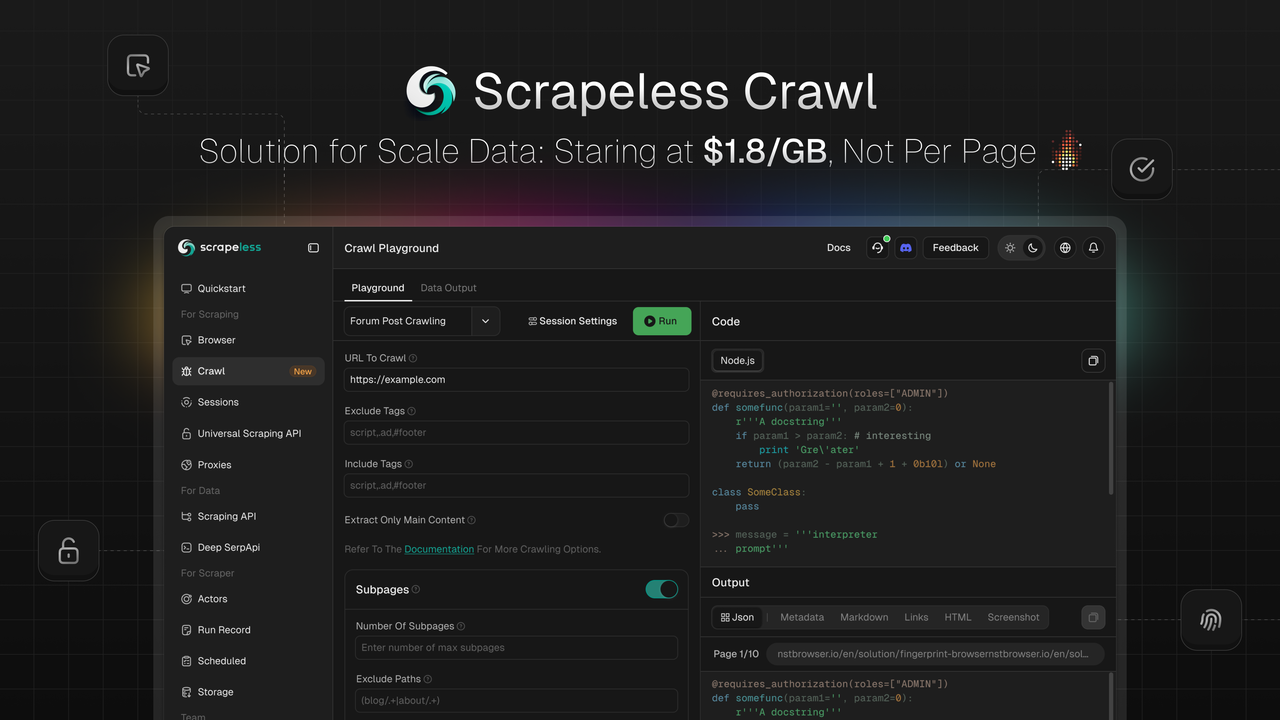
स्क्रेपलेस क्रॉल क्या है और यह कैसे काम करता है?
Senior Web Scraping Engineer
Scrapeless को Crawl लॉन्च करने की खुशी है, जो बड़े पैमाने पर डेटा स्क्रैपिंग और प्रोसेसिंग के लिए विशेष रूप से निर्मित एक विशेषता है। Crawl अपनी बुद्धिमान पुनरावर्ती स्क्रैपिंग, थोक डेटा प्रोसेसिंग क्षमताओं, और लचीली बहु-फॉर्मेट आउटपुट के साथ खड़ा है, जो उद्यमों और डेवलपर्स को तेजी से विशाल वेब डेटा अधिग्रहण और प्रोसेसिंग करने की शक्ति देता है—जो AI प्रशिक्षण, बाजार विश्लेषण, व्यवसाय निर्णय लेने, और अन्य कई क्षेत्रों में अनुप्रयोगों को बढ़ावा देती है।
💡जल्द आ रहा है: AI LLM गेटवे के माध्यम से डेटा निकासी और सारांशण, ओपन-सोर्स ढांचों और दृश्य कार्यप्रवाह एकीकरण के लिए निर्बाध समाकलन—AI डेवलपर्स के लिए वेब कंटेंट की चुनौतियों का समाधान।
Crawl क्या है
Crawl केवल एक साधारण डेटा स्क्रैपिंग उपकरण नहीं है, बल्कि यह एक व्यापक मंच है जो स्क्रैपिंग और क्रॉलिंग कार्यक्षमताओं को एकीकृत करता है।
-
थोक क्रॉलिंग: बड़े पैमाने पर एकल-पृष्ठ क्रॉलिंग और पुनरावर्ती क्रॉलिंग का समर्थन करता है।
-
बहु-फॉर्मेट वितरण: JSON, Markdown, Metadata, HTML, Links, और Screenshot स्वरूपों के साथ संगत।
-
एंटी-डिटेक्शन स्क्रैपिंग: हमारा स्वतंत्र रूप से विकसित क्रोमियम कर्नेल, उच्च अनुकूलन, सत्र प्रबंधन, और एंटी-डिटेक्शन क्षमताओं की अनुमति देता है, जैसे फिंगरप्रिंट कॉन्फ़िग़रेशन, CAPTCHA हल करना, स्टेल्थ मोड, और प्रॉक्सी रोटेशन वेबसाइट ब्लॉकों को बाईपास करने के लिए।
-
स्व-विकसित क्रोमियम-चालित: हमारे क्रोमियम कर्नेल द्वारा संचालित, उच्च अनुकूलन, सत्र प्रबंधन, और स्वचालित CAPTCHA हल करने की अनुमति देता है।
1. ऑटो CAPTCHA सॉल्वर: सामान्य CAPTCHA प्रकारों जैसे reCAPTCHA v2 और Cloudflare Turnstile/Challenge को स्वचालित रूप से संभालता है।
2. सत्र रिकॉर्डिंग और पुनरावृत्ति: सत्र पुनरावृत्ति आपको रिकॉर्ड की गई प्लेबैक के माध्यम से क्रियाओं और अनुरोधों की जांच करने में मदद करती है, उन्हें चरण-दर-चरण समीक्षा करते हुए समस्याओं के समाधान और प्रक्रिया सुधार के लिए तेजी से समझने में।
3. समवर्ती लाभ: अन्य क्रॉलर्स के विपरीत जिनके पास सख्त समवर्ती सीमाएँ हैं, Crawl की बुनियादी योजना 50 समवर्तिता का समर्थन करती है, जबकि प्रीमियम योजना में असीमित समवर्तिता है।
4. लागत में बचत: एंटी-क्रॉल उपायों वाले वेबसाइटों पर प्रतिस्पर्धियों को बेहतर प्रदर्शन करते हुए, यह मुफ़्त CAPTCHA समाधान में महत्वपूर्ण लाभ प्रदान करता है — अपेक्षित 70% लागत की बचत।
उन्नत डेटा स्क्रैपिंग और प्रोसेसिंग क्षमताओं का लाभ उठाते हुए, Crawl संरचित रीयल-टाइम खोज डेटा की डिलीवरी सुनिश्चित करता है। यह उद्यमों और डेवलपर्स को बाजार के रुझानों से हमेशा आगे रहने, डेटा-चालित स्वचालन कार्यप्रवाह को अनुकूलित करने, और बाजार रणनीतियों को तेजी से समायोजित करने में सक्षम बनाता है।
Crawl के साथ जटिल डेटा चुनौतियों का समाधान करें: तेज़, अधिक बुद्धिमान, और अधिक कुशल
उन डेवलपर्स और उद्यमों के लिए जिन्हें बड़े पैमाने पर विश्वसनीय वेब डेटा की आवश्यकता है, Crawl भी प्रदान करता है:
✔ उच्च गति डेटा स्क्रैप – सेकंडों में कई वेब पृष्ठों से डेटा पुनः प्राप्त करें।
✔ निर्बाध एकीकरण– जल्द ही ओपन-सोर्स फ्रेमवर्क और दृश्य कार्यप्रवाह एकीकरण, जैसे Langchain, N8n, Clay, Pipedream, Make आदि के साथ एकीकृत करें।
✔ भू-लक्षित प्रॉक्सी – अंतर्निर्मित प्रॉक्सी समर्थन 195 देशों के लिए।
✔ सत्र प्रबंधन – बुद्धिमानी से सत्रों का प्रबंधन करें और रीयल-टाइम में LiveURL सत्र देखें।
Crawl का उपयोग कैसे करें
Crawl API या तो एक कॉल में वेब पृष्ठों से विशिष्ट सामग्री लाने या एक सम्पूर्ण साइट और इसकी लिंकों को पुनरावर्ती रूप से क्रॉल करने के द्वारा डेटा स्क्रैप को सरल बनाता है, जिससे सभी उपलब्ध डेटा एकत्र किया जा सके, बहु-फॉर्मेट में समर्थित।
Scrapeless स्क्रैप अनुरोध शुरू करने और उनकी स्थिति/परिणाम जांचने के लिए एंडपॉइंट प्रदान करता है। डिफ़ॉल्ट रूप से, स्क्रैपिंग असंक्रामक है: पहले एक काम शुरू करें, फिर इसकी स्थिति की निगरानी करें जब तक कि यह पूरा न हो जाए। हालांकि, हमारे SDKs में एक सरल फ़ंक्शन शामिल है जो पूरी प्रक्रिया को संभालता है और काम समाप्त होने पर डेटा लौटाता है।
इंस्टॉलेशन
NPM का उपयोग करके Scrapeless SDK स्थापित करें:
Bash
npm install @scrapeless-ai/sdkPNPM का उपयोग करके Scrapeless SDK स्थापित करें:
Bash
pnpm add @scrapeless-ai/sdkएकल पृष्ठ पर क्रॉल करें
एक कॉल में वेब पृष्ठों से विशिष्ट डेटा (जैसे उत्पाद विवरण, समीक्षाएँ) क्रॉल करें।
उपयोग
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// क्लाइंट प्रारंभ करें
const client = new Scrapeless({
apiKey: "your-api-key", // अपना API कुंजी प्राप्त करने के लिए https://scrapeless.com पर जाएँ
});
(async () => {
const result = await client.scrapingCrawl.scrape.scrapeUrl(
"https://example.com"
);
console.log(result);
})();ब्राउज़र कॉन्फ़िगरेशन्स
आप स्क्रैपिंग के लिए सत्र सेटिंग्स को अनुकूलित कर सकते हैं, जैसे प्रॉक्सी का उपयोग करना, जैसे कि एक नए ब्राउज़र सत्र का निर्माण।
Scrapeless स्वचालित रूप से सामान्य CAPTCHAs को संभालता है, जिसमें reCAPTCHA v2 और Cloudflare Turnstile/Challenge शामिल हैं—कोई अतिरिक्त सेटअप की आवश्यकता नहीं है, विवरण के लिए देखें कैप्चा सॉल्विंग।
सभी ब्राउज़र पैरामीटर का अन्वेषण करने के लिए, API संदर्भ या ब्राउज़र पैरामीटर देखें।
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// क्लाइंट को प्रारंभ करें
const client = new Scrapeless({
apiKey: "your-api-key", // अपना API कुंजी https://scrapeless.com से प्राप्त करें
});
(async () => {
const result = await client.scrapingCrawl.scrapeUrl(
"https://example.com",
{
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();स्क्रैप कॉन्फ़िगरेशन
स्क्रैप कार्यों के लिए वैकल्पिक पैरामीटर में आउटपुट प्रारूप, मुख्य पृष्ठ सामग्री केवल लौटाने के लिए फ़िल्टर करना, और पृष्ठ नेविगेशन के लिए अधिकतम समय सीमा निर्धारित करना शामिल हैं।
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// क्लाइंट को प्रारंभ करें
const client = new ScrapingCrawl({
apiKey: "your-api-key", // अपना API कुंजी https://scrapeless.com से प्राप्त करें
});
(async () => {
const result = await client.scrapeUrl(
"https://example.com",
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
);
console.log(result);
})();स्क्रैप एंडपॉइंट पर पूर्ण संदर्भ के लिए, API संदर्भ देखें।
बैच स्क्रैप
बैच स्क्रैप सामान्य स्क्रैप के समान कार्य करता है, सिवाय इसके कि एकल URL के बजाय, आप एक साथ स्क्रैप करने के लिए URLs की एक सूची प्रदान कर सकते हैं।
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// क्लाइंट को प्रारंभ करें
const client = new ScrapingCrawl({
apiKey: "your-api-key", // अपना API कुंजी https://scrapeless.com से प्राप्त करें
});
(async () => {
const result = await client.batchScrapeUrls(
["https://example.com", "https://scrapeless.com"],
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();क्रॉल उपपृष्ठ
क्रॉल API एक वेबसाइट और इसके लिंक को पुनरावृत्त रूप से क्रॉल करने का समर्थन करता है ताकि सभी उपलब्ध डेटा निकाला जा सके।
विस्तृत उपयोग के लिए, क्रॉल API संदर्भ देखें।
उपयोग
पूरे डोमेन और उसके लिंक का अन्वेषण करने के लिए पुनरावृत्त क्रॉल का उपयोग करें, हर उपलब्ध डेटा का टुकड़ा निकालें।
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// क्लाइंट को प्रारंभ करें
const client = new ScrapingCrawl({
apiKey: "your-api-key", // अपना API कुंजी https://scrapeless.com से प्राप्त करें
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
},
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();प्रतिक्रिया
JavaScript
{
"success": true,
"status": "completed",
"completed": 2,
"total": 2,
"data": [
{
"url": "https://example.com",
"metadata": {
"title": "Example Page",
"description": "A sample webpage"
},
"markdown": "# Example Page\nThis is content...",
...
},
...
]
}हर क्रॉल की गई पृष्ठ की अपनी स्थिति होती है completed या failed और इसमें अपनी त्रुटि फ़ील्ड हो सकती है, इसलिए इसके प्रति सतर्क रहें। पूर्ण स्कीमा देखने के लिए, API संदर्भ देखें।
ब्राउज़र कॉन्फ़िगरेशन
स्क्रैप कार्यों के लिए सत्र कॉन्फ़िगरेशन के अनुकूलन का प्रक्रिया नई ब्राउज़र सत्र बनाने के समान होती है। उपलब्ध विकल्पों में प्रॉक्सी कॉन्फ़िगरेशन शामिल है। सभी समर्थित सत्र पैरामीटर देखने के लिए API संदर्भ या ब्राउज़र पैरामीटर देखें।
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// क्लाइंट को प्रारंभ करें
const client = new ScrapingCrawl({
apiKey: "your-api-key", // अपना API कुंजी https://scrapeless.com से प्राप्त करें
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();स्क्रैप कॉन्फ़िगरेशन
पैरामीटर में आउटपुट प्रारूप, केवल मुख्य पृष्ठ सामग्री वापस करने के लिए फ़िल्टर, और पृष्ठ नेविगेशन के लिए अधिकतम टाइमआउट सेटिंग शामिल हो सकते हैं।
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// क्लाइंट प्रारंभ करें
const client = new ScrapingCrawl({
apiKey: "your-api-key", // अपना API कुंजी प्राप्त करें https://scrapeless.com से
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
}
);
console.log(result);
})();क्रॉल एंडपॉइंट के लिए पूर्ण संदर्भ के लिए, API संदर्भ देखें।
क्रॉलिंग के विभिन्न उपयोग मामलों की खोज करना
डेवलपर्स के लिए अपने कोड का परीक्षण और डिबग करने के लिए एक अंतर्निहित प्लेग्राउंड उपलब्ध है, और आप किसी भी स्क्रैपिंग आवश्यकता के लिए क्रॉल का उपयोग कर सकते हैं, उदाहरण के लिए:
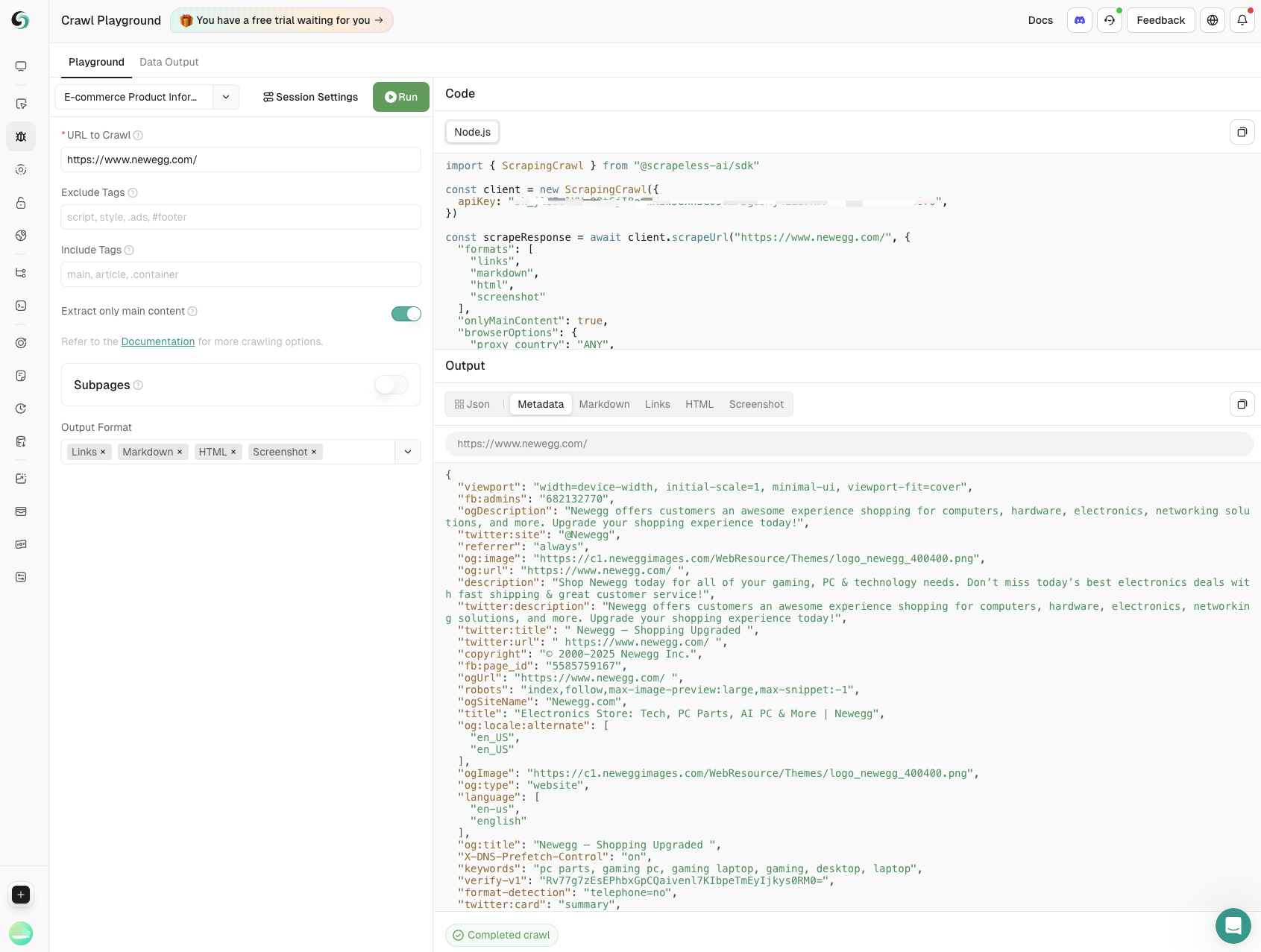
- उत्पाद जानकारी स्क्रैपिंग
मुख्य डेटा जिसमें उत्पाद नाम, मूल्य, उपयोगकर्ता रेटिंग और समीक्षा की संख्या को ई-कॉमर्स वेबसाइटों पर स्क्रैप करके निकाला जाता है। उत्पाद निगरानी का पूर्ण समर्थन करता है और व्यवसायों को सूचित निर्णय लेने में मदद करता है।
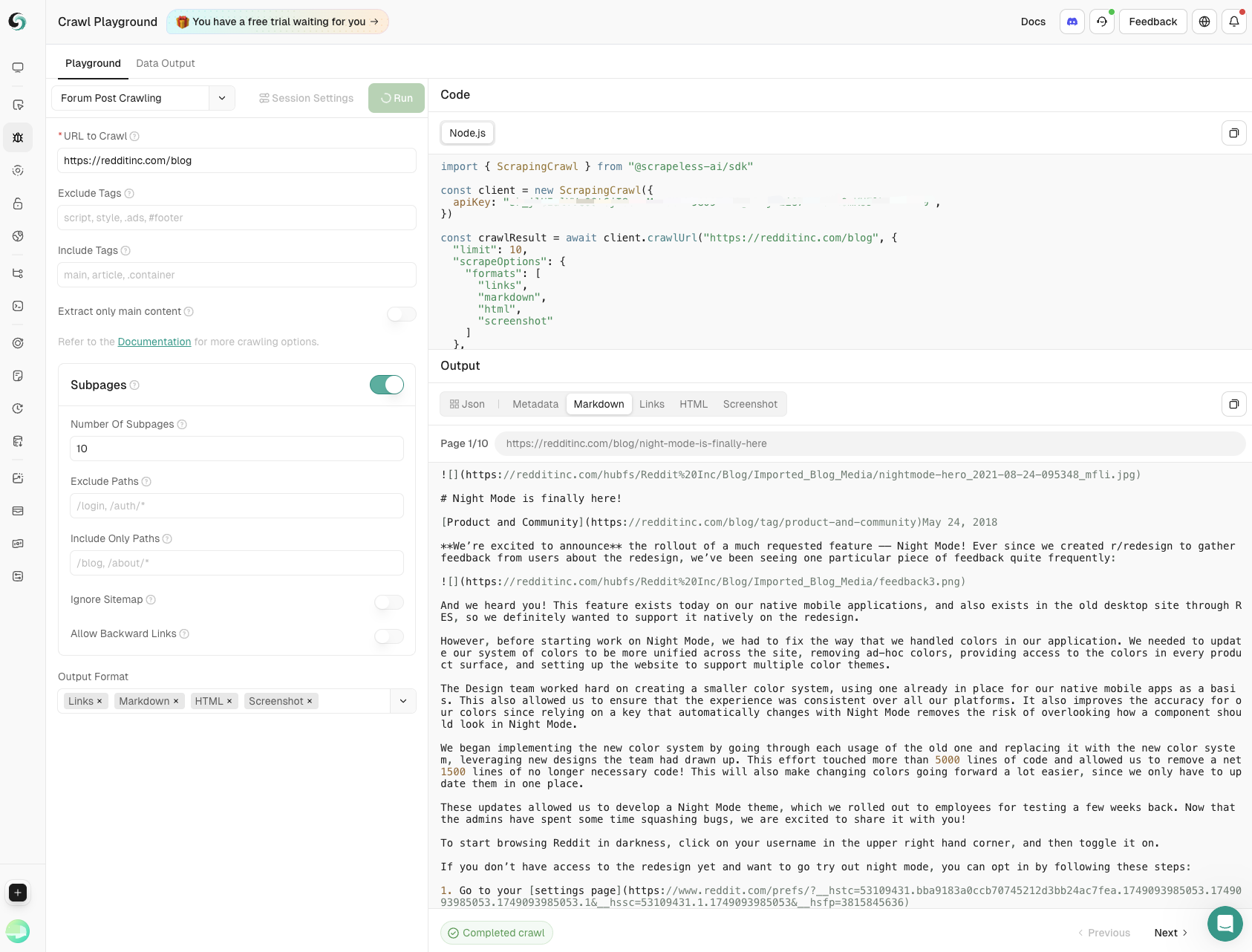
- फोरम पोस्ट क्रॉलिंग
मुख्य पोस्ट सामग्री और उपपृष्ठ टिप्पणियों को गहराई और चौड़ाई पर सटीक नियंत्रण के साथ कैप्चर करें, सामुदायिक चर्चाओं से व्यापक अंतर्दृष्टि सुनिश्चित करें।
अब क्रॉल और स्क्रैप करें!
किसी भी आवश्यकता के लिए लागत-कुशल और सस्ती: $1.8/जीबी से शुरू, प्रति पृष्ठ नहीं
हमारे क्रोमियम-आधारित स्क्रैपर के साथ प्रतिस्पर्धियों को आउटपरफॉर्म करें जिसमें प्रॉक्सी की मात्रा और घंटे की दर को मिलाकर मूल्य निर्धारण मॉडल है, जो बड़े पैमाने पर डेटा परियोजनाओं पर प्रति पृष्ठ मॉडल के मुकाबले 70% लागत की बचत प्रदान करता है।
अब एक परीक्षण के लिए पंजीकरण करें और मजबूत वेब टूलकिट प्राप्त करें।
💡उच्च-मात्रा उपयोगकर्ताओं के लिए, अनुकूलित मूल्य निर्धारण के लिए हमसे संपर्क करें - आपकी जरूरतों के अनुरूप प्रतिस्पर्धी दरें।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


