
MCP-RAG सर्वर: संपूर्ण सेटअप और उपयोग मार्गदर्शिका
Advanced Data Extraction Specialist
AI अनुप्रयोगों के तेजी से विकसित हो रहे युग में, ऐसे सिस्टम की आवश्यकता कभी भी इतनी अधिक नहीं रही है जो स्थिर डोमेन ज्ञान को वास्तविक समय की वेब जानकारी के साथ संयोजित कर सकें। पारंपरिक पुनर्प्राप्ति-संवर्धित उत्पादन (RAG) मॉडल अक्सर पूर्व-निर्धारित डेटा पर निर्भर करते हैं, जो उन्हें नए विकास की प्रतिक्रिया देने में सीमित करता है। MCP-RAG सर्वर इस अंतर को पाटता है जिससे यह अर्थमय वेक्टर खोज (Qdrant के माध्यम से) को वास्तविक समय की वेब खोज क्षमताओं (Scrapeless के माध्यम से) के साथ एकीकृत करता है, जो बुद्धिमान प्रश्न उत्तर प्रणाली के लिए एक उत्पादन-तैयार नींव प्रदान करता है। चाहे आप एक उद्यम हो जो आंतरिक ज्ञान एजेंट का निर्माण कर रहा हो या एक डेवलपर हो जो LLM एकीकरण के साथ प्रयोग कर रहा हो, यह गाइड आपको MCP-RAG की पूर्ण सेटअप और उपयोग के माध्यम से मार्गदर्शन करेगी—यह सुनिश्चित करते हुए कि आप एक आधुनिक, प्रतिक्रियाशील AI ज्ञान प्रणाली को तैनात करने के लिए सक्षम हैं।
MCP-RAG सर्वर क्या है?
MCP-RAG सर्वर एक TypeScript-आधारित सिस्टम है जो वेक्टर खोज क्षमताओं को वास्तविक समय की वेब खोज के साथ संयोजित करके एक उन्नत AI ज्ञान प्रणाली बनाता है। यह तीन मुख्य उपकरण प्रदान करता है:
- मशीन लर्निंग FAQ पुनर्प्राप्ति - आपके वेक्टर डेटाबेस के माध्यम से सिमेंटिक खोज
- दस्तावेज़ जोड़ना - नई जानकारी के साथ अपने ज्ञान आधार का विस्तार करें
- वेब खोज - इंटरनेट से वर्तमान जानकारी प्राप्त करें
यह सिस्टम महत्वपूर्ण AI सीमाओं को हल करता है: पुराने ज्ञान, डोमेन विशेषज्ञता की कमी, और असमर्थन जानकारी पुनर्प्राप्ति।
Scrapeless परिचय: RAG का वेब बुद्धिमान संवर्धन इंजन
Scrapeless गूगल सर्च स्क्रैपिंग एपीआई एक शक्तिशाली वेब स्क्रैपिंग एपीआई है जो बिना पारंपरिक क्रॉलर द्वारा ब्लॉक होने के जोखिम के बिना खोज इंजन परिणामों तक स्थिर पहुँच प्रदान करता है।
RAG सिस्टम के लिए Scrapeless क्यों आवश्यक है
पारंपरिक RAG सिस्टम अपने स्थिर ज्ञान आधार द्वारा सीमित होते हैं। Scrapeless MCP-RAG सर्वर को निम्नलिखित तरीके से परिवर्तित करता है:
- वास्तविक समय की जानकारी पुनर्प्राप्ति: वेब से नवीनतम जानकारी की पहुँच
- ज्ञान आधार संवर्धन: वर्तमान डेटा के साथ अपने वेक्टर डेटाबेस को लगातार अपडेट करें
- पूरक खोज: जब आंतरिक ज्ञान अपर्याप्त हो तो अंतर भरें
- विविध दृष्टिकोण: विभिन्न भौगोलिक क्षेत्रों और भाषाओं से खोजें
Scrapeless MCP-RAG में कैसे काम करता है?
Scrapeless MCP-RAG सर्वर के साथ एक TypeScript एनकैप्सुलेशन क्लास ScrapelessClient के माध्यम से एकीकृत होता है ताकि निम्नलिखित क्षमताएँ प्राप्त की जा सकें:
export class ScrapelessClient {
private api: AxiosInstance;
constructor(config: ScrapelessConfig) {
this.api = axios.create({
baseURL: config.baseURL,
headers: {
"Content-Type": "application/json",
"x-api-token": config.token,
},
});
}
async searchWeb(params: WebSearchParams) {
try {
const response = await this.api.post("/api/v1/scraper/request", {
actor: "scraper.google.search",
input: {
q: params.query,
gl: params.country || "us",
hl: params.language || "en",
google_domain: params.domain || "google.com"
}
});
return {
query: params.query,
results: response.data
};
} catch (error) {
// त्रुटि प्रबंधन...
}
}
}समर्थित उन्नत सुविधाएँ
| सुविधा | विवरण |
|---|---|
| गूगल सर्च एकीकरण | खोज परिणाम प्राप्त करने के लिए scraper.google.search अभिनेता का उपयोग करता है |
| भू-निर्देशन | gl पैरामीटर का उपयोग करके देश/क्षेत्र को नियंत्रित करता है |
| बहुभाषी समर्थन | hl पैरामीटर का उपयोग करके विभिन्न भाषाओं में परिणामों को लौटाता है |
| खोज इंजन डोमेन स्विचिंग | google.de, google.fr आदि जैसे कई डोमेन का समर्थन करता है |
| प्रॉक्सी ऑटो-प्रबंधन | आईपी ब्लॉकिंग से बचने के लिए डिफ़ॉल्ट रूप से प्रॉक्सी रोटेशन सक्षम करता है |
बुद्धिमान प्रश्न उत्तर प्रणाली तैनाती गाइड (वेक्टर खोज + वास्तविक समय की वेब खोज आधारित)
चरण 1: प्रोजेक्ट संरचना को आरंभ करें और निर्भरताएँ स्थापित करें
प्रोजेक्ट को क्लोन करें और सेटअप करें:
git clone git@github.com:scrapeless-ai/mcp-rag-server.git
cd mcp-rag-serverप्रोजेक्ट संरचना का विश्लेषण करें:
mcp-rag-server/
├── src/
│ ├── config.ts
│ ├── index.ts
│ ├── server.ts
│ ├── qdrant-client.ts
│ └── scrapeless-client.ts
├── package.json
├── tsconfig.json
└── .envनिर्भरताएँ स्थापित करें:
npm install💡समस्या हल हुई:
यह सुनिश्चित करें कि TypeScript परियोजना वातावरण तैयार है, आवश्यक निर्भरताएँ (जैसे @modelcontextprotocol/sdk, axios, zod, आदि) एकीकृत की गई हैं, और विकास के लिए आवश्यक प्रकार की परिभाषाएँ भी स्वचालित रूप से कॉन्फ़िगर की गई हैं।
चरण 2: पर्यावरण कॉन्फ़िगरेशन
`.env` फ़ाइल बनाएँ:
QDRANT_URL=http://localhost:6333
QDRANT_API_KEY=
QDRANT_COLLECTION=ml_faq_collection
SCRAPELESS_KEY=आपकी_scrapeless_api_key
SCRAPELESS_BASE_URL=https://api.scrapeless.com
कॉन्फ़िगरेशन को समझना (config.ts से):
const QDRANT_URL = process.env.QDRANT_URL?.trim() || "http://localhost:6333";
const QDRANT_API_KEY = process.env.QDRANT_API_KEY?.trim() || "";
const QDRANT_COLLECTION = process.env.QDRANT_COLLECTION?.trim() || "ml_faq_collection";
const SCRAPELESS_KEY = process.env.SCRAPELESS_KEY?.trim();
const SCRAPELESS_BASE_URL = process.env.SCRAPELESS_BASE_URL?.trim() || "https://api.scrapeless.com";
**💡समस्या का समाधान:**
बाह्य निर्भरताओं (Qdrant वेक्टर डेटाबेस और Scrapeless रीयल-टाइम खोज) के लिए सही कनेक्शन पैरामीटर प्रदान करें। डिफ़ॉल्ट मान और trim() प्रोसेसिंग को कॉन्फ़िगरेशन कोड में एकीकृत किया गया है ताकि वेरिएबल फ़ॉर्मेट में त्रुटियाँ न हों। यदि Scrapeless Key अनुपस्थित है, तो एक चेतावनी जारी की जाएगी।
### चरण 3: Qdrant वेक्टर डेटाबेस सेट करें
**Docker के साथ Qdrant शुरू करें:**Qdrant छवि खींचें
docker pull qdrant/qdrant
डेटा पवित्रता के साथ Qdrant कंटेनर चलाएं
docker run -d
--name qdrant-server
-p 6333:6333
-p 6334:6334
-v $(pwd)/qdrant_storage:/qdrant/storage
qdrant/qdrant
**एक FAQ वेक्टर संग्रह बनाएं:**curl -X PUT 'http://localhost:6333/collections/ml_faq_collection'
-H 'Content-Type: application/json'
--data-raw '{
"vectors": {
"size": 1536,
"distance": "Cosine"
}
}'
**💡समस्या का समाधान:**
चेतना वेक्टर पुनर्प्राप्ति भंडारण को कॉन्फ़िगर करें, 1536 आयामों और कोसाइन समानता का उपयोग करें, और एम्बेडिंग जेनरेटर आउटपुट और QdrantClient कॉल के साथ संगत रहें।
### चरण 4: Scrapeless रीयल-टाइम वेब खोज को एकीकृत करें
**Scrapeless API Key प्राप्त करना:**
1. [Scrapeless](https://app.scrapeless.com/passport/login?utm_source=official&utm_medium=blog&utm_campaign=mcprag) पर जाएँ और एक खाता बनायें।
2. डैशबोर्ड से अपना API Token प्राप्त करें।
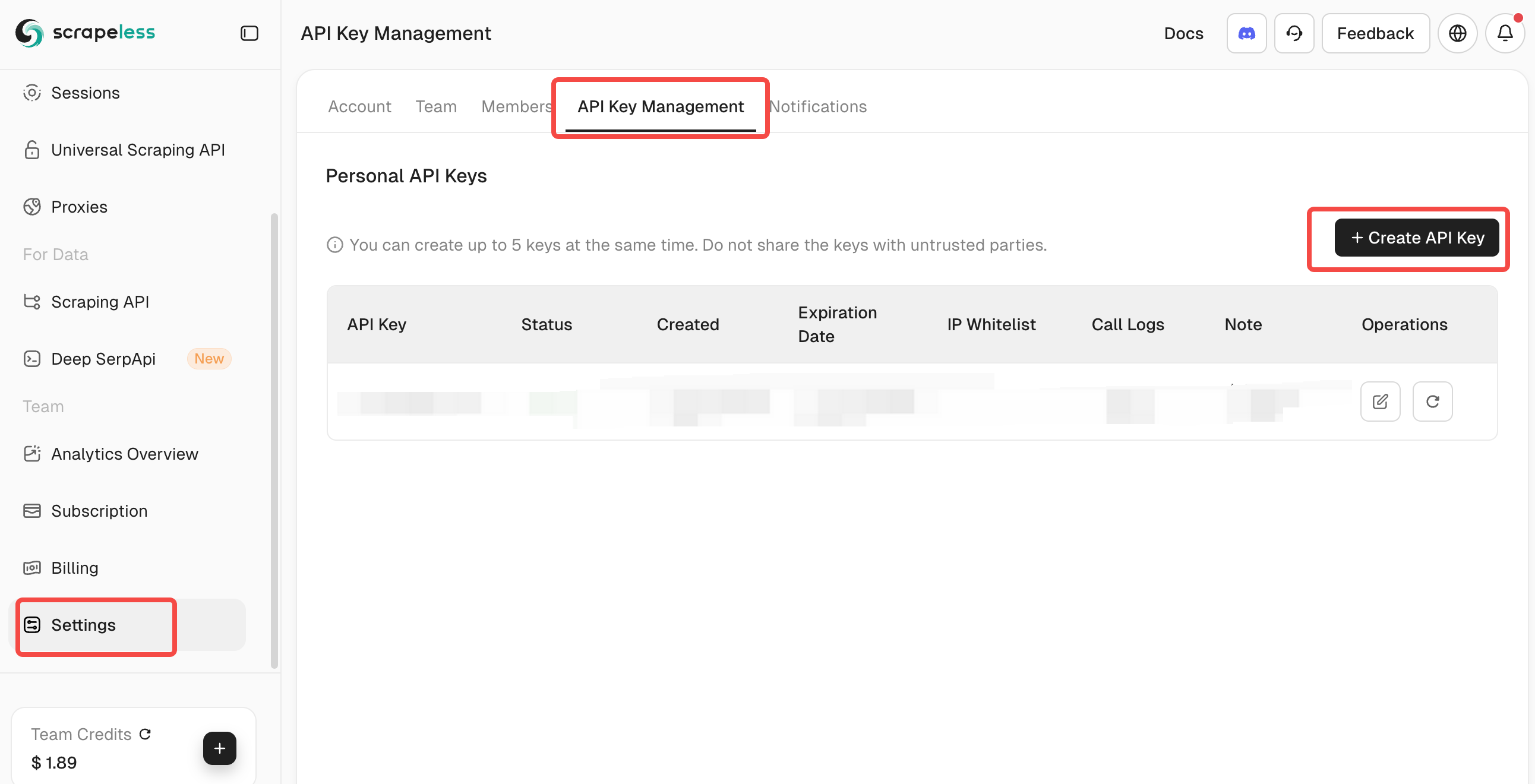
3. इसे .env फ़ाइल में SCRAPELESS_KEY के अंतर्गत जोड़ें।
**Scrapeless कनेक्शन का परीक्षण करें:**API कनेक्शन का परीक्षण करें (वैकल्पिक)
curl -X POST 'https://api.scrapeless.com/api/v1/scraper/request'
-H 'Content-Type: application/json'
-H 'x-api-token: YOUR_API_KEY'
-d '{"actor": "scraper.google.search", "input": {"q": "test query"}}'
समस्या का समाधान: यह कदम सुनिश्चित करता है कि आपका Scrapeless API ठीक से कॉन्फ़िगर किया गया है। सिस्टम में एपीआई कुंजी सेट होने की पुष्टि के लिए मान्यता शामिल है, जो वेब खोजों के दौरान रनटाइम त्रुटियों को रोकती है।
### चरण 5: TypeScript प्रोजेक्ट बनाएं
TypeScript को JavaScript में संकलित करें:npm run build
निर्माण के दौरान क्या होता है (package.json से):
```language
{
"scripts": {
"build": "tsc && chmod 755 build/index.js",
"start": "node build/index.js"
}
}निर्माण आउटपुट को सत्यापित करें:
language
ls build/
# दिखाना चाहिए: index.js, server.js, config.js, qdrant-client.js, scrapeless-client.jsसमस्या का समाधान:
यह कदम TypeScript को JavaScript में संकलित करता है और सुनिश्चित करता है कि मुख्य प्रवेश बिंदु निष्पादन योग्य हो। निर्माण प्रक्रिया ES मॉड्यूल के आउटपुट देती है (जैसा कि package.json में "type": "module" द्वारा निर्दिष्ट है) Node.js के साथ संगत है।
चरण 6: MCP सर्वर शुरू करें
language
सर्वर चलाएँ:
npm startस्टार्टअप के दौरान क्या होता है (index.ts से):
async function main() {
try {
console.log("MCP एजेंटिक राग सर्वर शुरू हो रहा है...");
const transport = new StdioServerTransport();
await server.connect(transport);
console.log("MCP सर्वर पोर्ट 8080 पर चल रहा है");
} catch (error) {
console.error("मुख्य(): एक घातक त्रुटि:", error);
process.exit(1);
}
}समस्या का समाधान:
यह कदम STDIO परिवहन का उपयोग करके MCP सर्वर को प्रारंभ करता है। सर्वर उचित त्रुटि प्रबंधन और लॉगिंग के साथ प्रारंभ होता है।
ऊपर दिए गए छह चरणों का पालन करने से, आप एक एआई-संचालित प्रश्न-उत्तर प्रणाली का निर्माण करेंगे जिसमें:
- समांतर QA क्षमताएँ (Qdrant वेक्टर डेटाबेस द्वारा संचालित)
- रीयल-टाइम वेब संवर्धन (Scrapeless API एकीकरण द्वारा)
- LLM-तैयार आधारभूत संरचना (MCP प्रोटोकॉल मानक पर आधारित)
यह उद्यमों या डेवलपर्स के लिए उत्पादन-सिद्ध RAG (Retrieval-Augmented Generation) प्रणाली को जल्दी से तैनात करने के लिए एक ठोस आधार तैयार करता है।
मूल तत्वों का विस्तृत विवरण
QdrantClient: वेक्टर प्रसंस्करण इंजन
QdrantClient एम्बेडिंग उत्पादन और वेक्टर डेटाबेस इंटरैक्शन कार्य प्रदान करता है। उदाहरण में प्रदर्शन के लिए एक सरल निरपेक्ष एम्बेडिंग विधि का उपयोग किया गया है:
private generateEmbedding(text: string): number[] {
const seed = [...text].reduce((sum, char) => sum + char.charCodeAt(0), 0) % 10000;
const vector: number[] = [];
let value = seed;
for (let i = 0; i < 1536; i++) {
value = (value * 48271) % 2147483647;
vector.push((value / 2147483647) * 2 - 1);
}
return vector;
}मुख्य विशेषताएँ:
- सरल निरपेक्ष एम्बेडिंग उत्पादन
- दस्तावेज़ जोड़ने के लिए अपसर्ट संचालन
- कॉन्फ़िगर करने योग्य स्कोरिंग थ्रेशोल्ड के साथ समांतर खोज
- उचित त्रुटि हैंडलिंग और बैकअप प्रतिक्रियाएँ
ScrapelessClient: वेब खोज इंजन इंटरफेस
ScrapelessClient Scrapeless API का उपयोग करके वेब खोज को लागू करता है और उन्नत खोज पैरामीटर का समर्थन करता है:
async searchWeb(params: WebSearchParams) {
try {
if (!this.api.defaults.headers.common["x-api-token"]) {
throw new Error("Scrapeless API कुंजी सेट नहीं की गई है");
}
const response = await this.api.post("/api/v1/scraper/request", {
actor: "scraper.google.search",
input: {
q: params.query,
gl: params.country || "us",
hl: params.language || "en",
google_domain: params.domain || "google.com"
}
});
return {
query: params.query,
results: response.data
};
} catch (error) {
// त्रुटि हैंडलिंग...
}
}मुख्य विशेषताएँ:
- Scrapeless के माध्यम से Google खोज एकीकरण
- कॉन्फ़िगर करने योग्य देश, भाषा, और डोमेन
- शामिल त्रुटि हैंडलिंग
- API कुंजी प्रमाणीकरण
MCP सर्वर उपकरण
server.ts फ़ाइल तीन मुख्य उपकरणों को परिभाषित करती है:
- मशीन-लर्निंग-FAQ-रिक्ति:
- ML अवधारणाओं के लिए वेक्टर डेटाबेस में खोजें
- अर्थ संबंधी समानता मिलान का उपयोग करें
- स्कोर के साथ स्वरूपित परिणाम लौटाएं
- FAQ में दस्तावेज़ जोड़ें:
- ज्ञान आधार में नए दस्तावेज़ जोड़ें
- मेटाडेटा का समर्थन करता है (श्रेणी, स्रोत, टैग)
- विस्तृत प्रतिक्रियाओं के साथ उचित त्रुटि हैंडलिंग
- scrapeless-web-search:
- Scrapeless API के माध्यम से वेब खोजें
- कॉन्फ़िगर करने योग्य खोज पैरामीटर
- रीयल-टाइम जानकारी पुनर्प्राप्ति
उपयोग गाइड: Scrapeless के साथ प्रणाली का उपयोग करना
बुनियादी उपयोग के उदाहरण
ज्ञान आधार में खोजें:
मशीन-लर्निंग-FAQ-रिक्ति का उपयोग करें ताकि न्यूरल नेटवर्क के बारे में जानकारी मिल सकेनई जानकारी जोड़ें:
FAQ में दस्तावेज़ जोड़ने का उपयोग करें ताकि इसे जोड़ा जा सके:
पाठ: "रैंडम फॉरेस्ट एन्सेम्बल लर्निंग विधियाँ हैं..."
श्रेणी: "एन्सेम्बल विधियाँ"
टैग: ["रैंडम फॉरेस्ट", "एन्सेम्बल लर्निंग"]Scrapeless के साथ वेब खोजें:
language
scrapeless-web-search का उपयोग करें ताकि AI में हालिया विकास खोज सकेंउन्नत Scrapeless उपयोग:
language
scrapeless-web-search का उपयोग करें:
प्रश्न: "लेटेस्ट PyTorch विशेषताएँ"
देश: "uk"
भाषा: "en"
डोमेन: "google.co.uk"Scrapeless एकीकरण के साथ उन्नत वर्कफ़्लो
ज्ञान आधार वृद्धि:
1. "लेटेस्ट ट्रांसफार्मर मॉडल 2024" खोजने के लिए scrapeless-web-search का उपयोग करें
2. प्रासंगिक निष्कर्ष जोड़ने के लिए add-document-to-faq का उपयोग करें
3. सत्यापित करने के लिए मशीन-लर्निंग-FAQ-रिक्ति का उपयोग करें कि जानकारी खोजने योग्य हैजानकारी सत्यापन:
1. मौजूदा ज्ञान की जांच के लिए मशीन-लर्निंग-FAQ-रिक्ति का उपयोग करें
2. वर्तमान जानकारी खोजने के लिए scrapeless-web-search का उपयोग करें
3. तुलना करें और ज्ञान आधार को तदनुसार अपडेट करेंबहुभाषी ज्ञान निर्माण:
1. जर्मन AI अनुसंधान खोजने के लिए country="de" और language="de" के साथ scrapeless-web-search का उपयोग करें
2. अनुवादित सारांश जोड़ने के लिए add-document-to-faq का उपयोग करें
3. एक बहुभाषी ज्ञान आधार बनाएँClaude डेस्कटॉप के साथ एकीकरण
परियोजना में Claude डेस्कटॉप एकीकरण के लिए एक नमूना कॉन्फ़िगरेशन शामिल है:
{
"mcpServers": {
"MCP-RAG-app": {
"command": "node",
"args": ["your-path/to/build/index.js"],
"host": "127.0.0.1",
"port": 8080,
"timeout": 30000,
"env": {
"QDRANT_URL": "http://localhost:6333",
"QDRANT_API_KEY": "",
"QDRANT_COLLECTION": "ml_faq_collection",
"SCRAPELESS_KEY": "SCRAPELESS_KEY"
}
}
}
}सामान्य समस्याएँ और समाधान
- निर्माण की त्रुटियाँ:
- सुनिश्चित करें कि Node.js संस्करण >= 18 है
- TypeScript संकलन की जांच करें: npx tsc --noEmit
- रनटाइम त्रुटियाँ:
- जांचें कि Qdrant चल रहा है: curl http://localhost:6333/health
- जांचें कि पर्यावरण चर ठीक से सेट हैं
- सुनिश्चित करें कि Scrapeless API कुंजी मान्य है
- Scrapeless-विशिष्ट मुद्दे:
- सुनिश्चित करें कि API कुंजी पर्यावरण में सही ढंग से सेट है
- Scrapeless डैशबोर्ड में API कोटा और सीमा की जांच करें
- सही API अंत बिंदु कॉन्फ़िगरेशन सुनिश्चित करें
- कनेक्शन मुद्दे:
- जांचें कि पोर्ट उपलब्ध हैं (Qdrant के लिए 6333)
- फ़ायरवॉल सेटिंग्स की जांच करें
- सुनिश्चित करें कि Docker कंटेनर चल रहे हैं
संयुक्त प्रणाली के लाभ
Scrapeless का Qdrant के साथ एकीकरण एक शक्तिशाली हाइब्रिड प्रणाली बनाता है:
- स्थैतिक + गतिशील ज्ञान: अपने संग्रहीत ज्ञान आधार को रीयल-टाइम वेब डेटा के साथ संयोजित करें
- बुद्धिमान खोज: आंतरिक डेटा के लिए अर्थ संबंधी खोज का उपयोग करें और वेब सामग्री के लिए कीवर्ड खोज
- निरंतर वृद्धि: ताजे जानकारी के साथ अपने ज्ञान आधार को स्वचालित रूप से अपडेट करें
- वैश्विक दृष्टिकोण: विभिन्न क्षेत्रों और भाषाओं की जानकारी प्राप्त करें
- विश्वसनीयता: Scrapeless बिना ब्लॉकिंग समस्याओं के लगातार वेब पहुंच सुनिश्चित करता है
निष्कर्ष
MCP-RAG सर्वर और Scrapeless एक उच्च स्केलेबल, वास्तविक समय में अपडेट होने वाली बुद्धिमान प्रश्न-उत्तर प्रणाली को लागू करते हैं। इसकी मुख्य मान्यताएँ शामिल हैं:
- अर्थ संबंधी समझ: वेक्टर समानता के माध्यम से संदर्भ को समझना
- वास्तविक समय की जानकारी पहुंच: Scrapeless का उपयोग करके नवीनतम वेब सामग्री प्राप्त करना
- मानक प्रोटोकॉल एकीकरण: MCP प्रोटोकॉल का उपयोग करके, प्लेटफार्मों से कनेक्ट करना जैसे Claude आसान है
- लचीला कॉन्फ़िगरेशन: अनुकूलन योग्य ज्ञान आधार संग्रह और खोज उपकरण
- भविष्य-केंद्रित बुद्धिमान मंच: गतिशील ज्ञान संवर्धन, बहुभाषा समर्थन और वेब बुद्धिमान क्रॉलिंग का समर्थन करें।
Scrapeless के जुड़ने से प्रणाली अब केवल एक स्थिर ज्ञान आधार नहीं रह गई है, बल्कि एक वैश्विक दृष्टिकोण और निरंतर सीखने की क्षमताओं के साथ एक एआई ज्ञान इंजन बन गई है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


