंग:
- प्रति लीड लागत (API की लागत)
- संपर्क करने का समय
- अवसर में रूपांतरण
- राजस्व एयरट्रिब्यूशन
निष्कर्ष
यह बुद्धिमान B2B लीड जनरेशन वर्कफ़्लो आपकी बिक्री संभावनाओं को परिवर्तित करता है, संभावित ग्राहकों की खोज, योग्यता, और संगठन को स्वचालित करके। Google खोज को बुद्धिमान क्रॉलिंग और AI विश्लेषण के साथ मिलाकर, आप अपनी बिक्री पाइपलाइन बनाने के लिए एक व्यवस्थित दृष्टिकोण बनाते हैं।
यह वर्कफ़्लो आपकी विशेष उद्योग, कंपनी आकार लक्ष्यों, और योग्यता मानदंडों के अनुसार अनुकूलित होता है, जबकि AI-संचालित विश्लेषण के माध्यम से उच्च डेटा गुणवत्ता बनाए रखता है। सही सेटअप और निगरानी के साथ, यह प्रणाली आपके बिक्री टीम के लिए योग्य लीड का एक लगातार स्रोत बन जाती है।
Google शीट्स के साथ एकीकरण बिक्री टीमों के लिए एक सुलभ डेटाबेस प्रदान करता है, जबकि Discord सूचनाएं उच्च-मूल्य संभावनाओं की तात्कालिक जागरूकता सुनिश्चित करती हैं। मॉड्यूलर डिज़ाइन विभिन्न सूचनाओं की सेवाओं, CRM सिस्टम, और डेटा संग्रहण समाधानों के अनुरूप अनुकूलन की अनुमति देता है।
Scrapeless यथासंभव कानूनों और विनियमों का सख्ती से पालन करता है, केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करता है जो वेबसाइट की सेवा की शर्तों और गोपनीयता नीतियों के अनुसार है। यह समाधान वैध व्यावसायिक बुद्धिमत्ता और मार्केटिंग अनुकूलन के उद्देश्यों के लिए डिज़ाइन किया गया है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


