
स्क्रैपलेस और ब्राउज़र उपयोग को सबसे अच्छा कैसे लागू करें?
Senior Web Scraping Engineer
स्क्रैपिंग ब्राउज़र दैनिक डेटा निष्कर्षण और स्वचालन कार्यों के लिए एक प्रतिष्ठित उपकरण बन गया है। ब्राउज़र-यूज़ को स्क्रैपलेस स्क्रैपिंग ब्राउज़र के साथ एकीकृत करके, आप ब्राउज़र स्वचालन सीमाओं को पार कर सकते हैं और अवरोधों से बच सकते हैं।
इस लेख में, हम ब्राउज़र-यूज़ और स्क्रैपलेस स्क्रैपिंग ब्राउज़र का उपयोग करके एक स्वचालित एआई एजेंट उपकरण बनाएंगे जो स्वचालित डेटा स्क्रैपिंग करेगा। आप देखेंगे कि यह आपके समय और प्रयास की कैसे बचत करता है, जिससे स्वचालन कार्यों को आसान बनाता है!
आप सीखेंगे:
- ब्राउज़र-यूज़ क्या है, और यह एआई एजेंटों के निर्माण में कैसे मदद करता है?
- स्क्रैपिंग ब्राउज़र ब्राउज़र-यूज़ की सीमाओं को प्रभावी ढंग से कैसे पार कर सकता है?
- ब्राउज़र-यूज़ और स्क्रैपिंग ब्राउज़र का उपयोग करके एक ब्लॉक-फ्री एआई एजेंट कैसे बनाया जाए?
ब्राउज़र-यूज़ क्या है?
ब्राउज़र-यूज़ एक पायथन-आधारित एआई ब्राउज़र स्वचालन पुस्तकालय है, जिसे एआई एजेंटों को उन्नत ब्राउज़र स्वचालन क्षमताओं के साथ सशक्त बनाने के लिए डिज़ाइन किया गया है। यह एक वेबपेज पर सभी इंटरएक्टिव तत्वों को पहचान सकता है और एजेंटों को पृष्ठ के साथ कार्यक्रमात्मक रूप से बातचीत करने की अनुमति देता है—सामान्य कार्य जैसे खोज, क्लिक करना, फॉर्म भरना और डेटा स्क्रैपिंग करना। अपने मूल में, ब्राउज़र-यूज़ वेबसाइटों को संरचित पाठ में बदल देता है और प्ले राइट जैसे ब्राउज़र ढांचे का समर्थन करता है, जिससे वेब इंटरैक्शनों को बहुत सरल बनाता है।
पारंपरिक स्वचालन उपकरणों के विपरीत, ब्राउज़र-यूज़ दृश्य समझ को एचटीएमएल संरचना पार्सिंग के साथ जोड़ता है, जिससे एआई एजेंट प्राकृतिक भाषा निर्देशों का उपयोग करके ब्राउज़र को नियंत्रित कर सकते हैं। इससे एआई को पृष्ठ की सामग्री को समझने और कार्यों को प्रभावी ढंग से निष्पादित करने में अधिक बुद्धिमान बना देता है। इसके अलावा, यह मल्टी-टैब प्रबंधन, तत्व इंटरैक्शन ट्रैकिंग, कस्टम एक्शन हैंडलिंग और निर्मित त्रुटि पुनर्प्राप्ति तंत्र का समर्थन करता है ताकि स्वचालन कार्यप्रवाह की स्थिरता और निरंतरता सुनिश्चित हो सके।
महत्वपूर्ण रूप से, ब्राउज़र-यूज़ सभी प्रमुख बड़े भाषा मॉडल (जैसे GPT-4, क्लॉड 3, लामा 2) के साथ संगत है। लैंगचेन एकीकरण के साथ, उपयोगकर्ता बस कार्यों का वर्णन प्राकृतिक भाषा में कर सकते हैं, और एआई एजेंट जटिल वेब संचालन को पूरा करेगा। एआई-चालित वेब इंटरैक्शन स्वचालन की तलाश कर रहे उपयोगकर्ताओं के लिए, यह एक शक्तिशाली और आशाजनक उपकरण है।
एआई एजेंट विकास में ब्राउज़र-यूज़ की सीमाएँ
जैसा कि ऊपर उल्लेख किया गया है, ब्राउज़र-यूज़ हैरी पॉटर की जादुई छड़ी की तरह काम नहीं करता है। इसके बजाय, यह ब्राउज़रों को स्वचालित करने के लिए दृश्य इनपुट और एआई नियंत्रण को जोड़ता है, जिसका उपयोग प्ले राइट द्वारा किया जाता है।
ब्राउज़र-यूज़ निश्चित रूप से कुछ कमी के साथ आता है, लेकिन ये सीमाएँ स्वचालन ढांचे से नहीं आती हैं। बल्कि, ये उन्हीं ब्राउज़रों से आती हैं जिनका यह नियंत्रण करता है। प्ले राइट जैसे उपकरण विशेष कॉन्फ़िगरेशन और स्वचालन के लिए उपकरणों के साथ ब्राउज़रों को लॉन्च करते हैं, जो एंटी-बॉट डिटेक्शन सिस्टम के लिए भी उजागर हो सकते हैं।
जिस परिप्रेक्ष्य में, आपका एआई एजेंट अक्सर CAPTCHA चुनौतियों या ब्लॉक किए गए पृष्ठों जैसे "क्षमा करें, हमारे अंत में कुछ गलत हो गया" का सामना कर सकता है। ब्राउज़र-यूज़ की पूरी क्षमता को अनलॉक करने के लिए विचारशील समायोजन की आवश्यकता होती है। अंतिम लक्ष्य एंटी-बॉट सिस्टम को ट्रिगर करने से बचना है ताकि आपका एआई स्वचालन सुचारू रूप से चलता रहे।
विस्तृत परीक्षण के बाद, हम आत्मविश्वास से कह सकते हैं: स्क्रैपिंग ब्राउज़र सबसे प्रभावी समाधान है।
स्क्रैपलेस स्क्रैपिंग ब्राउज़र क्या है?
स्क्रैपिंग ब्राउज़र एक क्लाउड-आधारित, सर्वर रहित ब्राउज़र स्वचालन उपकरण है, जिसे गतिशील वेब स्क्रैपिंग में तीन मुख्य समस्याओं को हल करने के लिए डिज़ाइन किया गया है: उच्चConcurrency bottlenecks, anti-bot evasion, and cost control.
-
यह लगातार एक उच्च-समवर्ती, एंटी-ब्लॉकिंग हेडलेस ब्राउज़र वातावरण प्रदान करता है, जिससे डेवलपर्स को गतिशील सामग्री को आसानी से स्क्रैप करने में मदद मिलती है।
-
इसमें एक वैश्विक प्रॉक्सी आईपी पूल और फिंगरप्रिंटिंग प्रौद्योगिकी है, जो स्वचालित रूप से CAPTCHA को हल करने और ब्लॉकिंग तंत्रों को बायपास करने में सक्षम है।
विशेष रूप से एआई डेवलपर्स के लिए निर्मित, स्क्रैपलेस स्क्रैपिंग ब्राउज़र में गहराई से अनुकूलित क्रोमियम कोर और वैश्विक रूप से वितरित प्रॉक्सी नेटवर्क है। उपयोगकर्ता एआई अनुप्रयोगों और एजेंटों के निर्माण के लिए कई हेडलेस ब्राउज़र उदाहरणों को सुचारू रूप से चला और प्रबंधित कर सकते हैं, जो वेब के साथ बातचीत करते हैं। यह स्थानीय इंफ्रास्ट्रक्चर और प्रदर्शन की बाधाओं को समाप्त करता है, जिससे आप अपनी समाधानों के निर्माण पर पूरी तरह ध्यान केंद्रित कर सकते हैं।
ब्राउज़र-यूज़ और स्क्रैपिंग ब्राउज़र एक साथ कैसे काम करते हैं?
एकीकृत होने पर, डेवलपर ब्राउज़र संचालन का संचालन करने के लिए ब्राउज़र-यूज़ का उपयोग कर सकते हैं जबकि वे स्क्रैपलेस की स्थिर क्लाउड सेवा और मजबूत एंटी-ब्लॉकिंग क्षमताओं पर भरोसा कर सकते हैं ताकि विश्वसनीयता से वेब डेटा हासिल किया जा सके।
ब्राउज़र-यूज़ सरल एपीआई प्रदान करता है जो एआई एजेंटों को वेब सामग्री को "समझने" और बातचीत करने की अनुमति देता है। उदाहरण के लिए, यह उपभोक्ता को निर्देशों की व्याख्या करने के लिए ओपनएआई या एंथ्रोपिक जैसे LLMs का उपयोग कर सकता है और प्ले राइट के माध्यम से ब्राउज़र में कार्यों जैसे खोज या लिंक क्लिक की क्रियाएँ पूर्ण कर सकता है।
Here is the translation of your text into Hindi:
Scrapeless का स्क्रैपिंग ब्राउज़र इस सेटअप को इसके कमजोरियों को ठीक करके पूरा करता है। जब बड़े वेबसाइटों के साथ कठोर एंटी-बॉट उपायों का सामना करना होता है, तो इसका उच्च-संवहन प्रॉक्सी समर्थन, CAPTCHA हल करना और ब्राउज़र अनुकरण तंत्र स्थिर स्क्रैपिंग सुनिश्चित करते हैं।
सारांश में, ब्राउज़र-उपयोग बुद्धिमत्ता और कार्य समन्वय को संभालता है, जबकि Scrapeless एक मजबूत स्क्रैपिंग आधार प्रदान करता है, जिससे स्वचालित ब्राउज़र कार्य अधिक कुशल और विश्वसनीय बनते हैं।
एक स्क्रैपिंग ब्राउज़र को ब्राउज़र-उपयोग के साथ कैसे एकीकृत करें?
चरण 1. Scrapeless API कुंजी प्राप्त करें
- Scrapeless डैशबोर्ड पर रजिस्टर और लॉगिन करें।
- "सेटिंग्स" पर जाएं।
- "API कुंजी प्रबंधन" पर क्लिक करें।
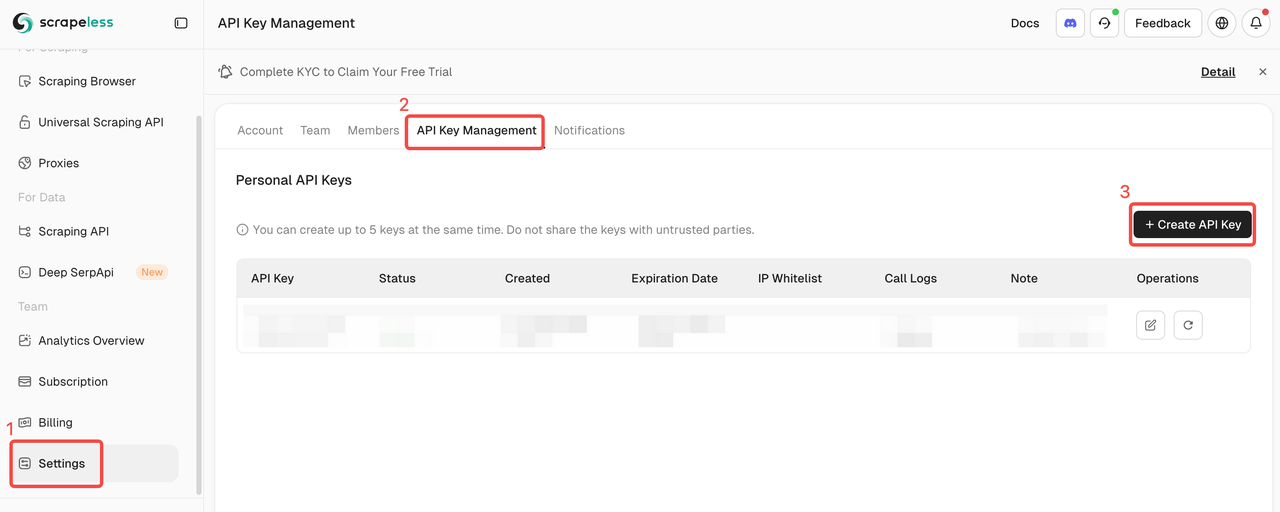
फिर अपने .env फ़ाइल में SCRAPELESS_API_KEY वातावरणीय चर को कॉपी और सेट करें।
ब्राउज़र-उपयोग में AI सुविधाओं को सक्षम करने के लिए, आपको एक बाहरी AI प्रदाता से एक वैध API कुंजी की आवश्यकता है। इस उदाहरण में, हम OpenAI का उपयोग करेंगे। यदि आपने अभी तक एक API कुंजी उत्पन्न नहीं की है, तो एक बनाने के लिए OpenAI के आधिकारिक गाइड का पालन करें।
आपकी .env फ़ाइल में OPENAI_API_KEY वातावरणीय चर की भी आवश्यकता है।
अस्वीकरण: निम्नलिखित चरण OpenAI के साथ एकीकरण पर केंद्रित हैं, लेकिन आप नीचे दिए गए आपके आवश्यकताओं के अनुसार अनुकूलित कर सकते हैं, बस सुनिश्चित करें कि आप ब्राउज़र-उपयोग द्वारा समर्थित किसी अन्य AI उपकरण का उपयोग करें।
.evn
OPENAI_API_KEY=your-openai-api-key
SCRAPELESS_API_KEY=your-scrapeless-api-key💡 याद रखें कि नमूना API कुंजी को आपके वास्तविक API कुंजी से बदलें
अगला, अपने प्रोग्राम में ChatOpenAI का आयात करें: langchain_openaiagent.py
Plain Text
from langchain_openai import ChatOpenAIनोट करें कि ब्राउज़र-उपयोग AI एकीकरण को संभालने के लिए LangChain पर निर्भर करता है। इसलिए, भले ही आपने अपने प्रोजेक्ट में स्पष्ट रूप से langchain_openai स्थापित नहीं किया हो, यह पहले से उपयोग के लिए उपलब्ध है।
gpt-4o OpenAI एकीकरण को निम्नलिखित मॉडल के साथ सेट करता है:
Plain Text
llm = ChatOpenAI(model="gpt-4o")कोई अतिरिक्त कॉन्फ़िगरेशन की आवश्यकता नहीं है। ऐसा इसलिए है क्योंकि langchain_openai स्वचालित रूप से OPENAI_API_KEY वातावरणीय चर से API कुंजी को पढ़ता है।
अन्य AI मॉडलों या प्रदाताओं के साथ एकीकरण के लिए, आधिकारिक ब्राउज़र-उपयोग दस्तावेज़ को देखें।
चरण 2. ब्राउज़र उपयोग स्थापित करें
पाइप के साथ (Python कम से कम v.3.11):
Shell
pip install browser-useस्मृति कार्यक्षमता के लिए (PyTorch संगतता के कारण Python<3.13 की आवश्यकता है):
Shell
pip install "browser-use[memory]"चरण 3. ब्राउज़र और एजेंट कॉन्फ़िगरेशन सेट करें
यहाँ पर ब्राउज़र कॉन्फ़िगरेशन और एक ऑटोमेशन एजेंट बनाने का तरीका है:
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Google पर जाएं, 'Scrapeless' के लिए खोजें, पहले पोस्ट पर क्लिक करें और शीर्षक पर लौटें"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # या आपके द्वारा उपयोग किए जाने वाले मॉडल को चुनें
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)चरण 4. मुख्य फ़ंक्शन बनाएं
यहाँ मुख्य फ़ंक्शन है जो सब कुछ एक साथ रखता है:
Python
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())चरण 5. अपने स्क्रिप्ट को चलाएँ
अपने स्क्रिप्ट को चलाएँ:
Shell
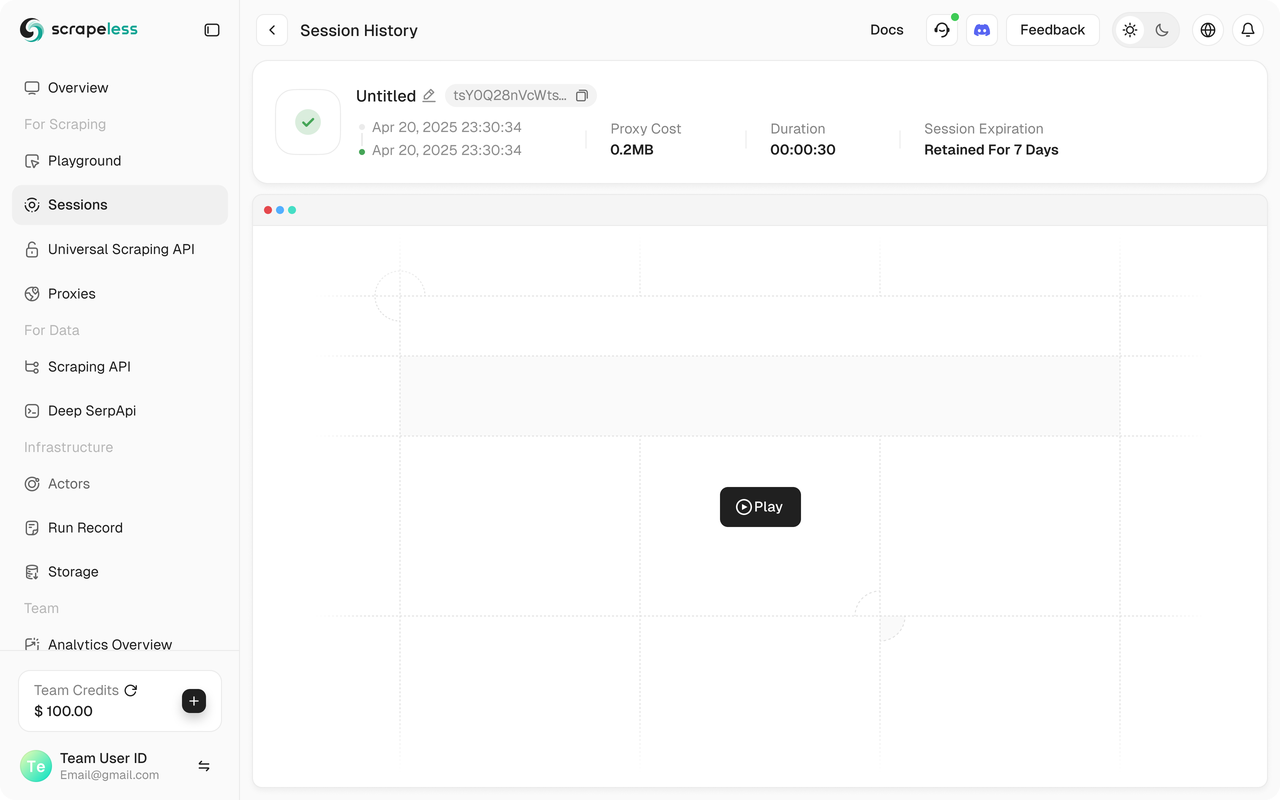
python run main.pyआपको Scrapeless डैशबोर्ड में अपना Scrapeless सत्र शुरू करते हुए देखना चाहिए।
इसके अलावा, Scrapeless सत्र पुनर्प्रजनन का समर्थन करता है, जो कार्यक्रम दृश्यता सक्षम करता है। कार्यक्रम चलाने से पहले, सुनिश्चित करें कि आपने वेब रिकॉर्डिंग फ़ंक्शन को सक्षम किया है। जब सत्र समाप्त हो जाता है, तो आप सीधे डैशबोर्ड पर रिकॉर्ड देख सकते हैं जिससे आपको समस्याओं का तेजी से समाधान करने में मदद मिलती है।
पूर्ण कोड
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "गूगल पर जाएं, 'Scrapeless' के लिए खोजें, पहले पोस्ट पर क्लिक करें और शीर्षक पर वापस आएं"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # या उस मॉडल को चुनें जिसे आप उपयोग करना चाहते हैं
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())💡 ब्राउज़र उपयोग वर्तमान में केवल पायथन का समर्थन करता है।
💡 आप लाइव सत्र में URL की प्रतिलिपि ले सकते हैं ताकि सत्र की प्रगति को वास्तविक समय में देखा जा सके, और आप सत्र इतिहास में सत्र का पुनःप्रشारण भी देख सकते हैं।
चरण 6. परिणाम चलाना
JavaScript
{
"done": {
"text": "पहले खोज परिणाम का शीर्षक जो क्लिक किया गया है: 'Effortless Web Scraping Toolkit - Scrapeless' है।",
"success": True,
}
}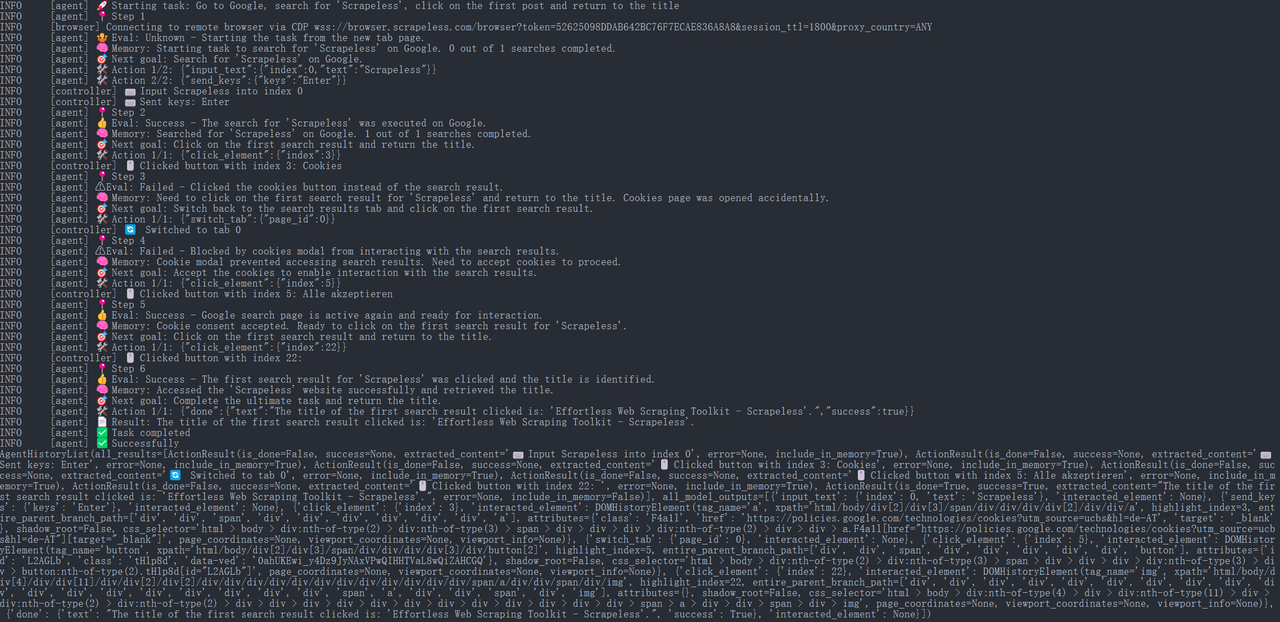
इसके बाद, ब्राउज़र उपयोग एजेंट स्वचालित रूप से URL खोलेगा और पृष्ठ का शीर्षक प्रिंट करेगा: “Scrapeless: Effortless Web Scraping Toolkit” (यह Scrapeless के आधिकारिक होमपेज पर शीर्षक का एक उदाहरण है)।
पूरी निष्पादन प्रक्रिया को Scrapeless कंसोल में "डैशबोर्ड" → "सत्र" → "सत्र इतिहास" पृष्ठ के तहत देखा जा सकता है, जहां आप हाल ही में निष्पादित सत्र के विवरण देखेंगे।
चरण 7. परिणाम निर्यात करना
टीम साझाकरण और संग्रहण उद्देश्यों के लिए, हम स्क्रैप की गई जानकारी को JSON या CSV फ़ाइल में सहेज सकते हैं। उदाहरण के लिए, निम्नलिखित कोड स्निपेट शीर्षक परिणामों को एक फ़ाइल में लिखने का तरीका दिखाता है:
Python
import json
from pathlib import Path
def save_to_json(obj, filename):
path = Path(filename)
path.parent.mkdir(parents=True, exist_ok=True)
with path.open('w', encoding='utf-8') as f:
json.dump(obj, f, ensure_ascii=False, indent=4)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
save_to_json(result.model_dump(), "scrapeless_update_report.json")
await browser.close()
asyncio.run(main())उपर्युक्त कोड यह दिखाता है कि फ़ाइल कैसे खोली जाए और JSON प्रारूप में सामग्री लिखी जाए, जिसमें खोज कीवर्ड, लिंक, और पृष्ठ शीर्षक शामिल हैं। उत्पन्न scrapeless_update_report.json फ़ाइल को आंतरिक रूप से कंपनी ज्ञान आधार या सहयोग प्लेटफ़ॉर्म के माध्यम से साझा किया जा सकता है, जिससे टीम के सदस्यों के लिए स्क्रैपिंग परिणाम देखना आसान हो जाता है। सरल पाठ प्रारूप के लिए, आप बस एक्सटेंशन को .txt में बदल सकते हैं और इसके बजाय बुनियादी पाठ आउटपुट विधियों का उपयोग कर सकते हैं।
समापन
Scrapeless की स्क्रैपिंग ब्राउज़र सेवा का उपयोग करते हुए और ब्राउज़र उपयोग AI एजेंट के साथ, हम जानकारी पुनर्प्राप्ति और रिपोर्टिंग के लिए एक स्वचालित प्रणाली आसानी से बना सकते हैं।
- Scrapeless एक स्थिर और कुशल क्लाउड-आधारित स्क्रैपिंग समाधान प्रदान करता है जो जटिल एंटी-स्क्रैपिंग तंत्र को संभाल सकता है।
- ब्राउज़र उपयोग AI एजेंट को बुद्धिमानी से ब्राउज़र को नियंत्रित करने की अनुमति देता है ताकि खोज, क्लिक, और निष्कर्षण जैसे कार्य किए जा सकें।
यह एकीकरण डेवलपर्स को स्वचालित एजेंटों को थकाऊ वेब डेटा संग्रह कार्यों को सौंपने की अनुमति देता है, शोध दक्षता को महत्वपूर्ण रूप से बढ़ाता है जबकि सटीकता और वास्तविक समय के परिणामों को सुनिश्चित करता है।
Scrapeless का स्क्रैपिंग ब्राउज़र AI को नेटवर्क अवरोधों से बचाने में मदद करता है जबकि वास्तविक समय में खोज डेटा प्राप्त करता है और संचालन की स्थिरता सुनिश्चित करता है। ब्राउज़र उपयोग की लचीली रणनीति इंजन के साथ मिलकर, हम एक अधिक शक्तिशाली AI स्वचालन शोध उपकरण बनाने में सक्षम हैं जो स्मार्ट व्यवसायिक निर्णय लेने के लिए मजबूत समर्थन प्रदान करता है। यह उपकरण सेट AI एजेंटों को "क्वेरी" वेब सामग्री के रूप में काम करने में सक्षम बनाता है जैसे कि वे किसी डेटाबेस के साथ बातचीत कर रहे हों, जिससे मैनुअल प्रतियोगी निगरानी की लागत में बड़ी कमी और R&D तथा विपणन टीमों की दक्षता में सुधार होता है।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


