
Scrapeless का उपयोग करके Google Lens परिणामों को कैसे स्क्रैप करें
Advanced Data Extraction Specialist
Google Lens क्या है?
Google Lens एक कृत्रिम बुद्धिमत्ता और छवि पहचान तकनीक पर आधारित एप्लीकेशन है जो कैमरे या चित्रों के माध्यम से वस्तुओं, पाठ, स्थलों और अन्य सामग्री की पहचान कर सकता है और प्रासंगिक जानकारी प्रदान कर सकता है।
क्या Google Lens से डेटा खुरचना कानूनी है?
Google Lens डेटा को स्क्रैप करना अवैध नहीं है, लेकिन कई कानूनी और नैतिक दिशानिर्देश हैं जिनका पालन करने की आवश्यकता है। उपयोगकर्ताओं को यह सुनिश्चित करने के लिए Google की सेवा की शर्तें, डेटा गोपनीयता कानून और बौद्धिक संपदा अधिकारों को समझना चाहिए कि उनकी गतिविधियाँ अनुपालन में हैं। सर्वोत्तम प्रथाओं का पालन करके और कानूनी विकास के बारे में सूचित रहकर, आप वेब स्क्रैपिंग से जुड़े कानूनी मुद्दों के जोखिम को कम कर सकते हैं।
Google Lens को स्क्रैप करने में चुनौतियाँ
- उन्नत एंटी-बॉट तकनीक: Google नेटवर्क ट्रैफ़िक पैटर्न की निगरानी करता है। क्रॉलर से बड़ी संख्या में दोहराव वाले अनुरोधों का जल्दी पता लगाया जा सकता है, जिससे IP प्रतिबंध लग जाते हैं, जो क्रॉलिंग प्रक्रिया को रोक देते हैं।
अनुशंसित पठन: एंटी-बॉट: यह क्या है और इससे कैसे बचें - जावास्क्रिप्ट - रेंडर्ड सामग्री: Google Lens के लिए अधिकांश डेटा जावास्क्रिप्ट द्वारा गतिशील रूप से उत्पन्न होता है, जो पारंपरिक क्रॉलर के लिए दुर्गम है, जिसके लिए Puppeteer या Selenium जैसे हेडलेस ब्राउज़र के उपयोग की आवश्यकता होती है, लेकिन इससे जटिलता और संसाधन खपत बढ़ जाती है।
- CAPTCHA सुरक्षा: Google मानव उपयोगकर्ताओं को प्रमाणित करने के लिए CAPTCHA का उपयोग करता है। क्रॉलर को CAPTCHA चुनौतियों का सामना करना पड़ सकता है जिन्हें प्रोग्रामेटिक रूप से हल करना मुश्किल है।
- बार-बार वेबसाइट अपडेट: Google नियमित रूप से Google Lens की संरचना और लेआउट को बदलता है। क्रॉलिंग कोड जल्दी से पुराना हो सकता है, और डेटा निष्कर्षण के लिए उपयोग किए जाने वाले XPath या CSS चयनकर्ता काम करना बंद कर सकते हैं। निरंतर निगरानी और अपडेट की आवश्यकता है।
Python के साथ Google Lens को स्क्रैप करने के लिए चरण गाइड
चरण 1. पर्यावरण को कॉन्फ़िगर करें
- Python: सॉफ्टवेयर Python चलाने का मूल है। आप नीचे दिखाए गए अनुसार आधिकारिक वेबसाइट से हमें आवश्यक संस्करण डाउनलोड कर सकते हैं। हालाँकि, नवीनतम संस्करण डाउनलोड करने की अनुशंसा नहीं की जाती है। आप नवीनतम संस्करण से पहले के 1.2 संस्करण डाउनलोड कर सकते हैं।
- Python IDE: Python को सपोर्ट करने वाला कोई भी IDE काम करेगा, लेकिन हम PyCharm की सलाह देते हैं। यह विशेष रूप से Python के लिए डिज़ाइन किया गया एक विकास उपकरण है। PyCharm संस्करण के लिए, हम मुफ्त PyCharm कम्युनिटी संस्करण की अनुशंसा करते हैं
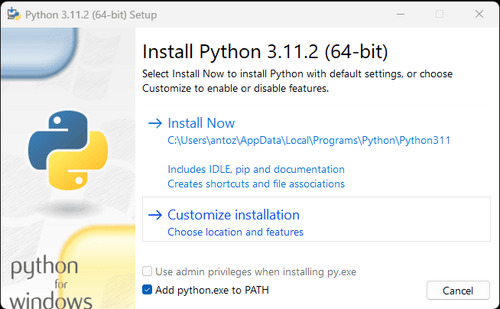
नोट: यदि आप विंडोज़ उपयोगकर्ता हैं, तो इंस्टॉलेशन विज़ार्ड के दौरान "Add python.exe to PATH" विकल्प को चेक करना न भूलें। यह विंडोज़ को टर्मिनल में Python और कमांड का उपयोग करने की अनुमति देगा। चूँकि Python 3.4 या बाद के संस्करण में यह डिफ़ॉल्ट रूप से शामिल है, इसलिए आपको इसे मैन्युअल रूप से स्थापित करने की आवश्यकता नहीं है।
अब आप जांच सकते हैं कि क्या Python स्थापित है, टर्मिनल या कमांड प्रॉम्प्ट खोलकर और निम्न कमांड दर्ज करके:
python --versionचरण 2. निर्भरताएँ स्थापित करें
प्रोजेक्ट निर्भरताओं को प्रबंधित करने और अन्य Python प्रोजेक्ट्स के साथ संघर्ष से बचने के लिए वर्चुअल एन्वायरमेंट बनाने की अनुशंसा की जाती है। टर्मिनल में प्रोजेक्ट निर्देशिका पर जाएँ और google_lens नामक वर्चुअल एन्वायरमेंट बनाने के लिए निम्न कमांड निष्पादित करें:
python -m venv google_lensअपने सिस्टम के आधार पर वर्चुअल एन्वायरमेंट को सक्रिय करें:
विंडोज़:
google_lens_env\Scripts\activateMacOS/Linux:
source google_lens_env/bin/activateवर्चुअल एन्वायरमेंट को सक्रिय करने के बाद, वेब स्क्रैपिंग के लिए आवश्यक Python लाइब्रेरी स्थापित करें। Python में अनुरोध भेजने के लिए लाइब्रेरी requests है, और डेटा स्क्रैप करने के लिए मुख्य लाइब्रेरी BeautifulSoup4 है। उन्हें निम्न कमांड का उपयोग करके स्थापित करें:
pip install requests
pip install beautifulsoup4
pip install playwrightचरण 3. डेटा स्क्रैप करें
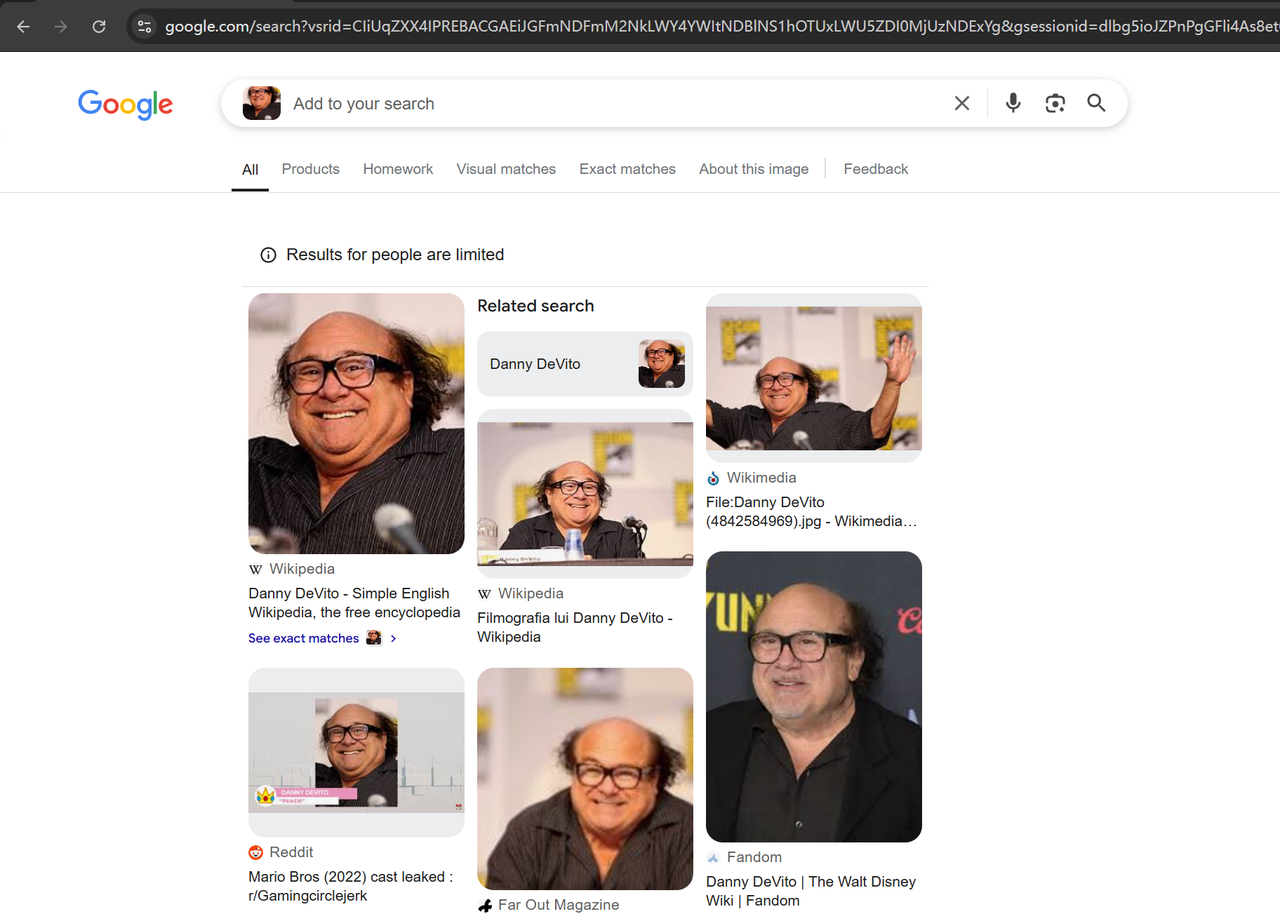
अपने ब्राउज़र में Google lens(https://www.google.com/?olud) खोलें और "https://i.imgur.com/HBrB8p0.png" खोजें। नीचे खोज परिणाम है:
शीर्षक और छवि जानकारी स्क्रैप करें
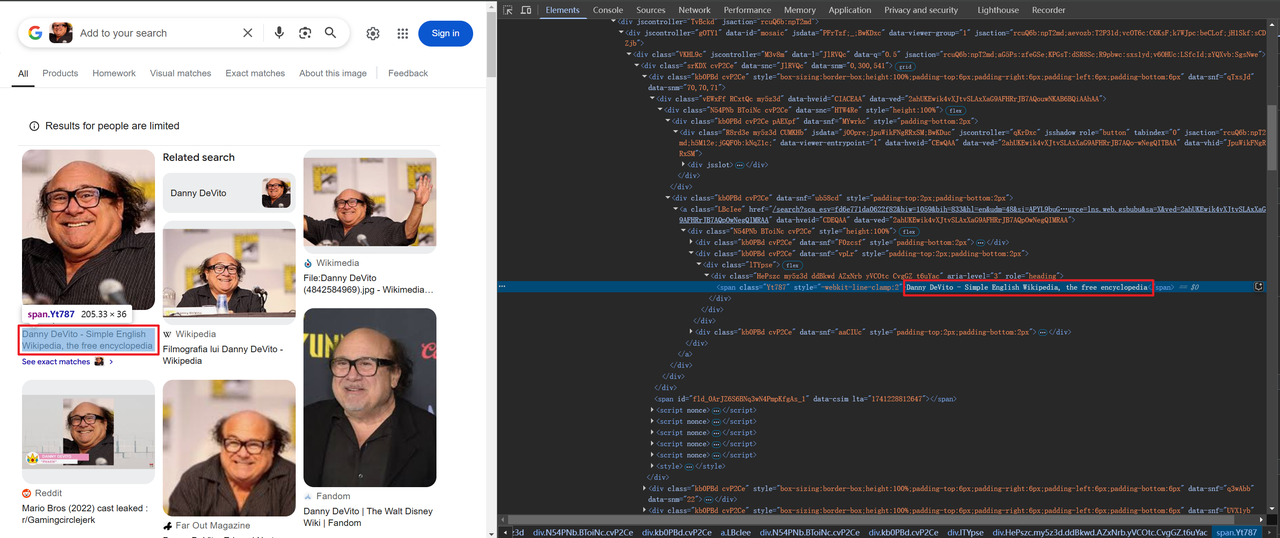
कुछ छवियों को बेस64 में एन्कोड किया जाता है, जबकि अन्य HTTP के माध्यम से लिंक किए जाते हैं, जैसे:
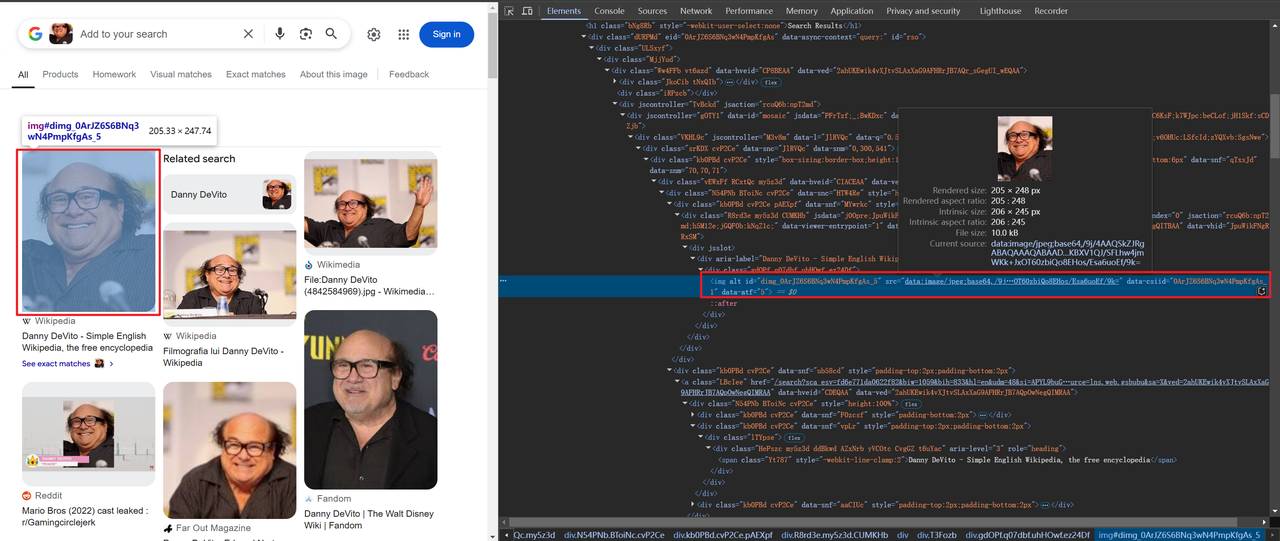
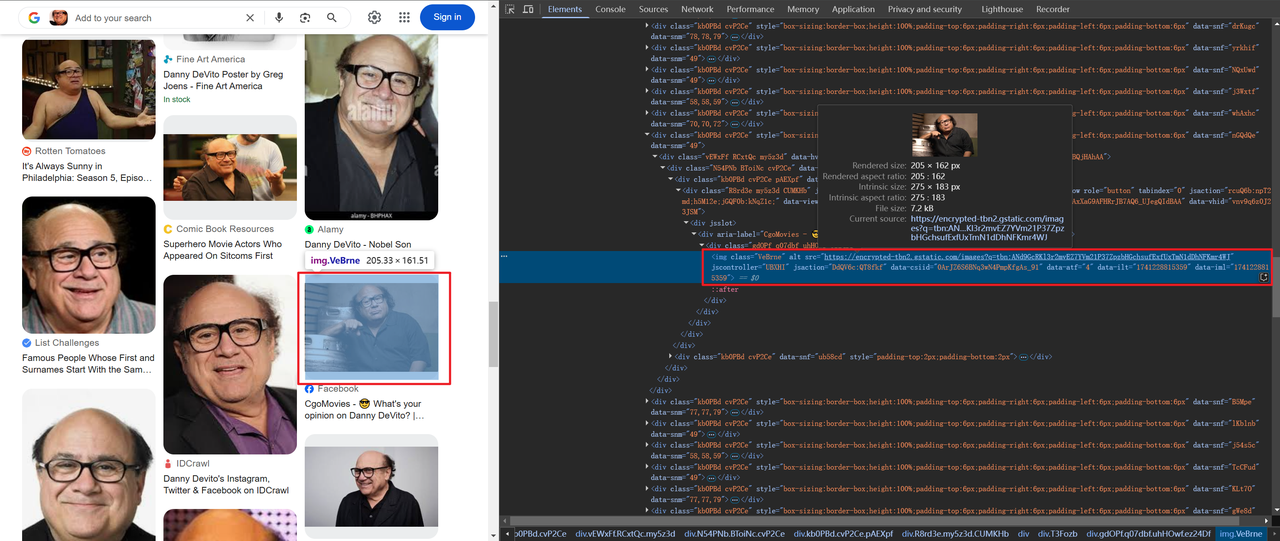
शीर्षक और छवि जानकारी प्राप्त करने का कोड इस प्रकार है:
# लेंस जानकारी को एक डिक्शनरी में संग्रहीत करें
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}चूँकि हमें केवल एक नहीं, बल्कि पृष्ठ पर सभी डेटा को स्क्रैप करने की आवश्यकता है, इसलिए हमें लूप के माध्यम से और उपरोक्त डेटा को स्क्रैप करने की आवश्यकता है। पूर्ण कोड इस प्रकार है:
import json
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwright
def scrape(url: str) -> str:
with sync_playwright() as p:
# ब्राउज़र लॉन्च करें और कुछ सुविधाओं को अक्षम करें जो पता लगाने का कारण बन सकती हैं
browser = p.chromium.launch(
headless=True,
args=[
"--disable-blink-features=AutomationControlled",
"--disable-dev-shm-usage",
"--disable-gpu",
"--disable-extensions",
],
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
bypass_csp=True,
)
page = context.new_page()
page.goto(url)
page.wait_for_selector("body", state="attached")
# यह सुनिश्चित करने के लिए 2 सेकंड तक प्रतीक्षा करें कि पृष्ठ पूरी तरह से लोड या रेंडर किया गया है
page.wait_for_timeout(2000)
html_content = page.content()
browser.close()
return html_content
def main():
url = "https://lens.google.com/uploadbyurl?url=https%3A%2F%2Fi.imgur.com%2FHBrB8p0.png"
html_content = scrape(url)
soup = BeautifulSoup(html_content, 'html.parser')
# पृष्ठ का मुख्य डेटा प्राप्त करें
items = soup.find('div', {'jscontroller': 'M3v8m'}).find("div")
# परिपत्र असेंबली
assembly = lens_info(items)
# परिणामों को JSON फ़ाइल में सहेजें
with open('google_lens_data.json', 'w') as json_file:
json.dump(assembly, json_file, indent=4)
def lens_info(items):
lens_data = []
for item in items:
# लेंस जानकारी को एक डिक्शनरी में संग्रहीत करें
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}
lens_data.append(img_info)
return lens_data
if __name__ == "__main__":
main()चरण 4. परिणाम आउटपुट करें
आपकी PyCharm निर्देशिका में google_lens_data.json नाम की एक फ़ाइल बन जाएगी। आउटपुट इस प्रकार है (आंशिक उदाहरण):
[
{
"title": "Danny DeVito - Wikipedia",
"thumbnail": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAQEhAQEBAQEB
},
{
"title": "Devito Danny Royalty-Free Images, Stock Photos & Pictures | Shutterstock",
"thumbnail": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcSO6Pkv_UmXiianiCh52nD5s89d7KrlgQQox-f-K9FtXVILvHh_"
},
{
"title": "DATA | Celebrity Stats | Page 62",
"thumbnail": "https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcQ9juRVpW6sjE3OANTKIJzGEkiwUpjCI20Z1ydvJBCEDf3-NcQE"
},
{
"title": "Danny DeVito, Grand opening of Buca di Beppo italian restaurant on Universal City Walk Universal City, California - 28.01.09 Stock Photo - Alamy",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQq_07f-Unr7Y5BXjSJ224RlAidV9pzccqjucD4VF7VkJEJJqBk"
}
]अधिक कुशल उपकरण: Scrapeless के साथ Google Lens परिणामों को कैसे स्क्रैप करें
Scrapeless एक शक्तिशाली उपकरण प्रदान करता है जो डेवलपर्स को जटिल कोड लिखे बिना आसानी से Google Lens खोज परिणामों को स्क्रैप करने में मदद करता है। यहाँ आपके Python क्रॉलर उपकरण में Scrapeless API को एकीकृत करने के विस्तृत चरण दिए गए हैं:
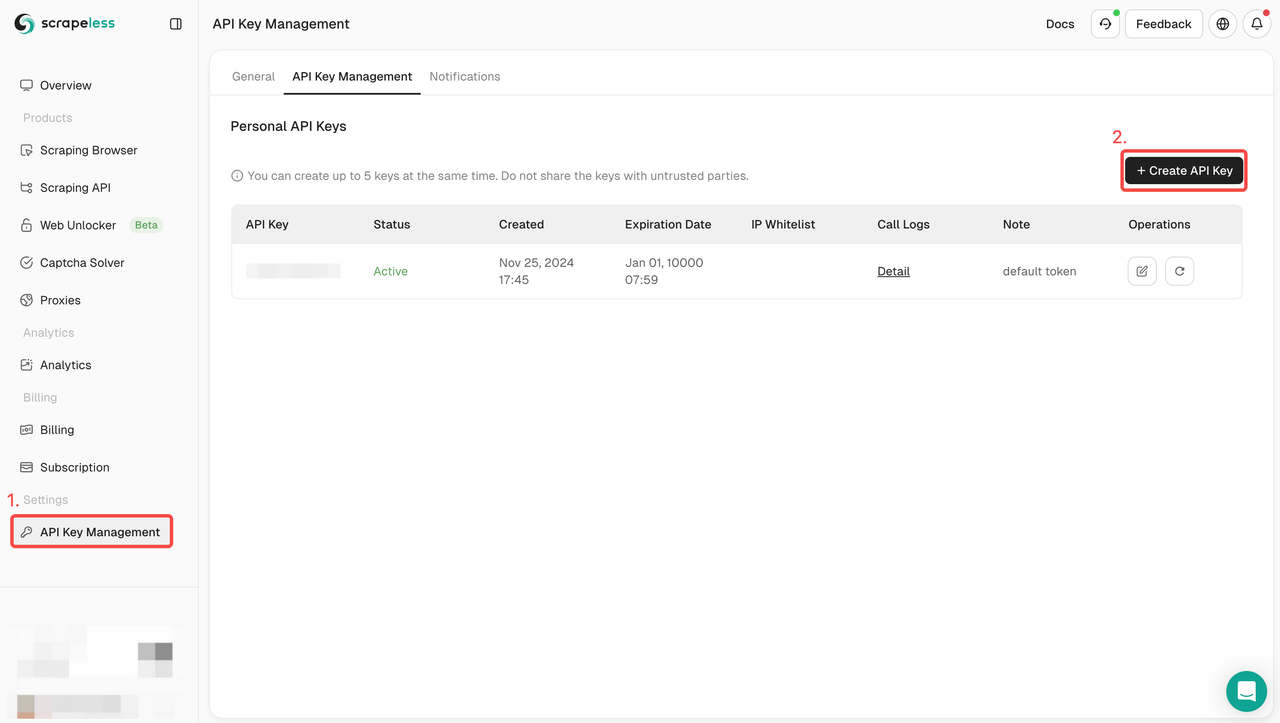
चरण 1: Scrapeless के लिए साइन अप करें और एक API कुंजी प्राप्त करें
- यदि आपके पास अभी तक Scrapeless खाता नहीं है, तो Scrapeless वेबसाइट पर जाएँ और साइन अप करें।
- साइन अप करने के बाद, अपने डैशबोर्ड में लॉग इन करें।
- डैशबोर्ड में, API कुंजी प्रबंधन पर जाएँ और API कुंजी बनाएँ पर क्लिक करें। उत्पन्न API कुंजी की प्रतिलिपि बनाएँ, जो Scrapeless API को कॉल करते समय आपकी प्रमाणीकरण क्रेडेंशियल होगी।
चरण 2: Scrapeless API को एकीकृत करने के लिए एक Python स्क्रिप्ट लिखें
Scrapeless API का उपयोग करके Google Lens परिणामों को स्क्रैप करने के लिए एक नमूना कोड इस प्रकार है:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
engine: "google_lens",
hl: "en",
country: "jp",
url: "https://s3.zoommer.ge/zoommer-images/thumbs/0170510_apple-macbook-pro-13-inch-2022-mneh3lla-m2-chip-8gb256gb-ssd-space-grey-apple-m25nm-apple-8-core-gpu_550.jpeg",
}
payload = Payload("scraper.google.lens", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()टिप्पणियाँ
API कुंजी सुरक्षा: कृपया सुनिश्चित करें कि आप अपनी API कुंजी को सार्वजनिक कोड रिपॉजिटरी में उजागर न करें।
क्वेरी अनुकूलन: अधिक सटीक परिणाम प्राप्त करने के लिए अपनी आवश्यकताओं के अनुसार क्वेरी पैरामीटर समायोजित करें। API पैरामीटर के बारे में अधिक जानकारी के लिए, आप Scrapeless के आधिकारिक API दस्तावेज़ की जाँच कर सकते हैं
Google Lens को स्क्रैप करने के लिए Scrapeless क्यों चुनें
Scrapeless एक शक्तिशाली AI-संचालित वेब स्क्रैपिंग उपकरण है जिसे कुशल और स्थिर वेब स्क्रैपिंग के लिए डिज़ाइन किया गया है।
1. वास्तविक समय डेटा और उच्च-गुणवत्ता वाले परिणाम
Scrapeless वास्तविक समय Google Lens खोज परिणाम प्रदान करता है और 1-2 सेकंड के भीतर Google Lens खोज परिणाम वापस कर सकता है। सुनिश्चित करें कि उपयोगकर्ताओं को जो डेटा मिलता है वह हमेशा अद्यतित रहता है।
2. किफायती मूल्य
Scrapeless की कीमत बहुत प्रतिस्पर्धी है, केवल $0.1 प्रति 1,000 क्वेरी की कीमत के साथ।
3. शक्तिशाली फ़ंक्शन समर्थन
Scrapeless कई खोज प्रकारों का समर्थन करता है, जिसमें 20 से अधिक Google खोज परिणाम परिदृश्य शामिल हैं। यह JSON प्रारूप में संरचित डेटा वापस कर सकता है, जो उपयोगकर्ताओं के लिए जल्दी से पार्स करने और उपयोग करने के लिए सुविधाजनक है।
Scrapeless Deep SerpAPI: एक शक्तिशाली वास्तविक समय खोज डेटा समाधान
Scrapeless Deep SerpApi एक वास्तविक समय खोज डेटा प्लेटफ़ॉर्म है जिसे AI अनुप्रयोगों और पुनर्प्राप्ति-वर्धित पीढ़ी (RAG) मॉडल के लिए डिज़ाइन किया गया है। यह वास्तविक समय, सटीक और संरचित Google खोज परिणाम डेटा प्रदान करता है, जो 20 से अधिक Google SERP प्रकारों का समर्थन करता है, जिसमें Google खोज, Google रुझान, Google खरीदारी, Google उड़ानें, Google होटल, Google मानचित्र आदि शामिल हैं।

मुख्य विशेषताएं
- वास्तविक समय डेटा अद्यतन: पिछले 24 घंटों के भीतर डेटा अपडेट पर आधारित, जानकारी की समयबद्धता और सटीकता सुनिश्चित करना।
- बहु-भाषा और भू-स्थान समर्थन: बहु-भाषा और भू-स्थान का समर्थन करता है, और उपयोगकर्ता के स्थान, डिवाइस प्रकार और भाषा के आधार पर खोज परिणामों को अनुकूलित कर सकता है।
- तेज़ प्रतिक्रिया: औसत प्रतिक्रिया समय केवल 1-2 सेकंड है, जो उच्च-आवृत्ति और बड़े पैमाने पर डेटा पुनर्प्राप्ति के लिए उपयुक्त है।
- सहज एकीकरण: Python, Node.js, Golang आदि जैसी मुख्यधारा की प्रोग्रामिंग भाषाओं के साथ संगत, मौजूदा परियोजनाओं में एकीकृत करना आसान है।
- लागत प्रभावी: $0.1 प्रति 1,000 क्वेरी की कीमत के साथ, यह बाजार में सबसे किफायती SERP समाधान है।
विशेष ऑफ़र
- नि:शुल्क परीक्षण: एक नि:शुल्क परीक्षण प्रदान किया जाता है, और उपयोगकर्ता सभी सुविधाओं का अनुभव कर सकते हैं।
- डेवलपर समर्थन कार्यक्रम: पहले 100 उपयोगकर्ता $50 (500,000 क्वेरी) के मुफ्त API कॉल कोटा प्राप्त कर सकते हैं, जो परीक्षण और विस्तार परियोजनाओं के लिए उपयुक्त है।
यदि आपके कोई प्रश्न हैं या अनुकूलन आवश्यकताओं की आवश्यकता है, तो आप Discord लिंक पर क्लिक करके Liam से संपर्क कर सकते हैं।
निष्कर्ष
इस लेख में, हमने विस्तार से बताया कि Google Lens खोज परिणामों को क्रॉल करने के लिए Scrapeless का उपयोग कैसे करें। Scrapeless द्वारा प्रदान किए गए शक्तिशाली API के साथ, डेवलपर्स और शोधकर्ता जटिल कोड लिखे बिना या एंटी-क्रॉलिंग तंत्र के बारे में चिंता किए बिना आसानी से वास्तविक समय, उच्च-गुणवत्ता वाले दृश्य डेटा प्राप्त कर सकते हैं। Scrapeless की दक्षता और लचीलापन इसे Google Lens डेटा को संसाधित करने के लिए एक आदर्श उपकरण बनाता है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।



{kind=link}