
स्क्रैपलेस एक्स ब्राउज़र उपयोग
Senior Web Scraping Engineer
ब्राउज़र उपयोग एक ब्राउज़र स्वचालन SDK है जो स्क्रीनशॉट का उपयोग करके ब्राउज़र की स्थिति और क्रियाओं को कैप्चर करता है ताकि उपयोगकर्ता इंटरैक्शन का अनुकरण किया जा सके। यह अध्याय यह बताएगा कि आप बैखरण-सहायता का उपयोग करके सरल कॉल के साथ वेब पर एजेंट कार्यों को कैसे आसानी से निष्पादित कर सकते हैं।
स्क्रैपलेस API कुंजी प्राप्त करें
डैशबोर्ड के सेटिंग टैब पर जाएं:
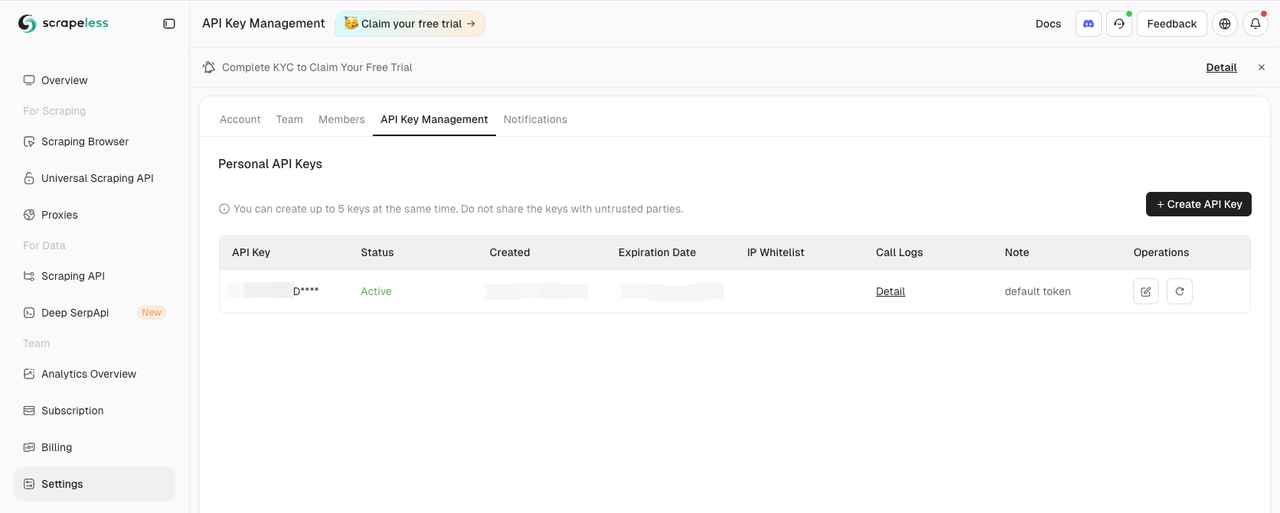
फिर अपनी .env फ़ाइल में SCRAPELESS_API_KEY पर्यावरण चर कॉपी करें और सेट करें।
आपकी .env फ़ाइल में OPENAI_API_KEY पर्यावरण चर भी आवश्यक हैं।
.env
OPENAI_API_KEY=आपकी-openai-api-कुंजी
SCRAPELESS_API_KEY=आपकी-सक्रैपलेस-api-कुंजी💡 याद रखें कि नमूना API कुंजी को अपनी वास्तविक API कुंजी से बदलें
ब्राउज़र उपयोग स्थापित करें
pip के साथ (Python>=3.11):
Shell
pip install browser-useमेमोरी कार्यक्षमता के लिए (PyTorch संगतता के कारण Python<3.13 की आवश्यकता है):
Shell
pip install "browser-use[memory]"ब्राउज़र और एजेंट कॉन्फ़िगरेशन सेट करें
यहाँ दिखाया गया है कि ब्राउज़र को कैसे कॉन्फ़िगर करें और एक स्वचालन एजेंट कैसे बनाएं:
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Google पर जाएं, 'Scrapeless' के लिए खोजें, पहले पोस्ट पर क्लिक करें और शीर्षक पर लौटें"
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": os.environ.get("SCRAPELESS_API_KEY"),
"session_ttl": 180,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # या वह मॉडल चुनें जिसका आप उपयोग करना चाहते हैं
api_key=SecretStr(os.environ.get("OPENAI_API_KEY")),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)मुख्य फ़ंक्शन बनाएँ
यहाँ मुख्य फ़ंक्शन है जो सब कुछ एक साथ लाता है:
Python
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())अपनी स्क्रिप्ट चलाएँ
अपनी स्क्रिप्ट चलाएँ:
Shell
python run main.pyआपको स्क्रैपलेस डैशबोर्ड में आपका स्क्रैपलेस सत्र शुरू होता हुआ देखना चाहिए।
पूरा कोड
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Google पर जाएं, 'Scrapeless' के लिए खोजें, पहले पोस्ट पर क्लिक करें और शीर्षक पर लौटें"
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": os.environ.get("SCRAPELESS_API_KEY"),
"session_ttl": 180,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # या वह मॉडल चुनें जिसका आप उपयोग करना चाहते हैं
api_key=SecretStr(os.environ.get("OPENAI_API_KEY")),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())💡 ब्राउज़र उपयोग वर्तमान में केवल Python का समर्थन करता है।
💡 आप लाइव सत्र में URL कॉपी कर सकते हैं ताकि आप सत्र की प्रगति को वास्तविक समय में देख सकें, और आप सत्र इतिहास में सत्र की पुनरावृत्ति भी देख सकते हैं।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


