
Python में Google Finance टिकर कोट डेटा कैसे स्क्रैप करें
Advanced Data Extraction Specialist
तेज़-तर्रार वित्त की दुनिया में, निवेशकों, व्यापारियों और विश्लेषकों के लिए अद्यतित और सटीक शेयर बाजार डेटा तक पहुँच आवश्यक है। Google Finance एक अमूल्य संसाधन है जो वास्तविक समय के शेयर कोटेशन, ऐतिहासिक वित्तीय डेटा, समाचार और मुद्रा दरें प्रदान करता है। पाइथन का उपयोग करके इस डेटा को स्क्रैप करना सीखना उन लोगों के लिए बहुत फायदेमंद हो सकता है जो डेटा को एकत्रित करना, भावना विश्लेषण करना, बाजार पूर्वानुमान बनाना या जोखिम का प्रभावी ढंग से प्रबंधन करना चाहते हैं।
Google Finance क्यों स्क्रैप करें?
Google Finance को स्क्रैप करने से कई कारणों से फायदा हो सकता है, जिनमें शामिल हैं:
- वास्तविक समय का शेयर डेटा - अद्यतित शेयर कीमतों, बाजार के रुझानों और ऐतिहासिक प्रदर्शन तक पहुँच।
- स्वचालित बाजार विश्लेषण - प्रवृत्ति विश्लेषण, पोर्टफोलियो प्रबंधन या एल्गोरिथम ट्रेडिंग के लिए बड़े पैमाने पर वित्तीय डेटा एकत्र करें।
- कंपनी की अंतर्दृष्टि - निवेश अनुसंधान के लिए वित्तीय सारांश, आय रिपोर्ट और शेयर प्रदर्शन एकत्र करें।
- प्रतियोगी और उद्योग अनुसंधान - डेटा-संचालित निर्णय लेने के लिए प्रतियोगियों के वित्तीय स्वास्थ्य और उद्योग के रुझानों की निगरानी करें।
- समाचार और भावना विश्लेषण - भावना ट्रैकिंग के लिए विशिष्ट शेयरों या उद्योगों से संबंधित समाचार लेख और अपडेट निकालें।
क्या स्क्रैप किया जाएगा
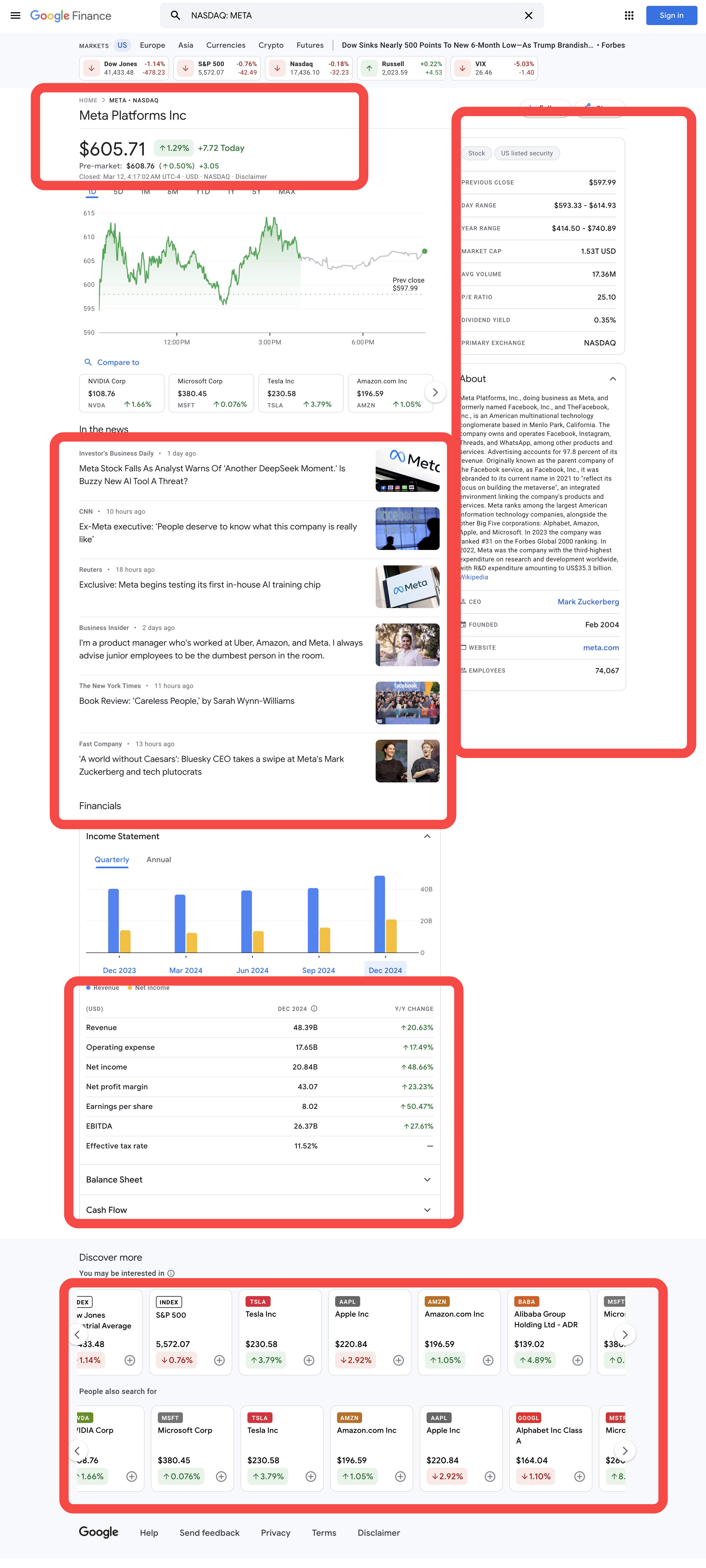
पाइथन में Google Finance टिकर कोट डेटा को कैसे स्क्रैप करें
चरण 1. पर्यावरण को कॉन्फ़िगर करें
-
पाइथन: सॉफ्टवेयर पाइथन चलाने का मूल है। आप नीचे दिखाए अनुसार आधिकारिक वेबसाइट से हमें जिस संस्करण की आवश्यकता है उसे डाउनलोड कर सकते हैं। हालाँकि, नवीनतम संस्करण डाउनलोड करने की अनुशंसा नहीं की जाती है। आप नवीनतम संस्करण से पहले 1.2 संस्करण डाउनलोड कर सकते हैं।
-
पाइथन IDE: पाइथन को सपोर्ट करने वाला कोई भी IDE काम करेगा, लेकिन हम PyCharm की सलाह देते हैं। यह विशेष रूप से पाइथन के लिए डिज़ाइन किया गया एक विकास उपकरण है। PyCharm संस्करण के लिए, हम मुफ़्त PyCharm कम्युनिटी संस्करण की अनुशंसा करते हैं
ध्यान दें: यदि आप विंडोज़ उपयोगकर्ता हैं, तो इंस्टॉलेशन विज़ार्ड के दौरान "Add python.exe to PATH" विकल्प को चेक करना न भूलें। यह विंडोज़ को टर्मिनल में पाइथन और कमांड का उपयोग करने की अनुमति देगा। चूँकि पाइथन 3.4 या बाद के संस्करण में यह डिफ़ॉल्ट रूप से शामिल है, इसलिए आपको इसे मैन्युअल रूप से स्थापित करने की आवश्यकता नहीं है।
अब आप टर्मिनल या कमांड प्रॉम्प्ट खोलकर और निम्न कमांड दर्ज करके जांच सकते हैं कि पाइथन स्थापित है या नहीं:
python --versionचरण 2. निर्भरताएँ स्थापित करें
प्रोजेक्ट निर्भरताओं को प्रबंधित करने और अन्य पाइथन प्रोजेक्ट्स के साथ संघर्ष से बचने के लिए एक वर्चुअल वातावरण बनाने की सिफारिश की जाती है। टर्मिनल में प्रोजेक्ट निर्देशिका पर नेविगेट करें और google_lens नामक वर्चुअल वातावरण बनाने के लिए निम्न कमांड निष्पादित करें:
python -m venv google_financeअपने सिस्टम के आधार पर वर्चुअल वातावरण को सक्रिय करें:
- विंडोज़:
language
google_finance_env\Scripts\activate- MacOS/Linux:
language
source google_finance_env/bin/activateवर्चुअल वातावरण को सक्रिय करने के बाद, वेब स्क्रैपिंग के लिए आवश्यक पाइथन लाइब्रेरी स्थापित करें। पाइथन में अनुरोध भेजने के लिए लाइब्रेरी अनुरोध है, और डेटा को स्क्रैप करने के लिए मुख्य लाइब्रेरी BeautifulSoup4 है। निम्नलिखित कमांड का उपयोग करके उन्हें स्थापित करें:
language
pip install requests
pip install beautifulsoup4
pip install playwrightचरण 3. डेटा स्क्रैप करें
Google Finance से स्टॉक जानकारी निकालने के लिए, हमें पहले यह समझने की आवश्यकता है कि वांछित स्टॉक को स्क्रैप करने के लिए वेबसाइट के URL का उपयोग कैसे किया जाए। आइए नैस्डैक इंडेक्स को एक उदाहरण के रूप में लें, जिसमें कई स्टॉक हैं जिनसे हम जानकारी प्राप्त कर सकते हैं। प्रत्येक स्टॉक के प्रतीक तक पहुँचने के लिए, हम इस लिंक से नैस्डैक स्टॉक फ़िल्टर का उपयोग कर सकते हैं। अब आइए META को हमारे लक्षित स्टॉक के रूप में लक्षित करें। इंडेक्स और स्टॉक के साथ, हम स्क्रिप्ट का पहला स्निपेट बना सकते हैं।
हम वेबसाइट की गोपनीयता की दृढ़ता से रक्षा करते हैं। इस ब्लॉग में सभी डेटा सार्वजनिक हैं और केवल क्रॉलिंग प्रक्रिया के प्रदर्शन के रूप में उपयोग किए जाते हैं। हम कोई भी जानकारी और डेटा सहेजते नहीं हैं।
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"अब हम TARGET_URL पर HTTP अनुरोध करने के लिए अनुरोध लाइब्रेरी का उपयोग कर सकते हैं और HTML सामग्री को स्क्रैप करने के लिए एक सुंदर सूप उदाहरण बना सकते हैं।
language
एक HTTP अनुरोध करें
page = requests.get(TARGET_URL)# "page" से सामग्री प्राप्त करने के लिए एक HTML पार्सर का उपयोग करें
soup = BeautifulSoup(page.content, "html.parser")क्रॉलिंग शुरू करने से पहले, हमें पहले वेब पेज का निरीक्षण करके HTML तत्व (TARGET_URL) को संसाधित करने की आवश्यकता है।
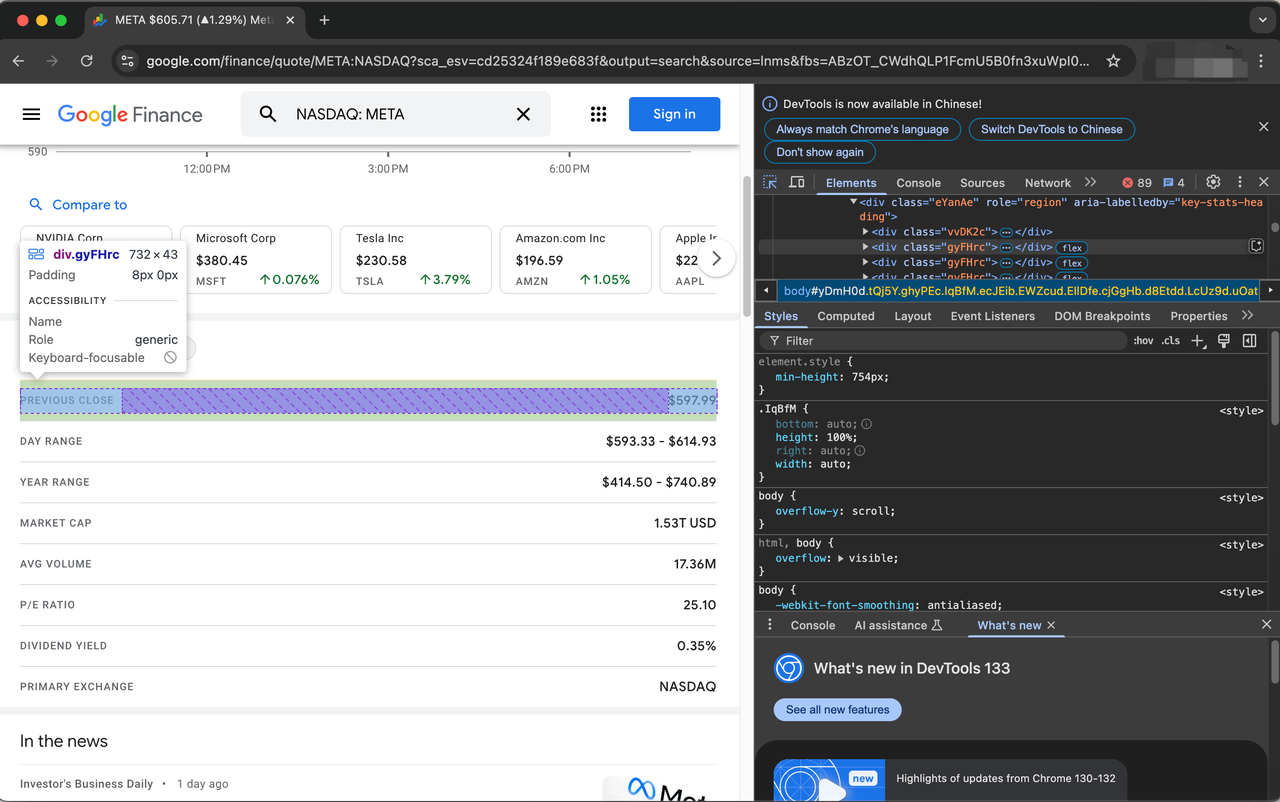
स्टॉक का वर्णन करने वाली वस्तुओं को वर्ग gyFHrc द्वारा दर्शाया गया है। प्रत्येक ऐसे तत्व के अंदर, एक वर्ग होता है जो आइटम के शीर्षक (जैसे "पिछला समापन मूल्य") और संबंधित मान (जैसे $597.99) का प्रतिनिधित्व करता है। शीर्षक mfs7Fc वर्ग से प्राप्त किया जा सकता है, जबकि मान P6K39c वर्ग से आता है।
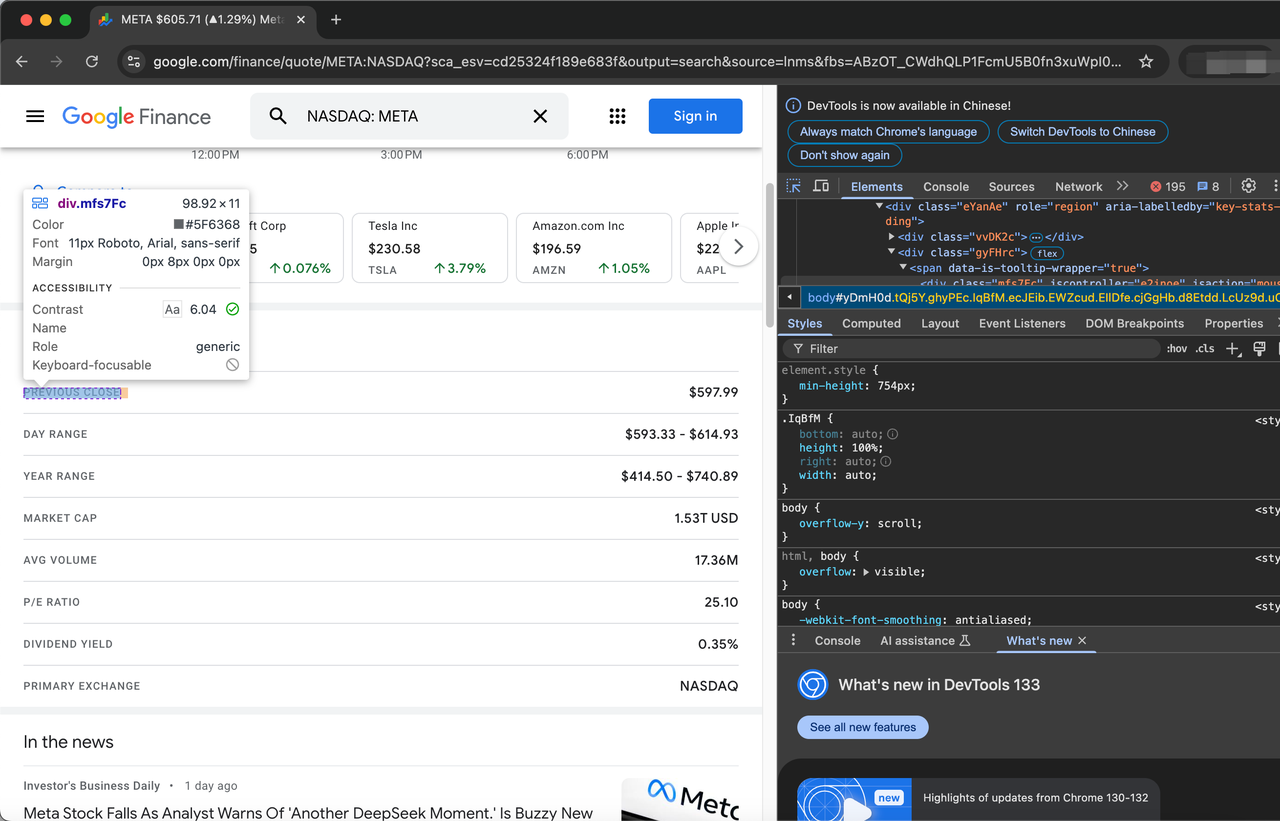
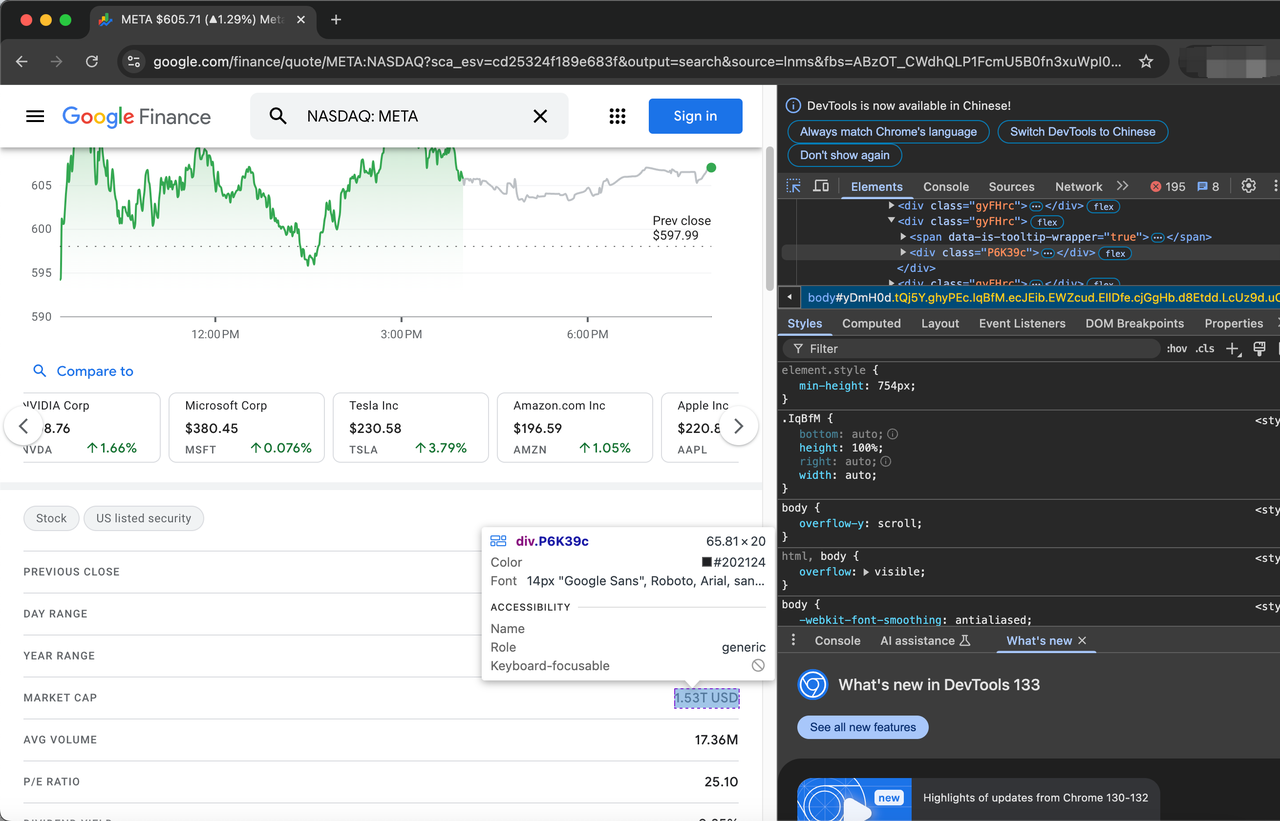
क्रॉल किए जाने वाले आइटमों की पूरी सूची इस प्रकार है:
- पिछला बंद
- दिन रेंज
- वर्ष रेंज
- बाजार पूंजीकरण
- औसत आयतन
- पी/ई अनुपात
- लाभांश उपज
- प्राथमिक एक्सचेंज
- सीईओ
- स्थापित
- वेबसाइट
- कर्मचारी
आइए देखें कि पाइथन कोड का उपयोग करके इन वस्तुओं को कैसे प्राप्त किया जाए।
# स्टॉक का वर्णन करने वाली वस्तुएँ प्राप्त करें
items = soup.find_all("div", {"class": "gyFHrc"})
# स्टॉक विवरण संग्रहीत करने के लिए एक शब्दकोश बनाएँ
stock_description = {}
# वस्तुओं पर पुनरावृति करें और उन्हें शब्दकोश में जोड़ें
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)यह एक साधारण स्क्रिप्ट का एक उदाहरण है जिसे आपके पसंदीदा स्टॉक को ट्रैक करने के लिए एक ट्रेडिंग बॉट, एप्लिकेशन या एक साधारण डैशबोर्ड में एकीकृत किया जा सकता है।
पूर्ण कोड
पृष्ठ से कई और डेटा विशेषताएँ हैं जिन्हें आप प्राप्त कर सकते हैं, लेकिन अभी के लिए, पूर्ण कोड कुछ इस तरह दिखता है।
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"# एक HTTP अनुरोध करें
page = requests.get(TARGET_URL)# "page" से सामग्री प्राप्त करने के लिए एक HTML पार्सर का उपयोग करें
soup = BeautifulSoup(page.content, "html.parser")# स्टॉक का वर्णन करने वाली वस्तुएँ प्राप्त करें
items = soup.find_all("div", {"class": "gyFHrc"})# स्टॉक विवरण संग्रहीत करने के लिए एक शब्दकोश बनाएँ
stock_description = {}# वस्तुओं पर पुनरावृति करें और उन्हें शब्दकोश में जोड़ेंfor item in items:
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_valueपरिणामों के कुछ उदाहरण इस प्रकार हैं:

Google Finance को स्क्रैप करते समय सीमाएँ
उपरोक्त विधि का उपयोग करके, आप एक छोटा स्क्रैपर बना सकते हैं, लेकिन यदि आप बड़े पैमाने पर स्क्रैपिंग करने जा रहे हैं, तो यह स्क्रैपर आपको डेटा प्रदान करना जारी नहीं रखेगा। Google डेटा स्क्रैपिंग को लेकर बहुत संवेदनशील है और अंततः आपके IP को ब्लॉक कर देगा।
एक बार आपका IP ब्लॉक हो जाने के बाद, आप कुछ भी स्क्रैप नहीं कर पाएँगे और आपकी डेटा पाइपलाइन अंततः टूट जाएगी। तो, इस समस्या को कैसे दूर करें? एक बहुत ही सरल समाधान है और वह है Google Finance स्क्रैपिंग API का उपयोग करना।
आइए देखें कि इस API का उपयोग करके Google Finance से असीमित डेटा कैसे स्क्रैप करें।
Scrapeless Google Finance स्क्रैपिंग API का उपयोग क्यों करें
डेटा गुणवत्ता और सटीकता
- उच्च-सटीकता डेटा: Scrapeless SerpApi हमेशा सटीक, विश्वसनीय और अद्यतित Google Finance डेटा प्रदान करता है, यह सुनिश्चित करता है कि उपयोगकर्ता सबसे प्रामाणिक और उपयोगी बाजार जानकारी प्राप्त कर सकें।
- वास्तविक समय के अपडेट: Google Finance पर नवीनतम डेटा वास्तविक समय में प्राप्त करने में सक्षम होना, जिसमें वास्तविक समय के शेयर कोटेशन, बाजार के रुझान आदि शामिल हैं, उन उपयोगकर्ताओं के लिए आवश्यक है जिन्हें समय पर निवेश निर्णय लेने की आवश्यकता है।
बहु-भाषा और स्थान समर्थन
- बहु-भाषा समर्थन: कई भाषाओं का समर्थन करता है, और उपयोगकर्ता अपनी आवश्यकताओं के अनुसार विभिन्न भाषाओं में वित्तीय डेटा प्राप्त कर सकते हैं ताकि दुनिया भर के विभिन्न क्षेत्रों में उपयोगकर्ताओं की आवश्यकताओं को पूरा किया जा सके।
- स्थान अनुकूलन: आप निर्दिष्ट भौगोलिक स्थानों, डिवाइस प्रकारों और अन्य मापदंडों के आधार पर अनुकूलित खोज परिणाम प्राप्त कर सकते हैं, जो विभिन्न क्षेत्रों में बाजार की स्थिति का विश्लेषण करने या स्थानीय बाजार अनुसंधान करने के लिए बहुत उपयोगी है।
प्रदर्शन और लागत लाभ
- सुपर तेज गति: केवल 1-2 सेकंड के औसत प्रतिक्रिया समय के साथ, Scrapeless SerpApi बाजार पर सबसे तेज़ खोज क्रॉलिंग API में से एक है, जो उपयोगकर्ताओं को आवश्यक डेटा जल्दी से प्रदान कर सकता है।
- लागत प्रभावी: Scrapeless SerpApi प्रति हजार क्वेरी केवल $0.1 पर Google खोज API प्रदान करता है। यह मूल्य निर्धारण मॉडल बड़े पैमाने पर डेटा स्क्रैपिंग परियोजनाओं के लिए बहुत ही लागत प्रभावी है।
एकीकरण - आसान एकीकरण: Scrapeless SerpApi विभिन्न लोकप्रिय प्रोग्रामिंग भाषाओं (जैसे पाइथन, Node.js, Golang, आदि) के साथ एकीकरण का समर्थन करता है, और उपयोगकर्ता इसे अपने स्वयं के अनुप्रयोगों या विश्लेषण उपकरणों में आसानी से एम्बेड कर सकते हैं।
स्थिरता और विश्वसनीयता - उच्च उपलब्धता: Scrapeless SerpApi में उच्च सेवा उपलब्धता और स्थिरता है, जो लंबी अवधि और उच्च आवृत्ति डेटा स्क्रैपिंग के दौरान उपयोगकर्ताओं को निर्बाध सेवा सुनिश्चित कर सकती है।
- पेशेवर समर्थन: Scrapeless SerpApi उपयोग के दौरान सामने आने वाली समस्याओं को हल करने में उपयोगकर्ताओं की मदद करने के लिए पेशेवर तकनीकी सहायता और ग्राहक सेवा प्रदान करता है और यह सुनिश्चित करता है कि उपयोगकर्ता डेटा को सुचारू रूप से प्राप्त और उपयोग कर सकें।
Scrapeless के साथ Google Finance डेटा को कैसे स्क्रैप करें
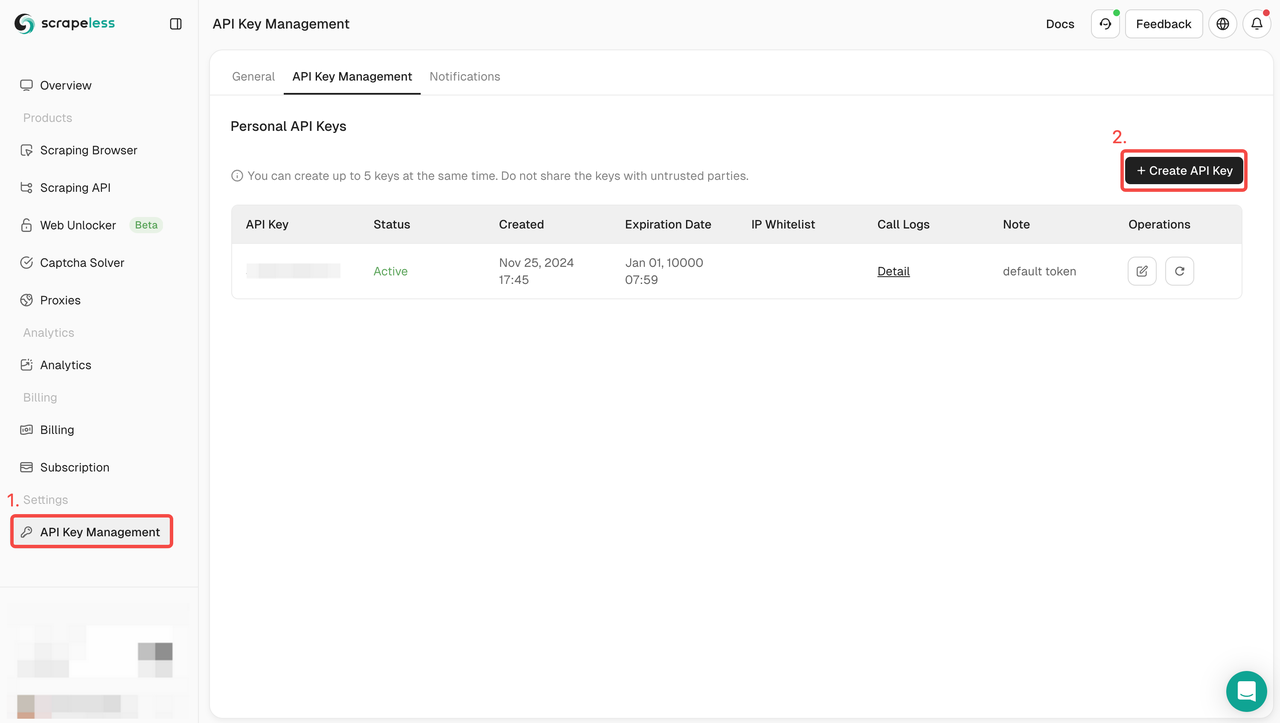
चरण 1: Scrapeless के लिए साइन अप करें और एक API कुंजी प्राप्त करें
- यदि आपके पास अभी तक Scrapeless खाता नहीं है, तो Scrapeless वेबसाइट पर जाएँ और साइन अप करें। आप 20,000 मुफ़्त खोज क्वेरी प्राप्त कर सकते हैं।
- साइन अप करने के बाद, अपने डैशबोर्ड में लॉग इन करें।
- डैशबोर्ड में, API कुंजी प्रबंधन पर नेविगेट करें और API कुंजी बनाएँ पर क्लिक करें। उत्पन्न API कुंजी की प्रतिलिपि बनाएँ, जो Scrapeless API को कॉल करते समय आपकी प्रमाणीकरण क्रेडेंशियल होगी।
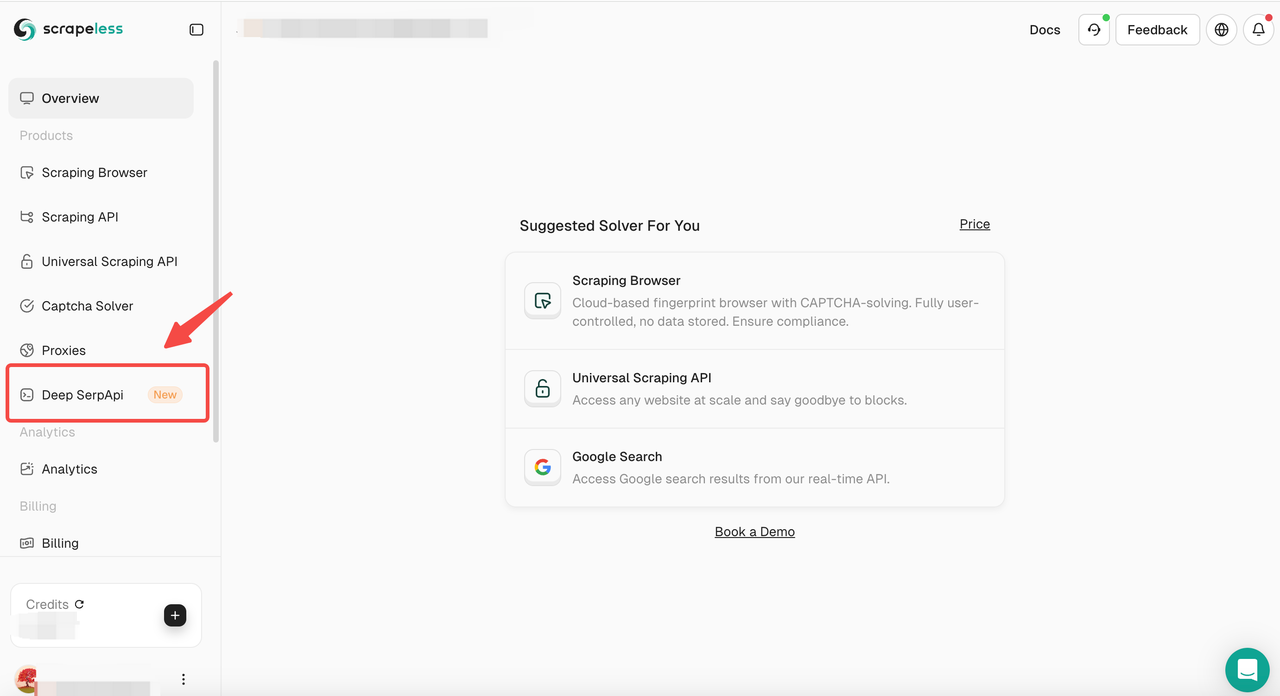
चरण 2: Deep SerpApi प्लेग्राउंड तक पहुँचें
- फिर "Deep SerpApi" अनुभाग पर जाएँ।
चरण 3: खोज पैरामीटर सेट करें
- प्लेग्राउंड में, अपना खोज कीवर्ड दर्ज करें, जैसे "GOOGL:NASDAQ"।
- अन्य पैरामीटर सेट करें, जैसे क्वेरी शब्द, भाषा, समय आदि।
Google Finance के मापदंडों के बारे में जानने के लिए आप Scrapeless के आधिकारिक API दस्तावेज़ को देखने के लिए भी क्लिक कर सकते हैं।
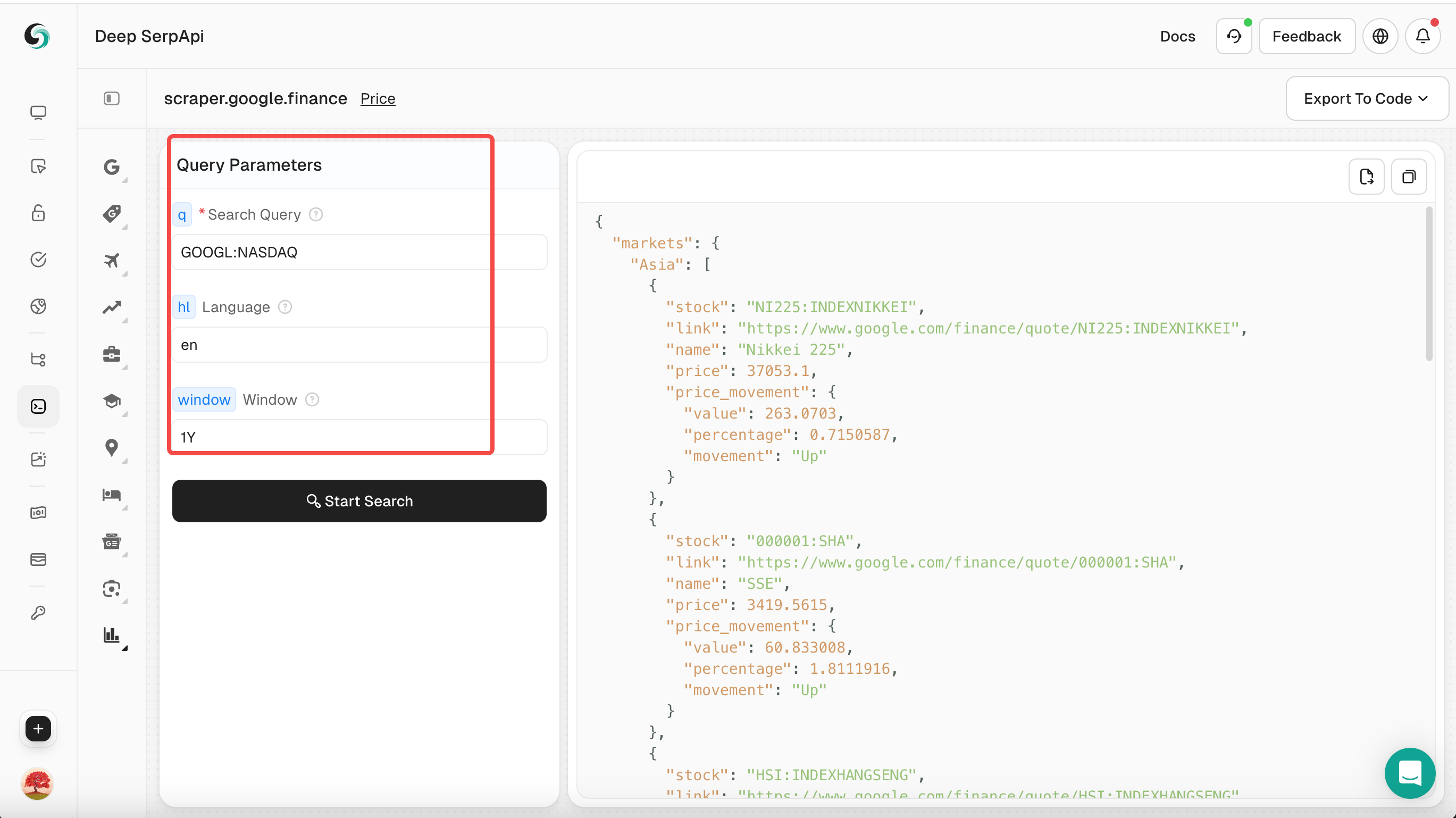
चरण 4: खोज करें
- "खोज प्रारंभ करें" बटन पर क्लिक करें, और प्लेग्राउंड Deep Serp API को एक अनुरोध भेजेगा और संरचित JSON डेटा लौटाएगा।
चरण 5: डेटा देखें और निर्यात करें
- विस्तृत जानकारी देखने के लिए लौटाए गए JSON डेटा को ब्राउज़ करें।
- यदि आवश्यक हो, तो आप आगे के विश्लेषण के लिए डेटा को CSV या JSON प्रारूप में निर्यात करने के लिए ऊपरी दाएँ कोने में "प्रतिलिपि बनाएँ" पर क्लिक कर सकते हैं।
मुफ़्त डेवलपर सहायता:
अपने AI टूल, एप्लिकेशन या प्रोजेक्ट में Scrapeless Deep SerpApi को एकीकृत करें (हम पहले ही Dify का समर्थन करते हैं, और भविष्य में Langchain, Langflow, FlowiseAI और अन्य फ्रेमवर्क का समर्थन करेंगे)।
सोशल मीडिया पर अपने एकीकरण परिणाम साझा करें और आपको प्रति माह 500K उपयोग तक, 1 से 12 महीने की मुफ़्त डेवलपर सहायता मिलेगी।
अपनी परियोजना को बेहतर बनाने और अधिक विकास सहायता का आनंद लेने के इस अवसर को जब्त करें! अधिक जानकारी के लिए आप Liam से Discord के माध्यम से भी संपर्क कर सकते हैं।
Scrapeless API को कैसे एकीकृत करें
Scrapeless API का उपयोग करके Google Finance परिणामों को स्क्रैप करने के लिए यहाँ नमूना कोड दिया गया है:
language
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "आपकी api कुंजी"
headers = {
"x-api-token": token
}
input_data = {
"q": "GOOG:NASDAQ",
"window": "MAX",
.....
}
payload = Payload("scraper.google.finance", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("त्रुटि:", response.status_code, response.text)
return
print("बॉडी", response.text)
if __name__ == "__main__":
send_request()अधिक सटीक परिणाम प्राप्त करने के लिए आवश्यकतानुसार क्वेरी पैरामीटर समायोजित करें। API पैरामीटर के बारे में अधिक जानकारी के लिए, आप Scrapeless आधिकारिक API दस्तावेज़ देख सकते हैं
आपको अपनी कॉपी की गई API कुंजी के साथ YOUR-API-KEY को बदलना होगा।
अतिरिक्त संसाधन
पाइथन के साथ Google समाचार कैसे स्क्रैप करें
Puppeteer के साथ Cloudflare को कैसे बायपास करें
Scrapeless के साथ Google Lens परिणाम कैसे स्क्रैप करें
निष्कर्ष
निष्कर्ष में, पाइथन में Google Finance टिकर कोट डेटा को स्क्रैप करना वास्तविक समय की वित्तीय जानकारी तक पहुँचने के लिए एक शक्तिशाली तकनीक है। अनुरोध और BeautifulSoup जैसी लाइब्रेरी, या सेलेनियम जैसे अधिक उन्नत उपकरणों का उपयोग करके, आप अपने निवेश निर्णयों को सूचित करने के लिए बाजार डेटा को कुशलतापूर्वक निकाल और विश्लेषण कर सकते हैं। वेबसाइट की सेवा की शर्तों का सम्मान करना याद रखें और टिकाऊ डेटा तक पहुँच के लिए उपलब्ध होने पर आधिकारिक API का उपयोग करने पर विचार करें।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


