
Cách cạo dữ liệu công việc công khai của Google
Advanced Data Extraction Specialist
Với hàng triệu tin tuyển dụng trực tuyến, việc duyệt thủ công trên Google Jobs có thể tốn thời gian và không hiệu quả. Scrape kết quả Google Jobs cho phép bạn tự động hóa quy trình, tiết kiệm thời gian quý báu và truy cập nhanh vào các tin tuyển dụng mới nhất. Cho dù bạn là nhà tuyển dụng, nhà phát triển hay người tìm việc muốn thu thập dữ liệu liên quan, hướng dẫn này sẽ chỉ cho bạn từng bước cách scrape kết quả Google Jobs một cách hiệu quả và có trách nhiệm. Hãy bắt đầu thôi!
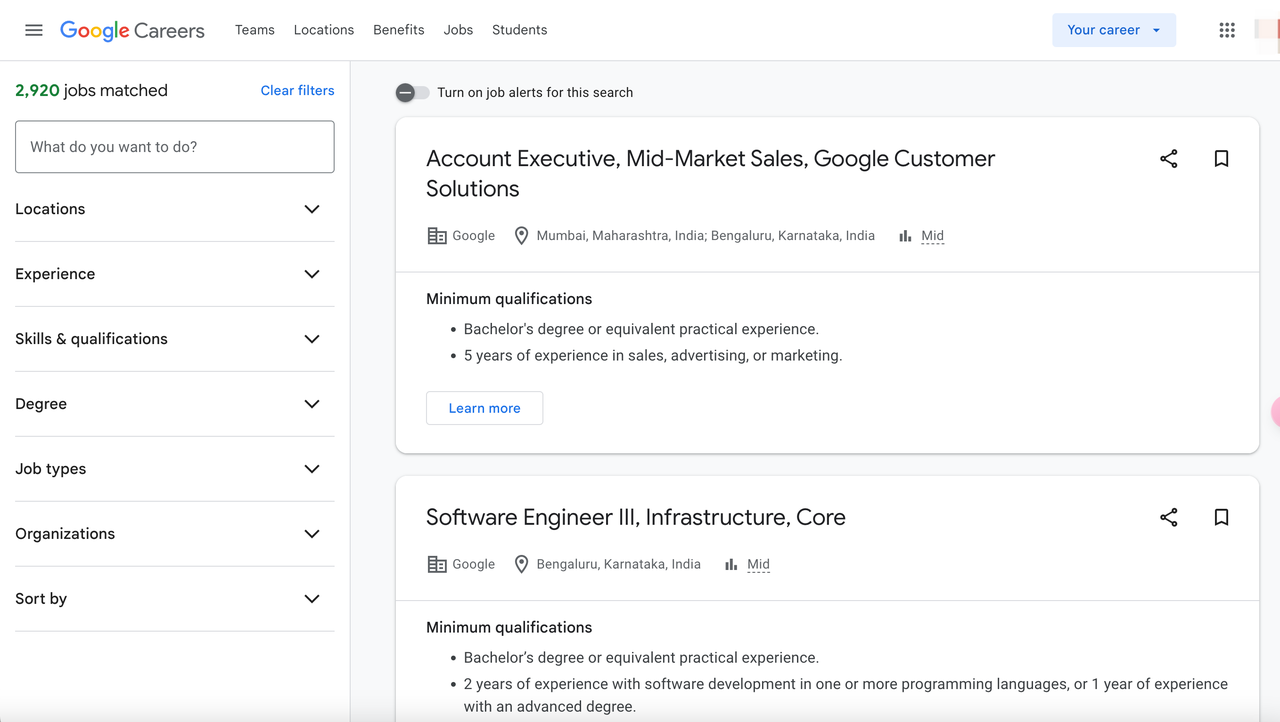
Tại sao nên Scrape Google Jobs?
Google Jobs tổng hợp các tin tuyển dụng từ nhiều nguồn, bao gồm các bảng tuyển dụng, trang web của công ty và các công ty tuyển dụng. Scrape Google Jobs có thể cung cấp cho bạn dữ liệu về:
- Xu hướng thị trường việc làm: Theo dõi các kỹ năng được yêu cầu, phạm vi lương và chức danh công việc.
- Phân tích cạnh tranh: Phân tích các tin tuyển dụng từ đối thủ cạnh tranh.
- Thông tin tuyển dụng: Cải thiện chiến lược tuyển dụng dựa trên dữ liệu thời gian thực.
Vì Google Jobs phục vụ một loạt các người tìm việc và nhà tuyển dụng, việc scrape dữ liệu này có thể mang lại những lợi thế đáng kể cho các bảng tuyển dụng, các công ty tuyển dụng, bộ phận nhân sự và các nhà nghiên cứu thị trường.
Thách thức của việc Scrape Google Jobs
Mặc dù việc scrape Google Jobs có thể rất có giá trị, nhưng nó đi kèm với những thách thức:
- Công nghệ chống Scrape: Google sử dụng các kỹ thuật như CAPTCHA, chặn IP và giới hạn tốc độ để ngăn chặn các bot scrape dữ liệu.
- Thay đổi HTML thường xuyên: Google thường xuyên cập nhật cấu trúc web của mình, yêu cầu các scraper phải liên tục thích ứng.
- Mối quan tâm pháp lý: Scrape Google Jobs có thể vi phạm điều khoản dịch vụ của Google, vì vậy điều cần thiết là phải thận trọng.
Tuy nhiên, với các công cụ phù hợp, bạn có thể vượt qua những rào cản này và scrape kết quả Google Jobs một cách hiệu quả
Các công cụ được đề xuất: Sử dụng Scrapeless để Scrape Google Jobs
Scrapeless Google Job Scraping API là một công cụ để trích xuất dữ liệu công việc từ công cụ tìm kiếm Google Jobs. Nó cho phép người dùng lấy dữ liệu có cấu trúc liên quan đến tìm kiếm việc làm cụ thể, chẳng hạn như tiêu đề công việc, tên công ty, địa điểm làm việc, ngày đăng, mô tả công việc, v.v., thông qua các cuộc gọi API đơn giản. API được thiết kế để đơn giản hóa quy trình thu thập dữ liệu, cho phép người dùng tập trung vào việc phân tích và tận dụng dữ liệu mà không cần phải xử lý những phức tạp của việc scrape và phân tích cú pháp web.
Scrapeless Google Job Scraping API cung cấp nhiều tham số cho phép người dùng tùy chỉnh các yêu cầu tìm kiếm theo nhu cầu cụ thể.
Dưới đây là một số tham số thường được sử dụng:
| Tham số | Bắt buộc | Mô tả |
|---|---|---|
| engine | TRUE | Đặt tham số thành google_jobs để sử dụng công cụ API Google Jobs. |
| q | TRUE | Tham số xác định truy vấn bạn muốn tìm kiếm. |
| uule | FALSE | Tham số là vị trí được mã hóa của Google mà bạn muốn sử dụng cho tìm kiếm. Tham số uule và location không thể được sử dụng cùng nhau. |
| google_domain | FALSE | Tham số xác định miền Google cần sử dụng. Mặc định là google.com. Truy cập trang miền Google Google domains page để biết danh sách đầy đủ các miền Google được hỗ trợ. |
| gl | FALSE | Tham số xác định quốc gia cần sử dụng cho tìm kiếm Google. Đó là mã quốc gia hai chữ cái (ví dụ: us cho Hoa Kỳ, uk cho Vương quốc Anh hoặc fr cho Pháp). Truy cập trang quốc gia Google Google countries page để biết danh sách đầy đủ các quốc gia Google được hỗ trợ. |
| hl | FALSE | Tham số xác định ngôn ngữ cần sử dụng cho tìm kiếm Google Jobs. Đó là mã ngôn ngữ hai chữ cái (ví dụ: en cho tiếng Anh, es cho tiếng Tây Ban Nha hoặc fr cho tiếng Pháp). Truy cập trang ngôn ngữ Google Google languages page để biết danh sách đầy đủ các ngôn ngữ Google được hỗ trợ. |
| next_page_token | FALSE | Tham số xác định mã thông báo trang tiếp theo. Nó được sử dụng để truy xuất trang kết quả tiếp theo. Tối đa 10 kết quả được trả về mỗi trang. Mã thông báo trang tiếp theo có thể được tìm thấy trong phản hồi JSON của SerpApi: pagination -> next_page_token. |
| lrad | TRUE | Xác định bán kính tìm kiếm tính bằng kilomet. Không giới hạn bán kính một cách nghiêm ngặt. |
| ltype | TRUE | Tham số sẽ lọc kết quả theo hình thức làm việc tại nhà. |
| uds | TRUE | Tham số cho phép lọc tìm kiếm. Đó là một chuỗi được Google cung cấp dưới dạng bộ lọc. Giá trị uds được cung cấp trong phần: bộ lọc với giá trị uds, q và link được cung cấp cho mỗi bộ lọc. |
Tính năng chính:
- Thu thập dữ liệu công việc hiệu quả: Lấy dữ liệu Google Jobs trong thời gian thực và trả về thông tin công việc có cấu trúc để dễ dàng phân tích và sử dụng.
- Dễ dàng tích hợp: Hỗ trợ nhiều ngôn ngữ lập trình (Python, JavaScript, v.v.) và API trả về định dạng JSON, dễ dàng tích hợp và phân tích.
- Bỏ qua công nghệ chống thu thập dữ liệu: Tự động xử lý CAPTCHA và các biện pháp chống thu thập dữ liệu để đảm bảo thu thập dữ liệu ổn định mà không cần lo lắng về việc bị chặn IP.
- Lọc đa chiều và tìm kiếm tùy chỉnh: Hỗ trợ lọc theo loại công việc, địa điểm, mức lương, v.v. và cho phép các truy vấn tùy chỉnh để khớp chính xác với nhu cầu.
- Hỗ trợ phân trang: Tự động thu thập nhiều trang thông tin công việc để tránh xử lý phân trang thủ công.
- Phạm vi toàn cầu: Hỗ trợ thu thập dữ liệu xuyên khu vực, thích ứng với môi trường đa ngôn ngữ và cung cấp dữ liệu công việc toàn cầu.
- Phân tích và báo cáo: Dữ liệu đã thu thập có thể được sử dụng để phân tích xu hướng tuyển dụng, cung cấp báo cáo và thống kê thu thập dữ liệu chi tiết.
- Hỗ trợ kỹ thuật đáng tin cậy: Hỗ trợ dịch vụ khách hàng 24/7, cung cấp tài liệu và ví dụ chi tiết để giúp các nhà phát triển bắt đầu nhanh chóng.
Đăng ký dùng thử miễn phí của Scrapeless và nhận 100.000 yêu cầu! Trải nghiệm web scraping hiệu quả ngay bây giờ, dễ dàng lấy dữ liệu như Google Jobs và giúp dự án của bạn bắt đầu nhanh chóng! Đừng bỏ lỡ cơ hội này, hãy bắt đầu ngay!
Cách Scrape kết quả Google Jobs với Scrapeless
Sử dụng Scrapeless Google Job Scraping API rất đơn giản, chỉ cần làm theo các bước sau:
1. Đăng ký tài khoản Scrapeless và lấy khóa API.
Để bắt đầu, bạn cần lấy Khóa API từ Bảng điều khiển Scrapeless:
- Đăng nhập vào Bảng điều khiển Scrapeless.
- Điều hướng đến Quản lý Khóa API.
- Nhấp vào Tạo để tạo Khóa API duy nhất của bạn.
- Sau khi tạo, chỉ cần nhấp vào Khóa API để sao chép nó.

2. Tạo URL yêu cầu API, bao gồm các tham số bắt buộc.
- Truy cập tài liệu API.
- Nhấp vào "Thử nghiệm" cho điểm cuối mong muốn.
- Nhập khóa API của bạn vào trường "Xác thực".
- Điền vào các tham số cần thiết trong cài đặt tham số. (Ở đây chúng ta sử dụng barista new york làm ví dụ)
Dưới đây là các ví dụ về yêu cầu:
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.google.jobs",
"input": {
"engine": "google_jobs",
"q": "barista new york"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)3. Gửi yêu cầu HTTP đến điểm cuối API.
4. Phân tích dữ liệu định dạng JSON được trả về bởi API.
Dưới đây là một số ví dụ về kết quả. Bạn có thể xem thông tin cụ thể thông qua tài liệu API.
{
"filters": [
{
"name": "Salary",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=Barista+new+york+salary&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQIDRAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J",
"q": "Barista new york salary"
}
},
{
"name": "Remote",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista%2Bnew%2Byork+remote&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQICxAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU",
"q": "barista+new+york remote"
}
},
{
"name": "Date posted",
"options": [
{
"name": "Yesterday",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york since yesterday&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAC",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw",
"q": "barista new york since yesterday"
}
},
{
"name": "Last 3 days",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 3 days&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAD",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg",
"q": "barista new york in the last 3 days"
}
},
{
"name": "Last week",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last Tại sao Scrapeless là lý tưởng để Scrape Google Jobs
- Không có CAPTCHA: Scrapeless bỏ qua CAPTCHA, đảm bảo quá trình scrape diễn ra suôn sẻ.
- Quản lý Proxy tự động: Dịch vụ xoay vòng địa chỉ IP và quản lý proxy, vì vậy bạn sẽ không bị Google cấm.
- Tỷ lệ thành công cao: Scrapeless được xây dựng để xử lý các biện pháp chống bot của Google một cách hiệu quả, mang lại tỷ lệ thành công cao cho việc scrape.
- Dữ liệu có cấu trúc: Scrapeless trả về dữ liệu ở định dạng có cấu trúc, giúp dễ dàng phân tích và tích hợp vào quy trình làm việc của bạn.
Ngoài ra, Scrapeless SERP API cũng hỗ trợ trích xuất dữ liệu từ Google Maps, Google Flights, Google Trends, các trang kết quả tìm kiếm của Google, v.v.
Các thực tiễn tốt nhất để Scrape Google Jobs
Mặc dù việc scrape có thể hiệu quả, nhưng điều quan trọng là phải tuân theo các thực tiễn tốt nhất để tránh các vấn đề:
- Tôn trọng Điều khoản dịch vụ của Google: Scrape Google Jobs có thể vi phạm điều khoản dịch vụ của Google, vì vậy luôn sử dụng scraping một cách có trách nhiệm và hiểu rõ các rủi ro pháp lý tiềm tàng.
- Điều tiết Yêu cầu: Đừng quá tải Google với quá nhiều yêu cầu trong một thời gian ngắn. Sử dụng các tính năng như giới hạn tốc độ hoặc độ trễ ngẫu nhiên để tránh bị phát hiện.
- Giám sát hiệu suất Scrape: Thường xuyên giám sát hiệu suất của công cụ scrape để đảm bảo nó hoạt động như mong muốn và dữ liệu chính xác.
Câu hỏi thường gặp về Google Jobs Scraper
1. Google Jobs Scraper là gì?
Google Jobs Scraper là một công cụ được thiết kế để trích xuất các tin tuyển dụng từ Google Jobs. Nó có thể giúp bạn thu thập dữ liệu có giá trị như tiêu đề công việc, tên công ty, địa điểm, mức lương và mô tả công việc.
2. Việc scrape Google Maps có hợp pháp không?
Việc scrape dữ liệu công khai vì lý do đạo đức không vi phạm pháp luật.
Kết luận
Việc scrape kết quả Google Jobs có thể cung cấp những hiểu biết có giá trị về thị trường việc làm, giúp tối ưu hóa chiến lược tuyển dụng và cho phép các doanh nghiệp duy trì khả năng cạnh tranh. Scrapeless cung cấp một giải pháp tuyệt vời để scrape các tin tuyển dụng từ Google mà không cần phải xử lý CAPTCHA, lệnh cấm IP hoặc mã hóa phức tạp. Bằng cách sử dụng Scrapeless, bạn có thể nhanh chóng thu thập dữ liệu công việc có cấu trúc và sử dụng nó cho nghiên cứu thị trường hoặc nỗ lực tuyển dụng của mình.
Cho dù bạn là nhà phân tích dữ liệu, nhà tuyển dụng hay doanh nghiệp muốn hiểu xu hướng tuyển dụng, Scrapeless đều cung cấp một cách đơn giản, đáng tin cậy và hiệu quả để truy cập dữ liệu Google Jobs.
Sử dụng Scrapeless ngay bây giờ và cải thiện hiệu quả scraping của bạn! Chỉ cần đăng ký và bạn có thể nhận được 1000000 yêu cầu miễn phí, tham gia cộng đồng Discord của chúng tôi và tham gia các hoạt động để kiếm thêm tín dụng miễn phí!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


