
什么是 Activepieces?
Activepieces 是一个开源的、以 AI 为先的无代码业务自动化平台——本质上是一个自托管的 Zapier 替代品,具有强大的浏览器自动化功能。
Scrapeless 在 Activepieces 中提供以下模块:
1. Google 搜索 – 访问并检索来自 Google 的丰富搜索数据。
2. Google 趋势 - 提取 Google 趋势数据,以跟踪关键字的流行度和搜索兴趣随时间的变化。
3. 通用抓取 – 访问并提取来自通常会阻止机器人的 JS 渲染网站的数据。
4. 抓取网页数据 – 从单个网页提取信息。
5. 从所有页面抓取数据 – 爬取一个网站及其链接页面以提取全面的数据。
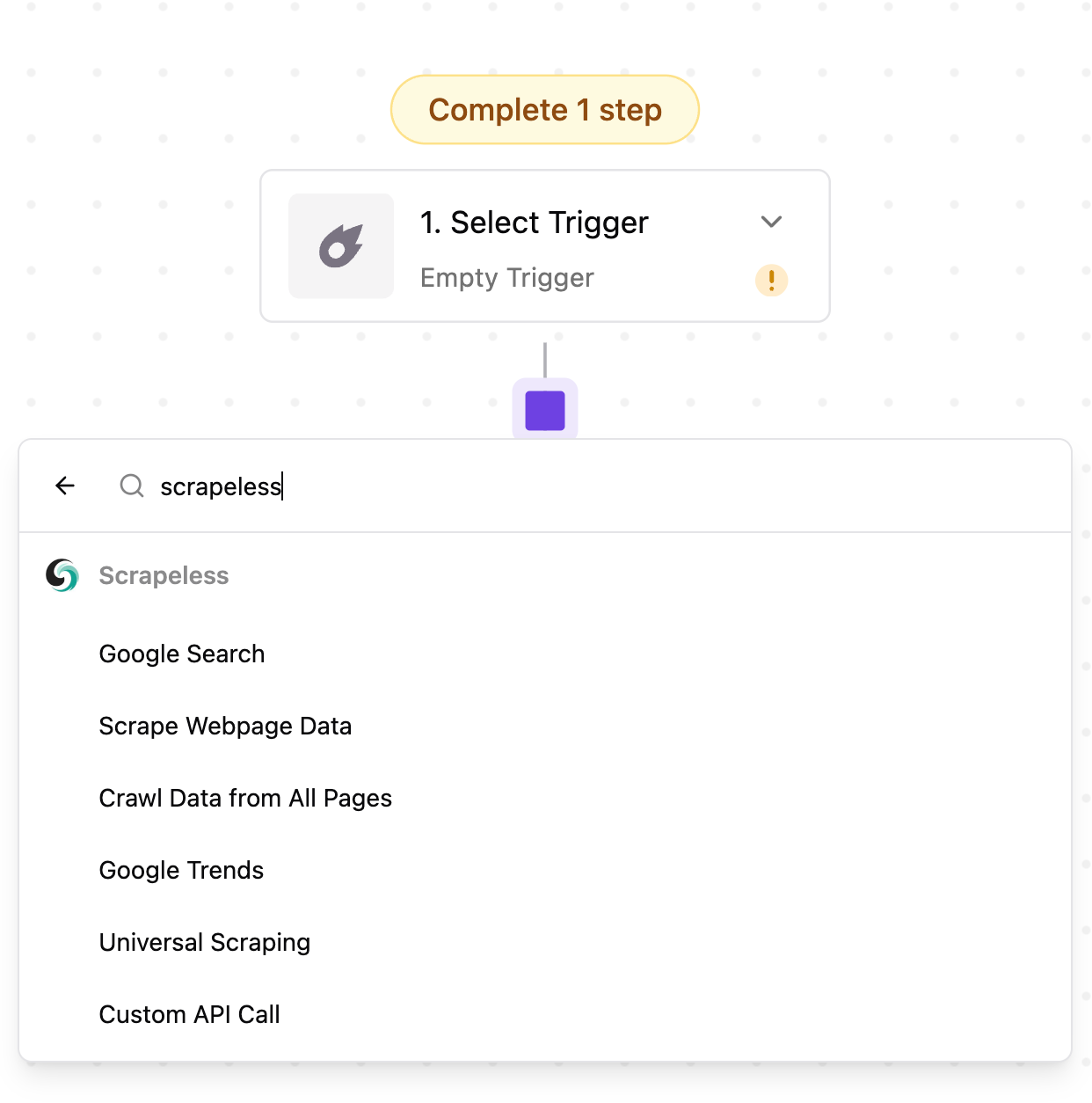
如何在 Activepieces 中使用 Scrapeless?
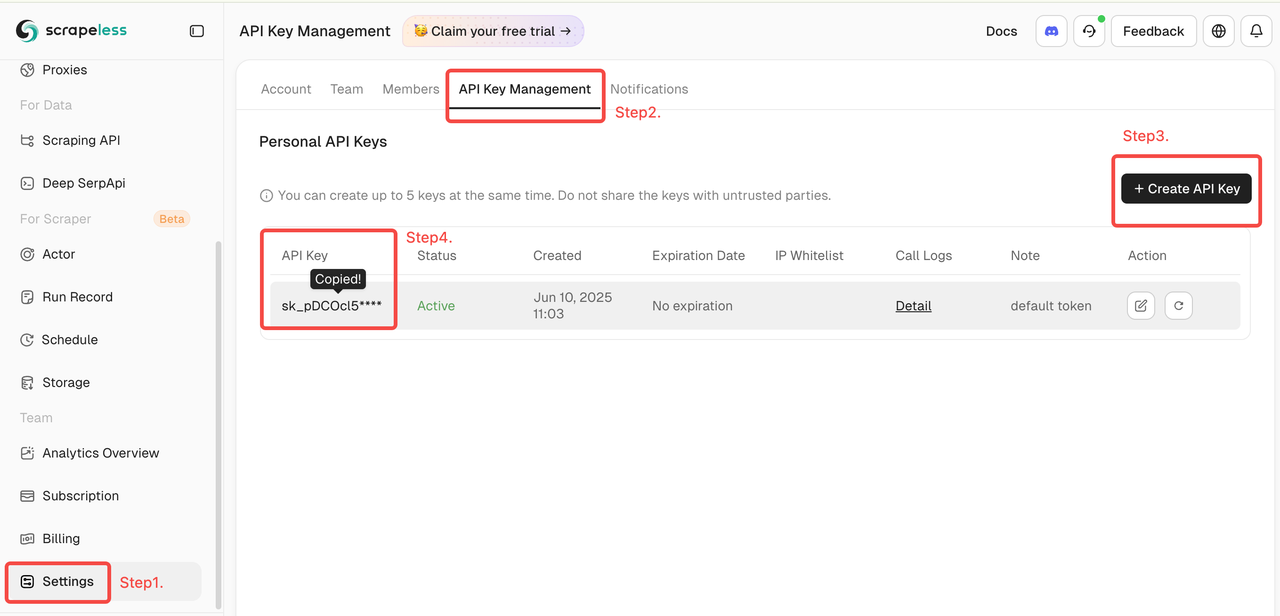
第一步:获取您的 Scrapeless API 密钥
- 创建一个帐户并 登录 Scrapeless 控制面板。您可以获得 2000 次免费 API 调用。
- 生成您的 Scrapeless API 密钥。
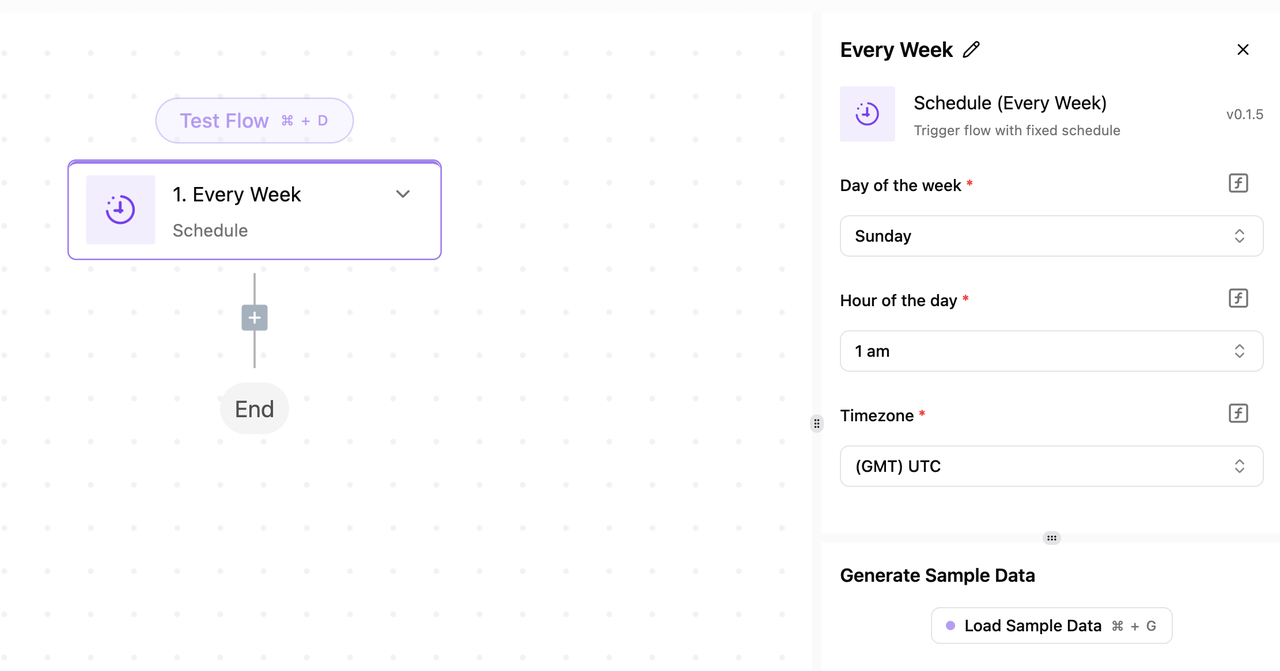
第二步:设置触发条件并连接到 Scrapeless
- 根据您的实际需求设置触发条件。
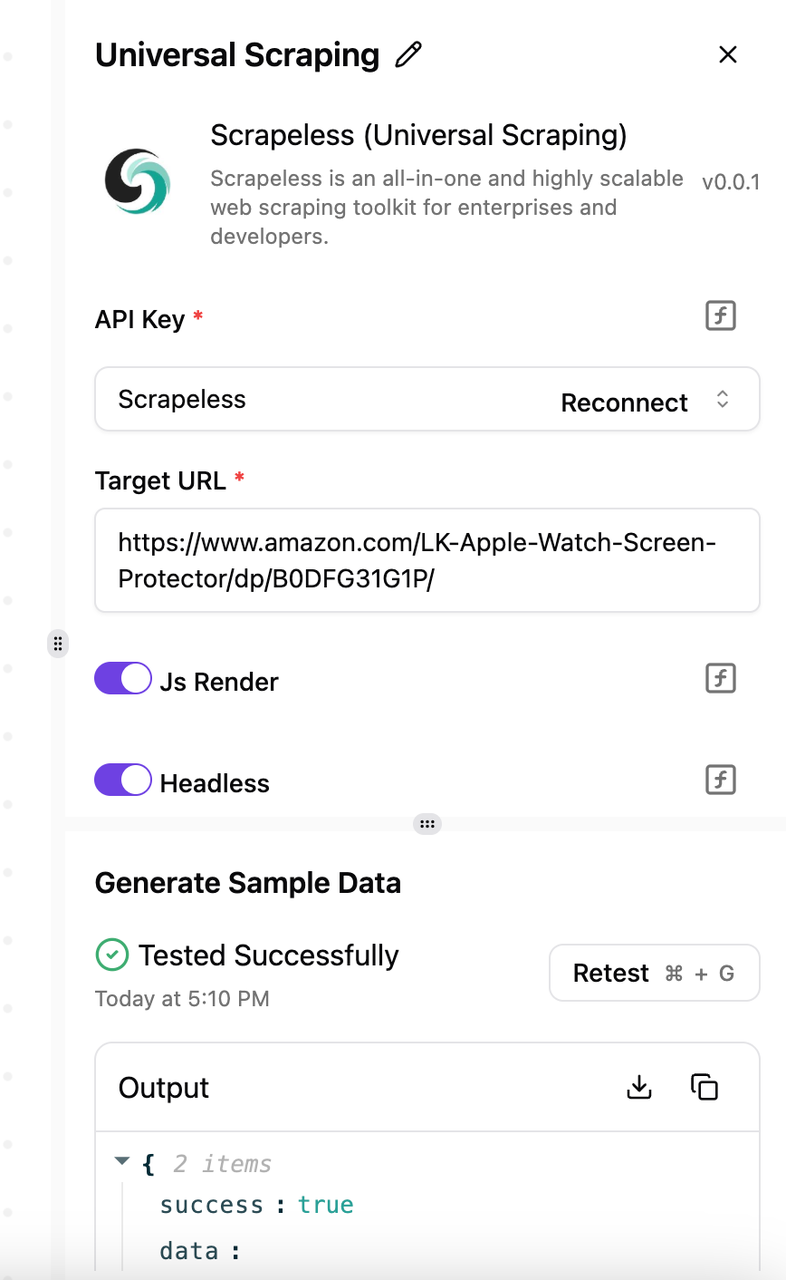
- 连接您的 Scrapeless 帐户。在这里,我们选择通用抓取,并使用
https://www.amazon.com/LK-Apple-Watch-Screen-Protector/dp/B0DFG31G1P/作为示例 URL。
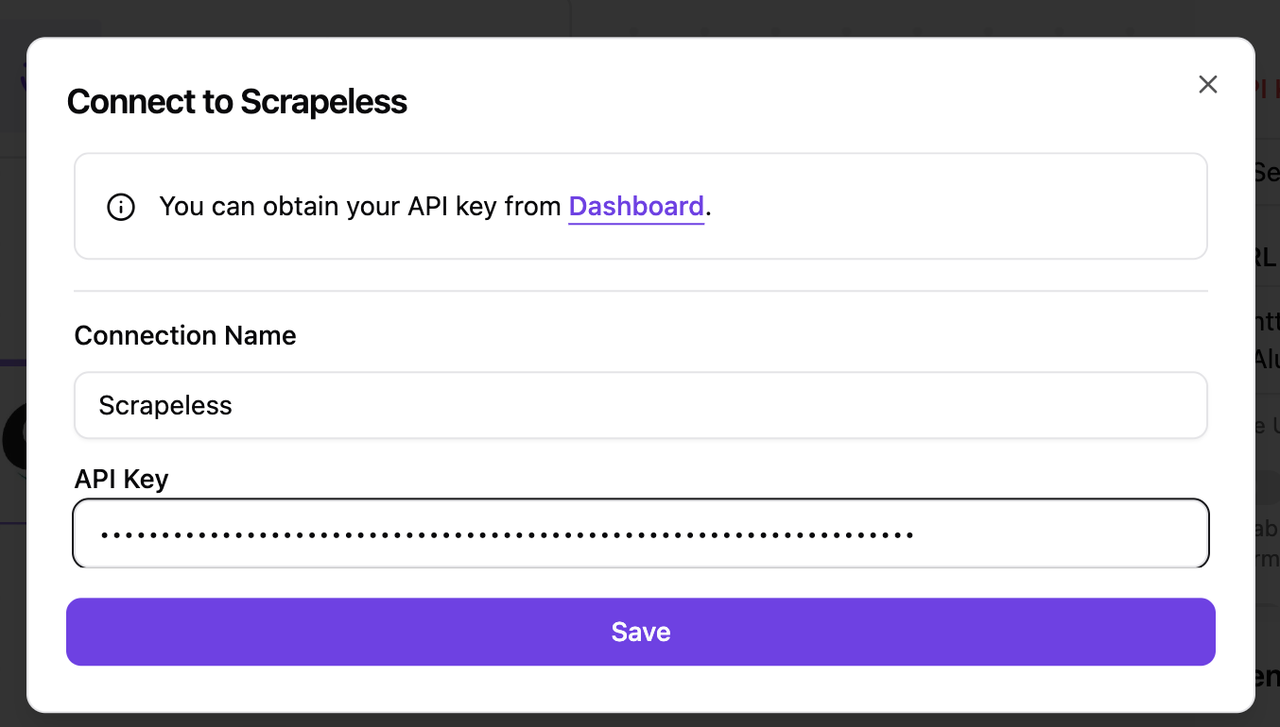
第三步:清理数据
接下来,我们需要清理在上一步中抓取的 HTML 数据。首先,在 输入 部分选择 通用抓取数据。代码配置如下:
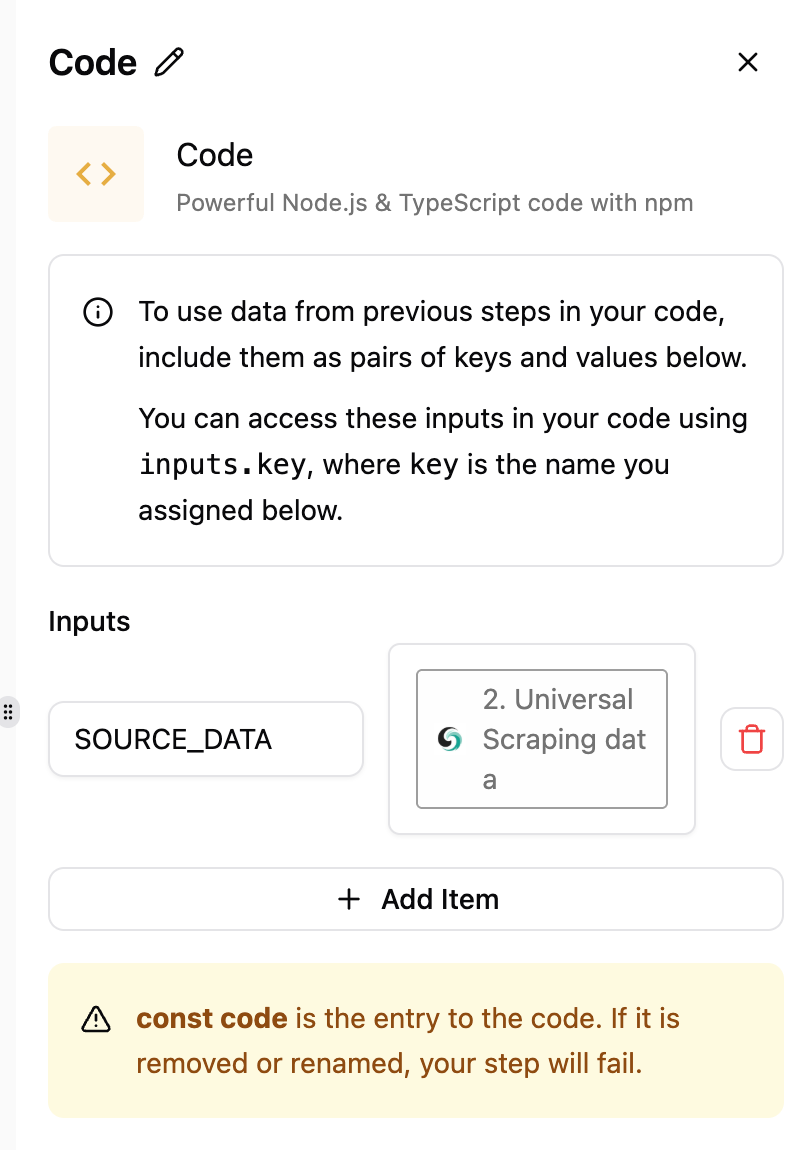
export const code = async (inputs) => {
const html = inputs.SOURCE_DATA
const titleMatch = html.match(/id=['"]productTitle['"][^>]*>([^<]+)</i);
const title = titleMatch ? titleMatch[1].trim() : "";
const priceMatch = html.match(/class=['"]a-offscreen['"][^>]*>\$?([\d.,]+)/i);
const price = priceMatch ? priceMatch[1].trim() : "";
const ratingMatch = html.match(/class=['"]a-icon-alt['"][^>]*>([^<]+)</i);
const rating = ratingMatch ? ratingMatch[1].trim() : "";
return [
{
json: {
title,
price,
rating
},
},
];
};第四步:连接到 Google Sheets
接下来,您可以选择将清理和结构化的数据输出到 Google Sheets。只需添加一个 Google Sheets 节点并配置您的 Google Sheets 连接。
注意:确保提前创建一个 Google Sheet。
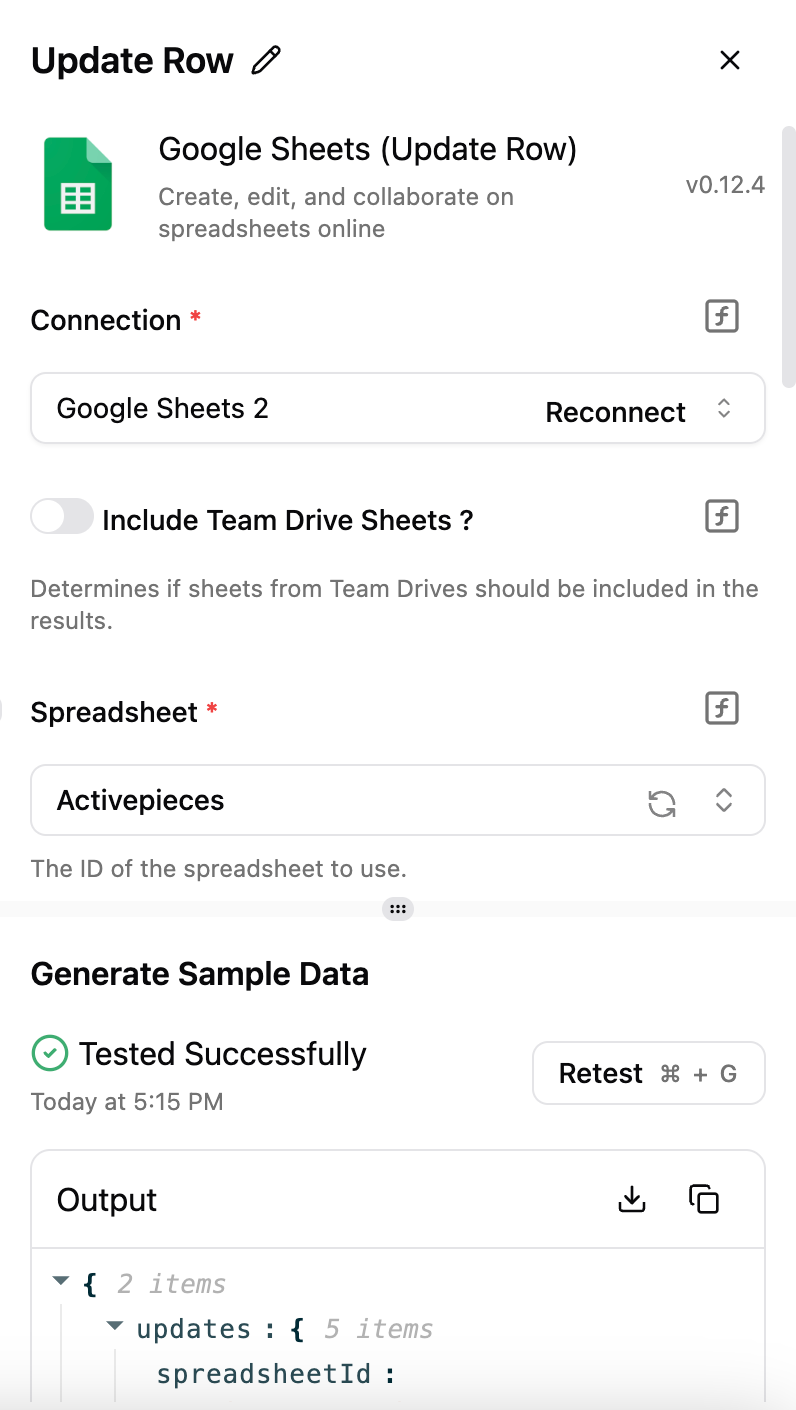
输出结果的示例

这就是如何设置和使用 Scrapeless 的简单教程。如果您有任何问题,可以在 Scrapeless Discord 上随时讨论。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。
在本页上