Loading...
🎯 कस्टमाइज़ करने योग्य, डिटेक्शन-प्रतिरोधी क्लाउड ब्राउज़र जो स्व-विकसित Chromium द्वारा संचालित है, वेब क्रॉलर और एआई एजेंट्स के लिए डिज़ाइन किया गया। 👉अभी आज़माएं
सबसे व्यापक गाइड, सभी वेब स्क्रैपिंग डेवलपर्स के लिए बनाया गया है।
स्क्रैपलेस प्रमुख उद्यमों द्वारा विश्वसनीय एआई-संचालित, मजबूत और स्केलेबल वेब स्क्रैपिंग और ऑटोमेशन सेवाओं की पेशकश करता है। हमारे उद्यम-ग्रेड समाधान आपकी परियोजना की जरूरतों को पूरा करने के लिए तैयार हैं, समर्पित तकनीकी सहायता के साथ। एक मजबूत तकनीकी टीम और लचीली डिलीवरी समय के साथ, हम केवल सफल डेटा के लिए शुल्क लेते हैं, जिससे सीमाओं को दरकिनार करते हुए कुशल डेटा निष्कर्षण को सक्षम किया जाता है।
अपने व्यवसाय के विकास को ईंधन देने के लिए अब हमसे संपर्क करें।
अपना संपर्क विवरण प्रदान करें, और हम तुरंत एक उत्पाद डेमो और परिचय की पेशकश करने के लिए पहुंचेंगे। हम यह सुनिश्चित करते हैं कि आपकी जानकारी गोपनीय बनी रहे, जीडीपीआर मानकों का अनुपालन।
आपका नि: शुल्क परीक्षण तैयार है! मुफ्त में एक स्क्रैपलेस खाते के लिए साइन अप करें, और आपका परीक्षण आपके खाते में तुरंत सक्रिय हो जाएगा।
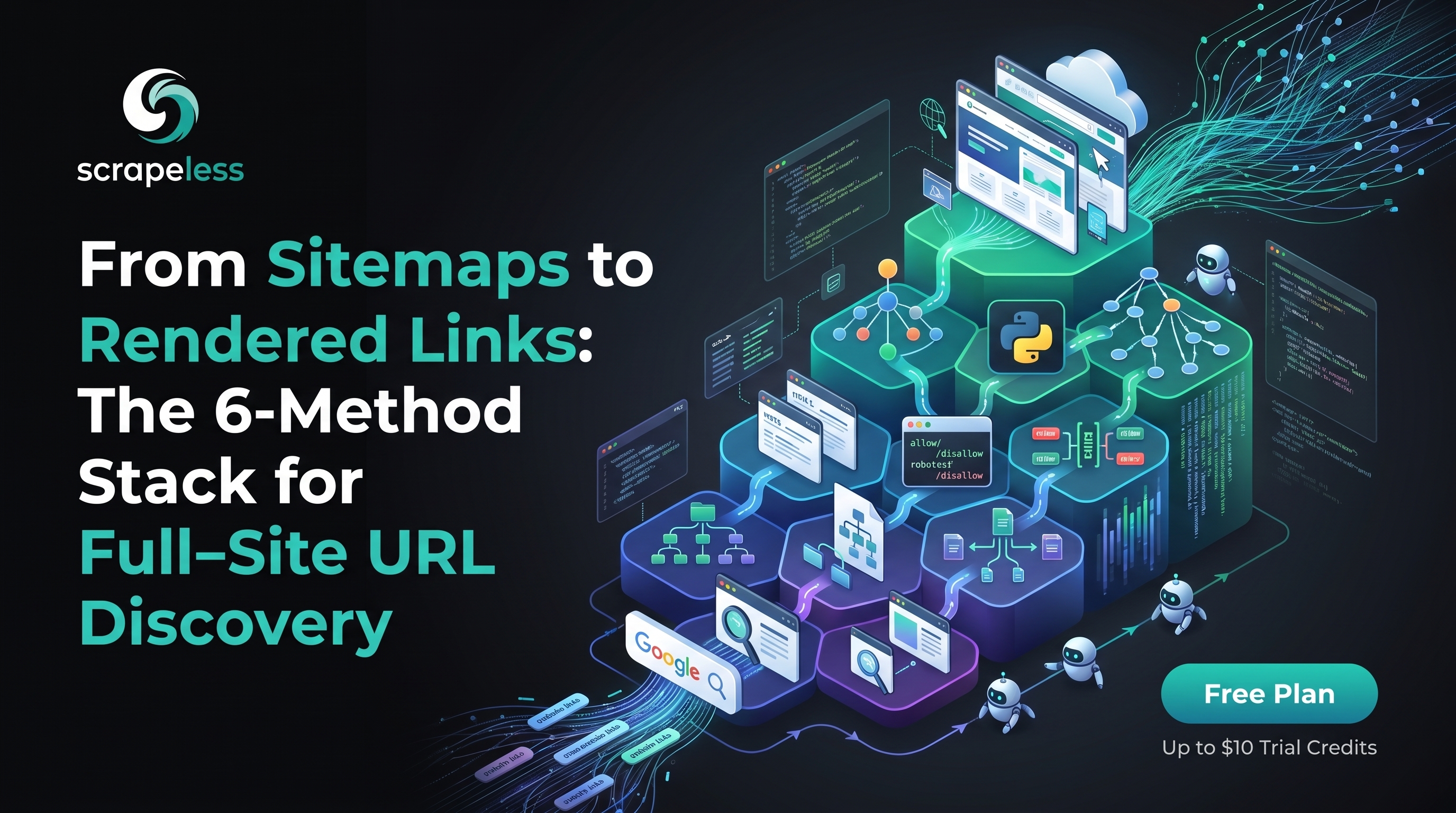
यह मार्गदर्शिका यह प्रदर्शित करती है कि कोई एकल तरीका पूर्ण URL सूची नहीं लौटाता—गूगल का साइट: ऑपरेटर एक तेज़ अनुमान प्रदान करता है, साइटमैप उन चीजों को घोषित करते हैं जिन्हें प्रकाशकों ने पंजीकृत किया है, एक चौड़ाई-प्रथम HTTP क्रॉलर जुड़े हुए अनाथों को खोजता है, और एक क्लाउड ब्राउज़र जावास्क्रिप्ट-पेंटेड लिंक को प्रस्तुत करता है—और लागत और पूर्णता के क्रम में छह तरीकों के माध्यम से चलता है, मुफ्त साइट: खोज से लेकर संपूर्ण स्टैक दृष्टिकोण तक: साइटमैप स्थानों और निषेध नियमों के लिए robots.txt पढ़ें, साइटमैप पेड़ को पुनरावृत्त रूप से चलाएं, एक पायथन BFS क्रॉलर चलाएं जो हर URL पर robots.txt का सम्मान करता है, और क्लाइंट-साइड लिंक खोज के लिए जावास्क्रिप्ट-भारी होस्ट को Scrapeless Scraping Browser में बढ़ाएं। परिणाम एक स्तरित, डुप्लिकेट-मुक्त संघ है जो तकनीकी SEO ऑडिट, सामग्री प्रवासन, टूटे लिंक स्वीप, मूल्य निगरानी, LLM संग्रह ग्रहण, और प्रतिस्पर्धात्मक सामग्री मानचित्रण को कवर करता है—यह साबित करते हुए कि पूर्ण URL खोज के लिए साइटमैप, क्रॉलर्स, और रेंडरिंग को सहायक तरीकों के रूप में मानना आवश्यक है, न कि विकल्प के रूप में।
यह गाइड तर्क करता है कि 'मुफ्त' सार्वजनिक डेटा कभी भी मुफ्त नहीं था, बल्कि मीटर रहित था—खुला वेब एक निहित सौदे पर आधारित था जहाँ वेब क्रॉलर सामग्री को लेते थे और प्रकाशकों को इसके बदले रिफरल ट्रैफिक मिलता था, एक ऐसा सौदा जिसे AI उत्तर इंजन ने उन पृष्ठों को पढ़कर तोड़ दिया बिना क्लिक भेजे—और भुगतान-प्रति-क्रॉल (HTTP 402 और क्लाउडफ्लेयर के बुनियादी ढाँचे के माध्यम से कार्यान्वित) उस पढ़ाई के मूल्य को फिर से मूल्यांकन करता है, डेटा लागत को अवसंरचना (प्रॉक्सी, रेंडरिंग, इंजीनियरिंग) से पहुंच शुल्क में स्थानांतरित करता है। संचालन संबंधी समाधान दार्शनिक नहीं बल्कि अनुशासित है: खोज (विस्तृत, कम-आवृत्ति मानचित्रण) को रिफ्रेश (संकीर्ण, उच्च-आवृत्ति अपडेट) से अलग करें, उपयोगी अपडेट के लिए लागत को ट्रैक करें न कि अनुरोध के लिए लागत, और पहली कोशिश में सफल होने वाले साफ रेंडर पर निवेश करें, ताकि डेटा टीम प्रत्येक पहुंच शुल्क को ठीक एक बार भुगतान करे और मीटर लगे वेब एक हल करने योग्य आर्थिक समस्या बन जाए न कि एक बजट आपदा।

यह गाइड दिखाती है कि Elixir के BEAM रनटाइम में वेब स्क्रैपिंग के लिए सस्ती समवर्तीता की सुविधा होती है - हजारों हल्के प्रक्रियाएँ URL के पार फैलने के लिए उत्पन्न की जाती हैं बिना थ्रेड-पूल ट्यूनिंग के - और इस स्थानीय समवर्तीता को एक दो-स्तरीय बढ़ाव पैटर्न के साथ जोड़ा जाता है: HTTP स्तर Req, HTTPoison और Crawly का उपयोग करता है जो 195+ देशों में Scrapeless आवासीय प्रॉक्सी के माध्यम से सेवा-रेंडर किए गए पृष्ठों के लिए मार्ग निर्दिष्ट करता है, जबकि ब्राउज़र स्तर JavaScript-भारी और एंटी-बॉट लक्ष्यों को Scrapeless स्क्रैपिंग ब्राउज़र पर बढ़ाता है जो Elixir के माध्यम से System.cmd/3 द्वारा कॉल किए गए एक न्यूनतम पायथन रेंडरिंग सहायक से है। परिणाम एक उत्पादन-क्षेत्र स्क्रैपिंग स्टैक है जो समवर्ती श्रेणी क्रॉल, अनुसूचित निगरानी, भू-विशिष्ट स्नैपशॉट, और आरएजी सेवन को प्रारंभिक पैमाने पर संभालता है - सभी BEAM से Chrome DevTools प्रोटोकॉल को सीधे बोलने के लिए कहे बिना।

सार्वजनिक डेटा सिद्धांत में खुला है और व्यवहार में इसे गेटेड किया गया है: एक पृष्ठ पढ़ना तुच्छ है, लेकिन पैंतालीस देशों से दस हजार पृष्ठ पढ़ना एक दिन में जावास्क्रिप्ट और एंटी-बॉट सुरक्षा के पीछे एक अवसंरचना की समस्या है। यह अंतर कि कौन इसे बड़े पैमाने पर कर सकता है और कौन नहीं—न कि डेटा स्वयं—वहीं प्रतिस्पर्धात्मक लाभ केंद्रित होता है, और एआई प्रणालियाँ इसे विरासत में लेती हैं और बढ़ाती हैं। समाधान अवसंरचना है (195+ देशों में आवासीय प्रॉक्सी, एंटी-डिटेक्शन क्लाउड रेंडरिंग, एकीकृत एपीआई सतह) जो 'सिद्धांत में सार्वजनिक' को 'व्यवहार में पहुंच योग्य' में बदल देती है छोटे टीमों के लिए, जिम्मेदारी से इसका उपयोग करके मैदान को समतल करने के लिए बिना इसे कुचलने के।

यह गाइड एजेंटिक वाणिज्य को पावर देने वाले तीन-स्तरीय एआई अर्थव्यवस्था स्टैक के माध्यम से चलती है - एक टूल प्रोटोकॉल (MCP) जो एजेंटों को टूल और डेटा तक पहुंचने की अनुमति देता है, मशीन-स्वदेशी भुगतान प्रोटोकॉल (x402, एजेंटिक वाणिज्य प्रोटोकॉल, एजेंट भुगतान प्रोटोकॉल) जो एजेंटों को बिना मानव के मूल्य निपटाने की अनुमति देते हैं, और एक विश्वसनीय डेटा स्तर जो स्वायत्त खरीद निर्णयों को लाइव वेब पर वास्तव में क्या सच है, पर आधारित रखता है। महत्वपूर्ण अंतर्दृष्टि है कि डेटा गुणवत्ता वह भार-धारण करने वाली नींव है: एक एजेंट जो पुराने मूल्य पर या एक खाली जावास्क्रिप्ट-निर्मित पृष्ठ पर भुगतान करता है, चुपचाप और महंगा विफल होता है, यही वजह है कि स्क्रेपलेस स्क्रैपिंग ब्राउज़र - जावास्क्रिप्ट को रेंडर करना, क्षेत्र द्वारा आवासीय निकासी को पिन करना, और एंटी-बॉट सिस्टम को परास्त करना - किसी भी एजेंटिक-वाणिज्य प्रणाली के लिए एक आकर्षक वस्तु नहीं बल्कि एक आवश्यकता है जो उस अधिकांश वेब तक पहुंचना चाहती है जो अभी भी मानवों के लिए बनाया गया है।

यह मार्गदर्शिका यह प्रदर्शित करती है कि उच्च गुणवत्ता वाले LLM और RAG कॉर्पस बनाने के लिए साफ़ पाठ निकासी की आवश्यकता होती है, न कि कच्चे HTML की, और चार चरणों वाली Python पाइपलाइन के माध्यम से चलती है - google_search या साइटमैप के माध्यम से URL खोजें, प्रत्येक पृष्ठ को एंटी-डिटेक्शन क्लाउड ब्राउज़र में रेंडर करें और scrape_markdown के साथ साफ Markdown निकालें, Markdown को 500-1000 टोकन के ओवरलैपिंग विंडोज में विभाजित करें, और प्रत्येक चंके को पुनर्प्राप्ति के लिए एक वेक्टर डेटाबेस में एम्बेड करें। परिणाम एक स्केलेबल प्रणाली है जो अव्यवस्थित सार्वजनिक वेब पृष्ठों को उत्पादन-ग्रेड कॉर्पस में बदल देती है जिसमें 70% कम टोकन लागत और नाटकीय रूप से बेहतर पुनर्प्राप्ति गुणवत्ता होती है, सभी बिना प्रति-साइट एडाप्टर या फिंगरप्रिंट ट्यूनिंग के।

गूगल मैप्स सबसे समृद्ध स्थानीय व्यवसाय निर्देशिका है, लेकिन इसे व्यापक स्तर पर निकालना एंटी-डिटेक्शन रेंडरिंग और रेजिडेंशियल प्रॉक्सी राउटिंग की आवश्यकता होती है। यह गाइड चार-चरणीय कार्यप्रवाह के माध्यम से चलती है—google_search के साथ खोजें और मैप्स स्क्रॉलिंग को रेंडर करें, सेमांटिक सेलेक्टर से संरचित क्षेत्र निकालें, व्यवसाय वेबसाइटों से समृद्ध करें, और reputations के आधार पर गुणांकित करें—जो श्रेणी खोजों को बिना मैन्युअल शोध या प्रति-사이트 एडॉप्टर्स के डिडुप्लिकेटेड, CRM-तैयार लीड सूचियों में बदलती है।
यह गाइड यह दिखाता है कि cURL के साथ JSON भेजने के लिए दो स्वतंत्र घटकों की आवश्यकता होती है—एक JSON अनुरोध शरीर और एक Content-Type: application/json हेडर—और इसे प्राप्त करने के लिए दो विधियों के माध्यम से चलता है: क्लासिक -d फ़्लैग के साथ स्पष्ट -H हेडर, और आधुनिक --json शॉर्टकट (curl 7.82.0+) जो दोनों हेडर अपने आप सेट करता है। सामान्य गलतियों (शेल कोटिंग, हेडर भूलना, फ़ाइल प्रबंधन), सार्वजनिक इको एंडपॉइंट्स के खिलाफ कार्यशील उदाहरणों और Scrapeless MCP API के लिए वास्तविक कॉल को कवर करके, यह गाइड दिखाता है कि एक cURL कमांड जो आपके टर्मिनल में काम करता है, सीधा प्रोडक्शन कोड में कैसे अनुवादित होता है।



