
एक AI-संचालित अनुसंधान सहायक बनाएं जिसमें लाइनर + स्क्रेपलेस + क्लॉड हो।
Advanced Data Extraction Specialist
आधुनिक टीमों को सूचित निर्णय लेने के लिए विश्वसनीय डेटा तक तत्काल पहुँच की आवश्यकता होती है। चाहे आप प्रतिस्पर्धियों पर शोध कर रहे हों, प्रवृत्तियों का विश्लेषण कर रहे हों, या बाजार की खुफिया जानकारी जमा कर रहे हों, मैनुअल डेटा संग्रह आपके कार्यप्रवाह को धीमा कर देता है और आपके विकास की गति को तोड़ देता है।
लीनर के प्रोजेक्ट प्रबंधन प्लेटफॉर्म को स्क्रेपलेस के शक्तिशाली डेटा निकासी एपीआई और क्लॉड एआई की विश्लेषणात्मक क्षमताओं के साथ मिलाकर, आप एक बुद्धिमान अनुसंधान सहायक बना सकते हैं जो सीधे आपके लीनर मामलों में सरल आदेशों का जवाब देता है।
यह एकीकरण आपके लीनर कार्यक्षेत्र को एक स्मार्ट कमांड सेंटर में बदल देता है, जहाँ /search प्रतियोगी विश्लेषण या /trends एआई बाजार टाइप करने पर स्वचालित रूप से व्यापक डेटा संग्रह और एआई-प्रेरित विश्लेषण ट्रिगर होता है—सभी को आपके लीनर मामलों में संरचित टिप्पणियों के रूप में वापस प्रस्तुत किया जाता है।
लीनर + स्क्रेपलेस + क्लॉड क्यों चुनें?
लीनर: आधुनिक विकास कार्यक्षेत्र
लीनर टीम सहयोग और कार्य प्रबंधन के लिए सर्वोत्तम इंटरफ़ेस प्रदान करता है:
- मुद्दा-प्रेरित कार्यप्रवाह: विकास प्रक्रियाओं के साथ स्वाभाविक एकीकरण
- वास्तविक समय में अपडेट: त्वरित सूचनाएँ और समन्वित टीम संचार
- वेबहुक और एपीआई: बाहरी उपकरणों के साथ शक्तिशाली स्वचालन क्षमताएँ
- परियोजना ट्रैकिंग: अंतर्निहित विश्लेषिकी और प्रगति की निगरानी
- टीम सहयोग: निर्बाध टिप्पणी और चर्चा सुविधाएँ
स्क्रेपलेस: उद्यम-मानक डेटा निकासी
स्क्रेपलेस कई स्रोतों में विश्वसनीय, स्केलेबल डेटा निकासी प्रदान करता है:
- गूगल सर्च: सभी परिणाम प्रकारों में गूगल SERP डेटा का व्यापक निकासी सक्षम बनाता है।
- गूगल ट्रेंड्स: लोकप्रियता, क्षेत्रीय रुचि, और संबंधित खोजों सहित गूगल से कीवर्ड ट्रेंड डेटा प्राप्त करता है।
- यूनिवर्सल स्क्रैपिंग एपीआई: JS-Render वेबसाइटों से डेटा तक पहुँच और निकासी करें जो आमतौर पर बॉट्स को ब्लॉक करती हैं।
- क्रॉल: एक वेबसाइट और उसकी लिंक की गई पृष्ठों को क्रॉल करें और विस्तृत डेटा निकाला जाए।
- स्क्रैप: एक ही वेबपृष्ठ से जानकारी निकालें।
क्लॉड एआई: बुद्धिमान डेटा विश्लेषण
क्लॉड एआई कच्चे डेटा को कार्यान्वयन योग्य अंतर्दृष्टियों में बदलता है:
- उन्नत तर्क: विकसित विश्लेषण और पैटर्न पहचान
- संरचित आउटपुट: लीनर टिप्पणियों के लिए साफ, प्रारूपित प्रतिक्रियाएँ
- संदर्भ जागरूकता: व्यवसाय के संदर्भ और उपयोगकर्ता के इरादे को समझता है
- कार्यान्वयन योग्य अंतर्दृष्टियाँ: सिफारिशें और अगले कदम प्रदान करता है
- डेटा संश्लेषण: कई डेटा स्रोतों को एक सुसंगत विश्लेषण में मिलाता है
उपयोग के मामले
प्रतिस्पर्धात्मक खुफिया कमांड सेंटर
तत्काल प्रतियोगी शोध
- बाजार स्थिति विश्लेषण: स्वचालित प्रतियोगी वेबसाइट क्रॉलिंग और विश्लेषण
- प्रवृत्ति निगरानी: प्रतियोगी उल्लेखों और ब्रांड भावना परिवर्तनों को ट्रैक करें
- उत्पाद लॉन्च पहचान: जब प्रतिस्पर्धियों ने नए फीचर्स लॉन्च किए हैं, तब पहचान करें
- रणनीतिक अंतर्दृष्टियाँ: प्रतियोगी स्थिति का एआई-प्रेरित विश्लेषण
कमांड उदाहरण:
/search "प्रतिस्पर्धी उत्पाद लॉन्च" 2024
/trends प्रतियोगी-ब्रांड-नाम
/crawl https://competitor.com/productsबाजार अनुसंधान स्वचालन
वास्तविक समय में बाजार खुफिया
- उद्योग प्रवृत्ति विश्लेषण: बाजार सेगमेंट के लिए स्वचालित गूगल ट्रेंड्स मॉनिटरिंग
- उपभोक्ता भावना: उत्पाद श्रेणियों के लिए खोज प्रवृत्ति विश्लेषण
- बाजार अवसर पहचान: एआई-प्रेरित बाजार अंतर विश्लेषण
- निवेश अनुसंधान: स्टार्टअप और उद्योग फंडिंग प्रवृत्ति विश्लेषण
कमांड उदाहरण:
/trends "कृत्रिम बुद्धिमत्ता बाजार"
/search "SaaS स्टार्टअप फंडिंग 2024"
/crawl https://techcrunch.com/category/startupsउत्पाद विकास अनुसंधान
फीचर अनुसंधान और वैधता
- उपभोक्ता आवश्यकता विश्लेषण: उत्पाद सुविधाओं के लिए खोज प्रवृत्ति विश्लेषण
- तकनीकी अनुसंधान: स्वचालित दस्तावेजीकरण और एपीआई अनुसंधान
- सर्वश्रेष्ठ प्रथा खोज: कार्यान्वयन पैटर्न के लिए उद्योग नेताओं को क्रॉल करें
- बाजार वैधता: उत्पाद- बाजार फिट आकलन के लिए प्रवृत्ति विश्लेषण
कमांड उदाहरण:
/search "उपयोगकर्ता प्रमाणीकरण सर्वोत्तम प्रथाएँ"
/trends "मोबाइल ऐप फीचर्स"
/crawl https://docs.stripe.com/apiकार्यान्वयन गाइड
चरण 1: लीनर कार्यक्षेत्र सेटअप
अपने लीनर वातावरण को तैयार करें
-
अपने लीनर कार्यक्षेत्र तक पहुँचें
- linear.app पर जाएँ और अपने कार्यक्षेत्र में लॉगिन करें
- वेबहुक कॉन्फ़िगरेशन के लिए प्रशासनिक अनुमतियाँ सुनिश्चित करें
- अनुसंधान स्वचालन के लिए एक परियोजना बनाएँ या चुनें
-
लीनर एपीआई टोकन उत्पन्न करें
- लीनर सेटिंग्स > एपीआई > व्यक्तिगत एपीआई टोकन पर जाएँ
- उचित अनुमतियों के साथ "टोकन बनाएं" पर क्लिक करें
- n8n कॉन्फ़िगरेशन में उपयोग के लिए टोकन की कॉपी करें
चरण 2: n8n कार्यप्रवाह सेटअप
अपना n8n स्वचालन वातावरण बनाएं
- n8n उदाहरण सेट करें
- n8n क्लाउड का उपयोग करें या स्वयं-होस्ट करें (नोट: स्वयं-होस्टिंग के लिए ngrok सेटअप आवश्यक है; इस गाइड के लिए, हम n8n क्लाउड का उपयोग करेंगे)
- नया वर्कफ़्लो बनाने के लिए Linear के लिए
- प्रदान किया गया वर्कफ़्लो JSON आयात करें
- लाइनर ट्रिगर कॉन्फ़िगर करें
- अपना लाइनर क्रेडेंशियल API टोकन का उपयोग करके जोड़ें
- समस्या घटनाओं के लिए सुनने के लिए एक वेबहुक सेट करें
- आवश्यकतानुसार टीम आईडी कॉन्फ़िगर करें और संसाधन फ़िल्टर लागू करें
कदम 3: Scrapeless एकीकरण सेटअप
अपने Scrapeless खाते को कनेक्ट करें
- Scrapeless क्रेडेंशियल प्राप्त करें
- scrapeless.com पर साइन अप करें
- डैशबोर्ड > API कुंजी पर जाएं
- n8n कॉन्फ़िगरेशन के लिए अपना API टोकन कॉपी करें
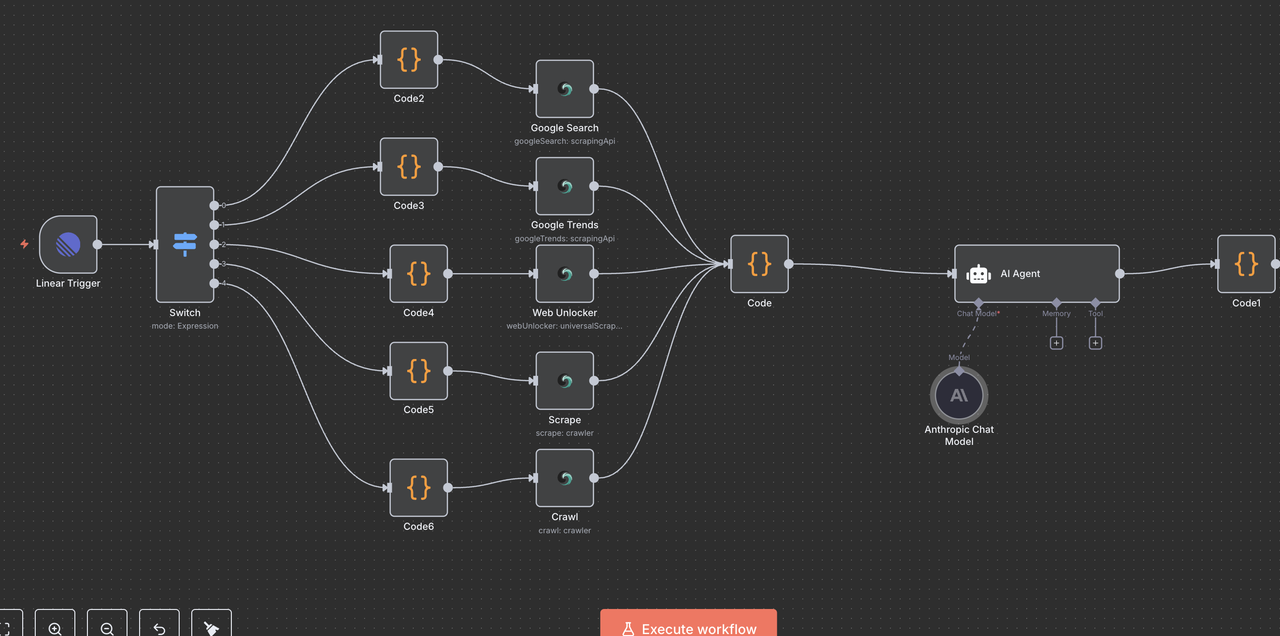
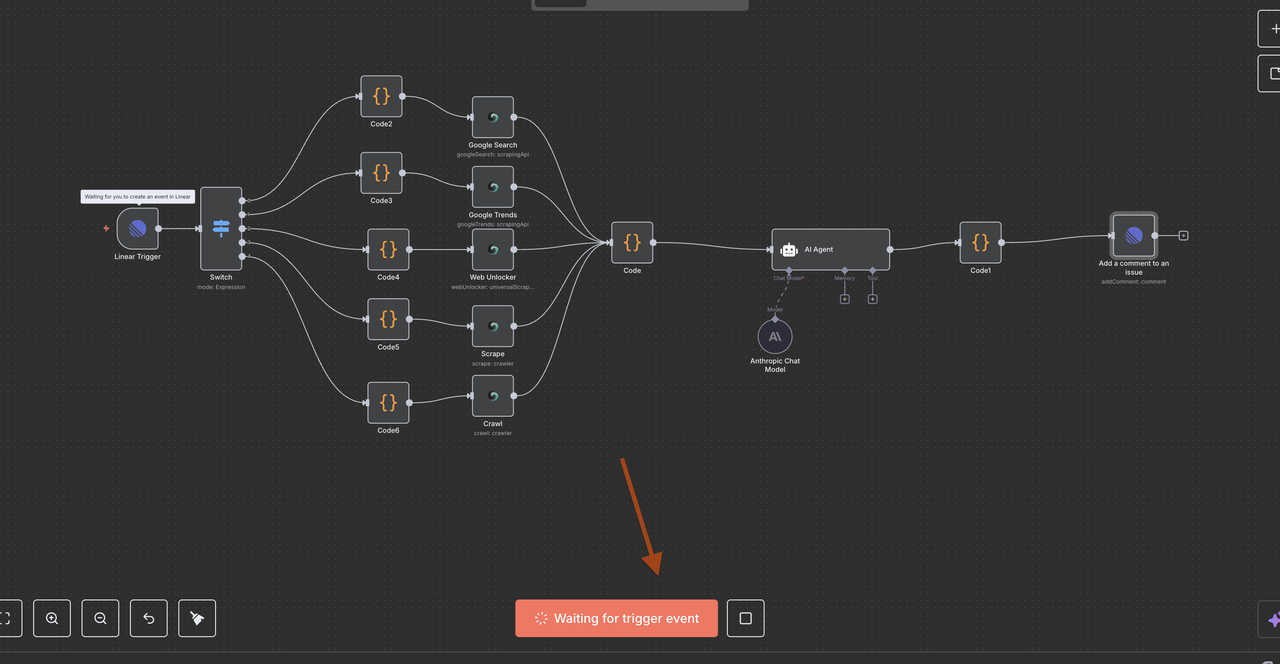
वर्कफ़्लो आर्किटेक्चर को समझना
आइए वर्कफ़्लो के प्रत्येक घटक के माध्यम से चरण दर चरण चलें, यह समझाते हैं कि प्रत्येक नोड क्या करता है और वे एक साथ कैसे काम करते हैं।
चरण 4: लाइनर ट्रिगर नोड (प्रवेश बिंदु)
शुरुआत का बिंदु: लाइनर ट्रिगर
लाइनर ट्रिगर हमारे वर्कफ़्लो का प्रवेश बिंदु है। यह नोड:
यह क्या करता है:
- लाइनर से वेबहुक घटनाओं के लिए सुनता है जब भी मुद्दे बनाए या अपडेट किए जाते हैं
- शीर्षक, विवरण, टीम आईडी और अन्य मेटाडेटा सहित पूर्ण समस्या डेटा कैप्चर करता है
- केवल तब ट्रिगर होता है जब विशिष्ट घटनाएँ होती हैं (जैसे, समस्या बनाई गई, समस्या अपडेट की गई, टिप्पणी बनाई गई)
कॉन्फ़िगरेशन विवरण:
- टीम आईडी: आपके विशेष लाइनर कार्यक्षेत्र टीम से लिंक करता है
- संसाधन:
issue,comment, औरreactionघटनाओं की निगरानी करने के लिए सेट करें - वेबहुक URL: n8n द्वारा स्वचालित रूप से उत्पन्न होता है और इसे लाइनर की वेबहुक सेटिंग में जोड़ा जाना चाहिए
यह क्यों आवश्यक है:
यह नोड आपके लाइनर मुद्दों को स्वचालन ट्रिगर्स में बदलता है।
उदाहरण के लिए, जब कोई व्यक्ति एक समस्या शीर्षक में /search competitor analysis टाइप करता है, तो वेबहुक उस डेटा को असली समय में n8n को भेजता है।
चरण 5: स्विच नोड (कमांड राउटर)
बुद्धिमान कमांड पहचान और राउटिंग
स्विच नोड "मस्तिष्क" के रूप में कार्य करता है जो यह निर्धारित करता है कि मुद्दे के शीर्षक में कमांड के आधार पर किस प्रकार का शोध करना है।
यह कैसे काम करता है:
// कमांड पहचान और राउटिंग लॉजिक
{
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/search') ? 0 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/trends') ? 1 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/unlock') ? 2 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/scrape') ? 3 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/crawl') ? 4 :
-1
}रूट व्याख्याएँ
- आउटपुट 0 (
/search): वेब खोज परिणामों के लिए Google सर्च API की तरफ राउट करता है - आउटपुट 1 (
/trends): प्रवृत्ति विश्लेषण के लिए Google ट्रेंड्स API की तरफ राउट करता है - आउटपुट 2 (
/unlock): सुरक्षित सामग्री तक पहुंच के लिए Web Unlocker की तरफ राउट करता है - आउटपुट 3 (
/scrape): एकल-पृष्ठ सामग्री निकालने के लिए Scraper की तरफ राउट करता है - आउटपुट 4 (
/crawl): बहु-पृष्ठ वेबसाइट की खंडन के लिए Crawler की तरफ राउट करता है - आउटपुट -1: कोई कमांड नहीं मिली, वर्कफ़्लो स्वतः समाप्त होता है
स्विच नोड कॉन्फ़िगरेशन
- मोड: गतिशील राउटिंग के लिए
"Expression"पर सेट करें - आउटपुट की संख्या:
5(प्रत्येक कमांड प्रकार के लिए एक) - व्यक्तिकरण: जावास्क्रिप्ट कोड राउटिंग लॉजिक निर्धारित करता है
एपीआई प्रोसेसिंग के लिए कमांड तैयार करना
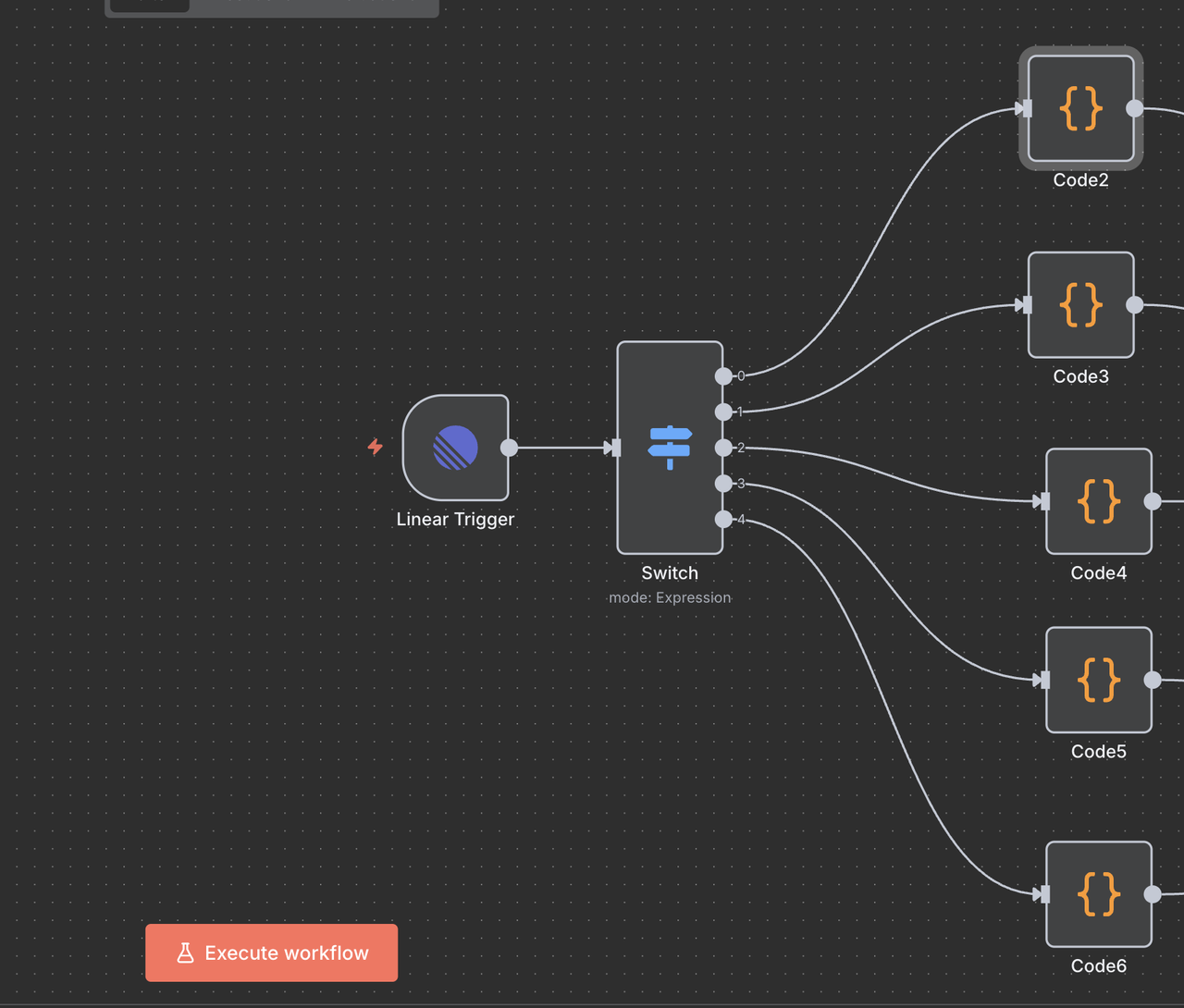
प्रत्येक मार्ग में एक कोड नोड शामिल होता है जो स्क्रैपलेस एपीआई को कॉल करने से पहले समस्या शीर्षक से कमांड को साफ करता है।
प्रत्येक कोड नोड क्या करता है:
js
// एपीआई प्रोसेसिंग के लिए शीर्षक से कमांड साफ करें
const originalTitle = $json.data.title;
let cleanTitle = originalTitle;
// पहचान की गई कमांड के आधार पर कमांड प्रीफिक्स हटा दें
if (originalTitle.toLowerCase().includes('/search')) {
cleanTitle = originalTitle.replace(/\/search/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/trends')) {
cleanTitle = originalTitle.replace(/\/trends/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/unlock')) {
cleanTitle = originalTitle.replace(/\/unlock/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/scrape')) {
cleanTitle = originalTitle.replace(/\/scrape/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/crawl')) {
cleanTitle = originalTitle.replace(/\/crawl/gi, '').trim();
}
return {
data: {
...($json.data),
title: cleanTitle
}
};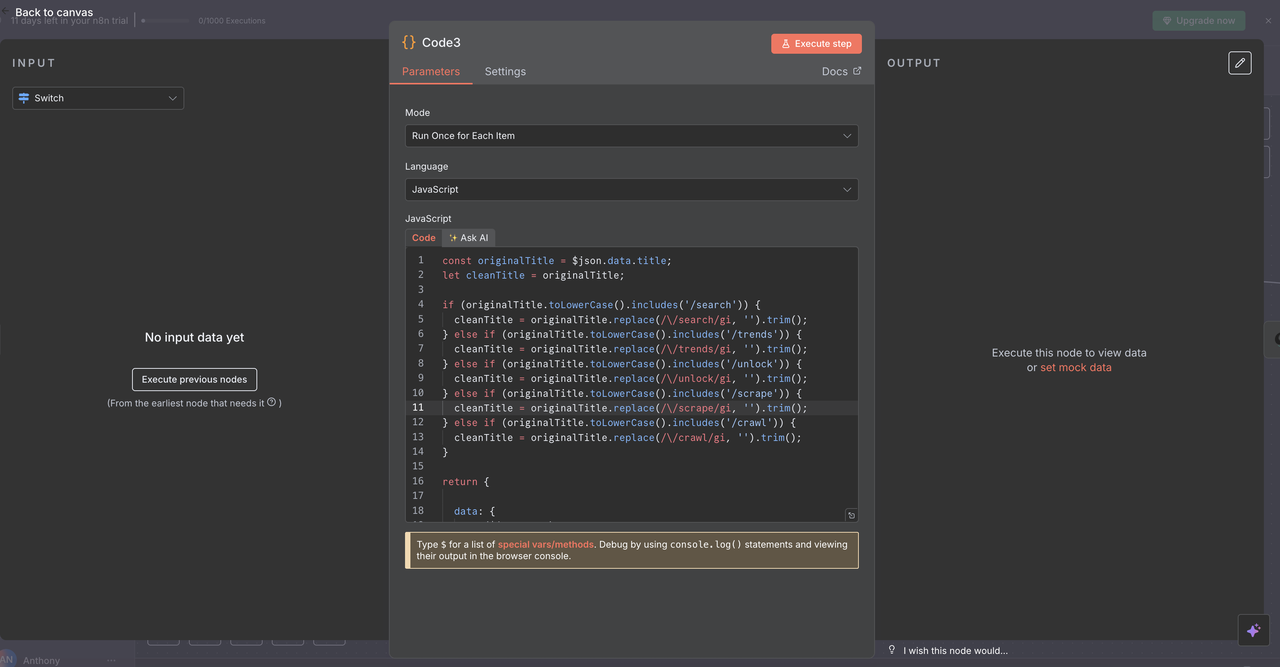
उदाहरण ट्रांसफॉर्मेशन
/search competitor analysis→competitor analysis/trends AI market growth→AI market growth/unlock https://example.com→https://example.com
यह कदम महत्वपूर्ण क्यों है
स्क्रैपलेस एपीआई को सही ढंग से कार्य करने के लिए कमांड प्रीफिक्स के बिना साफ क्वेरी की आवश्यकता है।
यह सुनिश्चित करता है कि एपीआई को भेजा गया डेटा सटीक और व्याख्या करने योग्य हो, जिससे स्वचालन की विश्वसनीयता में सुधार होता है।
कदम 7: स्क्रैपलेस ऑपरेशन नोड्स
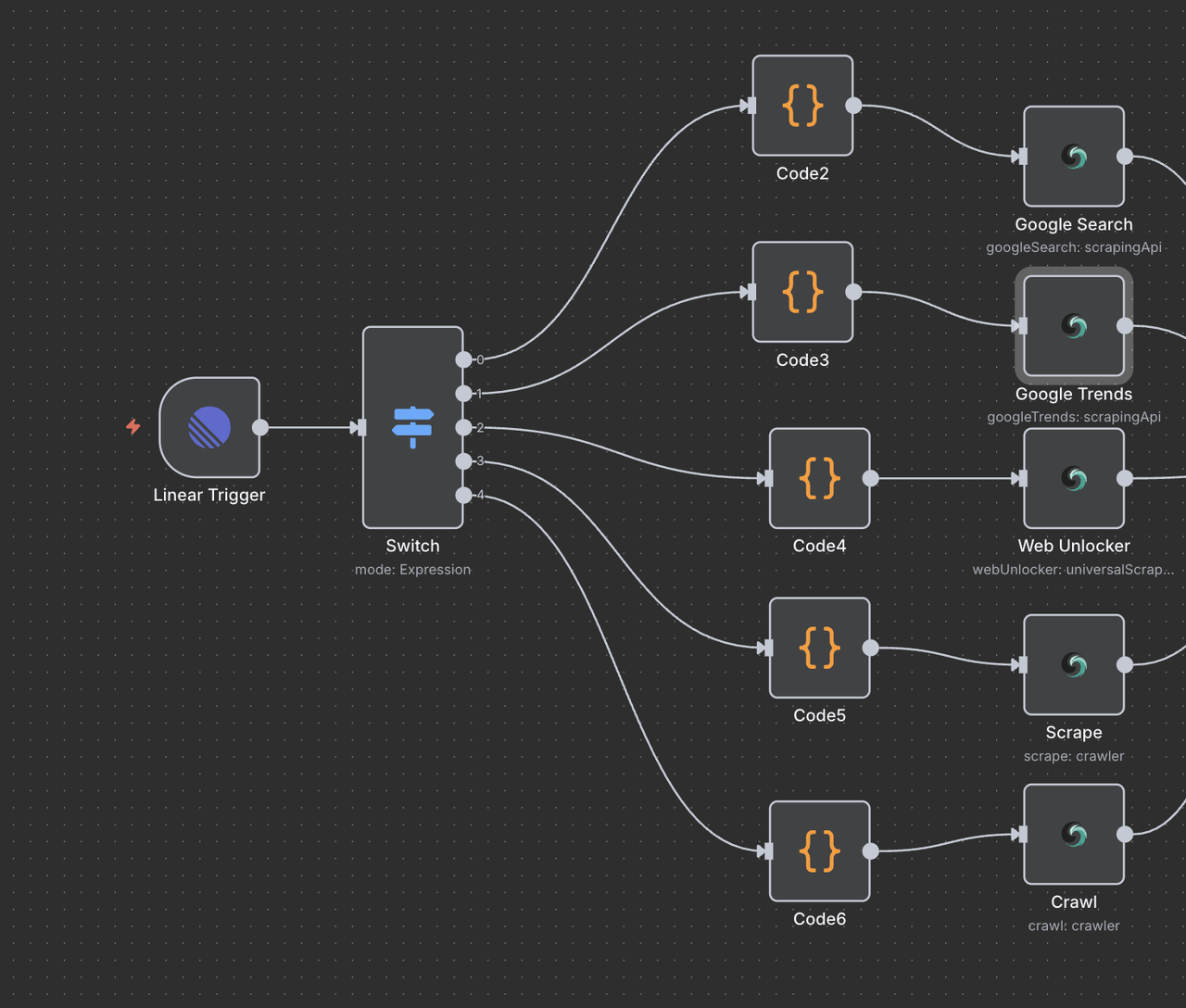
यह अनुभाग प्रत्येक स्क्रैपलेस ऑपरेशन नोड के बारे में विवरण देता है और इसके कार्य को समझाता है।
7.1 गूगल सर्च नोड (/search कमांड)
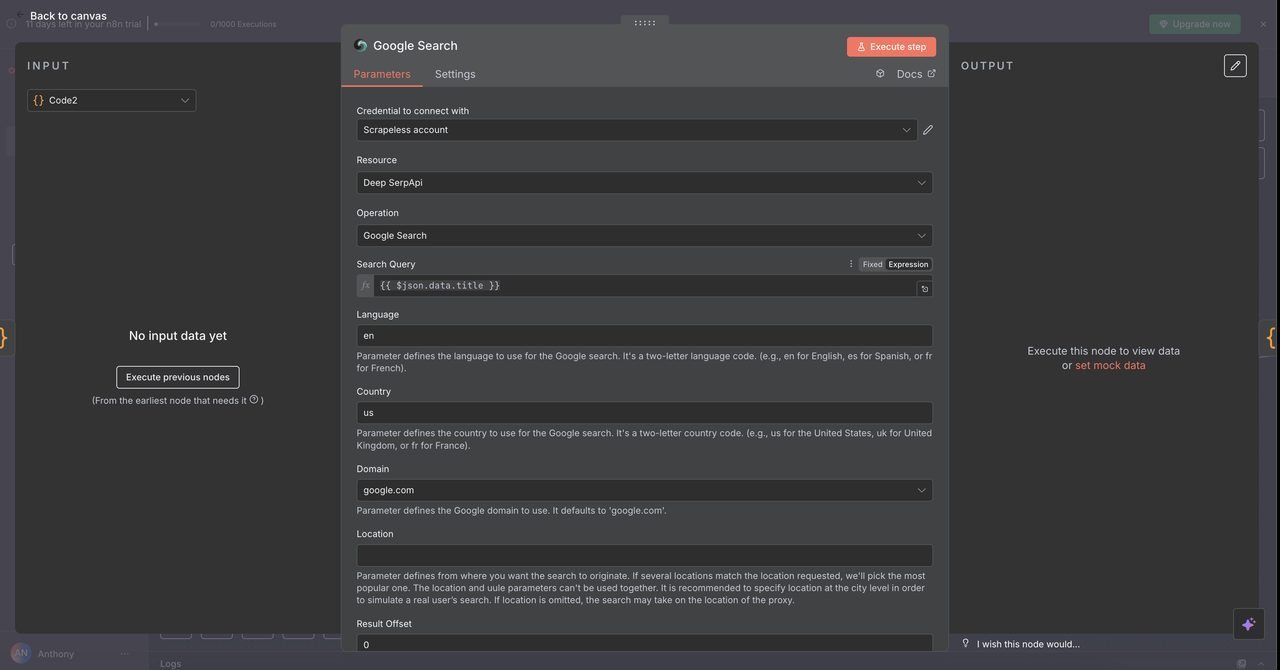
उद्देश्य:
गूगल वेब सर्च करता है और ऑर्गेनिक सर्च परिणाम लौटाता है।
कॉन्फ़िगरेशन:
- ऑपरेशन:
गूगल सर्च(डिफ़ॉल्ट) - क्वेरी:
{{ $json.data.title }}(पिछले चरण से साफ किया गया शीर्षक) - देश:
"US"(स्थानीय के अनुसार कस्टमाइज़ की जा सकती है) - भाषा:
"en"(अंग्रेज़ी)
क्या लौटाता है:
- ऑर्गेनिक सर्च परिणाम: शीर्षक, यूआरएल और स्निप्पेट
- "लोगों ने भी पूछे" संबंधित प्रश्न
- मेटाडेटा: अनुमानित परिणाम संख्या, सर्च अवधि
उपयोग के मामले:
- प्रतियोगी उत्पादों पर शोध
/search competitor pricing strategy
- उद्योग रिपोर्ट खोजें
/search SaaS market report 2024
- सर्वोत्तम प्रथाओं की खोज
/search API security best practices
7.2 गूगल ट्रेंड्स नोड (/trends कमांड)
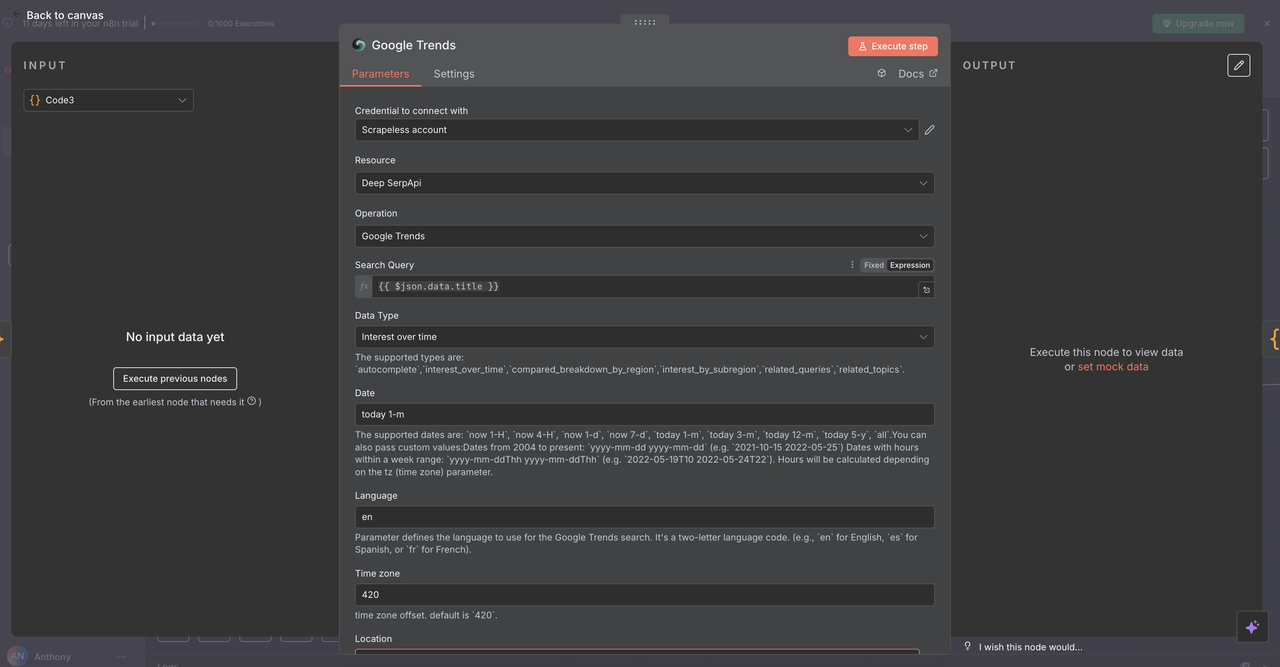
उद्देश्य:
विशिष्ट कीवर्ड के लिए खोज प्रवृत्ति डेटा और समय के साथ रुचि का विश्लेषण करता है।
कॉन्फ़िगरेशन:
- ऑपरेशन:
गूगल ट्रेंड्स - क्वेरी:
{{ $json.data.title }}(साफ किया हुआ कीवर्ड या वाक्यांश) - समय सीमा: 1 महीना, 3 महीने, 1 वर्ष जैसे विकल्पों में से चुनें
- भौगोलिक:
वैश्विकसेट करें या एक क्षेत्र निर्दिष्ट करें
क्या लौटाता है:
- समय के साथ रुचि का चार्ट (0–100 पैमाना)
- संबंधित क्वेरियाँ और ट्रेंडिंग विषय
- रुचि का भौगोलिक वितरण
- ट्रेंड संदर्भ के लिए श्रेणी के ब्रेकडाउन
उपयोग के मामले:
- बाजार प्रमाणन
/trends electric vehicle adoption - मौसमी विश्लेषण
/trends holiday shopping trends - ब्रांड निगरानी
/trends company-name mentions
7.3 वेब अनलॉकर नोड (/unlock कमांड)
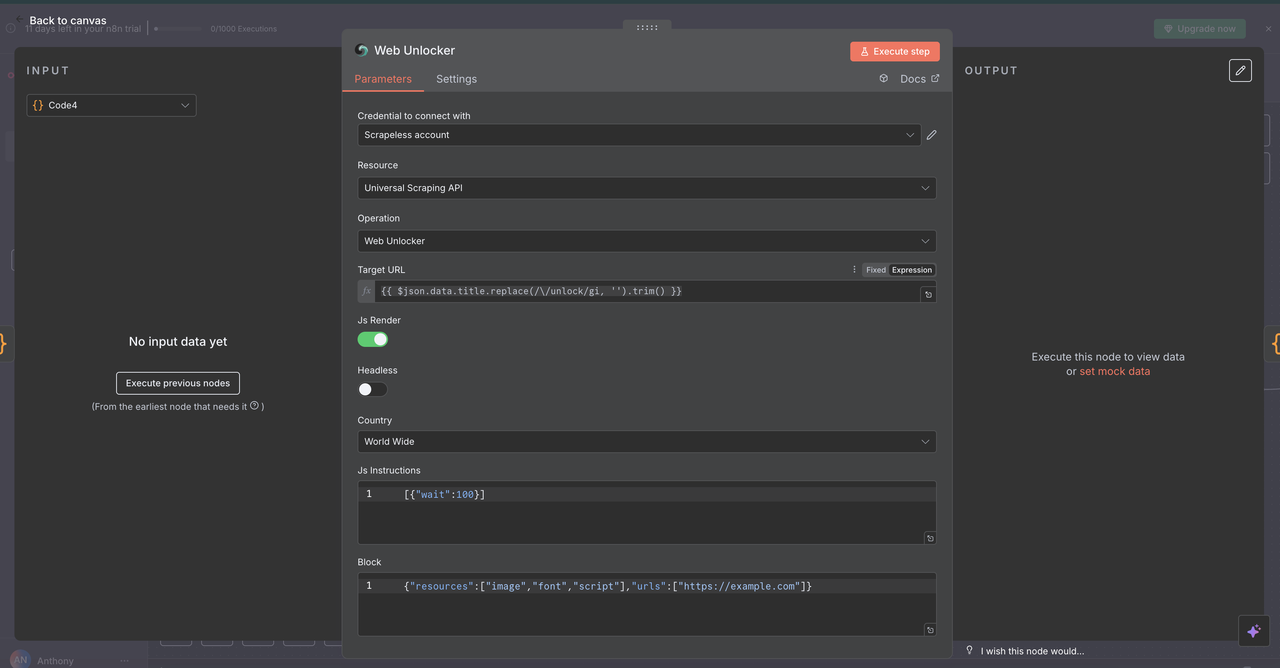
उद्देश्य:
ऐसे वेबसाइटों से सामग्री तक पहुंचना जो एंटी-बॉट मैकेनिज्म या पेवाल द्वारा संरक्षित हैं।
कॉन्फ़िगरेशन:
- स्रोत:
यूनिवर्सल स्क्रैपिंग एपीआई - यूआरएल:
{{ $json.data.title }}(एक मान्य यूआरएल होना चाहिए) - हेडलेस:
false(बेहतर एंटी-बॉट संगतता के लिए) - जावास्क्रिप्ट रेंडरिंग:
enabled(पूर्ण डायनैमिक सामग्री लोडिंग के लिए)
क्या लौटाता है:
- पृष्ठ की पूरी HTML सामग्री
- जावास्क्रिप्ट-रेंडर की गई अंतिम सामग्री
- सामान्य एंटी-बॉट सुरक्षा को बाईपास करने की क्षमता
उपयोग के मामले:
- प्रतियोगी मूल्य विश्लेषण
/unlock https://competitor.com/pricing - गेटेड शोध तक पहुँच
/unlock https://research-site.com/report - डायनमिक ऐप्स को स्क्रैप करना
/unlock https://spa-application.com/data
7.4 स्क्रैपर नोड (/scrape कमांड)
उद्देश्य:
एकल वेबपृष्ठ से चयनकर्ताओं या डिफ़ॉल्ट पार्सिंग के माध्यम से संरचित सामग्री निकालना।
कॉन्फ़िगरेशन:
- संसाधन:
क्रॉलर(यहाँ एकल-पृष्ठ स्क्रैपिंग के लिए उपयोग किया गया) - यूआरएल:
{{ $json.data.title }}(लक्ष्य वेबपृष्ठ) - फॉर्मेट: आउटपुट के लिए चुनें
HTML,Text, याMarkdown - चयनकर्ता: विशिष्ट सामग्री को लक्षित करने के लिए वैकल्पिक CSS चयनकर्ता
यह क्या लौटाता है:
- पृष्ठ से संरचित, साफ़ टेक्स्ट
- पृष्ठ मेटाडेटा (शीर्षक, विवरण, आदि)
- डिफ़ॉल्ट रूप से नेविगेशन/विज्ञापनों को बाहर करता है
उपयोग के मामले:
- समाचार लेख निकासी
/scrape https://news-site.com/article - एपीआई डॉक्स पार्सिंग
/scrape https://api-docs.com/endpoint - उत्पाद जानकारी संग्रहण
/scrape https://product-page.com/item
7.5 क्रॉलर नोड (/crawl कमांड)
उद्देश्य:
एक वेबसाइट के कई पृष्ठों को व्यवस्थित तरीके से क्रॉल करना ताकि व्यापक डेटा निकासी की जा सके।
कॉन्फ़िगरेशन:
- संसाधन:
क्रॉलर - ऑपरेशन:
क्रॉल - यूआरएल:
{{ $json.data.title }}(प्रारंभिक बिंदु यूआरएल) - आवर्तनों की सीमा: अतिरिक्त लोड से बचने के लिए वैकल्पिक सीमा, जैसे 5–10 पृष्ठ
- शामिल/बहिष्कृत पैटर्न: क्रॉल दायरे को परिष्कृत करने के लिए Regex या स्ट्रिंग फ़िल्टर
यह क्या लौटाता है:
- कई संबंधित पृष्ठों की सामग्री
- साइट की नेविगेशन संरचना
- लक्षित डोमेन/उप-खंडों में समृद्ध डेटा सेट
उपयोग के मामले:
-
प्रतिकूल अनुसंधान
/crawl https://competitor.com
(जैसे मूल्य निर्धारण, विशेषताएँ, कंपनी के बारे में पृष्ठ) -
डोक्यूमेंटेशन मैपिंग
/crawl https://docs.api.com
(पूरा एपीआई या विकास डोक्यूमेंटेशन क्रॉल करें) -
सामग्री ऑडिट
/crawl https://blog.company.com
(एसईओ समीक्षा के लिए लेखों, श्रेणियों, टैग का मानचित्रण)
कदम 8: डेटा विलय और प्रसंस्करण
सभी स्क्रैपलेस परिणामों को एक साथ लाना
एक एकल कोड नोड का उपयोग करके स्क्रैपलेस संचालन शाखाओं में से एक को निष्पादित करने के बाद, AI प्रसंस्करण के लिए उत्तर को सामान्यीकृत किया जाता है।
विलय कोड नोड का उद्देश्य:
- किसी भी स्क्रैपलेस नोड से आउटपुट को एकत्रित करना
- सभी कमांडों में डेटा प्रारूप को सामान्यीकृत करना
- क्लॉड या अन्य AI मॉडल इनपुट के लिए अंतिम पेलोड तैयार करना
कोड कॉन्फ़िगरेशन:
javascript
// स्क्रैपलेस प्रतिक्रिया को AI-रीड करने योग्य प्रारूप में परिवर्तित करें
return {
output: JSON.stringify($json, null, 2)
};कदम 9: क्लॉड AI विश्लेषण इंजन
बुद्धिमत्तापूर्ण डेटा विश्लेषण और अंतर्दृष्टि उत्पन्न करना
9.1 AI एजेंट नोड सेटअप
⚠️ क्लॉड के लिए अपनी एपीआई कुंजी सेट करना न भूलें।
AI एजेंट नोड वह जगह है जहाँ जादू होता है - यह सामान्यीकृत स्क्रैपलेस आउटपुट लेता है और इसे स्पष्ट, क्रियाशील अंतर्दृष्टियों में बदलता है जो लिनियर टिप्पणियों या अन्य रिपोर्टिंग उपकरणों में उपयोग के लिए उपयुक्त हैं।
कॉन्फ़िगरेशन विवरण:
- प्रॉम्प्ट प्रकार:
परिभाषित करें - पाठ इनपुट:
{{ $json.output }}(विलय नोड से संसाधित JSON स्ट्रिंग) - सिस्टम संदेश: क्लॉड के लिए टोन, भूमिका, और कार्य निर्धारित करता है
AI विश्लेषण प्रणाली प्रॉम्प्ट:
आप एक डेटा विश्लेषक हैं। खोज/स्क्रैप परिणामों का संक्षेप में सारांश करें। तथ्यात्मक और संक्षिप्त रहें। लिनियर टिप्पणियों के लिए प्रारूपित करें।
प्रदान किए गए डेटा का विश्लेषण करें और एक संरचित सारांश बनाएं जिसमें शामिल हो:
- प्रमुख निष्कर्ष और अंतर्दृष्टियाँ
- डेटा स्रोत और विश्वसनीयता मूल्यांकन
- क्रियाशील सिफारिशें
- प्रासंगिक मैट्रिक्स और प्रवृत्तियाँ
- आगे के अनुसंधान के लिए अगले कदम
अपने उत्तर को आसान पढ़ने के लिए स्पष्ट शीर्षक और बुलेट बिंदुओं के साथ प्रारूपित करें।यह प्रॉम्प्ट क्यों काम करता है
- विशिष्टता: क्लॉड को सटीक रूप से यह बताता है कि कौन सा विश्लेषण करना है
- संरचना: स्पष्ट अनुभागों के साथ संगठित आउटपुट का अनुरोध करता है
- संदर्भ: लिनियर टिप्पणी प्रारूपित करने के लिए अनुकूलित
- क्रियाशीलता: अंतर्दृष्टियों पर ध्यान केंद्रित करता है जिन पर टीमें कार्रवाई कर सकती हैं
9.2 क्लॉड मॉडल कॉन्फ़िगरेशन
एंथ्रोपिक चैट मॉडल नोड AI एजेंट को क्लॉड की शक्तिशाली भाषा प्रसंस्करण से जोड़ता है।
मॉडल चयन और पैरामीटर
-
मॉडल:
claude-3-7-sonnet-20250219(क्लॉड सोनट 3.7) -
तापमान:
0.3(रचनात्मकता और निरंतरता के बीच संतुलन)
Here is the translated text in Hindi: -
मैक्स टोकन्स:
4000(व्यापक प्रतिक्रियाओं के लिए पर्याप्त)
ये सेटिंग्स क्यों
- क्लॉड सोननेट 3.7: बुद्धिमत्ता, प्रदर्शन और लागत-कुशलता का एक मजबूत संतुलन
- कम तापमान (0.3): सटीक, दोहराने योग्य प्रतिक्रियाएं सुनिश्चित करता है
- 4000 टोकन्स: अत्यधिक खर्च के बिना गहन अंतर्दृष्टि उत्पन्न करने के लिए पर्याप्त
कदम 10: प्रतिक्रिया प्रसंस्करण और सफाई
क्लॉड के आउटपुट को रैखिक टिप्पणियों के लिए तैयार करना
10.1 प्रतिक्रिया सफाई कोड नोड
कोड नोड क्लॉड द्वारा एआई प्रतिक्रिया को रैखिक टिप्पणियों में ठीक से प्रदर्शित करने के लिए साफ करता है।
प्रतिक्रिया सफाई कोड:
// क्लॉड एआई प्रतिक्रिया को रैखिक टिप्पणियों के लिए साफ करें
return {
output: $json.output
.replace(/\\n/g, '\n')
.replace(/\\\"/g, '"')
.replace(/\\\\/g, '\\')
.trim()
};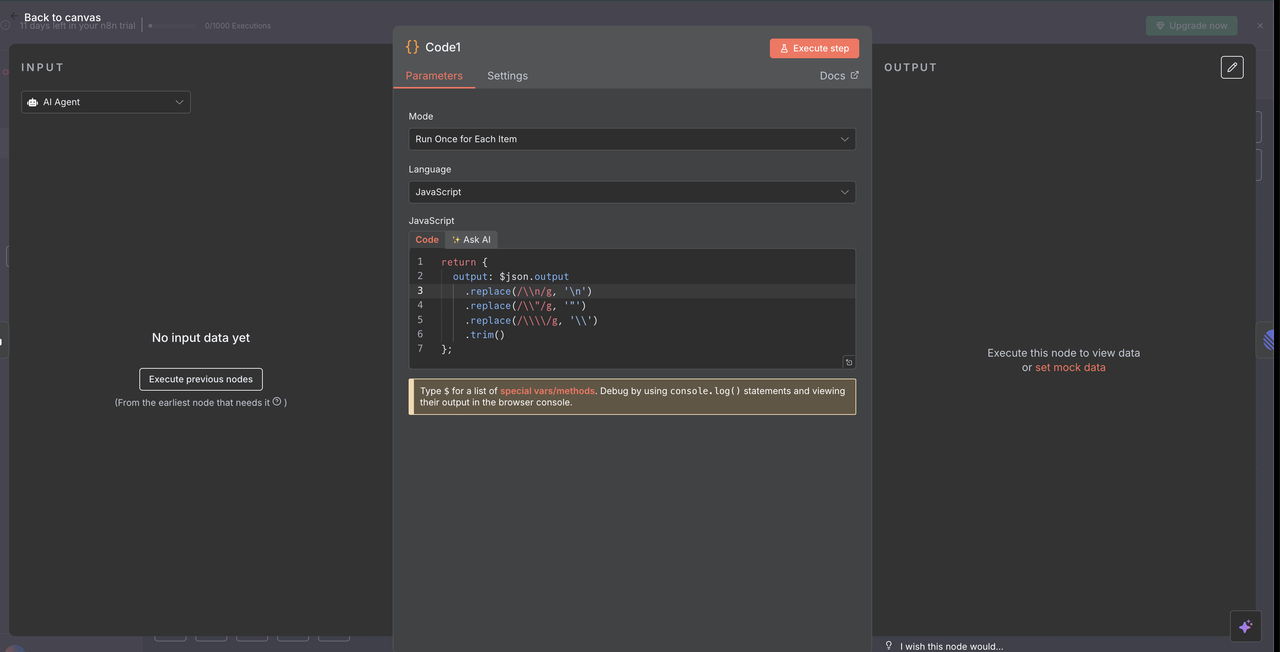
यह सफाई क्या हासिल करती है
- एस्केप कैरेक्टर हटाना: JSON एस्केप कैरेक्टर को हटाता है जो सही तरीके से प्रदर्शित नहीं होंगे
- लाइन ब्रेक ठीक करना: शाब्दिक
\nस्ट्रिंग्स को वास्तविक लाइन ब्रेक में परिवर्तित करता है - उद्धरण सामान्यीकरण: सुनिश्चित करता है कि उद्धरण रैखिक टिप्पणियों में ठीक से दिखाई दें
- व्हाइटस्पेस ट्रिमिंग: अनावश्यक अग्रणी और बाद के स्थानों को हटाता है
सफाई क्यों आवश्यक है
- क्लॉड का आउटपुट JSON के रूप में वितरित किया जाता है जो विशेष वर्णों को एस्केप करता है
- रैखिक का मार्कडाउन रेंडरर ठीक से स्वरूपित साधारण पाठ की आवश्यकता होती है
- बिना इस सफाई चरण के, प्रतिक्रिया कच्चे एस्केप कैरेक्टर दिखाएगी, जिससे पठनीयता में कमी आएगी
10.2 रैखिक टिप्पणी वितरण
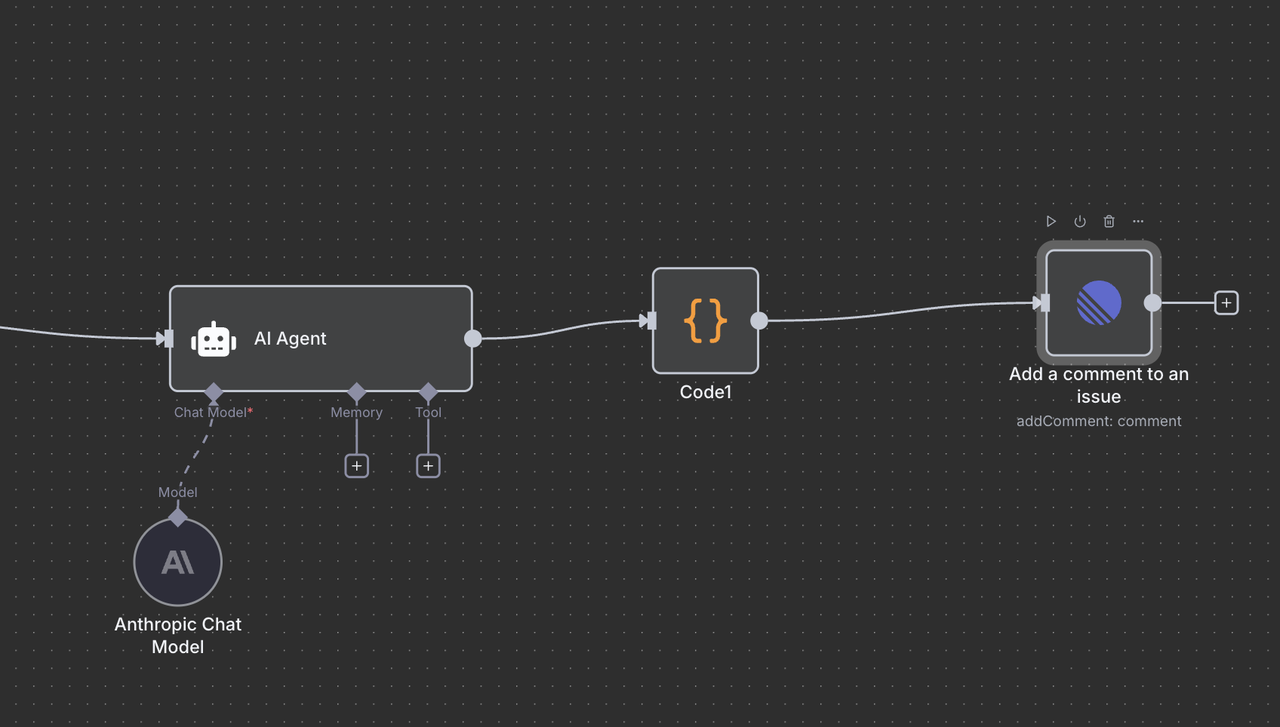
अंतिम रैखिक नोड एआई-जनित विश्लेषण को मूल मुद्दे पर टिप्पणी के रूप में लौटाता है।
कॉन्फ़िगरेशन विवरण:
- संसाधन:
"टिप्पणी"ऑपरेशन पर सेट - मुद्दा आईडी:
{{ $('Linear Trigger').item.json.data.id }} - टिप्पणी:
{{ $json.output }} - अतिरिक्त फ़ील्ड: वैकल्पिक रूप से मेटाडेटा या स्वरूपन विकल्प शामिल करें
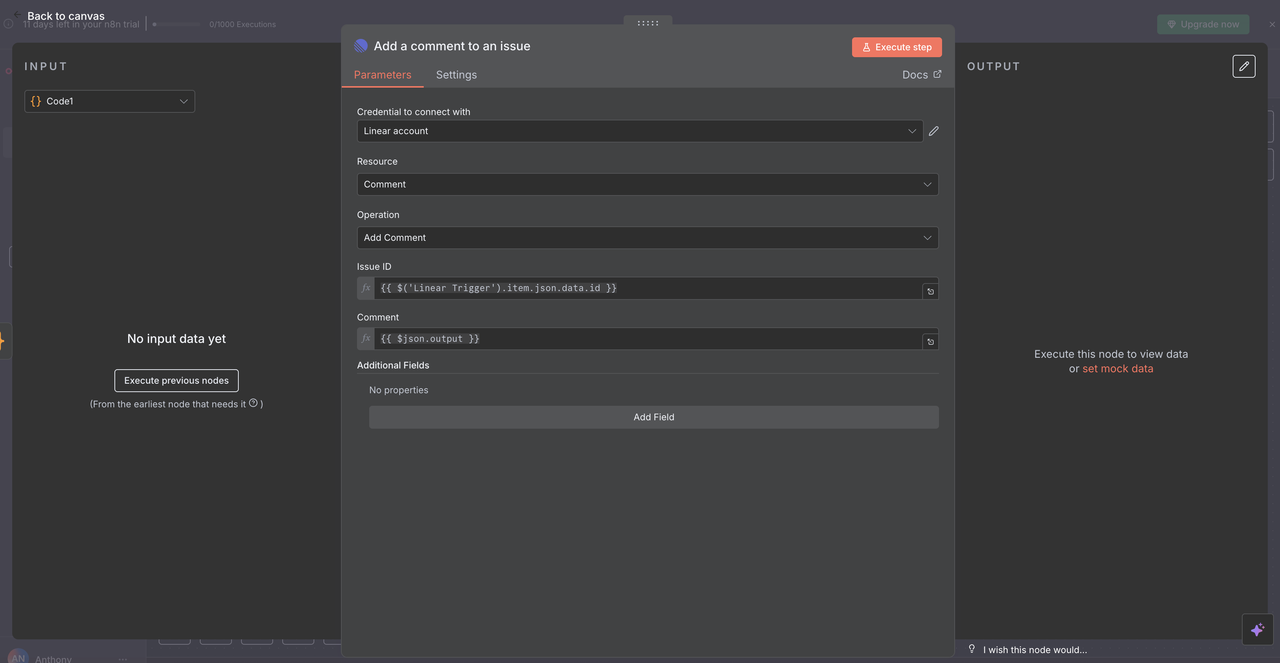
मुद्दा आईडी कैसे काम करती है
- मूल रैखिक ट्रिगर नोड को संदर्भित करता है
- कार्य प्रवाह शुरू करने वाले वेबहुक से सटीक मुद्दा आईडी का उपयोग करता है
- सुनिश्चित करता है कि एआई प्रतिक्रिया सही रैखिक मुद्दे पर प्रकट हो
पूर्ण चक्र
- उपयोगकर्ता
/search competitive analysisके साथ एक मुद्दा बनाता है - कार्य प्रवाह आदेश को संसाधित करता है और डेटा एकत्र करता है
- क्लॉड एकत्रित परिणामों का विश्लेषण करता है
- विश्लेषण को उसी मुद्दे पर टिप्पणी के रूप में वापस पोस्ट किया जाता है
- टीम सीधे संदर्भ में अनुसंधान अंतर्दृष्टियों को देखती है
कदम 11: अपने शोध सहायक का परीक्षण करना
पूर्ण कार्यप्रवाह का सत्यापन करें
अब कि सभी नोड्स कॉन्फ़िगर किए गए हैं, सुनिश्चित करने के लिए प्रत्येक आदेश प्रकार का परीक्षण करें कि यह ठीक से कार्य कर रहा है।
11.1 प्रत्येक आदेश प्रकार का परीक्षण करें
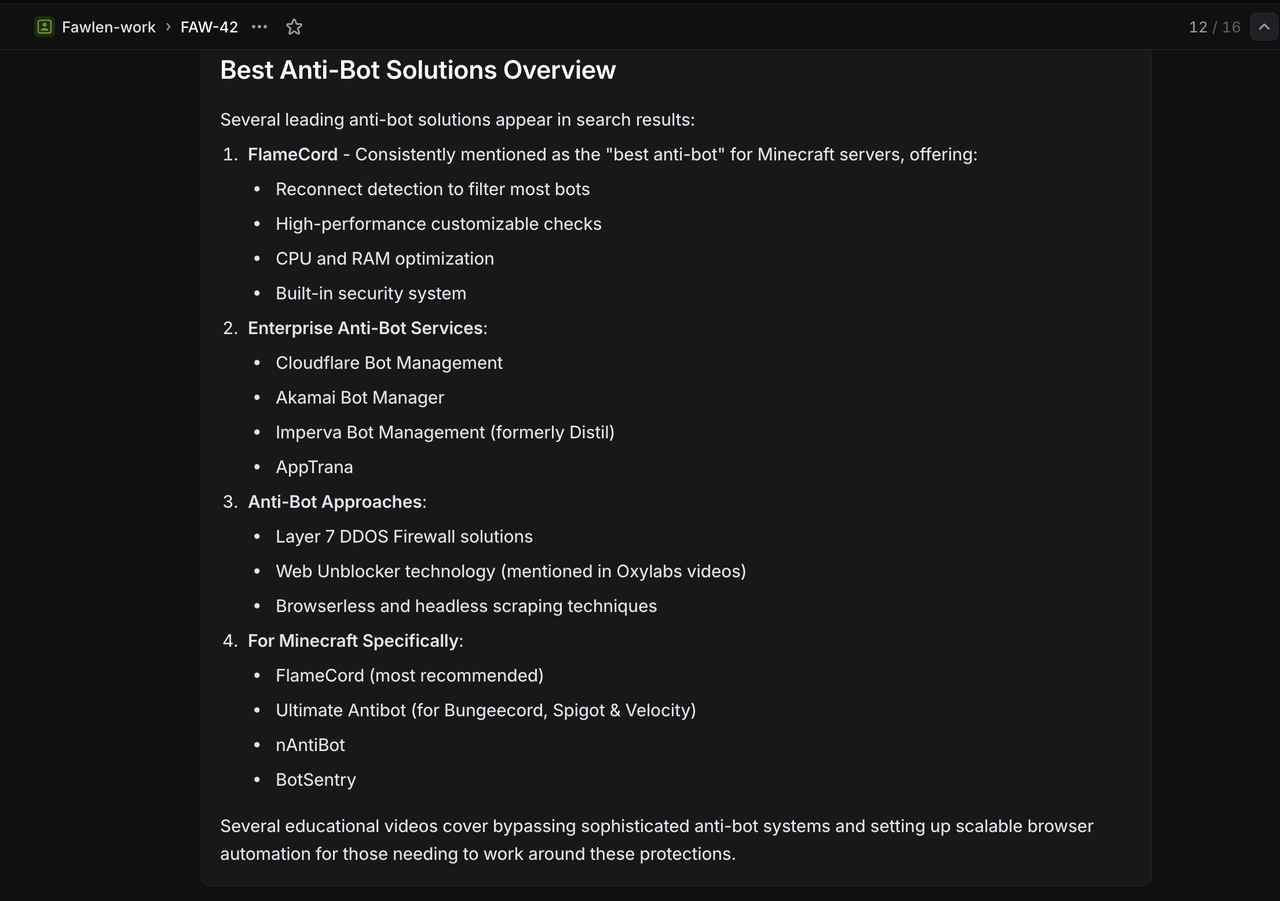
इन विशिष्ट शीर्षकों के साथ रैखिक में परीक्षण मुद्दे बनाएं:
गूगल सर्च परीक्षण:
`/search competitive analysis for SaaS platforms` अपेक्षित परिणाम: एसएएएस प्रतिस्पर्धात्मक विश्लेषण के बारे में गूगल खोज परिणाम लौटाता है
गूगल ट्रेंड्स परीक्षण:
`/trends artificial intelligence adoption` अपेक्षित परिणाम: समय के साथ एआई गोद लेने की रुचि दिखाने वाले प्रवृत्ति डेटा लौटाता है
वेब अनलॉकर परीक्षण:
`/unlock https://competitor.com/pricing` अपेक्षित परिणाम: एक सुरक्षित या जावास्क्रिप्ट-भारी मूल्य निर्धारण पृष्ठ की सामग्री लौटाता है
स्क्रैपर परीक्षण:
`/scrape https://news.ycombinator.com` अपेक्षित परिणाम: हैकर न्यूज़ होमपेज से संरचित सामग्री लौटाता है
क्रॉलर परीक्षण:
`/crawl https://docs.anthropic.com` अपेक्षित परिणाम: एंथ्रोपिक के दस्तावेज़ों के कई पृष्ठों से सामग्री लौटाता है
समस्या निवारण गाइड
रैखिक वेबहुक समस्याएं
- समस्या: वेबहुक ट्रिगर नहीं हो रहा है
- समाधान: वेबहुक यूआरएल और रैखिक अनुमतियों की जांच करें
- जांचें: n8n वेबहुक एंडपॉइंट स्थिति
स्क्रेपलेस एपीआई गलतियाँ
- समस्या: प्रमाणीकरण विफलताएँ
- समाधान: एपीआई कुंजी और खाते की सीमाओं की जांच करें
- जांचें: स्क्रेपलेस डैशबोर्ड पर उपयोग मेट्रिक्स
क्लॉड एआई प्रतिक्रिया समस्याएँ
- समस्या: खराब या अधूरी विश्लेषण
- हल: सिस्टम प्रॉम्प्ट और संदर्भ को परिष्कृत करें
- जाँच: इनपुट डेटा की गुणवत्ता और स्वरूपण
लिनियर टिप्पणी स्वरूपण
- समस्या: टूटे हुए मार्कडाउन या स्वरूपण
- हल: प्रतिक्रिया सफाई कोड को अपडेट करें
- जांच: विशेष अक्षर प्रबंधन
निष्कर्ष
लिनियर के सहयोगात्मक कार्यक्षेत्र, स्क्रैपलेस के विश्वसनीय डेटा निष्कर्षण, और क्लॉड एआई के बुद्धिमान विश्लेषण का संयोजन एक शक्तिशाली अनुसंधान स्वचालन प्रणाली बनाता है जो टीमों के लिए जानकारी इकट्ठा करने और प्रोसेस करने के तरीके को बदल देता है।
यह एकीकरण अनुसंधान की जरूरतों की पहचान करने और कार्रवाई योग्य अंतर्दृष्टि प्राप्त करने के बीच की friction को समाप्त करता है। बस लिनियर मुद्दों में कमांड टाइप करके, आपकी टीम व्यापक डेटा संग्रह और विश्लेषण कार्यप्रवाह को ट्रिगर कर सकती है, जिनके लिए पारंपरिक रूप से घंटों की मैन्युअल मेहनत की आवश्यकता होती।
मुख्य लाभ
- ⚡ त्वरित अनुसंधान: सवाल से अंतर्दृष्टि तक 60 सेकंड से कम में
- 🎯 संदर्भ संरक्षण: अनुसंधान प्रोजेक्ट चर्चाओं से जुड़ा रहता है
- 🧠 एआई संवर्धन: कच्चा डेटा स्वचालित रूप से कार्रवाई योग्य बुद्धिमत्ता बनता है
- 👥 टीम दक्षता: साझा अनुसंधान टीम के समूहन पहुँच में
- 📊 व्यापक कवरेज: एकीकृत कार्यप्रवाह में कई डेटा स्रोत
अपनी टीम की अनुसंधान क्षमताओं को प्रतिक्रियाशील से प्रोएक्टिव में बदलें। लिनियर, स्क्रैपलेस और क्लॉड की एक साथ कार्यशील होने से, आप सिर्फ डेटा नहीं इकट्ठा कर रहे हैं - आप एक प्रतिस्पर्धात्मक बुद्धिमत्ता लाभ बना रहे हैं जो आपके व्यवसाय के साथ बढ़ता है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


