
स्क्रैपलेस और पाइनकोन डेटाबेस का उपयोग करके एआई समर्थित ब्लॉग लेखक
Senior Web Scraping Engineer
आप एक अनुभवी सामग्री निर्माता होना चाहिए। स्टार्टअप टीम के रूप में, उत्पाद की दिन-प्रतिदिन अपडेट की गई सामग्री बहुत समृद्ध है। आपको न केवल वेबसाइट ट्रैफ़िक को तेजी से बढ़ाने के लिए बड़ी संख्या में ड्रेनेज ब्लॉग प्रस्तुत करने की आवश्यकता है, बल्कि प्रत्येक सप्ताह उत्पाद अद्यतन प्रचार के लिए 2-3 ब्लॉग भी तैयार करने की आवश्यकता है।
भुगतान वाले विज्ञापनों के बोली बजट को बढ़ाने के लिए अधिक धन खर्च करने की तुलना में, सामग्री विपणन के अभी भी अपरिवर्तनीय लाभ हैं: सामग्री की विस्तृत श्रृंखला, ग्राहकों को अधिग्रहण परीक्षण की कम लागत, उच्च आउटपुट दक्षता, तुलनात्मक रूप से कम ऊर्जा निवेश, समृद्ध क्षेत्र अनुभव ज्ञान का आधार आदि।
हालांकि, बहुत सारी सामग्री विपणन के परिणाम क्या हैं?
दुर्भाग्य से, कई लेख Google खोज के 10 वें पृष्ठ पर गहराई से दबे हुए हैं।
क्या "कम-ट्रैफ़िक" लेखों के मजबूत प्रभाव से बचने का कोई अच्छा तरीका है?
क्या आपने कभी एक स्व-संसाधित SEO लेखक बनाने की इच्छा व्यक्त की है जो शीर्ष प्रदर्शन वाले ब्लॉगों का ज्ञान क्लोन करता है और बड़े पैमाने पर ताजा सामग्री उत्पन्न करता है?
इस गाइड में, हम आपको n8n, Scrapeless, Gemini (आप चाहें तो इससे अन्य जैसे Claude/OpenRouter भी चुन सकते हैं), और Pinecone का उपयोग करके पूरी तरह से स्वचालित SEO सामग्री उत्पन्न करने के कार्यप्रवाह के निर्माण के लिए मार्गदर्शन करेंगे।
यह कार्यप्रवाह डेटा-आधारित उच्च-ट्रैफिक ब्लॉगों पर आधारित सामग्री एकत्र करने, संग्रहीत करने और उत्पन्न करने के लिए एक पुनर्प्राप्ति-वर्धित पीढ़ी (RAG) प्रणाली का उपयोग करता है।
YouTube ट्यूटोरियल: https://www.youtube.com/watch?v=MmitAOjyrT4
यह कार्यप्रवाह क्या करता है?
यह कार्यप्रवाह चार चरणों में शामिल होगा:
- भाग 1: Scrapeless Crawl को कॉल करें ताकि लक्षित वेबसाइट के सभी उप-पृष्ठों को क्रॉल किया जा सके, और Scrape का उपयोग करके प्रत्येक पृष्ठ की पूरी सामग्री का गहराई से विश्लेषण करें।
- भाग 2: क्रॉल की गई डेटा को Pinecone वेक्टर स्टोर में सहेजें।
- भाग 3: Scrapeless के Google Search नोड का उपयोग करके लक्षित विषय या कीवर्ड के मूल्य का पूरी तरह से विश्लेषण करें।
- भाग 4: Gemini को निर्देश दें, और RAG के माध्यम से तैयार किए गए डेटाबेस से संदर्भ सामग्री का एकीकरण करें, और लक्षित ब्लॉग उत्पन्न करें या प्रश्नों का उत्तर दें।
यदि आपने Scrapeless के बारे में नहीं सुना है, तो यह एक प्रमुख इन्फ्रास्ट्रक्चर कंपनी है जो AI एजेंटों, स्वचालन कार्यप्रवाहों और वेब क्रॉलिंग को शक्ति प्रदान करने पर ध्यान केंद्रित करती है। Scrapeless उन आवश्यक निर्माण ब्लॉकों को प्रदान करता है जो डेवलपर्स और व्यवसायों को कुशलता से बुद्धिमान, स्वायत्त प्रणालियाँ बनाने में सक्षम बनाते हैं।
इसके मूल में, Scrapeless ब्राउज़र-स्तरीय उपकरण और प्रोटोकॉल-आधारित APIs प्रदान करता है - जैसे कि हेडलेस क्लाउड ब्राउज़र, डीप सर्प API, और यूनिवर्सल क्रॉलिंग APIs - जो AI एजेंटों और स्वचालन प्लेटफार्मों के लिए एकीकृत, मॉड्यूलर आधार के रूप में कार्य करते हैं।
यह वास्तव में AI अनुप्रयोगों के लिए बनाया गया है क्योंकि AI मॉडल अक्सर कई चीजों के साथ अद्यतित नहीं होते हैं, चाहे वह वर्तमान घटनाएँ हों या नई प्रौद्योगिकियाँ
n8n के अलावा, इसे API के माध्यम से भी कॉल किया जा सकता है, और मेक जैसे मुख्यधारा प्लेटफार्मों पर नोड्स हैं:
आप इसे सीधे आधिकारिक वेबसाइट पर भी उपयोग कर सकते हैं।
n8n में Scrapeless का उपयोग करने के लिए:
- सेटिंग > सामुदायिक नोड्स पर जाएं
- n8n-nodes-scrapeless को खोजें और इसे स्थापित करें
हमें सबसे पहले n8n पर Scrapeless सामुदायिक नोड स्थापित करने की आवश्यकता है:
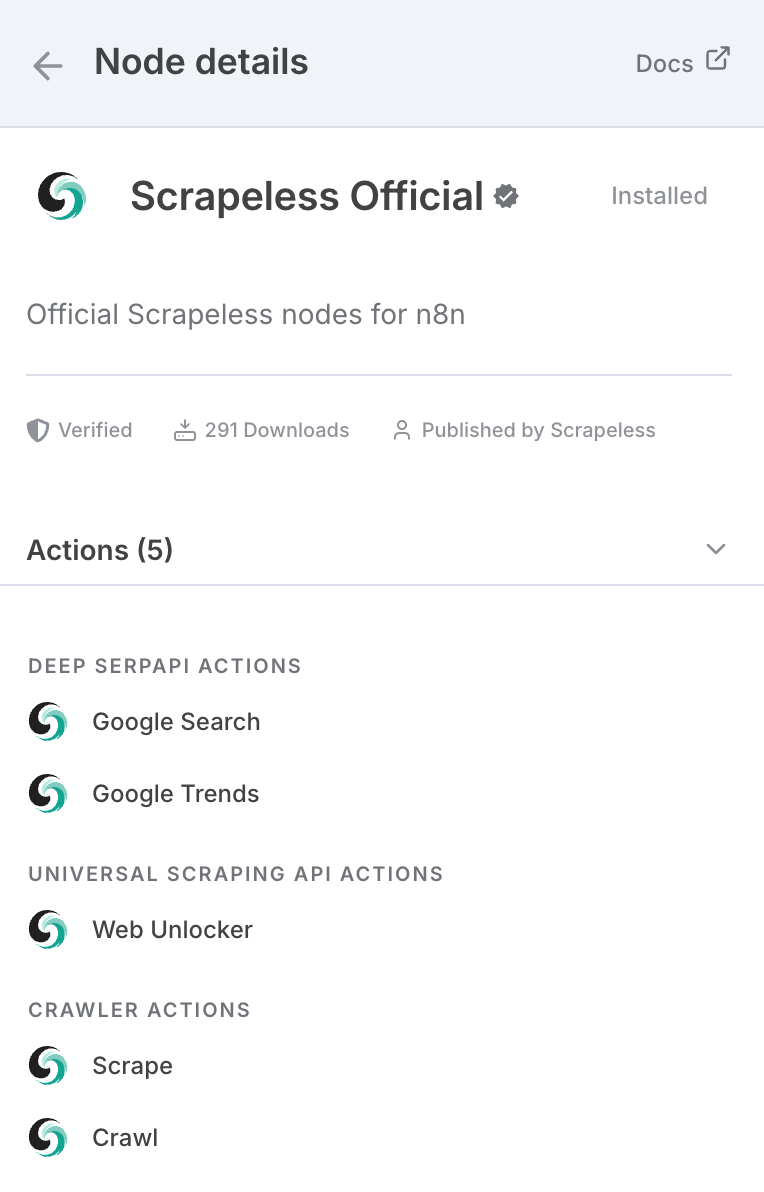
क्रेडेंशियल कनेक्शन
Scrapeless API कुंजी
इस ट्यूटोरियल में, हम Scrapeless सेवा का उपयोग करेंगे। कृपया सुनिश्चित करें कि आपने पंजीकरण कराया है और API कुंजी प्राप्त की है।
- Scrapeless वेबसाइट पर साइन अप करें ताकि आप अपनी API कुंजी प्राप्त करें और मुफ्त परीक्षण का दावा करें।
- इसके बाद, आप Scrapeless नोड खोल सकते हैं, क्रेडेंशियल्स अनुभाग में अपनी API कुंजी पेस्ट कर सकते हैं, और इसे कनेक्ट कर सकते हैं।
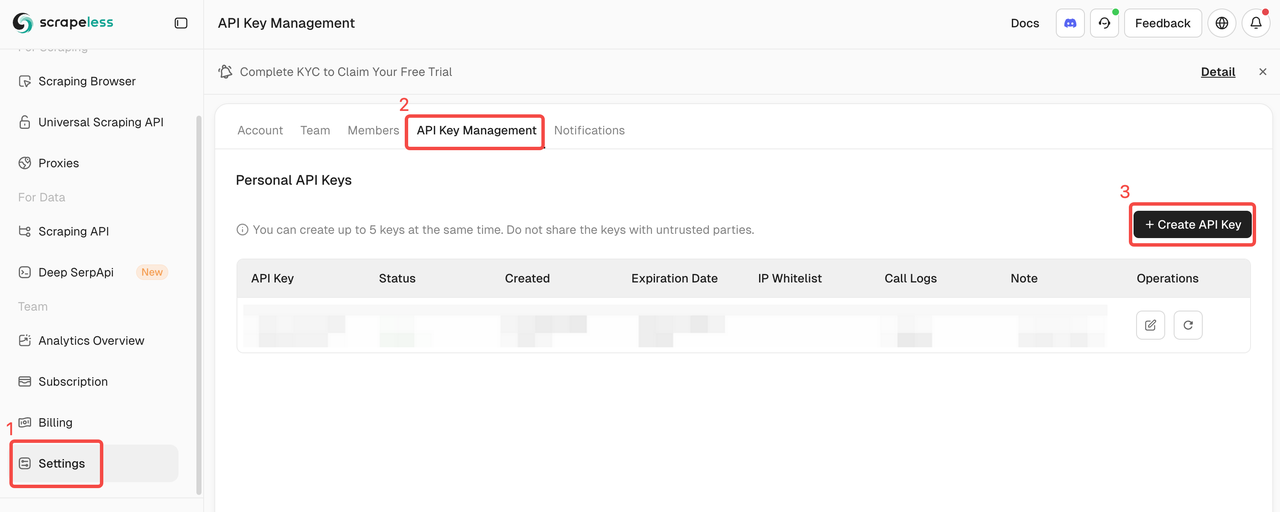
Pinecone इंडेक्स और API कुंजी
डेटा को क्रॉल करने के बाद, हम इसे एकीकृत और संसाधित करेंगे और सभी डेटा को Pinecone डेटाबेस में इकट्ठा करेंगे। हमें पहले से Pinecone API कुंजी और इंडेक्स तैयार करना होगा।
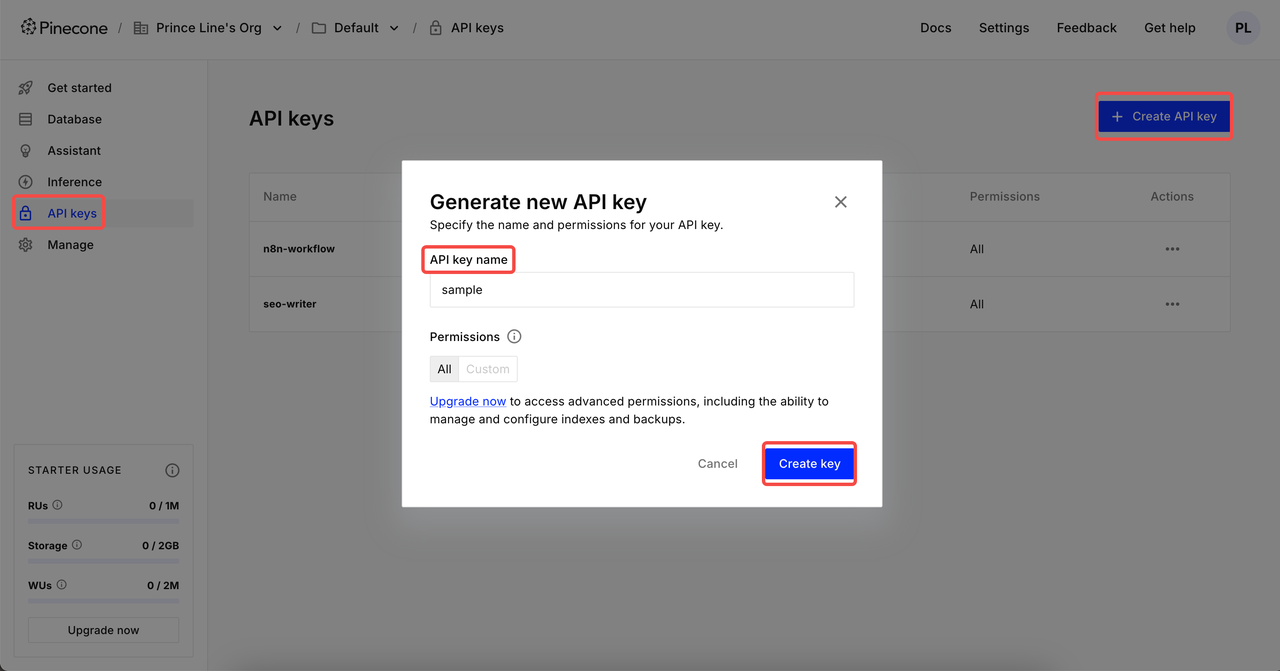
API कुंजी बनाएं
लॉगिन करने के बाद, API कुंजी पर क्लिक करें → API कुंजी बनाएं पर क्लिक करें → अपनी API कुंजी का नाम भरें → कुंजी बनाएं। अब, आप इसे n8n क्रेडेंशियल्स में सेट कर सकते हैं।
⚠️ निर्माण पूरा होने के बाद, कृपया अपनी API कुंजी कॉपी करें और सहेजें। डेटा सुरक्षा के लिए, Pinecone बनाई गई API कुंजी को फिर से प्रदर्शित नहीं करेगा।
इंडेक्स बनाएं
Here is the translation of the provided text into Hindi:
इंडेक्स क्लिक करें और निर्माण पृष्ठ पर जाएं। सेट करें इंडेक्स नाम → चुनें कॉन्फ़िगरेशन के लिए मॉडल → उचित आयाम सेट करें → इंडेक्स बनाएं।
2 सामान्य आयाम सेटिंग्स:
- Google Gemini Embedding-001 → 768 आयाम
- OpenAI का टेक्स्ट-एम्बेडिंग-3-स्मॉल → 1536 आयाम
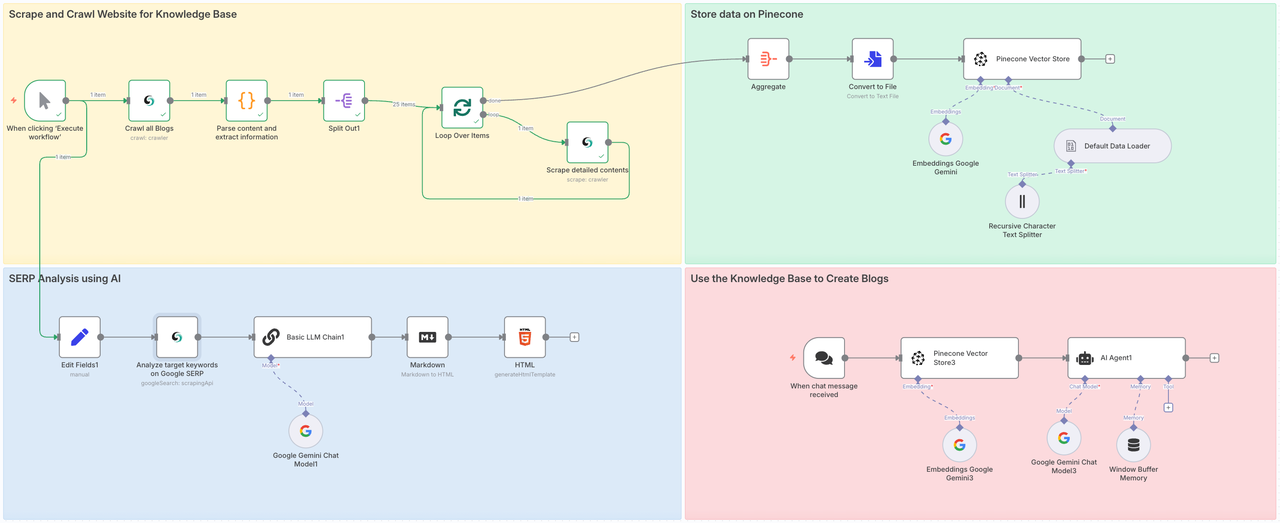
चरण 1: ज्ञान आधार के लिए वेबसाइटों को स्क्रैप और क्रॉल करें
पहला चरण सीधे सभी ब्लॉग सामग्री को एकत्रित करना है। बड़े क्षेत्र से सामग्री को क्रॉल करना हमारे एआई एजेंट को सभी क्षेत्रों से डेटा स्रोत प्राप्त करने की अनुमति देता है, ताकि अंतिम आउटपुट लेखों की गुणवत्ता सुनिश्चित हो सके।
- स्क्रैपलेस नोड लेख पृष्ठ को क्रॉल करता है और सभी ब्लॉग पोस्ट URLs एकत्र करता है।
- फिर यह हर URL के माध्यम से लूप करता है, ब्लॉग सामग्री को स्क्रैप करता है और डेटा को व्यवस्थित करता है।
- प्रत्येक ब्लॉग पोस्ट को आपके एआई मॉडल का उपयोग करके एंबेड किया जाता है और पाइनकॉन में संग्रहीत किया जाता है।
- हमारे मामले में, हम सिर्फ कुछ मिनटों में 25 ब्लॉग पोस्ट को स्क्रैप करते हैं - बिना एक अंगुली उठाए।
स्क्रैपलेस क्रॉल नोड
इस नोड का उपयोग लक्षित ब्लॉग वेबसाइट की सभी सामग्री को क्रॉल करने के लिए किया जाता है जिसमें मेटा डेटा, उप-पृष्ठ की सामग्री और इसे मार्कडाउन प्रारूप में निर्यात करना शामिल है। यह बड़े पैमाने पर सामग्री क्रॉलिंग है जिसे हम मैनुअल कोडिंग के माध्यम से जल्दी नहीं कर सकते।
कॉन्फ़िगरेशन:
- अपने स्क्रैपलेस एपीआई कुंजी को कनेक्ट करें
- संसाधन:
क्रॉलर - संचालन:
क्रॉल - अपने लक्षित स्क्रैपिंग वेबसाइट का इनपुट दें। यहाँ हम https://www.scrapeless.com/hi/blog को संदर्भ के रूप में उपयोग करते हैं।
कोड नोड
ब्लॉग डेटा प्राप्त करने के बाद, हमें डेटा को पार्स करना और उसमें से आवश्यक संरचित जानकारी निकालनी है।
नीचे वह कोड है जिसका मैंने इस्तेमाल किया। आप इसे सीधे संदर्भित कर सकते हैं:
JavaScript
return items.map(item => {
const md = $input.first().json['0'].markdown;
if (typeof md !== 'string') {
console.warn('मार्कडाउन सामग्री एक स्ट्रिंग नहीं है:', md);
return {
json: {
title: '',
mainContent: '',
extractedLinks: [],
error: 'मार्कडाउन सामग्री एक स्ट्रिंग नहीं है'
}
};
}
const articleTitleMatch = md.match(/^#\s*(.*)/m);
const title = articleTitleMatch ? articleTitleMatch[1].trim() : 'कोई शीर्षक नहीं मिला';
let mainContent = md.replace(/^#\s*.*(\r?\n)+/, '').trim();
const extractedLinks = [];
const linkRegex = /\[([^\]]+)\]\((https?:\/\/[^\s#)]+)\)/g;
let match;
while ((match = linkRegex.exec(mainContent))) {
extractedLinks.push({
text: match[1].trim(),
url: match[2].trim(),
});
}
return {
json: {
title,
mainContent,
extractedLinks,
},
};
});नोड: अलग करें
अलग नोड हमें साफ किए गए डेटा को एकीकृत करने और हमें आवश्यक URLs और पाठ सामग्री निकालने में मदद कर सकता है।
आइटम पर लूप + स्क्रैपलेस स्क्रेप
आइटम पर लूप
स्क्रैपलेस के स्क्रेप के साथ लूप ओवर टाइम नोड का उपयोग करके बार-बार क्रॉलिंग कार्य करें, और पहले प्राप्त सभी आइटमों का गहन विश्लेषण करें।
स्क्रैपलेस स्क्रेप
स्क्रैप नोड का उपयोग पूर्व में प्राप्त URL में समाहित सभी सामग्री को क्रॉल करने के लिए किया जाता है। इस तरह, प्रत्येक URL को गहराई से विश्लेषण किया जा सकता है। मार्कडाउन प्रारूप में लौटाया गया और मेटाडेटा और अन्य जानकारी एकीकृत की गई।
चरण 2. पाइनकॉन पर डेटा संग्रहीत करें
हमने सफलतापूर्वक स्क्रैपलेस ब्लॉग पृष्ठ की पूरी सामग्री निकाल ली है। अब हमें पाइनकॉन वेक्टर स्टोर तक पहुंचने की आवश्यकता है ताकि हम इस जानकारी को स्टोर कर सकें ताकि हम इसे बाद में उपयोग कर सकें।
नोड: एग्रीगेट
ज्ञान आधार में डेटा को सुविधाजनक तरीके से संग्रहीत करने के लिए, हमें सभी सामग्री को एकीकृत करने के लिए एग्रीगेट नोड का उपयोग करने की आवश्यकता है।
- एग्रीगेट:
सभी आइटम डेटा (एक सूची में) - फील्ड में आउटपुट डालें:
data - शामिल करें:
सभी फ़ील्ड
शानदार! सभी डेटा सफलतापूर्वक एकीकृत किया गया है। अब हमें प्राप्त डेटा को एक टेक्स्ट फॉर्मेट में परिवर्तित करने की आवश्यकता है जिसे सीधे पाइनकोन द्वारा पढ़ा जा सके। ऐसा करने के लिए, बस एक फ़ाइल में परिवर्तित करें।
नोड: पाइनकोन वेक्टर स्टोर
अब हमें ज्ञान आधार को कॉन्फ़िगर करने की आवश्यकता है। उपयोग किए गए नोड हैं:
पाइनकोन वेक्टर स्टोरगूगल जेमीनीडिफ़ॉल्ट डेटा लोडररिकर्सिव कैरेक्टर टेक्स्ट स्प्लिटर
उपर्युक्त चार नोड पुनरावृत्त रूप से उस डेटा को एकीकृत और क्रॉल करेंगे जिसे हमने प्राप्त किया है। फिर सभी को पाइनकोन ज्ञान आधारित में एकीकृत किया जाएगा।
चरण 3. AI का उपयोग करके SERP विश्लेषण
यह सुनिश्चित करने के लिए कि आप ऐसा कंटेंट लिख रहे हैं जो रैंक करे, हम एक जीवित SERP विश्लेषण करते हैं:
- अपने चुने हुए कीवर्ड के लिए खोज परिणाम प्राप्त करने के लिए Scrapeless Deep SerpApi का उपयोग करें
- दोनों कीवर्ड और खोज इरादा (जैसे, स्क्रैपिंग, गूगल ट्रेंड्स, API) इनपुट करें
- परिणामों का विश्लेषण एक LLM द्वारा किया जाता है और उन्हें HTML रिपोर्ट में संक्षेपित किया जाता है
नोड: फ़ील्ड संपादित करें
ज्ञान आधार तैयार है! अब यह निर्धारित करने का समय है कि हमारे लक्ष्य कीवर्ड क्या हैं। सामग्री बॉक्स में लक्ष्य कीवर्ड भरें और इरादा जोड़ें।
नोड: गूगल सर्च
गूगल सर्च नोड लक्ष्य कीवर्ड प्राप्त करने के लिए Scrapeless का डीप सर्पAPI कॉल करता है।
नोड: LLM चेन
जेमिनी के साथ LLM चेन बनाना हमें पिछले चरणों में प्राप्त डेटा का विश्लेषण करने में मदद कर सकता है और LLM को वह संदर्भ इनपुट और इरादा समझा सकता है जिसका हमें उपयोग करना है ताकि LLM उस फीडबैक को उत्पन्न कर सके जो बेहतर तरीके से जरूरतों को पूरा करे।
नोड: मार्कडाउन
चूंकि LLM सामान्यतः मार्कडाउन प्रारूप में आउटपुट करता है, उपयोगकर्ता के रूप में हम सीधे उस डेटा को प्राप्त नहीं कर सकते जिसकी हमें सबसे स्पष्ट आवश्यकता है, इसलिए कृपया परिणामों को HTML में परिवर्तित करने के लिए एक मार्कडाउन नोड जोड़ें।
नोड: HTML
अब हमें परिणामों को मानकीकरण करने के लिए HTML नोड का उपयोग करने की आवश्यकता है - संबंधित सामग्री को अंतर्ज्ञानी रूप से प्रदर्शित करने के लिए ब्लॉग/रिपोर्ट प्रारूप का उपयोग करें।
- संचालन:
HTML टेम्पलेट उत्पन्न करें
आवश्यक कोड इस प्रकार है:
XML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>रिपोर्ट सारांश</title>
<link href="https://fonts.googleapis.com/css2?family=Inter:wght@400;600;700&display=swap" rel="stylesheet">
<style>
body {
margin: 0;
padding: 0;
font-family: 'Inter', sans-serif;
background: #f4f6f8;
display: flex;
align-items: center;
justify-content: center;
min-height: 100vh;
}
.container {
background-color: #ffffff;
max-width: 600px;
width: 90%;
padding: 32px;
border-radius: 16px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
text-align: center;
}
h1 {
color: #ff6d5a;
font-size: 28px;
font-weight: 700;
margin-bottom: 12px;
}
h2 {
color: #606770;
font-size: 20px;
font-weight: 600;
margin-bottom: 24px;
}
.content {
color: #333;
font-size: 16px;
line-height: 1.6;
white-space: pre-wrap;
}
@media (max-width: 480px) {
.container {
padding: 20px;
}
h1 {
font-size: 24px;
}
h2 {
font-size: 18px;
}
}
</style>
</head>
<body>
<div class="container">
<h1>डेटा रिपोर्ट</h1>
<h2>स्वचालन के माध्यम से संसाधित</h2>
<div class="content">{{ $json.data }}</div>
</div>
<script>
console.log("नमस्ते दुनिया!");
</script>
</body>
</html>इस रिपोर्ट में शामिल हैं:
- शीर्ष-रैंकिंग कीवर्ड और लंबे-पूंछ वाले वाक्यांश
- उपयोगकर्ता खोज इरादा रुझान
- सुझावित ब्लॉग शीर्षक और कोण
- कीवर्ड क्लस्टरिंग
चरण 4. AI + RAG के साथ ब्लॉग उत्पन्न करना
अब जब आपने ज्ञान संचित और संग्रहीत किया है और अपने कीवर्ड पर शोध किया है, तो अपने ब्लॉग को उत्पन्न करने का समय आ गया है।
- SERP रिपोर्ट से अंतर्दृष्टि का उपयोग करते हुए एक प्रॉम्प्ट तैयार करें
- AI एजेंट (जैसे, क्लॉड, जेमिनी, या ओपनराउटर) को कॉल करें
- मॉडल पाइनकोन से प्रासंगिक संदर्भ प्राप्त करता है और एक पूर्ण ब्लॉग पोस्ट लिखता है
सामान्य एआई आउटपुट के विपरीत, यहाँ का परिणाम Scrapeless की मूल सामग्री से विशेष विचारों, वाक्यांशों और टोन को शामिल करता है — जो RAG के कारण संभव हुआ है।
अंतिम विचार
यह अंत-से-अंत SEO सामग्री इंजन n8n + Scrapeless + वेक्टर डेटाबेस + LLMs की शक्ति को प्रदर्शित करता है।
आप कर सकते हैं:
- Scrapeless ब्लॉग पेज को किसी अन्य ब्लॉग से बदलें
- पाइनकोन को अन्य वेक्टर स्टोर्स के लिए स्वैप करें
- लेखन इंजन के रूप में OpenAI, क्लॉड या जेमिनी का उपयोग करें
- कस्टम प्रकाशन पाइपलाइन बनाएं (जैसे, CMS या Notion पर स्वचालित रूप से पोस्ट करना)
👉 आज ही Scrapeless कम्युनिटी नोड को स्थापित करके शुरू करें और बिना कोडिंग के बड़े पैमाने पर ब्लॉग उत्पन्न करना शुरू करें।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


