Loading...
🎯 Trình duyệt đám mây tùy chỉnh, chống phát hiện được hỗ trợ bởi Chromium tự phát triển, thiết kế dành cho trình thu thập dữ liệu web và tác nhân AI. 👉Dùng thử ngay
Hướng dẫn toàn diện nhất, được tạo ra cho tất cả các nhà phát triển cào web.
Scrapless cung cấp các dịch vụ tự động hóa và tự động hóa web được cung cấp bởi AI, mạnh mẽ và có thể mở rộng được tin tưởng bởi các doanh nghiệp hàng đầu. Các giải pháp cấp doanh nghiệp của chúng tôi được thiết kế để đáp ứng nhu cầu dự án của bạn, với sự hỗ trợ kỹ thuật chuyên dụng trong suốt. Với một nhóm kỹ thuật mạnh mẽ và thời gian phân phối linh hoạt, chúng tôi chỉ tính phí cho dữ liệu thành công, cho phép trích xuất dữ liệu hiệu quả trong khi bỏ qua các giới hạn.
Liên hệ với chúng tôi ngay bây giờ để thúc đẩy sự phát triển kinh doanh của bạn.
Cung cấp chi tiết liên hệ của bạn và chúng tôi sẽ nhanh chóng liên hệ để cung cấp bản demo và giới thiệu sản phẩm. Chúng tôi đảm bảo thông tin của bạn vẫn được bảo mật, tuân thủ các tiêu chuẩn GDPR.
Bản dùng thử miễn phí của bạn đã sẵn sàng! Đăng ký một tài khoản không cần thiết miễn phí và bản dùng thử của bạn sẽ được kích hoạt ngay lập tức trong tài khoản của bạn.
Học cách xây dựng một máy chủ proxy HTTP cơ bản đa luồng bằng cách sử dụng các mô-đun socket và threading của Python. Hướng dẫn này bao gồm các khái niệm cốt lõi của lập trình mạng và so sánh một giải pháp tùy chỉnh với khả năng mạnh mẽ của các dịch vụ thương mại như Scrapeless Proxies cho việc thu thập dữ liệu web ở mức độ sản xuất.

Khám phá thế giới của các proxy UDP: tìm hiểu chúng là gì, cách chúng hoạt động như một cổng cho các ứng dụng thời gian thực như trò chơi và VoIP, và cách chúng so sánh với các proxy HTTP và SOCKS. Khám phá những lợi ích của việc sử dụng một giải pháp proxy chuyên biệt như Scrapeless cho nhu cầu dữ liệu của bạn.

Hướng dẫn từng bước để cấu hình proxy HTTP/HTTPS và SOCKS trong Node.js sử dụng thư viện `node-fetch` và các gói proxy agent, cần thiết cho việc thu thập dữ liệu và web scraping ẩn danh. Tính năng Proxy Scrapeless.

Hướng dẫn toàn diện về IPv6, chi tiết về cấu trúc 128-bit của nó, những lợi thế chính so với IPv4 (không gian địa chỉ, bảo mật, hiệu quả), và vai trò quan trọng của nó trong việc cung cấp các giải pháp proxy có khả năng mở rộng và hiệu quả về chi phí cho việc thu thập dữ liệu web.

Khám phá các proxy công khai là gì, lợi ích của chúng và những rủi ro bảo mật đáng kể mà chúng gây ra. Tìm hiểu lý do tại sao các dịch vụ cao cấp như Scrapeless cung cấp một lựa chọn an toàn và đáng tin cậy hơn cho việc ẩn danh và thu thập dữ liệu trên web.

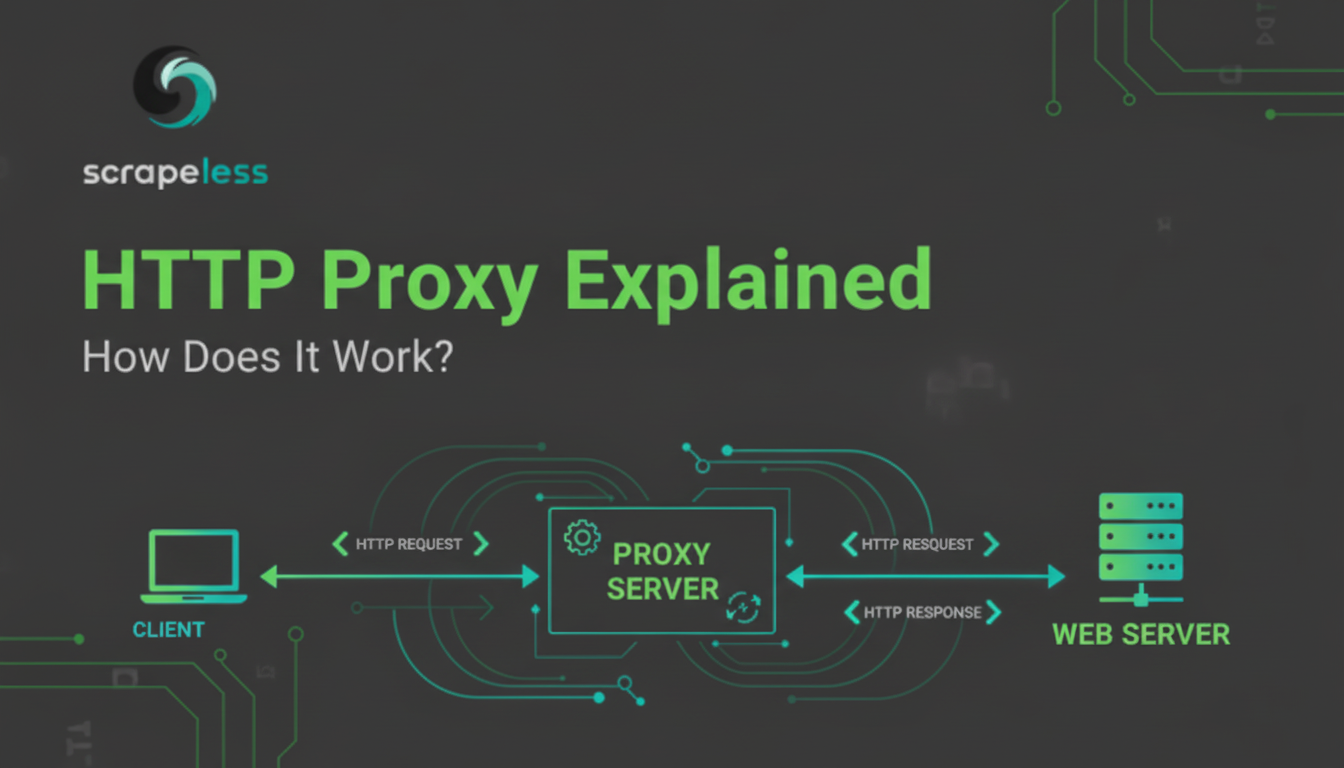
Một giải thích chi tiết về các proxy HTTP, bao gồm chức năng, các loại (Proxy chuyển tiếp, Proxy đảo ngược, Proxy trong suốt), lợi ích (An ninh, Lưu trữ, Ẩn danh) và vai trò thiết yếu trong việc thu thập dữ liệu trên web. Các tính năng của Proxy Scrapeless.
Hướng dẫn toàn diện về Interstellar Proxy, bao gồm các tính năng, bước triển khai và lý do tại sao các giải pháp chuyên nghiệp như Scrapeless Proxies là cần thiết cho các hoạt động dữ liệu lớn và đáng tin cậy.

So sánh tốc độ và hiệu suất thực tế của IPv4 và IPv6, phân tích sự khác biệt trong thiết kế, tác động đến hạ tầng, và cách các proxy hỗn hợp như Scrapeless có thể tối ưu hóa việc thu thập dữ liệu và hoạt động mạng của bạn.



