
Hướng dẫn tích hợp MCP: Chrome DevTools MCP, Playwright MCP và Scrapeless Browser MCP
Expert Network Defense Engineer
Hướng dẫn này giới thiệu ba máy chủ Giao thức Ngữ cảnh Mô hình (MCP) — Chrome DevTools MCP, Playwright MCP và Browser MCP.
Tổng quan: Chọn MCP phù hợp
| Loại MCP | Công nghệ | Lợi ích | Hệ sinh thái chính | Tốt nhất cho |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | Tiêu chuẩn chính thức, công cụ phân tích hiệu suất mạnh mẽ và sâu sắc. | Rộng (Gemini, Copilot, Cursor) | Tự động hóa CI/CD, quy trình làm việc đa IDE và kiểm toán hiệu suất sâu. |
| Playwright MCP | Node.js / Playwright | Sử dụng cây khả năng tiếp cận thay vì điểm ảnh; chắc chắn và thân thiện với LLM mà không cần nhìn. | Rộng (VS Code, Copilot) | Tự động hóa có cấu trúc, đáng tin cậy, ít bị hỏng do thay đổi giao diện nhỏ. |
| Scrapeless Browser MCP | Dịch vụ đám mây | Không cần thiết lập địa phương, trình duyệt đám mây có thể mở rộng, xử lý các trang web phức tạp và biện pháp chống bot. | Dựa trên API (Bất kỳ khách hàng nào) | Nhiệm vụ tự động hóa quy mô lớn, song song và tương tác với các trang web có phát hiện bot mạnh mẽ. |
Một trình duyệt đám mây, vô vàn tích hợp
Cả ba MCP — Chrome DevTools MCP, Playwright MCP và Scrapeless Browser MCP — đều chia sẻ một nền tảng: tất cả đều kết nối với Scrapeless Cloud Browser.
Khác với tự động hóa trình duyệt địa phương truyền thống, Scrapeless Browser chạy hoàn toàn trên đám mây, cung cấp sự linh hoạt và khả năng mở rộng vô song cho các nhà phát triển và tác nhân AI.
Dưới đây là những điều làm cho nó thực sự mạnh mẽ:
- Tích hợp liền mạch: Hoàn toàn tương thích với Puppeteer, Playwright và CDP, cho phép di chuyển dễ dàng từ các dự án hiện có chỉ với một dòng mã.
- Phủ sóng IP toàn cầu: Truy cập vào các nhóm IP dân cư, ISP và không giới hạn ở hơn 195 quốc gia, với mức giá minh bạch và hiệu quả ($0.6–1.8/GB). Hoàn hảo cho tự động hóa dữ liệu web quy mô lớn.
- Hồ sơ cách ly: Mỗi nhiệm vụ chạy trong một môi trường riêng biệt, đảm bảo cô lập phiên, quản lý nhiều tài khoản và ổn định lâu dài.
- Mở rộng đồng thời không giới hạn: Khởi động ngay lập tức 50–1000+ phiên bản trình duyệt với hạ tầng tự động mở rộng — không cần thiết lập máy chủ, không nút thắt hiệu suất.
- Các nút biên trên toàn cầu: Triển khai trên nhiều nút toàn cầu để có độ trễ cực thấp và khởi động nhanh hơn 2–3 lần so với các trình duyệt đám mây khác.
- Chống phát hiện: Giải pháp tích hợp cho reCAPTCHA, Cloudflare Turnstile và AWS WAF, đảm bảo tự động hóa không bị gián đoạn ngay cả dưới các lớp bảo vệ nghiêm ngặt.
- Gỡ lỗi trực quan: Đạt được gỡ lỗi tương tác giữa người và máy và theo dõi lưu lượng proxy theo thời gian thực qua Live View. Phát lại các phiên theo từng trang thông qua Ghi âm Phiên để nhanh chóng xác định sự cố và tối ưu hóa hoạt động.
Chrome DevTools MCP
Chrome DevTools MCP là một máy chủ Giao thức Ngữ cảnh Mô hình (MCP) cho phép các trợ lý lập trình AI — như Gemini, Claude, Cursor, hoặc Copilot — điều khiển và kiểm tra một trình duyệt Chrome trực tiếp để tự động hóa đáng tin cậy, gỡ lỗi nâng cao và phân tích hiệu suất.
Tính năng chính
- Nhận thông tin hiệu suất: Sử dụng Chrome DevTools để ghi lại các dấu vết và trích xuất thông tin hiệu suất có thể hành động.
- Gỡ lỗi trình duyệt nâng cao: Phân tích các yêu cầu mạng, chụp màn hình và kiểm tra bảng điều khiển trình duyệt.
- Tự động hóa đáng tin cậy: Sử dụng Puppeteer để tự động hóa các hành động trong Chrome và tự động chờ kết quả hành động.
Yêu cầu
- Node.js v20.19 hoặc phiên bản LTS bảo trì mới nhất.
- npm.
Bắt đầu
Đăng nhập vào Scrapeless và lấy API Key của bạn.
Khởi động nhanh
Cấu hình JSON này được sử dụng bởi một khách hàng MCP để kết nối với máy chủ Chrome DevTools MCP và điều khiển phiên bản trình duyệt đám mây Scrapeless từ xa.
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"chrome-devtools-mcp@latest",
"--wsEndpoin=wss://browser.scrapeless.com/api/v2/browser?token=scrapeless api key&proxyCountry=US&sessionRecording=true&sessionTTL=900&sessionName=CDPDemo"
]
}
}
}Trường hợp sử dụng
- Phân tích hiệu suất web: Ghi lại các dấu vết bằng CDP và trích xuất thông tin có thể hành động về thời gian tải trang, yêu cầu mạng và thực thi JavaScript, cho phép các trợ lý AI gợi ý tối ưu hóa hiệu suất.
- Gỡ lỗi tự động: Ghi lại nhật ký điều khiển, kiểm tra lưu lượng mạng, chụp ảnh màn hình và tự động phục hồi lỗi để xử lý sự cố nhanh hơn.
- Kiểm thử đầu cuối: Tự động hóa các quy trình phức tạp với Puppeteer, xác thực tương tác trang và kiểm tra việc hiển thị nội dung động trong Chrome.
- Tự động hóa hỗ trợ AI: Các LLM như Gemini hoặc Copilot có thể điền mẫu, nhấp vào nút, hoặc thu thập dữ liệu có cấu trúc từ các trang Chrome với độ tin cậy và độ chính xác cao.
Playwright MCP
Playwright MCP là một máy chủ Mô hình-Bối cảnh-Giao thức (MCP) cung cấp khả năng tự động hóa trình duyệt dựa trên Playwright. Nó cho phép các mô hình ngôn ngữ lớn (LLMs) hoặc trợ lý lập trình AI tương tác với các trang web.
Các tính năng chính
- Nhanh và nhẹ. Sử dụng cây truy cập của Playwright, không dựa vào đầu vào pixel.
- Thân thiện với LLM. Không cần mô hình nhận diện hình ảnh, hoạt động hoàn toàn trên dữ liệu có cấu trúc.
- Ứng dụng công cụ xác định. Tránh được sự không rõ ràng thường gặp với các phương pháp dựa trên ảnh chụp màn hình.
Yêu cầu
- Node.js 18 hoặc mới hơn
- VS Code, Cursor, Windsurf, Claude Desktop, Goose hoặc bất kỳ khách hàng MCP nào khác
Bắt đầu
Đăng nhập vào Scrapeless và nhận Mã API của bạn.
Khởi động nhanh
Cấu hình JSON này được sử dụng bởi một khách hàng MCP để kết nối với máy chủ Playwright MCP và điều khiển phiên bản trình duyệt đám mây Scrapeless từ xa.
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--headless",
"--cdp-endpoint=wss://browser.scrapeless.com/api/v2/browser?token=Your_Token&proxyCountry=ANY&sessionRecording=true&sessionTTL=900&sessionName=playwrightDemo"
]
}
}
}Trình diễn
Các trường hợp sử dụng
-
Thu thập dữ liệu web và trích xuất dữ liệu: Các LLM được hỗ trợ bởi Playwright MCP có thể duyệt các trang web, trích xuất dữ liệu có cấu trúc và tự động hóa các tác vụ thu thập phức tạp trong một môi trường trình duyệt thực. Điều này hỗ trợ thu thập thông tin quy mô lớn cho nghiên cứu thị trường, tập hợp nội dung và trí tuệ cạnh tranh.
-
Thực hiện quy trình tự động: Playwright MCP cho phép các đại lý AI thực hiện các quy trình web lặp đi lặp lại như nhập liệu, tạo báo cáo và cập nhật bảng điều khiển. Nó đặc biệt hiệu quả cho tự động hóa quy trình kinh doanh, tuyển dụng HR và các hoạt động tần suất cao khác.
-
Dịch vụ và hỗ trợ khách hàng cá nhân hóa: Các đại lý AI có thể sử dụng Playwright MCP để tương tác trực tiếp với các cổng thông tin web, lấy dữ liệu cụ thể cho người dùng và thực hiện các hành động khắc phục sự cố. Điều này cho phép trải nghiệm hỗ trợ cá nhân hóa, nhạy cảm với bối cảnh — ví dụ, tự động lấy chi tiết đơn hàng hoặc giải quyết các vấn đề đăng nhập.
Browser MCP
Máy chủ Scrapeless Browser MCP kết nối liền mạch các mô hình như ChatGPT, Claude và các công cụ như Cursor và Windsurf với một loạt khả năng bên ngoài, bao gồm:
- Tự động hóa trình duyệt cho việc điều hướng và tương tác ở cấp độ trang
- Thu thập dữ liệu từ các trang động, nặng JavaScript—xuất ra dưới dạng HTML, Markdown hoặc ảnh chụp màn hình
Các công cụ MCP được hỗ trợ
| Tên | Mô tả |
|---|---|
| browser_create | Tạo hoặc sử dụng lại một phiên trình duyệt đám mây bằng Scrapeless. |
| browser_close | Đóng phiên hiện tại bằng cách ngắt kết nối trình duyệt đám mây. |
| browser_goto | Điều hướng trình duyệt đến một URL cụ thể. |
| browser_go_back | Quay lại một bước trong lịch sử trình duyệt. |
| browser_go_forward | Tiến về một bước trong lịch sử trình duyệt. |
| browser_click | Nhấp vào một phần tử cụ thể trên trang. |
| browser_type | Gõ văn bản vào một trường nhập cụ thể. |
| browser_press_key | Mô phỏng một lần nhấn phím. |
| browser_wait_for | Chờ một phần tử trang cụ thể xuất hiện. |
| browser_wait | Tạm dừng thực thi trong khoảng thời gian cố định. |
| browser_screenshot | Chụp một bức ảnh màn hình của trang hiện tại. |
| browser_get_html | Lấy HTML đầy đủ của trang hiện tại. |
| browser_get_text | Lấy tất cả văn bản có thể nhìn thấy từ trang hiện tại. |
| browser_scroll | Cuộn xuống cuối trang. |
| browser_scroll_to | Cuộn một phần tử cụ thể vào chế độ xem. |
| scrape_html | Lấy nội dung HTML đầy đủ từ một URL. |
| scrape_markdown | Lấy nội dung của một URL dưới dạng Markdown. |
| scrape_screenshot | Chụp ảnh màn hình chất lượng cao của bất kỳ trang web nào. |
Bắt đầu
Đăng nhập vào Scrapeless và nhận mã API của bạn.
Cấu hình Khách hàng MCP của bạn
Máy chủ Scrapeless MCP hỗ trợ cả hai chế độ vận chuyển Stdio và Streamable HTTP.
🖥️ Stdio (Thực thi cục bộ)
{
"mcpServers": {
"Máy chủ Scrapeless MCP": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}🌐 Streamable HTTP (Chế độ API lưu trữ)
{
"mcpServers": {
"Máy chủ Scrapeless MCP": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}Tùy chọn Nâng cao
Tùy chỉnh hành vi phiên trình duyệt với các tham số tùy chọn. Những tham số này có thể được thiết lập thông qua biến môi trường (đối với Stdio) hoặc tiêu đề HTTP (đối với Streamable HTTP):
| Stdio (Biến môi trường) | Streamable HTTP (Tiêu đề HTTP) | Mô tả |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Chỉ định một ID hồ sơ trình duyệt có thể tái sử dụng để duy trì phiên. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Bật lưu trữ lâu dài cho cookie, lưu trữ cục bộ, v.v. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Định nghĩa thời gian hết hạn tối đa phiên trong giây. Phiên sẽ tự động hết hạn sau thời gian không hoạt động này. |
Trường hợp sử dụng
Lấy dữ liệu và thu thập thông tin
- Giám sát Thương mại điện tử: Tự động truy cập các trang sản phẩm để thu thập giá cả, tình trạng kho hàng và mô tả.
- Nghiên cứu Thị trường: Lấy dữ liệu hàng loạt các tin tức, đánh giá hoặc trang công ty để phân tích và so sánh.
- Tổng hợp Nội dung: Trích xuất nội dung trang, bài viết và bình luận để thu thập tập trung.
- Tạo Dữ liệu Khách hàng: Thu thập thông tin liên hệ và thông tin công ty từ các trang web công ty hoặc danh bạ.
Kiểm thử & Đảm bảo Chất lượng
- Xác minh Chức năng: Sử dụng các cú nhấp chuột, gõ văn bản và chờ phần tử để đảm bảo các trang hoạt động như mong đợi.
- Kiểm thử Hành trình Người dùng: Mô phỏng các tương tác của người dùng thực tế (gõ, nhấp chuột, cuộn trang) để xác thực quy trình làm việc.
- Hỗ trợ Kiểm thử Hồi quy: Chụp ảnh màn hình của những trang chính và so sánh để phát hiện các thay đổi về giao diện người dùng hoặc nội dung.
Tự động hóa Nhiệm vụ & Quy trình
- Điền mẫu: Tự động hoàn thành và gửi các mẫu web (ví dụ: đăng ký, khảo sát).
- Thu thập Dữ liệu & Tạo Báo cáo: Định kỳ trích xuất dữ liệu trang và lưu dưới dạng HTML hoặc ảnh màn hình để phân tích.
- Nhiệm vụ Hành chính Đơn giản: Tự động hóa các hoạt động lặp đi lặp lại ở phía sau hoặc trên web bằng cách sử dụng cú nhấp chuột và gõ văn bản mô phỏng.
Triển lãm
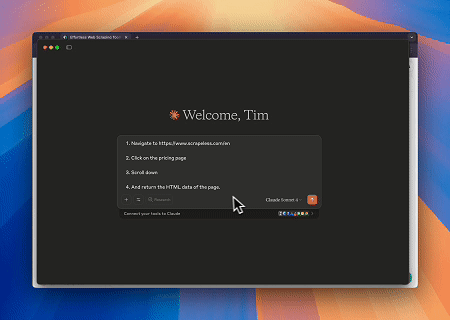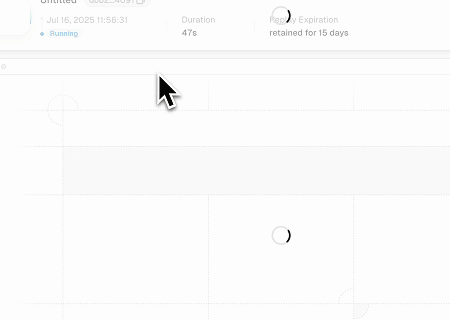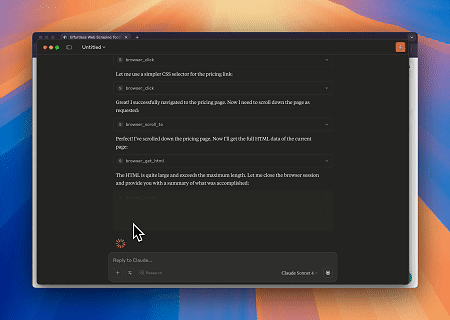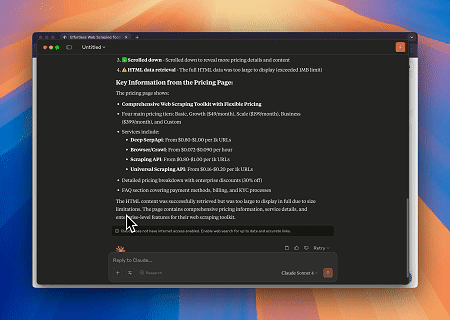
Trường hợp 1: Tự động hóa Tương tác Web và Trích xuất Dữ liệu với Claude
Sử dụng Máy chủ MCP Trình duyệt, Claude có thể thực hiện các thao tác web phức tạp—như điều hướng, nhấp chuột, cuộn trang và lấy dữ liệu—thông qua các lệnh hội thoại, với bản xem trước thực thi theo thời gian thực qua các phiên trực tiếp.
Trường hợp 2: Bỏ qua Cloudflare để Lấy Nội dung Trang Đích
Sử dụng Máy chủ MCP Trình duyệt, các trang được bảo vệ bởi Cloudflare được truy cập tự động, và khi hoàn thành, nội dung trang được trích xuất và trả về ở định dạng Markdown.
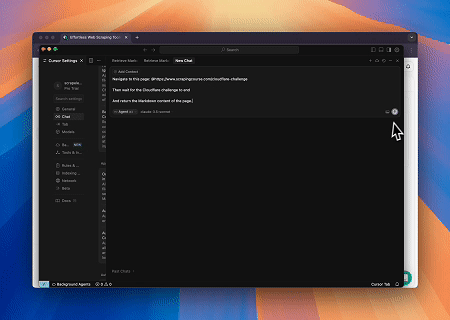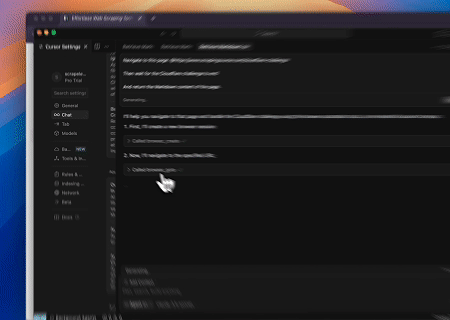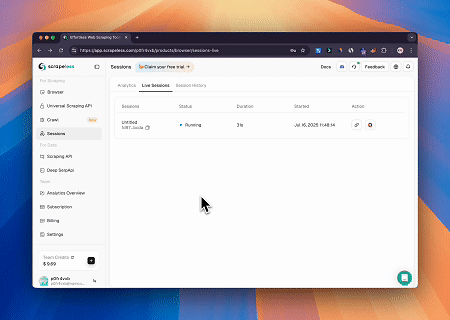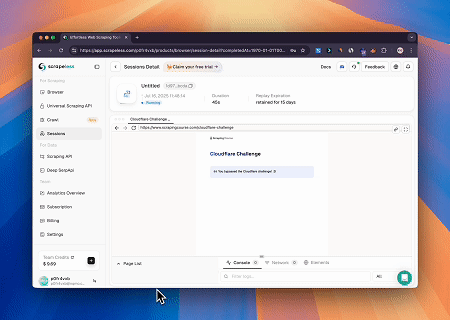
Tích hợp
Claude Desktop
- Mở Claude Desktop
- Điều hướng đến: Cài đặt → Công cụ → Máy chủ MCP
- Nhấp "Thêm Máy chủ MCP"
- Dán cấu hình Stdio hoặc Streamable HTTP ở trên
- Lưu và bật máy chủ
- Claude sẽ bây giờ có thể thực hiện các truy vấn web, trích xuất nội dung và tương tác với các trang bằng Scrapeless
Cursor IDE
- Mở Cursor
- Nhấn Cmd + Shift + P và tìm kiếm: Cấu hình Máy chủ MCP
- Thêm cấu hình Scrapeless MCP sử dụng định dạng ở trên
- Lưu tệp và khởi động lại Cursor (nếu cần)
- Bây giờ bạn có thể hỏi Cursor những điều như:
- “Tìm kiếm StackOverflow để giải quyết lỗi này”
- “Lấy HTML từ trang này”
- Và nó sẽ sử dụng Scrapeless trong nền.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


