![Amazon स्क्रैपर API [2025 पूरी गाइड]](/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Famazon-scraper-api%2Fcfb72f0037679639ea3cd6ff1695dc79.png&w=1920&q=100)
Amazon स्क्रैपर API [2025]: आपको हमेशा के लिए ज़रूरी एकमात्र गाइड
Advanced Data Extraction Specialist
ई-कॉमर्स डेटा की मांग बढ़ने के साथ, अमेज़ॅन प्लेटफ़ॉर्म पर डेटा क्रॉल और विश्लेषण करना तेजी से महत्वपूर्ण होता जा रहा है। Amazon Scraper API का उपयोग करके, व्यवसाय और डेवलपर्स आसानी से अमेज़ॅन से उत्पाद जानकारी, कीमतें, समीक्षाएँ, इन्वेंटरी और अन्य डेटा निकाल सकते हैं।
हालांकि, प्रौद्योगिकी की निरंतर प्रगति के बावजूद, कई उपयोगकर्ताओं को अभी भी कुशलतापूर्वक और सटीक रूप से डेटा क्रॉल करने की चुनौती का सामना करना पड़ता है।
इस गाइड में, हम आपको Amazon Scraper API की गहरी समझ देंगे:
#1. Amazon Scraper API के मुख्य कार्यों को समझें
#2. API को शीघ्रता से कॉन्फ़िगर करें और क्रॉलिंग शुरू करें
#3. डेटा क्रॉलिंग के लिए सर्वोत्तम अभ्यास
2025 में, Amazon Scraper API अधिक शक्तिशाली और लचीला हो गया है, और यह प्रतिस्पर्धी बाजार में आगे रहने में आपकी मदद करने के लिए सटीक संरचित डेटा प्रदान कर सकता है। आगे, हम विस्तार से बताएंगे कि इस उपकरण का पूरी क्षमता से उपयोग कैसे करें।
Amazon Scraper API क्या है?
एक Amazon Scraper API एक ऐसा उपकरण है जो अमेज़ॅन की वेबसाइट से डेटा निकालने की प्रक्रिया को स्वचालित करता है। इसका उपयोग विभिन्न उद्देश्यों के लिए बड़ी मात्रा में डेटा एकत्रित और संसाधित करने के लिए किया जा सकता है।
कुछ डेटा जिसे Amazon Scraper API का उपयोग करके एकत्र किया जा सकता है, इसमें शामिल हैं:
उत्पाद समीक्षाएँ, उत्पाद विवरण, ऑफ़र, उत्पाद खोज, उत्पाद मूल्य निर्धारण, ASIN, विक्रेता का नाम, मर्चेंट ID, शीर्षक और URL।
Amazon Scraper API का उपयोग क्यों करें?
Amazon Scraper API व्यवसायों के लिए अमेज़ॅन से डेटा संग्रह को सरल बनाने का एक शक्तिशाली उपकरण है।
यहाँ बताया गया है कि आपको इसका उपयोग क्यों करना चाहिए:
- स्वचालित डेटा निष्कर्षण: उत्पाद डेटा संग्रह को स्वचालित करके समय की बचत करता है।
- वास्तविक समय अपडेट: आपके डेटा को अद्यतित कीमतों, स्टॉक, समीक्षाओं आदि के साथ चालू रखता है।
- सटीक, संरचित डेटा: आसान विश्लेषण और एकीकरण के लिए संरचित प्रारूप (जैसे JSON) में डेटा प्रदान करता है।
- प्रतियोगी मूल्य ट्रैकिंग: प्रतियोगी मूल्य निर्धारण और उत्पाद उपलब्धता की निगरानी करता है।
- स्केलेबल और कुशल: IP ब्लॉकिंग के जोखिम के बिना बड़ी डेटा मात्रा को संभालता है।
- सहज एकीकरण: त्वरित सेटअप और उपयोग के लिए आपके सिस्टम में आसानी से एकीकृत होता है।
Amazon Scraper API कैसे काम करता है?
Amazon Scraper API उत्पाद पृष्ठों पर स्वचालित अनुरोध भेजकर अमेज़ॅन से डेटा प्राप्त करता है। यह कीमतों, उत्पाद विवरणों, समीक्षाओं और उपलब्धता जैसी जानकारी निकालता है, और डेटा को JSON जैसे संरचित प्रारूप में वापस करता है। अमेज़ॅन के एंटी-स्क्रेपिंग उपायों द्वारा अवरुद्ध होने से बचने के लिए, API IP पतों और हेडलेस ब्राउज़रों को घुमाने जैसे तरीकों का उपयोग करता है।
Scraping API का उपयोग करके Amazon को स्क्रैप करें
Amazon डेटा को स्क्रैप करने के सबसे आसान तरीकों में से एक समर्पित scraping API जैसे Scrapeless का उपयोग करना है। यह उपकरण पूरी प्रक्रिया को सुव्यवस्थित करता है, उपयोगकर्ताओं को उत्पाद विवरण, समीक्षाएँ, ऑफ़र, खोज परिणाम और मूल्य निर्धारण जैसे प्रमुख विवरणों को आसानी से निकालने में सक्षम बनाता है, सभी एक सुविधाजनक JSON प्रारूप में।
केवल एक साधारण API कॉल के साथ, Scrapeless व्यापक कोडिंग ज्ञान की आवश्यकता के बिना अमेज़ॅन डेटा के धन तक पहुँचना संभव बनाता है, जो समय और प्रयास बचाने के इच्छुक उपयोगकर्ताओं के लिए एक आदर्श समाधान है।

Scrapeless Amazon Scraping API का उपयोग करके, आप कर सकते हैं:
- उपयोगकर्ता के अनुकूल इंटरफ़ेस: अधिकांश उपकरण एक पॉइंट-एंड-क्लिक इंटरफ़ेस प्रदान करते हैं जो आपके द्वारा स्क्रैप किए जाने वाले डेटा का चयन करना आसान बनाता है।
- पूर्व-निर्मित टेम्पलेट: Scrapeless जैसे उपकरण विशेष रूप से अमेज़ॅन के लिए डिज़ाइन किए गए पूर्व-निर्मित टेम्पलेट प्रदान करते हैं, जिससे उपयोगकर्ता न्यूनतम सेटअप के साथ उत्पाद विवरणों को स्क्रैप कर सकते हैं।
- स्वचालित डेटा निष्कर्षण: ये उपकरण IP रोटेशन और CAPTCHA चुनौतियों को स्वचालित रूप से संभालते हैं, अमेज़ॅन द्वारा अवरुद्ध होने के जोखिम को कम करते हैं।
Amazon डेटा को कैसे स्क्रैप करें:
चरण 1. Scrapeless में लॉग इन करें
चरण 2. Scraping API क्लिक करें > Shopee स्क्रैपिंग पृष्ठ दर्ज करने के लिए Amazon का चयन करें।
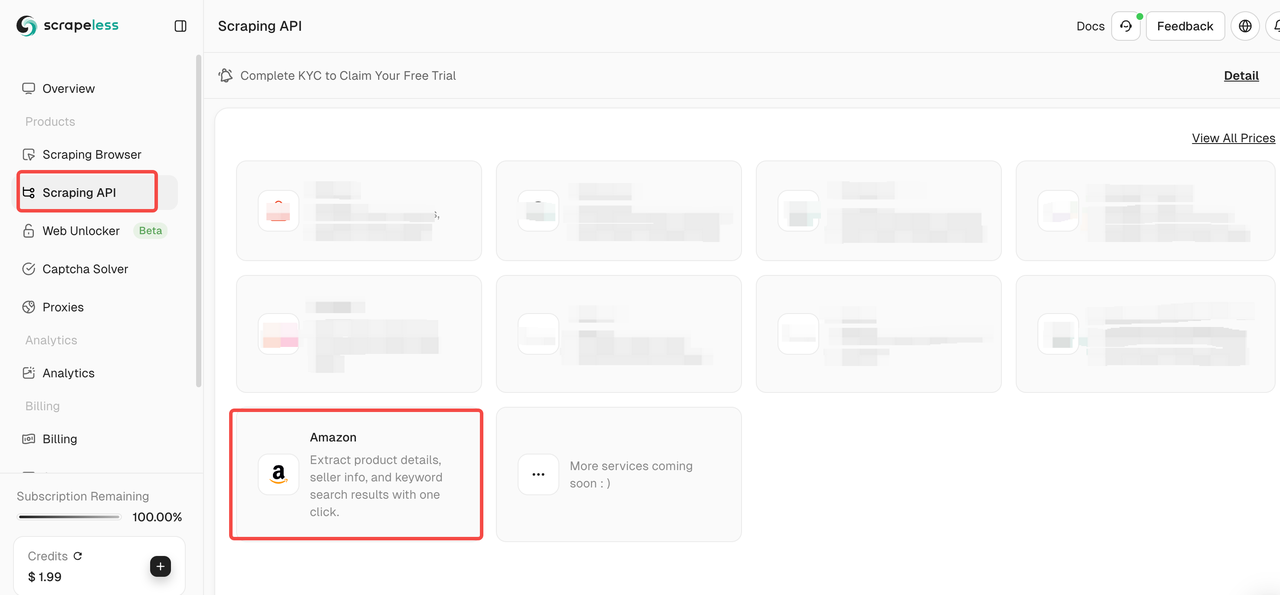
चरण 3. उस Amazon उत्पाद पृष्ठ का लिंक पेस्ट करें जिसे आप क्रॉल करना चाहते हैं इनपुट बॉक्स में। और क्रॉल करने के लिए डेटा के प्रकार का चयन करें।
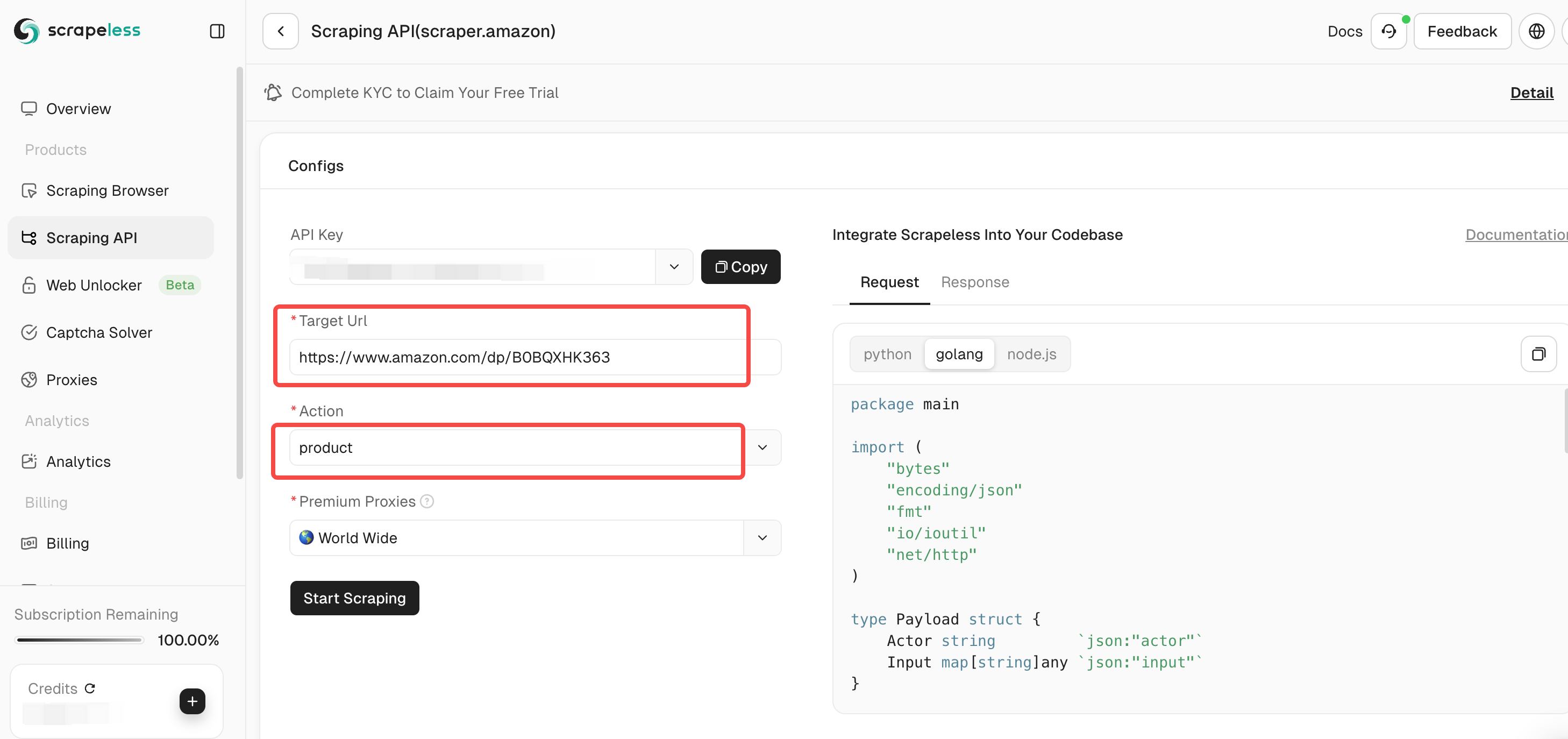
टूल पृष्ठ पर, आप क्रॉल करने के लिए डेटा के प्रकार का चयन कर सकते हैं:
- विक्रेता: विक्रेता जानकारी क्रॉल करें, जिसमें विक्रेता का नाम, रेटिंग, संपर्क जानकारी आदि शामिल हैं।
- उत्पाद: शीर्षक, मूल्य, रेटिंग, टिप्पणियाँ आदि जैसे उत्पाद विवरण क्रॉल करें।
- कीवर्ड: उत्पाद से संबंधित कीवर्ड क्रॉल करें ताकि आप उत्पाद के SEO और बाजार के रुझानों का विश्लेषण कर सकें।
चरण 4. यह पुष्टि करने के बाद कि इनपुट लिंक और चयनित डेटा प्रकार सही हैं, "Start Scraping" बटन पर क्लिक करें। सिस्टम डेटा क्रॉल करना शुरू कर देगा और पृष्ठ के दाईं ओर के पैनल पर क्रॉल किए गए परिणाम प्रदर्शित करेगा।
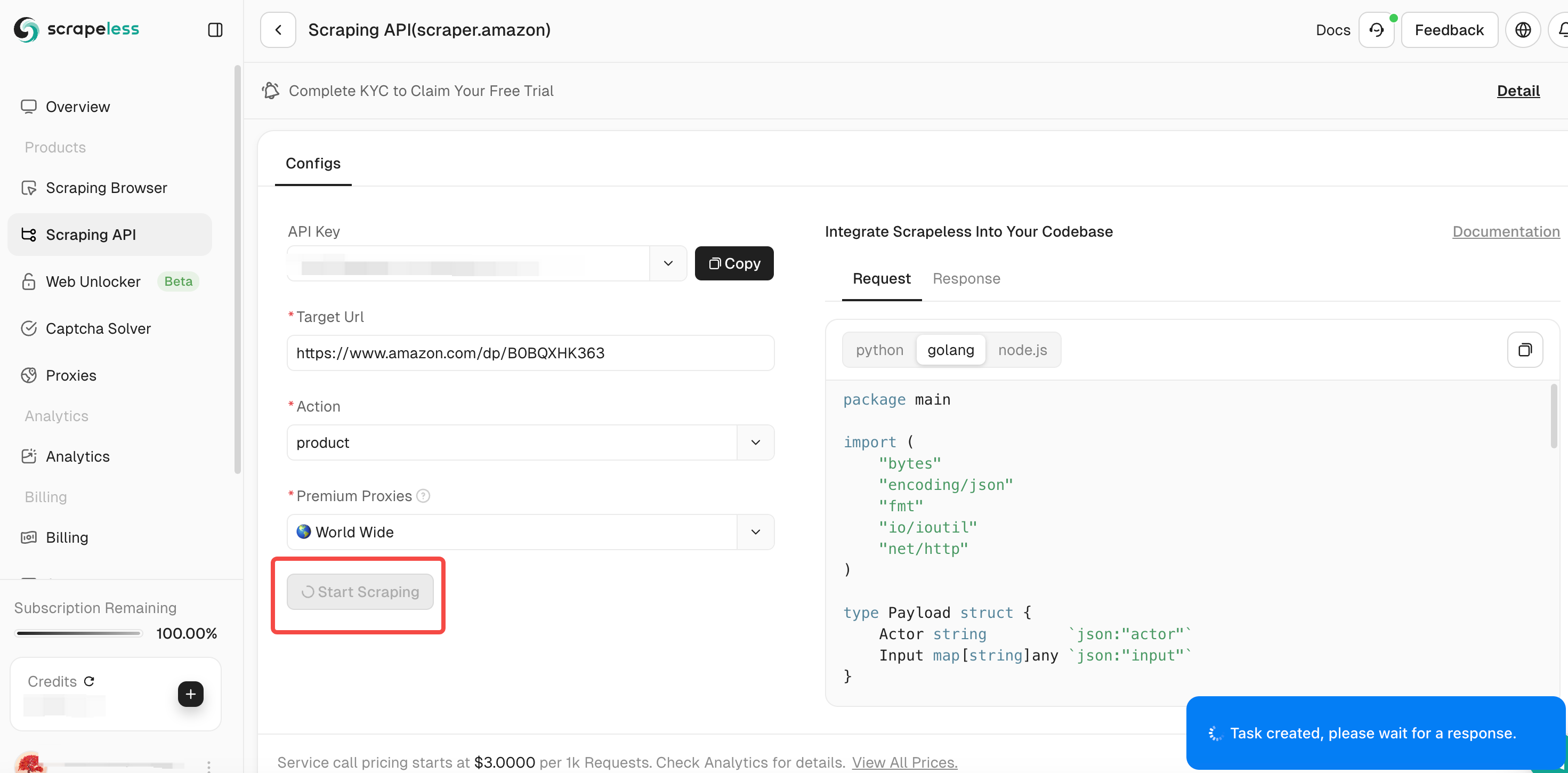
चरण 5. क्रॉलिंग पूरा होने के बाद, आप दाईं ओर के पैनल में क्रॉल किए गए डेटा को देख सकते हैं। आसान विश्लेषण के लिए परिणाम एक स्पष्ट प्रारूप में प्रदर्शित किए जाएंगे।
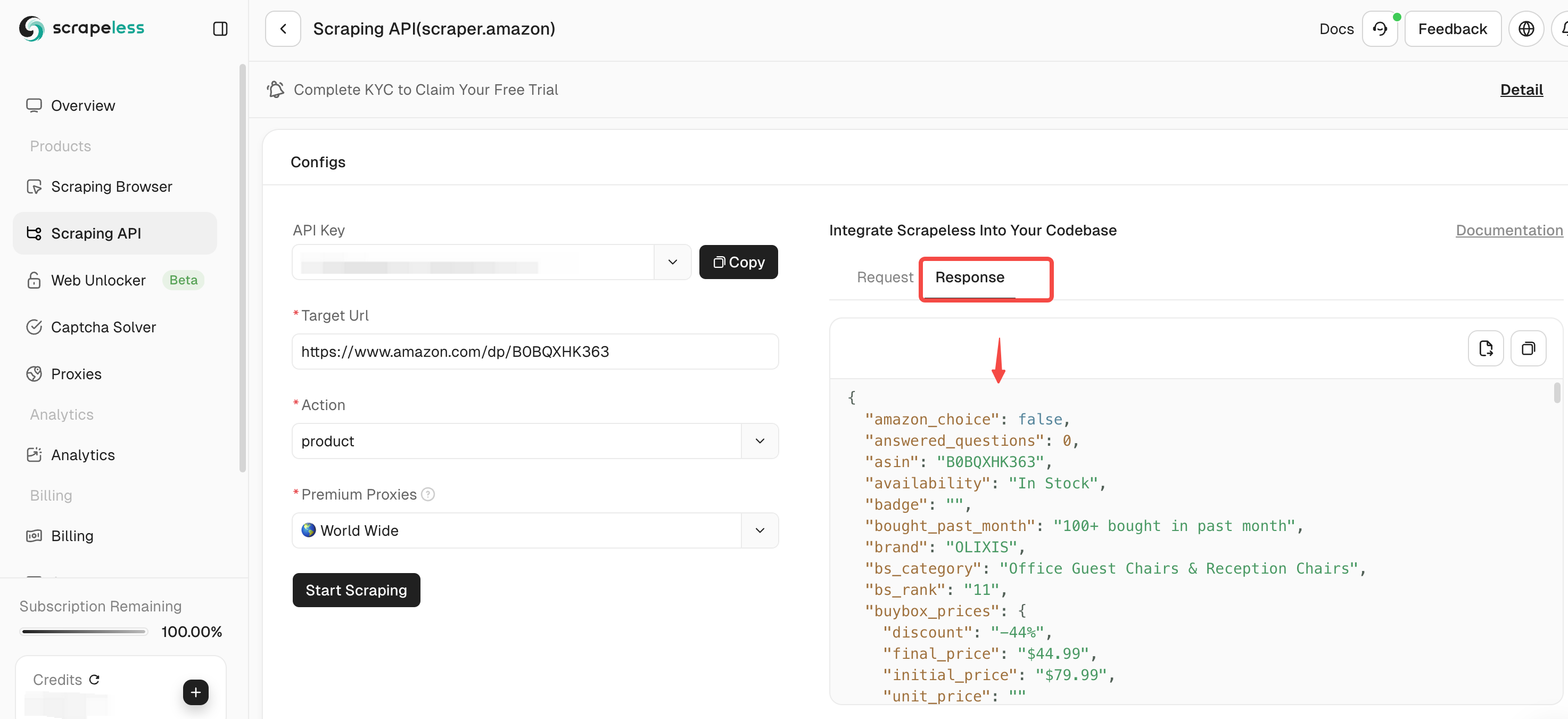
यदि आपको अन्य उत्पादों को क्रॉल करने की आवश्यकता है, तो एक नया अमेज़ॅन लिंक दर्ज करने के लिए जारी रखें और उपरोक्त चरणों को दोहराएँ।
अमेज़ॅन से संरचित डेटा को जल्दी से स्क्रैप करना चाहते हैं? Scrapeless Amazon API सभी जटिलताओं को संभालता है, घूमने वाले प्रॉक्सी से लेकर हेडलेस ब्राउज़र तक, तेज़ और सहज डेटा निष्कर्षण सुनिश्चित करता है। लॉग इन करें अब अपने डैशबोर्ड पर और तुरंत अपना मुफ़्त परीक्षण प्राप्त करें!
अनुरोध नमूने
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))डेटा स्क्रैपिंग में आने वाली सामान्य समस्याओं से कैसे बचें
समस्या 1: यदि थोड़े समय में बहुत अधिक अनुरोध किए जाते हैं, तो वेबसाइटें अक्सर एक ही IP पते से अनुरोधों को ब्लॉक या थ्रॉटल करती हैं, जो डेटा स्क्रैपिंग को रोकती है।
- समाधान: अनुरोधों को विभिन्न IP पतों पर वितरित करने के लिए एक घूर्णन प्रॉक्सी या प्रॉक्सी पूल का उपयोग करें। यह दर सीमा से टकराने या अवरुद्ध होने से बचने में मदद करता है।
समस्या 2: अमेज़ॅन सहित कई वेबसाइटें, स्वचालित स्क्रैपिंग प्रयासों का पता लगाने के लिए कैप्चा या अन्य एंटी-बॉट तंत्र का उपयोग करती हैं, जिससे डेटा निकालना मुश्किल हो जाता है।
- समाधान: कैप्चा को बायपास करने के लिए, एक हेडलेस ब्राउज़र या एक कैप्चा सॉल्विंग सेवा का उपयोग करें जो आपके लिए कैप्चा को स्वचालित रूप से पूरा करता है। Scrapeless Scraper API कैप्चा को स्वचालित रूप से हल करके या पता लगाने से बचने के लिए मशीन लर्निंग एल्गोरिदम का उपयोग करके इस समस्या को हल कर सकता है।
Amazon Scraper API के बारे में FAQ
क्या अमेज़ॅन डेटा स्क्रैपिंग की अनुमति देता है?
Amazon की सेवा की शर्तें डेटा संग्रह के लिए अपनी वेबसाइट तक स्वचालित पहुँच की अनुमति देती हैं, लेकिन कुछ आवश्यकताएँ हैं:
- सार्वजनिक डेटा: अमेज़ॅन ऐसे डेटा को स्क्रैप करने की अनुमति देता है जो साइट पर जाने वाले किसी भी व्यक्ति के लिए सुलभ है, जैसे उत्पाद जानकारी, कीमतें और समीक्षाएँ।
- व्यक्तिगत उपयोग या अनुसंधान: अमेज़ॅन व्यक्तिगत उपयोग या अनुसंधान उद्देश्यों के लिए स्क्रैपिंग की अनुमति देता है।
क्या आप कीमतों के लिए अमेज़ॅन को स्क्रैप कर सकते हैं?
हाँ, आप अमेज़ॅन से उत्पाद जानकारी प्राप्त कर सकते हैं, जिसमें शामिल हैं:
- मूल्य: वर्तमान मूल्य, छूट और ऐतिहासिक मूल्य परिवर्तन।
- उत्पाद शीर्षक: उत्पाद का नाम और विवरण।
- उत्पाद विवरण: विशिष्टताएँ, विशेषताएँ और तकनीकी विवरण।
- ग्राहक समीक्षाएँ और रेटिंग: उपयोगकर्ता प्रतिक्रिया, रेटिंग और समीक्षा सारांश।
- उपलब्धता: स्टॉक स्थिति, शिपिंग विकल्प और डिलीवरी समय।
- चित्र: उत्पाद चित्र और थंबनेल।
- ASIN (Amazon मानक पहचान संख्या): एक उत्पाद के लिए एक अद्वितीय पहचानकर्ता।
आपको आवश्यकता हो सकती है:
Shein डेटा को कैसे स्क्रैप करें
सर्वश्रेष्ठ Google ट्रेंड्स स्क्रैपिंग API - Google ट्रेंड्स से डेटा को आसानी से स्क्रैप करें
सर्च इंजन स्क्रैपिंग के लिए शीर्ष 6 SERP API
निष्कर्ष
यहाँ, एक पेशेवर API सेवा प्रदाता के रूप में, Scrapeless[वेब स्क्रैपिंग टूलकिट] आपको Amazon Scraper API का उपयोग कैसे करें और जटिल तकनीकी सेटिंग्स या डेटा निष्कर्षण मुद्दों के बारे में चिंता किए बिना आसानी से आवश्यक डेटा प्राप्त करने में मदद करने के लिए एक विस्तृत मार्गदर्शिका प्रदान करेगा।
डेवलपर्स और कंपनियों के लिए जो अमेज़ॅन से डेटा को जल्दी से निकालना चाहते हैं, Amazon Scraper API एक कुशल और उपयोग में आसान समाधान है। यह क्रॉलिंग प्रक्रिया को सरल करता है, जिससे आप बहुत समय और प्रयास लगाए बिना सटीक डेटा प्राप्त कर सकते हैं।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


