
Python में वेब क्रॉलर: 2025 के लिए एक चरण-दर-चरण मार्गदर्शिका
Advanced Data Extraction Specialist
डेटा की मात्रा में नाटकीय वृद्धि के साथ, वेब क्रॉलिंग डेटा साइंस, मार्केट रिसर्च और प्रतिस्पर्धी विश्लेषण जैसे क्षेत्रों में एक उपकरण बन गया है। सहोदर प्रोग्रामिंग भाषाओं में, पाइथन अपनी संक्षिप्त सिंटैक्स और शक्तिशाली लाइब्रेरी सपोर्ट के साथ वेब क्रॉलर्स पाइथन (पाइथन वेब क्रॉलर्स) विकसित करने के लिए पसंदीदा भाषा बन गई है। चाहे वह ई-कॉमर्स प्लेटफॉर्म से डेटा निकालना हो या किसी समाचार वेबसाइट से नवीनतम लेख एकत्र करना हो, वेब क्रॉलर्स पाइथन कार्य को कुशलतापूर्वक पूरा कर सकते हैं। यह लेख आपको एक चरण-दर-चरण मार्गदर्शिका का 2025 संस्करण प्रदान करेगा ताकि आप पाइथन का उपयोग करके एक शक्तिशाली और शक्तिशाली वेब क्रॉलर कैसे बनाते हैं, बुनियादी ज्ञान से लेकर उन्नत तकनीकों तक, को व्यापक रूप से बेहतर बनाने में मदद मिलेगी। आपकी वेब क्रॉलिंग क्षमताएँ।
पाइथन में वेब क्रॉलर क्या है और डेटा निष्कर्षण के लिए यह क्यों महत्वपूर्ण है
एक वेब क्रॉलर एक स्वचालित प्रोग्राम है जिसे विशिष्ट नियमों के अनुसार इंटरनेट से जानकारी क्रॉल करने के लिए डिज़ाइन किया गया है। यह ब्राउज़र का अनुकरण करके वेब पेजों तक पहुँचता है, आवश्यक डेटा निकालता है और उसे स्थानीय रूप से संग्रहीत करता है। इस प्रक्रिया में आमतौर पर प्रारंभिक URL का चयन करना, वेब पेज सामग्री डाउनलोड करना, HTML पार्स करना, लिंक का अनुसरण करना और अधिक डेटा प्राप्त करने के लिए इस प्रक्रिया को दोहराना शामिल है। डेटा निष्कर्षण में वेब क्रॉलर्स की भूमिका महत्वपूर्ण है क्योंकि यह बड़ी संख्या में वेब पेजों से जानकारी को कुशलतापूर्वक एकत्र कर सकता है और सर्च इंजन इंडेक्स निर्माण और डेटा विश्लेषण कार्यों का समर्थन कर सकता है।
पाइथन में वेब क्रॉलर के लाभ
पाइथन में वेब क्रॉलर्स लिखने के कई फायदे हैं, खासकर लचीलेपन और उपयोग में आसानी के मामले में। सबसे पहले, पाइथन का सिंटैक्स संक्षिप्त और सीखने में आसान है, जिससे डेवलपर्स जल्दी से शुरुआत कर सकते हैं और जटिल क्रॉलिंग तर्क को लागू कर सकते हैं। दूसरा, पाइथन में स्क्रैपी और ब्यूटीफुलसूप जैसे लाइब्रेरी और फ्रेमवर्क का खजाना है, जो वेब पेज पार्सिंग और डेटा निष्कर्षण की प्रक्रिया को बहुत सरल करते हैं। इसके अलावा, पाइथन की क्रॉस-प्लेटफ़ॉर्म प्रकृति क्रॉलर्स को विभिन्न ऑपरेटिंग सिस्टम पर चलने की अनुमति देती है, जिससे विकास और परिनियोजन का लचीलापन बढ़ जाता है।
💡 संबंधित रीडिंग: 2025 में पाइथन के साथ वेब स्क्रैपिंग
पाइथन में वेब क्रॉलिंग के लिए उन्नत तकनीकें
जब पाइथन वेब क्रॉलर विकसित करने की बात आती है, तो कई उन्नत तकनीकें हैं जो आपकी वेब स्क्रैपिंग क्षमताओं को बढ़ा सकती हैं, खासकर जब गतिशील सामग्री और एंटी-स्क्रैपिंग उपायों से निपटने की बात आती है। ये रणनीतियाँ जावास्क्रिप्ट रेंडरिंग, CAPTCHA सॉल्विंग और IP ब्लॉकिंग जैसी चुनौतियों को दूर करने के लिए महत्वपूर्ण हैं, जिनका सामना अक्सर पाइथन वेब क्रॉलर बनाते समय किया जाता है। यहाँ कुछ प्रमुख रणनीतियाँ दी गई हैं:
- गतिशील वेब पेजों को संभालना:
- सेलेनियम का उपयोग करें: यह लाइब्रेरी आपको ब्राउज़र क्रियाओं को स्वचालित करने की अनुमति देती है, जिससे आप डेटा निकालने से पहले जावास्क्रिप्ट सामग्री के लोड होने का इंतजार कर सकते हैं।
- Ajax अनुरोध करें: अपने ब्राउज़र के डेवलपर टूल में नेटवर्क अनुरोधों का विश्लेषण करें ताकि API समापन बिंदुओं की पहचान की जा सके। अधिक कुशल डेटा पुनर्प्राप्ति के लिए इन समापन बिंदुओं पर सीधे अनुरोध भेजने के लिए पाइथन में अनुरोध लाइब्रेरी का उपयोग करें।
- एंटी-स्क्रैपिंग उपायों को दरकिनार करना:
- प्रॉक्सी का उपयोग करें: कई IP पतों पर अनुरोधों को वितरित करने के लिए रोटेटिंग प्रॉक्सी IP लागू करें, जिससे वेबसाइटों के लिए आपकी स्क्रैपिंग गतिविधियों का पता लगाना और ब्लॉक करना कठिन हो जाता है।
- उपयोगकर्ता-एजेंट को स्पॉफ करें: लोकप्रिय ब्राउज़रों की नकल करने के लिए अपने अनुरोध शीर्षकों में उपयोगकर्ता-एजेंट स्ट्रिंग को संशोधित करें। इससे बॉट के रूप में चिह्नित होने की संभावना कम हो जाती है।
- दक्षता बढ़ाना:
- एसिंक्रोनस प्रोग्रामिंग लागू करें: समवर्ती अनुरोध करने के लिए asyncio और aiohttp जैसी लाइब्रेरी का उपयोग करें, जिससे डेटा निष्कर्षण प्रक्रिया में तेजी आती है।
- XPath या CSS चयनकर्ता का लाभ उठाएँ: ये उपकरण HTML तत्वों के सटीक लक्ष्यीकरण की अनुमति देते हैं, जिससे आपके डेटा निष्कर्षण की सटीकता और दक्षता में सुधार होता है।
वेब क्रॉलिंग के लिए अपना पाइथन पर्यावरण सेट करना
अपना वेब क्रॉलिंग परिवेश स्थापित करने से पहले, आपको कुछ बुनियादी परिवेश तैयार करने की आवश्यकता है:
- पाइथन 3+:इंस्टॉलर डाउनलोड करें, इसे डबल-क्लिक करें, और इंस्टॉलेशन विज़ार्ड का पालन करें।
- पाइथन IDE: पाइथन एक्सटेंशन के साथ विजुअल स्टूडियो कोड या पाइचार्म।
फिर, python-crawler नामक एक प्रोजेक्ट को इनिशियलाइज़ करने के लिए टर्मिनल में निम्न कमांड दर्ज करें:
mkdir python-crawler
cd python-crawler
python -m venv envवेब क्रॉलिंग करते समय, हमें HTTP अनुरोधों और HTML पार्सिंग के लिए दो लाइब्रेरी का उपयोग करने की आवश्यकता होती है। पाइथन में दो सबसे लोकप्रिय लाइब्रेरी हैं:
- अनुरोध: एक शक्तिशाली HTTP क्लाइंट लाइब्रेरी जो HTTP अनुरोध भेज सकती है और प्रतिक्रियाओं को संसाधित कर सकती है।
- beautifulsoup4: एक पूर्ण-सुविधा वाला HTML और XML पार्सर।
इन्हें स्थापित करने के लिए टर्मिनल में निम्न कमांड टाइप करें:
pip install beautifulsoup4 requestsप्रोजेक्ट फ़ोल्डर में, crawler.py बनाएँ और प्रोजेक्ट निर्भरताओं को आयात करें:
import requests
from bs4 import BeautifulSoupप्रोजेक्ट बन गया है, आइए वेब क्रॉलिंग शुरू करें।
पाइथन का उपयोग करके अमेज़ॅन डेटा कैसे स्क्रैप करें
अमेज़ॅन से डेटा स्क्रैप करने से उत्पाद जानकारी, समीक्षाएँ और रुझानों के बारे में सामग्री प्राप्त हो सकती है। हालाँकि, अमेज़ॅन के एंटी-स्क्रैपिंग उपाय, जैसे कि CAPTCHA और IP दर सीमा, प्रक्रिया को चुनौतीपूर्ण बनाते हैं। इस गाइड में, हम आपको पाइथन का उपयोग करके अमेज़ॅन डेटा को स्क्रैप करने के तरीके के बारे में बताएँगे।
पाइथन में एक साधारण वेब क्रॉलर कैसे बनाएँ
ऊपर दिए गए चरणों के अनुसार वेबसाइट क्रॉलिंग परिवेश को सेट करने के बाद, आपको पाइथन में एक साधारण वेब क्रॉलर बनाने के लिए नीचे दिए गए चरणों का पालन करने की आवश्यकता है।
चरण 1: अनुरोध और ब्यूटीफुलसूप का उपयोग करके बेसिक वेब क्रॉलर
कोड उदाहरण
import requests
from bs4 import BeautifulSoup
class SimpleWebCrawler:
def __init__(self, start_url):
self.start_url = start_url
self.visited_urls = set()
self.urls_to_visit = [start_url]
def crawl(self):
while self.urls_to_visit:
current_url = self.urls_to_visit.pop(0)
if current_url in self.visited_urls:
continue
print(f"Crawling: {current_url}")
response = requests.get(current_url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
self.visited_urls.add(current_url)
self.extract_links(soup)
def extract_links(self, soup):
for link in soup.find_all('a', href=True):
absolute_link = link['href']
if absolute_link not in self.visited_urls and absolute_link not in self.urls_to_visit:
self.urls_to_visit.append(absolute_link)
if __name__ == "__main__":
crawler = SimpleWebCrawler("https://example.com")
crawler.crawl()व्याख्या
- इनिशियलाइज़ेशन: SimpleWebCrawler क्लास एक शुरुआती URL के साथ इनिशियलाइज़ करता है और विज़िट किए गए URL और विज़िट करने के लिए URL को ट्रैक करने के लिए सेट करता है।
- क्रॉलिंग लॉजिक: क्रॉल विधि urls_to_visit सूची में URL को संसाधित करती है, प्रत्येक पृष्ठ की सामग्री को प्राप्त करती है।
- लिंक निष्कर्षण: extract_links विधि पृष्ठ पर सभी हाइपरलिंक ढूँढती है और उन्हें उन URL की सूची में जोड़ती है जिन्हें अभी तक देखा नहीं गया है।
चरण 2: अधिक जटिल क्रॉलिंग के लिए स्क्रैपी का उपयोग करना
यदि आपके प्रोजेक्ट को एक साथ कई अनुरोधों को संभालने या बड़ी वेबसाइटों को कुशलतापूर्वक स्क्रैप करने जैसी अधिक उन्नत सुविधाओं की आवश्यकता है, तो स्क्रैपी का उपयोग करने पर विचार करें।
बेसिक स्क्रैपी उदाहरण
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = ['https://example.com']
def parse(self, response):
for link in response.css('a::attr(href)').getall():
yield response.follow(link, self.parse)स्क्रैपी चलाना
आप कमांड लाइन का उपयोग करके अपने स्क्रैपी स्पाइडर को चला सकते हैं:
scrapy crawl my_spiderपाइथन के साथ अमेज़ॅन डेटा कैसे स्क्रैप करें
अगला, यह खंड विस्तार से पेश करेगा कि पाइथन का उपयोग करके अमेज़ॅन डेटा को कैसे क्रॉल किया जाए।
चरण 1। सबसे पहले, हमें उत्पाद पृष्ठ प्राप्त करने और अनुरोध करने के लिए get विधि का उपयोग करने की आवश्यकता है:
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)response.content सर्वर द्वारा उत्पन्न HTML दस्तावेज़ है। इसे ब्यूटीफुलसूप में फ़ीड किया जाता है, और html.parser विकल्प आपको उस पार्सर को निर्दिष्ट करने देता है जिसका लाइब्रेरी उपयोग करेगी:
soup = BeautifulSoup(response.content, "html.parser")चरण 2। इसके बाद, हमें वह डेटा प्राप्त करने की आवश्यकता है जिसे हम क्रॉल करना चाहते हैं। हम संबंधित तत्वों को प्राप्त करने के लिए CSS चयनकर्ताओं का उपयोग कर सकते हैं।
ब्यूटीफुलसूप दो विधियाँ, select और select_one प्रदान करता है, जो दोनों CSS चयनकर्ता रणनीतियों का समर्थन करती हैं।
कोड लिखने से पहले, आप तत्व की CSS देखने के लिए डेवलपमेंट टूल खोल सकते हैं।
- उत्पाद शीर्षक प्राप्त करें:
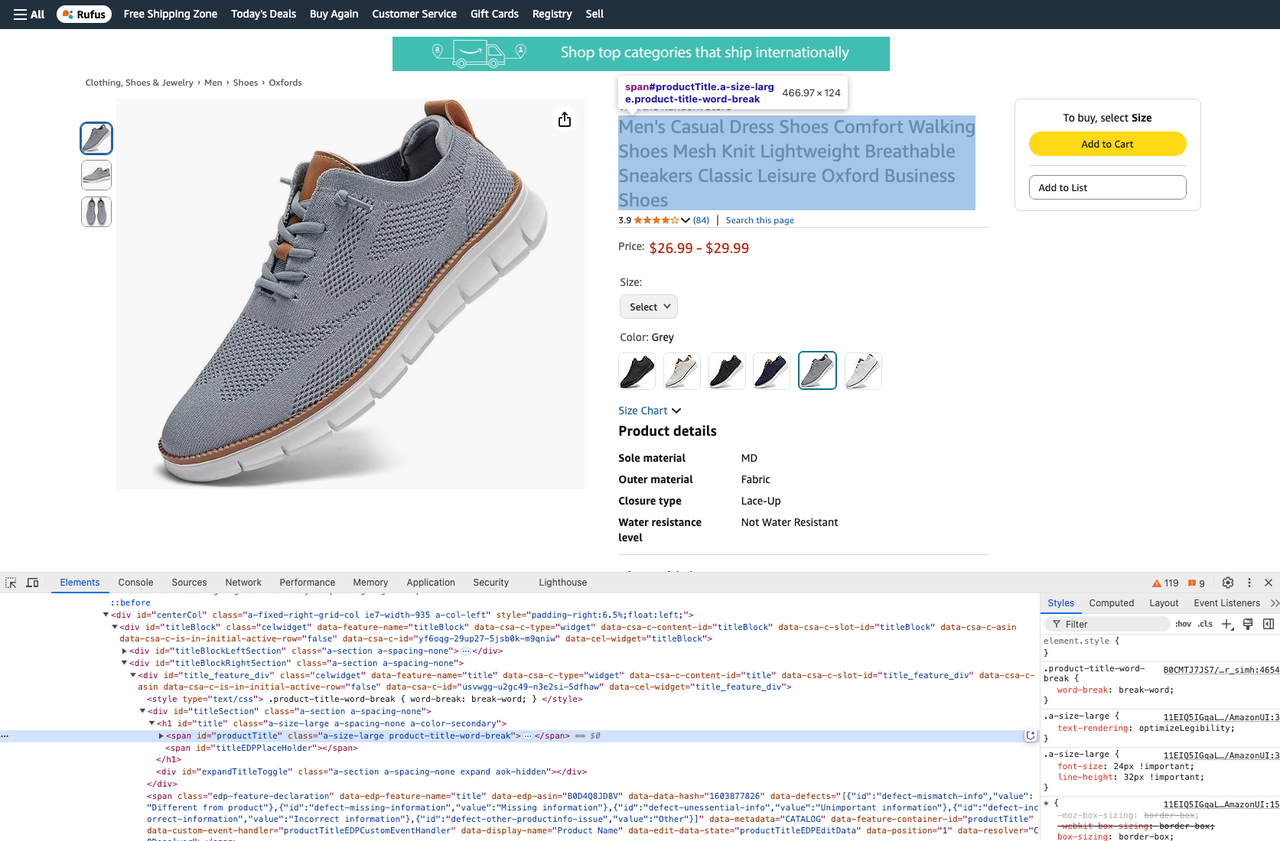
product_title = soup.select_one("#productTitle").text- उत्पाद विवरण प्राप्त करें:
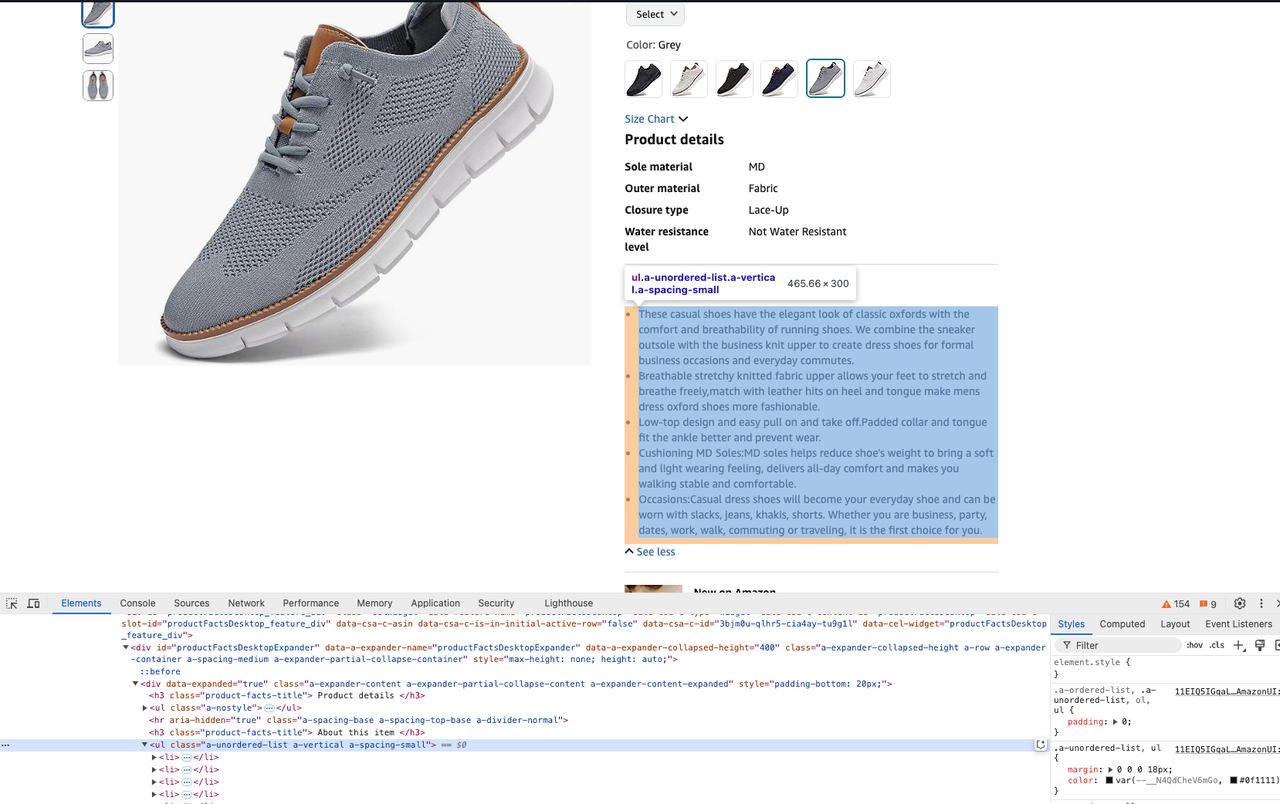
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text- किसी उत्पाद की कीमत प्राप्त करें:
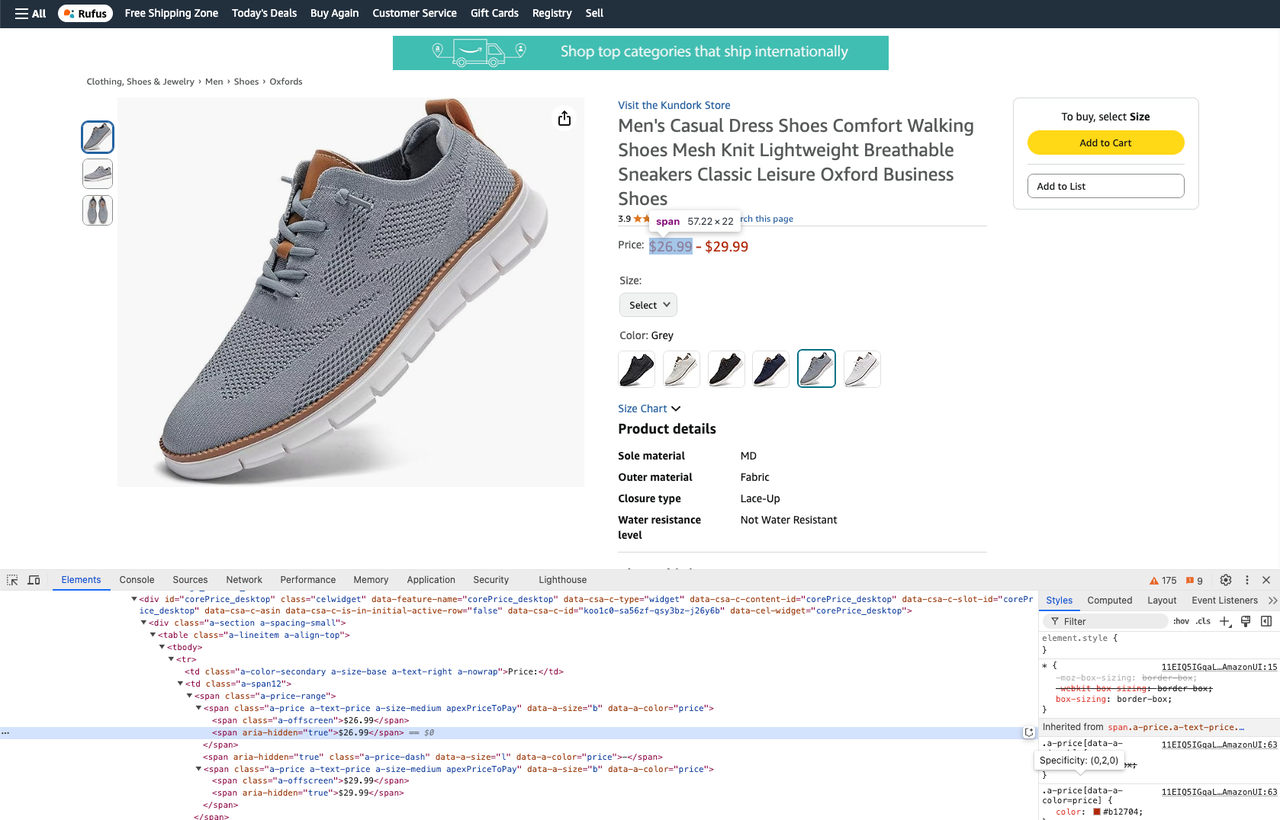
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text- उत्पाद समीक्षाएँ प्राप्त करें:
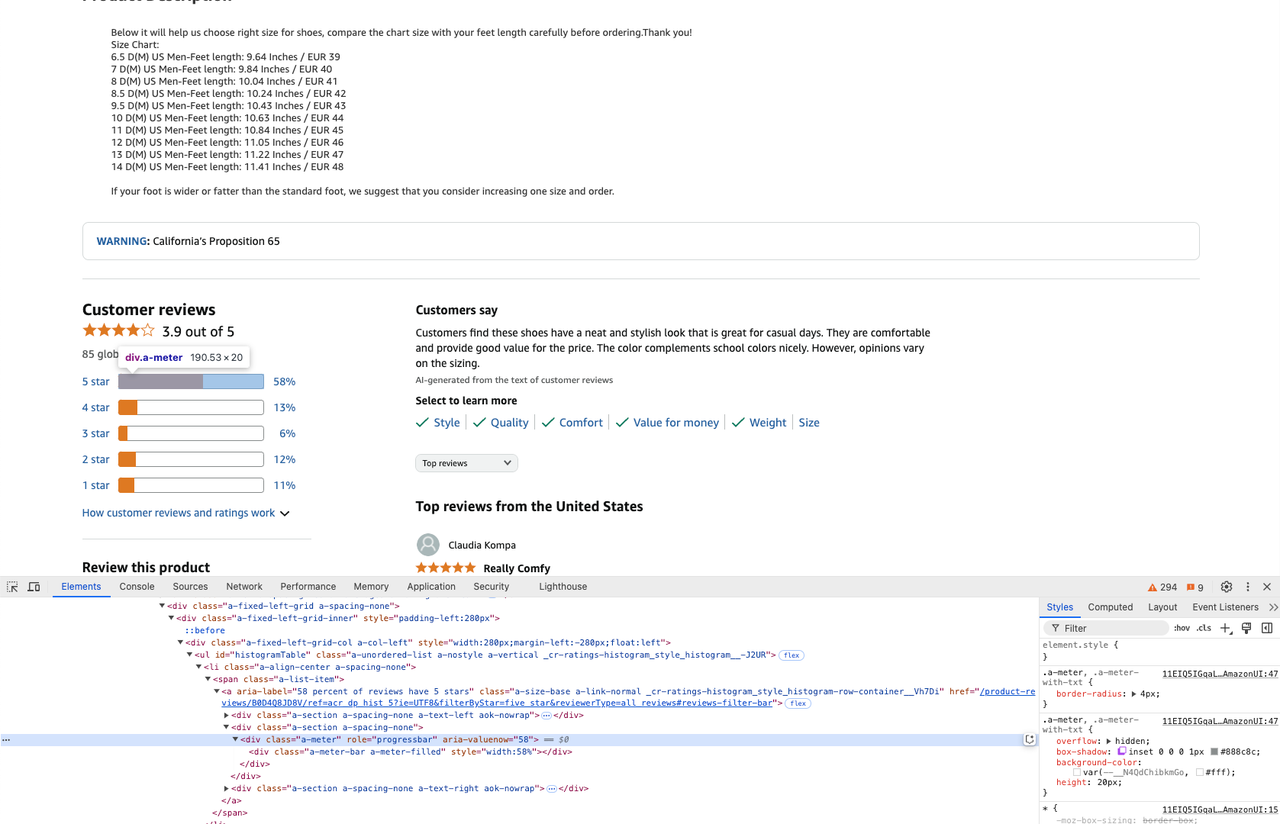
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'चरण 3। अब जब हमने वेबसाइट क्रॉल कर ली है और हमें वह डेटा मिल गया है जिसे हम चाहते हैं, तो हम क्रॉल की गई जानकारी को एक csv फ़ाइल में निकाल सकते हैं।
ऐसा करने के लिए, फ़ाइल के शीर्ष पर निम्नलिखित जोड़ें:
import csvक्रॉल किए गए डेटा को एक csv फ़ाइल में लिखें:
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])क्रॉल कमांड निष्पादित करने के लिए टर्मिनल में निम्न कमांड चलाएँ:
python crawler.pyचरण 4। निष्पादन पूरा होने के बाद, हम देख सकते हैं कि product.csv फ़ाइल आपके फ़ोल्डर में दिखाई देती है। इस फ़ाइल को खोलें और हम उस डेटा परिणाम को देख सकते हैं जिसे हमने क्रॉल किया है:

पूर्ण कोड इस प्रकार है:
import csv
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
product_title = soup.select_one("#productTitle").text
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])कैसे Scrapeless's अमेज़ॅन स्क्रैपिंग API आपके वेब क्रॉलिंग कार्यों को सरल बना सकता है
Scrapeless का अमेज़ॅन स्क्रैपिंग API डेटा को अमेज़ॅन से निकालने की प्रक्रिया को स्वचालित और सरल बनाने के लिए डिज़ाइन किया गया है, जिससे यह डेवलपर्स और व्यवसायों के लिए एक मूल्यवान उपकरण बन जाता है। वेब क्रॉलर पाइथन दृष्टिकोण का उपयोग करने के विपरीत, जिसमें अक्सर व्यापक मैनुअल कोडिंग और विभिन्न चुनौतियों जैसे IP रोटेशन या CAPTCHA बाइपासिंग को संभालना शामिल होता है, Scrapeless API प्रक्रिया को सुव्यवस्थित करता है। यह कई ऐसी सुविधाएँ प्रदान करता है जो दक्षता को बढ़ाती हैं, जिससे उपयोगकर्ता जटिल पाइथन स्क्रिप्टिंग की आवश्यकता के बिना आसानी से उत्पाद की कीमतें, समीक्षाएँ और विवरण जैसे डेटा एकत्र कर सकते हैं।
अमेज़ॅन स्क्रैपिंग API के अलावा, Scrapeless में Shopee स्क्रैपिंग API, Lazada स्क्रैपिंग API, Google रुझान स्क्रैपिंग API, Google उड़ानें स्क्रैपिंग API, Google खोज स्क्रैपिंग API, Airbnb स्क्रैपिंग API, आदि शामिल हैं, जो वेब डेटा निष्कर्षण के लिए एक व्यापक समाधान प्रदान करते हैं।
आसानी से स्क्रैपिंग शुरू करने के लिए तैयार हैं?
आज ही Scrapeless के लिए साइन अप करें और हमारे API की शक्ति का अनुभव करने के लिए अपना निःशुल्क परीक्षण प्राप्त करें। अमेज़ॅन, शोपी और अधिक जैसे शीर्ष ई-कॉमर्स प्लेटफॉर्म से निर्बाध डेटा निष्कर्षण अनलॉक करें। छूटें नहीं—अभी शुरुआत करें!
मैनुअल पाइथन वेब क्रॉलर्स पर लाभ
1. स्वचालन और दक्षता
अमेज़ॅन स्क्रैपिंग API पूरी डेटा निष्कर्षण प्रक्रिया को स्वचालित करता है, यह सुनिश्चित करता है कि उपयोगकर्ता जल्दी और सटीक रूप से बड़ी मात्रा में डेटा एकत्र कर सकते हैं। यह जटिल कोडिंग को समाप्त करता है जो आमतौर पर मैनुअल पाइथन वेब क्रॉलर्स के लिए आवश्यक होती है, जिसमें अक्सर गतिशील सामग्री और एंटी-स्क्रैपिंग उपायों जैसी विभिन्न चुनौतियों से निपटना शामिल होता है।
2. अंतर्निहित अवसंरचना
Scrapeless के API के साथ, उपयोगकर्ताओं को एक मजबूत अवसंरचना से लाभ होता है जो स्वचालित रूप से प्रॉक्सी प्रबंधन, IP रोटेशन और CAPTCHA समाधान को संभालता है। इसके विपरीत, मैनुअल पाइथन वेब क्रॉलर्स को डेवलपर्स को स्वयं इन सुविधाओं को लागू करने की आवश्यकता होती है, जो समय लेने वाली और त्रुटि-प्रवण हो सकती है।
3. कोड-मुक्त इंटरफ़ेस
API एक कोड-मुक्त इंटरफ़ेस प्रदान करता है जो उपयोगकर्ताओं को सरल API कॉल के साथ स्क्रैपिंग कार्य शुरू करने की अनुमति देता है। यह पाइथन वेब क्रॉलर के लिए कोड लिखने और डिबग करने से बहुत आसान है, इसलिए विभिन्न कौशल स्तरों के उपयोगकर्ता इसका उपयोग कर सकते हैं।
API के माध्यम से कुशलतापूर्वक अमेज़ॅन डेटा निकालें
Scrapeless के अमेज़ॅन स्क्रैपिंग API का उपयोग करके, उपयोगकर्ता इन चरणों का पालन करके संरचित डेटा को आसानी से निकाल सकते हैं:
-
API कुंजी पीढ़ी: Scrapeless के लिए साइन अप करें और अपनी अनूठी API कुंजी उत्पन्न करें।
-
स्क्रैपिंग API पर क्लिक करें और अमेज़ॅन चुनें।
-
अपनी आवश्यकताओं को परिभाषित करें: उस डेटा के प्रकार को निर्दिष्ट करें जिसे आप स्क्रैप करना चाहते हैं (जैसे, उत्पाद विवरण, समीक्षाएँ)।
-
स्क्रैपिंग शुरू करें पर क्लिक करें: सरल API कॉल का उपयोग करके अमेज़ॅन से डेटा का अनुरोध करें।
-
संरचित डेटा प्राप्त करें: Scrapeless API विश्लेषण या आपके सिस्टम में एकीकरण के लिए विभिन्न स्वरूपों (जैसे, JSON) में एकत्रित डेटा प्रदान करता है।
Scrapeless के अमेज़ॅन स्क्रैपिंग API का लाभ उठाकर, उपयोगकर्ता अपने वेब स्क्रैपिंग कार्यों को बहुत सरल कर सकते हैं, जिससे वे वेब स्क्रैपिंग की जटिलता का प्रबंधन करने के बजाय अंतर्दृष्टि का विश्लेषण करने पर ध्यान केंद्रित कर सकते हैं। यह शक्तिशाली उपकरण न केवल उत्पादकता में सुधार करता है, बल्कि डेटा संरक्षण नियमों के अनुपालन को भी सुनिश्चित करता है, जिससे यह उन व्यवसायों के लिए आदर्श है जो अपने बाजार अनुसंधान प्रयासों में प्रतिस्पर्धी लाभ प्राप्त करना चाहते हैं।
यदि आपको अपनी परियोजना में Scrapeless को एकीकृत करने की आवश्यकता है, तो आप हमारे नमूना कोड का उल्लेख कर सकते हैं। आप पूर्ण दस्तावेज़ देखने के लिए यहां भी क्लिक कर सकते हैं।
अनुरोध नमूने - उत्पाद
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)अनुरोध नमूने - विक्रेता
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))अनुरोध नमूने - कीवर्ड
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))आज ही Scrapeless डिस्कॉर्ड समुदाय में शामिल हों!
साप्ताहिक समाचारों, अनन्य अपडेट के साथ अपडेट रहें, और क्रेडिट जीतने के अवसर के लिए रोमांचक कार्यक्रमों में भाग लें। मज़े से न चूकें—अभी कार्रवाई का हिस्सा बनें!
वेब क्रॉलर पाइथन के बारे में पूछे जाने वाले प्रश्न
FAQ #1: पाइथन में वेब क्रॉलर्स और वेब स्क्रैपर्स में क्या अंतर है?
डेटा निष्कर्षण के क्षेत्र में वेब क्रॉलर्स और वेब स्क्रैपर्स के अलग-अलग उपयोग हैं। एक वेब क्रॉलर मुख्य रूप से खोज पर केंद्रित है; यह URL खोजने और अनुक्रमित करने के लिए वेबसाइटों को ब्राउज़ करता है, अनिवार्य रूप से इंटरनेट या किसी विशिष्ट वेबसाइट का नक्शा बनाता है। वेब क्रॉलर का आउटपुट आमतौर पर URL की एक सूची होती है। इसके विपरीत, एक वेब स्क्रैपर इन URL से विशिष्ट डेटा निकालता है, जैसे कि उत्पाद विवरण या मूल्य निर्धारण जानकारी। जबकि दोनों प्रक्रियाओं में HTML सामग्री डाउनलोड करना शामिल है, क्रॉलर का लक्ष्य लिंक एकत्र करना है, जबकि स्क्रैपर का लक्ष्य इन पृष्ठों से प्रासंगिक डेटा बिंदुओं को फ़िल्टर और निकालना है।
FAQ #2: पाइथन के साथ वेब क्रॉलर बनाते समय CAPTCHA को कैसे संभालें?
पाइथन के साथ वेब क्रॉलर बनाते समय CAPTCHA को संभालना सबसे चुनौतीपूर्ण पहलुओं में से एक है, क्योंकि इसे विशेष रूप से स्वचालित पहुँच को रोकने के लिए डिज़ाइन किया गया है। CAPTCHA को संभालने के लिए यहाँ कुछ प्रभावी रणनीतियाँ दी गई हैं:
- हेडलेस ब्राउज़र का उपयोग करें: हेडलेस ब्राउज़र Puppeteer या Playwright जैसे उपकरणों के साथ मिलकर CAPTCHA को वास्तविक ब्राउज़र व्यवहार की नकल करके बायपास करने में मदद कर सकते हैं।
- CAPTCHA को ट्रिगर करने से बचें:
2.1 प्रॉक्सी सेवा का उपयोग करें IP पतों को घुमाएँ पता लगाने से बचने के लिए।
2.2 मानव गतिविधि की नकल करने के लिए अनुरोध हेडर (जैसे, उपयोगकर्ता एजेंट) को यादृच्छिक करें और अनुरोधों के बीच देरी करें।
जबकि ये तरीके CAPTCHA को बायपास करने में मदद कर सकते हैं, हमेशा सुनिश्चित करें कि आपके कार्य वेबसाइट की सेवा की शर्तों और कानूनी आवश्यकताओं का पालन करते हैं।
FAQ #3: क्या पाइथन का उपयोग करके अमेज़ॅन जैसी वेबसाइटों से डेटा स्क्रैप करना कानूनी है?
वेब स्क्रैपिंग की वैधता कई कारकों पर निर्भर करती है, खासकर जब अमेज़ॅन जैसे ई-कॉमर्स प्लेटफॉर्म को लक्षित किया जाता है। यहाँ कुछ प्रमुख बातें हैं:
- Robots.txt अनुपालन: वेबसाइटों में अक्सर एक फ़ाइल शामिल होती है जो बताती है कि साइट के कौन से हिस्सों को स्क्रैप किया जा सकता है। इसे अनदेखा करना अपने आप में अवैध नहीं है, लेकिन इसे अनैतिक या सर्वोत्तम प्रथाओं के खिलाफ माना जा सकता है।
- उचित उपयोग और सार्वजनिक डेटा: यदि डेटा सार्वजनिक रूप से सुलभ है और गैर-वाणिज्यिक उद्देश्यों (जैसे शैक्षणिक अनुसंधान) के लिए उपयोग किया जाता है, तो यह कुछ अधिकार क्षेत्रों में "उचित उपयोग" के अंतर्गत आ सकता है। हालाँकि, ऐसा होना सुनिश्चित नहीं है।
कानूनी समस्याओं से बचने के लिए:
- डेटा स्क्रैप करने से पहले, हमेशा वेबसाइट की सेवा की शर्तों की जाँच करें।
- यदि संभव हो, तो अनुमति मांगें।
- Scrapeless जैसे कानूनी वेबसाइट स्क्रैपिंग API का उपयोग करें।
निष्कर्ष
इस लेख में, हमने पाइथन में वेब क्रॉलर के महत्व का पता लगाया, विशेष रूप से ई-कॉमर्स डेटा क्रॉलिंग में इसका व्यापक अनुप्रयोग। एक लचीली और शक्तिशाली प्रोग्रामिंग भाषा के रूप में, पाइथन कई लाइब्रेरी और उपकरण प्रदान करता है जो डेवलपर्स को ई-कॉमर्स प्लेटफार्म
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


