Pipeline ETL là gì? Hướng dẫn toàn diện về Trích xuất, Chuyển đổi và Tải dữ liệu.
Expert Network Defense Engineer
Cần dữ liệu đáng tin cậy cho pipeline ETL của bạn? Tăng cường giai đoạn thu thập của bạn với Proxy Scrapeless — giải pháp nhanh chóng, đáng tin cậy và tiết kiệm cho mọi nhu cầu.
Trong thế giới phân tích dữ liệu và trí tuệ doanh nghiệp, khả năng di chuyển và xử lý thông tin một cách hiệu quả là cực kỳ quan trọng. Pipeline ETL là một khái niệm cơ bản trong lĩnh vực này, đại diện cho một quy trình có hệ thống được sử dụng để chuyển dữ liệu từ một hoặc nhiều nguồn tới một điểm đích nơi nó có thể được phân tích. ETL viết tắt cho Extract, Transform, and Load, và đây là một loại pipeline dữ liệu cụ thể rất quan trọng để duy trì chất lượng và tính nhất quán của dữ liệu trong một tổ chức [1].
Hướng dẫn này sẽ hướng dẫn bạn qua ba giai đoạn của pipeline thu thập dữ liệu ETL điển hình của một doanh nghiệp, khám phá lợi ích của nó và minh họa cách mà các giải pháp proxy chất lượng cao là rất cần thiết cho việc thực hiện thành công giai đoạn thu thập ban đầu.
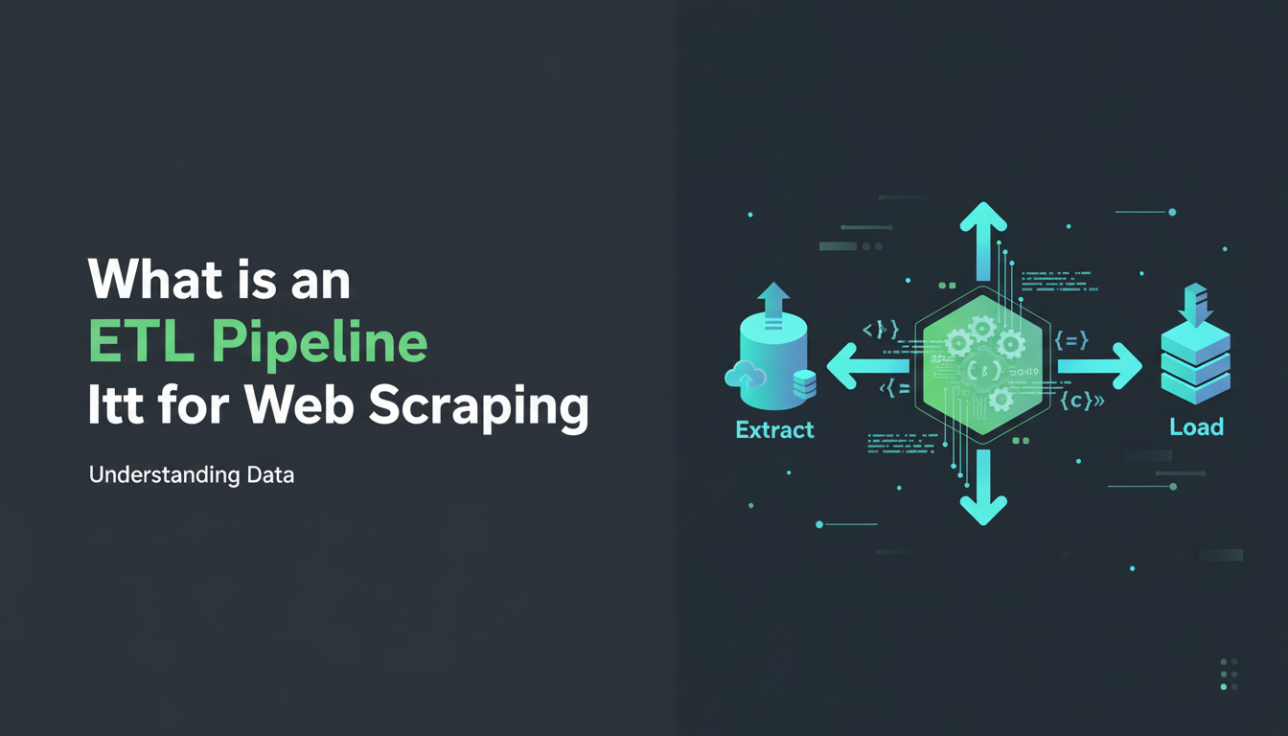
1. Giải Thích Pipeline ETL
Pipeline ETL là một tập hợp các quá trình được sắp xếp theo thứ tự được sử dụng để di chuyển dữ liệu từ một hệ thống này sang một hệ thống khác, tối ưu hóa quy trình xử lý dữ liệu và hiệu suất [2].
a. Thu Thập
Đây là giai đoạn ban đầu, nơi dữ liệu thô được thu thập từ một nguồn hoặc hồ dữ liệu. Các nguồn có thể đa dạng từ cơ sở dữ liệu nội bộ (như NoSQL) đến các mục tiêu nguồn mở bên ngoài như các nền tảng truyền thông xã hội hoặc các trang web đối thủ. Quy trình Thu Thập Dữ Liệu có thể bao gồm nhiều kỹ thuật khác nhau, bao gồm thu thập toàn bộ, thu thập gia tăng hoặc thu thập dựa trên API [3]. Khi thu thập dữ liệu từ web công cộng, việc sử dụng các proxy mạnh mẽ là cần thiết để quản lý các yêu cầu kết nối và tránh tình trạng chặn IP.
b. Chuyển Đổi
Dữ liệu được thu thập hiếm khi ở trạng thái đồng nhất; nó thường được thu thập trong nhiều định dạng khác nhau (ví dụ: JSON, CSV, HTML, SQL). Giai đoạn Chuyển Đổi đề cập đến quy trình cấu trúc, làm sạch và xác thực dữ liệu này để nó phù hợp với định dạng đồng nhất thích hợp cho hệ thống mục tiêu. Điều này có thể bao gồm làm sạch dữ liệu, loại bỏ trùng lặp, chuẩn hóa, và tổng hợp. Các công ty thường dành một khoảng thời gian đáng kể cho việc làm sạch dữ liệu, một quy trình mà các pipeline ETL vững chắc nhằm tự động hóa.
c. Tải
Tải là giai đoạn cuối cùng, liên quan đến việc chuyển giao hoặc tải dữ liệu đã được chuyển đổi đến một điểm đích cuối cùng, chẳng hạn như kho dữ liệu, CRM, hoặc cơ sở dữ liệu. Điểm đích này cho phép dữ liệu được phân tích để tạo ra đầu ra có thể hành động. Các điểm đích thông dụng bao gồm Amazon S3, Google Cloud, Microsoft Azure, SFTP, hoặc API nội bộ. Các loại tải chính bao gồm tải ban đầu, tải gia tăng và làm mới toàn bộ.
| Tính năng | Pipeline ETL | Pipeline Dữ Liệu |
|---|---|---|
| Phạm vi | Quy trình cụ thể (Thu Thập, Chuyển Đổi, Tải) | Thuật ngữ rộng hơn cho kiến trúc thu thập dữ liệu toàn vòng |
| Trọng tâm | Chuyển đổi và cấu trúc dữ liệu | Di chuyển và dòng chảy dữ liệu |
| Chuyển đổi | Xảy ra trước khi tải (T rồi L) | Có thể xảy ra trước hoặc sau khi tải (T rồi L, hoặc L rồi T - ELT) |
| Tốt Nhất Cho | Tập dữ liệu nhỏ hơn, phức tạp; dữ liệu có cấu trúc | Tập dữ liệu lớn, không có cấu trúc; dữ liệu theo thời gian thực |
2. Lợi Ích Của Các Pipeline ETL
Việc triển khai một kiến trúc pipeline ETL mạnh mẽ mang lại nhiều lợi ích quan trọng cho các doanh nghiệp đang tìm cách tận dụng dữ liệu để phát triển và tạo ra lợi thế cạnh tranh.
a. Tích Hợp Dữ Liệu Thô Từ Nhiều Nguồn
Một quy trình ETL được thiết kế tốt cho phép các công ty thu thập dữ liệu thô một cách hiệu quả dưới nhiều định dạng từ nhiều nguồn và nhập chúng vào hệ thống của họ để phân tích. Phạm vi nhìn nhận mở rộng này đảm bảo rằng việc ra quyết định gần gũi hơn với các xu hướng tiêu dùng và cạnh tranh hiện tại.
b. Giảm Thời Gian Để Có Được Thông Tin
Bằng cách tự động hóa quy trình từ thu thập ban đầu đến tải cuối cùng, thời gian cần thiết để rút ra những thông tin có thể hành động giảm đi đáng kể. Thay vì xem xét và chuyển đổi thủ công, quy trình tối ưu hóa cho phép phân tích và phản ứng nhanh hơn.
c. Giải Phóng Tài Nguyên Của Công Ty
Các pipeline ETL vững chắc tự động hóa định dạng và làm sạch dữ liệu, những công việc thường tốn thời gian. Bằng cách tự động hóa những bước này, các công ty có thể giải phóng nhân sự và tài nguyên để tập trung vào các hoạt động có giá trị cao hơn, chẳng hạn như phân tích nâng cao và lập kế hoạch chiến lược.
3. Vai Trò Quan Trọng Của Proxy Trong Giai Đoạn Thu Thập
Khi giai đoạn thu thập dữ liệu bao gồm thu thập dữ liệu từ web công cộng (web scraping), độ tin cậy và chất lượng của hạ tầng proxy trở thành yếu tố quan trọng nhất. Thiếu proxy hiệu suất cao, quy trình thu thập có thể gặp trở ngại nghiêm trọng do bị chặn IP, CAPTCHA và thời gian phản hồi chậm.
Proxy Scrapeless: Nguồn sức mạnh cho thu thập dữ liệu tin cậy
Đối với các doanh nghiệp phụ thuộc vào dữ liệu bên ngoài cho các quy trình ETL của họ, Proxy Scrapeless cung cấp giải pháp mạnh mẽ, có khả năng mở rộng cho giai đoạn thu thập. Scrapeless cung cấp quyền truy cập vào các IP thực từ hộ gia đình, trung tâm dữ liệu, IPv6 và ISP tĩnh, đảm bảo tỷ lệ thành công cao và độ trễ thấp cho các tác vụ thu thập dữ liệu yêu cầu cao.
Với hơn 90 triệu IP từ hộ gia đình ở hơn 195 quốc gia, Scrapeless mang đến khả năng bao phủ, tốc độ và độ tin cậy vô song. Nguồn IP khổng lồ và đa dạng này là điều cần thiết để duy trì tính ẩn danh và tránh bị phát hiện trong quá trình thu thập quy mô lớn, là thành phần chính của Thực hành tốt nhất trong Web Scraping.
🌍 Proxy dành cho hộ gia đình
- 90 triệu+ IP thực ở 195+ quốc gia
- Tự động xoay vòng & tỷ lệ thành công 99,98%
- Hỗ trợ định vị địa lý
- Giao thức HTTP/HTTPS/SOCKS5
- Thời gian phản hồi <0,5s
- Độ bền cao và tốc độ tải nhanh
⚡ Proxy từ trung tâm dữ liệu
- Thời gian hoạt động 99,99% & phản hồi siêu nhanh
- Thời gian phiên không giới hạn
- Tích hợp API dễ dàng
- Băng thông cao, độ trễ thấp
- Hỗ trợ HTTP/HTTPS/SOCKS5
🔐 Proxy IPv6
- 50 triệu+ IP IPv6 đã được xác minh
- Tự động xoay vòng
- Tính ẩn danh cao, IP chuyên dụng
- Tuân thủ GDPR & CCPA
- Thanh toán theo GB
🏠 Proxy ISP tĩnh
- IP hộ gia đình tĩnh chuyên dụng, cung cấp sự ổn định của IP từ trung tâm dữ liệu với sự tin cậy của IP hộ gia đình.
- Thời gian hoạt động 99,99% và độ trễ thấp
- Lý tưởng cho các phiên dài hạn trên các nền tảng yêu cầu độ tin cậy cao.
- Hỗ trợ định vị địa lý
- Giao thức HTTP/HTTPS/SOCKS5
Scrapeless cũng cung cấp các giải pháp có thể tự động hóa toàn bộ quá trình thu thập và biến đổi dữ liệu, chẳng hạn như Tích hợp Scrapeless với Make và Hướng dẫn Tích hợp MCP, giúp tăng tốc độ "thời gian đến hồi đáp dữ liệu" bằng cách cung cấp dữ liệu sạch, sẵn sàng sử dụng. Đối với các doanh nghiệp chú trọng đến trí tuệ cạnh tranh, việc tận dụng Công cụ Theo dõi Giá Tốt Nhất thường là kết quả trực tiếp của một quy trình ETL thành công.
4. Tự động hóa quy trình ETL
Nhiều công ty chọn tự động hóa quy trình thu thập dữ liệu và quy trình ETL của họ bằng cách sử dụng các công cụ chuyên biệt. Cách tiếp cận này cho phép các doanh nghiệp tập trung vào hoạt động cốt lõi của họ trong khi tận dụng kiến trúc ETL tự động được phát triển và vận hành bởi bên thứ ba.
Lợi ích chính của việc tự động hóa bao gồm:
- Thu thập dữ liệu web mà không cần yêu cầu hạ tầng hoặc mã lập trình.
- Không cần nhân lực kỹ thuật bổ sung.
- Dữ liệu được tự động làm sạch, phân tích và tổng hợp, và được cung cấp ở định dạng đồng nhất mà bạn chọn (JSON, CSV, HTML hoặc Microsoft Excel). Điều này thay thế hiệu quả giai đoạn Biến đổi thủ công.
- Dữ liệu được gửi trực tiếp đến điểm đến mục tiêu của công ty (ví dụ: Amazon S3, API).
5. Câu hỏi thường gặp (FAQ)
Q: Sự khác biệt giữa quy trình ETL và quy trình Dữ liệu là gì?
A: Quy trình ETL là một loại quy trình dữ liệu cụ thể, trong đó giai đoạn biến đổi (T) diễn ra trước giai đoạn tải (L). Quy trình Dữ liệu là thuật ngữ rộng hơn bao gồm toàn bộ kiến trúc để di chuyển dữ liệu, có thể bao gồm ETL, ELT (Trích xuất, Tải, Biến đổi), hoặc các quy trình di chuyển dữ liệu đơn giản [4].
Q: Tại sao proxy cần thiết cho giai đoạn thu thập ETL?
A: Khi giai đoạn thu thập liên quan đến việc thu thập dữ liệu từ các trang web công cộng (web scraping), proxy là cần thiết để xoay vòng địa chỉ IP, phân bổ yêu cầu và ngăn chặn việc IP của trình thu thập bị chặn bởi các hệ thống chống bot. Proxy chất lượng cao, như của Scrapeless, đảm bảo rằng việc thu thập là đáng tin cậy và có thể mở rộng.
Q: Tôi có thể xây dựng một quy trình ETL bằng Python không?
A: Có, Python là lựa chọn phổ biến để xây dựng các quy trình ETL. Các thư viện như Pandas được sử dụng để xử lý và biến đổi dữ liệu, trong khi các công cụ như Apache Airflow hoặc Luigi có thể được sử dụng để quản lý quy trình làm việc và lập lịch cho quy trình.
Q: Thách thức chính trong quá trình ETL là gì?
A: Thách thức lớn nhất thường là giai đoạn Chuyển đổi, vì nó liên quan đến việc làm sạch, chuẩn hóa và đối chiếu dữ liệu từ các nguồn khác nhau thành một định dạng nhất quán. Chất lượng của dữ liệu được trích xuất cũng là một thách thức lớn, đó là lý do tại sao các phương pháp trích xuất đáng tin cậy, thường được hỗ trợ bởi các proxy mạnh mẽ, là rất cần thiết.
Q: ELT pipeline là gì?
A: ELT là viết tắt của Extract, Load, Transform. Trong mô hình này, dữ liệu được trích xuất và tải trực tiếp vào kho dữ liệu (L), sau đó quá trình chuyển đổi (T) được thực hiện trong kho. Cách tiếp cận này thường được ưa chuộng cho các kho dữ liệu dựa trên đám mây và các tập dữ liệu lớn.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


