
ब्राउज़र फ़िंगरप्रिंटिंग क्या है और यह पहचान फ़िंगरप्रिंट कैसे करता है?
Senior Web Scraping Engineer
ब्राउज़र फिंगरप्रिंटिंग डिवाइस इंटेलिजेंस बनाने का आधार है, जिससे व्यवसाय दुनिया भर की वेबसाइटों पर वेबसाइट विज़िटरों की विशिष्ट पहचान कर सकते हैं।
जिस प्रकार आपका शारीरिक फिंगरप्रिंट लूप्स, व्हर्ल्स और आर्चेस का एक बिलकुल अनोखा संयोजन है, उसी प्रकार वेबसाइट से जुड़ने के लिए आपके द्वारा उपयोग किए जाने वाले वेब ब्राउज़र भी एक अनोखा निशान छोड़ते हैं। हालाँकि, डबल लूप्स और टेंट के आकार के आर्चेस के बजाय, ब्राउज़रों में स्क्रीन रिज़ॉल्यूशन, संग्रहीत WebGL और ग्राफ़िक्स कार्ड कॉन्फ़िगरेशन जैसे व्यक्तिगत मार्कर होते हैं।
ब्राउज़र फिंगरप्रिंटिंग क्या है और यह आपके डिवाइस का पता कैसे लगाता है और बॉट गतिविधि को कैसे ब्लॉक करता है?
इस लेख को पढ़कर और अब उन्हें समझकर।
ब्राउज़र फिंगरप्रिंटिंग क्या है?
ब्राउज़र फिंगरप्रिंटिंग उपकरणों और तकनीकों का एक समूह है जो वेब उपयोगकर्ताओं की ब्राउज़िंग गतिविधियों के माध्यम से डेटा एकत्रित कर सकता है। वेबसाइटें आपके बारे में विभिन्न जानकारी एकत्रित करती हैं, जैसे कि उपयोगकर्ता ऑपरेटिंग सिस्टम, ब्राउज़र प्रकार, स्क्रीन रिज़ॉल्यूशन, समय क्षेत्र, कीबोर्ड लेआउट, आदि, और यह प्रक्रिया आमतौर पर आपकी जानकारी के बिना की जाती है। इन विवरणों को संसाधित करके, यह प्रत्येक उपयोगकर्ता के लिए एक अद्वितीय पहचानकर्ता या "डिजिटल फिंगरप्रिंट" बनाता है।
ब्राउज़र फिंगरप्रिंटिंग कुकीज़ से थोड़ा मिलता-जुलता दिखता है। लेकिन वे इस मायने में भिन्न हैं कि फिंगरप्रिंटिंग को उपयोगकर्ता की सहमति की आवश्यकता नहीं होती है और कोई "ऑप्ट-आउट" फ़ंक्शन नहीं होता है, जिसे आप मूल रूप से कुकीज़ वाली किसी वेबसाइट पर पहली बार विज़िट करते समय देख सकते हैं।
कौन सा डेटा एकत्रित किया जाएगा?
ब्राउज़र फिंगरप्रिंटिंग उपकरण उपयोगकर्ता के सॉफ़्टवेयर और हार्डवेयर कॉन्फ़िगरेशन से संबंधित उपयोगकर्ता डेटा एकत्रित करते हैं, जिसमें शामिल हैं:
| ✅ सिस्टम फ़ॉन्ट्स | ✅ क्या कुकीज़ सक्षम हैं |
| ✅ ऑपरेटिंग सिस्टम | ✅ ओएस भाषा |
| ✅ ऑपरेटिंग सिस्टम | ✅ ओएस भाषा |
| ✅ प्लेटफ़ॉर्म | ✅ HTTP हेडर विशेषताएँ |
| ✅ कीबोर्ड लेआउट | ✅ उपयोग किए गए वेब ब्राउज़र एक्सटेंशन |
| ✅ टोर ब्राउज़र या नहीं | ✅ ऑडियो संदर्भ विश्लेषण |
| ✅ सुरक्षित ब्राउज़र या नहीं | ✅ CPU वर्ग |
| ✅ उपयोगकर्ता एजेंट | ✅ HTML 5 कैनवास फिंगरप्रिंटिंग (कैनवास आकार) |
| ✅ ब्राउज़र स्थानीय डेटाबेस | ✅ टच सपोर्ट |
| ✅ नेविगेटर गुण | ✅ त्वरक, निकटता और जाइरोस्कोप जैसे सेंसर |
मेरी खोज कैसे हुई?
यदि आप पर नज़र रखी जा रही है या आपकी पहचान की जा रही है, तो संभव है कि आपके ब्राउज़र कॉन्फ़िगरेशन, प्लगइन्स या पर्याप्त गोपनीयता उपायों की कमी ने आपके फिंगरप्रिंट को अलग बना दिया हो। फिंगरप्रिंट विशेष रूप से उपयोगकर्ताओं के लिए प्रभावी हैं:
- अद्वितीय ब्राउज़र कॉन्फ़िगरेशन पर निर्भर करते हैं।
- अत्यधिक अनुकूलित या पुराने ब्राउज़रों का उपयोग करते हैं।
- जावास्क्रिप्ट या कैनवास डेटा संग्रह को ब्लॉक करने में विफल रहते हैं।
पता लगाने से बचने के लिए, गोपनीयता-केंद्रित ब्राउज़रों, एंटी-डिटेक्ट ब्राउज़र समाधान जैसे उपकरणों, अनावश्यक प्लगइन्स को अक्षम करने या फिंगरप्रिंट डेटा को अस्पष्ट करने वाले ब्राउज़र सुविधाओं का लाभ उठाने पर विचार करें।
ब्राउज़र फिंगरप्रिंटिंग कैसे काम करता है?
1️⃣ चरण 1. डेटा संग्रह
वेबसाइटें जावास्क्रिप्ट या अन्य तकनीकों के माध्यम से उपयोगकर्ता ब्राउज़र और डिवाइस की जानकारी एकत्रित करती हैं, जिसमें ब्राउज़र प्रकार, ऑपरेटिंग सिस्टम, स्क्रीन रिज़ॉल्यूशन, भाषा सेटिंग्स, फ़ॉन्ट्स, हार्डवेयर जानकारी (जैसे GPU), और कैनवास/WebGL रेंडरिंग आउटपुट शामिल हैं।
2️⃣ चरण 2. संयुक्त विशेषताएँ
एकत्रित कई विशेषताओं को एक डेटा सेट में एकीकृत किया जाता है, जो कुछ विशेषताओं के बदलने पर भी (जैसे ब्राउज़र अपग्रेड) पर्याप्त विशिष्टता बनाए रख सकता है।
3️⃣ चरण 3. एक अद्वितीय पहचानकर्ता उत्पन्न करें
इन डेटा सेट (जैसे हैश गणना) को संसाधित करके, उपयोगकर्ता के डिवाइस और ब्राउज़र की पहचान करने के लिए एक अद्वितीय फिंगरप्रिंट उत्पन्न किया जाता है।
4️⃣ चरण 4. क्रॉस-सेशन और वेबसाइट ट्रैकिंग
वेबसाइटें उपयोगकर्ताओं को ट्रैक करने के लिए उत्पन्न फिंगरप्रिंट का उपयोग करती हैं, और उपयोगकर्ता कुकीज़ साफ़ करने या गोपनीयता मोड को सक्षम करने पर भी उसी उपयोगकर्ता की पहचान कर सकती हैं।
ब्राउज़र फिंगरप्रिंटिंग को कैसे बायपास करें?
Scrapeless स्क्रैपिंग ब्राउज़र ब्राउज़र फिंगरप्रिंटिंग को बायपास करने का एक प्रभावी तरीका है। यह एक उच्च-प्रदर्शन सर्वरलेस प्लेटफ़ॉर्म प्रदान करता है। यह गतिशील वेबसाइटों से डेटा निकालने की प्रक्रिया को प्रभावी ढंग से सरल करता है। डेवलपर्स समर्पित सर्वरों के बिना हेडलेस ब्राउज़र चला सकते हैं, प्रबंधित कर सकते हैं और उनकी निगरानी कर सकते हैं, जिससे कुशल वेब ऑटोमेशन और डेटा संग्रह सक्षम हो जाता है।
वेब स्क्रैपिंग के लिए Scrapeless विशेष क्यों है?
Scrapeless स्क्रैपिंग ब्राउज़र में 195 देशों और 70 मिलियन से अधिक आवासीय IP पतों को कवर करने वाला एक वैश्विक नेटवर्क, एक शक्तिशाली वेब अनलॉकर और एक अत्यधिक स्थिर कैप्चा सॉल्वर है। यह उन उपयोगकर्ताओं के लिए आदर्श है जिन्हें विश्वसनीय और स्केलेबल वेब स्क्रैपिंग समाधान की आवश्यकता होती है।
Scrapeless स्क्रैपिंग ब्राउज़र का उपयोग कैसे करें?
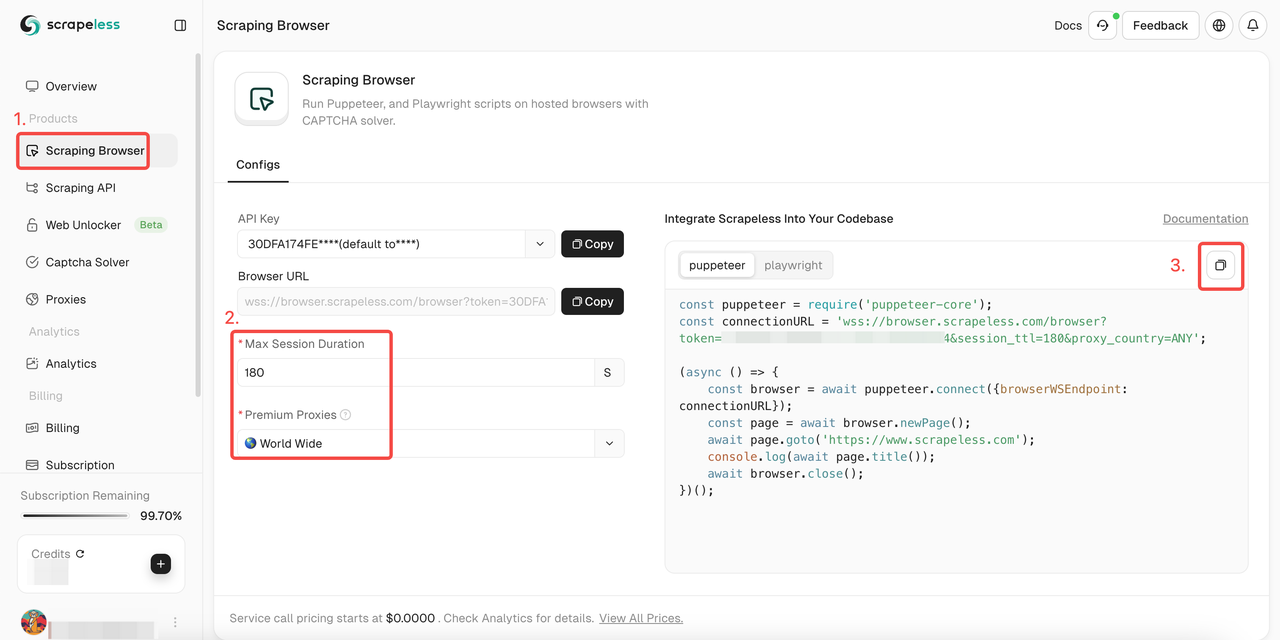
- चरण 1. साइन इन करें Scrapeless
- चरण 2. "स्क्रैपिंग ब्राउज़र" दर्ज करें
- चरण 3. अपनी आवश्यकताओं के अनुसार पैरामीटर सेट करें
- चरण 4. अपनी परियोजना में एकीकृत करने के लिए नमूना कोड कॉपी करें:
पपेटियर
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();प्लेराइट
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();अधिक विवरण प्राप्त करना चाहते हैं? हमारा दस्तावेज़ आपकी बहुत मदद करेगा!
- पपेटियर:
आवश्यक लाइब्रेरी स्थापित करें
सबसे पहले, puppeteer-core स्थापित करें, जो पपेटियर का एक हल्का संस्करण है जिसे मौजूदा ब्राउज़र इंस्टेंस से कनेक्ट करने के लिए डिज़ाइन किया गया है:
Bash
npm install puppeteer-coreस्क्रैपिंग ब्राउज़र से कनेक्ट करने के लिए कोड लिखें
अपने पपेटियर कोड में, निम्न विधि का उपयोग करके स्क्रैपिंग ब्राउज़र से कनेक्ट करें:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();इस तरह, आप स्केलेबिलिटी, आईपी रोटेशन और वैश्विक पहुँच सहित स्क्रैपिंग ब्राउज़र इन्फ़्रास्ट्रक्चर का लाभ उठा सकते हैं।
उदाहरण:
स्क्रैपिंग ब्राउज़र के साथ एकीकरण के बाद यहाँ कुछ सामान्य पपेटियर ऑपरेशन दिए गए हैं:
- नेविगेशन और पृष्ठ सामग्री निष्कर्षण
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- स्क्रीनशॉट
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- कस्टम स्क्रिप्ट चलाएँ
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();- प्लेराइट:
आवश्यक लाइब्रेरी स्थापित करें
सबसे पहले, playwright-core स्थापित करें, जो प्लेराइट का एक हल्का संस्करण है जो मौजूदा ब्राउज़र इंस्टेंस से कनेक्ट करता है:
Bash
npm install playwright-coreस्क्रैपिंग ब्राउज़र से कनेक्ट करने के लिए कोड लिखें
प्लेराइट कोड में, निम्न विधि का उपयोग करके स्क्रैपिंग ब्राउज़र से कनेक्ट करें:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();यह आपको स्केलेबिलिटी, आईपी रोटेशन और वैश्विक पहुँच सहित स्क्रैपिंग ब्राउज़र के इन्फ़्रास्ट्रक्चर का लाभ उठाने की अनुमति देता है।
उदाहरण:
स्क्रैपिंग ब्राउज़र के साथ एकीकरण के बाद यहाँ कुछ सामान्य प्लेराइट ऑपरेशन दिए गए हैं:
- नेविगेशन और पृष्ठ सामग्री निष्कर्षण
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- स्क्रीनशॉट
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- कस्टम स्क्रिप्ट चलाएँ
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();7 ब्राउज़र फिंगरप्रिंटिंग तकनीकें
1. कैनवास फिंगरप्रिंटिंग
कैनवास फिंगरप्रिंटिंग HTML5 कैनवास तत्व के माध्यम से उपयोगकर्ता के डिवाइस के GPU और ग्राफ़िक्स ड्राइवर में अंतर का विश्लेषण करता है। स्क्रिप्ट एक इमेज बनाता है और ब्राउज़र के रेंडरिंग परिणामों को कैप्चर करता है। डिवाइस हार्डवेयर में अंतर थोड़े अलग रेंडरिंग में परिणाम देते हैं, और इन विशेषताओं को एक अद्वितीय "कैनवास फिंगरप्रिंट" में बदल दिया जाता है।
2. WebGL फिंगरप्रिंटिंग
यह तकनीक उपयोगकर्ता के ब्राउज़र में 3D ग्राफ़िक्स उत्पन्न करने के लिए WebGL का उपयोग करती है और उत्पन्न ग्राफ़िक्स (GPU और ड्राइवर के कारण) में सूक्ष्म अंतरों का विश्लेषण करके डिवाइस के लिए एक अद्वितीय पहचानकर्ता उत्पन्न करती है। यह उपयोगकर्ताओं को सटीक रूप से अलग करने के लिए डिवाइस हार्डवेयर और ड्राइवरों के संयोजन पर निर्भर करता है।
3. मीडिया डिवाइस फिंगरप्रिंटिंग
मीडिया डिवाइस फिंगरप्रिंटिंग उपयोगकर्ता के डिवाइस पर मीडिया हार्डवेयर और कनेक्टेड डिवाइस की पहचान करके फिंगरप्रिंट उत्पन्न करता है। हालाँकि उपयोगकर्ताओं को कैमरा या माइक्रोफ़ोन एक्सेस को अधिकृत करने की आवश्यकता होती है, लेकिन यह उन सेवाओं के लिए बहुत उपयोगी है जो मीडिया डिवाइस (जैसे वीडियो कॉल) पर निर्भर करती हैं।
4. TLS फिंगरप्रिंटिंग
TLS फिंगरप्रिंटिंग सुरक्षित संचार स्थापित करते समय डिवाइस और सर्वर द्वारा उपयोग किए जाने वाले एन्क्रिप्शन एल्गोरिदम के संयोजन का विश्लेषण करके डिवाइस की पहचान करता है। यह विधि एक अद्वितीय डिवाइस फिंगरप्रिंट उत्पन्न करने के लिए TLS हैंडशेक में विवरणों का उपयोग करती है।
5. फ़ॉन्ट फिंगरप्रिंटिंग
यह तकनीक उपयोगकर्ता के डिवाइस पर स्थापित फ़ॉन्ट्स के अद्वितीय सेट का उपयोग करके एक फिंगरप्रिंट उत्पन्न करती है। उपयोगकर्ता के सिस्टम में फ़ॉन्ट अंतरों का पता लगाकर, वेबसाइट उपयोगकर्ता डिवाइसों के बीच अंतर कर सकती है। यह विधि व्यक्तिगत सामग्री वितरण और उपयोगकर्ता पहचान के लिए विशेष रूप से प्रभावी है।
6. मोबाइल डिवाइस फिंगरप्रिंटिंग
मोबाइल डिवाइस फिंगरप्रिंटिंग ऑपरेटिंग सिस्टम और स्क्रीन रिज़ॉल्यूशन जैसे डेटा का उपयोग करके डिवाइस की एक अनूठी प्रोफ़ाइल बनाता है। यह प्लेटफ़ॉर्म को वापसी करने वाले उपयोगकर्ताओं की पहचान करने और असामान्य डिवाइस व्यवहार का पता लगाने में मदद करता है और उपयोगकर्ता अनुभव को अनुकूलित करने और धोखाधड़ी को रोकने के लिए एक महत्वपूर्ण उपकरण है।
7. ऑडियो फिंगरप्रिंटिंग
ऑडियो फिंगरप्रिंटिंग डिवाइस ऑडियो उत्पन्न करने और संसाधित करने के तरीके में सूक्ष्म हार्डवेयर और सॉफ़्टवेयर अंतरों को कैप्चर करके उपयोगकर्ताओं की पहचान करता है। यह तकनीक डिजिटल अधिकार प्रबंधन और व्यक्तिगत ऑडियो सामग्री वितरण में व्यापक रूप से उपयोग की जाती है।
मेरे फिंगरप्रिंट क्यों एकत्रित किए गए थे?
- धोखाधड़ी का पता लगाना। फिंगरप्रिंटिंग उन साइटों के लिए प्रारंभिक चेतावनी संकेतक प्रदान करता है जो धोखाधड़ी के उच्च स्तर के अधीन हो सकती हैं।
- खाता निर्माण और पुनर्प्राप्ति। फिंगरप्रिंटिंग एक ही उपयोगकर्ता को बहुत अधिक खाते बनाने/बनाने से रोकता है। यह उनकी साइट पर स्पैम को रोकता है और अधिक सुरक्षा प्रदान करता है। इसके अलावा, लॉगिन जानकारी भूल जाने के बाद अपने खाते को पुनर्प्राप्त करने वाले उपयोगकर्ताओं के अस्तित्व को सत्यापित करने के लिए मिलान फिंगरप्रिंट एक बहुत ही उपयोगी उपकरण है।
- सामग्री निजीकरण। सामग्री निजीकरण फिंगरप्रिंटिंग से निकटता से संबंधित है। विज्ञापन और वेब पेज निजीकरण आपके उपयोग इतिहास के आधार पर बनाए जा सकते हैं, आपको उन चीजों को खोजने के लिए मार्गदर्शन करते हैं जो आपको लगता है कि आप देखना, सुनना या खरीदना चाहते हैं।
कुकीज़ और ब्राउज़र फिंगरप्रिंटिंग: विशिष्ट अंतर
कुकीज़ डेटा के छोटे टुकड़े होते हैं जो वेबसाइटें आपकी यात्रा के बारे में जानकारी याद रखने के लिए आपके डिवाइस पर संग्रहीत करती हैं। वे पारदर्शी और प्रबंधित करने में आसान हैं, जिससे उपयोगकर्ता ब्राउज़र सेटिंग्स के माध्यम से उन्हें देख सकते हैं, हटा सकते हैं या ब्लॉक कर सकते हैं। हालाँकि, फिंगरप्रिंट पूरी तरह से निष्क्रिय हैं। वे आपके डिवाइस पर संग्रहीत किए बिना या आपके साथ किसी भी प्रत्यक्ष बातचीत के बिना चुपचाप डेटा एकत्रित करते हैं।
निम्न सामग्री आपको उनके अंतर को स्पष्ट रूप से देखने में मदद कर सकती है:
| सुविधा | कुकीज़ | फिंगरप्रिंट |
|---|---|---|
| स्थिरता | अस्थायी; समाप्त हो सकता है या मैन्युअल रूप से हटाया जा सकता है। | दीर्घकालिक: शायद ही कभी बदलते हार्डवेयर, सॉफ़्टवेयर और व्यवहारिक डेटा पर आधारित। |
| पारदर्शिता | उपयोगकर्ता की सहमति की आवश्यकता है; उपयोगकर्ता कुकीज़ को देख सकते हैं, हटा सकते हैं या ब्लॉक कर सकते हैं। | चुपके से संचालित होता है, अक्सर उपयोगकर्ता जागरूकता या ऑप्ट-आउट विकल्पों के बिना। |
| ट्रैकिंग | उपयोगकर्ता के डिवाइस पर संग्रहीत, आमतौर पर स्पष्ट सहमति की आवश्यकता होती है। | उपयोगकर्ता की सहमति के बिना निष्क्रिय डेटा संग्रह। |
| क्षेत्र | विशिष्ट वेबसाइटों तक सीमित है जब तक कि स्पष्ट रूप से साझा नहीं किया जाता है। | वेबसाइटों, सत्रों, उपकरणों और यहां तक कि विभिन्न नेटवर्क में उपयोगकर्ताओं को ट्रैक करता है। |
| परिहार कठिनाई | ब्राउज़र सेटिंग्स या एक्सटेंशन का उपयोग करके आसानी से अवरुद्ध या प्रबंधित किया जाता है। | उन्नत उपायों की आवश्यकता होती है, जैसे कि एंटी-डिटेक्ट ब्राउज़र या विशेष उपकरण। |
| प्रकटीकरण | बैनर और गोपनीयता नीतियों के माध्यम से प्रकट किया गया। | शायद ही कभी प्रकट किया जाता है, जिससे उपयोगकर्ताओं के लिए यह जानना मुश्किल हो जाता है कि फिंगरप्रिंटिंग कब होती है। |
निचला रेखा
ब्राउज़र फिंगरप्रिंटिंग ऑनलाइन ट्रैकिंग में एक शक्तिशाली लेकिन विवादास्पद उपकरण बन गया है, जो जटिल तकनीक को गहरे गोपनीयता मुद्दों के साथ जोड़ता है। कुकीज़ का उपयोग करने के विपरीत, फिंगरप्रिंट निष्क्रिय रूप से डेटा एकत्रित करता है और पारंपरिक गोपनीयता बचाव जैसे "अदृश्यता" का विरोध करता है, जिससे यह एक लगातार और कुछ हद तक आक्रामक ट्रैकिंग विधि बन जाती है।
सीमलेस डेटा संग्रह और क्रॉलिंग प्राप्त करने के लिए फिंगरप्रिंट पहचान को प्रभावी ढंग से कैसे बायपास करें? Scrapeless स्क्रैपिंग ब्राउज़र आपको वास्तविक ब्राउज़र फिंगरप्रिंटिंग और बुद्धिमान आईपी रोटेशन प्रदान करता है, जिससे तेज़ प्रतिक्रिया और कुशल वेबसाइट अनब्लॉकिंग सुनिश्चित होती है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


