
2024 में क्लाउडफ्लेयर को बायपास करने के लिए प्लेराइट का उपयोग कैसे करें
Advanced Data Extraction Specialist
हेडलेस ब्राउझर वापरत असताना, तुमचा वेब स्क्रॅपर अजूनही ब्लॉक होत आहे का? या मार्गदर्शकात प्लेराइटचा मास्क सुधारण्याद्वारे क्लाउडफ्लेअर कसे बायपास करावे हे तुम्हाला समजेल.
क्लाउडफ्लेअर: ते काय आहे?
सुरक्षा आणि कामगिरी ऑप्टिमायझेशन प्रदाता क्लाउडफ्लेअरने प्रदान केलेली एक सेवा म्हणजे बॉट मॅनेजमेंट, ही अनेक स्क्रॅपर्ससाठी एक दुःस्वप्न आहे. सुमारे पाचव्या भागात वेबसाइट वेब अॅप्लिकेशन फायरवॉल (WAF) वापरतात, जे नियमितपणे स्क्रॅपर्स ओळखतात आणि थांबवतात. प्लेराइट आणि सेलेनियम सारखे हेडलेस ब्राउझर्स या श्रेणीत येतात.
क्लाउडफ्लेअर कसे कार्य करते
क्लाउडफ्लेअर अनेक तंत्रांचा वापर करून बॉट्स आणि वास्तविक वापरकर्त्यांनी तयार केलेले ट्रॅफिक तुलना करतो आणि वेगळे करतो, जसे की:
वर्तन विश्लेषण: ते वापरकर्त्यांच्या वेबसाइटशी असलेल्या संवादांच्या अनेक पैलूंचे निरीक्षण करते, ज्यामध्ये क्लिक्स, माउस हालचाल आणि पृष्ठ लोड वेळ समाविष्ट आहे.
IP प्रतिष्ठा विश्लेषण: प्रत्येक विनंतीचा IP पत्ता एक डेटाबेसशी तुलना केला जातो जेणेकरून ते स्क्रॅपिंगसाठी वापरले गेले आहे की नाही हे निर्धारित केले जाऊ शकते.
युजर-एजंट विश्लेषण: स्ट्रिंग वेबसाइट विनंती करणारा ब्राउझर किंवा डिव्हाइस ओळखण्याचे साधन म्हणून काम करते. क्लाउडफ्लेअर स्क्रॅपर्सद्वारे वापरले जाणारे सामान्य किंवा त्वरीत ओळखता येणारे युजर-एजंट स्ट्रिंग्स ओळखू शकतो.
CAPTCHA चाचणी: सिस्टम वेबसाइटला विनंती करणारा वापरकर्ता रोबोट आहे की मानव आहे हे ठरवण्यासाठी निवडू शकतो. वापरकर्ता उत्तीर्ण झाल्यास विनंती मंजूर केली जाईल. अन्यथा ते बंदी घातले जाईल.
विनंती दर विश्लेषण: या तंत्राचा वापर करून, एखादा वेबसाइटला पाठवलेल्या प्रश्नांची संख्या ट्रॅक करू शकतो आणि स्वयंचलित बॉट्सच्या वैशिष्ट्यांच्या ट्रेंड्स ओळखू शकतो. उदाहरणार्थ, बॉट्स अनेकदा थोड्या वेळात खूप प्रश्ना पाठवतात.
बेस प्लेराइट वापरणे क्लाउडफ्लेअर बायपास करण्यासाठी अपुरा का आहे
बेस प्लेराइट वापरून क्लाउडफ्लेअरच्या बॉट-विरोधी संरक्षणांना पार करणे शक्य नसावे. कारण? हे किंवा इतर ब्राउझर ऑटोमेशन टूल्स वापरून मानव-सारखे ब्राउझिंग वर्तन अनुकरण करून काही अडचणी दूर केल्या जाऊ शकतात, अधिक प्रगत पद्धती, जसे की प्रॉक्सी आणि कस्टम युजर एजंट वापरणे, क्लाउडफ्लेअरवर मात करण्यासाठी अतिरिक्त प्रयत्न आवश्यक असू शकतात.
हे दाखवण्यासाठी, चला एक नोडजेएस प्लेराइट प्रोजेक्ट सुरू करूया आणि पाहूया की क्लाउडफ्लेअरवर ते कसे कार्य करत नाही.
पायरी 1: तुमच्या संगणकावर npm आणि नोड.जेएस स्थापित आहेत याची खात्री करा.
पायरी 2: इच्छित डायरेक्टरीमध्ये नेव्हिगेट केल्यानंतर नवीन प्रोजेक्ट सुरू करण्यासाठी या कमांडचा वापर करा:
language
npm initपायरी 3: आता प्लेराइटला अवलंबितता म्हणून स्थापित करण्यासाठी खालील कमांड वापरा.
language
npm install playwrightपायरी 4: उत्तम काम! आता तुम्ही प्लेराइट वापरणे सुरू करू शकता. तुमच्या प्रोजेक्ट डायरेक्टरीमध्ये .js एक्सटेंशनसह नवीन फाइल तयार करा, जसे की scraper.js. त्यात, https://crozdesk.com ला भेट द्या आणि स्क्रीनशॉट घेण्यासाठी एक स्क्रिप्ट तयार करा.
language
const playwright = require("playwright");
async function scraper() {
const browser = await playwright.chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://crozdesk.com");
await page.waitForTimeout(1000);
await page.screenshot({ path: "screenshot.png", fullPage: true });
await browser.close();
}
scraper();तुम्ही पाहू शकता, आमचा स्क्रॅपर क्रोमियमला ब्राउझर म्हणून वापरतो, परंतु तुम्ही दुसरा वापरण्यास मोकळे आहात.
पायरी 5: संपूर्ण कोड चालविण्यासाठी या कमांडचा वापर करा:
language
node scraper.jsहे परिणाम आहे:
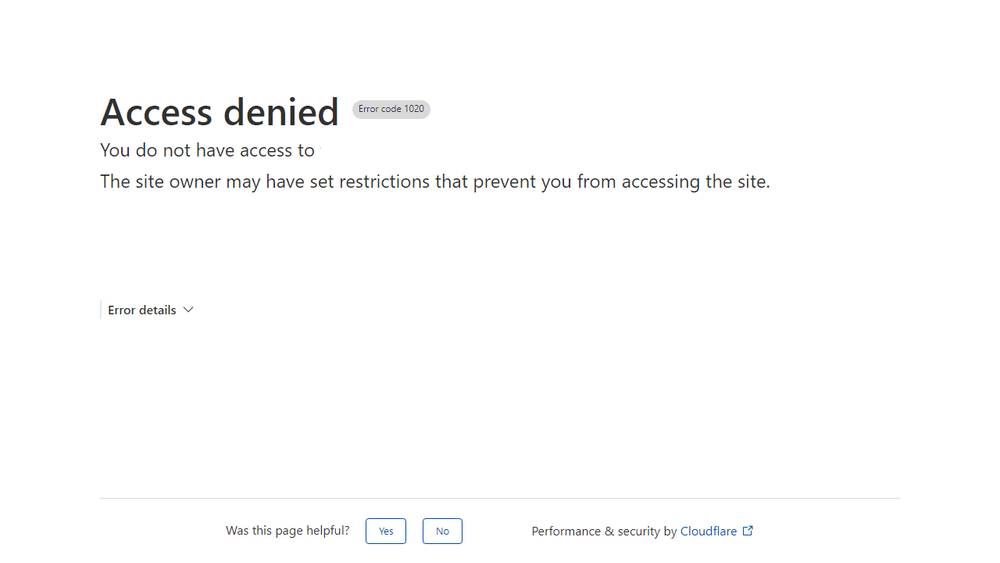
दुर्दैवाने, प्लेराइटचा साधा आवृत्ती बॉट म्हणून फ्लॅग केली जाते आणि त्यानंतर वेबसाइटला प्रवेश देण्यास प्रतिबंधित केला जातो.
पुढील भागात, आपण काही धोरणांचा आढावा घेऊ जे तुम्हाला क्लाउडफ्लेअर बायपास करण्यास मदत करतील. वाचत रहा!
प्लेराइट मास्क करून क्लाउडफ्लेअर कसे बायपास करावे
क्लाउडफ्लेअरच्या ओळखीच्या तंत्रांना हाताळण्यासाठी काही धोरणे पाहूया. सहसा, तुमच्या स्क्रिप्टला कार्य करण्यासाठी, यांचे मिश्रण आवश्यक असेल.
पद्धत 1: मानवी वर्तनाचे अनुकरण करा
स्वयंचलित ब्राउझरला अधिक मानवी दिसण्यासाठी, तुम्ही आमच्या पूर्वीच्या प्लेराइट स्क्रॅपर कोडमध्ये वेबसाइटशी संवाद साधण्यासाठी यादृच्छिक थांबा, स्क्रोलिंग आणि इतर संवाद जोडू शकता.
पद्धत 2: प्रॉक्सी वापरा
तुम्ही थोड्या वेळात खूप प्रश्ना पाठवले तर वेबसाइट स्क्रॅपिंगमधून बंदी घालवणे सोपे आहे. स्वतःला विविध वापरकर्त्यांसारखे दिसण्यासाठी रोटेटिंग प्रॉक्सी वापरून, तुम्ही त्याचे प्रतिबंध करू शकता.
पद्धत 3: एक अद्वितीय युजर-एजंट निवडा
युजर-एजंट्स क्लायंट बद्दलची माहिती देतात जे विनंती करत आहेत, ज्यामध्ये ऑपरेटिंग सिस्टम आणि ब्राउझर समाविष्ट आहेत. ओळखले जाण्यापासून रोखण्यासाठी प्लेराइटच्या डिफॉल्टच्या ऐवजी लोकप्रिय ऑनलाइन ब्राउझरचे अनुकरण करणारे कस्टम युजर-एजंट वापरणे चांगले आहे.
पद्धत 4: CAPTCHA सोल्व्हर वापरा
प्लेराइटसह, तुम्ही स्क्रॅपलेस सारखी विविध उपकरणे वापरू शकता, जे CAPTCHAs सोडवू शकतात.
सतत वेब स्क्रॅपिंग ब्लॉक्स आणि CAPTCHAs ने कंटाळले का?
Scrapeless - अंतिम सर्व-इन-वन वेब स्क्रॅपिंग सोल्यूशन!
अपने डेटा एक्सट्रैक्शन की पूरी क्षमता को हमारे शक्तिशाली टूल सूट के साथ अनलॉक करें:
सर्वश्रेष्ठ वेब अनलॉकर
स्वचालित रूप से उन्नत CAPTCHA को हल करें, अपने स्क्रैपिंग को निर्बाध और निर्बाध बनाए रखें।
अंतर का अनुभव करें - इसे मुफ्त में आज़माएं!
विधि 5: Playwright-extra जोड़ें
Playwright-extra Playwright प्लगइन्स के लिए एक ढाँचा है जो हल्का है और अतिरिक्त सहायक ऐड-ऑन की अनुमति देता है। जिसका हम उपयोग Cloudflare को दरकिनार करने के लिए करेंगे उसे Puppeteer-extra-plugin-stealth कहा जाता है, और यह कई रणनीतियों को नियोजित करता है, जिसमें माउस इवेंट जनरेशन और उपयोगकर्ता-एजेंट संशोधन शामिल है, ताकि हेडलेस ब्राउज़र के उपयोग को छिपाया जा सके।
निष्कर्ष में
जैसा कि आप देख सकते हैं, आप Cloudflare को दरकिनार करने के लिए Playwright का उपयोग कर सकते हैं, लेकिन आपको कुछ परिष्कृत चालों का उपयोग करने की आवश्यकता हो सकती है जो हर बार काम नहीं कर सकती हैं। इस बीच, Scrapeless आपको तुरंत सफल होने में मदद करेगा और आपको अभी एक मुफ्त API कुंजी प्रदान करेगा।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


